







博士,开发人员,经理,教授和算法交易员-路易斯博士的故事
原文:https://blog.quantinsti.com/developer-manager-professor-algo-trader-epat-success-story-luiz-guedes/
如果我们告诉你一个人,他不仅接受了科学教育,进入了软件行业,然后进入了金融行业,现在还学习了算法交易,你会相信我们吗?
如果我们说他也学会了三种武术呢?
难以置信?这正是路易斯博士的故事。
Luiz 博士拥有 PUC/里约 pontifíCIA Universidade católica do Rio de Rio de Janeiro/Rio 的计算机科学博士学位、IME 的计算机系统硕士学位和计算机工程师学位。此外,他拥有 FGV 瓦加斯基金会的工商管理硕士学位。
他总是在不断地寻求克服自己,成为一个更好的人——不仅在智力上,而且作为一个人。他说,学习让他变得更好,帮助他理解世界是如何运转的,并给他一个探索新机会的机会。
我们联系了路易斯博士,这是他与我们分享的他的生活故事。
嗨,路易斯博士,给我们介绍一下你自己

嗨!我的名字是路易斯·古德斯。我是一名计算机工程师,拥有计算机科学学位,是巴西里约热内卢军事学院的教授。
26 年前,我获得博士学位后,从事软件开发工作,后来,我获得了工商管理硕士学位,并为科技公司工作。我做了 30 年的软件开发人员,现在是 Occam Brasil gesto de Recursos 的资产经理和定量分析主管。
我喜欢武术,练过跆拳道,是合气道黑带,现在在练咏春。几年前,我的父亲心脏病发作,大约在那个时候,我意识到我需要努力保持健康。
那时,我喜欢让·克劳德·云顿的电影,这让我对学习武术产生了兴趣,从 1996 年开始学习跆拳道。
我热爱外语,我学过汉语、韩语和日语。总的来说,我知道超过 6 种语言。
从科学到金融,再到现在的算法交易——这是怎么发生的?
我妈妈说,
那些更优秀的人总会有一席之地。
所以,我总是努力变得更好。我不能做我不知道的事。所以,当我读 MBA 的时候,尽管我发现这些知识很有趣,但我不能应用它们。
在巴西,有一句谚语,
人们总是会成长到顶峰,然后就会跌倒。
我觉得这是真的,因此,尽管我很喜欢这个管理职位,但我还是决定不做了。我没有不愉快的感觉。
我对金融的兴趣是大约三年前通过我的哥哥产生的,他对比特币非常好奇。慢慢地,我也开始交易比特币。6 个月后,我意识到这不值得大肆宣传。所以,我去了股票市场,开始自学。
我总是通过各种量化网站和各种在线内容不断寻找学习算法交易。我仍然总是在网上寻找参考资料。
我开始学习技术分析,研究技术指标。那时我还不知道 Python,但是如果我使用 C 和 C++的话。我还为我的交易创造了一个 algo 交易机器人。
我注意到:
- 虽然技术分析很有趣,但有时它不起作用
- 有很多事情我不明白
- 有些我不知道为什么会发生
我意识到我需要很多知识:
- 关于市场
- 市场背后发生了什么
- 对图表的理解
我相信正规学习,因为尽管我自己学习过,自己研究过,但拥有结构化的知识对于避免信息差距非常重要。
这对你的知识和理解至关重要。这就是我当初开始修技术分析课程的原因,但都是徒劳。
因此,我一直在寻找有用的学习资源,就在那时,我发现了 QuantInsti 的白皮书和博客。此后不久,我浏览了 EPAT 的教学大纲,意识到这正是我要找的内容。
我可以回答我一直在问的所有问题。我终于有了一个可以问我问题的人,而不必再继续寻找答案了。
我心想,这看起来很有趣,我可以自己从中赚钱。我只用了一天时间就报名参加了 EPAT 项目!
我之前工作的软件开发公司被另一家公司收购了,公司的方向也变了。所以,我不得不搬家。我可能会跳槽到同一行业的另一家公司,或者干脆跳槽到一个新的行业。
我喜欢交易,写软件和做分析。所以,我和一个朋友谈了这件事。他的朋友在银行和市场工作,所以也许他可以把我介绍给他们。这正是我即将完成 EPAT 课程的时候。
就在那时,我被介绍给了三家公司!如果我没有参加 EPAT 的课程,我肯定能胜任这份工作。EPAT 让我的快速职业转变成为可能,并为我提供了新的机会。从 EPAT 毕业后,我现在在一家做投资基金的资产管理公司做量化分析师。
我一直认为交易是我退休后会做的事情,但我现在仍然在做。
EPAT 是如何为你的专业知识增值的?
EPAT 课程有三大支柱——计算机编程、金融和数学。这三个领域之间的平衡以及这种知识的混合方式使其更有意义和可操作性。我们可以在工作、交易或投资中使用这些知识。
我相信这才是真正打动我的地方!我觉得这是 EPAT 课程最大的好处和优势!
我以前的知识只和计算机科学有关,而且我有非常好的工科基础。但是我在金融方面有知识空白,我没有应用我所拥有的知识。这是我在 EPAT 期间做的事情。
在参加 EPAT 课程之前,我不知道交易中有一些东西。交易需要很多知识,尤其是当你投资股票的时候。
人们需要意识到:
- 事情应该如何发展
- 事情不应该怎样发展
- 风险管理
- 理解统计数据背后的数学
- 如何获得对你有利的概率等。
现场讲座:我以前参加过的所有课程都有预先录制的课程,而 EPAT 讲座提供了一种人情味,这是我所欣赏的。我发现现场课堂讲课非常有趣。
解决我的疑问:我提出的任何问题都很快得到了解答。我学到了很多我甚至不知道存在过的东西。在与我的 EPAT 团队联系时,我注意到 EPAT 有来自科学、数学、计算机科学和许多其他领域的参与者!
在 EPAT,我学到了很多现在对我有帮助的东西,特别是如何创造更好的交易算法。我学会了如何编写更好的 Algo 交易软件。我会在课堂上学习 Python,练习它,然后在我的系统上尝试。这帮助我找到了如何在交易中使用它的方法,我意识到这对我来说简单多了。这种实践学习是第一个直接的好处。
哦,我喜欢这些作业!他们对我来说是无价的。他们几乎是我所寻找的一切,来扩展我的边界。
项目工作:当我的 EPAT 项目工作被指派一名导师时,最初我有点担心导师是否知道我想做的事情,以及与之相关的话题。但是,令我惊讶的是,他们知道的比我做的多得多!所以,我的恐惧很快就消失了。
分享一个你最喜欢的 EPAT 特色!
师资力量、内容、平台——都非常好。
有像欧内斯特·陈博士、托马斯·斯塔克博士、尤安·辛克莱博士这样令人难以置信的教授上课,以及完整的师资基础是令人难以置信的。他们拥有的知识是杰出的,就好像他们是为此而生的。
即使在他们的讲座结束后,教员们也总是乐意回答你的问题和疑虑。我会和他们联系,给他们发问题,他们总是迅速回复我的问题,并给我的项目提供有用的建议。所以,对我来说,教师是 EPAT 最好的特色。
课程设置真的很好,平台完美无瑕,工作起来像新机器一样!
你给 Algo 交易爱好者的建议。
继续成长!
在攻读 MBA 期间,我发现学习管理比应用概念更有趣。今天,当我在团队项目中工作时,或者当我必须与人打交道或帮助他们时,这些知识对我很有帮助。
当我为支付行业开发技术时,我并不了解数据科学。所以,我做了一些数据科学方面的认证,我发现这真的很有趣。今天,它对我的背景帮助很大。学什么都没有浪费。
继续努力!
即使是在跳 EPAT 舞的时候,每周我都努力练习我所学的内容。如果我今天能或者不能练习我的编码,下周我会再试一次。我一直在努力。我发现做一点点事情比什么都不做要多得多。所以,继续努力。
人们为我会说 7 种语言而鼓掌,并对我是如何做到的感到震惊。但是这些年来,这对我来说是一种渐进的成长。你也可以的!
继续学习!
如果你知道一些东西,或者即使你对算法交易一无所知,EPAT 是一个很好的起点。当你成为全球 EPAT 校友社区的一员时,你可以终身学习。
您可以随时查看课程的最新进展,并通过最新的 EPAT 讲座获取最新的市场内容。
我只是一个金融初学者,因为我有计算机科学的背景。但是,我的金融和交易知识,以及技能,来自 EPAT 的课程,而且它们还在增长。
人们年轻时就开始在金融市场工作。50 多岁的我很难找到一份工作,相比之下,今天在这个领域刚刚起步的人。市场害怕雇佣老年人。
你可能有很多经验,很多技能和很多知识,但你可能会因为没有坚持学习而错过一个好的工作机会。所以,继续学习。首先,EPAT 是个好地方。
感谢您抽出时间与我们交谈,路易斯博士。得知你这些年来取得的成就和成功,我们感到很惊讶,我们希望你能有所成就。最美好的祝愿!
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
交易阿尔法:开发微阿尔法生成系统[网络研讨会]
原文:https://blog.quantinsti.com/developing-micro-alpha-generating-system-webinar-18-november-2022/
https://www.youtube.com/embed/xga-aObEd6g?rel=0
关于会议
这节课通过识别各种微阿尔法机会向你介绍阿尔法交易的技巧。它涵盖了各种微阿尔法策略,参数优化的过程,以及如何开发一个交易系统。
概观
- 阿尔法交易简介
- 微阿尔法的概念
- 参数置换过程
- 各种微阿尔法策略
- 阿尔法的类型
- 互动问答
扬声器简介
Thomas Starke 博士(AAAQuants 首席执行官)

Starke 博士拥有物理学博士学位,目前担任澳大利亚领先的自营交易公司 AAAQuants 的首席执行官,领导着该公司的量化交易团队。他还在牛津大学担任高级研究员。
rushda an sari(QuantInsti 技术内容经理)

Rushda 是 quantin STI Quantra 研究和内容团队的技术内容经理。她的教育背景包括金融管理研究生文凭。此外,在股票交易方面,她也有实践经验。
本次网络研讨会于:
2022 年 11 月 18 日星期五
东部时间上午 6:00 | IST 时间下午 4:30 |新加坡时间下午 7:00
Python 中的对角点差期权交易策略
原文:https://blog.quantinsti.com/diagonal-spreads-options-trading-strategy-python/
到了 Viraj Bhagat
市场发展迅速,交易在很短的时间内完成。无数的交易者和无数的策略在这个过程中扮演着他们的角色。在一天结束的时候,一些人漂浮着,而一些人向上航行,一些人绊倒,甚至跌倒,第二天再站起来。交易期权在这方面起着关键的作用,因为它们为交易者提供了创造多种策略的能力,但却耗费了时间。市场上有很多这样的策略,花时间去学习它们和研究它们的技术细节是很重要的。虽然股票可能只允许一个人交易看跌或看涨,但他们经常横向移动,但在特定的范围内。正是在这种情况下,你进入了一个对角线传播。
什么是价差?
证券的同时买入和卖出被称为价差或价差交易或相对价值交易,通常以期货合约和期权为支柱进行。除此之外,有时也使用证券。价差可以由买入或卖出构成,既可以是借方价差,也可以是贷方价差。基于月份和分支的关系,创建跨页结构并将其区分为垂直跨页、水平跨页和对角跨页。
什么是对角线传播?
对角传播策略是:
- 一个期权交易策略
- 两步战略
- 结合了长通话日历分布和短通话分布
垂直价差、水平价差和对角价差的比较
根据 Investopedia 的说法,对角线传播利用不同的月份和打击,它沿对角线移动,因此得名。

虽然据说这些在以前的报纸上被称为:【1】
- 期权价格>以表格方式列出
- 执行价格>按行列出,即垂直列出
- 过期时间>列中列出,即水平
因此,对角线分布意味着在不同行和列中存在具有不同执行价格和到期日的期权。
日历跨页和对角线跨页的差异
对角价差的近期前景可能是看跌或看涨。它类似于日历跨页,因为:
- 卖出近期期权
- 买入长期期权
- 利用即将到期选项中的快速时间衰减
什么是对角线呼叫传播?
当前景略微乐观时,人们会卖出较高的近月看涨期权,而卖出较低的远月看涨期权
什么是对角卖出价差?
当前景略微看跌时,人们卖出较低的近月看跌期权,而卖出较高的远月看跌期权
什么时候执行对角扩展?
- 你认为会上涨(如果买入)或再次下跌(如果卖出)的短期弱势或强势,然后利用它
- 该策略是在短期内控制风险,如果市场运行平稳,它就可以在长期内开放
- 当为了钱而执行时,它允许满足保证金要求
- 空头期权到期自动柜员机无价值> IV 扩大>增加剩余多头期权的价格>保留卖出期权的全部信用>降低我们拥有的多头期权的成本基础
- 对角线价差>短边到期无价值>金钱>买入>长边价差
改变是关键!
一个人必须时刻注意和警惕他/她的策略的表现。如果在任何情况下,传播需要一些调整,它将不得不小心,以防止任何损失。一个人可以在战略实施后,通过持续研究市场并暗示其战略的变化来获得最大利益,从而将它作为一种优势。
从对角价差交易策略中获利
对角线价差的最大利润可描述如下:
- 最大值利润=收到的净信贷* -为买入期权支付的溢价(买入期权 B)
- *净信贷是通过卖出买入期权 A)获得的
对角线价差交易策略的损失
对角线排列的最大损失可描述如下:
- 对于净信贷:最大损失=执行 A–执行 B–净信贷记录。
- 对于净借方:最大损失=执行 A–执行 B +已付净借方
对角扩展策略的设置
如果交易朝着我们的方向快速发展,你可能会赔钱。因此,与其他跨页相比,对角线跨页的设置非常重要。它涉及同时购买:
- 同等数量的选择
- 这两个选项应该属于同一类
- 两者应该具有相同的基础安全性
- 两种不同的执行价格
- 2 个不同的到期月
一个电话的对角线传播看起来像这样: 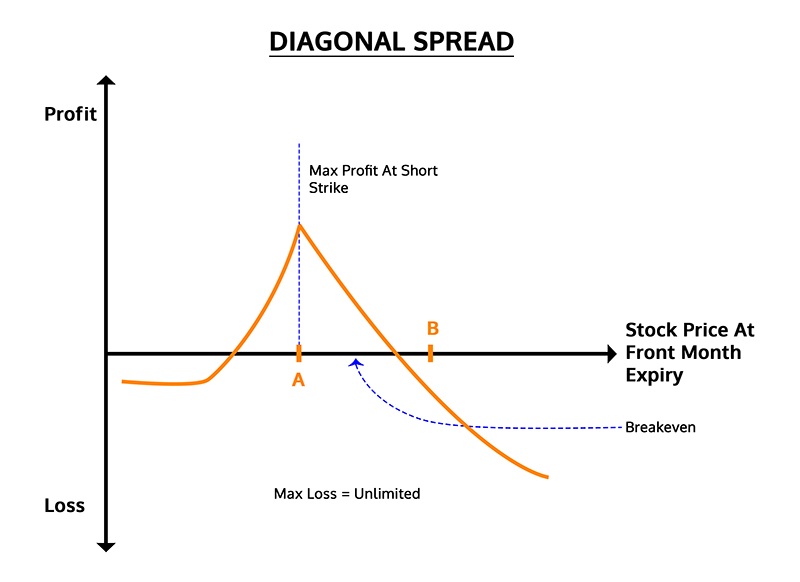
策略(在‘呼叫’的情况下)
- 卖出 1 个 OTM 看涨期权-较低的执行价格-交割月
- 购买 1 个 OTM 看涨期权–B–更高的执行价格–后一个月(长期)
- 股票通常会低于执行价 A
我们将借助一个例子来解释这个策略。
长呼对角传播
实施多头对角价差交易策略
我将解释使用长时间看涨期权的对角线传播的示例,为此,我将使用 NIFTY(Ticker-NIFTY)的示例。以下是 NIFTY  的期权链。我们现在将从 2018 年 4 月和 2018 年 5 月获取 2 个看涨期权价格2018 年 4 月:
的期权链。我们现在将从 2018 年 4 月和 2018 年 5 月获取 2 个看涨期权价格2018 年 4 月: 2018 年 5 月:
2018 年 5 月: 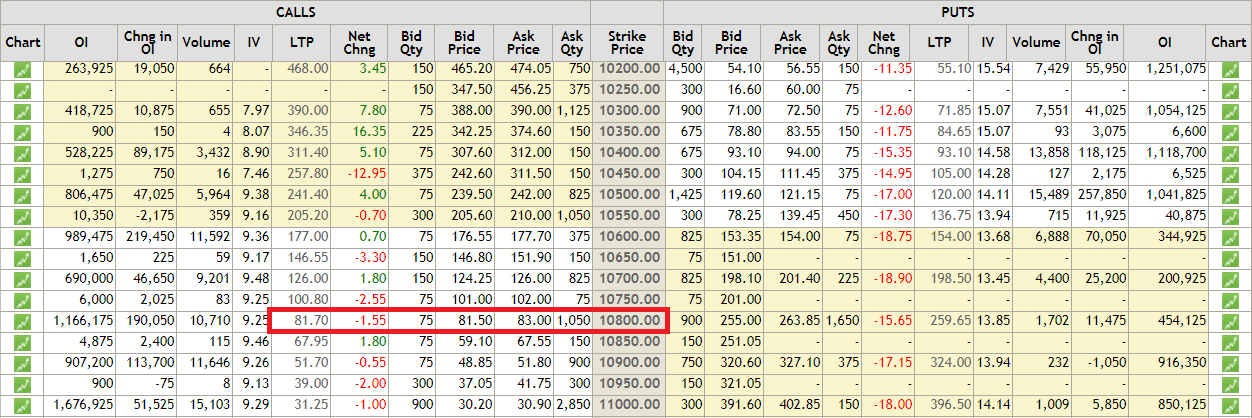
策略
# Importing Libraries
# Data manipulation
import numpy as np
import pandas as pd
# To plot
import matplotlib.pyplot as plt
import seaborn
plt.style.use('ggplot')
# BS Model
import mibian
# Importing Libraries
# Data manipulation
import numpy as np
import pandas as pd
# To plot
import matplotlib.pyplot as plt
import seaborn
plt.style.use('ggplot')
# BS Model
import mibian
# Nifty futures price
nifty_april_fut = 10595.40
nifty_may_fut = 10625.50
april_strike_price = 10700
may_strike_price = 10800
april_call_price = 10
may_call_price = 82
setup_cost = may_call_price - april_call_price
# Today's date is 20 April 2018\. Therefore, days to April expiry is 7 days and days to May expiry is 41 days.
days_to_expiry_april_call = 6
days_to_expiry_may_call = 41
# Range of values for Nifty
sT = np.arange(0.97*nifty_april_fut,1.03*nifty_april_fut,1)
#interest rate for input to Black-Scholes model
interest_rate = 0.0
# Front-month IV
april_call_iv = mibian.BS([nifty_april_fut, april_strike_price, interest_rate, days_to_expiry_april_call],
callPrice=april_call_price).impliedVolatility
print "Front Month IV %.2f" % april_call_iv,"%"
# Back-month IV
may_call_iv = mibian.BS([nifty_may_fut, may_strike_price, interest_rate, days_to_expiry_may_call],
callPrice=may_call_price).impliedVolatility
print "Back Month IV %.2f" % may_call_iv,"%"
Front Month IV 8.53 %
Back Month IV 11.26 %
# Changing days to expiry to a day before the front-month expiry
days_to_expiry_april_call = 0.001
days_to_expiry_may_call = 35 - days_to_expiry_april_call
df = pd.DataFrame()
df['nifty_price'] = sT
df['april_call_price'] = np.nan
df['may_call_price'] = np.nan
# Calculating call price for different possible values of Nifty
for i in range(0,len(df)):
df.loc[i,'april_call_price'] = mibian.BS([df.iloc[i]['nifty_price'], april_strike_price, interest_rate, days_to_expiry_april_call],
volatility=april_call_iv).callPrice
# Since, interest rate is considered 0%, 35 is added to the nifty price to get the Nifty December futures price.
df.loc[i,'may_call_price'] = mibian.BS([df.iloc[i]['nifty_price']+35, may_strike_price, interest_rate, days_to_expiry_may_call],
volatility=may_call_iv).callPrice
df.head()
nifty_price april_call_price may_call_price
0 10277.538 0.0 27.305711
1 10278.538 0.0 27.455138
2 10279.538 0.0 27.605211
3 10280.538 0.0 27.755935
4 10281.538 0.0 27.907309
df['payoff'] = df.may_call_price - df.april_call_price - setup_cost
plt.figure(figsize=(10,5))
plt.ylabel("Payoff")
plt.xlabel("Nifty Price")
plt.plot(sT,df.payoff)
plt.show()
 T2】
T2】max_profit = max(df['payoff'])
min_profit = min(df['payoff'])
print "%.2f" %max_profit
print "%.2f" %min_profit
35.55
-88.94
最大利润:35.55 印度卢比 最大损失:88.94 印度卢比
结论
经验丰富的老手和更高级的人最常采用这种策略,因为它包括卖出 2 个期权,同时具有一定的波动性和可预测性;但股价稳定。因此,要实施这种策略,你需要对市场和他的选择相当透彻。
现代交易需要系统的方法,需要引导自己远离直觉交易。通过我们的系统期权交易课程,学习如何以系统的方式交易期权。此外,你可以探索期权交易策略,如蝴蝶,铁秃鹰和传播策略。立即注册!
下载数据文件
- 对角扩散期权策略——Python 代码
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
定量分析师和技术分析师的区别
原文:https://blog.quantinsti.com/difference-quants-technical-analysts/
定量分析师和技术分析师是一个硬币的两面。因为技术分析师和量化分析师都为算法交易实践工作,他们相互联系但又各自独立。通过找出每一个是如何单独工作的,您可以更好地了解每一个的重要性以及融合如何有用。
本博客涵盖:
定量分析师和技术分析师有什么相同点和不同点?
当我们在比较这两个角色时发现了相似之处,就更容易筛选出它们的不同之处。角色不同,责任也不同。
定量分析师和技术分析师的相似之处
| 定量分析师和技术分析师 |
| 用于算法交易领域 |
| 使用技术指标,如趋势线,移动平均线,均值回归 |
| 看看市场过去的表现 |
| 帮助创建交易策略,包括进场和出场信号,以及仓位大小算法 |
定量分析师和技术分析师的区别
| Quants | 技术分析师 |
| 定量分析师不仅预测市场未来的行为,还专注于创造交易策略 | 技术分析师专注于借助历史市场数据预测市场未来的行为 |
| 定量分析师使用数学、统计和金融学位 | 需要注册金融技术员、注册市场技术员或类似的金融学位 |
| 定量分析师给出夏普比率、预期风险、预期回报和其他特定算法或策略的统计数据 | 技术分析师根据过去类似的情况给出市场上的买入或卖出信号 |
| 以及技术指标/工具,如移动平均线、振荡指标、趋势线等。定量分析师还使用机器学习、神经网络和夏普比率等统计工具。 | 技术分析师利用技术指标和基于市场过去表现的先入之见 |
技术分析示例
我用图形表示了随机指标的值/结果,下面给出了一个简单的例子:

在上图中,从左到右显示了%K(随机指标值)线。这个%K 用蓝线表示,显示了在过去 14 个周期中收盘价和最低价之差占最高价和最低价之差的比例。当%K 高于 80 时,这是一个超买的情况,当%K 低于 20 时,这是一个超卖的情况。
类似地,%D 是平滑的随机指标值,它也产生买卖信号。要了解更多关于随机振荡器的知识,你可以注册我们的 Python 交易课程!
定量分析的例子
定量分析的一个例子是在使用技术指标后创建的交易策略的夏普比率。
在这种情况下,我们可以说,在使用随机振荡器并看到超买和超卖的情况后,定量分析师将在夏普比率的基础上制定交易策略。夏普比率衡量投资资产或交易策略中每单位标准差的超额回报。
- 高夏普比率——单位风险回报更高
- 夏普比率低——单位风险回报率更高
**夏普比率方程:**夏普比率= (Rp - Rf) / σ
其中,
Rp=平均投资组合收益
Rf= 无风险利率
σ=投资组合的标准差
假设你预期你的投资组合年化回报率为 12%。如果无风险利率是 7%,你的投资组合有 8%的标准差。您投资组合的夏普比率计算如下:
夏普比率= (12% - 7%)/ 8% = 0.625
定量分析师和技术分析师的组合以及他们在一起的好处
当一个定量分析师和一个技术分析师一起工作时,就会产生一个成功的算法交易团队。让我们看看如何。
技术分析师利用技术指标来预测市场情况,看市场是更有可能看跌还是看涨。在这些结果的帮助下,定量分析师可以利用统计工具来获得预期收益、风险、夏普比率等结果。
然后,结合两者,即基于历史市场表现和统计数字的市场预测,可以创建一个交易策略。
定量分析师和技术分析师一起工作的好处如下:
- 任务的专业化使工作更有效率
- 两者的结合有助于评估长期投资,因为一个根据历史表现预测市场情况,另一个进行统计测试以量化策略的表现
- 两者结合在一起可以帮助交易者意识到交易决策的潜在优势和风险
- 该策略被验证两次。一个借助于技术指标,另一个借助于统计工具
- 结合技术和数量分析会带来更多有利的交易
如何区分 Quants 和技术分析师的学历要求?
要成为一名定量分析师,你需要精通多门学科,比如金融、统计、数学、计算机科学等。
现在,既然一个定量分析师实际上需要在一个更广泛的框架中,那么他需要精通数学和统计学以及金融。
但是,要成为一名技术分析师,你主要需要拥有金融方面的教育资格,因为这个职位要求你研究历史市场数据或表现。根据历史市场数据,技术分析师预测市场未来的表现。
我们整理了一些最受欢迎的由专家撰写的关于技术分析的博客。
结论
我们在这篇博客中讨论了定量分析师和技术分析师,以及他们如何专注于自己的角色和职责。定量分析师和技术分析师在同一个算法交易领域工作。虽然他们在各自的岗位上表现出色,但结合起来,他们会在算法交易中取得成功。
如果你想学习如何将技术指标用于一种被称为摇摆交易的交易策略,你可以选择摇摆交易的这门课程。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
Dijkstra 算法
马里奥·比萨
开始学习寻找最短路径的 Dijkstra 算法。我们简要回顾了 Kruskal 算法、Prim 算法、Johnson 算法和 Bellman 算法。我们将涵盖:
- 什么是 Dijkstra 算法?
- Dijkstra 算法是如何工作的?
- Dijkstra 算法的伪代码
- Dijkstra 算法表
- Dijkstra 算法时间复杂度
- 什么时候使用 Dijkstra 算法?
- 迪杰斯特拉算法 vs 克鲁斯卡尔算法
- Dijkstra 算法 vs Prim 算法
- 普里姆算法 vs 克鲁斯卡尔算法
- 如何使用 Dijkstra 算法寻找最短路径?
- 为什么 Dijkstra 算法对于负权重会失败?
什么是 Dijkstra 算法?
Edsger W. Dijkstra (1930-2002) 是一位杰出的物理学家,他在分布式和并发计算以及其他数学领域取得了巨大的进步。
以他的名字命名的算法寻找最优解以获得图或网中的最短路径,尽管我们将在下面看到对算法的改进以提高效率。
Dijkstra 算法属于所谓的贪婪算法家族,因为它仅考虑当前时刻做出决策,而不考虑该决策可能如何影响未来,即,它在给定时刻做出最佳决策,而不考虑未来后果。
贪婪算法通常用于解决优化问题,例如选择最短路径或在计算机上执行任务的最佳顺序。
在这种情况下,贪婪算法在给定时刻选择最有希望的部分或任务,而不会在以后重新考虑这是否是最佳决策。因此,这是一个简单的算法实现,因为没有必要控制替代方案,也没有后续撤销以前的决定。
诸如 Dijkstra 算法、Kruskal 算法或 Prim 算法之类的贪婪算法的特征在于以下一般属性:
- 算法要求以最优的方式解决问题,在构建解决方案时,我们有一组或一列候选方案,如图的边、要计划的任务等。
- 随着算法的进行,两个集合被累积,一个包含已经被评估和选择的候选,另一个包含已经被评估但是被拒绝的候选。
- 有一个功能可以检查一组候选项是否形成了问题的解决方案,暂时忽略这是否是最佳解决方案。
- 还有第二个功能,测试给定的一组候选项是否可行,即是否有可能与其他候选项达成解决方案,以获得最终解决方案。同样,我们暂时忽略了解决方案是否是最优的。
- 还有第三个函数,用于选择既未被选中也未被拒绝的候选项,该候选项是在给定时间点最有希望的解决方案候选项。
- 最后,还有第四个函数叫做 objective,它返回我们已经找到的解,尽管严格来说它不是贪婪算法的一部分。
为了解决这个问题,我们寻找(第一)构成解的候选集,以及(第二)优化目标函数值的候选集。贪婪算法一步一步地进行。
最初,所选候选项的集合是空的,并且在每一步,最佳候选项被认为是通过选择函数添加到该集合中的。
- 如果所选候选的新扩展集对于一个解决方案是不可行的,无论最优与否,则该候选被拒绝。
- 如果候选的扩展集合仍然形成可能的解,无论最优与否,新的候选被添加到选择的候选集合中。
就这样,我们一步一步地继续前进,直到找到一个一定是最优的解决方案。
正如我们已经说过的,这些特征是贪婪算法所共有的,尽管我们将在后面看到,Dijkstra、Kruskal 和 Prim 贪婪算法具有独特的特征。
Dijkstra 算法是如何工作的?
Dijkstra 算法解决了给定图形的最小路径问题。
给定一个有向图 G = {N,E} 其中 N 是 G 的节点集,E 是有向边集,每条边都有非负的长度,我们也可以讨论重量或成本,其中一个节点作为原点节点。
问题是确定从原点到其他每个节点的最短路径的长度。
正如我们在贪婪算法的一般特征中所看到的,Dijkstra 算法使用两组节点 S 和 c。组 S 保存所选节点的集合以及在给定时间每个节点到原始节点的距离。集合 C 包含所有未被选择且距离未知的候选节点。
由此我们推导出一个不变性质 N = S U C 。
也就是说,节点集等于所选节点集和未选节点集的并集。
在算法的第一步中,集合 S 只有节点原点,当算法完成时,它包含所有图节点以及每条边的成本。
如果从原点到特殊节点的路径中涉及的所有节点都在所选节点的集合 s 内,则我们称之为特殊节点。Dijkstra 算法维护一个矩阵 D,该矩阵在每一步都用集合 s 中每个节点的最短特殊路径的长度或权重进行更新
当试图将一个新的“v”节点添加到 S 时,到“v”的最短特殊路径也是到所有其他节点的最短路径(参见参考书中的演示)。当算法完成时,所有的节点都在 S 中,矩阵 D 包含了从原点到图中任何其他节点的所有特殊路径,从而解决了我们的最小路径问题。
在查看 Python 实现之前,让我们先看看 Dijkstra 算法在伪代码中是如何工作的。
Dijkstra 算法的伪代码
Dijkstra 算法的伪代码是:
直接市场准入(DMA):简介、交易平台、经纪人等等
由查尼卡·塔卡和何塞·卡洛斯·冈萨雷斯·田中
直接市场准入是交易领域的一个有趣的部分,它在 20 世纪 80 年代开始被散户交易者使用,但在 20 世纪 90 年代逐渐在机构交易者中流行起来。投资银行、对冲基金等。主要在今天使用直接市场准入。
让我们通过这篇博客了解更多关于直接市场准入的信息,内容包括:
什么是直接市场准入?
直接市场访问 (DMA)是对金融市场交易所指令簿的直接访问,导致证券的日常交易。通常是投资银行(花旗集团、摩根大通)、对冲基金等公司。直接进入市场。
直接市场准入的运作
让我们假设一个交易者或公司想通过直接市场交易股票。首先,将需要一个平台,通过经纪人利用直接进入市场的设施。
之后,交易者会下订单,经纪人会做一个快速检查,找出在市场上开仓的保证金。在必要的检查之后,交易者将能够看到其他市场参与者的订单,并判断下达交易订单的市场情况。

Working of direct market access
直接市场准入交易平台
交易平台由经纪人提供,帮助交易者直接与交易所执行交易指令,无需任何中介。这些直接进入的经纪人必须为您提供一个高度专业化的交易平台,具有一些功能,例如:
- 可以用 Python、C 等语言编程的路由模块。
- 算法交易能力
- 用于进行技术分析、基本分析等分析的可编程扫描仪。
- 一个一次性进行大量交易的软件(在尽可能短的时间内)
下面您可以看到一些通过交易平台提供直接市场准入服务的经纪人:
| 经纪人 | 网站链接 | 量滴存款 | 交易平台 | 基础年 | 公开交易 |
| FP 市场 | 点击这里 | $100 | MT4、MT5、IRESS、WebTrader | Two thousand and five | 不 |
| 瑞士报价 | 点击这里 | $1000 | MT4、MT5、高级交易员 | One thousand nine hundred and ninety-six | 是 |
| 前沿(武器)系统 | 点击这里 | $1 | MT4、MT5,专有 | Two thousand and nine | 不 |
| VantageFX | 点击这里 | $200 | MT4,MT5,网上交易 | Two thousand and nine | 不 |
| 铁皮人 | 点击这里 | $100 | MT4 | Two thousand and ten | 不 |
| FXTM | 点击这里 | $10 | MT4, MT5 | Two thousand and eleven | 不 |
直接市场准入的成本
为了获得直接进入市场的好处,交易者要为上表中提到的每个经纪人支付最低保证金。因此,直接进入市场的所有者只需要支付执行费就可以将交易指令发送到市场。
直接市场准入与零售交易
说到直接进入市场和零售交易的区别,主要的区别是零售交易者通过中间人来执行他们的订单。然而,直接市场准入允许交易者直接与交易所执行交易指令。
让我们看看直接市场准入和零售交易之间的更多区别:
| 直接市场准入 | 非直接市场准入 |
| 直接进入市场是由经纪人提供的 | 在某些零售交易中,不提供直接进入市场的途径,而是由经纪人充当中介 |
| 下交易订单是一个快速的过程,因为交易者可以直接在交易所执行交易 | 交易指令的执行速度取决于经纪人的技术 |
| 支付执行费是为了将交易指令发送到市场 | 根据回报支付佣金 |
| 直接市场准入可以利用 ATS (替代交易系统)订单类型,这些订单类型向直接市场准入的所有者支付回扣,以向市场提供流动性 | 不支付回扣 |
超低延迟直接市场访问
直接市场访问的主要优势之一是,与一些经纪人拥有的路由器层相比,它提供了低延迟。一些技术供应商试图优化这一功能,将他们的服务称为超低延迟直接市场访问,这意味着与仅低延迟(LL)相比,他们在延迟方面有所改善。
低延迟和超低延迟直接市场访问有什么区别?
一旦你读了上面这段话,你可能会问自己这个问题。我们可以告诉你的是,业界对这两者没有明确的区分。
让我们给你解释一下为什么会这样。ULLDMA 是关于处理高资产量,只有 500 微秒的延迟,超过这个数字可以理解为 LLDMA。即使这个数字可以给你一个思路,也不要混淆!
如果你在 80 年代交易,ULL DMA 可能意味着一个更大的数字,可能是毫秒,现在 500 可能是区分两者的一个很好的代理数字,但在未来,随着技术的进步,你可以预期这个数字会减少到零!
什么样的交易者最能利用这种服务?
低频交易者投资的频率大于一分钟。高频交易者的交易频率不到一分钟。我们必须说,ULLDMA 服务在基础设施方面可能非常昂贵。
这也是因为如此高频率的交易只有在交易量非常大的情况下才能盈利。所以你可能会猜测,从成本效益的角度来看,高频交易者是可能从这种超低延迟中获利的人。
卖方如何提供 ULL DMA?
由于交易指令是以数字方式执行的,它们以光速从卖方传送到证券交易所。如果供应商的系统和证券交易所之间的距离更近,这一速度可能会有所提高。
您可能在寻找一些问题的答案,例如:
他们如何缩短这一距离?
他们与交易所的距离应该有多近?
嗯,这两个问题可以简单地回答:协同定位是一种实践,这意味着供应商在存放交易所计算机服务器的同一场所创建其基础架构。这样,它们就保证了信息传播速度方面的最近距离和最高效率。
外汇直接市场准入
在我们谈论外汇直接市场准入之前,让我们向您解释一下外汇间接市场准入。
没有外汇直接市场准入,外汇订单如何运作?
散户投资者进入外汇市场的常见服务是由所谓的经纪人交易台提供的。经纪人的交易台负责优化散户交易者的订单到达机构银行的最佳路径。
操作是这样的:经纪人接收银行机构的出价并要求报价,然后他们汇总报价为散户交易者“做市”。因此,交易台为散户交易者创建买入和卖出报价,这样,这些经纪人就允许市场的流动性和有效性。
此外,经纪人充当散户交易者的交易对手也很常见。当散户买入时,经纪人扮演卖家的角色,当散户卖出时,经纪人扮演买家的角色,即使投资者利用了杠杆。这类经纪人也被称为“做市”(MM)经纪人。
然而,由于越来越多的人在金融市场交易,越来越多的技术进步正在到来,越来越多的经纪人现在向散户交易者提供外汇直接市场准入。
外汇直接市场准入的运作
让我们了解外汇直接市场访问和股票直接市场访问的工作原理,在股票直接市场访问中,您可以在没有“智能路由器”的情况下从多个交易所访问订单簿。这款智能路由器可能会为您的特斯拉股票购买订单优化最佳路线。
在 forex direct market access 中,您可以访问相同银行机构的报价,而无需我们上面谈到的交易台的干预。因此,举例来说,每当你买入或卖出欧元美元时,你的订单会由经纪商直接发送到银行间市场执行。
那么交易会立即完成。为交易者直接进入市场的经纪人也称为无交易台经纪人(NDD 经纪人)。
所以你可能想知道:
与普通经纪人相比,我如何看待无交易台经纪人的买卖报价?
你能猜到吗? 很简单!
- 对于一个普通的经纪人,你只会看到一个买价和一个卖价,因为,正如我们前面讨论过的,经纪人的价格是其交易台提供的来自不同银行机构的“集合”。
- 在非交易台经纪人的情况下,你会看到来自这些银行机构的几个出价和要价,所以在这种情况下,你可以根据你的需要选择大量的出价和要价!
你能与直接市场准入经纪人交易外汇 CFD 衍生品吗?
差价合约(CFD)是一种使投资者能够按照货币对的方向进行交易,而不是按照现货报价进行交易的合约。一些外汇直接市场准入经纪人可以让你直接与银行机构交易这种类型的衍生品。
我们应该补充一点,通常情况下,最好的差价合约经纪商在行业内拥有最好的声誉,并且倾向于拥有专业或机构客户。所以,每当你对你的交易经验有疑问或问题时,所有这些经纪人都有正确的知识来帮助你,以防你需要它。
此外,我们可以说,如果你是一个交易量很大的交易员,那么你可能需要与提供差价合约的直接市场准入经纪商合作,这样你的大单就不会影响市场。这在大市场交易时很重要,就像在流动性差的市场一样。
佣金率呢?
一些做市商在交易外汇时只对每笔交易收取佣金,而其他人则按相同的差价收取费用。
但是,通常情况下,直接市场准入外汇经纪商会对买卖价差收取少量加价,并且不会对订单收取任何其他佣金。
直接市场准入的优势
以下是直接市场准入(DMA)的优势:
- 所有价格馈送都是可见的,并提供透明度,允许您评估出价和出价量
- 与经纪人设定报价的做市商模式不同,DMA 模式是订单驱动的,这使您成为价格制定者,而不是价格接受者
- 订单执行速度更快
- 经纪人不访问订单流,因此,没有重新报价,因此,DMA 意味着更快地执行交易订单
- 经纪人不作为你交易的对手,所以他们不会产生委托代理问题
- 收取小额差价加价
直接市场准入的缺点
直接市场准入的缺点可以列举如下:
- DMA 帮助您访问交易所中的订单簿,这意味着您只能交易有中央证券交易所的工具
- 除非你是一个有经验的交易者,否则很少有经纪人会为零售交易提供 DMA
- 如果用户不经常交易或者长时间不活动,经纪人费用可能会很高
- 价格并不总是比非 DMA 经纪人好
结论
在这篇博客中,我们讨论了交易领域中最相关的直接进入市场的概念。直接市场准入机制允许交易商/机构在金融市场进行交易,无需任何中介。
直接市场准入是一种更快的方法,使直接市场准入的所有者直接控制进出头寸。我们还讨论了不同类型的直接市场准入及其弊端。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就去看看吧!
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
基于股票相关性和指数波动性的分散策略[EPAT 项目]
原文:https://blog.quantinsti.com/dispersion-strategy-correlation-stocks-volatility-index/

尼廷·阿格沃尔和 T2·贾斯比尔·辛格
本文是贾斯比尔·辛格提交并由尼廷·阿加瓦尔指导的期末项目,是 QuantInsti 算法交易(EPAT) 高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
简介
本文基于股票相关性、指数波动性,使用分散策略检验交易利润。分散有助于交易者只考虑波动性(假设相关性均值回复),因此,确保通过购买或出售期货来对冲 delta 风险。在这种策略中,多头和空头都是建立在波动性的基础上的,现在有了更多的策略,最好使用利用相对价值而不是绝对价值的策略。这限制了风险资金的单向流动。
具体来说,当相关性很高时,分散交易利用指数期权相对于单个期权的过高定价。根据单个股票之间的相关值,可以通过卖出指数期权和买入指数成分期权或买入指数期权和卖出指数成分期权来交易离差。
最近几年,关于为什么离差交易有利可图,有很多假设。最广为接受的理论是市场无效理论,该理论认为期权市场的供给和需求驱动了偏离其理论价值的溢价。在 1996 年至 2005 年的研究中,这一点在 2000 年后离差交易不再盈利时得到了证明。
战略
为了区分分散交易,它只是一种对冲策略,利用指数和指数成份股之间隐含波动率的相对价值差异。它涉及一个指数的空头期权头寸和一个指数成分的多头期权头寸,反之亦然。在指数上建立空头头寸或接近资金扼杀的头寸,在构成该指数的 50-60 %的股票上建立多头头寸或资金扼杀的头寸。空头头寸减轻了多头带来的风险。此外,在资金多空和资金紧缩的情况下,delta 敞口接近于零。因此,分散策略针对较大的市场波动进行对冲,并构成较低的方向性风险。
对于指数 其中 W i 是指数中股票‘I’的权重。使用
其中 W i 是指数中股票‘I’的权重。使用 可以计算出指数的方差,其中σIT6】2 为指数方差,w i 为股票在指数中的权重。σ i 2 为个股方差,ρ ij 为股票 I 与股票 j 的相关性。
可以计算出指数的方差,其中σIT6】2 为指数方差,w i 为股票在指数中的权重。σ i 2 为个股方差,ρ ij 为股票 I 与股票 j 的相关性。
离差交易的利润来自于这样一个事实,即相关性均值回归,如果一个人购买了相关性,那么一只股票的已实现波动率将高于指数的已实现波动率。德里森认为,只有负相关风险溢价才有可能在分散策略中获利。但这可以通过指数期权相对于单个股票期权的过高定价来实现。因此,卖出指数期权,买入其成分的期权,并用期货合约进一步对冲,以始终保持 delta 中性,这也是一项有利可图的交易。
在整个交易过程中,买入或卖出的期权数量不变,期货头寸根据期权的 delta,通过买入或卖出期货合约进行调整。
对冲期权的利润可以通过以下方式计算:
P ≈ θ. (n<sup>2</sup>-1) + NV-dσ/σ
其中θ =时间-衰减,单位为美元;n =标准化移动;N=归一化织女星
数据
分散交易策略的重点是印度银行 Nifty 指数期权及其成份股银行股。我们将 15 分钟的数据用于这一策略。
实施战略
项目期间采取的步骤如下:
隐含波动率计算
为了实施这一策略,首先计算指数银行 Nifty 和银行 Nifty 股票的隐含波动率是很重要的。期权价格反映了一种工具的风险,无论是股票还是指数。期权价格传递的风险水平通常被称为隐含波动率。单一股票期权的隐含波动率只是反映了市场对该股票价格回报未来波动率的预期。然而,指数波动是由两个因素共同驱动的,即指数成分的单个 vol 和指数成分价格回报的相关性。通过计算隐含波动率,我们试图找出股票之间的相关性是高还是低。我们使用布莱克-斯科尔斯模型来计算 IV。我们需要时间来成熟,执行价格,无风险利率和当前的基础价格。由于我们使用的是当月期权,从当前价格我们确定了期权 ATM 罢工,我们有无风险利率。
隐含相关性计算
我们用隐含波动率来计算股票之间的隐含相关性。波动性之间的相关性是买入或卖出的标志。如果隐含相关性高,则有卖出指数期权和买入股票期权的迹象,反之亦然。
选择选项
对于这种策略,我们结合使用了看跌期权和看涨期权。当使用这种方法时,对冲期权是很重要的,这可以通过向银行 Nifty 指数和银行 Nifty 股票投资等量的资金来实现,以实现完美的对冲交易。时间衰减:交易在月初使用月度期权进行,并维持到到期。保持交易直到到期有助于获得卖出期权的时间衰减的好处。
对冲
这是进一步对冲使用期货合同,以保持整个过程 delta 中性。该策略的 Delta 每 15 分钟调整一次,当 delta 超过 1 时,卖出一份期货合约,当 delta 下降到-1 时,买入一份期货合约来抵消 delta。在交易过程中保持 delta 接近于零是很重要的。
损益计算
该策略的 PNL 来自两个因素,一个来自期权,另一个来自期货合约。增加期货合约以在到期时保持 delta 中性,所有头寸被平仓并计算最终利润。
结论
分散交易是一种非常有利可图的策略,它在低风险的情况下提供高回报,但正确地实施该策略以获得利润是至关重要的。如果策略是自动化的,套期保值是自动计算和执行的,那么使用这种策略会更容易。利用自动化系统,可以更容易地实现跟踪策略的自动化系统,套期保值计算可以根据期权价格的变化进行调整。
阅读我们的下一篇文章,它描述了开发一个完全基于云的自动交易系统,该系统将利用均值回复或趋势跟踪执行算法。本文是作者提交的最后一个项目,作为他们在 QuantInsti算法交易(EPAT) 高管课程的一部分。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。 本项目提供的所有内容仅供参考,我们不保证通过使用这些指导您将获得一定的利润。
NSE 股票的分散交易[EPAT 项目]
原文:https://blog.quantinsti.com/dispersion-trading-on-nse-stocks/

作者:普内特·金拉
什么是色散?
在离差或相关交易中,交易者关注波动性。波动性意味着回归,因此离差或相关性也意味着回归。
多头和空头都是基于波动性。为了应对方向性风险,通过买入或卖出期货来抵消头寸。所以方向性风险是有限的。
离差通过卖出指数期权和买入股票期权或买入指数期权和卖出股票期权进行交易。
分散策略详情
离差交易是一种对冲策略,利用指数和指数成分之间隐含波动率的相对价值差异。
跨股和扼制组合是通过在指数上建立空头期权头寸和在指数成分上建立多头期权头寸来实现的,反之亦然。
通过保持单个股票/指数期权投资组合的 delta 接近于零,每个股票和指数期权投资组合的方向风险得以保存。

- 离差交易的利润来自于这样一个事实,即相关性均值回归,如果一个人购买了相关性,那么一只股票的已实现波动率将高于指数的已实现波动率。
- 指数期权投资组合和每一个股票期权投资组合都是持续的 delta 中性,直到头寸被平仓。这里初始期权头寸不变,但我们在整个分散交易中买入或做空不同数量的期权指数或股票。
数据和时间框架
分散交易策略的重点是印度银行 Nifty 指数期权及其成份股银行股。我们将 15 分钟的数据用于这一策略。我们也可以使用 30 分钟的数据。这一切都取决于,哪个时间框架是最好的结果。
战略实践指南
项目期间采取的步骤如下:
隐含波动率计算
为了实施这一策略,首先计算指数银行 Nifty 和银行 Nifty 中股票的隐含波动率是很重要的。
我们使用布莱克-斯科尔斯模型来计算 IV。我们需要时间来成熟,执行价格,无风险利率,和当前的基础价格
举例:
成份股之一的银行 Nifty 和 SBIN 股票的隐含波动率计算。

隐含/脏相关计算
我们用隐含波动率来计算股票之间的隐含相关性。我们用指数 IV 除以加权平均股票 IV 来检查 IC 水平。如果隐含相关性高,则有卖出指数期权和买入股票期权的迹象,反之亦然。
举例:
银行 NIFTY 的隐含相关性计算

选项选择
我们结合运用了看跌期权和看涨期权的跨式和扼杀式策略。空头是指同一次买入和卖出的自动柜员机。扼杀意味着 OTM 打电话和放。最初的对冲是通过购买或出售相对股票期货来保持 delta 接近于零。
连续 Delta 中性/动态对冲
这是进一步对冲使用期货合同,以保持整个过程 delta 中性。这个策略的 Delta 每十五分钟调整一次。当 delta 超过 1 时,卖出一份期货合约,当 delta 下降到-1 时,买入一份期货合约来抵消 delta。在交易过程中保持 delta 接近于零是很重要的。
举例:
AXISBANK 股票的连续 delta 对冲

止损并退出
除了进场和持续的 Delta 中性,当交易对我们有利时和交易对我们不利时,也有必要制定一个退出分散交易的计划。这种风险管理可以防止意外损失或放弃已获得的利润。
损益计算
该策略的 PNL 来自两个因素,一个来自期权,另一个来自期货合约。增加期货合约以保持 delta 中性。到期时,结清所有头寸,并计算最终利润。
举例:
P&L 从个股(YESBANK)和总 P&L 的分散交易策略。

分散应用
分散交易是一种非常有利可图的低风险对冲策略,回报远远大于风险。如果这个策略在回溯测试后自动交易,那么可以产生更有效的结果。这种策略可用于任何交易指数,其中指数期货被交易且指数成分期权具有足够的流动性进行交易。在印度或全球市场,有许多指数适用于相关性/离差交易。
下一步
分散交易是一种非常有利可图的策略,它在低风险的情况下提供高回报,但正确地实施该策略以获得利润是至关重要的。我们的下一篇文章展示了一个基于离差交易的项目。这个项目是 QuantInsti 算法交易培训项目提供的 EPAT 课程的一部分。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。 本项目提供的所有内容仅供参考,我们不保证通过使用这些指导您将获得一定的利润。
下载中的文件:
- NSE 股票的分散交易- Excel 表格
印度市场的分散交易策略
原文:https://blog.quantinsti.com/dispersion-trading-strategy-indian-markets-project-karthik-kaushal/
这个项目证明了统计套利交易中的机会。这种策略是建立在这样一种理念上的,即在指数及其成份股的波动性中存在一些可重复的模式。
我们对隐含波动率和一篮子股票的隐含波动率之间的价差进行建模,这些股票按其在指数中的实际权重进行加权。我们选择 BANKNIFTY 作为指数及其成份股来回测这种策略,也称为分散交易。
最后,我们证明了该策略的损益是正的。回溯测试基于一个月的日内数据,可以扩展到更长的时间。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Karthik Kaushal 是一名期权交易员,有 3 年的工作经验。他的职业生涯始于 EY 的一名数据工程师。后来,他追随自己的热情,从专业领域转向了金融市场。
这让他在孟买的一个自营交易部门获得了一份小工作,主要从事印度市场的期权交易。目前,他在 True beacon 的期权交易部门工作。他的职责包括在基于系统性波动的策略上部署大量机构资本。
除了传统市场,他还在自己的书中交易加密期权。他拥有迈索尔国家工程学院的电气和电子工程学士学位。
战略思想
我们以合适的日内频率计算指数及其成份股的波动率。
一旦我们有了每个股票成分和指数的波动性,我们将计算指数的波动性与成份股的加权(解释指数现货价格的权重)平均值之间的相关性。
现在,根据相关性,当相关性超过一个预定的阈值时,我们将采取立场。当它交叉时,我们进入一个买/卖第一 OTM 扼杀和跨在指数中,并采取指数成份股的反立场。只要我们在这个位置,我们就在选择的频率上对冲 delta。
在相关性回到退出阈值后,我们将退出所有头寸。当我们回测系统时,进入和退出阈值被确定/优化。
资料组
目前,作为 EPAT 项目的一部分,我们提供了指数和股票的期权和期货的 30 分钟内数据。我们必须进行预处理,并基于此计算 IV 和相关性。
动机
离差交易是基于高度量化的严格性和有前途的理论的策略。我确实浏览了一些学术论文,在这些论文中,该策略被应用于世界各地的多个市场,这表明了该策略在认真执行时的稳健性。
项目大纲
我对 BANKNIFTY 及其成份股的离差交易策略进行了回溯测试。
我在 2017 年 1 月以 15 分钟的频率进行了为期 1 个月的回溯测试。BANKNIFTY 指数主要有 AXISBANK、HDFCBANK、ICICIBANK、INDUSINDBANK、KOTAKBANK、SBIN 和 YESBANK,其他几只股票的权重可以忽略不计。
以下是股票在指数中的权重。
| 轴心银行 | 9.6% |
| hdfc 银行 | 30.1% |
| icici 银行 | 19% |
| 科塔银行 | 11.23% |
| SBIN | 9.82% |
| 工业银行 | 7.62% |
| YESBANK | 5.59% |
战略思想
我们使用第一个 OTM 执行价格合约计算股票和指数的平均隐含波动率,公式如下。
平均 IV = {(看跌期权的 IV *股价与第一次 OTM 看涨期权的执行价格的距离)+((看涨期权的 IV *股价与第一次 OTM 看跌期权的执行价格的距离)}/(两次执行之间的距离)。
然后我们通过股票在指数中的权重计算股票平均 IV 的加权平均值,并计算股票的 banknify/加权平均 IV 的比率- IV。
该比率也称为脏关联,每 15 分钟计算一次。在此基础上,我们计算出回望期为 30 的移动 Z 分数。
如果 Z 值大于 1,我们预计 BANKNIFTY IV 会下跌,或者股票的加权平均 IV 会上涨,因此,我们首先做空 banknify 的 OTM 扼杀,然后买入所有股票的 OTM 扼杀。相反,Z 值小于-1。
在我们按照上面的规则进场后,每隔 15 分钟我们对冲 delta——我们计算我们所有头寸的 delta 并使其接近零。
这可以通过计算我们投资组合中每只股票和指数的 delta 来完成,如果每只股票的单位数量 delta 大于 0.1 或小于-0.1,我们可以通过在期货中建仓来进行适当的对冲。
如果 Z 值达到小于 0.8 的数量级,我们对所有位置进行平方,并计算 PnL。
位置尺寸
后验测试考虑了 4 手 BANKNIFTY——4 手 PE 和 4 手 CE,关于这一点,成分股票的风险敞口是根据其在 bank nifty 上的各自权重计算的。
这种安排所需的保证金约为 150-200 万卢比(无杠杆),包括对冲和 MTM 处理的保证金。
例如,如果 Z>1,BANKNIFTY 当前价格为 18050。以下是回溯测试代码记录的交易(忽略数量中的小数,因为它可以四舍五入为整数)。

举例来说,对于 ce,AXISBANK 数量约为 380,因为 AXISBANK 的权重约为 9.6%。因此,合同价值为 380*460 = 174,800,是 100 数量 BANKNIFTY 18100 CE 价值的 9.6%(100 * 18100 = 1810000)。
回溯测试结果
Number of trades: 56
Total PnL: Rs. 7256

以上结果只是一个月的时间,所以周期太小,无法下结论。目的只是为了展示这种策略的潜力。
改进和建议
- 我们可以用不同的频率来测试这个策略。
- 我们可以优化对冲阈值及其频率。
- 对于我们测试策略的每个频率,我们可以优化/改变进入和退出的 z 分数阈值。
- 当然,后验期应该大大延长。
下面的 Python 代码中提供了完整的 Python 代码和相关信息。可以下载参考一下。
如果你想学习算法交易的各个方面,那就去看看这个算法交易课程,它涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。立即注册!
文件在下载
- 项目的完整 Python 代码
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
使用期权的分散交易[EPAT 项目]
原文:https://blog.quantinsti.com/dispersion-trading-using-options/
作者:杰耶什·库鲁普
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易(EPAT)高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
简介
离差交易是一种利用隐含相关性和随后实现的相关性之间的差异的策略。离差交易利用了指数期权之间隐含波动率和实际波动率之间的差异大于单个股票期权之间的差异这一事实。因此,交易者可以基于这种波动性差异卖出指数上的期权并买入单个股票期权,反之亦然。分散交易是一种相关性交易,因为在个股相关性不强的时候,交易通常是盈利的,而在相关性上升的压力时期,这种策略会亏损。证券之间的相关性被用作确定交易进入的因素。根据单个股票之间的相关值,离差可以通过卖出指数期权和买入指数成分期权或买入指数期权和卖出指数成分期权进行交易。对于这种策略的盈利能力,最广为接受的理论是市场无效率,该理论认为期权市场的供给和需求驱动溢价偏离其理论价值。
策略
为了区分分散交易,它只是一种对冲策略,利用指数和指数成份股之间隐含波动率的相对价值差异。它涉及指数证券的空头期权头寸和指数成分的多头期权头寸,反之亦然。实际上,我们将根据进场信号做多/做空。我们必须注意,只有当 delta 敞口接近于零时,这种交易才会成功。因此,分散策略是针对大的市场波动。下面是成功的分散交易需要采取的一系列行动。
- 计算脏相关(ρ)
- 当脏相关超过阈值/达到极限时生成信号
- 根据逻辑买卖指数和个别证券
- 定期计算 delta,并通过购买/出售期货来抵消它,使交易 Delta 保持中性
- 当脏相关性超过平均值(ρ=0.5)时退出
为了理解波动性的差异是如何被捕捉的,我们需要理解一篮子股票的指数方差。它被给出为:

其中,σ I 2 是指数方差 wi 是股票在指数中的权重σIT6】2 是个股方差ρij 是股票 I 与股票 j 的相关性这一策略的好处在于相关性趋向于均值回复。因此,如果一个人在比率的极端情况下建仓,我们可以确信这将意味着在某一点的回复。
实施战略
要实施该策略,我们需要计算下面给出的指标。
计算最接近的隐含波动率
因为我们有溢价值,到期时间,利率,股息和最近的罢工,我们可以使用布莱克斯科尔斯模型计算最近罢工的隐含波动率。为了计算相关性,需要将单个证券和指数的最接近的加权平均隐含波动率相加。
在上面的函数 CalculateIV 中,我们可以看到,首先计算单个买入和卖出 IV,然后计算这些 IV 的加权平均值。权重更多地给予那些更接近未来价格的罢工。
脏关联
这是指数隐含波动率与股票加权平均值之比的平方。公式如下所示:


上面的代码片段显示了脏关联的计算。在这里,首先计算单个证券的交易量,然后在 Vol_IndSecurities 中求和。该比率是在指数和个股之间计算的,并且是平方。
定义阈值
这是根据风险偏好产生进/出信号的重要一步。在这个项目中,阈值是 z1=0.2,z2=0.8,z3=0.5,其中 z1 给出买入指数和做空单个证券的信号,z2 给出做空指数和做多单个证券的信号,z3 是所有头寸平仓的退出阈值
选择要交易的期权
一旦我们得到买入/卖出的信号,我们将会同时使用空头和空头。本项目考虑了最近的 3 个 OTM 走向。投资金额需要在指数和单个证券之间平均分配。录入时,需要记下批量、购买数量,以便每个阶段的增量便于使用。
对冲
这是进一步对冲使用期货合同,以保持整个过程 delta 中性。这个策略的 Delta 应该每十五分钟调整一次。当 delta 超过 1 时,卖出一份期货合同,当 delta 下降到-1 时,买入一份期货合同来抵消 delta。在交易过程中保持 delta 接近于零是很重要的。
上面的片段显示了如何根据进/出信号进行持仓。每当我们有进场信号时,我们就持续监控 delta,确保它是中性的。同样,总的 deltas 最初被加起来,然后用买入或卖出的期货合约来抵消。当前持仓的期货也便于计算每个点的 delta。买入或卖出的期货总额被确定,并乘以期货价格,以计算交易的额外投资。
损益计算
为了计算 PnL,需要考虑以下因素:
- 初始交易,进场时买入/卖出期权的成本
- 对冲成本,为使交易 delta 中性而投资的期货总量
- 期货结算,在退出信号时结算期货合约的金额
- 期权平仓,当所有头寸在退出信号时平仓的结果
 上面的片段展示了 PnL 的计算。这里我们可以看到,我们已经计算了初始交易的买入成本(买入/卖出看涨期权和看跌期权)。我们已经计算了看涨期权和看跌期权的平方价格。额外的投资或买卖的期货用 FutSet 表示,在交易结束时结算。对冲金额存储在对冲变量中。
上面的片段展示了 PnL 的计算。这里我们可以看到,我们已经计算了初始交易的买入成本(买入/卖出看涨期权和看跌期权)。我们已经计算了看涨期权和看跌期权的平方价格。额外的投资或买卖的期货用 FutSet 表示,在交易结束时结算。对冲金额存储在对冲变量中。  以上是执行的代码示例。可以看出,由于脚本中包含复杂的计算,执行需要相当长的时间。
以上是执行的代码示例。可以看出,由于脚本中包含复杂的计算,执行需要相当长的时间。
结论
分散交易是一个复杂的策略,然而,这是一个有利可图的策略,在低风险下提供高回报。为了使这种策略更好,有必要使策略自动化,套期保值应该根据价格变动而动态变化。在波动性高的时候交易(即季度业绩、个股新闻等。)当相关性不强时,可能会导致更多的利润。为了最大限度地提高策略的准确性,我们可以缩短捕捉波动的时间间隔,并相应地计算 deltas。了解期权交易中的未平仓合约一个可以在期货和期权交易中轻松使用的指标,未平仓合约表示什么,如何读取未平仓合约数据,并考虑如何使用 Python 建立未平仓合约交易的一些基本假设
为什么背离交易的经验是必须的?
在决定交易时,分歧是最重要的因素之一。但是,作为一个交易者,在做交易决定时,还有其他重要的因素需要考虑。我们将在本文前面非常简要地讨论这些因素。
虽然,有了背离交易的经验,你会理解它的实际作用,这是相当有利可图的。在这里,我们将通过所有重要的方面,如其意义,类型,指标,事实和实际证明其价值的用途。此外,还有一些订单类型可以帮助您根据自己的分析做出最佳决策。我们将讨论一切,从分析股票价格,预测它们,然后使用最相关的订单类型来执行订单。
现在,让我们深入探讨一下本文中涉及的一些基本主题,它们是:
- 交易中的背离:含义和类型
- 背离交易的指标/振荡指标
- 你知道吗?(关于背离交易的有用事实)
- 如何使用规则的和隐藏的发散?
交易中的分歧:意义和类型
交易中的背离意味着资产的实际价格和你所依赖的技术指标之间的不同步。技术指标意在帮助你估算一项资产的价格。如果价格下跌,技术指标上涨,这种不匹配被称为正背离。相反,如果价格上涨,技术指标下跌,这就是所谓的负背离。
准确地说,例如,如果一项资产的价格创出新高,而指标显示较低的低点,这就是背离。
发散的一个例子是下图。它表明市场(实际价格)创下新高,但不是指标。因此,指标显示背离。

来源:维基百科
在做交易决定时研究背离的主要理论是,指标/振荡指标表明实际价格可能很快发生反转。因此,背离有助于估计未来的市场价格,这样你就可以做出正确的交易决定。
但是,另一个重要的观点是,你不能把你的交易决定完全建立在背离的基础上。你还必须考虑其他重要的工具,比如趋势线(支撑位和阻力位)来确认反转。这尤其适用于指标/振荡器长期背离的情况。

来源:维基百科
在上图中,你可以看到支撑趋势线和反转趋势线。
- 支撑趋势线简单地暗示价格水平在一段时间内稳定,资产价格不会跌破该水平。例如,在该图中,在支撑趋势线上不同的时间间隔(年)有不同的价格水平,低于该水平价格不会下跌。
- 阻力趋势线,另一方面,是资产价格水平在一段时间内不会超过的趋势线。例如,在上面的图像中,显示了不同年份的不同价格水平,资产价格不会超过该价格水平。
现在,让我们前进到前方的分歧类型。
背离表明潜在的看涨(价格上涨)市场或潜在的看跌(股价下跌)市场,因此,主要是这两种类型。但是,两者(看涨和看跌)都有进一步的两种类型。
这就是为什么我们将它们分为两大类,即常规(看涨和看跌)和隐藏(看涨和看跌)背离。好了,事不宜迟,让我们来讨论一下。

常规发散有两种类型:
- 常规看涨背离
- 常规看跌背离
常规看涨背离
在常规看涨背离的情况下:
- 该指标显示更高的低点
- 实际市场价格显示更低的低点
常规看跌背离
在常规看跌背离的情况下:
- 指标显示较低的高点
- 实际市场价格显示更高的高点
隐藏的分歧有两种类型:
- 隐藏的看涨背离
- 隐藏的看跌背离
隐藏的看涨背离
在隐藏看涨背离的情况下:
- 指示器显示更低的低点
- 实际市场价格显示更高的低点
隐藏的看跌背离
在常规看跌背离的情况下:
- 指标显示更高的高点
- 实际市场价格显示较低的高点
我们试图通过下面描述趋势变化的图片来使理解变得清晰。有两行,即“价格”和“振荡指标”,每一列都有不同类型的背离,显示振荡指标与价格相反的运动或“振荡指标与价格的背离”。
每个背离都预示着潜在的价格反转。

资料来源:orbex
正如你在上面的图中看到的,一个振荡指标显示了与市场实际价格趋势的背离(反向运动)。这些背离表明趋势可能逆转。
在第一列中,当市场中的实际价格创出更高的高点,但指标创出更低的高点(下降趋势)时,注意到常规看跌背离。
第二列显示常规看涨背离,因为市场中的实际价格形成较低的低点,但指标形成较高的低点(上升趋势)。
第三列显示隐藏的看跌背离,当市场中的实际价格创造了一个较低的高点,但振荡器创造了一个较高的高点(下降趋势)时,就会出现这种背离。
第四列显示了隐藏的看涨背离,当市场中的实际价格出现更高的低点,但振荡器出现更低的低点(上升趋势)时,就会出现这种背离。
由于我们已经讨论了这些类型,我们将在本文的后面了解它们的用法。
现在让我们向前看,找出背离交易的指标/振荡指标。
背离交易的指标/振荡指标
背离交易需要指标/振荡指标来指示资产价格的特定运动。正如我们前面提到的,指标揭示了背离,因此,交易者能够根据指标的分析做出决定。因此,当任何指标显示背离时,实际市场中可能会有价格反转的警告。当实际价格显示一个更高的高点,而指标显示一个更低的高点时,它表明市场正走向一个常规的熊市。相反,如果实际价格显示一个更低的低点,指标显示一个更高的低点,这是一个常规的牛市。我们现在将讨论最受欢迎的指标/振荡指标,它们是:
- 相对强度指数
- 随机振荡器
- 移动平均收敛发散(MACD)
相对强度指数
相对强度指数(RSI)是 J. Welles Wilder (1978)提出的一个著名的背离指标/振荡指标。它帮助交易者获得当前价格相对于不同资产前一天收盘价的相对强度。RSI 也有助于验证市场的进入点和退出点,也像其他指标一样显示潜在的价格反转。另外,默认情况下,RSI 是在14 天的时间段内计算的。
这个指标让你知道什么时候买入资产,什么时候卖出。这通常通过查看 70 和 30 的阈值来完成。你可以在下图中看到 RSI 的工作原理。如果该指标高于 70,这意味着市场已经超买**(这是卖出的好时机),可能会通过下跌来自我修正。另一方面,如果跌破 30,则资产处于超卖(这是买入的好时机),市场可以回撤至超过 30 的更高水平。**

来源:维基百科
此外,据观察, RSI 和另一个振荡器 MACD 一起比单独更有力量。
随机振荡器
另一个非常流行的指标是由乔治·c·莱恩(1950 年)开发的随机振荡器。全世界的交易者都相信这一指标预示着潜在的价格反转。通过评估市场的势头,该指标通过比较收盘价和一段时间内的价格来提供帮助。在牛市中,人们认为价格通常会在高点附近收盘,而在熊市中则会发生相反的情况,因为价格会在低点附近收盘。这一指标基于上述假设。
该指标主要有两个阈值,即 80 和 20。高于上限 80,该指标表明价格超买,是卖出的好时机。反之,低于 20,表明价格超卖,是买入的好时机。
现在,我们将在这里了解一下慢速和快速随机指标的概念。慢速随机指标被称为%D,而快速随机指标被称为%K。在这里,重要的是要注意%D 比%K 更重要。

来源:维基百科
在上图中,您可以看到该指标是用从 0 到 100 的值绘制的。这意味着这个值既不能低于 0,也不能高于 100。另外,%K 显示快速随机线,也就是蓝线,%D 显示慢速随机线,也就是红线。80 以上是超买条件(卖出时机),20 以下是超卖条件(买入时机)。
这里要注意的是%K 线在%D 线之前改变方向。但是,如果慢速随机指标%D 在快速随机指标%K 之前改变方向,就有可能出现价格反转。尽管如此,价格反转将是一个渐进的过程。如果指标达到 0 或 100(极限),则表明出现了强烈的波动。这个指标对于抓住关键的反转点非常有用,因此被用于各种技术设置。
要点提示:当%K 穿过%D 上方时,产生买入信号(看涨),当%K 穿过%D 下方时,产生卖出信号(看跌)。
移动平均收敛发散(MACD)
在这里,重要的是要注意价格变动有助于使用 MACD 时的相关信息。
简而言之,趋同意味着趋势将会继续,而背离表明趋势逆转是可以预期的。
趋同和趋异分析要求你分析一段时间内的价格变化点。简单来说,它需要你关注一段时间内价格的转折点。两个主要观察结果是:
- 价格高点是上涨还是下跌?
- 价格的低点是上升还是下降?
因此,找出这些点的共同点和不同点有助于你成为获利者。在背离中,总是存在增加的波动性,这导致了频繁的盈利机会。
有了 MACD,你就能注意到实例,并通过观察和分析找出有利可图的机会。MACD 能让你理解市场行为,从而更准确地预测未来。在该振荡器的工作中,使用了指数移动平均和简单移动平均 e。让我们看看下图:

来源:维基百科
这张图显示了 MACD 的工作情况。因为经典设置将 EMA 保持为 12 和 26,而 SMA 设置为 9,所以您可以照原样使用它们。或者,您可以根据交易偏好选择任何其他值。
用这个振荡指标,当移动平均线彼此靠近时会发生收敛,反之,当移动平均线远离时会发生发散。此外,当 12 周期均线(较短周期)高于 26 周期均线(较长周期)时,指标高于 0。然而,当较短的 12 周期均线低于较长的 26 周期均线时,它低于 0。这意味着正值表示牛市,负值表示熊市。
现实世界的例子
接下来,你可以从道琼斯的真实例子中得到启示,如何根据我们刚刚讨论的预测振荡指标来推断市场的表现。
2020 年 3 月 25 日在当前冠状病毒爆发的场景中,根据livetradingnews.com,“DJ INDU AVERG 目前比其 200 期移动平均值低 23.3%,处于下降趋势。与过去 10 个周期的平均波动性相比,波动性非常高。波动性很有可能会降低,价格很有可能会在近期稳定下来。我们的交易量指标反映了 DJI 适度的交易量流出(轻度看跌)。我们的趋势预测振荡指标目前看跌 DJI,在过去的 21 个周期里一直如此。我们的动量振荡指标创下了 14 年来的新高,而证券价格却没有。这是一个看涨背离。”
接下来,让我们看看关于背离交易的有趣事实。
你知道吗?(关于背离交易的有用事实)
好吧!现在是时候找出一些有趣和有用的事实与分歧交易。这些事实是这种交易的独特之处,如果遵循这些事实,对你这个交易者来说是非常有益的。我们将逐一讨论它们。那么,你知道吗:
您可以通过特定的订单类型使您的交易更有利可图?
背离交易有一些“订单类型”,每种都有其重要性。总共有四种订单类型,我们将在这里了解一下,在特定情况下,特定的订单类型可能比其他订单类型更有利可图。订单类型包括:
市场订单
这种订单类型是当您进入市场时执行的基本类型,并且不指定相同的价格。但是,这可能对你不利,因为这意味着你将以当前的出价(例如,售价 11 美元)购买股票,即使它高于买入价(例如,买入价 10.50 美元)。
限价单
在这种情况下,为你购买股票设置了一个限价。例如,如果您以 10.50 美元的限价单进入市场,您的订单将不会在报价为 10.50 美元之前执行。
止损单
通过这种方式,你可以设定交易资金的上限。例如,如果你希望在一次交易中只交易 500 美元,那么你可以将你的止损(卖出股票)设置为 40 美分,一旦价格达到 499.40 美元,它就会变成市价单。这将最终限制我们的损失。
停止限价指令
这类似于止损单,但适用于购买股票。例如,如果你希望以 1.10 美元的价格买入股票,不超过 1.10 美元,那么你可以将其设定为你的触发价格。一旦股价达到 1.10 美元,你的限价单就会被触发。
现在,这里的要点是,如果你知道所有这些订单类型,那么在特定的买入或卖出情况下,你将能够从上述选项中选择一个来下单。
例如,限价单比市价单更有利可图。但是,只有在你不在乎速度或时间的情况下,你的首选价格才会被触发。而且,万一你想在某个价位卖出,止损会帮你做到。然而,如果你想在一个特定的价格买入,那么止损更有利于避免损失。因此,无论是帮助你获得更多的利润还是规避损失,了解订单类型是必不可少的。
连接正确的点是最重要的?
你必须重视这样一个事实,即在描绘实际价格的高点和低点的图表上连接正确的点是至关重要的。这里有四种情况–前高点、当前高点、前低点和当前低点。
如下图所示,仅将前一个电流与电流(高或低)相连非常重要。

另一件重要的事情是连接实际市场中所有的前期高点(更高的高点或更低的高点)和前期低点(更高的低点和更低的低点)以及下图所示的指标。

另一个要点是,你一定不能忘记连接垂直市场,这意味着实际市场价格(高或低)中的点应该在指标中连接。看看下面的图片。

较长的时间框架比较短的时间框架更相关?
人们已经正确地观察到,较长的时间框架比较短的时间框架更准确,因为其中的错误信号更少。这无疑意味着交易会更少,但有更准确的信号,如果你计划好交易,你可以在这种情况下获得更多。另一方面,较短的则不太可靠。例如,一小时图或者更长的时间图可以帮你搞定。
过早入市会导致亏损?
人们还看到,过早进入市场会导致亏损。而且,如果你太早太频繁地进入市场,可能会导致巨大的损失。但是,你在利用背离交易来获利,而不是亏损。在这种情况下,您必须记住以下几点:
你必须等待指标 交叉 ,因为它预示着势头的潜在转变。这意味着在交叉发生后,可能会有从买入到卖出或者从卖出到买入的转变。如下图所示。

来源:babypips
其次,你必须等待指标脱离超卖或超买的范畴,因为如果它长时间停留在其中一个范畴,它可能无法准确地指示反转。请参考下图了解相同的内容。

来源:babypips
好了。让我们向前看,找出如何使用规则的和隐藏的分歧。
如何使用规则的和隐藏的发散?
当我们在上面读到背离的类型和振荡因素时,我们正确理解了每一个的重要性。但是,现在剩下的是知道如何在交易中使用它们?
基本上,背离有助于交易者识别市场价格的潜在变化,也有助于在此基础上做出适当的交易决定。
让我们来看看如何利用常规和隐藏的背离(连同它们的振荡指标)来做交易决定。
正则散度
正如我们前面看到的,常规背离在发现趋势反转何时会发生方面起着非常重要的作用。看到 MACD 振荡指标的收敛-发散,我们知道收敛意味着趋势可能会继续,发散意味着趋势反转更有可能发生。
常规看涨背离是指当市场中的实际价格形成较低的低点,但指标形成较高的低点(上升趋势)。
常规看跌背离是指市场中的实际价格创出更高的高点,但指标创出更低的高点(下降趋势)。
在这两种情况下,我们预计趋势会逆转。
现在,正则散度可以用来进行如下观察:
- 背离意味着趋势反转是可以预期的。
- 如果货币出现二倍或三倍背离,趋势反转的可能性很大。因此,趋势延续(收敛)的可能性不大。
在常规背离中,振荡指标表明动量转移,因此表明趋势反转。这意味着观察背离有助于知道趋势的结束是预期的。但是,我们已经提到,但再次强调,利用其他因素,以及确认趋势反转或趋势结束是否真的会发生。
仅凭分歧就得出结论是不可取的。此外,获得一个趋势可能结束的额外确认总是有益的。
隐藏的分歧
隐藏背离另一方面,是趋势延续(收敛)的高明指标。
隐藏的看涨背离发生在市场的实际价格创出更高的低点,但振荡指标创出更低的低点(上升趋势)时。
隐藏的看跌背离发生在市场的实际价格创造了一个较低的高点,但振荡指标创造了一个较高的高点(下降趋势)。
你可以在下图中看到常规的背离和隐藏的背离。

来源:交易策略指南
在上图中,你可以看到常规背离导致趋势反转,因此,价格下跌+/-350 点。
同样,可以看到一个隐藏的背离导致趋势的延续,这使得价格上涨了 400 个点并持续下去。
结论
因为这篇文章的目的是讨论在交易中分歧的重要性,以及如何在交易中获得利润,我们把重点放在它的意义和用途上。除了基础知识之外,我们还讨论了一些重要的方面,这些方面的“事实”揭示了如何在每种情况下让分歧更有利可图。简要概述了所有重要的东西,这篇文章讲述了作为交易者,是什么让背离有利可图。因此,在发散方面的经验是必须的,因为它可以通过将应用程序放在正确的位置来获取利润。希望这篇文章能帮助你对背离交易有所了解!
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
多样化的 ETF 投资组合:从回溯测试到实时交易
原文:https://blog.quantinsti.com/diversified-etf-portfolio-project-chee-wai-wan/
这个项目解释了使用九个部门 ETF 的投资组合的交易策略的创建和回溯测试,以及使用 REST API 将该策略转化为交互式经纪人(IBKR)上的实时交易。这个项目完全编码在 Jupyter 笔记本上。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
CW Wan 是一名终身学习者,对商业、经济、金融和数据科学有着浓厚的兴趣。他认为算法交易是他所有兴趣汇聚的一个主题。他目前在新加坡的一家工程和技术集团工作。
他拥有 Quantic 商业和技术学院的高级工商管理硕士学位、新加坡国立大学商业分析理学硕士学位(MSBA)以及伦敦玛丽女王大学金融经济学理学硕士学位。
项目摘要
这个 EPAT 的期末专题包括两部分。
第一部分包括使用九只 SPDR 行业 ETF【1】的投资组合创建并回溯测试一个盈利策略。我创建了一个只做多的每日策略,基于短/长均线交叉的进场/出场信号,以及动态的资金分配(每个季度重新平衡)。
使用 2012 年 1 月至 2021 年 12 月的每日数据进行的 10 年回溯测试得出的平均年回报率超过 30%,夏普比率为 1.4,最大下降幅度为-12%。
第二部分包括将上述策略转化为交互式经纪人(IBKR)上的实时交易。使用 IBKR 的客户端 Web API【2】(RESTful API),并在 Jupyter Notebook【3】上完全编码,我成功地创建了算法上执行上述策略的日常程序所需的所有函数。
项目的这一部分是最累人的,花了将近两个月才完成,但也是最令人满意的。
承认
我要感谢我的项目导师 Rekhit Pachanekar 和 Danish Khajuria 为项目提供的宝贵建议和指导,以及我的课程支持经理 Laxmi Rawat 在 EPAT 课程期间提供的无可挑剔的支持。
项目动机
在我参加 EPAT 课程之前,我问销售顾问,在最终项目中,是否有可能创建一个类似于以下内容的实时算法交易模型/投资组合:

Example Retail Investor Fund[4]
在我开始 EPAT 之前,我几乎没有现场交易市场的经验,但我有一些基本的数据科学和 Python 编程经验。我也有过一些关于量子乌托邦的经历。但是在我能学到很多算法交易之前,它就被关闭了。
因此,对我来说,如果没有别的事情,我希望从 EPAT 课程中学到建立和管理自己投资组合的能力,这种能力至少要与散户投资者的投资组合一样好。
介绍
本着这个目标,我的项目由两部分组成:
第一部分:回溯测试盈利策略——应用在 Python 交易上学到的经验教训——面向对象编程【6】、基于事件的回溯测试【7】和 ETF 交易【8】——我成功地利用 9 只 SPDR 行业 ETF 的投资组合创建了一个简单但盈利的策略。
使用 2012 年 1 月至 2021 年 12 月的每日数据进行的 10 年回溯测试得出的平均年回报率超过 30%,夏普比率为 1.4,最大下降幅度为-12%。这一策略似乎有可能超越上述零售基金的业绩。
第 2 部分——实时交易盈利策略—应用在 REST API【9】和算法交易系统架构【10】上学到的经验,我设法编写了所有必要的函数,通过算法执行上述策略的日常程序,使用 IBKR 的客户端 Web API 连接到经纪人。我完全是在 Jupyter 笔记本上完成的。
本报告的其余部分结构如下:
- 第 2 节提供了关于回溯测试和结果的更多细节。
- 第 3 节解释了实时交易算法是如何设计的。
- 第 4 节总结。
第 1 部分:回溯测试
数据挖掘
为这一策略选择的主要工具是 9 只 SPDR 行业 ETF:
| 股票行情 | 描述 |
| XLY | 非必需消费品 |
| XLP | 消费品 |
| XLE | 活力 |
| XLF | 金融的 |
| XLV | 卫生保健 |
| x 连锁鳞癣 | 产业的 |
| XLB | 材料 |
| XLK | 技术 |
| XLU | 公用事业 |
选择这 9 只 ETF 的理由如下:
- 简单——跟踪 9 个行业的整体表现比跟踪 1500 家公司更容易。
- 交易成本–只交易 9 种工具比交易 1500 家公司更便宜。
- 多元化–每个 ETF 已经是每个领域中最好的公司的多元化投资组合。ETF 投资组合允许进一步分散投资。每季度进行一次的动态资本配置,允许投资组合买入表现更好的行业,“驾驭赢家”。
我们使用雅虎财经【11】(Python yfinance 库)下载了 10 年的每日价格数据,从 2012 年 1 月开始到 2021 年 12 月结束。
我们将 SPY 作为基准。这 9 只 ETF 和 SPY 的价格图表如下:

战略描述
进场/出场信号:我们采用了只做多的指数移动策略(EMA)交叉策略:如果空头 EMA 穿过 1.01 倍的多头 EMA,我们就进入多头。否则我们退出交易。
交易频率:我们使用每日收盘价来计算信号。因此,该策略将每天执行一次。在实时交易期间,该例行程序将在美国市场每个交易时段的最后 5 分钟内执行。
动态资本分配:我们每季度跟踪每个 ETF 的表现,并通过将其季度回报除以所有 ETF 的季度回报之和来计算每个 ETF 的新资本分配。这确保了 ETF 的构成越好,下一季度分配给它的资本就越多。
数据分析
使用面向对象编程,我们在 Jupyter Notebook 上使用 Python 执行了基于事件的回测。结果如下:

主要发现
该策略的 10 年累计对数回报率为 1.58(或简单回报率为 385%),略高于其 SPY 基准(对数回报率为 1.54,简单回报率为 366%)。
最大下降幅度为-0.13,相当于-12%。这发生在 2020 年 COVID19 疫情发作期间。可以看出,当时 SPY 经历的缩减幅度要大得多。
所达到的夏普比率为 1.39。
每个 ETF 的性能统计如下。
- 我们观察到,虽然所有的 ETF 都有正的平均利润,但只有非必需消费品和科技股的命中率超过 0.5。
- 对于其他人来说,积极交易的回报远远超过了消极交易的损失。

限制
上述策略的局限性在于它过于简单,尽管它提供了良好的性能。可以做更多的工作来改进战略或微调战略参数以取得更好的业绩。
然而,在第二部分,我必须将策略转化为现场交易,我认为这更重要。策略改进可以在项目提交后进行。
现场交易
实施方法
项目的第二部分是将策略转换成实时算法交易系统。
我已经有了一个交互式经纪人(IBKR)的账户,所以第一步是确定我将使用 EPAT 课程中教授的哪种方法来连接 IBKR。
- IBKR TWS API【12】——这是 IBKR 专有的开源 API。
- IBridgePy【13】——这是一个第三方应用程序,其外观和工作方式与 Quantopian 的平台相似。
- IBKR 的 REST API——这是 IBKR 的行业标准 RESTfulAPI。
下表总结了我对 EPAT 教授的三种方法的尝试:
| 考虑事项 | TWS API | 杂交 | REST API |
| 内置的交易方法 | 是 |
- be
- All-Trotskyist style
|
- not have
- You need to create your own methods/functions
|
| 要安装的文件 |
- Tw or IB gateway
- [TWS API installs 1016.01.msi file]
|
- Tw or IB gateway
- IBridgePy.zip file (only unzip, no need to install)
|
- [TWS] or IB gateway (optional)
- Client.gwzip file (only unzip, no need to install)
|
| 费用 | 自由的 |
- The free version needs to manually download a new IBridgePy.zip file every 1+ weeks.
- IBridgePy 高级版
需要 360 美元的年费 | 自由的 |
| 努力(排名) |
- medium-sized
- Need to learn how to use the built-in methods
|
- Low, if all goes well.
- Panoramic style
|
- tall
- You need to create your own methods/functions
|
| 易于故障排除 |
- It may be difficult to check what’s wrong [under the hood]
|
- It’s hard to check what’s wrong [under the hood]
- Error messages are meaningless.
| 容易的 |
| Jupyter 笔记本友好? | 未确定的 |
- not have
- You need to run IBridgePy. Py file, and then run your own code, which must be in a separate. Py file
| 是 |
| 技能可转移给其他经纪人? | 不 | 仅限 IBKR、TD Ameritrade 和 Robinhood | 是的,许多经纪人提供 REST API |
归结为 IBridgePy(简单?)vs. REST API(灵活性)。
在与 IBridgePy 的故障排除困难(以及过于频繁地更新 zip 文件的恼人需求)斗争了几个星期后,我决定使用 REST API 方法。
虽然构建我自己的方法/函数来连接 IBKR 很费时间,但是使用 Jupyter Notebook 的能力(对初学程序员有用!),将它们设计成完全按照我想要的方式工作,并且立即排除错误是非常宝贵的。此外,在使用 RESTAPI 中学习的技能可以转移到其他经纪人(如羊驼【14】)和其他非交易目的。
交易系统设计
根据 EPAT 关于系统架构的教训,我按照自动交易系统的基本架构设计了我的系统:

Basic System Architecture [10]
我使用的交易者应用程序是 Jupyter Notebook,这是一个友好但强大的 Python GUI,适合初学者和高级用户。它的结构允许我将代码分解成独立的部分,分别进行测试和故障排除。
它包含标记语言的能力使我更容易记录每一步。我关于这个项目的笔记因此被包括在本报告的附件中。
其余的块由 Python 函数组成。有三种类型的函数:
- 交易序列函数–这些核心函数初始化交易环境,确保交易会话与经纪人连接并通过认证,并在交易日的预定时间调用适当的 ALGO 交易函数或 IB REST API 函数。
- ALGO 交易功能–这些功能旨在执行交易操作的特定部分。需要时,这些函数将调用 IB RESTAPI 函数与代理通信,以获取信息或下订单。
- IB REST API 函数–创建这些函数是为了向 IBRK 服务器发送 GET 或 POST 请求,并接收和处理响应。
下表列出并描述了为执行 algo 交易策略而编写的所有三种类型的函数,从交易序列函数开始。
- 第一个列出的是 algo_daily_schedule() ,它是主要的时间表控制功能,将在所示的交易日调用其他适当的交易序列功能。
- 其他交易序列函数将根据需要调用适当的 ALGO 交易函数或 IB REST API 函数。
- ALGO 交易函数将调用 IB REST API 函数来与经纪人通信。
为执行算法交易策略而编写的函数类型
为这个项目编写的各种类型的函数在下面的 pdf 中提到:
下载这个 PDF 的链接在这个博客的末尾。
挑战
使用 REST API 为交易系统编码是一件累人的事情。
- 事实上,许多时间都花在编写与代理连接的 IB REST API 函数上。
- 我首先必须得到正确的 get 或 POST 结构。
- 然后,我必须将响应解析成与我的系统兼容的格式。
- 花费了大量精力来处理错误响应或意外响应。
- 项目结束后,可以做更多的工作来改进错误处理。
局限性在于,季度再平衡和动态资本分配没有包括在内。遗漏的原因是我没有 3 个月的时间来测试它。
另一个主要限制是系统中没有内置风险管理模块。这两项限制将在项目结束后完成。
参考书目
- https://www.sectorspdr.com/sectorspdr/
- https://interactivebrokers.github.io/cpwebapi/
- https://jupyter.org/
- https://www.syfe.com/equity100
- https://en.wikipedia.org/wiki/Quantopian
- EPAT 课程:DMP 02 面向对象编程导论
- EPAT 课程:DMP-03/04 金融 Python
- EPAT 课程:EFS-06 理解交易所交易基金
- EPAT 课程:TBP-02 休息 API
- EPAT 课程:自动交易系统的 TIO-01 系统结构
- https://pypi.org/project/yfinance/
- https://interactivebrokers.github.io/tws-api/
- https://ibridgepy.com/
- https://alpaca.markets/
摘要
我已经完成了这个 EPAT 项目的两个部分。
在第一部分中,我创建并回测了一个盈利策略,使用了 9 只 SPDR 行业 ETF 的投资组合。使用 2012 年 1 月至 2021 年 12 月的每日数据进行的 10 年回溯测试得出:
- 年平均回报率超过 30%,
- 夏普比率为 1.4,以及
- 最大下降幅度为-12%。
这些结果令人鼓舞,它们似乎胜过了激励这个项目的散户基金。然而,该策略很简单,还可以做更多的工作来提高其性能。
在第二部分中,我使用 REST API 方法并在 Jupyter Notebook 上完全编码,将上述策略转化为交互式经纪人(IBKR)上的实时交易。
项目的这一部分是最累人的,花了将近 2 个月才完成,但也是最令人满意的。将做更多的工作来包括季度再平衡部分,并增加风险管理方面的考虑。
结论
参与这个项目是一次富有成效的经历,我从 EPAT 的许多课程中学到了很多东西。我能够想出一个有利可图的策略,使用 Python 进行回溯测试,并创建一个算法交易系统,在 IBKR 纸上交易账户上实时执行该策略。
从我开始课程前在这个领域的初学者到课程结束后能够完成这个(当然是在项目导师的帮助下!),我相信这证明了 EPAT 的课程是真正优秀的!
如果你想学习算法交易的各个方面,那就去看看这个算法交易课程,它涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。立即注册!
文件在下载
- 项目的完整 Python 代码
- PDF 文档-为执行算法交易策略而编写的函数类型
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
使用加密比较 API 下载 Python 中的加密货币数据
原文:https://blog.quantinsti.com/download-cryptocurrency-data-python-cryptocompare-api/
何塞·卡洛斯·冈萨雷斯·田中
Python 中如何使用 Cryptocompare API 下载加密货币数据?Cryptocompare 是一家加密货币市场数据提供商。这个博客解释了你如何用超级简单的步骤来做到这一点,并让你随时准备应用它!
如果你正在向算法交易或加密货币世界迈出第一步,那么这篇文章就是为你准备的!
我们涵盖:
为什么选择 CryptoCompare?
CryptoCompare 允许用户从大多数重要的加密交易所获得实时价格,绘制图表并进行市场研究分析。它还允许我们获得有限的免费数据进行下载。这就是我们在这篇文章中要做的。
导入库
首先,让我们在我们的 Jupyter 笔记本中安装 cryptocompare 库:
如何用 Python 下载外汇价格数据
原文:https://blog.quantinsti.com/download-forex-price-data-yfinance-library-python/
何塞·卡洛斯·冈萨雷斯·田中
在互联网上,你会找到许多下载外汇价格数据的来源,如 quandl,alpha vantage,brokers’ APIs,yahoo finance 等。今天,我们将教你如何从雅虎财经获取外汇价格数据,从每天到每分钟的频率。
我知道你在想什么:“有很多网站解释如何用雅虎财经库下载股票价格数据,但几乎没有关于如何用它下载外汇价格数据的内容”。
我们都知道股票市场是一个投资的好地方。然而,当你有一个好的策略,外汇资产可以帮助你赚一大笔钱。作为一个探索这个神奇市场的 algo 交易者,yfinance 库将帮助我们轻松下载外汇价格数据。
雅虎财务库安装
太简单了!在我们进入下载部分之前,不要忘记在您的环境中安装这个库。您可以使用以下代码来实现这一点:
用 Python 的雅虎财经库下载期货数据
原文:https://blog.quantinsti.com/download-futures-data-yahoo-finance-library-python/
何塞·卡洛斯·冈萨雷斯·田中
你必须做的第一件事就是学会用 Python 下载期货数据。这个博客解释了完整的过程,并帮助您了解所需的各个步骤。
期货交易本来就是杠杆交易。在投资组合中使用杠杆时必须小心谨慎。管理杠杆的一个好方法是用算法进行交易,这就是这篇博客的重要性。
它包括:
雅虎!财务库安装
Python 是世界上最简单的编程语言之一。Python 使得新手更容易更快地掌握编程技能。建立自己的 Python 交易系统也很容易。
我们将使用一个 Jupyter 笔记本。我们来编码吧!如果你还没有在你的机器上安装这个著名的库,这里有代码:
使用神经网络的动态资产分配
原文:https://blog.quantinsti.com/dynamic-asset-allocation-neural-networks-project-mrinal-mahajan/
该项目旨在通过利用一组动态线性神经网络模型的每日回报预测,为包括 nifty 银行指数在内的股票建立资产配置策略。
神经网络模型是动态的,并且在每个交易日结束时每天更新,以对市场和股票趋势的变化做出反应。除此之外,模型的线性使得结果易于解释。
本项目中使用的完整数据文件和 python 代码也可以在本文末尾下载。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Mrinal Mahajan 毕业于 IIT 坎普尔大学机械工程专业。
交易和投资是他一直着迷的事情,为了在这一领域发展,他从全球风险专业人士协会(GARP)获得了金融风险管理(FRM)的许可。
过去 3 年,他一直在分析领域工作,曾为一些美国最大的银行工作。他目前在信用卡欺诈风险建模领域与一家领先的美国银行合作。
作为获得交易实践经验的下一步,他决定利用他的分析技能来开发一些有利可图且需要最少监控的东西。
就在那时,他萌生了这个项目的想法,在 Quantinsti 团队的指导下,他得以实施这个项目。
定义问题陈述
根据昨天的数据,预测股票价格从今天收盘到第二天收盘的百分比变化。
简而言之,如果我们可以获得每日频率的数据,那么基于昨天(d-1)数据中创建的变量,我们希望预测第二天(d+1)和今天(d)收盘时的价格变化百分比。
根据预测,我们可以知道,如果我们在今天收盘时买入股票,明天是否会盈利。
根据模型结果,我们希望制定一个资产分配策略,该策略可以利用 BTST(今天买明天卖)功能,与各种经纪人的当天交易相比,该功能的交易成本相对较低。
逼近解
第 1 部分-模型开发
我们创建了以下一组动态神经网络模型
- 概率预测器——确定正回报的概率
- 正回报预测器–仅针对正回报实例训练的模型,用于预测回报的正对数值
- 负回报预测器-仅在负回报实例上训练的模型,预测回报的负对数值
在这里,对数收益被用作因变量,而不是百分比收益或价格变化,以保持序列的平稳性。
- 发展数据–2010 年至 2015 年
- 验证数据–2016 年至 2018 年 4 月
- 过时数据–2018 年 5 月至 2020 年 12 月
股票的历史数据如下所示
| 银行/公司名称 | 符号 | 在漂亮银行的权重 | 数据来自 |
| HDFC 银行有限公司 | hdfc 银行 | 28.39% | 01-01-2010 |
| ICICI 银行有限公司 | ICICIBANK | 19.48% | 01-01-2010 |
| Kotak Mahindra 银行有限公司 | 科塔银行 | 16.31% | 01-01-2010 |
| Axis 银行有限公司 | 轴心银行 | 14.95% | 01-01-2010 |
| 印度国家银行 | SBIN | 9.56% | 01-01-2010 |
| 兴业银行股份有限公司。 | 工业银行 | 4.37% | 01-01-2010 |
| 班丹银行有限公司 | 班德汉银行 | 2.58% | 27-03-2018 |
| 联邦银行有限公司 | 联邦银行 | 1.33% | 01-01-2010 |
| RBL 银行有限公司 | rbl 银行 | 1.06% | 31-08-2016 |
| IDFC 第一银行有限公司 | IDFCFIRSTB | 0.85% | 06-11-2015 |
| 旁遮普国家银行 | PNB | 0.46% | 01-01-2010 |
| 巴罗达银行 | 班克 boarda | 0.66% | 01-10-2010 |
第二部分-战略
该策略的目的是每天在 12 只银行股之间分配现金流入和出售任何现有头寸产生的可用现金。
执行该策略的程序如下
- 从概率模型中获得第二天正回报(未来回报)的概率§。
- 从确定性回报模型中获得正的和负的对数回报,并将对数值转换为百分比。假设正百分比回报是 m ,负百分比回报是 n 。
- 将预期收益(e)计算为 p*m+(1-p)n .将预期收益转换为 log 并除以最近 5 天 log 收益的波动率(标准差)得到一个比值。让我们称这个比率为夏普。
- 将夏普修改为最小值(0,夏普)。对于夏普值为 0 的股票,如果持有预期损失(根据预期回报计算)/[到目前为止的利润]的比例,则卖出该股票,如果利润为正,则卖出该股票的所有股票。
- 对于夏普比率为正的股票,按其夏普比率分配出售股票获得的现金和实际现金。
第 3 部分-风险管理
对每只股票的投资应用 20%的止损,即如果一只股票现有头寸的市场价值低于投资价值的 80%,则卖出该股票的所有股票。
模型开发
作为模型输入而创建的变量如下
| 变量 | 尺寸 | 描述 |
| 返回 _1d | 过去的回报 | 前 1 天日志返回 |
| 返回 _2d | 过去的回报 | 最近 2 天日志返回 |
| 返回 _3d | 过去的回报 | 最近 3 天日志返回 |
| return_4d | 过去的回报 | 最近 4 天日志返回 |
| return_5d | 过去的回报 | 最近 5 天日志返回 |
| return_6d | 过去的回报 | 最近 6 天日志返回 |
| return_7d | 过去的回报 | 过去 7 天的日志返回 |
| 返回 _8d | 过去的回报 | 过去 8 天的日志返回 |
| return_9d | 过去的回报 | 最近 9 天日志返回 |
| return_10d | 过去的回报 | 最近 10 天日志返回 |
| 打开 _ 更改 | 变化 | 记录最后一天打开的更改 |
| 高 _ 变化 | 变化 | 记录最后一天的高点变化 |
| 低 _ 变化 | 变化 | 记录最后一天的下限变化 |
| 范围 _ 变化 | 变化 | 记录前一天高低范围的变化 |
| 体积 _ 变化 | 变化 | 记录前一天的卷更改 |
| 挥发性 5 | 波动性 | 过去 5 天日志回报的标准偏差 |
| 挥发性 20 | 波动性 | 过去 20 天日志回报的标准偏差 |
| MA5 _ 比率 | 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 | 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 高 5 _ 比率 | 比率 | 最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 | 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 比率 | 最后一天接近最后 20 天高点的比率 |
| Low20_ratio | 比率 | 过去 20 天的最低价格与最后一天收盘价格的比率 |
| return_1d_nifty | 过去回报俏皮 | nifty bank 最近 1 天的日志回报 |
| return_2d_nifty | 过去回报俏皮 | nifty bank 最近两天的日志回报 |
| return_3d_nifty | 过去回报俏皮 | nifty bank 最近 3 天的日志回报 |
| return_4d_nifty | 过去回报俏皮 | nifty bank 最近 4 天的日志回报 |
| 返回 _5d_nifty | 过去回报俏皮 | nifty bank 最近 5 天的日志回报 |
| return_6d_nifty | 过去回报俏皮 | nifty bank 最近 6 天的日志回报 |
| return_7d_nifty | 过去回报俏皮 | nifty bank 最近 7 天的日志回报 |
| return_8d_nifty | 过去回报俏皮 | nifty bank 最近 8 天的日志回报 |
| return_9d_nifty | 过去回报俏皮 | nifty bank 最近 9 天的日志回报 |
| return_10d_nifty | 过去回报俏皮 | nifty bank 的最近 10 天日志回报 |
| MA5 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 最后一天接近最后 20 天移动平均值的比率 |
| 高 5 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 的最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 _ 俏皮 | 漂亮的比率 | nifty 银行的最近 5 天低点与最近一天收盘的比率 |
| 高 20 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | 漂亮的比率 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 挥发性 5_nifty | 波动俏皮 | nifty bank 过去 5 天日志回报的标准差 |
| 波动性 20_nifty | 波动俏皮 | nifty bank 过去 20 天日志回报的标准差 |
| 布林 5 _ 比率 | 布林格 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 5 天 |
| 布林 20 _ 比率 | 布林格 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 20 天 |
| ADX5 | 动量指示器 | 5 天内的平均方向移动指数 |
| RSI5 | 动量指示器 | 5 天内的相对强度指数 |
| ADX20 | 动量指示器 | 20 天内的平均方向移动指数 |
| RSI20 | 动量指示器 | 20 天的相对强度指数 |
| 相互关系 | 巧妙的关联 | 最近 10 天的回报与最近 10 天的回报的相关性 |
首先创建一个公共输入数据集。然后,我们继续分析 3 个用例的可变趋势——概率、正回报和负回报模型。
例如,我们在下面展示了 3 个模型中相关变量的趋势。
模型 1 -概率模型趋势

模型 2 -正回报模型趋势

这一趋势表明了这样一种假设,即对于价格的上行,股票与市场的相关性越高,回报越高。
模型 3 -负回报模型趋势

趋势表明,总体而言,随着相关性的增加,对股价的负面影响也会增加。
在可视化趋势后,我们使用高级分析技术(如方差膨胀、变量聚类和反向选择)以及趋势的基本直观可视化,对每个模型进行了变量缩减。
注意:模型开发的代码和资源可以在博客的末尾找到。
在变量分析和简化之后,以下变量被用作模型的输入。
概率预测模型
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| return_5d | 最近 5 天日志返回 |
| return_10d | 最近 10 天日志返回 |
| 打开 _ 更改 | 记录最后一天打开的更改 |
| 高 _ 变化 | 记录最后一天的高点变化 |
| 低 _ 变化 | 记录最后一天的下限变化 |
| 体积 _ 变化 | 记录前一天的卷更改 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| 布林 5 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 5 天 |
| 布林 20 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 20 天 |
| RSI5 | 5 天内的相对强度指数 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| return_8d_nifty | nifty 的最近 8 天日志返回 |
| return_10d_nifty | nifty 的最近 10 天日志返回 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
正回报预测模型
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _2d | 最近 2 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| return_4d | 最近 4 天日志返回 |
| 打开 _ 更改 | 记录最后一天打开的更改 |
| 体积 _ 变化 | 记录前一天的卷更改 |
| 电压 5 | 过去 5 天日志回报的标准偏差 |
| 电压 20 | 过去 20 天日志回报的标准偏差 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| 高 5 _ 比率 | 最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| ADX20 | 20 天内的平均方向移动指数 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| return_9d_nifty | nifty 的最近 9 天日志返回 |
| return_10d_nifty | nifty 的最近 10 天日志返回 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 |
负收益预测模型
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _2d | 最近 2 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| 高 _ 变化 | 记录最后一天的高点变化 |
| 电压 5 | 过去 5 天日志回报的标准偏差 |
| 电压 20 | 过去 20 天日志回报的标准偏差 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| 返回 _5d_nifty | nifty 的最近 5 天日志返回 |
| return_9d_nifty | nifty 的最近 9 天日志返回 |
| 高 5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 |
使用给定的变量,开发具有收敛架构的线性神经网络模型。收敛架构是这样的,在下一个隐藏层,节点的数量是当前层的一半。
**例如:**在概率模型中有 26 个输入,即在输入层有 26 个节点,然后在第一隐藏层有 13 个节点,在第二隐藏层有 6 个节点,在第三隐藏层有 3 个节点,最后在输出层有一个节点。
在这种情况下,所有隐藏层节点都具有线性函数,只有输出层具有 sigmoid 函数。在正负收益模型中,包括输出在内的所有节点都是线性激活的。
用于训练模型的开发数据来自 2010-2015–5 年。
每个模型的静态方程系数如下
概率预测模型
比值对数(p/1-p)的线性方程
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| return_5d | 最近 5 天日志返回 |
| return_10d | 最近 10 天日志返回 |
| 打开 _ 更改 | 记录最后一天打开的更改 |
| 高 _ 变化 | 记录最后一天的高点变化 |
| 低 _ 变化 | 记录最后一天的下限变化 |
| 体积 _ 变化 | 记录前一天的卷更改 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| 布林 5 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 5 天 |
| 布林 20 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 20 天 |
| RSI5 | 5 天内的相对强度指数 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| return_8d_nifty | nifty 的最近 8 天日志返回 |
| return_10d_nifty | nifty 的最近 10 天日志返回 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
正回报模型
对数收益的线性方程
| 变量 | 描述 | 系数 |
| 返回 _1d | 前 1 天日志返回 | 0.112714604 |
| 返回 _2d | 最近 2 天日志返回 | 0.076917067 |
| 返回 _3d | 最近 3 天日志返回 | 0.137521163 |
| return_4d | 最近 4 天日志返回 | 0.139919728 |
| 打开 _ 更改 | 记录最后一天打开的更改 | 0.044385113 |
| 体积 _ 变化 | 记录前一天的卷更改 | 0.00109395 |
| 电压 5 | 过去 5 天日志回报的标准偏差 | -0.00038334 |
| 电压 20 | 过去 20 天日志回报的标准偏差 | 0.056020129 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 | 0.314374059 |
| 高 5 _ 比率 | 最后一天接近最后 5 天高点的比率 | 0.315460533 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 | 0.204366401 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 | 0.133332253 |
| ADX20 | 20 天内的平均方向移动指数 | 0.001150683 |
| RSI20 | 20 天的相对强度指数 | 0.01172027 |
| return_1d_nifty | nifty 的最近 1 天日志返回 | 0.267879993 |
| return_2d_nifty | nifty 的最近 2 天日志返回 | 0.193813279 |
| return_3d_nifty | nifty 的最近 3 天日志返回 | 0.161507115 |
| return_4d_nifty | nifty 的最近 4 天日志返回 | 0.104044914 |
| return_9d_nifty | nifty 的最近 9 天日志返回 | 0.039391026 |
| return_10d_nifty | nifty 的最近 10 天日志返回 | 0.029924326 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 | 0.247091874 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 | 0.047915675 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 | 0.018904656 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 | 0.055917718 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 | 0.097226188 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 | 0.048495531 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 | 0.001289934 |
| 拦截 | | -0.232171148 |
负收益模型
对数收益的线性方程
| 变量 | 描述 | 系数 |
| 返回 _1d | 前 1 天日志返回 | 0.124469906 |
| 返回 _2d | 最近 2 天日志返回 | 0.094707593 |
| 返回 _3d | 最近 3 天日志返回 | 0.098002963 |
| 高 _ 变化 | 记录最后一天的高点变化 | 0.061372437 |
| 电压 5 | 过去 5 天日志回报的标准偏差 | 0.489989489 |
| 电压 20 | 过去 20 天日志回报的标准偏差 | 0.461109012 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 | 0.143796369 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 | 0.245543823 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 | 0.214187935 |
| RSI20 | 20 天的相对强度指数 | 0.017691486 |
| return_1d_nifty | nifty 的最近 1 天日志返回 | 0.152266026 |
| return_2d_nifty | nifty 的最近 2 天日志返回 | 0.149913758 |
| return_3d_nifty | nifty 的最近 3 天日志返回 | 0.137844741 |
| return_4d_nifty | nifty 的最近 4 天日志返回 | 0.135978788 |
| 返回 _5d_nifty | nifty 的最近 5 天日志返回 | 0.005645283 |
| return_9d_nifty | nifty 的最近 9 天日志返回 | 0.035861455 |
| 高 5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天高点的比率 | 0.303022981 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 | 0.101814494 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 | 0.074914791 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 | 0.029958185 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 | 0.481154203 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 | 0.024172308 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 | 0.000418738 |
| 拦截 | | -0.212120146 |
静态与动态模型
2010-2015 年(5 年)数据的模型开发为我们提供了所有模型的静态方程。然而,神经网络的好处是它不同节点的权重可以通过输入新数据来更新。
这在直觉上是有意义的,因为市场或股票并不总是遵循一个固定的静态方程,我们需要一个能够反映这些变化的动态解决方案。
作为相同概念的证明,我们通过每天输入 2016 年 1 月至 2018 年 4 月的数据并更新模型权重,创建了一个动态模型。所有 3 个模型的方程都显示了一段时间内的变化。
接下来,我们比较了 2018 年 1 月至 2018 年 4 月期间的结果,以了解差异。在这里,我们试图比较不同股票在这 4 个月中两个模型的准确度和精确度。
为了解释我们如何构建预测指标,假设概率模型返回价格上涨的概率 p,正负回报模型给出 x 和- y 作为回报,那么预期回报 e = px+(1-p)(-y) 。
如果 e 是正的,我们说正收益是预测的,我们的准确度和召回率都是基于此。
静态与动态——按月拆分
| 月 | 静态 | 动态 |
| 精度 | 精度 | 回忆 | 精度 | 精度 | 回忆 |
| 2018-01 | 43% | 42% | 41% | 46% | 46% | 53% |
| 2018-02 | 46% | 42% | 89% | 53% | 40% | 35% |
| 2018-03 | 50% | 44% | 46% | 54% | 46% | 27% |
| 2018-04 | 50% | 48% | 46% | 50% | 48% | 53% |
| 总计 | 47% | 44% | 54% | 51% | 46% | 43% |
从上面的统计数据可以看出,与静态模型相比,动态模型的预测更加准确和精确。此外,随着越来越多的数据输入到模型中,模型结果很有可能在未来得到改善。
静态与动态——股票分割
| 符号 | 静态 | 动态 |
| 精度 | 精度 | 回忆 | 精度 | 精度 | 回忆 |
| AXISBANK | 46% | 41% | 67% | 51% | 41% | 42% |
| 班克巴罗达 | 50% | 45% | 56% | 51% | 45% | 36% |
| 联邦银行 | 51% | 49% | 47% | 49% | 45% | 37% |
| HDFCBANK | 46% | 39% | 24% | 61% | 61% | 53% |
| ICICIBANK | 48% | 42% | 76% | 50% | 39% | 36% |
| 开始吧 | 48% | 48% | 37% | 49% | 50% | 43% |
| KOTAKBANK | 46% | 58% | 43% | 53% | 64% | 51% |
| PNB | 40% | 34% | 63% | 53% | 37% | 37% |
| SBIN | 45% | 40% | 75% | 49% | 36% | 38% |
| t0rb lbank t1 号 | 50% | 50% | 60% | 41% | 41% | 43% |
| bandhan 银行 | 69% | 40% | 67% | 54% | 29% | 67% |
| IDFCFIRSTB | 45% | 41% | 53% | 49% | 44% | 50% |
| 总计 | 47% | 44% | 54% | 51% | 46% | 43% |
可以看出,对于大多数股票来说,动态模型变得更加准确和精确。
战略
基于动态模型结果,我们实施了一些今天买明天卖(BTST)策略的变体。回溯测试期从 2018 年 5 月 1 日至 2020 年 12 月 10 日,为 2.61 年。
与之比较的基准策略是 nifty 银行指数上的买入并持有策略。最终成为最佳选择的变体是每月 SIP,每只股票投资的止损为 20%。我们案例中的 SIP 金额为每月 20,000 印度卢比。
以下是这方面的统计数字
| 统计数据 | 基准 | 月啜 |
| 最大投资回报率 | 26.89% | 131.87% |
| 米诺里 | -33.83% | -22.92% |
| 最大压降 | 47.86% | 55.39% |
| 最终国王 | 19.70% | 53.31% |
| 同比退货 | 7.14% | 17.80% |
可以看出,与买入并持有 bank nifty 的基准策略相比,这种策略产生的年回报率至少超过 10%。战略的加班表现可以在下图中看到:

从图表中可以看出,尽管该策略在最初几年比基准稍有滞后,但在最近一段时间却表现出色。
局限性
- 回溯测试不考虑任何交易成本,但是,对于这种策略,各种经纪人都可以获得最小的交易成本。然而,为了进一步微调,可以只出售已交付的股票,而不是未结头寸。
- 为了获得当天买卖股票的最佳价格,需要实施市场微观结构策略。
- 一个自动化的应用程序来执行每天的战略将是必需的。这是通过在 Zerodha 的 KITE 平台上创建一个应用程序来实现的。
结果
在 2011 年 2 月 11 日记录该项目时,该模型在一个月的时间内给出了大约 5%的投资回报。
详情见下表:-
| 符号 | 投入的资金 | 市值 | 损益表 | 股份持有量 | 德马特的股份 | LTP |
| HDFCBANK | 1387.15 | 1581.75 | 194.60 | 1 | 1 | 1581.75 |
| ICICIBANK | 6.20 | - | -6.20 | 0 | 0 | 632.15 |
| KOTAKBANK | 7066.20 | 7808.20 | 742.00 | 4 | 4 | 1952.05 |
| AXISBANK | - | - | - | 0 | 0 | 734.80 |
| SBIN | 16.55 | - | -16.55 | 0 | 0 | 392.25 |
| 开始吧 | 4256.60 | 5114.00 | 857.40 | 5 | 5 | 1022.80 |
| bandhan 银行 | 376.15 | - | -376.15 | 0 | 0 | 331.20 |
| 联邦银行 | 779.70 | 745.65 | -34.05 | 9 | 8 | 82.85 |
| t0rb lbank t1 号 | 2483.95 | 2673.55 | 189.60 | 11 | 11 | 243.05 |
| IDFCFIRSTB | 719.21 | 758.25 | 39.04 | 15 | 13 | 50.55 |
| 班克巴罗达 | 412.75 | 398.50 | -14.25 | 5 | 4 | 79.70 |
| PNB | 228.40 | 118.35 | -110.05 | 3 | 3 | 39.45 |
| 市场资金 | 17732.86 | 19198.25 | 1465.39 | | | |
| 库存现金 | 2267.14 | 1886.55 | -380.59 | | | |
| 总计 | 20000.00 | 21084.80 | 1084.80 | | | |
| ROI | 5.42% | | | | | |
编码
这个策略的代码和详细分析可以在这里找到。
结论
利用动态线性模型,为漂亮的银行股制定积极的每日投资组合再平衡资产配置策略,可以帮助在大约 3 年的时间内产生接近 20%的年回报率。
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT) 的高管课程。该课程包括各种培训模块,让你具备在算法交易中建立一个有前途的职业生涯所需的技能。
为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
动态资金管理
扎克·奥克斯
许多有抱负的交易者大多梦想上帝般的回报——从几笔好交易开始,他们拿出心理计算器,开始计算他们什么时候会成为亿万富翁,或者开下一家文艺复兴资本。
有经验的交易者会告诉你,好交易和坏交易在业余交易者和大师交易者之间没有太大的区别——真正的区别在于纪律,而这通常是以资金管理的形式实现的。
当我想到圣杯系统的时候,我主要梦到标准差、相关性和下降。我梦想有一个标准偏差的系统,需要科学的符号来衡量它的方差,平均相关度
在开发过程中,我只考虑一次回报,或者实际上是性能的任何上升指标——这是我第一次测试系统以确保它满足我的最低性能阈值。只要够用,直到投资组合层面我都不会再考虑回归。
对于好奇的人来说,我的系统门槛通常是:
- 同比增长 25%,
- 小于 2.5% DD,
- 夏普> 2.5,
- 平均交易> 75 美元,以及
- 胜率> 65%。
我们马上会回到胜率,因为我认为从数量上来说,胜率是系统实力的两个最重要的预测指标之一。系统通常会偏离到几对指标的平衡行为——赢率与平均交易(止损和目标平衡行为),最大损失/固定止损与提款——我发现低固定止损通常会增加提款(通过降低赢率——见平衡行为 1)。
对于那些不明白的人,让我们来定义胜率,然后我会告诉你它与这个版本的关系,因为有几种方法可以衡量它。我倾向于用盈利交易/总交易来衡量,但许多人更多地把它作为回忆统计来衡量,并把它作为盈利交易/亏损交易来对待,但我发现这个指标有太多的移动部分——当有选择时,我总是选择最简单的形式来表达任何问题。
回到资金管理——量化交易者的纪律化身。
如果你还没有注意到,我首先从风险的角度考虑策略——我总是考虑不利因素和最坏的情况,并从那里开始积累。我典型的资金管理倾向于遵循同样的逻辑,因为我更喜欢使用我能找到的最保守的资金管理算法。我认为交易中的“持久力”是有道理的——我的首要任务是确保当我的系统找到正确的事件组合来反弹时,我还活着。
你们中的一些人会说这太消极了——我应该把重点放在不需要恢复上——但是对于那些多年来系统交易的人来说,所有的系统都有亏损——系统越好,亏损在心理上就越困难。
我的 MM 解决方案一直使用固定比率,它使用一个 delta 值来保护你的利润,只有当你在每份合同中赚取了 Delta 量的利润时,才添加合同-因此,如果你的 Delta 是 50k,你有 1 份合同,你需要 50K 的利润增加到 2 份,然后达到 3 份,你需要 100k (2x50k)。
下面是公式,供参考。
*N = . 5 * SQRT(1+8 (ProfitPerContract/Delta))+1
或者用 Python:
数量= .5 * (np.sqrt(1 + 8(P/D)) + 1)*
虽然这是一个很好的基础解决方案,但我一直有兴趣找到一种方法,将这个难题的关键部分——胜率——运用到资金管理中。
也许有一种方法,我们可以增加每个方向的仓位大小,甚至是特定的进场,因为进场或出场以高胜率证明其实力?
这有点罗嗦——简单地说,假设你的短线是 9/10,长线是 4/10——也许我们应该把大部分资金放在短线上,直到它开始平衡?
(有人可能会说,我们应该权衡相反的情况,因为比率最终应该接近它们各自的均值——但这是一个效率 MM 系统,而不是均值回复 MM 系统!不过,自己试一试可能会很有趣。)
那么这在策略代码中需要什么呢?显然,我们需要一种方法来计算每个方向的交易,这可以简单地随着每个条目而增加—(注意范围,确保使用类变量或全局变量,否则它会随着方法的范围而清除)。
因此,让我们使用全局变量,因为这样更简单/更易读—我将添加 LONGS 和 SHORTS 变量,将它们初始化为 0(尽管将它们设置为 10 可能是个好主意,并将 WINS 初始化为 5 以开始偶数)。这些变量将计算方向性交易,但是如果你有 10 个不同的进场信号,你可以为每个信号加上全局计数。

对于每个计数(分母),我们将创建一个 LongWins(分子),以计算我们各自的 WinPct 变量—两者都应该是 globals 或 class vars。
对于位置,我通过导入将全局放在顶部,但是,我们应该如何增加 Wins?我选择这样做,只是在我的 trailStop 逻辑中增加“xWins”全局变量(就在它被调用之前——退出一个成功的交易),但是如果你有一个固定的目标也可以。
你也可以走相反的路线,只用固定止损跟踪亏损(然后确保计算 WinPct = (1-LongLosers)。

我也有两个基于逻辑的出场——它们在一系列的低点/高点之后出场,但是不清楚这是否有利可图。有几种方法可以处理这个问题——你可以打一个电话来确定成本基础,这样就可以在它之前打开 PnL,或者(为了简单起见)我只是将它们增加了 0.5,一般认为它们是中性的。
既然您已经设置了计数和所有需要的变量——是时候使用它们了!

我创建了一个方法,将这些值作为输入,并为您各自的条目确定适当的数量。我已经附上了代码,但为了澄清这是你要用 WinPctLongs = LongWins / Longs 分配 win pct 的地方。
另一个关键部分是为 MAXQTY 或完整数量设置一个全局值——我现在将它设置为 100。这是您的 win pct 将从中抽取的百分比,以确定固定数量,并确保您返回一个 int(或向下舍入一个 float — round(qty,0)),因为没有半股。
使用前面的例子,(9/10)空头现在将为下一个空头条目交易 90 股(. 9 x MAXQTY)空头。

虽然这个 MM 系统在基本示例上表现不佳——主要是因为它最初将其缩小到 1/100 的大小(我会将每个 WinPct 初始化为 50,并将测试 MAXQTY 的初始数量增加一倍,以获得可比的结果)——但我确实认为像这样的动态 MM 方法实际上可以与传统的 MM 算法结合使用,如 Fixed Ratio 目标是最终产品大于其各部分的总和。
***纪律不能用 6 行代码来教。*T3】
但希望通过一点探索,你可以利用这一点来培养市场所需的勇气。
交易愉快!
免责声明:本客座博文中提供的观点、意见和信息仅属作者个人观点,不代表 QuantInsti 的观点、意见和信息。本文中所做的任何陈述或共享的链接的准确性、完整性和有效性都不能得到保证。我们对任何错误、遗漏或陈述不承担任何责任。与侵犯知识产权相关的任何责任由他们承担。
下载中的文件:
- mod_beg - Python 代码
- Win_Rate_MM Jupyter 笔记本
(在示例代码中,我还包括了固定比率、代码和一种在一个系统中使用字典跟踪多种工具/策略的方法)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









