







原文:RealPython
Python Web 应用程序:将脚本部署为 Flask 应用程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Flask 在 Web 上部署你的 Python 脚本
你写了一个令你自豪的 Python 脚本,现在你想向全世界炫耀它。但是怎么会是?大多数人不会知道如何处理你的.py文件。将你的脚本转换成一个 Python web 应用是一个让你的代码对广大受众可用的好办法。
在本教程中,您将学习如何从本地 Python 脚本到完全部署的 Flask web 应用程序,您可以与全世界共享该应用程序。
本教程结束时,你会知道:
- 什么是网络应用以及你如何在线托管它们
- 如何将 Python 脚本转换成 Flask web 应用
- 如何通过在 Python 代码中添加 HTML 来改善用户体验
- 如何将你的 Python web 应用部署到谷歌应用引擎
除了浏览一个示例项目之外,您还会在整个教程中找到大量的练习。他们会给你机会通过额外的练习巩固你所学的东西。您也可以通过单击下面的链接下载将用于构建 web 应用程序的源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用了解如何使用 Flask 创建 Python web 应用程序。
温习基础知识
在本节中,您将在本教程实践部分的不同主题中获得理论基础:
- 存在哪些类型的 Python 代码分发
- 为什么构建 web 应用程序是一个好的选择
- 什么是 web 应用程序
- 内容如何通过互联网传递
- 虚拟主机意味着什么
- 存在哪些托管提供商,使用哪一个
重温这些主题可以帮助你在为 Web 编写 Python 代码时更加自信。然而,如果你已经熟悉了它们,那么请随意跳过,安装 Google Cloud SDK,并开始构建你的 Python web 应用。
分发您的 Python 代码
把你的代码带给你的用户叫做分发。传统上,有三种不同的方法可以用来分发您的代码,以便其他人可以使用您的程序:
- Python 库
- 独立程序
- Python web 应用程序
您将仔细研究下面的每一种方法。
Python 库
如果你使用过 Python 广泛的包生态系统,那么你可能已经安装了带有 pip 的 Python 包。作为一名程序员,您可能希望在 PyPI 上发布您的 Python 包,以允许其他用户通过使用pip安装它来访问和使用您的代码:
$ python3 -m pip install <your-package-name>
在您成功地将代码发布到 PyPI 之后,这个命令将在您的任何用户的计算机上安装您的包,包括它的依赖项,前提是他们有互联网连接。
如果您不想将代码发布为 PyPI 包,那么您仍然可以使用 Python 的内置sdist命令来创建一个源发行版或一个 Python 轮来创建一个构建发行版来与您的用户共享。
像这样分发代码可以使它接近您编写的原始脚本,并且只添加其他人运行它所必需的内容。然而,使用这种方法也意味着您的用户需要使用 Python 来运行您的代码。许多想要使用脚本功能的人不会安装 Python,或者不熟悉直接处理代码所需的过程。
向潜在用户展示代码的一种更加用户友好的方式是构建一个独立的程序。
独立程序
计算机程序有不同的形状和形式,将 Python 脚本转换成独立程序有多种选择。下面你会读到两种可能性:
- 打包您的代码
- 构建 GUI
像 PyInstaller 、 py2app 、 py2exe 或公文包这样的程序可以帮助打包你的代码。它们将 Python 脚本转换成可执行程序,可以在不同平台上使用,而不需要用户显式运行 Python 解释器。
**注意:**要了解更多关于打包代码的信息,请查看使用 PyInstaller 轻松分发 Python 应用程序的或收听真正的 Python 播客插曲打包 Python 应用程序的选项。
虽然打包代码可以解决依赖性问题,但是代码仍然只能在命令行上运行。大多数人习惯于使用提供图形用户界面(GUI)的程序。您可以通过为 Python 代码构建一个 GUI 来让更多的人访问您的代码。
**注意:**有不同的软件包可以帮助你构建 GUI,包括 Tkinter 、 wxPython 和 PySimpleGUI 。如果你想构建一个基于桌面的应用,那么看看 Python GUI 编程的学习路径。
虽然一个独立的 GUI 桌面程序可以让你的代码被更多的人访问,但是它仍然是人们入门的一个障碍。在运行你的程序之前,潜在用户需要完成几个步骤。他们需要找到适合其操作系统的正确版本,下载并成功安装。有些人可能在成功之前就放弃了。
许多开发人员转而构建可以在互联网浏览器上快速访问和运行的 web 应用程序,这是有道理的。
Python 网络应用
web 应用程序的优势在于它们是独立于平台的,任何能够访问互联网的人都可以运行。他们的代码在后端服务器上实现,程序在那里处理输入的请求,并通过所有浏览器都能理解的共享协议做出响应。
Python 支持许多大型 web 应用程序,并且是后端语言的常见选择。许多 Python 驱动的 web 应用程序从一开始就被规划为 web 应用程序,并且是使用 Python web 框架构建的,比如您将在本教程中使用的 Flask 。
然而,与上面描述的 web 优先的方法不同,您将从一个不同的角度出发。毕竟,你没有计划构建一个网络应用。您刚刚创建了一个有用的 Python 脚本,现在您想与全世界分享。为了让更多的用户能够访问它,您将把它重构为一个 web 应用程序,然后部署到互联网上。
是时候回顾一下什么是 web 应用程序,以及它与 Web 上的其他内容有何不同。
了解 Python Web 应用程序
从历史上看,网站有固定的内容,对于访问该页面的每个用户都是一样的。这些网页被称为静态网页,因为当你与它们互动时,它们的内容不会改变。当提供静态网页时,web 服务器通过发回该网页的内容来响应您的请求,而不管您是谁或您采取了什么其他操作。
您可以在第一个上线的 URL浏览静态网站的示例,以及它链接到的页面:

这种静态网站不被认为是应用程序,因为它们的内容不是由代码动态生成的。虽然静态网站曾经构成了整个互联网,但今天的大多数网站都是真正的网络应用程序,提供可以改变内容的动态网页(T2)。
例如,一个网络邮件应用程序允许你以多种方式与之交互。根据您的操作,它可以显示不同类型的信息,通常停留在一个页面中:
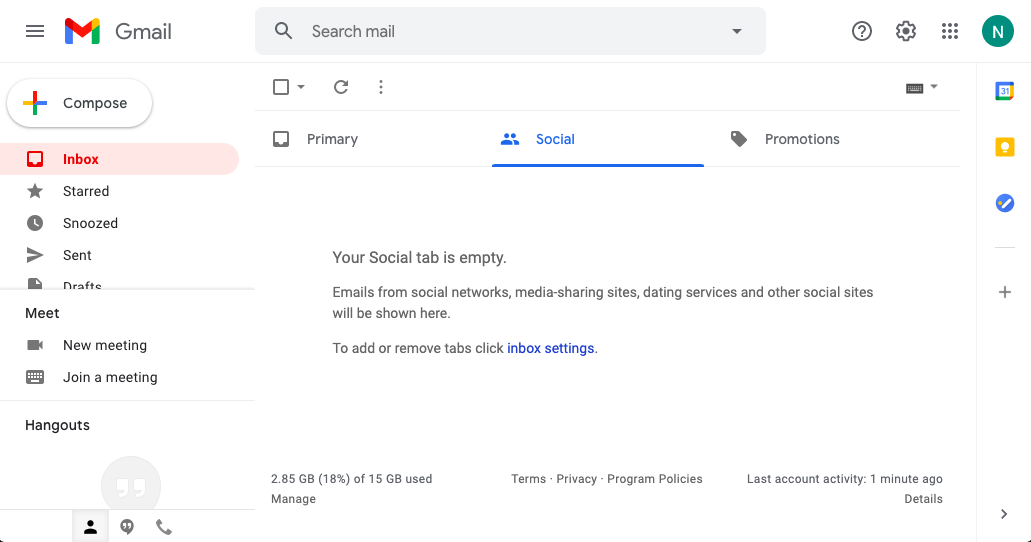
Python 驱动的 web 应用使用 Python 代码来决定采取什么动作和显示什么内容。您的代码由托管您网站的 web 服务器运行,这意味着您的用户不需要安装任何东西。他们只需要一个浏览器和一个互联网连接就可以与你的代码进行交互。
让 Python 在网站上运行可能很复杂,但是有许多不同的 web 框架自动处理细节。如上所述,在本教程中,您将构建一个基本的 Flask 应用程序。
在接下来的部分中,您将从较高的层面了解在服务器上运行 Python 代码并向用户提供响应所需的主要过程。
查看 HTTP 请求-响应周期
通过互联网提供动态内容涉及许多不同的部分,它们都必须相互通信才能正常工作。以下是用户与 web 应用程序交互时发生的情况的概述:
-
**发送:**首先,你的用户在你的 web 应用上请求一个特定的网页。例如,他们可以通过在浏览器中键入 URL 来实现这一点。
-
**接收:**这个请求被托管你的网站的网络服务器接收。
-
**匹配:**您的 web 服务器现在使用一个程序将用户的请求匹配到您的 Python 脚本的特定部分。
-
**运行:**程序调用适当的 Python 代码。当您的代码运行时,它会写出一个网页作为响应。
-
**传送:**然后程序通过网络服务器将这个响应传送给你的用户。
-
**查看:**最后,用户可以查看 web 服务器的响应。例如,生成的网页可以在浏览器中显示。
这是内容如何通过互联网传送的一般过程。服务器上使用的编程语言以及用于建立连接的技术可能会有所不同。然而,用于跨 HTTP 请求和响应进行通信的概念保持不变,被称为 HTTP 请求-响应周期。
注意: Flask 将为您处理大部分这种复杂性,但它有助于在头脑中保持对这一过程的松散理解。
要让 Flask 在服务器端处理请求,您需要找到一个 Python 代码可以在线的地方。在线存储你的代码来运行一个网络应用程序叫做虚拟主机,有很多提供商提供付费和免费的虚拟主机服务。
选择托管提供商:谷歌应用引擎
选择虚拟主机提供商时,您需要确认它支持运行 Python 代码。它们中的许多都需要花钱,但本教程将坚持使用一个免费的选项,它是专业的、高度可扩展的,但设置起来仍然合理: Google App Engine 。
注意: Google App Engine 对每个应用强制执行每日配额。如果你的网络应用超过了这些限额,那么谷歌将开始向你收费。如果你是谷歌云的新客户,那么你可以在注册时获得一个免费促销积分。
还有许多其他的免费选项,比如 PythonAnywhere 、 Repl.it 或 Heroku ,你可以稍后再去探索。使用 Google App Engine 将为您学习如何将 Python 代码部署到 web 上提供一个良好的开端,因为它在抽象掉复杂性和允许您自定义设置之间取得了平衡。
谷歌应用引擎是谷歌云平台(GCP)的一部分,该平台由谷歌运营,代表着一个大型云提供商,另外还有微软 Azure 和亚马逊网络服务(AWS) 。
要开始使用 GCP,请为您的操作系统下载并安装 Google Cloud SDK 。除了本教程,你还可以参考谷歌应用引擎的文档。
**注意:**您将使用 Python 3 标准环境。谷歌应用引擎的标准环境支持 Python 3 运行时,并提供一个免费层。
Google Cloud SDK 安装还包括一个名为gcloud的命令行程序,您稍后将使用它来部署您的 web 应用程序。安装完成后,您可以通过在控制台中键入以下命令来验证一切正常:
$ gcloud --version
您应该会在终端中收到一个文本输出,类似于下面的内容:
app-engine-python 1.9.91
bq 2.0.62
cloud-datastore-emulator 2.1.0
core 2020.11.13
gsutil 4.55
您的版本号可能会不同,但是只要在您的计算机上成功找到了gcloud程序,您的安装就成功了。
有了这个概念的高级概述和 Google Cloud SDK 的安装,您就可以设置一个 Python 项目,稍后您将把它部署到互联网上。
构建一个基本的 Python Web 应用程序
Google App Engine 要求您使用 web 框架在 Python 3 环境中创建 web 应用程序。由于您试图使用最小的设置将您的本地 Python 代码放到互联网上,所以像 Flask 这样的微框架是一个不错的选择。Flask 的最小实现是如此之小,以至于您可能甚至没有注意到您正在使用一个 web 框架。
**注意:**如果你以前在 Python 2.7 环境下使用过 Google App Engine,那么你会注意到这个过程已经发生了显著的变化。
两个值得注意的变化是 webapp2 已经退役,你不再能够在app.yaml文件中指定动态内容的 URL。这两个变化的原因是 Google App Engine 现在要求您使用 Python web 框架。
您将要创建的应用程序将依赖于几个不同的文件,因此您需要做的第一件事是创建一个项目文件夹来保存所有这些文件。
设置您的项目
创建一个项目文件夹,并给它一个描述您的项目的名称。对于本练习项目,调用文件夹hello-app。这个文件夹中需要三个文件:
main.py包含你的 Python 代码,包装在 Flask web 框架的最小实现中。requirements.txt列出了代码正常工作所需的所有依赖关系。app.yaml帮助谷歌应用引擎决定在其服务器上使用哪些设置。
虽然三个文件听起来很多,但是您会看到这个项目在所有三个文件中使用了不到十行代码。这代表了您需要为任何可能启动的 Python 项目提供给 Google App Engine 的最小设置。剩下的就是你自己的 Python 代码了。您可以通过单击下面的链接下载将在本教程中使用的完整源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用了解如何使用 Flask 创建 Python web 应用程序。
接下来,您将查看每个文件的内容,从最复杂的文件main.py开始。
创建main.py
是 Flask 用来传递内容的文件。在文件的顶部,您在第 1 行导入了Flask类,然后您在第 3 行创建了一个 Flask 应用程序的实例:
1from flask import Flask
2
3app = Flask(__name__)
4
5@app.route("/")
6def index():
7 return "Congratulations, it's a web app!"
创建 Flask app后,在第 5 行编写一个名为@app.route的 Python 装饰器,Flask 用它来连接函数中包含的代码的 URL 端点。@app.route的参数定义了 URL 的路径组件,在本例中是根路径("/")。
第 6 行和第 7 行的代码组成了index(),由装饰器包装。该函数定义了当用户请求已定义的 URL 端点时应该执行的操作。它的返回值决定了用户加载页面时会看到什么。
注:index()的命名只是约定俗成。它关系到一个网站的主页面通常怎么叫index.html。如果需要,您可以选择不同的函数名。
换句话说,如果用户在他们的浏览器中输入你的 web 应用的基本 URL,那么 Flask 运行index()并且用户看到返回的文本。在这种情况下,该文本只是一句话:Congratulations, it's a web app!
您可以呈现更复杂的内容,也可以创建多个函数,以便用户可以访问应用程序中的不同 URL 端点来接收不同的响应。然而,对于这个初始实现,坚持使用这个简短且令人鼓舞的成功消息是很好的。
创建requirements.txt
下一个要看的文件是requirements.txt。因为 Flask 是这个项目唯一的依赖项,所以您只需要指定:
Flask==2.1.2
如果您的应用程序有其他依赖项,那么您也需要将它们添加到您的requirements.txt文件中。
在服务器上设置项目时,Google App Engine 将使用requirements.txt为项目安装必要的 Python 依赖项。这类似于在本地创建并激活一个新的虚拟环境之后你会做的事情。
创建app.yaml
第三个文件app.yaml,帮助 Google App Engine 为您的代码建立正确的服务器环境。这个文件只需要一行代码,它定义了 Python 运行时:
runtime: python38
上面显示的行阐明了 Python 代码的正确运行时是 Python 3.8。这足以让 Google App Engine 在其服务器上进行必要的设置。
**注意:**确保您想要使用的 Python 3 运行时环境在 Google App Engine 上可用。
您可以使用 Google App Engine 的app.yaml文件进行额外的设置,例如向您的应用程序添加环境变量。您还可以使用它来定义应用程序静态内容的路径,如图像、CSS 或 JavaScript 文件。本教程不会深入这些额外的设置,但是如果你想添加这样的功能,你可以参考 Google App Engine 关于 app.yaml配置文件的文档。
这九行代码完成了这个应用程序的必要设置。您的项目现在可以部署了。
然而,在将代码投入生产之前对其进行测试是一个很好的做法,这样可以捕捉到潜在的错误。接下来,在将代码部署到互联网之前,您将检查本地的一切是否如预期的那样工作。
本地测试
Flask 附带了一个开发 web 服务器。您可以使用这个开发服务器来复查您的代码是否按预期工作。为了能够在本地运行 Flask development server,您需要完成两个步骤。一旦您部署了代码,Google App Engine 将在其服务器上执行相同的步骤:
- 建立一个虚拟环境。
- 安装
flask包。
为了设置 Python 3 虚拟环境,在终端上导航到您的项目文件夹,并键入以下命令:
$ python3 -m venv venv
这将使用您系统上安装的 Python 3 版本创建一个名为venv的新虚拟环境。接下来,您需要通过获取激活脚本来激活虚拟环境:
$ source venv/bin/activate
执行该命令后,您的提示符将会改变,表明您现在正在虚拟环境中操作。成功设置并激活虚拟环境后,就可以安装 Flask 了:
$ python3 -m pip install -r requirements.txt
这个命令从 PyPI 获取requirements.txt中列出的所有包,并将它们安装到您的虚拟环境中。在这种情况下,唯一安装的包将是 Flask。
等待安装完成,然后打开main.py并在文件底部添加以下两行代码:
if __name__ == "__main__":
app.run(host="127.0.0.1", port=8080, debug=True)
这两行告诉 Python 在从命令行执行脚本时启动 Flask 的开发服务器。只有在本地运行脚本时才会用到它。当您将代码部署到 Google App Engine 时,一个专业的 web 服务器进程,如 Gunicorn ,将会为应用程序提供服务。你不需要做任何改变来实现这一点。
现在,您可以启动 Flask 的开发服务器,并在浏览器中与 Python 应用程序进行交互。为此,您需要通过键入以下命令来运行启动 Flask 应用程序的 Python 脚本:
$ python3 main.py
Flask 启动开发服务器,您的终端将显示如下所示的输出:
* Serving Flask app "main" (lazy loading)
* Environment: production
WARNING: This is a development server.
Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://127.0.0.1:8080/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 315-059-987
这个输出告诉您三条重要的信息:
-
WARNING: 这是 Flask 的开发服务器,也就是说你不想用它来为你的代码在生产中服务。谷歌应用引擎将为你处理。 -
Running on http://127.0.0.1:8080/: 这是你可以找到你的应用的网址。这是你的本地主机的网址,这意味着应用程序正在你自己的电脑上运行。在浏览器中导航到该 URL 以实时查看您的代码。 -
Press CTRL+C to quit: 同一行还告诉你,按键盘上的Ctrl+C可以退出开发服务器。
按照说明,在http://127.0.0.1:8080/打开一个浏览器标签。您应该看到一个页面,显示您的函数返回的文本:Congratulations, it's a web app!
注意:URL127.0.0.1也叫 localhost ,意思是指向自己的电脑。冒号(:)后面的数字8080称为端口号。该端口可以被认为是一个特定的频道,类似于广播电视或无线电频道。
您已经在main.py文件的app.run()中定义了这些值。在端口8080上运行应用程序意味着您可以监听这个端口号,并接收来自开发服务器的通信。端口8080通常用于本地测试,但是您也可以使用不同的号码。
您可以使用 Flask 的开发服务器来检查您对 Python 应用程序代码所做的任何更改。服务器监听您在代码中所做的更改,并将自动重新加载以显示它们。如果您的应用程序在开发服务器上不能像您期望的那样呈现,那么它也不能在生产中工作。因此,在部署它之前,请确保它看起来不错。
还要记住,即使它在本地工作得很好,部署后也可能不一样。这是因为当您将代码部署到 Google App Engine 时,还涉及到其他因素。然而,对于一个基本的应用程序,比如你在本教程中构建的应用程序,如果它在本地运行良好,你可以确信它可以在生产中运行。
更改index()的返回值,并确认您可以看到浏览器中反映的更改。玩弄它。当你把index()的返回值改为 HTML 代码,比如<h1>Hello</h1>,而不是使用纯文本字符串,会发生什么?
在本地开发服务器上检查了您的设置和代码的功能之后,您就可以将它部署到 Google App Engine 了。
部署您的 Python Web 应用程序
终于到了让你的应用上线的时候了。但是首先,你的代码需要在谷歌的服务器上有一个位置,你需要确保它安全到达那里。在本节教程中,您将在云中和本地完成必要的部署设置。
在谷歌应用引擎上设置
一步一步地阅读下面的设置过程。您可以将您在浏览器中看到的内容与截图进行比较。示例截图中使用的项目名称是hello-app。
首先登录谷歌云平台。导航到仪表板视图,您会在窗口顶部看到一个工具栏。选择工具栏左侧的向下箭头按钮。这将弹出一个包含 Google 项目列表的模式:
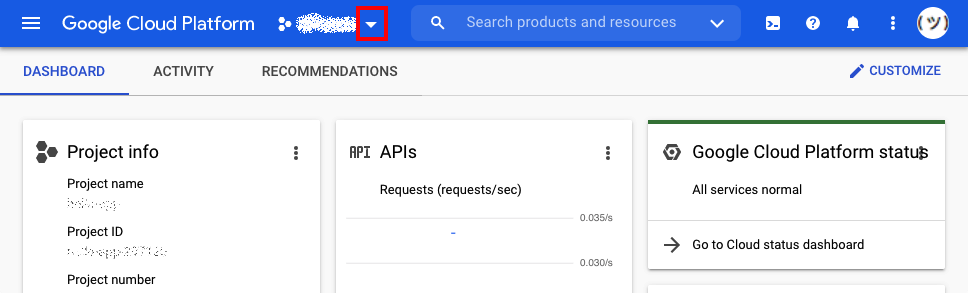
该模式显示您的项目列表。如果您尚未创建任何项目,该列表可能为空。在该模式的右上角,找到新项目按钮并点击它:

点击新项目会将你重定向到一个新页面,在这里你可以为你的项目选择一个名字。这个名称将出现在您的应用程序的 URL 中,看起来类似于http://your-application-name.nw.r.appspot.com。使用hello-app作为这个项目的名称,以与教程保持一致:
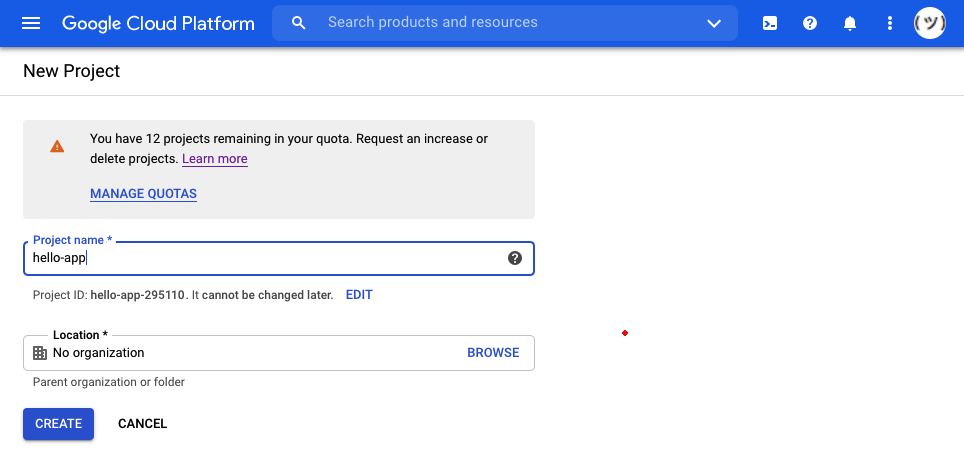
您可以在项目名称输入框下看到您的项目 ID。项目 ID 由您输入的名称和 Google App Engine 添加的数字组成。在本教程的例子中,您可以看到项目 ID 是hello-app-295110。复制您的个人项目 ID,因为您将在以后的部署中需要它。
**注意:**由于项目 ID 需要是唯一的,您的编号将与本教程中显示的不同。
你现在可以点击创建并等待项目在 Google App Engine 端建立。完成后,会弹出一个通知,告诉你一个新项目已经创建。它还为您提供了选择它的选项。点击选择项目继续操作:

点击选择项目会将你重定向到新的谷歌云平台项目的主页。看起来是这样的:
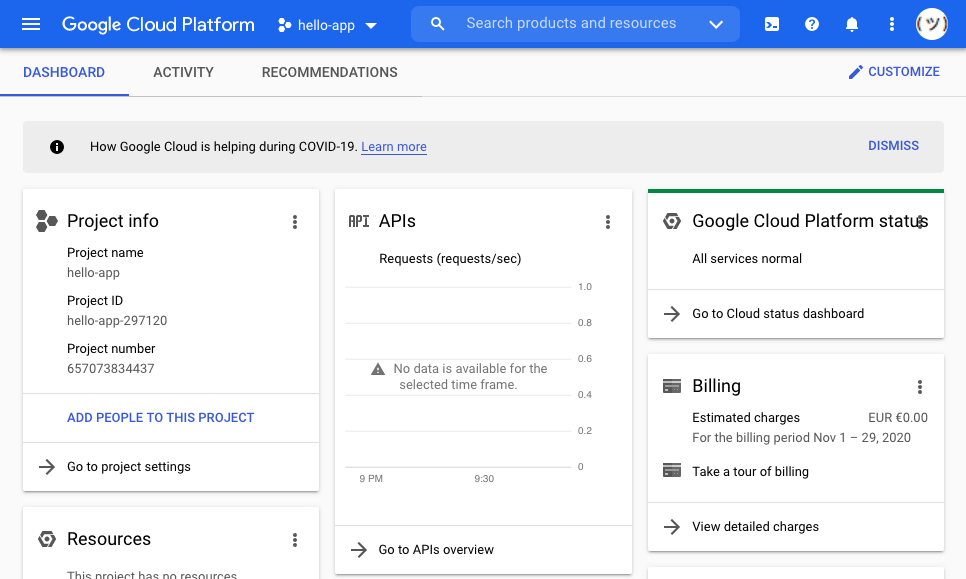
从这里,你想切换到谷歌应用引擎的仪表板。你可以点击左上角的汉堡菜单,向下滚动选择第一个列表中的应用引擎,然后选择下一个弹出列表顶部的仪表盘:
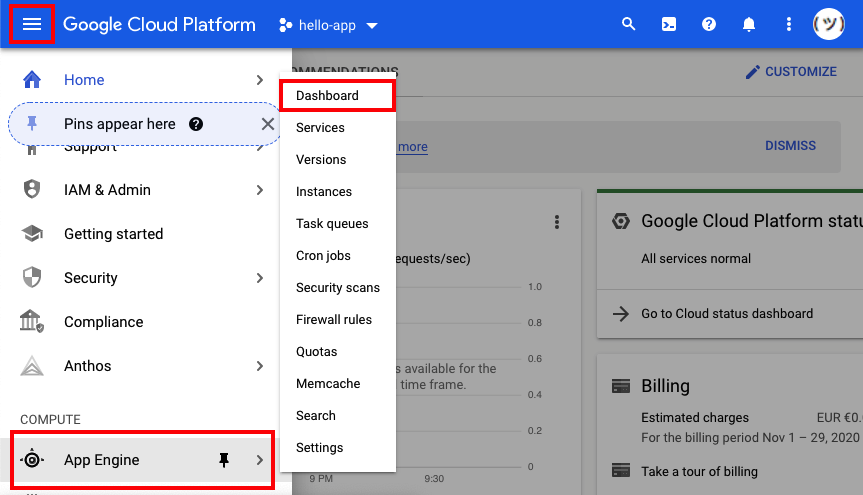
这将最终把您重定向到新项目的 Google App Engine 仪表板视图。由于该项目到目前为止是空的,因此该页面将类似于以下内容:
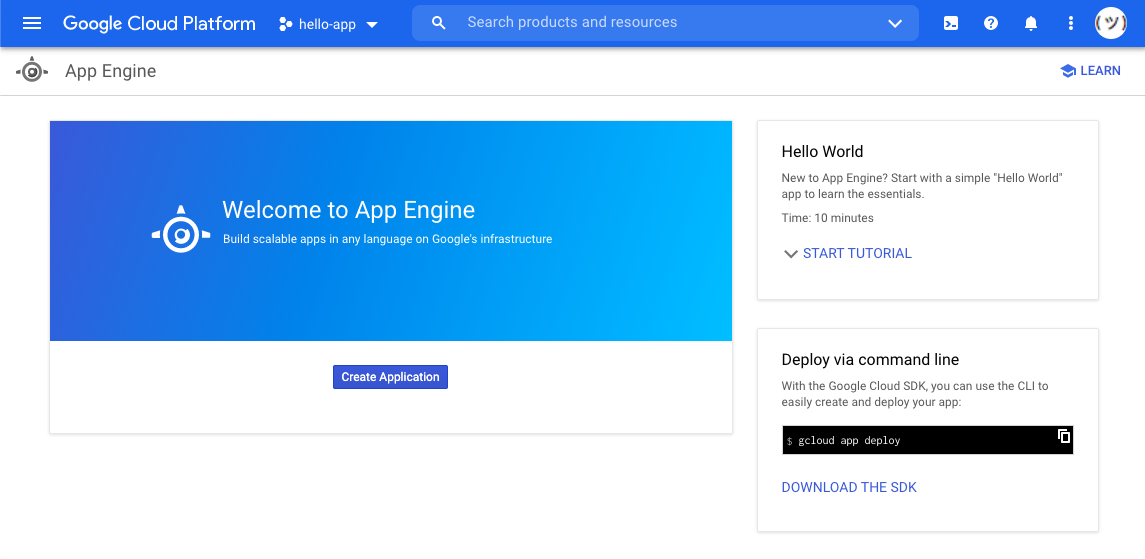
当您看到此页面时,意味着您已经完成了在 Google App Engine 上设置一个新项目。现在,您已经准备好返回到您计算机上的终端,并完成将您的应用程序部署到该项目所需的本地步骤。
为部署在本地设置
在成功地安装了谷歌云 SDK 之后,你就可以访问gcloud命令行界面了。该程序附带了指导您部署 web 应用程序的有用说明。首先键入在 Google App Engine 网站上创建新项目时建议您使用的命令:
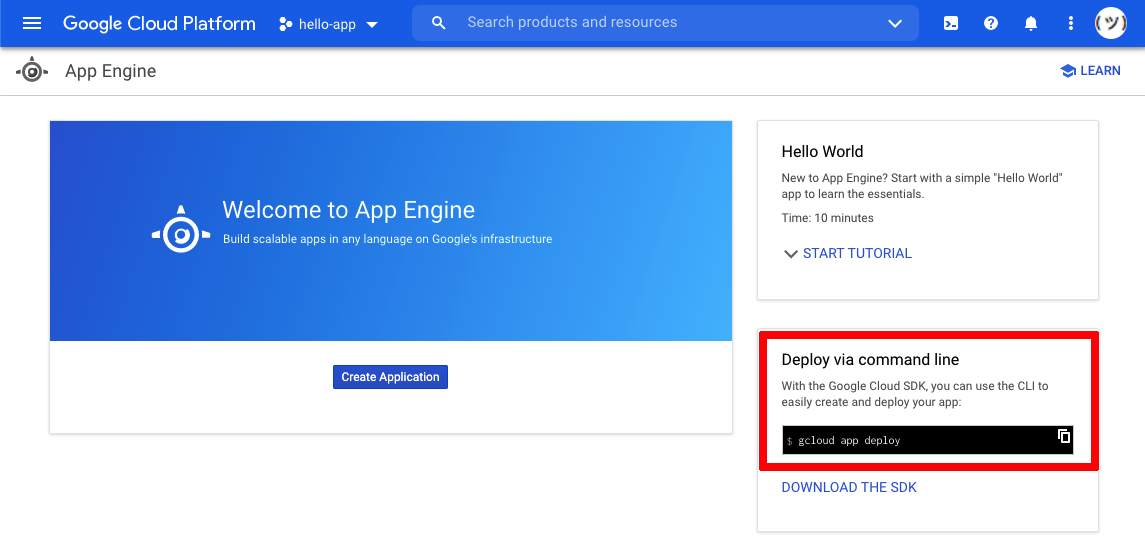
正如您在页面右下角看到的,Google App Engine 建议使用一个终端命令将您的代码部署到这个项目中。打开您的终端,导航到您的项目文件夹,然后运行建议的命令:
$ gcloud app deploy
当您在没有任何预先设置的情况下执行此命令时,程序将响应一条错误消息:
ERROR: (gcloud.app.deploy)
You do not currently have an active account selected.
Please run:
$ gcloud auth login
to obtain new credentials.
If you have already logged in with a different account:
$ gcloud config set account ACCOUNT
to select an already authenticated account to use.
您收到此错误消息是因为您无法将任何代码部署到您的 Google App Engine 帐户,除非您向 Google 证明您是该帐户的所有者。您需要从本地计算机使用您的 Google App Engine 帐户进行身份验证。
gcloud命令行应用程序已经为您提供了您需要运行的命令。将它键入您的终端:
$ gcloud auth login
这将通过生成一个验证 URL 并在浏览器中打开它来启动身份验证过程。通过在浏览器窗口中选择您的 Google 帐户并授予 Google Cloud SDK 必要的权限来完成该过程。完成此操作后,您可以返回到您的终端,在这里您会看到一些关于认证过程的信息:
Your browser has been opened to visit:
https://accounts.google.com/o/oauth2/auth?client_id=<yourid>
You are now logged in as [<your@email.com>].
Your current project is [None]. You can change this setting by running:
$ gcloud config set project PROJECT_ID
如果您看到此消息,则身份验证成功。您还可以看到,命令行程序再次为您提供了关于下一步的有用信息。
它告诉您当前没有项目集,您可以通过运行gcloud config set project PROJECT_ID来设置一个。现在您将需要您之前记录的项目 ID。
**注意:**您可以随时通过访问 Google App Engine 网站,点击向下箭头,调出显示您所有 Google 项目的模式,从而获得您的项目 ID。项目标识列在项目名称的右侧,通常由项目名称和一个六位数组成。
在运行建议的命令时,确保用您自己的项目 ID 替换hello-app-295110:
$ gcloud config set project hello-app-295110
您的终端将打印出一条简短的反馈消息,表明项目属性已经更新。在成功地验证和设置默认项目为您的项目 ID 之后,您已经完成了必要的设置步骤。
运行部署流程
现在,您已经准备好再次尝试初始部署命令:
$ gcloud app deploy
gcloud应用程序从您刚刚设置的默认配置中获取您的认证凭证和项目 ID 信息,并允许您继续。接下来,您需要选择一个区域来托管您的应用程序:
You are creating an app for project [hello-app-295110].
WARNING: Creating an App Engine application for a project is
irreversible and the region cannot be changed.
More information about regions is at
<https://cloud.google.com/appengine/docs/locations>.
Please choose the region where you want your App Engine application
located:
[1] asia-east2
[2] asia-northeast1
[3] asia-northeast2
[4] asia-northeast3
[5] asia-south1
[6] asia-southeast2
[7] australia-southeast1
[8] europe-west
[9] europe-west2
[10] europe-west3
[11] europe-west6
[12] northamerica-northeast1
[13] southamerica-east1
[14] us-central
[15] us-east1
[16] us-east4
[17] us-west2
[18] us-west3
[19] us-west4
[20] cancel
Please enter your numeric choice:
输入左侧列出的数字之一,然后按下 Enter 。
**注意:**你选择哪个地区的这个 app 并不重要。但是,如果您正在构建一个流量很大的大型应用程序,那么您会希望将它部署到一个在物理上靠近大多数用户所在位置的服务器上。
输入一个数字后,CLI 将继续设置过程。在将您的代码部署到 Google App Engine 之前,它会向您展示部署的概况,并要求您进行最终确认:
Creating App Engine application in project [hello-app-295110]
and region [europe-west]....done.
Services to deploy:
descriptor: [/Users/realpython/Documents/helloapp/app.yaml]
source: [/Users/realpython/Documents/helloapp]
target project: [hello-app-295110]
target service: [default]
target version: [20201109t112408]
target url: [https://hello-app-295110.ew.r.appspot.com]
Do you want to continue (Y/n)?
在您通过键入 Y 确认设置之后,您的部署将最终上路。当 Google App Engine 在其服务器上设置您的项目时,您的终端将向您显示更多信息和一个小的加载动画:
Beginning deployment of service [default]...
Created .gcloudignore file. See `gcloud topic gcloudignore` for details.
╔════════════════════════════════════════════════════════════╗
╠═ Uploading 3 files to Google Cloud Storage ═╣
╚════════════════════════════════════════════════════════════╝
File upload done.
Updating service [default]...⠼
由于这是首次部署您的 web 应用程序,因此可能需要几分钟才能完成。部署完成后,您将在控制台中看到另一个有用的输出。它看起来与下面的类似:
Deployed service [default] to [https://hello-app-295110.ew.r.appspot.com]
You can stream logs from the command line by running:
$ gcloud app logs tail -s default
To view your application in the web browser run:
$ gcloud app browse
现在,您可以在浏览器中导航到提到的 URL,或者键入建议的命令gcloud app browse来访问您的 live web 应用程序。您应该会看到与之前在本地主机上运行应用程序时看到的相同的简短文本响应:Congratulations, it's a web app!
请注意,此网站有一个您可以与其他人共享的 URL,他们将能够访问它。您现在拥有了一个真实的 Python web 应用程序!
再次更改index()的返回值,并使用gcloud app deploy命令第二次部署您的应用。确认您可以在浏览器中看到实时网站上反映的更改。
至此,您已经完成了将本地 Python 代码发布到 web 上的必要步骤。然而,到目前为止你放在网上的唯一功能是打印出一串文本。
是时候加快步伐了!按照同样的过程,您将在下一节中带来更多有趣的在线功能。您将把本地温度转换器脚本的代码重构到 Flask web 应用程序中。
将脚本转换成网络应用程序
由于本教程是关于从您已有的代码创建和部署 Python web 应用程序,因此在此为您提供了温度转换器脚本的 Python 代码:
def fahrenheit_from(celsius):
"""Convert Celsius to Fahrenheit degrees."""
try:
fahrenheit = float(celsius) * 9 / 5 + 32
fahrenheit = round(fahrenheit, 3) # Round to three decimal places
return str(fahrenheit)
except ValueError:
return "invalid input"
if __name__ == "__main__":
celsius = input("Celsius: ")
print("Fahrenheit:", fahrenheit_from(celsius))
这是一个简短的脚本,允许用户将摄氏温度转换为等效的华氏温度。
将代码保存为 Python 脚本,并尝试一下。确保它按预期工作,并且您了解它的功能。请随意改进代码。
有了这个工作脚本,现在需要修改代码,将其集成到 Flask 应用程序中。这样做有两个要点需要考虑:
- **执行:**web app 怎么知道什么时候运行代码?
- **用户输入:**web app 将如何收集用户输入?
您已经学习了如何通过将代码添加到分配了路由的函数中来告诉 Flask 执行特定的代码。首先从解决这项任务开始。
添加代码作为功能
Flask 将不同的任务分成不同的函数,每个函数通过@app.route装饰器被分配一条路径。当用户通过 URL 访问指定的路径时,相应函数中的代码就会被执行。
首先将fahrenheit_from()添加到main.py文件中,并用@app.route装饰器包装它:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def index():
return "Congratulations, it's a web app!"
@app.route("/") def fahrenheit_from(celsius):
"""Convert Celsius to Fahrenheit degrees."""
try:
fahrenheit = float(celsius) * 9 / 5 + 32
fahrenheit = round(fahrenheit, 3) # Round to three decimal places
return str(fahrenheit)
except ValueError:
return "invalid input"
if __name__ == "__main__":
app.run(host="127.0.0.1", port=8080, debug=True)
到目前为止,您只将 Python 脚本的代码复制到 Flask 应用程序的一个函数中,并添加了@app.route装饰器。
然而,这个设置已经有一个问题了。当您在开发服务器中运行代码时会发生什么?试试看。
目前,您的两个功能都由同一条路径触发("/")。当用户访问该路径时,Flask 选择第一个与之匹配的函数并执行该代码。在您的例子中,这意味着fahrenheit_from()永远不会被执行,因为index()匹配相同的路由并首先被调用。
您的第二个功能将需要其自己的唯一路径才能访问。此外,您仍然需要允许您的用户为您的功能提供输入。
将值传递给代码
您可以通过告诉 Flask 将基本 URL 之后的 URL 的任何剩余部分视为一个值并将其传递给函数来解决这两个任务。这只需要在fahrenheit_from()之前对@app.route装饰器的参数做一个小的改变:
@app.route("/<celsius>") def fahrenheit_from(celsius):
# -- snip --
尖括号语法(<>)告诉 Flask 捕捉基本 URL ( "/")后面的任何文本,并将其传递给装饰器包装为变量celsius的函数。注意fahrenheit_from()需要celsius作为输入。
**注意:**确保您捕获的 URL 路径组件与您传递给函数的参数同名。否则,Flask 会感到困惑,并通过向您显示一条错误消息来让您知道这一点。
回到您的 web 浏览器,使用 Flask 的开发服务器尝试新功能。现在,您可以使用不同的 URL 端点通过 web 应用程序访问这两项功能:
- 索引(
/): 如果你去基础网址,那么你会看到之前的鼓励短信。 - 摄氏度(
/42): 如果你在正斜杠后添加一个数字,那么你会看到转换后的温度出现在你的浏览器中。
更多地使用它,尝试输入不同的输入。即使您的脚本中的错误处理仍然有效,并在用户输入非数字输入时显示一条消息。您的 web 应用程序处理的功能与 Python 脚本在本地处理的功能相同,只是现在您可以将其部署到互联网上。
重构你的代码
Flask 是一个成熟的 web 框架,允许你把很多任务交给它的内部。例如,你可以让 Flask 负责类型检查你的函数的输入,如果不合适就返回一个错误消息。所有这些都可以通过@app.route的参数中的简洁语法来完成。将以下内容添加到路径捕获器中:
@app.route("/<int:celsius>")
在变量名前添加int:告诉 Flask 检查它从 URL 接收的输入是否可以转换成整数。如果可以,则将内容传递给fahrenheit_from()。如果不能,那么 Flask 会显示一个Not Found错误页面。
注意:Not Found错误意味着 Flask 试图将它从 URL 中截取的路径组件与它知道的任何函数进行匹配。
然而,它目前知道的唯一模式是空的基本路径(/)和后跟数字的基本路径,例如/42。由于像/hello这样的文本不匹配这些模式,它会告诉你在服务器上没有找到请求的 URL。
在应用 Flask 的类型检查后,您现在可以安全地移除fahrenheit_from()中的try … except块。Flask 只会将整数传递给函数:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def index():
return "Congratulations, it's a web app!"
@app.route("/<int:celsius>")
def fahrenheit_from(celsius):
"""Convert Celsius to Fahrenheit degrees."""
fahrenheit = float(celsius) * 9 / 5 + 32
fahrenheit = round(fahrenheit, 3) # Round to three decimal places
return str(fahrenheit)
if __name__ == "__main__":
app.run(host="127.0.0.1", port=8080, debug=True)
至此,您已经完成了将温度转换脚本转换为 web 应用程序的工作。确认本地一切正常,然后将您的应用再次部署到 Google App Engine。
重构index()。它应该返回解释如何使用温度转换器 web 应用程序的文本。请记住,您可以在返回字符串中使用 HTML 标记。HTML 将在您的登录页面上正确呈现。
在成功地将您的温度转换 web 应用程序部署到互联网后,您现在就有了一个链接,可以与其他人共享,并允许他们将摄氏温度转换为华氏温度。
然而,界面看起来仍然很基本,web 应用程序的功能更像是一个 API 而不是前端 web 应用程序。许多用户可能不知道如何在当前状态下与 Python web 应用程序进行交互。这向您展示了使用纯 Python 进行 web 开发的局限性。
如果你想创建更直观的界面,那么你至少需要开始使用一点 HTML。
在下一节中,您将继续迭代您的代码,并使用 HTML 创建一个输入框,它允许用户直接在页面上输入一个数字,而不是通过 URL。
改进您的网络应用程序的用户界面
在这一节中,您将学习如何向您的 web 应用程序添加 HTML <form> input 元素,以允许用户以他们习惯于从其他在线应用程序使用的直接方式与之交互。
为了改善 web 应用程序的用户界面和用户体验,您需要使用 Python 以外的语言,即前端语言,如 HTML、CSS 和 JavaScript。本教程尽可能避免深入讨论这些内容,而是专注于 Python 的使用。
然而,如果你想在你的网络应用中添加一个输入框,那么你需要使用一些 HTML。您将只实现绝对最小化,以使您的 web 应用程序看起来和感觉上更像用户熟悉的网站。您将使用 HTML <form>元素来收集他们的输入。
**注:**如果你想了解更多关于 HTML 的知识,那就去看看 Real Python 的面向 Python 开发者的 HTML 和 CSS或者 MDN 的HTML 简介。
更新您的 web 应用程序后,您将有一个文本字段,用户可以在其中输入以摄氏度为单位的温度。将会有一个转换按钮将用户提供的摄氏温度转换为华氏温度:
https://player.vimeo.com/video/492638932?background=1
转换后的结果将显示在下一行,并在用户点击转换时更新。
您还将更改应用程序的功能,以便表单和转换结果显示在同一页面上。您将重构代码,这样您只需要一个 URL 端点。
收集用户输入
首先在您的登录页面上创建一个<form>元素。将以下几行 HTML 复制到index()的返回语句中,替换之前的文本消息:
@app.route("/")
def index():
return """<form action="" method="get">
<input type="text" name="celsius">
<input type="submit" value="Convert">
</form>"""
当您在基本 URL 重新加载页面时,您会看到一个输入框和一个按钮。HTML 会正确呈现。恭喜,您刚刚创建了一个输入表单!
注意:请记住,这几行 HTML 代码本身并不构成一个有效的 HTML 页面。然而,现代浏览器被设计成可以填补空白并为你创建缺失的结构。
当你输入一个值然后点击转换会发生什么?虽然页面看起来一样,但您可能会注意到 URL 发生了变化。它现在显示一个查询参数,在基本 URL 后面有一个值。
例如,如果您在文本框中输入42并点击按钮,那么您的 URL 将如下所示:http://127.0.0.1:8080/?celsius=42。这是好消息!该值被成功记录并作为查询参数添加到 HTTP GET 请求中。看到这个 URL 意味着您再次请求基本 URL,但是这一次您发送了一些额外的值。
然而,这个额外的值目前没有任何作用。虽然表单已经设置好了,但是它还没有正确地连接到 Python web 应用程序的代码功能。
为了理解如何建立这种联系,您将阅读<form>元素的每一部分,看看不同的部分是关于什么的。您将分别查看以下三个元素及其属性:
<form>元素- 输入箱
- 提交按钮
每一个都是独立的 HTML 元素。虽然本教程旨在将重点放在 Python 而不是 HTML 上,但是对这段 HTML 代码有一个基本的了解仍然是有帮助的。从最外层的 HTML 元素开始。
<form>元素
元素创建了一个 HTML 表单。另外两个<input>元素被包装在里面:
<form action="" method="get">
<input type="text" name="celsius" />
<input type="submit" value="Convert" />
</form>
<form>元素还包含两个 HTML 属性,称为action和method:
-
action决定用户提交的数据将被发送到哪里。您在这里将值保留为空字符串,这使得您的浏览器将请求定向到调用它的同一个 URL。在您的情况下,这是空的基本 URL。 -
method定义了表单产生什么类型的 HTTP 请求。使用默认的"get"创建一个 HTTP GET 请求。这意味着用户提交的数据将在 URL 查询参数中可见。如果您提交敏感数据或与数据库通信,那么您需要使用 HTTP POST 请求。
检查完<form>元素及其属性后,下一步是仔细查看两个<input>元素中的第一个。
输入框
第二个 HTML 元素是嵌套在<form>元素中的<input>元素:
<form action="" method="get">
<input type="text" name="celsius" /> <input type="submit" value="Convert" />
</form>
第一个<input>元素有两个 HTML 属性:
-
type定义了应该创建什么类型的<input>元素。有很多可供选择,比如复选框和下拉元素。在这种情况下,您希望用户输入一个数字作为文本,所以您将类型设置为"text"。 -
name定义用户输入的值将被称为什么。你可以把它想象成一个字典的键,其中的值是用户在文本框中输入的任何内容。您看到这个名称作为查询参数的键出现在 URL 中。稍后您将需要这个键来检索用户提交的值。
HTML <input>元素可以有不同的形状,其中一些需要不同的属性。当查看第二个<input>元素时,您会看到一个这样的例子,它创建了一个提交按钮,并且是组成代码片段的最后一个 HTML 元素。
提交按钮
第二个<input>元素创建了允许用户提交输入的按钮:
<form action="" method="get">
<input type="text" name="celsius" />
<input type="submit" value="Convert" /> </form>
这个元素还有两个 HTML 属性,分别命名为type和value:
-
type定义了将创建什么样的输入元素。使用值"submit"创建一个按钮,允许您向前发送捆绑的表单数据。 -
value定义按钮应该显示什么文本。您可以随意更改它,看看按钮如何显示您更改的文本。
通过对不同 HTML 元素及其属性的简短概述,您现在对添加到 Python 代码中的内容以及这些元素的用途有了更好的理解。
将表单提交连接到 Flask 代码所需的信息是第一个<input>元素的name值celsius,您将使用它来访问函数中提交的值。
接下来,您将学习如何更改 Python 代码来正确处理提交的表单输入。
接收用户输入
在您的<form>元素的action属性中,您指定了 HTML 表单的数据应该被发送回它来自的同一个 URL。现在您需要包含在index()中获取值的功能。为此,您需要完成两个步骤:
-
**导入 Flask 的
request对象:**像许多 web 框架一样,Flask 将 HTTP 请求作为全局对象传递。为了能够使用这个全局request对象,您首先需要导入它。 -
获取值:
request对象包含提交的值,并允许您通过 Python 字典语法访问它。您需要从全局对象中获取它,以便能够在函数中使用它。
现在重写您的代码并添加这两个更改。您还需要将捕获的值添加到表单字符串的末尾,以显示在表单之后:
from flask import Flask
from flask import request
app = Flask(__name__)
@app.route("/")
def index():
celsius = request.args.get("celsius", "") return (
"""<form action="" method="get">
<input type="text" name="celsius">
<input type="submit" value="Convert">
</form>"""
+ celsius )
@app.route("/<int:celsius>")
def fahrenheit_from(celsius):
"""Convert Celsius to Fahrenheit degrees."""
fahrenheit = float(celsius) * 9 / 5 + 32
fahrenheit = round(fahrenheit, 3) # Round to three decimal places
return str(fahrenheit)
if __name__ == "__main__":
app.run(host="127.0.0.1", port=8080, debug=True)
request.args字典包含通过 HTTP GET 请求提交的任何数据。如果您的基本 URL 最初被调用,没有表单提交,那么字典将是空的,您将返回一个空字符串作为默认值。如果页面通过提交表单被调用,那么字典将在celsius键下包含一个值,您可以成功地获取它并将其添加到返回的字符串中。
旋转一下!现在,您可以输入一个数字,并看到它显示在表单按钮的正下方。如果你输入一个新的号码,那么旧的会被替换。您可以正确地发送和接收用户提交的数据。
在您继续将提交的值与您的温度转换器代码集成之前,您能想到这个实现有什么潜在的问题吗?
当你输入一个字符串而不是一个数字时会发生什么?试试看。
现在输入简短的 HTML 代码<marquee>BUY USELESS THINGS!!!</marquee>并按下转换。
目前,你的网络应用程序接受任何类型的输入,无论是一个数字,一个字符串,甚至是 HTML 或 JavaScript 代码。这是非常危险的,因为用户可能会通过输入特定类型的内容,无意或有意地破坏您的 web 应用程序。
大多数情况下,您应该允许 Flask 通过使用不同的项目设置来自动处理这些安全问题。但是,您现在就处于这种情况下,所以了解如何手动使您创建的表单输入安全是一个好主意。
转义用户输入
接受用户的输入并在没有首先调查你将要显示什么的情况下显示该输入是一个巨大的安全漏洞。即使没有恶意,您的用户也可能会做一些意想不到的事情,导致您的应用程序崩溃。
尝试通过添加一些 HTML 文本来破解未转义的输入表单。不要输入数字,复制下面一行 HTML 代码,将其粘贴到您的输入框中,然后单击 Convert :
<marquee><a href="https://www.realpython.com">CLICK ME</a></marquee>
Flask 将文本直接插入到 HTML 代码中,这会导致文本输入被解释为 HTML 标记。因此,您的浏览器会忠实地呈现代码,就像处理任何其他 HTML 一样。你突然不得不处理一个时髦的教育垃圾链接,而不是以文本的形式显示输入,这个链接是从 90 年代穿越到现在的:
https://player.vimeo.com/video/492638327?background=1
虽然这个例子是无害的,并且不需要刷新页面,但是您可以想象当以这种方式添加其他类型的内容时,这会带来怎样的安全问题。你不想让你的用户编辑你的 web 应用程序中不应该被编辑的部分。
为了避免这种情况,您可以使用 Flask 内置的 escape() ,它将特殊的 HTML 字符<、>和&转换成可以正确显示的等价表示。
您首先需要将escape导入到您的 Python 脚本中来使用这个功能。然后,当您提交表单时,您可以转换任何特殊的 HTML 字符,并使您的表单输入防 90 年代黑客攻击:
from flask import Flask
from flask import request, escape
app = Flask(__name__)
@app.route("/")
def index():
celsius = str(escape(request.args.get("celsius", ""))) return (
"""<form action="" method="get">
<input type="text" name="celsius">
<input type="submit" value="Convert">
</form>"""
+ celsius
)
@app.route("/<int:celsius>")
def fahrenheit_from(celsius):
"""Convert Celsius to Fahrenheit degrees."""
fahrenheit = float(celsius) * 9 / 5 + 32
fahrenheit = round(fahrenheit, 3) # Round to three decimal places
return str(fahrenheit)
if __name__ == "__main__":
app.run(host="127.0.0.1", port=8080, debug=True)
刷新您的开发服务器并尝试提交一些 HTML 代码。现在它将作为您输入的文本字符串显示给您。
**注意:**需要将转义序列转换回 Python str。否则,Flask 也会贪婪地将函数返回的<form>元素转换成转义字符串。
当构建更大的 web 应用程序时,你不必处理输入的转义,因为所有的 HTML 都将使用模板来处理。如果你想了解更多,那么看看烧瓶的例子。
在学习了如何收集用户输入以及如何对其进行转义之后,您终于准备好实现温度转换功能,并向用户显示他们输入的摄氏温度的华氏等效温度。
处理用户输入
因为这种方法只使用一个 URL 端点,所以您不能像前面那样依靠 Flask 通过 URL 路径组件捕获来检查用户输入。这意味着你需要从原始代码的初始fahrenheit_from()重新引入你的try … except块。
**注意:**因为你在fahrenheit_from()中验证用户输入的类型,你不需要实现flask.escape(),它也不会是你最终代码的一部分。您可以安全地移除escape的导入,并将对request.args.get()的调用剥离回初始状态。
这一次,fahrenheit_from()将不会与一个@app.route装饰者相关联。继续删除那行代码。当访问特定的 URL 端点时,您将从index()显式调用fahrenheit_from(),而不是让 Flask 执行它。
在从fahrenheit_from()中删除装饰器并重新引入try … except块之后,接下来您将添加一个条件语句到index(),检查全局request对象是否包含一个celsius键。如果是,那么你要调用fahrenheit_from()来计算相应的华氏温度。如果没有,那么您将一个空字符串赋给fahrenheit变量。
这样做允许您将fahrenheit的值添加到 HTML 字符串的末尾。空字符串在您的页面上是不可见的,但是如果用户提交了一个值,它就会显示在表单下面。
应用这些最终更改后,您完成了温度转换器烧瓶应用程序的代码:
1from flask import Flask
2from flask import request 3
4app = Flask(__name__)
5
6@app.route("/")
7def index():
8 celsius = request.args.get("celsius", "") 9 if celsius: 10 fahrenheit = fahrenheit_from(celsius) 11 else: 12 fahrenheit = "" 13 return (
14 """<form action="" method="get">
15 Celsius temperature: <input type="text" name="celsius"> 16 <input type="submit" value="Convert to Fahrenheit">
17 </form>"""
18 + "Fahrenheit: " 19 + fahrenheit 20 )
21
22def fahrenheit_from(celsius): 23 """Convert Celsius to Fahrenheit degrees."""
24 try: 25 fahrenheit = float(celsius) * 9 / 5 + 32
26 fahrenheit = round(fahrenheit, 3) # Round to three decimal places
27 return str(fahrenheit)
28 except ValueError: 29 return "invalid input"
30
31if __name__ == "__main__":
32 app.run(host="127.0.0.1", port=8080, debug=True)
由于有相当多的变化,这里是一步一步的审查编辑行:
-
**第 2 行:**您不再使用
flask.escape(),因此您可以将其从 import 语句中删除。 -
**第 8、11 和 12 行:**和以前一样,您通过 Flask 的全局
request对象获取用户提交的值。通过使用 dictionary 方法.get(),您可以确保如果没有找到键,将返回一个空字符串。如果页面最初被加载,而用户还没有提交表单,就会出现这种情况。这在第 11 行和第 12 行实现。 -
**第 19 行:**通过返回末尾带有默认空字符串的表单,可以避免在表单提交之前显示任何内容。
-
**第 9 行和第 10 行:**在用户输入一个值并点击 Convert 之后,相同的页面再次被加载。这一次,
request.args.get("celsius", "")找到了celsius键并返回相关的值。这使得条件语句评估为True,并且用户提供的值被传递给fahrenheit_from()。 -
第 24 到 29 行:
fahrenheit_from()检查用户是否提供了有效的输入。如果提供的值可以转换成一个float,那么该函数将应用温度转换代码并返回华氏温度。如果它不能被转换,那么就产生一个ValueError异常,函数返回字符串"invalid input"。 -
**第 19 行:**这一次,当你将
fahrenheit变量连接到 HTML 字符串的末尾时,它指向fahrenheit_from()的返回值。这意味着转换后的温度或错误信息字符串将被添加到您的 HTML 中。 -
**第 15 行和第 18 行:**为了使页面更容易使用,您还向这个相同的 HTML 字符串添加了描述性标签
Celsius temperature和Fahrenheit。
即使您添加这些字符串的方式不代表有效的 HTML,您的页面也会正确呈现。这要感谢现代浏览器的强大功能。
请记住,如果你有兴趣更深入地研究 web 开发,那么你需要学习 HTML 。但是为了让您的 Python 脚本在线部署,这就足够了。
现在,您应该能够在浏览器中使用温度转换脚本了。您可以通过输入框提供摄氏温度,单击按钮,然后在同一网页上看到转换后的华氏温度结果。因为您使用的是默认的 HTTP GET 请求,所以您也可以看到提交的数据出现在 URL 中。
**注意:**事实上,您甚至可以绕开表单,通过提供一个适当的地址来为celsius提供您自己的值,类似于您在没有 HTML 表单的情况下构建脚本时如何使用转换。
例如,尝试直接在你的浏览器中输入 URL localhost:8080/?celsius=42,你会看到结果温度转换出现在你的页面上。
使用gcloud app deploy命令将完成的应用程序再次部署到 Google App Engine。部署完成后,转到提供的 URL 或运行gcloud app browse来查看您的 Python web 应用程序在互联网上的实况。通过添加不同类型的输入来测试它。一旦你满意了,与世界分享你的链接。
您的 temperature converter web 应用程序的 URL 仍然类似于https://hello-app-295110.ew.r.appspot.com/。这不能反映你的应用程序的当前功能。
重新查看部署说明,在 Google App Engine 上创建一个新项目,使用一个更合适的名称,并在那里部署您的应用。这将让你练习创建项目和将 Flask 应用程序部署到 Google App Engine。
至此,您已经成功地将 Python 脚本转换为 Python web 应用程序,并将其部署到 Google App Engine 进行在线托管。您可以使用相同的过程将更多的 Python 脚本转换成 web 应用程序。
创建你自己的诗歌生成器,允许用户使用网络表单创建短诗。您的 web 应用程序应该使用单个页面和单个表单来接受 GET 请求。您可以使用这个示例代码来开始,或者您可以编写自己的代码。
如果你想了解更多关于你可以用 Google App Engine 做什么的信息,那么你可以阅读关于使用静态文件的并添加一个 CSS 文件到你的 Python web 应用程序来改善它的整体外观。
在线托管您的代码可以让更多的人通过互联网访问它。继续把你最喜欢的脚本转换成 Flask 应用程序,并向全世界展示它们。
结论
您在本教程中涉及了很多内容!您从一个本地 Python 脚本开始,并将其转换为一个用户友好的、完全部署的 Flask 应用程序,现在托管在 Google App Engine 上。
在学习本教程的过程中,您学习了:
- 网络应用程序如何通过互联网提供数据
- 如何重构你的 Python 脚本,以便你可以在线托管
- 如何创建一个基本的烧瓶应用程序
- 如何手动转义用户输入
- 如何将你的代码部署到谷歌应用引擎
现在,您可以将您的本地 Python 脚本放到网上供全世界使用。如果您想下载在本教程中构建的应用程序的完整代码,可以单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用了解如何使用 Flask 创建 Python web 应用程序。
如果你想学习更多关于使用 Python 进行 web 开发的知识,那么你现在已经准备好尝试 Python web 框架,比如 Flask 和 Django 。继续努力吧!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Flask 在 Web 上部署你的 Python 脚本*********
Python 中 Web 抓取的实用介绍
原文:https://realpython.com/python-web-scraping-practical-introduction/
Web 抓取是从 Web 上收集和解析原始数据的过程,Python 社区已经开发出一些非常强大的 Web 抓取工具。
互联网可能是这个星球上最大的信息源。许多学科,如数据科学、商业智能和调查报告,可以从收集和分析网站数据中受益匪浅。
在本教程中,您将学习如何:
- 使用字符串方法和正则表达式解析网站数据
- 使用 HTML 解析器解析网站数据
- 与表单和其他网站组件交互
**注:**本教程改编自 Python 基础知识:Python 实用入门 3 中“与 Web 交互”一章。
这本书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互,因此在整个教程中,你会偶尔看到对 IDLE 的引用。然而,从您选择的编辑器和环境运行示例代码应该没有问题。
源代码: 点击这里下载免费的源代码,你将使用它来收集和解析来自网络的数据。
从网站上抓取并解析文本
使用自动化过程从网站收集数据被称为网络搜集。一些网站明确禁止用户使用自动化工具抓取他们的数据,就像你将在本教程中创建的工具一样。网站这样做有两个可能的原因:
- 该网站有充分的理由保护其数据。例如,谷歌地图不会让你太快地请求太多结果。
- 向网站的服务器发出多次重复请求可能会耗尽带宽,降低其他用户访问网站的速度,并可能使服务器过载,从而导致网站完全停止响应。
在使用 Python 技能进行 web 抓取之前,您应该始终检查目标网站的可接受使用政策,以确定使用自动化工具访问网站是否违反了其使用条款。从法律上讲,违背网站意愿的网络抓取是一个灰色地带。
**重要提示:**请注意,在禁止抓取网页的网站上使用以下技术可能是非法的。
对于本教程,您将使用一个托管在 Real Python 服务器上的页面。您将访问的页面已经设置为与本教程一起使用。
既然你已经阅读了免责声明,你可以开始有趣的事情了。在下一节中,您将开始从单个 web 页面获取所有 HTML 代码。
打造你的第一台网络刮刀
你可以在 Python 的标准库中找到的一个有用的 web 抓取包是urllib,它包含了处理 URL 的工具。特别是, urllib.request 模块包含一个名为urlopen()的函数,您可以用它来打开程序中的 URL。
在 IDLE 的交互窗口中,键入以下内容以导入urlopen():
>>> from urllib.request import urlopen
您将打开的网页位于以下 URL:
>>> url = "http://olympus.realpython.org/profiles/aphrodite"
要打开网页,请将url传递给urlopen():
>>> page = urlopen(url)
urlopen()返回一个HTTPResponse对象:
>>> page
<http.client.HTTPResponse object at 0x105fef820>
要从页面中提取 HTML,首先使用HTTPResponse对象的.read()方法,该方法返回一个字节序列。然后使用.decode()将字节解码成使用 UTF-8 的字符串:
>>> html_bytes = page.read()
>>> html = html_bytes.decode("utf-8")
现在你可以打印HTML 来查看网页的内容:
>>> print(html)
<html>
<head>
<title>Profile: Aphrodite</title>
</head>
<body bgcolor="yellow">
<center>
<br><br>
<img src="/static/aphrodite.gif" />
<h2>Name: Aphrodite</h2>
<br><br>
Favorite animal: Dove
<br><br>
Favorite color: Red
<br><br>
Hometown: Mount Olympus
</center>
</body>
</html>
你看到的输出是网站的 HTML 代码,当你访问http://olympus.realpython.org/profiles/aphrodite时,你的浏览器会显示出来:
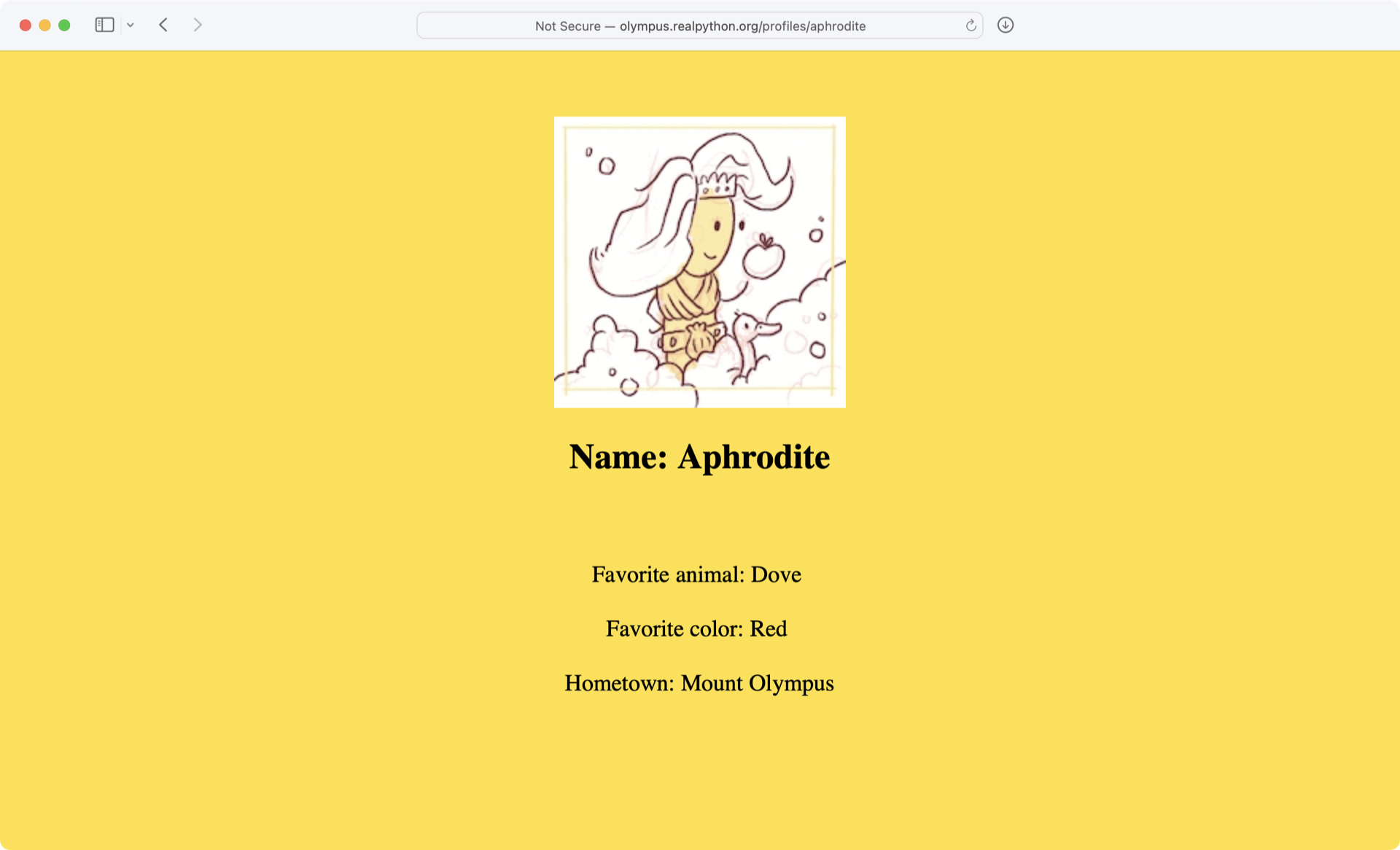
使用urllib,您可以像在浏览器中一样访问网站。但是,您没有可视化地呈现内容,而是将源代码作为文本获取。既然已经有了文本形式的 HTML,就可以用几种不同的方法从中提取信息。
用字符串方法从 HTML 中提取文本
从网页的 HTML 中提取信息的一种方法是使用字符串方法。例如,您可以使用.find()在 HTML 文本中搜索<title>标签,并提取网页的标题。
首先,您将提取您在前一个示例中请求的 web 页面的标题。如果你知道标题的第一个字符的索引和结束标签</title>的第一个字符的索引,那么你可以使用一个字符串切片来提取标题。
因为.find()返回一个子串第一次出现的索引,所以可以通过将字符串"<title>"传递给.find()来获得开始<title>标签的索引:
>>> title_index = html.find("<title>")
>>> title_index
14
但是,您并不需要<title>标签的索引。您需要标题本身的索引。要获得标题中第一个字母的索引,可以将字符串"<title>"的长度加到title_index中:
>>> start_index = title_index + len("<title>")
>>> start_index
21
现在通过将字符串"</title>"传递给.find()来获取结束</title>标签的索引:
>>> end_index = html.find("</title>")
>>> end_index
39
最后,您可以通过切分html字符串来提取标题:
>>> title = html[start_index:end_index]
>>> title
'Profile: Aphrodite'
现实世界中的 HTML 可能比阿芙罗狄蒂个人资料页面上的 HTML 复杂得多,也不太容易预测。这里是另一个个人资料页面,你可以抓取一些更混乱的 HTML:
>>> url = "http://olympus.realpython.org/profiles/poseidon"
尝试使用与上例相同的方法从这个新 URL 中提取标题:
>>> url = "http://olympus.realpython.org/profiles/poseidon"
>>> page = urlopen(url)
>>> html = page.read().decode("utf-8")
>>> start_index = html.find("<title>") + len("<title>")
>>> end_index = html.find("</title>")
>>> title = html[start_index:end_index]
>>> title
'\n<head>\n<title >Profile: Poseidon'
哎呦!标题中夹杂了一点 HTML。为什么会这样?
/profiles/poseidon页面的 HTML 看起来类似于/profiles/aphrodite页面,但是有一点小小的不同。开始的<title>标签在结束的尖括号(>)前有一个额外的空格,呈现为<title >。
html.find("<title>")返回-1,因为精确的子串"<title>"不存在。当-1加到len("<title>")上,即7时,start_index变量被赋值6。
字符串html的索引6处的字符是一个换行符(\n),正好在<head>标签的左尖括号(<)之前。这意味着html[start_index:end_index]返回所有从新行开始并在</title>标签之前结束的 HTML。
这类问题会以无数种不可预测的方式出现。您需要一种更可靠的方法来从 HTML 中提取文本。
了解正则表达式
正则表达式——或者简称为正则表达式——是可以用来在字符串中搜索文本的模式。Python 通过标准库的 re 模块支持正则表达式。
**注意:**正则表达式不是 Python 特有的。它们是一个通用的编程概念,许多编程语言都支持它们。
要使用正则表达式,您需要做的第一件事是导入re模块:
>>> import re
正则表达式使用称为元字符的特殊字符来表示不同的模式。例如,星号字符(*)代表零个或多个出现在星号前面的实例。
在下面的例子中,您使用.findall()来查找字符串中匹配给定正则表达式的任何文本:
>>> re.findall("ab*c", "ac")
['ac']
re.findall()的第一个参数是要匹配的正则表达式,第二个参数是要测试的字符串。在上面的例子中,您在字符串"ac"中搜索模式"ab*c"。
正则表达式"ab*c"匹配字符串中以"a"开头、以"c"结尾并且在两者之间有零个或多个"b"实例的任何部分。re.findall()返回所有匹配的列表。字符串"ac"匹配这个模式,所以它被返回到列表中。
以下是应用于不同字符串的相同模式:
>>> re.findall("ab*c", "abcd")
['abc']
>>> re.findall("ab*c", "acc")
['ac']
>>> re.findall("ab*c", "abcac")
['abc', 'ac']
>>> re.findall("ab*c", "abdc")
[]
注意,如果没有找到匹配,那么.findall()返回一个空列表。
模式匹配区分大小写。如果您想匹配这个模式而不考虑大小写,那么您可以传递第三个参数,值为re.IGNORECASE:
>>> re.findall("ab*c", "ABC")
[]
>>> re.findall("ab*c", "ABC", re.IGNORECASE)
['ABC']
您可以使用句点(.)来代表正则表达式中的任何单个字符。例如,您可以找到包含由单个字符分隔的字母"a"和"c"的所有字符串,如下所示:
>>> re.findall("a.c", "abc")
['abc']
>>> re.findall("a.c", "abbc")
[]
>>> re.findall("a.c", "ac")
[]
>>> re.findall("a.c", "acc")
['acc']
正则表达式中的模式.*代表重复任意次的任意字符。例如,您可以使用"a.*c"来查找以"a"开始并以"c"结束的每个子串,而不管中间是哪个或哪些字母:
>>> re.findall("a.*c", "abc")
['abc']
>>> re.findall("a.*c", "abbc")
['abbc']
>>> re.findall("a.*c", "ac")
['ac']
>>> re.findall("a.*c", "acc")
['acc']
通常,您使用re.search()来搜索字符串中的特定模式。这个函数比re.findall()稍微复杂一些,因为它返回一个名为MatchObject的对象,该对象存储不同的数据组。这是因为在其他匹配中可能有匹配,而re.search()返回每一个可能的结果。
MatchObject的细节在这里无关紧要。现在,只需知道在MatchObject上调用.group()将返回第一个也是最具包容性的结果,这在大多数情况下正是您想要的:
>>> match_results = re.search("ab*c", "ABC", re.IGNORECASE)
>>> match_results.group()
'ABC'
在re模块中还有一个对解析文本有用的函数。 re.sub() ,是 substitute 的简称,允许你用新文本替换匹配正则表达式的字符串中的文本。它的表现有点像 .replace() 弦法。
传递给re.sub()的参数是正则表达式,后面是替换文本,后面是字符串。这里有一个例子:
>>> string = "Everything is <replaced> if it's in <tags>."
>>> string = re.sub("<.*>", "ELEPHANTS", string)
>>> string
'Everything is ELEPHANTS.'
也许这并不是你所期望的。
re.sub()使用正则表达式"<.*>"查找并替换第一个<和最后一个>之间的所有内容,从<replaced>开始到<tags>结束。这是因为 Python 的正则表达式是贪婪的,这意味着当使用像*这样的字符时,它们试图找到最长的可能匹配。
或者,您可以使用非贪婪匹配模式*?,它的工作方式与*相同,只是它匹配可能的最短文本字符串:
>>> string = "Everything is <replaced> if it's in <tags>."
>>> string = re.sub("<.*?>", "ELEPHANTS", string)
>>> string
"Everything is ELEPHANTS if it's in ELEPHANTS."
这次,re.sub()找到了两个匹配项,<replaced>和<tags>,并用字符串"ELEPHANTS"替换这两个匹配项。
用正则表达式从 HTML 中提取文本
有了所有这些知识,现在试着从另一个个人资料页面解析出标题,其中包括这段相当粗心的 HTML 代码:
<TITLE >Profile: Dionysus</title / >
.find()方法在处理这里的不一致时会有困难,但是通过巧妙使用正则表达式,您可以快速有效地处理这段代码:
# regex_soup.py
import re
from urllib.request import urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
page = urlopen(url)
html = page.read().decode("utf-8")
pattern = "<title.*?>.*?</title.*?>"
match_results = re.search(pattern, html, re.IGNORECASE)
title = match_results.group()
title = re.sub("<.*?>", "", title) # Remove HTML tags
print(title)
通过将字符串分成三部分来仔细查看pattern中的第一个正则表达式:
-
<title.*?>匹配html中的开始<TITLE >标签。模式的<title部分与<TITLE匹配,因为re.search()是用re.IGNORECASE调用的,而.*?>匹配<TITLE之后直到第一个>实例的任何文本。 -
.*?非贪婪地匹配开头<TITLE >后的所有文本,停在第一个匹配的</title.*?>。 -
</title.*?>与第一个模式的不同之处仅在于它使用了/字符,因此它匹配html中的结束</title / >标记。
第二个正则表达式,字符串"<.*?>",也使用非贪婪的.*?来匹配title字符串中的所有 HTML 标签。通过用""替换任何匹配,re.sub()删除所有标签,只返回文本。
**注意:**用 Python 或任何其他语言进行 Web 抓取可能会很乏味。没有两个网站是以相同的方式组织的,HTML 通常是混乱的。此外,网站会随着时间而变化。今天有效的网页抓取工具不能保证明年或者下周也有效。
如果使用正确,正则表达式是一个强大的工具。在这篇介绍中,您仅仅触及了皮毛。有关正则表达式以及如何使用它们的更多信息,请查看由两部分组成的系列文章正则表达式:Python 中的正则表达式。
检查你的理解能力
展开下面的方框,检查您的理解情况。
编写一个程序,从以下 URL 获取完整的 HTML:
>>> url = "http://olympus.realpython.org/profiles/dionysus"
然后使用.find()显示*名称:和喜爱的颜色:*之后的文本(不包括任何可能出现在同一行的前导空格或尾随 HTML 标签)。
您可以展开下面的方框查看解决方案。
首先,从urlib.request模块导入urlopen函数:
from urllib.request import urlopen
然后打开 URL 并使用由urlopen()返回的HTTPResponse对象的.read()方法来读取页面的 HTML:
url = "http://olympus.realpython.org/profiles/dionysus"
html_page = urlopen(url)
html_text = html_page.read().decode("utf-8")
.read()方法返回一个字节串,所以使用.decode()通过 UTF-8 编码对字节进行解码。
现在您已经将 web 页面的 HTML 源代码作为一个字符串分配给了html_text变量,您可以从 Dionysus 的概要文件中提取他的名字和最喜欢的颜色。狄俄尼索斯个人资料的 HTML 结构与您之前看到的阿芙罗狄蒂个人资料的结构相同。
您可以通过在文本中找到字符串"Name:"并提取该字符串第一次出现之后和下一个 HTML 标签之前的所有内容来获得名称。也就是说,您需要提取冒号(:)之后和第一个尖括号(<)之前的所有内容。你可以用同样的技巧提取喜欢的颜色。
下面的 for循环为名称和喜爱的颜色提取文本:
for string in ["Name: ", "Favorite Color:"]:
string_start_idx = html_text.find(string)
text_start_idx = string_start_idx + len(string)
next_html_tag_offset = html_text[text_start_idx:].find("<")
text_end_idx = text_start_idx + next_html_tag_offset
raw_text = html_text[text_start_idx : text_end_idx]
clean_text = raw_text.strip(" \r\n\t")
print(clean_text)
看起来在这个for循环中进行了很多工作,但这只是一点点计算提取所需文本的正确索引的运算。继续并分解它:
-
您使用
html_text.find()来查找字符串的起始索引,可以是"Name:"或"Favorite Color:",然后将索引分配给string_start_idx。 -
由于要提取的文本紧接在
"Name:"或"Favorite Color:"中的冒号之后开始,所以通过将字符串的长度加到start_string_idx中可以获得紧跟在冒号之后的字符的索引,然后将结果赋给text_start_idx。 -
通过确定第一个尖括号(
<)相对于text_start_idx的索引,计算要提取的文本的结束索引,并将该值赋给next_html_tag_offset。然后将该值加到text_start_idx上,并将结果赋给text_end_idx。 -
你通过从
text_start_idx到text_end_idx分割html_text来提取文本,并将这个字符串分配给raw_text。 -
使用
.strip()删除raw_text开头和结尾的任何空白,并将结果赋给clean_text。
在循环结束时,使用print()显示提取的文本。最终输出如下所示:
Dionysus
Wine
这个解决方案是解决这个问题的众多解决方案之一,所以如果你用不同的解决方案得到相同的输出,那么你做得很好!
当你准备好了,你可以进入下一部分。
在 Python 中使用 HTML 解析器进行 Web 抓取
虽然正则表达式通常非常适合模式匹配,但有时使用专门为解析 HTML 页面而设计的 HTML 解析器更容易。有许多 Python 工具是为此而编写的,但是 Beautiful Soup 库是一个很好的开始。
装美汤
要安装 Beautiful Soup,您可以在终端中运行以下命令:
$ python -m pip install beautifulsoup4
使用这个命令,您可以将最新版本的 Beautiful Soup 安装到您的全局 Python 环境中。
创建一个BeautifulSoup对象
在新的编辑器窗口中键入以下程序:
# beauty_soup.py
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
page = urlopen(url)
html = page.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
这个程序做三件事:
-
使用
urllib.request模块中的urlopen()打开网址http://olympus.realpython.org/profiles/dionysus -
以字符串形式从页面中读取 HTML,并将其赋给
html变量 -
创建一个
BeautifulSoup对象,并将其分配给soup变量
分配给soup的BeautifulSoup对象是用两个参数创建的。第一个参数是要解析的 HTML,第二个参数是字符串"html.parser",它告诉对象在后台使用哪个解析器。"html.parser"代表 Python 内置的 HTML 解析器。
使用一个BeautifulSoup对象
保存并运行上面的程序。当它完成运行时,您可以使用交互窗口中的soup变量以各种方式解析html的内容。
**注意:**如果你没有使用 IDLE,那么你可以用-i标志运行你的程序进入交互模式。类似于python -i beauty_soup.py的东西将首先运行你的程序,然后让你进入一个 REPL,在那里你可以探索你的对象。
例如,BeautifulSoup对象有一个.get_text()方法,可以用来从文档中提取所有文本,并自动删除任何 HTML 标签。
在 IDLE 的交互窗口中或编辑器中的代码末尾键入以下代码:
>>> print(soup.get_text())
Profile: Dionysus
Name: Dionysus
Hometown: Mount Olympus
Favorite animal: Leopard
Favorite Color: Wine
这个输出中有很多空行。这些是 HTML 文档文本中换行符的结果。如果需要,可以用.replace() string 方法删除它们。
通常,您只需要从 HTML 文档中获取特定的文本。首先使用 Beautiful Soup 提取文本,然后使用.find() string 方法,这有时比使用正则表达式更容易。
然而,其他时候 HTML 标签本身是指出您想要检索的数据的元素。例如,您可能想要检索页面上所有图像的 URL。这些链接包含在<img> HTML 标签的src属性中。
在这种情况下,您可以使用find_all()返回该特定标记的所有实例的列表:
>>> soup.find_all("img")
[<img src="/static/dionysus.jpg"/>, <img src="/static/grapes.png"/>]
这将返回 HTML 文档中所有<img>标签的列表。列表中的对象看起来可能是代表标签的字符串,但它们实际上是 Beautiful Soup 提供的Tag对象的实例。Tag对象为处理它们所包含的信息提供了一个简单的接口。
您可以先从列表中解包Tag对象,对此进行一些探索:
>>> image1, image2 = soup.find_all("img")
每个Tag对象都有一个.name属性,该属性返回一个包含 HTML 标签类型的字符串:
>>> image1.name
'img'
您可以通过将名称放在方括号中来访问Tag对象的 HTML 属性,就像属性是字典中的键一样。
例如,<img src="/static/dionysus.jpg"/>标签只有一个属性src,其值为"/static/dionysus.jpg"。同样,像链接<a href="https://realpython.com" target="_blank">这样的 HTML 标签有两个属性,href和target。
要获得 Dionysus profile 页面中图像的来源,可以使用上面提到的字典符号访问src属性:
>>> image1["src"]
'/static/dionysus.jpg'
>>> image2["src"]
'/static/grapes.png'
HTML 文档中的某些标签可以通过Tag对象的属性来访问。例如,要获得文档中的<title>标签,可以使用.title属性:
>>> soup.title
<title>Profile: Dionysus</title>
如果您通过导航到个人资料页面来查看 Dionysus 个人资料的源代码,右键单击该页面,并选择查看页面源代码,那么您会注意到<title>标签全部用大写字母和空格书写:
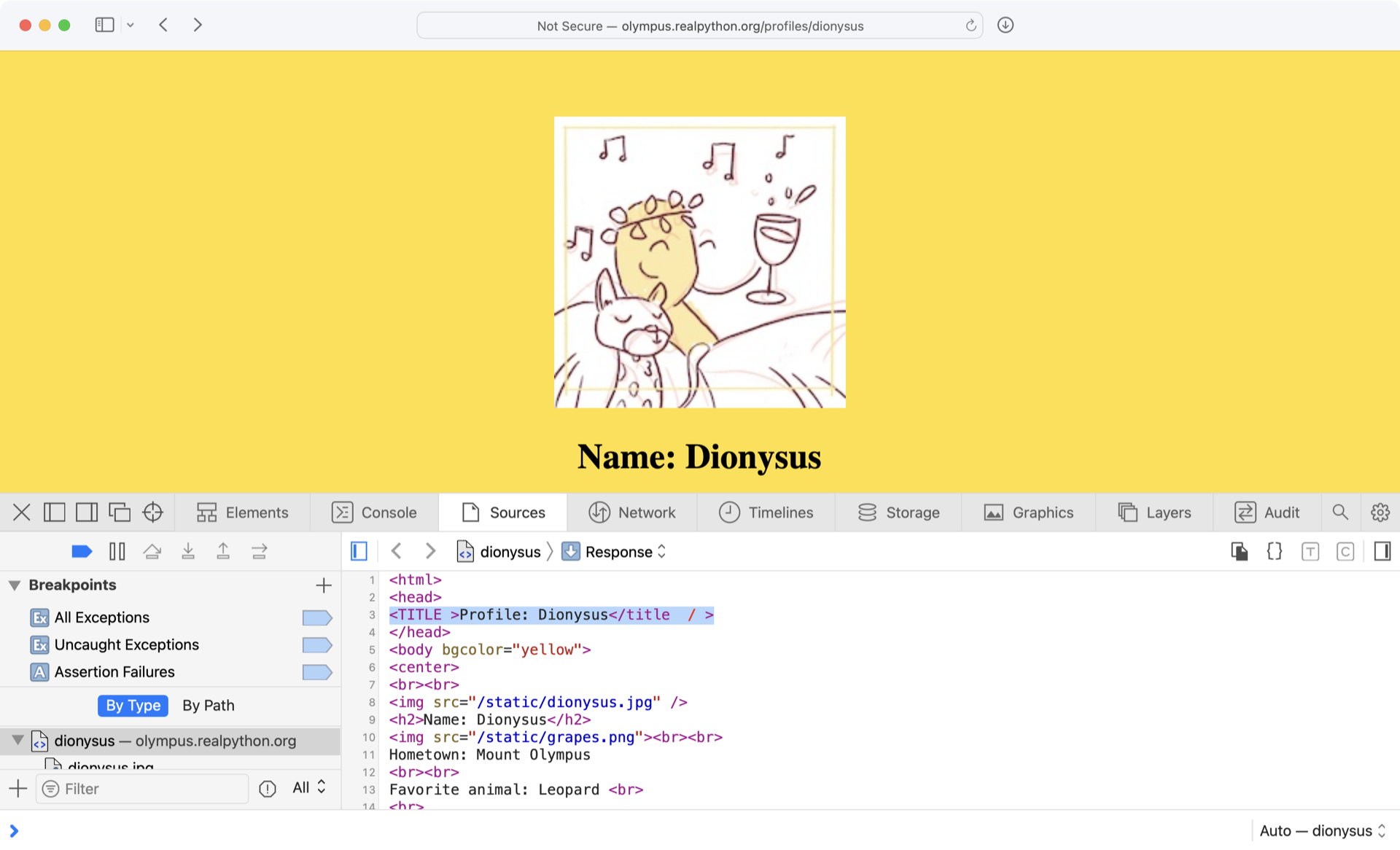
Beautiful Soup 通过删除开始标签中多余的空格和结束标签中多余的正斜杠(/)自动为您清理标签。
您还可以使用Tag对象的.string属性来检索标题标签之间的字符串:
>>> soup.title.string
'Profile: Dionysus'
Beautiful Soup 的一个特性是能够搜索特定类型的标签,这些标签的属性与某些值相匹配。例如,如果您想要查找所有具有与值/static/dionysus.jpg相等的src属性的<img>标签,那么您可以向.find_all()提供以下附加参数:
>>> soup.find_all("img", src="/static/dionysus.jpg")
[<img src="/static/dionysus.jpg"/>]
这个例子有些武断,从这个例子中可能看不出这种技术的用处。如果你花一些时间浏览各种网站并查看它们的页面源代码,那么你会注意到许多网站都有极其复杂的 HTML 结构。
当使用 Python 从网站抓取数据时,您通常会对页面的特定部分感兴趣。通过花一些时间浏览 HTML 文档,您可以识别具有独特属性的标签,这些标签可用于提取您需要的数据。
然后,不用依赖复杂的正则表达式或使用.find()来搜索整个文档,您可以直接访问您感兴趣的特定标签并提取您需要的数据。
在某些情况下,你可能会发现漂亮的汤并没有提供你需要的功能。lxml 库开始有点棘手,但是它提供了比解析 HTML 文档更大的灵活性。一旦你习惯了使用美丽的汤,你可能会想要检查一下。
**注意:**在定位网页中的特定数据时,像美人汤这样的 HTML 解析器可以节省您大量的时间和精力。然而,有时 HTML 写得很差,没有条理,甚至像 Beautiful Soup 这样复杂的解析器也不能正确地解释 HTML 标签。
在这种情况下,您通常需要使用.find()和正则表达式技术来解析出您需要的信息。
Beautiful Soup 非常适合从网站的 HTML 中抓取数据,但是它没有提供任何处理 HTML 表单的方法。例如,如果你需要在一个网站上搜索一些查询,然后搜索结果,那么单靠美丽的汤不会让你走得很远。
检查你的理解能力
展开下面的方框,检查您的理解情况。
编写一个程序,从 URL http://olympus.realpython.org/profiles的页面获取完整的 HTML。
使用 Beautiful Soup,通过查找名为a的 HTML 标记并检索每个标记的href属性所取的值,打印出页面上所有链接的列表。
最终输出应该如下所示:
http://olympus.realpython.org/profiles/aphrodite
http://olympus.realpython.org/profiles/poseidon
http://olympus.realpython.org/profiles/dionysus
确保在基本 URL 和相对 URL 之间只有一个斜杠(/)。
您可以展开下面的方框查看解决方案:
首先,从urlib.request模块中导入urlopen函数,从bs4包中导入BeautifulSoup类:
from urllib.request import urlopen
from bs4 import BeautifulSoup
在/profiles页面上的每个链接 URL 是一个相对 URL ,所以用网站的基本 URL 创建一个base_url变量:
base_url = "http://olympus.realpython.org"
您可以通过连接base_url和一个相对 URL 来构建一个完整的 URL。
现在用urlopen()打开/profiles页面,使用.read()获取 HTML 源代码:
html_page = urlopen(base_url + "/profiles")
html_text = html_page.read().decode("utf-8")
下载并解码 HTML 源代码后,您可以创建一个新的BeautifulSoup对象来解析 HTML:
soup = BeautifulSoup(html_text, "html.parser")
返回 HTML 源代码中所有链接的列表。您可以遍历这个列表,打印出网页上的所有链接:
for link in soup.find_all("a"):
link_url = base_url + link["href"]
print(link_url)
您可以通过"href"下标访问每个链接的相对 URL。将该值与base_url连接,创建完整的link_url。
当你准备好了,你可以进入下一部分。
与 HTML 表单交互
到目前为止,您在本教程中使用的urllib模块非常适合请求网页内容。但是,有时您需要与网页交互来获取您需要的内容。例如,您可能需要提交表单或单击按钮来显示隐藏的内容。
**注:**本教程改编自 Python 基础知识:Python 实用入门 3 中“与 Web 交互”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
Python 标准库并没有提供一个内置的交互处理网页的方法,但是许多第三方包可以从 PyPI 获得。其中, MechanicalSoup 是一个流行且相对简单的软件包。
本质上,MechanicalSoup 安装了所谓的无头浏览器,这是一个没有图形用户界面的网络浏览器。该浏览器通过 Python 程序以编程方式控制。
安装机械汤
您可以在您的终端中安装带有 pip 的机械汤:
$ python -m pip install MechanicalSoup
您需要关闭并重新启动您的空闲会话,以便 MechanicalSoup 在安装后加载并被识别。
创建一个Browser对象
在 IDLE 的交互窗口中键入以下内容:
>>> import mechanicalsoup
>>> browser = mechanicalsoup.Browser()
对象代表无头网络浏览器。您可以使用它们通过向它们的.get()方法传递一个 URL 来请求来自互联网的页面:
>>> url = "http://olympus.realpython.org/login"
>>> page = browser.get(url)
page是一个Response对象,存储从浏览器请求 URL 的响应:
>>> page
<Response [200]>
数字200代表请求返回的状态码。状态代码200表示请求成功。如果 URL 不存在,不成功的请求可能会显示状态代码404,如果请求时出现服务器错误,则可能会显示状态代码500。
MechanicalSoup 使用 Beautiful Soup 来解析请求中的 HTML,page有一个代表BeautifulSoup对象的.soup属性:
>>> type(page.soup)
<class 'bs4.BeautifulSoup'>
您可以通过检查.soup属性来查看 HTML:
>>> page.soup
<html>
<head>
<title>Log In</title>
</head>
<body bgcolor="yellow">
<center>
<br/><br/>
<h2>Please log in to access Mount Olympus:</h2>
<br/><br/>
<form action="/login" method="post" name="login">
Username: <input name="user" type="text"/><br/>
Password: <input name="pwd" type="password"/><br/><br/>
<input type="submit" value="Submit"/>
</form>
</center>
</body>
</html>
注意,这个页面上有一个<form>和用于用户名和密码的<input>元素。
提交带有机械汤的表格
在浏览器中打开上一个示例中的 /login 页面,在继续之前亲自查看一下:
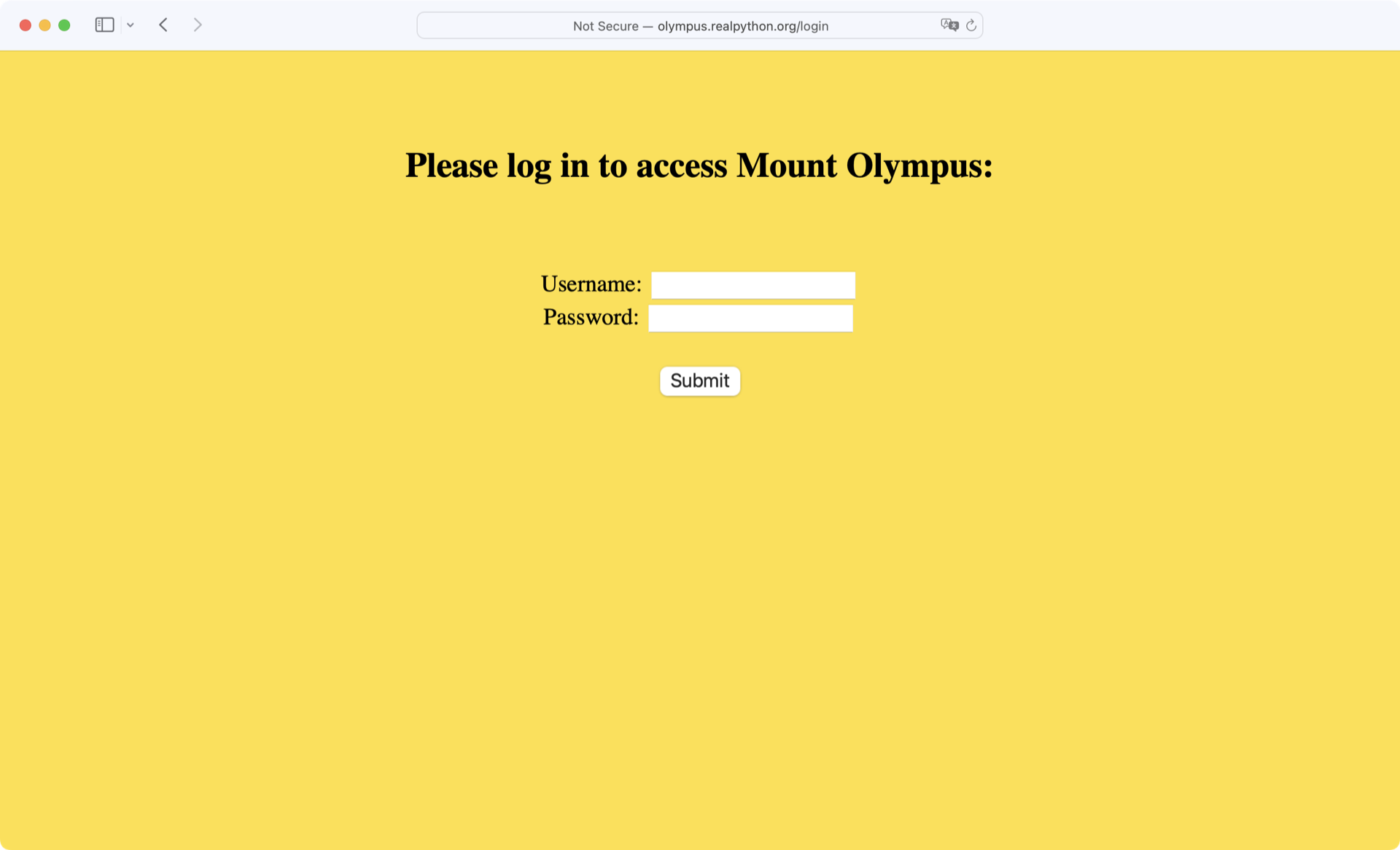
尝试输入随机的用户名和密码组合。如果你猜错了,那么消息*错误的用户名或密码!*显示在页面底部。
但是,如果您提供了正确的登录凭证,那么您将被重定向到 /profiles 页面:
| 用户名 | 密码 |
|---|---|
zeus | ThunderDude |
在下一个例子中,您将看到如何使用 Python 来使用 MechanicalSoup 填写和提交这个表单!
HTML 代码的重要部分是登录表单——也就是说,<form>标签中的所有内容。该页面上的<form>的name属性被设置为login。这个表单包含两个<input>元素,一个名为user,另一个名为pwd。第三个<input>元素是提交按钮。
既然您已经知道了登录表单的底层结构,以及登录所需的凭证,那么请看一个填写表单并提交表单的程序。
在新的编辑器窗口中,键入以下程序:
import mechanicalsoup
# 1
browser = mechanicalsoup.Browser()
url = "http://olympus.realpython.org/login"
login_page = browser.get(url)
login_html = login_page.soup
# 2
form = login_html.select("form")[0]
form.select("input")[0]["value"] = "zeus"
form.select("input")[1]["value"] = "ThunderDude"
# 3
profiles_page = browser.submit(form, login_page.url)
保存文件,按 F5 运行。要确认您已成功登录,请在交互式窗口中键入以下内容:
>>> profiles_page.url
'http://olympus.realpython.org/profiles'
现在分解上面的例子:
-
您创建了一个
Browser实例,并使用它来请求 URLhttp://olympus.realpython.org/login。使用.soup属性将页面的 HTML 内容分配给login_html变量。 -
login_html.select("form")返回页面上所有<form>元素的列表。因为页面只有一个<form>元素,所以可以通过检索列表中索引0处的元素来访问表单。当一页上只有一个表格时,你也可以使用login_html.form。接下来的两行选择用户名和密码输入,并将它们的值分别设置为"zeus"和"ThunderDude"。 -
你用
browser.submit()提交表格。注意,您向这个方法传递了两个参数,一个是form对象,另一个是通过login_page.url访问的login_page的 URL。
在交互窗口中,您确认提交成功地重定向到了/profiles页面。如果出了问题,那么profiles_page.url的值仍然是"http://olympus.realpython.org/login"。
注意:黑客可以通过快速尝试许多不同的用户名和密码,直到他们找到一个有效的组合,使用类似上面的自动化程序来暴力破解登录。
除了这是高度非法的,几乎所有的网站这些天来锁定你,并报告你的 IP 地址,如果他们看到你做了太多失败的请求,所以不要尝试!
既然您已经设置了profiles_page变量,那么是时候以编程方式获取/profiles页面上每个链接的 URL 了。
为此,您再次使用.select(),这次传递字符串"a"来选择页面上所有的<a>锚元素:
>>> links = profiles_page.soup.select("a")
现在您可以迭代每个链接并打印出href属性:
>>> for link in links:
... address = link["href"]
... text = link.text
... print(f"{text}: {address}")
...
Aphrodite: /profiles/aphrodite
Poseidon: /profiles/poseidon
Dionysus: /profiles/dionysus
每个href属性中包含的 URL 都是相对 URL,如果您想稍后使用 MechanicalSoup 导航到它们,这些 URL 没有太大帮助。如果您碰巧知道完整的 URL,那么您可以分配构建完整 URL 所需的部分。
在这种情况下,基本 URL 只是http://olympus.realpython.org。然后,您可以将基本 URL 与在src属性中找到的相对 URL 连接起来:
>>> base_url = "http://olympus.realpython.org"
>>> for link in links:
... address = base_url + link["href"]
... text = link.text
... print(f"{text}: {address}")
...
Aphrodite: http://olympus.realpython.org/profiles/aphrodite
Poseidon: http://olympus.realpython.org/profiles/poseidon
Dionysus: http://olympus.realpython.org/profiles/dionysus
你可以只用.get()、.select()和.submit()做很多事情。也就是说,机械汤可以做得更多。要了解更多关于机械汤的信息,请查阅官方文件。
检查你的理解能力
展开下面的方框,检查您的理解情况
使用 MechanicalSoup 向位于 URL http://olympus.realpython.org/login的登录表单提供正确的用户名(zeus)和密码(ThunderDude)。
提交表单后,显示当前页面的标题,以确定您已经被重定向到 /profiles 页面。
你的程序应该打印文本<title>All Profiles</title>。
您可以展开下面的方框查看解决方案。
首先,导入mechanicalsoup包并创建一个Broswer对象:
import mechanicalsoup
browser = mechanicalsoup.Browser()
通过将 URL 传递给browser.get()将浏览器指向登录页面,并获取带有.soup属性的 HTML:
login_url = "http://olympus.realpython.org/login"
login_page = browser.get(login_url)
login_html = login_page.soup
login_html是一个BeautifulSoup实例。因为页面上只有一个表单,所以您可以通过login_html.form访问该表单。使用.select(),选择用户名和密码输入,并填入用户名"zeus"和密码"ThunderDude":
form = login_html.form
form.select("input")[0]["value"] = "zeus"
form.select("input")[1]["value"] = "ThunderDude"
现在表单已经填写完毕,您可以使用browser.submit()提交它:
profiles_page = browser.submit(form, login_page.url)
如果您用正确的用户名和密码填写了表单,那么profiles_page实际上应该指向/profiles页面。你可以通过打印分配给profiles_page:的页面标题来确认这一点
print(profiles_page.soup.title)
您应该会看到以下显示的文本:
<title>All Profiles</title>
如果您看到文本Log In或其他东西,那么表单提交失败。
当你准备好了,你可以进入下一部分。
与网站实时互动
有时,您希望能够从提供持续更新信息的网站获取实时数据。
在你学习 Python 编程之前的黑暗日子里,你不得不坐在浏览器前,每当你想检查更新的内容是否可用时,点击刷新按钮来重新加载页面。但是现在您可以使用 MechanicalSoup Browser对象的.get()方法来自动化这个过程。
打开您选择的浏览器并导航至 URL http://olympus.realpython.org/dice:
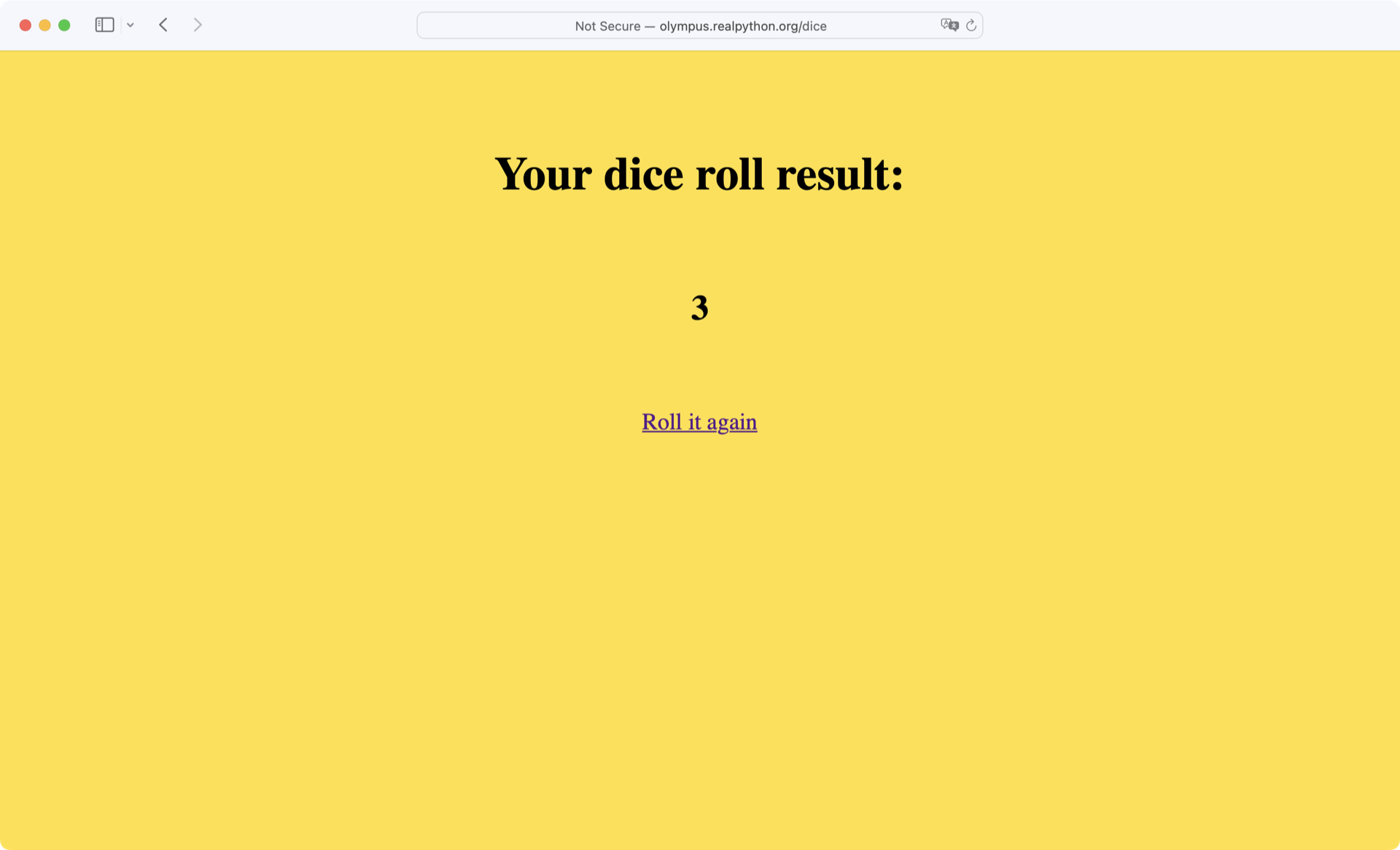
这个 /dice 页面模拟一个六面骰子的滚动,每次刷新浏览器都会更新结果。下面,您将编写一个程序,反复抓取页面以获得新的结果。
您需要做的第一件事是确定页面上的哪个元素包含掷骰子的结果。现在,右键单击页面上的任意位置并选择查看页面源即可。HTML 代码中间多一点的地方是一个类似下面的<h2>标签:
<h2 id="result">3</h2>
对于您来说,<h2>标签的文本可能不同,但是这是抓取结果所需的页面元素。
**注意:**对于这个例子,您可以很容易地检查出页面上只有一个带有id="result"的元素。尽管id属性应该是惟一的,但实际上您应该总是检查您感兴趣的元素是否被惟一标识。
现在开始编写一个简单的程序,打开 /dice 页面,抓取结果,并打印到控制台:
# mech_soup.py
import mechanicalsoup
browser = mechanicalsoup.Browser()
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
这个例子使用了BeautifulSoup对象的.select()方法来查找带有id=result的元素。传递给.select()的字符串"#result"使用 CSS ID 选择器 #来表示result是一个id值。
为了定期获得新的结果,您需要创建一个循环,在每一步加载页面。因此,上面代码中位于行browser = mechanicalsoup.Browser()之下的所有内容都需要放在循环体中。
对于本例,您希望以 10 秒的间隔掷出 4 次骰子。为此,代码的最后一行需要告诉 Python 暂停运行十秒钟。你可以用 Python 的 time模块中的 .sleep() 来做到这一点。.sleep()方法采用单个参数,表示以秒为单位的睡眠时间。
这里有一个例子来说明sleep()是如何工作的:
import time
print("I'm about to wait for five seconds...")
time.sleep(5)
print("Done waiting!")
当您运行这段代码时,您将会看到在第一个print()函数被执行 5 秒钟后才会显示"Done waiting!"消息。
对于掷骰子的例子,您需要将数字10传递给sleep()。以下是更新后的程序:
# mech_soup.py
import time
import mechanicalsoup
browser = mechanicalsoup.Browser()
for i in range(4):
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
time.sleep(10)
当您运行该程序时,您将立即看到打印到控制台的第一个结果。十秒钟后,显示第二个结果,然后是第三个,最后是第四个。打印第四个结果后会发生什么?
程序继续运行十秒钟,然后最终停止。那有点浪费时间!您可以通过使用一个 if语句来阻止它这样做,只对前三个请求运行time.sleep():
# mech_soup.py
import time
import mechanicalsoup
browser = mechanicalsoup.Browser()
for i in range(4):
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
# Wait 10 seconds if this isn't the last request
if i < 3:
time.sleep(10)
有了这样的技术,你可以从定期更新数据的网站上抓取数据。但是,您应该意识到,快速连续多次请求某个页面可能会被视为对网站的可疑甚至恶意使用。
**重要提示:**大多数网站都会发布使用条款文档。你经常可以在网站的页脚找到它的链接。
在试图从网站上抓取数据之前,请务必阅读本文档。如果您找不到使用条款,那么尝试联系网站所有者,询问他们是否有关于请求量的任何政策。
不遵守使用条款可能会导致您的 IP 被封锁,所以要小心!
过多的请求甚至有可能使服务器崩溃,所以可以想象许多网站都很关心对服务器的请求量!始终检查使用条款,并在向网站发送多个请求时保持尊重。
结论
虽然可以使用 Python 标准库中的工具解析来自 Web 的数据,但是 PyPI 上有许多工具可以帮助简化这个过程。
在本教程中,您学习了如何:
- 使用 Python 内置的
urllib模块请求网页 - 使用美汤解析 HTML
- 使用 MechanicalSoup 与 web 表单交互
- 反复从网站请求数据以检查更新
编写自动化的网络抓取程序很有趣,而且互联网上不缺乏可以带来各种令人兴奋的项目的内容。
请记住,不是每个人都希望你从他们的网络服务器上下载数据。在你开始抓取之前,一定要检查网站的使用条款,尊重你的网络请求时间,这样你就不会让服务器流量泛滥。
源代码: 点击这里下载免费的源代码,你将使用它来收集和解析来自网络的数据。
额外资源
有关使用 Python 进行 web 抓取的更多信息,请查看以下资源:
注意:如果你喜欢在这个例子中从 Python 基础知识:Python 3 实用介绍中所学到的东西,那么一定要看看本书的其余部分。****
什么是 Python 轮子,为什么要关心?
Python .whl文件,或者说轮子,是 Python 中很少被讨论的部分,但是它们对于 Python 包的安装过程是一个福音。如果你已经使用 pip 安装了一个 Python 包,那么很有可能是一个轮子使得安装更快更有效。
Wheels 是 Python 生态系统的一个组件,它有助于让包安装正常工作。它们允许更快的安装和更稳定的软件包分发过程。在本教程中,您将深入了解什么是轮子,它们有什么好处,以及它们是如何获得牵引力并使 Python 变得更加有趣的。
在本教程中,您将学习:
- 什么是车轮,它们与源分布相比如何
- 如何使用轮子来控制包装安装过程
- 如何为你自己的 Python 包创建和分发轮子
您将从用户和开发人员的角度看到使用流行的开源 Python 包的例子。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
设置
接下来,激活一个虚拟环境,并确保你已经安装了最新版本的pip、wheel和setuptools:
$ python -m venv env && source ./env/bin/activate
$ python -m pip install -U pip wheel setuptools
Successfully installed pip 20.1 setuptools-46.1.3 wheel-0.34.2
这就是你安装和制造轮子所需要的全部实验!
Python 打包变得更好:Python Wheels 简介
在您学习如何将一个项目打包到一个轮子之前,了解从用户的角度看使用一个轮子是什么样子会有所帮助。这听起来可能有点落后,但是学习轮子如何工作的一个好方法是从安装一个不是轮子的东西开始。
您可以像平常一样,通过在您的环境中安装一个 Python 包来开始这个实验。在这种情况下,安装 uWSGI 版本 2.0.x:
1$ python -m pip install 'uwsgi==2.0.*'
2Collecting uwsgi==2.0.*
3 Downloading uwsgi-2.0.18.tar.gz (801 kB) 4 |████████████████████████████████| 801 kB 1.1 MB/s
5Building wheels for collected packages: uwsgi
6 Building wheel for uwsgi (setup.py) ... done
7 Created wheel for uwsgi ... uWSGI-2.0.18-cp38-cp38-macosx_10_15_x86_64.whl
8 Stored in directory: /private/var/folders/jc/8_hqsz0x1tdbp05 ...
9Successfully built uwsgi
10Installing collected packages: uwsgi
11Successfully installed uwsgi-2.0.18
要完全安装 uWSGI,pip需要经过几个不同的步骤:
- 在第 3 行的上,它下载了一个名为
uwsgi-2.0.18.tar.gz的 TAR 文件(tarball),这个文件已经用 gzip 压缩过了。 - 在的第 6 行,它获取 tarball 并通过调用
setup.py构建一个.whl文件。 - 在线 7 上,它标记车轮
uWSGI-2.0.18-cp38-cp38-macosx_10_15_x86_64.whl。 - 在第 10 行上,它在构建完车轮后安装实际的包。
pip取回的tar.gz tarball 是一个源分布,或sdist,而不是一个轮子。在某些方面,sdist是轮子的反义词。
注意:如果您看到 uWSGI 安装出错,您可能需要安装 Python 开发头文件。
一个源代码分发包含源代码。这不仅包括 Python 代码,还包括与软件包捆绑在一起的任何扩展模块的源代码(通常用 C 或 C++ )。对于源代码发行版,扩展模块是在用户端编译的,而不是在开发人员端。
源代码发行版还包含一个名为 <package-name>.egg-info 的目录中的元数据包。这些元数据有助于构建和安装软件包,但是用户实际上不需要做任何事情。
从开发人员的角度来看,源代码发行版是在运行以下命令时创建的:
$ python setup.py sdist
现在尝试安装一个不同的包, chardet :
1$ python -m pip install 'chardet==3.*'
2Collecting chardet
3 Downloading chardet-3.0.4-py2.py3-none-any.whl (133 kB) 4 |████████████████████████████████| 133 kB 1.5 MB/s
5Installing collected packages: chardet
6Successfully installed chardet-3.0.4
您可以看到与 uWSGI 安装明显不同的输出。
安装 chardet 直接从 PyPI 下载一个.whl文件。轮子名称chardet-3.0.4-py2.py3-none-any.whl遵循一个特定的命名约定,您将在后面看到。从用户的角度来看,更重要的是,当pip在 PyPI 上找到一个兼容的轮子时,没有构建阶段。
从开发人员的角度来看,轮子是运行以下命令的结果:
$ python setup.py bdist_wheel
为什么 uWSGI 给你一个源码分发而 chardet 提供一个轮子?通过查看 PyPI 上每个项目的页面,并导航到下载文件区域,你就能明白其中的原因。本节将向您展示pip在 PyPI 索引服务器上实际看到的内容:
- uw SGIT3】由于与项目复杂性相关的原因,只提供了一个源分布 (
uwsgi-2.0.18.tar.gz)。 - chardet 提供了一个轮子和一个源分布,但是如果与你的系统兼容的话
pip会更喜欢轮子*。稍后您将看到如何确定这种兼容性。*
用于轮子安装的兼容性检查的另一个例子是 psycopg2 ,它为 Windows 提供了一系列轮子,但不为 Linux 或 macOS 客户端提供任何轮子。这意味着pip install psycopg2可以根据您的具体设置获取一个轮或一个源分布。
为了避免这些类型的兼容性问题,一些包提供了多个轮子,每个轮子都适合特定的 Python 实现和底层操作系统。
到目前为止,你已经看到了轮子和sdist之间的一些明显区别,但是更重要的是这些区别对安装过程的影响。
轮子让东西跑得更快
在上面,您看到了获取预建轮子的安装和下载sdist的安装的比较。Wheels 使得 Python 包的端到端安装更快,原因有二:
- 在其他条件相同的情况下,轮子通常比源分布的尺寸小,这意味着它们可以在网络中更快地移动。
- 从 wheels 直接安装避免了在源代码发行版之外构建包的中间步骤。
几乎可以保证,chardet 的安装只需要 uWSGI 所需时间的一小部分。然而,这可能是一个不公平的比较,因为 chardet 是一个非常小和不复杂的包。使用不同的命令,您可以创建一个更直接的比较,来演示轮子产生了多大的差异。
您可以通过传递--no-binary选项使pip忽略其向车轮的倾斜:
$ time python -m pip install \
--no-cache-dir \
--force-reinstall \
--no-binary=:all: \ cryptography
该命令对 cryptography 包的安装进行计时,告诉pip即使有合适的轮子也要使用源分布。包含:all:使得规则适用于cryptography及其所有依赖项。
在我的机器上,从开始到结束大约需要32 秒。不仅安装要花很长时间,而且构建cryptography还需要有 OpenSSL 开发头文件,并且 Python 可以使用。
注意:在--no-binary中,你很可能会看到一个关于cryptography安装所需的头文件丢失的错误,这是使用源代码发行版令人沮丧的原因之一。如果是这样的话,cryptography文档的安装部分会建议你为一个特定的操作系统需要哪些库和头文件。
现在你可以重新安装cryptography,但是这次要确保pip使用 PyPI 的轮子。因为pip更喜欢一个轮子,这类似于没有任何参数地调用pip install。但是在这种情况下,您可以通过要求一个带有--only-binary的轮子来明确意图:
$ time python -m pip install \
--no-cache-dir \
--force-reinstall \
--only-binary=cryptography \ cryptography
这个选项只需要 4 秒多一点,或者说只需要对cryptography及其依赖项使用源代码发行版的八分之一的时间。
什么是巨蟒轮?
Python .whl文件本质上是一个 ZIP ( .zip)档案,带有一个特制的文件名,告诉安装人员 wheel 将支持哪些 Python 版本和平台。
一个轮子是一种型的建成分布型的。在这种情况下,build意味着这个轮子以一种现成的格式出现,允许你跳过源代码发行版所需要的构建阶段。
注意:值得一提的是,尽管使用了术语构建,但是一个轮子并不包含.pyc文件,或者编译的 Python 字节码。
车轮文件名被分成由连字符分隔的多个部分:
{dist}-{version}(-{build})?-{python}-{abi}-{platform}.whl
{brackets}中的每一部分都是一个标签,或者是轮子名称的一个组成部分,承载着轮子包含的内容以及轮子在哪里可以工作或者不可以工作的一些含义。
下面是一个使用 cryptography 滚轮的示例:
cryptography-2.9.2-cp35-abi3-macosx_10_9_x86_64.whl
cryptography分配多个车轮。每个轮子都是一个平台轮子,这意味着它只支持 Python 版本、Python ABIs、操作系统和机器架构的特定组合。您可以将命名约定分成几个部分:
-
cryptography是包名。 -
2.9.2是cryptography的打包版本。版本是符合 PEP 440 的字符串,例如2.9.2、3.4或3.9.0.a3。 -
cp35是 Python 标签,表示轮子需要的 Python 实现和版本。cp代表 CPython ,Python 的参考实现,35代表 Python 3.5 。例如,这个轮子与 Jython 不兼容。 -
abi3是 ABI 的标记。ABI 代表应用二进制接口。你真的不需要担心它需要什么,但是abi3是 Python C API 二进制兼容性的一个独立版本。 -
macosx_10_9_x86_64是站台标签,恰好相当拗口。在这种情况下,它可以进一步分解为子部分:macosx就是 macOS 操作系统。10_9是 macOS developer tools SDK 版本,用于编译 Python,进而构建这个轮子。x86_64是对 x86-64 指令集架构的引用。
最后一个组件在技术上不是标签,而是标准的.whl文件扩展名。综合起来看,上述部件表示该cryptography轮设计用于的目标机器。
现在让我们来看一个不同的例子。以下是您在上述 chardet 案例中看到的内容:
chardet-3.0.4-py2.py3-none-any.whl
你可以把它分解成标签:
chardet是包名。3.0.4是 chardet 的包版本。py2.py3是 Python 标签,意思是轮子支持任何 Python 实现的 Python 2 和 3。none是 ABI 的标记,意思是 ABI 不是一个因素。any是站台。这个轮子几乎可以在任何平台上工作。
车轮名称的py2.py3-none-any.whl段很常见。这是一个万向轮,它将与 Python 2 或 3 一起安装在任何带有 ABI 的平台上。如果轮子以none-any.whl结束,那么它很可能是一个不关心特定 Python ABI 或 CPU 架构的纯 Python 包。
另一个例子是jinja2模板引擎。如果你导航到 Jinja 3.x alpha 版本的下载页面,那么你会看到下面的轮子:
Jinja2-3.0.0a1-py3-none-any.whl
注意这里缺少了py2。这是一个纯 Python 项目,可以在任何 Python 3.x 版本上工作,但它不是万向轮,因为它不支持 Python 2。相反,它被称为纯蟒蛇轮。
注:2020 年,多个项目也在放弃对 Python 2 的支持,Python 2 于 2020 年 1 月 1 日达到寿命终止(EOL)。Jinja 版于 2020 年 2 月放弃 Python 2 支持。
以下是为一些流行的开源包分发的.whl名称的几个例子:
| 车轮 | 事实真相 |
|---|---|
PyYAML-5.3.1-cp38-cp38-win_amd64.whl | PyYAML 用于采用 AMD64 (x86-64)架构的 Windows 上的 CPython 3.8 |
numpy-1.18.4-cp38-cp38-win32.whl | 用于 Windows 32 位上的 CPython 3.8 的 NumPy |
scipy-1.4.1-cp36-cp36m-macosx_10_6_intel.whl | SciPy 用于 macOS 10.6 SDK 上的 CPython 3.6,带有胖二进制(多指令集) |
既然你对什么是轮子有了透彻的了解,是时候谈谈它们有什么好处了。
Python 车轮的优势
这里有一个来自 Python 打包权威 (PyPA)的轮子的证明:
并不是所有的开发人员都有合适的工具或经验来构建用这些编译语言编写的组件,所以 Python 创建了 wheel,这是一种旨在将库与编译后的工件一起发布的包格式。事实上,Python 的包安装程序
pip总是更喜欢轮子,因为安装总是更快,所以即使是纯 Python 的包也能更好地使用轮子。(来源)
更全面的描述是,wheels 在几个方面对 Python 包的用户和维护者都有好处:
-
对于纯 Python 包和扩展模块,轮子的安装速度都比源代码发行版快。
-
轮子比源分布更小。比如
six轮大约是对应源分布的三分之一大小。当您考虑到单个包的pip install实际上可能会引发一系列依赖项的下载时,这种差异就变得更加重要了。 -
**车轮切
setup.py执行出方程式。**从源代码安装运行无论包含在那个项目的setup.py中。正如 PEP 427 所指出的,这相当于任意代码执行。轮子完全避免了这一点。 -
不需要编译器来安装包含已编译扩展模块的轮子。扩展模块包含在针对特定平台和 Python 版本的 wheel 中。
-
pip自动生成.pyc文件在轮子中匹配正确的 Python 解释器。 -
轮子提供了一致性,它将安装包所涉及的许多变量排除在方程式之外。
您可以使用 PyPI 上项目的下载文件选项卡来查看不同的可用发行版。例如,熊猫分发各种各样的轮子。
告诉pip下载什么
可以对pip进行细粒度控制,并告诉它喜欢或避免哪种格式。您可以使用--only-binary和--no-binary选项来完成此操作。您已经在安装cryptography包的前一节中看到了它们,但是有必要仔细看看它们做了什么:
$ pushd "$(mktemp -d)"
$ python -m pip download --only-binary :all: --dest . --no-cache six
Collecting six
Downloading six-1.14.0-py2.py3-none-any.whl (10 kB)
Saved ./six-1.14.0-py2.py3-none-any.whl
Successfully downloaded six
在本例中,您使用pushd "$(mktemp -d)"切换到一个临时目录来存储下载内容。你使用pip download而不是pip install,这样你就可以检查最终的轮子,但是你可以用install代替download,同时保持相同的选项集。
你下载的 six 模块有几个标志:
--only-binary :all:告诉pip约束自己使用轮子并忽略源分布。如果没有这个选项,pip将只会偏好轮子,但在某些情况下会退回到源分布。--dest .告诉pip将six下载到当前目录。--no-cache告诉pip不要在本地下载缓存中查找。您使用这个选项只是为了演示从 PyPI 的实时下载,因为您很可能在某个地方有一个six缓存。
我前面提到过,wheel 文件本质上是一个.zip档案。你可以从字面上理解这句话,也可以这样看待轮子。例如,如果您想查看一个轮子的内容,您可以使用unzip:
$ unzip -l six*.whl
Archive: six-1.14.0-py2.py3-none-any.whl
Length Date Time Name
--------- ---------- ----- ----
34074 01-15-2020 18:10 six.py
1066 01-15-2020 18:10 six-1.14.0.dist-info/LICENSE
1795 01-15-2020 18:10 six-1.14.0.dist-info/METADATA
110 01-15-2020 18:10 six-1.14.0.dist-info/WHEEL
4 01-15-2020 18:10 six-1.14.0.dist-info/top_level.txt
435 01-15-2020 18:10 six-1.14.0.dist-info/RECORD
--------- -------
37484 6 files
six是一个特例:它实际上是一个单独的 Python 模块,而不是一个完整的包。Wheel 文件也可能非常复杂,稍后您会看到这一点。
与--only-binary相反,您可以使用--no-binary来做相反的事情:
$ python -m pip download --no-binary :all: --dest . --no-cache six
Collecting six
Downloading six-1.14.0.tar.gz (33 kB)
Saved ./six-1.14.0.tar.gz
Successfully downloaded six
$ popd
本例中唯一的变化是切换到--no-binary :all:。这告诉pip忽略轮子,即使它们可用,而是下载一个源发行版。
--no-binary什么时候可能有用?这里有几个案例:
-
**对应的轮子坏了。**这是对轮子的讽刺。它们的设计是为了减少东西损坏的频率,但在某些情况下,轮子可能会配置错误。在这种情况下,为自己下载并构建源代码发行版可能是一个可行的替代方案。
您也可以使用上述带有pip install的标志。此外,:all:不仅会将--only-binary规则应用到您正在安装的包,还会应用到它的所有依赖项,您可以向--only-binary和--no-binary传递应用该规则的特定包的列表。
下面举几个安装网址库 yarl 的例子。包含 Cython 代码,依赖 multidict ,包含纯 C 代码。对于yarl及其依赖项,有几个严格使用或严格忽略轮子的选项:
$ # Install `yarl` and use only wheels for yarl and all dependencies
$ python -m pip install --only-binary :all: yarl
$ # Install `yarl` and use wheels only for the `multidict` dependency
$ python -m pip install --only-binary multidict yarl
$ # Install `yarl` and don't use wheels for yarl or any dependencies
$ python -m pip install --no-binary :all: yarl
$ # Install `yarl` and don't use wheels for the `multidict` dependency
$ python -m pip install --no-binary multidict yarl
在本节中,您了解了如何微调pip install将使用的发布类型。虽然常规的pip install应该没有选项,但了解这些选项对于特殊情况是有帮助的。
manylinux车轮标签
Linux 有许多变体和风格,比如 Debian、CentOS、Fedora 和 Pacman。其中的每一个都可能在共享库(如libncurses)和核心 C 库(如glibc)中略有不同。
如果你正在写一个 C/C++扩展,那么这可能会产生一个问题。用 C 编写并在 Ubuntu Linux 上编译的源文件不能保证在 CentOS 机器或 Arch Linux 发行版上是可执行的。你需要为每一个 Linux 变种建立一个单独的轮子吗?
幸运的是,答案是否定的,这要归功于一组特别设计的标签,称为 manylinux 平台标签家族。目前有三种变体:
-
manylinux1是人教版 513 中规定的原始格式。 -
manylinux2010是 PEP 571 中指定的更新,升级到 CentOS 6 作为 Docker 镜像所基于的底层操作系统。理由是 CentOS 5.11,即manylinux1中允许的库列表的来源,于 2017 年 3 月达到 EOL,并停止接收安全补丁和错误修复。 -
manylinux2014是 PEP 599 中指定的升级到 CentOS 7 的更新,因为 CentOS 6 计划于 2020 年 11 月达到 EOL。
你可以在熊猫项目中找到一个manylinux分布的例子。这里是从 PyPI 下载的可用熊猫列表中的两个(从许多中选出来的):
pandas-1.0.3-cp37-cp37m-manylinux1_x86_64.whl
pandas-1.0.3-cp37-cp37m-manylinux1_i686.whl
在这种情况下,pandas 为 CPython 3.7 构建了manylinux1轮子,支持 x86-64 和 i686 架构。
在它的核心,manylinux是一个 Docker 镜像,构建于 CentOS 操作系统的某个版本之上。它捆绑了一个编译器套件、多个版本的 Python 和pip,以及一组允许的共享库。
注意:术语允许表示一个低级的库,默认情况下会出现在几乎所有的 Linux 系统上。这个想法是,依赖关系应该存在于基本操作系统上,而不需要额外安装。
截至 2020 年中期,manylinux1仍然是主要的manylinux标签。其中一个原因可能只是习惯。另一个原因可能是客户端(用户)对manylinux2010及以上版本的支持仅限于的更新版本或pip:
| 标签 | 要求 |
|---|---|
manylinux1 | 8.1.0 或更高版本 |
manylinux2010 | pip 19.0 或更高版本 |
manylinux2014 | pip 19.3 或更高版本 |
换句话说,如果你是一个构建manylinux2010轮子的包开发者,那么使用你的包的人将需要pip19.0(2019 年 1 月发布)或更高版本来让pip从 PyPI 找到并安装manylinux2010轮子。
幸运的是,虚拟环境已经变得越来越普遍,这意味着开发人员可以在不接触系统pip的情况下更新虚拟环境的pip。然而,情况并非总是如此,一些 Linux 发行版仍然附带了过时版本的pip。
也就是说,如果你正在 Linux 主机上安装 Python 包,那么如果包的维护者不怕麻烦地创建了manylinux轮子,你应该感到幸运。这将几乎保证软件包的安装没有任何麻烦,不管您的具体 Linux 变体或版本如何。
注意:注意 PyPI 轮在 Alpine Linux (或者 BusyBox )上不工作。这是因为 Alpine 使用 musl 代替了标准 glibc 。musl libc图书馆标榜自己是“一个新的libc,努力做到快速、简单、轻量级、免费和正确。”不幸的是,说到轮子,glibc就不是了。
平台车轮的安全注意事项
从用户安全的角度来看,wheels 的一个值得考虑的特性是,wheels可能会受到版本腐烂的影响,因为它们捆绑了一个二进制依赖项,而不允许系统包管理器更新该依赖项。
例如,如果一个轮子包含了 libfortran 共享库,那么该轮子的发行版将使用它们所捆绑的libfortran版本,即使你用一个包管理器如apt、yum或brew来升级你自己机器的libfortran版本。
如果您在一个具有高度安全防范措施的环境中进行开发,某些平台轮子的这个特性是需要注意的。
召集所有开发者:打造你的车轮
本教程的标题是“你为什么要关心?”作为一名开发人员,如果您计划向社区分发 Python 包,那么您应该非常关心为您的项目分发 wheels,因为它们使最终用户的安装过程更干净,更简单。
你可以用兼容的轮子支持的目标平台越多,你就会越少看到标题为“在 XYZ 平台上安装失败”的问题为 Python 包分发轮子客观上降低了包的用户在安装过程中遇到问题的可能性。
在本地构建一个轮子你需要做的第一件事就是安装wheel。确保setuptools也是最新的也无妨:
$ python -m pip install -U wheel setuptools
接下来的几节将带您在各种不同的场景中构建轮子。
不同类型的车轮
正如本教程中所提到的,轮子有几种不同的变体,轮子的类型反映在其文件名中:
-
一个万向轮包含
py2.py3-none-any.whl。它在任何操作系统和平台上都支持 Python 2 和 Python 3。在巨蟒轮网站上列出的大多数轮子都是万向轮。 -
一个纯蟒轮包含
py3-none-any.whl或py2.none-any.whl。它支持 Python 3 或 Python 2,但不支持两者。它在其他方面与万向轮相同,但它将贴上py2或py3的标签,而不是py2.py3的标签。 -
一个平台轮支持特定的 Python 版本和平台。它包含指示特定 Python 版本、ABI、操作系统或架构的段。
轮子类型之间的差异取决于它们支持的 Python 版本以及它们是否针对特定的平台。以下是车轮变化之间差异的简明摘要:
| 车轮类型 | 支持 Python 2 和 3 | 支持所有 ABI、操作系统和平台 |
|---|---|---|
| 普遍的 | -好的 | -好的 |
| 纯 Python 语言 | -好的 | |
| 平台 |
正如您接下来将看到的,您可以通过相对较少的设置来构建万向轮和纯 Python 轮,但是平台轮可能需要一些额外的步骤。
打造纯 Python 车轮
您可以使用setuptools 为任何项目构建一个纯 Python 轮子或通用轮子,只需一个命令:
$ python setup.py sdist bdist_wheel
这将创建一个源分布(sdist)和一个轮(bdist_wheel)。默认情况下,两者都将放在当前目录下的dist/中。为了自己看,你可以为 HTTPie 构建一个轮子,这是一个用 Python 编写的命令行 HTTP 客户端,旁边还有一个sdist。
下面是为 HTTPie 包构建两种类型的发行版的结果:
$ git clone -q git@github.com:jakubroztocil/httpie.git
$ cd httpie
$ python setup.py -q sdist bdist_wheel $ ls -1 dist/
httpie-2.2.0.dev0-py3-none-any.whl
httpie-2.2.0.dev0.tar.gz
这就够了。您克隆项目,移动到它的根目录,然后调用python setup.py sdist bdist_wheel。你可以看到dist/包含了一个轮子和一个源分布。
默认情况下,得到的分布放在dist/中,但是您可以用-d / --dist-dir选项来改变它。您可以将它们放在临时目录中,而不是用于构建隔离:
$ tempdir="$(mktemp -d)" # Create a temporary directory
$ file "$tempdir"
/var/folders/jc/8_kd8uusys7ak09_lpmn30rw0000gk/T/tmp.GIXy7XKV: directory
$ python setup.py sdist -d "$tempdir"
$ python setup.py bdist_wheel --dist-dir "$tempdir"
$ ls -1 "$tempdir"
httpie-2.2.0.dev0-py3-none-any.whl
httpie-2.2.0.dev0.tar.gz
您可以将sdist和bdist_wheel步骤合并成一个,因为setup.py可以接受多个子命令:
$ python setup.py sdist -d "$tempdir" bdist_wheel -d "$tempdir"
如此处所示,您需要将选项如-d传递给每个子命令。
指定万向轮
万向轮是支持 Python 2 和 3 的纯 Python 项目的轮子。有多种方法可以告诉setuptools和distutils一个轮子应该是通用的。
选项 1 是在您项目的 setup.cfg 文件中指定选项:
[bdist_wheel] universal = 1
选项 2 是在命令行传递恰当命名的--universal标志:
$ python setup.py bdist_wheel --universal
选项 3 是使用它的options参数告诉setup()它自己关于标志的信息:
# setup.py
from setuptools import setup
setup(
# ....
options={"bdist_wheel": {"universal": True}}
# ....
)
虽然这三个选项中的任何一个都可以,但前两个是最常用的。你可以在 chardet 设置配置中看到这样的例子。之后,您可以使用前面所示的bdist_wheel命令:
$ python setup.py sdist bdist_wheel
无论您选择哪一个选项,最终的控制盘都是相同的。这种选择很大程度上取决于开发人员的偏好以及哪种工作流最适合您。
构建平台轮(macOS 和 Windows)
二进制发行版 是包含编译扩展的构建发行版的子集。扩展是你的 Python 包的非 Python 依赖或组件。
通常,这意味着你的包包含一个扩展模块或者依赖于一个用静态类型语言编写的库,比如 C,C++,Fortran,甚至是 Rust 或者 Go。平台轮的存在主要是针对单个平台,因为它们包含或依赖于扩展模块。
说了这么多,是时候造一个平台轮了!
根据您现有的开发环境,您可能需要完成一两个额外的先决步骤来构建平台轮子。下面的步骤将帮助您建立 C 和 C++扩展模块,这是目前最常见的类型。
在 macOS 上,您需要通过 xcode 获得命令行开发工具:
$ xcode-select --install
在 Windows 上,你需要安装微软 Visual C++ :
- 在浏览器中打开 Visual Studio 下载页面。
- 选择Visual Studio 工具→Visual Studio 构建工具→下载。
- 运行产生的
.exe安装程序。 - 在安装程序中,选择 C++构建工具→安装。
- 重启你的机器。
在 Linux 上,你需要一个 gcc 或者g++ / c++这样的编译器。
做好准备后,您就可以为 UltraJSON ( ujson)构建一个平台轮了,这是一个用纯 C 编写的 JSON 编码器和解码器,使用 Python 3 绑定。使用ujson是一个很好的玩具示例,因为它涵盖了几个基础:
- 它包含一个扩展模块,
ujson。 - 它依赖于要编译的 Python 开发头文件(
#include <Python.h>),但并不复杂。ujson就是为了做一件事,并且做好这件事,就是读写 JSON!
您可以从 GitHub 克隆这个项目,导航到它的目录,然后编译它:
$ git clone -q --branch 2.0.3 git@github.com:ultrajson/ultrajson.git
$ cd ultrajson
$ python setup.py bdist_wheel
您应该会看到大量的输出。这里有一个在 macOS 上的精简版本,其中使用了 Clang 编译器驱动程序:
clang -Wno-unused-result -Wsign-compare -Wunreachable-code -DNDEBUG -g ...
...
creating 'dist/ujson-2.0.3-cp38-cp38-macosx_10_15_x86_64.whl'
adding 'ujson.cpython-38-darwin.so'
以clang开头的代码行显示了对编译器的实际调用,包括一组编译标志。根据操作系统的不同,你可能还会看到像MSVC (Windows)或gcc (Linux)这样的工具。
如果在执行完上面的代码后遇到了一个fatal error,不用担心。你可以展开下面的方框,学习如何处理这个问题。
对ujson的这个setup.py bdist_wheel调用需要 Python 开发头文件,因为ujson.c拉入了<Python.h>。如果您没有将它们放在可搜索的位置,那么您可能会看到如下错误:
fatal error: 'Python.h' file not found
#include <Python.h>
要编译扩展模块,您需要将开发头文件保存在编译器可以找到它们的地方。
如果您使用的是 Python 3 的最新版本和虚拟环境工具,比如venv,那么 Python 开发头很可能会默认包含在编译和链接中。
否则,您可能会看到一个错误,指示找不到头文件:
fatal error: 'Python.h' file not found
#include <Python.h>
在这种情况下,您可以通过设置CFLAGS来告诉setup.py在其他地方寻找头文件。要找到头文件本身,可以使用python3-config:
$ python3-config --include
-I/Users/<username>/.pyenv/versions/3.8.2/include/python3.8
这告诉您 Python 开发头文件位于所示的目录中,您现在可以将它与python setup.py bdist_wheel一起使用:
$ CFLAGS="$(python3-config --include)" python setup.py bdist_wheel
更一般地说,您可以传递您需要的任何路径:
$ CFLAGS='-I/path/to/include' python setup.py bdist_wheel
在 Linux 上,您可能还需要单独安装头文件:
$ apt-get install -y python3-dev # Debian, Ubuntu
$ yum install -y python3-devel # CentOS, Fedora, RHEL
如果你检查 UltraJSON 的 setup.py ,那么你会看到它定制了一些编译器标志比如-D_GNU_SOURCE。通过setup.py控制编译过程的复杂性超出了本教程的范围,但是您应该知道,对编译和链接如何发生进行细粒度的控制是可能的。
如果你查看dist,那么你应该会看到创建的轮子:
$ ls dist/
ujson-2.0.3-cp38-cp38-macosx_10_15_x86_64.whl
请注意,该名称可能因平台而异。例如,您会在 64 位 Windows 上看到win_amd64.whl。
您可以查看 wheel 文件,发现它包含编译后的扩展名:
$ unzip -l dist/ujson-*.whl
...
Length Date Time Name
--------- ---------- ----- ----
105812 05-10-2020 19:47 ujson.cpython-38-darwin.so
...
这个例子显示了 macOS 的输出,ujson.cpython-38-darwin.so,这是一个共享对象(.so)文件,也称为动态库。
Linux:构建manylinux轮子
作为一名软件包开发人员,您很少想为一个单一的 Linux 变种构建轮子。Linux wheels 需要一套专门的约定和工具,以便它们可以跨不同的 Linux 环境工作。
与 macOS 和 Windows 的 wheels 不同,在一个 Linux 版本上构建的 wheels 不能保证在另一个 Linux 版本上工作,即使是具有相同机器架构的版本。事实上,如果您在现成的 Linux 容器上构建一个轮子,那么如果您试图上传它,PyPI 甚至不会接受这个轮子!
如果您希望您的包可以在一系列 Linux 客户机上使用,那么您需要一个manylinux轮子。manylinux轮是一种特殊类型的平台轮,被大多数 Linux 变体所接受。它必须在一个特定的环境中构建,并且需要一个名为auditwheel的工具来重命名车轮文件,以表明它是一个manylinux车轮。
注意:即使你是从开发者的角度而不是从用户的角度来阅读本教程,在继续本节之前,请确保你已经阅读了关于和manylinux滚轮标签的章节。
建立一个manylinux轮子可以让你瞄准更广泛的用户平台。 PEP 513 指定了 CentOS 的一个特定(和古老)版本,并提供了一系列 Python 版本。在 CentOS 和 Ubuntu 或任何其他发行版之间的选择没有任何特殊的区别。要点是构建环境由一个普通的 Linux 操作系统和一组有限的外部共享库组成,这些库对于不同的 Linux 变体是通用的。
谢天谢地,你不必亲自去做。PyPA 提供了一组 Docker 图像,只需点击几下鼠标就能提供这个环境:
- 选项 1 是从您的开发机器上运行
docker,并使用 Docker 卷挂载您的项目,以便它可以在容器文件系统中被访问。 - 选项 2 是使用一个 CI/CD 解决方案,比如 CircleCI、GitHub Actions、Azure DevOps 或 Travis-CI,它们将提取你的项目并在一个动作(比如 push 或 tag)上运行构建。
为不同的manylinux口味提供了 Docker 图像:
manylinux标签 | 体系结构 | Docker 图像 |
|---|---|---|
manylinux1 | x86-64 | quay.io/pypa/manylinux1_x86_64 |
manylinux1 | i686 | quay.io/pypa/manylinux1_i686 |
manylinux2010 | x86-64 | quay.io/pypa/manylinux2010_x86_64 |
manylinux2010 | i686 | quay.io/pypa/manylinux2010_i686 |
manylinux2014 | x86-64 | quay.io/pypa/manylinux2014_x86_64 |
manylinux2014 | i686 | quay.io/pypa/manylinux2014_i686 |
manylinux2014 | aarh64 足球俱乐部 | quay . io/pypa/manylinox 2014 _ aach 64 |
manylinux2014 | ppc64le | quay . io/pypa/manylinox 2014 _ ppc64 le |
manylinux2014 | s390x | quay.io/pypa/manylinux2014_s390x |
为了开始,PyPA 还提供了一个示例库, python-manylinux-demo ,这是一个结合 Travis-CI 构建manylinux轮子的演示项目。
虽然构建轮子作为远程托管 CI 解决方案的一部分很常见,但是您也可以在本地构建manylinux轮子。为此,你需要安装 Docker 。Docker 桌面可用于 macOS、Windows 和 Linux。
首先,克隆演示项目:
$ git clone -q git@github.com:pypa/python-manylinux-demo.git
$ cd python-manylinux-demo
接下来,分别为manylinux1 Docker 映像和平台定义几个 shell 变量:
$ DOCKER_IMAGE='quay.io/pypa/manylinux1_x86_64'
$ PLAT='manylinux1_x86_64'
DOCKER_IMAGE变量是 PyPA 为建造manylinux车轮维护的图像,托管在 Quay.io 。平台(PLAT)是提供给auditwheel的必要信息,让它知道应用什么平台标签。
现在,您可以提取 Docker 图像并在容器中运行 wheel-builder 脚本:
$ docker pull "$DOCKER_IMAGE"
$ docker container run -t --rm \
-e PLAT=$PLAT \
-v "$(pwd)":/io \
"$DOCKER_IMAGE" /io/travis/build-wheels.sh
这告诉 Docker 在manylinux1_x86_64 Docker 容器中运行build-wheels.sh shell 脚本,将PLAT作为容器中可用的环境变量传递。由于您使用了-v(或--volume)来绑定挂载一个卷,容器中生成的轮子现在可以在您的主机上的wheelhouse目录中访问:
$ ls -1 wheelhouse
python_manylinux_demo-1.0-cp27-cp27m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp27-cp27mu-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp35-cp35m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp36-cp36m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp37-cp37m-manylinux1_x86_64.whl
python_manylinux_demo-1.0-cp38-cp38-manylinux1_x86_64.whl
在几个简短的命令中,您就有了一组用于 CPython 2.7 到 3.8 的manylinux1轮子。一种常见的做法也是迭代不同的架构。例如,您可以对quay.io/pypa/manylinux1_i686 Docker 图像重复这个过程。这将建立针对 32 位(i686)架构的manylinux1轮子。
如果你想更深入地研究制造轮子,那么下一步最好是向最好的人学习。从 Python Wheels 页面开始,选择一个项目,导航到它的源代码(在 GitHub、GitLab 或 Bitbucket 之类的地方),亲自看看它是如何构建轮子的。
Python Wheels 页面上的许多项目都是纯 Python 项目,并分发通用轮子。如果您正在寻找更复杂的情况,那么请留意使用扩展模块的包。这里有两个例子可以吊起你的胃口:
如果你对建造manylinux车轮感兴趣,这两个项目都是著名的项目,提供了很好的学习范例。
捆绑共享库
另一个挑战是为依赖外部共享库的包构建轮子。manylinux图像包含一组预先筛选的库,如libpthread.so.0和libc.so.6。但是如果你依赖于列表之外的东西,比如 ATLAS 或者 GFortran 呢?
在这种情况下,有几种解决方案可供选择:
auditwheel将外部库捆绑成一个已经构建好的轮子。delocate在 macOS 上也是如此。
便利地,auditwheel出现在manylinux Docker 图像上。使用auditwheel和delocate只需要一个命令。只需告诉他们有关车轮文件的信息,剩下的工作由他们来完成:
$ auditwheel repair <path-to-wheel.whl> # For manylinux
$ delocate-wheel <path-to-wheel.whl> # For macOS
这将通过项目的setup.py检测所需的外部库,并将它们捆绑到轮子中,就像它们是项目的一部分一样。
利用auditwheel和delocate的项目的一个例子是 pycld3 ,它为紧凑语言检测器 v3 (CLD3)提供 Python 绑定。
pycld3包依赖于 libprotobuf ,不是一般安装的库。如果你偷看一个 pycld3 macOS 轮的内部,那么你会看到libprotobuf.22.dylib包含在那里。这是一个动态链接的共享库,它被捆绑到轮子中:
$ unzip -l pycld3-0.20-cp38-cp38-macosx_10_15_x86_64.whl
...
51 04-10-2020 11:46 cld3/__init__.py
939984 04-10-2020 07:50 cld3/_cld3.cpython-38-darwin.so
2375836 04-10-2020 07:50 cld3/.dylibs/libprotobuf.22.dylib --------- -------
3339279 8 files
车轮预装了libprotobuf。一个.dylib类似于一个 Unix .so文件或者 Windows .dll文件,但是我承认我不知道除此之外的本质区别。
auditwheel和delocate知道包括libprotobuf是因为 setup.py通过libraries的论证告诉他们:
setup(
# ...
libraries=["protobuf"],
# ...
)
这意味着auditwheel和delocate为用户省去了安装protobuf的麻烦,只要他们从一个平台和 Python 组合中安装,这个平台和 Python 组合有一个匹配的轮子。
如果你正在发布一个像这样有外部依赖的包,那么你可以帮你的用户一个忙,使用auditwheel或者delocate来省去他们自己安装依赖的额外步骤。
在持续集成中构建车轮
在本地机器上构建轮子的另一种方法是在项目的 CI 管道中自动构建轮子。
有无数的 CI 解决方案与主要的代码托管服务相集成。其中有 Appveyor 、 Azure DevOps 、 BitBucket Pipelines 、 Circle CI 、 GitLab 、 GitHub Actions 、 Jenkins 和 Travis CI 等等。
本教程的目的不是判断哪种 CI 服务最适合构建车轮,并且考虑到 CI 支持的发展速度,任何列出哪些 CI 服务支持哪些容器的列表都会很快过时。然而,这一节可以帮助你开始。
如果你正在开发一个纯 Python 包,那么bdist_wheel步骤是一个幸福的单行程序:你在哪个容器操作系统和平台上构建轮子基本上无关紧要。事实上,所有主要的 CI 服务都应该通过在项目中的一个特殊的 YAML 文件中定义步骤,使您能够以一种简洁的方式做到这一点。
例如,下面是您可以在 GitHub 操作中使用的语法:
1name: Python wheels 2on: 3 release: 4 types: 5 - created 6jobs: 7 wheels: 8 runs-on: ubuntu-latest 9 steps: 10 - uses: actions/checkout@v2 11 - name: Set up Python 3.x 12 uses: actions/setup-python@v2 13 with: 14 python-version: '3.x' 15 - name: Install dependencies 16 run: python -m pip install --upgrade setuptools wheel 17 - name: Build wheels 18 run: python setup.py bdist_wheel 19 - uses: actions/upload-artifact@v2 20 with: 21 name: dist 22 path: dist
在此配置文件中,您使用以下步骤构建一个轮子:
- 在第 8 行中,您指定作业应该在 Ubuntu 机器上运行。
- 在第 10 行中,您使用
checkout动作来设置您的项目存储库。 - 在第 14 行中,您告诉 CI 运行程序使用 Python 3 的最新稳定版本。
- 在第 21 行中,您请求生成的轮子作为工件可用,一旦作业完成,您可以从 UI 下载。
然而,如果您有一个复杂的项目(可能是一个带有 C 扩展或 Cython 代码的项目),并且您正在努力创建一个 CI/CD 管道来自动构建轮子,那么可能会涉及到额外的步骤。这里有几个项目,你可以通过例子来学习:
许多项目推出自己的配置项配置。然而,已经出现了一些解决方案来减少在配置文件中指定的构建轮子的代码量。您可以直接在 CI 服务器上使用 cibuildwheel 工具来减少构建多个平台轮子所需的代码和配置行。还有 multibuild ,它提供了一组 shell 脚本来帮助在 Travis CI 和 AppVeyor 上构建轮子。
确保你的车轮旋转正确
构建结构正确的车轮可能是一项精细的操作。例如,如果你的 Python 包使用了一个 src布局,而你忘记了在setup.py 中正确地指定它,那么产生的轮子可能在错误的位置包含了一个目录。
在bdist_wheel之后可以使用的一个检查是 check-wheel-contents 工具。它会查找常见问题,例如包目录结构异常或存在重复文件:
$ check-wheel-contents dist/*.whl
dist/ujson-2.0.3-cp38-cp38-macosx_10_15_x86_64.whl: OK
在这种情况下,check-wheel-contents表示使用ujson滚轮的一切都检查完毕。如果没有,stdout将会显示一个可能问题的概要,就像flake8中的过磅信息一样。
另一种确认你建造的轮子是否有合适的材料的方法是使用 TestPyPI 。首先,您可以在那里上传软件包:
$ python -m twine upload \
--repository-url https://test.pypi.org/legacy/ \
dist/*
然后,您可以下载相同的包进行测试,就像它是真实的一样:
$ python -m pip install \
--index-url https://test.pypi.org/simple/ \
<pkg-name>
这允许你通过上传然后下载你自己的项目来测试你的轮子。
上传 Python 轮子到 PyPI
现在是上传你的 Python 包的时候了。由于默认情况下sdist和轮子都放在dist/目录中,所以您可以使用 twine 工具来上传它们,这是一个用于将包发布到 PyPI 的实用程序:
$ python -m pip install -U twine
$ python -m twine upload dist/*
由于默认情况下sdist和bdist_wheel都输出到dist/,您可以放心地告诉twine使用 shell 通配符(dist/*)上传dist/下的所有内容。
结论
理解轮子在 Python 生态系统中扮演的关键角色可以让 Python 包的用户和开发者的生活更加轻松。此外,提高您在轮子方面的 Python 素养将有助于您更好地理解当您安装一个包时会发生什么,以及在越来越少的情况下,操作何时出错。
在本教程中,您学习了:
- 什么是车轮,它们与源分布相比如何
- 如何使用轮子来控制包装安装过程
- 万向、纯蟒、平台车轮有什么区别
- 如何为你自己的 Python 包创建和分发轮子
现在,您已经从用户和开发人员的角度对轮子有了很好的理解。您已经准备好打造自己的车轮,让项目的安装过程变得快速、方便和稳定。
请参阅下一节的附加阅读材料,深入了解快速扩张的车轮生态系统。
资源
Python Wheels 页面致力于跟踪 PyPI 上下载最多的 360 个包中对 Wheels 的支持。在本教程中,采用率是相当可观的,360 个中有 331 个,大约 91%。
有许多 Python 增强提案(pep)帮助规范和发展了 wheel 格式:
- PEP 425 -已构建发行版的兼容性标签
- PEP 427 -车轮二进制包格式 1.0
- PEP 491 -车轮二进制包格式 1.9
- PEP 513 -一个用于可移植 Linux 构建发行版的平台标签
- PEP 571-
manylinux2010平台标签 - PEP 599-
manylinux2014平台标签
以下是本教程中提到的各种车轮包装工具的列表:
- T2
pypa/wheel - T2
pypa/auditwheel - T2
pypa/manylinux pypa/python-manylinux-demo- T2
jwodder/check-wheel-contents - T2
matthew-brett/delocate - T2
matthew-brett/multibuild - T2
joerick/cibuildwheel
Python 文档中有几篇文章介绍了 wheels 和源代码发行版:
最后,这里有一些来自 PyPA 的更有用的链接:
- 打包您的项目
- Python 打包概述**********

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









