







原文:RealPython
Python 3.9:很酷的新特性供您尝试
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.9 中很酷的新特性
Python 3.9 来了!在过去的一年里,来自世界各地的志愿者一直致力于 Python 的改进。虽然测试版已经发布了一段时间,但 Python 3.9 的第一个正式版本于 2020 年 10 月 5 日在发布。
Python 的每个版本都包括新的、改进的和废弃的特性,Python 3.9 也不例外。文档给出了变更的完整列表。下面,您将深入了解最新版本的 Python 带来的最酷的特性。
在本教程中,您将了解到:
- 使用时区访问和计算
- 有效合并和更新字典
- 基于表达式使用装饰器
- 结合类型提示和其他注释
要自己尝试新功能,您需要安装 Python 3.9。可以从 Python 主页下载安装。或者,你可以使用官方 Docker 图片来尝试一下。参见 Docker 中的运行 Python 版本:如何尝试最新的 Python 版本了解更多详情。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
**额外学习材料:**查看真实 Python 播客第 30 集和这段办公时间记录Python 3.9 技巧和与真实 Python 团队成员的小组讨论。
正确的时区支持
Python 通过标准库中的 datetime 模块广泛支持处理日期和时间。然而,对使用时区的支持却有所欠缺。到目前为止,推荐的处理时区的方式一直是使用第三方库,比如 dateutil 。
在普通 Python 中处理时区的最大挑战是您必须自己实现时区规则。一个datetime支持设置时区,但是只有 UTC 立即可用。其他时区需要在抽象的 tzinfo 基类之上实现。
访问时区
你可以像这样从datetime库中得到一个 UTC 时间戳:
>>> from datetime import datetime, timezone
>>> datetime.now(tz=timezone.utc)
datetime.datetime(2020, 9, 8, 15, 4, 15, 361413, tzinfo=datetime.timezone.utc)
注意,产生的时间戳是时区感知的。它有一个由tzinfo指定的附加时区。没有任何时区信息的时间戳被称为幼稚。
保罗·甘索多年来一直是dateutil的维护者。他在 2019 年加入了 Python 核心开发人员,并帮助添加了一个新的 zoneinfo 标准库,使时区工作更加方便。
zoneinfo提供对互联网号码分配机构(IANA) 时区数据库的访问。IANA 每年都会几次更新它的数据库,它是时区信息最权威的来源。
使用zoneinfo,您可以获得一个描述数据库中任何时区的对象:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
zoneinfo.ZoneInfo(key='America/Vancouver')
您可以使用几个键中的一个来访问时区。在这种情况下,您使用"America/Vancouver"。
注意: zoneinfo使用驻留在您本地计算机上的 IANA 时区数据库。有可能——特别是在 Windows 上——你没有这样的数据库或者zoneinfo找不到它。如果您得到如下错误,那么zoneinfo无法定位时区数据库:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZoneInfoNotFoundError: 'No time zone found with key America/Vancouver'
IANA 时区数据库的 Python 实现可以在 PyPI 上作为 tzdata 获得。可以用 pip 安装:
$ python -m pip install tzdata
一旦安装了tzdata,zoneinfo应该能够读取所有支持的时区的信息。tzdata由 Python 核心团队维护。请注意,为了访问 IANA 时区数据库中的最新更改,您需要保持软件包更新。
您可以使用datetime函数的tz或tzinfo参数制作时区感知时间戳:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> datetime.now(tz=ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 9, 8, 17, 12, 0, 939001,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
>>> datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
datetime.datetime(2020, 10, 5, 3, 9,
tzinfo=zoneinfo.ZoneInfo(key='America/Vancouver'))
用时间戳记录时区对于记录非常有用。它还方便了时区之间的转换:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
>>> release.astimezone(ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 10, 5, 12, 9,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
请注意,奥斯陆时间比温哥华时间晚九个小时。
调查时区
IANA 时区数据库非常庞大。您可以使用zoneinfo.available_timezones()列出所有可用的时区:
>>> import zoneinfo
>>> zoneinfo.available_timezones()
{'America/St_Lucia', 'SystemV/MST7', 'Asia/Aqtau', 'EST', ... 'Asia/Beirut'}
>>> len(zoneinfo.available_timezones())
609
数据库中时区的数量可能因您的安装而异。在本例中,您可以看到列出了609时区名称。每个时区都记录了已经发生的历史变化,您可以更仔细地观察每个时区。
Kiritimati ,又名圣诞岛,目前位于世界最西部时区,UTC+14。情况并非总是如此。1995 年以前,该岛位于协调世界时 10 时国际日期变更线的另一侧。为了跨越日期线,Kiritimati 完全跳过了 1994 年 12 月 31 日。
通过仔细观察"Pacific/Kiritimati"时区对象,您可以看到这是如何发生的:
>>> from datetime import datetime, timedelta
>>> from zoneinfo import ZoneInfo
>>> hour = timedelta(hours=1)
>>> tz_kiritimati = ZoneInfo("Pacific/Kiritimati")
>>> ts = datetime(1994, 12, 31, 9, 0, tzinfo=ZoneInfo("UTC"))
>>> ts.astimezone(tz_kiritimati)
datetime.datetime(1994, 12, 30, 23, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
>>> (ts + 1 * hour).astimezone(tz_kiritimati)
datetime.datetime(1995, 1, 1, 0, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
1994 年 12 月 30 日,Kiritimati 岛上的时钟显示 23:00 时,新年开始了一个小时。1994 年 12 月 31 日,从来没有发生过!
您还可以看到相对于 UTC 的偏移量发生了变化:
>>> tz_kiritimati.utcoffset(datetime(1994, 12, 30)) / hour
-10.0
>>> tz_kiritimati.utcoffset(datetime(1995, 1, 1)) / hour
14.0
.utcoffset()返回一个timedelta。计算一个给定的timedelta代表多少小时的最有效的方法是用它除以一个代表一小时的timedelta。
关于时区还有很多其他奇怪的故事。Paul Ganssle 在他的 PyCon 2019 演讲中谈到了其中的一些问题,处理时区:你希望不需要知道的一切。看看能不能在时区数据库里找到其他人的踪迹。
使用最佳实践
与时区打交道可能会很棘手。然而,随着标准库中zoneinfo的出现,事情变得简单了一些。这里有一些建议在处理日期和时间时要记住:
-
民用时间像开会、火车离站或音乐会的时间,最好存储在他们的本地时区。您通常可以通过存储一个简单的时间戳和时区的 IANA 键来实现这一点。以字符串形式存储的民用时间的一个例子是
"2020-10-05T14:00:00,Europe/Oslo"。拥有关于时区的信息可以确保您总是能够恢复信息,即使时区本身发生了变化。 -
时间戳代表特定的时刻,通常记录事件的顺序。计算机日志就是一个例子。您不希望您的日志因为您的时区从夏令时变为标准时间而变得混乱。通常,您会将这些类型的时间戳存储为 UTC 中的原始日期时间。
因为 IANA 时区数据库一直在更新,所以您应该注意保持本地时区数据库的同步。如果您正在运行任何对时区敏感的应用程序,这一点尤其重要。
在 Mac 和 Linux 上,您通常可以信任您的系统来保持本地数据库的更新。如果你依赖于 tzdata 包,那么你应该记得不时地更新它。特别是,你不应该把它固定在一个特定的版本上好几年。
像"America/Vancouver"这样的名字可以让你明确地访问给定的时区。但是,当与用户交流时区相关的日期时间时,最好使用常规的时区名称。这些在时区对象上作为.tzname()可用:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> tz = ZoneInfo("America/Vancouver")
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=tz)
>>> f"Release date: {release:%b %d, %Y at %H:%M} {tz.tzname(release)}"
'Release date: Oct 05, 2020 at 03:09 PDT'
您需要向.tzname()提供一个时间戳。这是必要的,因为时区的名称可能会随时间而改变,例如夏令时:
>>> tz.tzname(datetime(2021, 1, 28))
'PST'
冬天,温哥华处于太平洋标准时间(PST) ,而夏天,温哥华处于太平洋夏令时(PDT) 。
zoneinfo仅在 Python 3.9 及更高版本的标准库中可用。然而,如果您正在使用 Python 的早期版本,那么您仍然可以利用zoneinfo。PyPI 上有后端口,可以安装 pip :
$ python -m pip install backports.zoneinfo
当导入zoneinfo时,您可以使用下面的习语:
try:
import zoneinfo
except ImportError:
from backports import zoneinfo
这使得您的程序与 3.6 及更高版本的所有 Python 兼容。关于zoneinfo的更多细节见 PEP 615 。
字典更新更简单
字典是 Python 中最基本的数据结构之一。它们在语言中随处可见,并且随着时间的推移得到了极大的优化。
有几种方法可以合并两本词典。然而,该语法要么有点晦涩,要么很麻烦:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> {**pycon, **europython}
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> merged = pycon.copy()
>>> for key, value in europython.items():
... merged[key] = value
...
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
这两种方法都是在不改变原始数据的情况下合并字典。注意"Cleveland"已经被merged中的"Edinburgh"覆盖。您也可以就地更新字典:
>>> pycon.update(europython)
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
不过,这改变了你原来的字典。请记住,.update()不会返回更新后的字典,所以在不改变原始数据的情况下使用.update()的巧妙尝试并不奏效:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> merged = pycon.copy().update(europython) # Does NOT work
>>> print(merged)
None
注意merged是 None ,当两个字典合并时,结果已经被丢弃。你可以使用 Python 3.8 中引入的海象操作符 ( :=)来完成这项工作:
>>> (merged := pycon.copy()).update(europython)
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
尽管如此,这不是一个特别可读或令人满意的解决方案。
在 PEP 584 的基础上,新版 Python 引入了两个新的字典操作符: union ( |)和 in-place union ( |=)。您可以使用|来合并两个字典,而|=将就地更新一个字典:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> pycon | europython
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> pycon |= europython
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
如果d1和d2是两本字典,那么d1 | d2和{**d1, **d2}做的一样。|运算符用于计算集合的并集,因此您可能已经熟悉这个符号了。
使用|的一个优点是,它可以处理不同的类似字典的类型,并在合并过程中保持这种类型:
>>> from collections import defaultdict
>>> europe = defaultdict(lambda: "", {"Norway": "Oslo", "Spain": "Madrid"})
>>> africa = defaultdict(lambda: "", {"Egypt": "Cairo", "Zimbabwe": "Harare"})
>>> europe | africa
defaultdict(<function <lambda> at 0x7f0cb42a6700>,
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'})
>>> {**europe, **africa}
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'}
当您想要有效地处理丢失的按键时,可以使用 defaultdict 。注意|保留了defaultdict,而{**europe, **africa}没有。
在|如何为字典工作和+如何为列表工作之间有一些相似之处。事实上,+操作符是最初提出的来合并字典。当你观察就地操作者时,这种对应变得更加明显。
|=的基本用途是就地更新字典,类似于.update():
>>> libraries = {
... "collections": "Container datatypes",
... "math": "Mathematical functions",
... }
>>> libraries |= {"zoneinfo": "IANA time zone support"}
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support'}
当您用|合并字典时,两个字典都需要是正确的字典类型。另一方面,就地操作符(|=)乐于使用任何类似字典的数据结构:
>>> libraries |= [("graphlib", "Functionality for graph-like structures")]
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support',
'graphlib': 'Functionality for graph-like structures'}
在这个例子中,您从一个 2 元组列表中更新libraries。当您想要合并的两个字典中有重叠的关键字时,会保留最后一个值:
>>> asia = {"Georgia": "Tbilisi", "Japan": "Tokyo"}
>>> usa = {"Missouri": "Jefferson City", "Georgia": "Atlanta"}
>>> asia | usa
{'Georgia': 'Atlanta', 'Japan': 'Tokyo', 'Missouri': 'Jefferson City'}
>>> usa | asia
{'Missouri': 'Jefferson City', 'Georgia': 'Tbilisi', 'Japan': 'Tokyo'}
在第一个例子中,"Georgia"指向"Atlanta",因为usa是合并中的最后一个字典。来自asia的值"Tbilisi"已被覆盖。注意,键"Georgia"仍然是结果字典中的第一个,因为它是asia中的第一个元素。颠倒合并的顺序会改变"Georgia"的位置和值。
运算符|和|=不仅被添加到常规字典中,还被添加到许多类似字典的类中,包括UserDictChainMapOrderedDictdefaultdictWeakKeyDictionaryWeakValueDictionary_EnvironMappingProxyType。它们已经而不是被添加到抽象基类 Mapping 或 MutableMapping 中。 Counter 容器已经使用|寻找最大计数。这一点没有改变。
您可以通过分别实现 .__or__() 和 .__ior__() 来改变|和|=的行为。详见 PEP 584 。
更灵活的装饰者
传统上,装饰器必须是一个命名的、可调用的对象,通常是一个函数或类。 PEP 614 允许装饰者是任何可调用的表达式。
大多数人不认为旧的修饰语法是限制性的。事实上,为装饰者放宽语法主要有助于一些特殊的用例。根据 PEP,激励用例与 GUI 框架中的回调相关。
PyQT 使用信号和插槽来连接小部件和回调。从概念上讲,你可以像下面这样把button的clicked信号连接到插槽say_hello():
button = QPushButton("Say hello")
@button.clicked.connect
def say_hello():
message.setText("Hello, World!")
当你点击按钮向问好时,将会显示文本Hello, World!。
**注意:**这不是一个完整的例子,如果您试图运行它,它会引发一个错误。它故意保持简短,以保持对装饰者的关注,而不是陷入 PyQT 如何工作的细节中。
有关 PyQt 入门和设置完整应用程序的更多信息,请参见 Python 和 PyQT:构建 GUI 桌面计算器。
现在假设您有几个按钮,为了跟踪它们,您将它们存储在一个字典中:
buttons = {
"hello": QPushButton("Say hello"),
"leave": QPushButton("Goodbye"),
"calculate": QPushButton("3 + 9 = 12"),
}
这一切都很好。然而,如果您想使用装饰器将一个按钮连接到一个插槽,这就给你带来了挑战。在 Python 的早期版本中,当使用装饰器时,不能使用方括号来访问项目。您需要执行如下操作:
hello_button = buttons["hello"]
@hello_button.clicked.connect
def say_hello():
message.setText("Hello, World!")
在 Python 3.9 中,这些限制被取消,现在您可以使用任何表达式,包括访问字典中的项的表达式:
@buttons["hello"].clicked.connect
def say_hello():
message.setText("Hello, World!")
虽然这不是一个大的变化,但在某些情况下,它允许您编写更干净的代码。扩展的语法也使得在运行时动态选择装饰器变得更加容易。假设您有以下可用的装饰者:
# story.py
import functools
def normal(func):
return func
def shout(func):
@functools.wraps(func)
def shout_decorator(*args, **kwargs):
return func(*args, **kwargs).upper()
return shout_decorator
def whisper(func):
@functools.wraps(func)
def whisper_decorator(*args, **kwargs):
return func(*args, **kwargs).lower()
return whisper_decorator
@normal装饰器根本不改变原始函数,而@shout和@whisper使函数返回的任何文本大写或小写。然后,您可以将对这些装饰器的引用存储在一个字典中,并让用户可以使用它们:
# story.py (continued)
DECORATORS = {"normal": normal, "shout": shout, "whisper": whisper}
voice = input(f"Choose your voice ({', '.join(DECORATORS)}): ")
@DECORATORS[voice]
def get_story():
return """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into
the book her sister was reading, but it had no pictures or
conversations in it, "and what is the use of a book," thought Alice
"without pictures or conversations?"
"""
print(get_story())
当您运行这个脚本时,会询问您将哪个装饰器应用于故事。然后,生成的文本被打印到屏幕上:
$ python3.9 story.py
Choose your voice (normal, shout, whisper): shout
ALICE WAS BEGINNING TO GET VERY TIRED OF SITTING BY HER SISTER ON THE
BANK, AND OF HAVING NOTHING TO DO: ONCE OR TWICE SHE HAD PEEPED INTO
THE BOOK HER SISTER WAS READING, BUT IT HAD NO PICTURES OR
CONVERSATIONS IN IT, "AND WHAT IS THE USE OF A BOOK," THOUGHT ALICE
"WITHOUT PICTURES OR CONVERSATIONS?"
这个例子就好像@shout已经应用于get_story()一样。然而,在这里,它是在运行时根据您的输入应用的。与按钮示例一样,通过使用临时变量,您可以在早期版本的 Python 中实现相同的效果。
关于 decorator 的更多信息,请查看 Python Decorators 的初级读本。关于轻松语法的更多细节,请参见 PEP 614 。
带注释的类型提示
在 Python 3.0 中,函数注释被引入。该语法支持向 Python 函数添加任意元数据。下面是一个向公式添加单位的示例:
# calculator.py
def speed(distance: "feet", time: "seconds") -> "miles per hour":
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
在本例中,注释仅用作读者的文档。稍后您将看到如何在运行时访问注释。
PEP 484 建议对类型提示使用注释。随着类型提示越来越受欢迎,它们在 Python 中已经挤掉了注释的其他用途。
由于除了静态类型之外还有几个注释的用例, PEP 593 引入了 typing.Annotated ,你可以用它将类型提示与其他信息结合起来。您可以像这样重做上面的calculator.py示例:
# calculator.py
from typing import Annotated
def speed(
distance: Annotated[float, "feet"], time: Annotated[float, "seconds"] ) -> Annotated[float, "miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Annotated至少需要两个参数。第一个参数是常规类型提示,其余参数是任意元数据。类型检查器只关心第一个参数,将元数据的解释留给您和您的应用程序。类型检查器会将类似于Annotated[float, "feet"]的类型提示与float同等对待。
您可以像往常一样通过.__annotations__访问注释。从calculator.py进口speed():
>>> from calculator import speed
>>> speed.__annotations__
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
每个注释都可以在字典中找到。您用Annotated定义的元数据存储在.__metadata__中:
>>> speed.__annotations__["distance"].__metadata__
('feet',)
>>> {var: th.__metadata__[0] for var, th in speed.__annotations__.items()}
{'distance': 'feet', 'time': 'seconds', 'return': 'miles per hour'}
最后一个示例通过读取每个变量的第一个元数据项来挑选出所有的单元。另一种在运行时访问类型提示的方法是使用来自typing模块的get_type_hints()。get_type_hints()默认情况下会忽略元数据:
>>> from typing import get_type_hints
>>> from calculator import speed
>>> get_type_hints(speed)
{'distance': <class 'float'>,
'time': <class 'float'>,
'return': <class 'float'>}
这应该允许大多数在运行时访问类型提示的程序继续工作,而无需更改。您可以使用新的可选参数include_extras来请求包含元数据:
>>> get_type_hints(speed, include_extras=True)
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
使用Annotated可能会导致非常冗长的代码。保持代码简短易读的一个方法是使用类型别名。您可以定义表示注释类型的新变量:
# calculator.py
from typing import Annotated
Feet = Annotated[float, "feet"] Seconds = Annotated[float, "seconds"] MilesPerHour = Annotated[float, "miles per hour"]
def speed(distance: Feet, time: Seconds) -> MilesPerHour:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
类型别名可能需要一些工作来设置,但是它们可以使您的代码非常清晰易读。
如果您有一个广泛使用注释的应用程序,您也可以考虑实现一个注释工厂。将以下内容添加到calculator.py的顶部:
# calculator.py
from typing import Annotated
class AnnotationFactory:
def __init__(self, type_hint):
self.type_hint = type_hint
def __getitem__(self, key):
if isinstance(key, tuple):
return Annotated[(self.type_hint, ) + key]
else:
return Annotated[self.type_hint, key]
def __repr__(self):
return f"{self.__class__.__name__}({self.type_hint})"
AnnotationFactory可以用不同的元数据创建Annotated对象。您可以使用注释工厂来创建更多的动态别名。更新calculator.py以使用AnnotationFactory:
# calculator.py (continued)
Float = AnnotationFactory(float)
def speed(
distance: Float["feet"], time: Float["seconds"] ) -> Float["miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Float[<metadata>]代表Annotated[float, <metadata>],所以这个例子的工作方式和前面两个例子完全一样。
更强大的 Python 解析器
Python 3.9 最酷的特性之一是你在日常编码生活中不会注意到的。Python 解释器的一个基本组件是解析器。在最新版本中,解析器被重新实现。
从一开始,Python 就使用一个基本的 LL(1)解析器将源代码解析成解析树。您可以将 LL(1)解析器想象成一次读取一个字符,并计算出如何在不回溯的情况下解释源代码的解析器。
使用简单解析器的一个优点是它的实现和推理相当简单。一个缺点是有个难题需要你用特殊的技巧来规避。
在一系列博客文章中,Python 的创始人吉多·范·罗苏姆调查了 PEG(解析表达式语法)解析器。PEG 解析器比 LL(1)解析器更强大,并且不需要特殊的修改。由于 Guido 的研究,在 Python 3.9 中实现了一个 PEG 解析器。详见 PEP 617 。
目标是让新的 PEG 解析器产生与旧的 LL(1)解析器相同的抽象语法树(AST) 。最新版本实际上附带了这两种解析器。虽然 PEG 解析器是默认的,但是您可以通过使用 -X oldparser 命令行标志来使用旧的解析器运行您的程序:
$ python -X oldparser script_name.py
或者,您可以设置 PYTHONOLDPARSER 环境变量。
旧的解析器将在 Python 3.10 中被移除。这将允许没有 LL(1)语法限制的新特性。目前正在考虑包含在 Python 3.10 中的一个这样的特性是结构模式匹配,如 PEP 622 中所述。
让两个解析器都可用对于验证新的 PEG 解析器来说是非常好的。您可以在两个解析器上运行任何代码,并在 AST 级别进行比较。在测试过程中,对整个标准库以及许多流行的第三方包进行了编译和比较。
您还可以比较这两种解析器的性能。一般来说,PEG 解析器和 LL(1)的性能相似。在整个标准库中,PEG 解析器稍微快一点,但是它也使用稍微多一点的内存。实际上,当使用新的解析器时,您不会注意到任何性能上的变化,无论是好是坏。
其他非常酷的功能
到目前为止,您已经看到了 Python 3.9 中最大的新特性。然而,Python 的每个新版本也包括许多小的变化。官方文件包括了所有这些变化的列表。在本节中,您将了解一些其他非常酷的新特性,您可以开始使用它们。
字符串前缀和后缀
如果您需要删除一个字符串的开头或结尾,那么.strip()似乎可以完成这项工作:
>>> "three cool features in Python".strip(" Python")
'ree cool features i'
后缀" Python"已经被删除,但是字符串开头的"th"也被删除。.strip()的实际行为有时令人惊讶——并引发了许多 bug 报告。人们很自然地认为.strip(" Python")会删除子串" Python",但它删除的是单个字符" "、"P"、"y"、"t"、"h"、"o"和"n"。
要真正删除字符串后缀,您可以这样做:
>>> def remove_suffix(text, suffix):
... if text.endswith(suffix):
... return text[:-len(suffix)]
... else:
... return text
...
>>> remove_suffix("three cool features in Python", suffix=" Python")
'three cool features in'
这样效果更好,但是有点麻烦。这段代码还有一个微妙的错误:
>>> remove_suffix("three cool features in Python", suffix="")
''
如果后缀碰巧是空字符串,不知何故整个字符串都被删除了。这是因为空字符串的长度是 0,所以text[:0]最终被返回。您可以通过将测试改为在suffix and text.endswith(suffix)上来解决这个问题。
在 Python 3.9 中,有两个新的字符串方法可以解决这个用例。您可以使用.removeprefix()和.removesuffix()分别删除字符串的开头或结尾:
>>> "three cool features in Python".removesuffix(" Python")
'three cool features in'
>>> "three cool features in Python".removeprefix("three ")
'cool features in Python'
>>> "three cool features in Python".removeprefix("Something else")
'three cool features in Python'
注意,如果给定的前缀或后缀与字符串不匹配,那么字符串将原封不动地返回。
.removeprefix()和.removesuffix()最多去掉一个词缀。如果你想确保将它们全部移除,那么你可以使用 while循环:
>>> text = "Waikiki"
>>> text.removesuffix("ki")
'Waiki'
>>> while text.endswith("ki"):
... text = text.removesuffix("ki")
...
>>> text
'Wai'
关于.removeprefix()和.removesuffix()的更多信息,请参见 PEP 616 。
直接输入提示列表和字典
为基本类型添加类型提示通常很简单,比如str、int和bool。您可以直接用类型进行注释。这种情况与您自己创建的自定义类型类似:
radius: float = 3.9
class NothingType:
pass
nothing: NothingType = NothingType()
仿制药是一个不同的故事。泛型通常是一个可以参数化的容器,比如一列数字。出于技术原因,在以前的 Python 版本中,您不能使用list[float]或list(float)作为类型提示。相反,您需要从typing模块导入一个不同的列表对象:
from typing import List
numbers: List[float]
在 Python 3.9 中,不再需要这种并行层次结构。现在,您终于可以使用list进行适当的类型提示了:
numbers: list[float]
这将使您的代码更容易编写,并消除同时拥有list和List的困惑。在未来,使用typing.List和类似的泛型如typing.Dict和typing.Type将被弃用,这些泛型最终将从typing中移除。
如果您需要编写与旧版本 Python 兼容的代码,那么您仍然可以通过使用 __future__导入来利用新语法,这在 Python 3.7 中是可用的。在 Python 3.7 中,您通常会看到类似这样的内容:
>>> numbers: list[float]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'type' object is not subscriptable
然而,使用__future__导入可以让这个例子工作:
>>> from __future__ import annotations
>>> numbers: list[float]
>>> __annotations__
{'numbers': 'list[float]'}
这是因为注释在运行时不会被计算。如果您尝试评估注释,那么您仍然会体验到TypeError。有关这种新语法的更多信息,请参见 PEP 585 。
拓扑排序
由节点和边组成的图对于表示不同种类的数据很有用。例如,当您使用 pip 安装来自 PyPI 的一个包时,该包可能依赖于其他包,而其他包又可能有更多的依赖项。
这种结构可以用一个图来表示,其中每个包是一个节点,每个依赖项用一条边来表示:
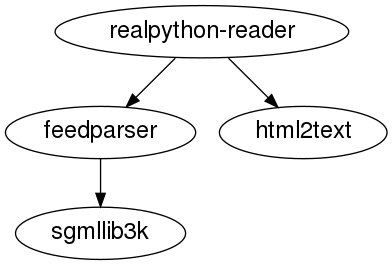
此图显示了 realpython-reader 包的依赖关系。直接取决于feedparser和html2text,而feedparser反过来又取决于sgmllib3k。
假设您希望按顺序安装这些软件包,以便始终满足所有依赖关系。然后你可以做所谓的拓扑排序来找到你的依赖关系的总顺序。
Python 3.9 在标准库中引入了一个新的模块 graphlib ,做拓扑排序。您可以使用它来查找集合的总顺序,或者考虑到可以并行化的任务来进行更高级的调度。要查看示例,您可以在字典中表示早期的依赖关系:
>>> dependencies = {
... "realpython-reader": {"feedparser", "html2text"},
... "feedparser": {"sgmllib3k"},
... }
...
这表达了您在上图中看到的依赖关系。例如,realpython-reader依赖于feedparser和html2text。在这种情况下,realpython-reader的具体依赖关系写成一个集合:{"feedparser", "html2text"}。您可以使用任何 iterable 来指定这些,包括一个列表。
**注意:**记住一个字符串在其字符上是可迭代的。因此,您通常希望将单个字符串包装在某种容器中:
>>> dependencies = {"feedparser": "sgmllib3k"} # Will NOT work
这个不不是说feedparser依赖sgmllib3k。而是说feedparser要靠s、g、m、l、l、i、b、3、k每一个。
要计算图表的总顺序,可以使用graphlib中的TopologicalSorter:
>>> from graphlib import TopologicalSorter
>>> ts = TopologicalSorter(dependencies)
>>> list(ts.static_order())
['html2text', 'sgmllib3k', 'feedparser', 'realpython-reader']
给定的顺序建议你先安装html2text,再安装sgmllib3k,再安装feedparser,最后安装realpython-reader。
**注:**一个图的全序不一定唯一。在本例中,其他有效的排序是:
sgmllib3k、html2text、feedparser、realpython-readersgmllib3k、feedparser、html2text、realpython-reader
TopologicalSorter有一个扩展的 API,允许你使用.add()增加节点和边。您还可以迭代地使用该图,这在调度可以并行完成的任务时特别有用。完整示例见文档。
最大公约数(GCD)和最小公倍数(LCM)
数的除数是一个重要的性质,在密码学和其他领域都有应用。Python 很早就有了计算两个数的最大公约数(GCD) 的函数:
>>> import math
>>> math.gcd(49, 14)
7
49 和 14 的 GCD 是 7,因为 7 是 49 和 14 的最大数。
最小公倍数(LCM) 与 GCD 有关。两个数的 LCM 是能被两个数相除的最小数。可以根据 GCD 来定义 LCM:
>>> def lcm(num1, num2):
... if num1 == num2 == 0:
... return 0
... return num1 * num2 // math.gcd(num1, num2)
...
>>> lcm(49, 14)
98
49 和 14 的最小公倍数是 98,因为 98 是能被 49 和 14 整除的最小数。在 Python 3.9 中,您不再需要定义自己的 LCM 函数:
>>> import math
>>> math.lcm(49, 14)
98
math.gcd()和math.lcm()现在都支持两个以上的数字。例如,你可以这样计算273、1729、6048的最大公约数:
>>> import math
>>> math.gcd(273, 1729, 6048)
7
注意math.gcd()和math.lcm()不能基于列表进行计算。然而,您可以将列表解包成逗号分隔的参数:
>>> import math
>>> numbers = [273, 1729, 6048]
>>> math.gcd(numbers)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object cannot be interpreted as an integer
>>> math.gcd(*numbers)
7
在 Python 的早期版本中,您需要嵌套几个对gcd()的调用或者使用 functools.reduce() :
>>> import math
>>> math.gcd(math.gcd(273, 1729), 6048)
7
>>> import functools
>>> functools.reduce(math.gcd, [273, 1729, 6048])
7
在 Python 的最新版本中,这些计算变得更加简单易懂。
新的 HTTP 状态代码
IANA T2 协调几个关键的互联网基础设施资源,包括你之前看到的时区数据库。另一个这样的资源是 HTTP 状态代码注册表。HTTP 状态代码可在 http标准库中获得:
>>> from http import HTTPStatus
>>> HTTPStatus.OK
<HTTPStatus.OK: 200>
>>> HTTPStatus.OK.description
'Request fulfilled, document follows'
>>> HTTPStatus(404)
<HTTPStatus.NOT_FOUND: 404>
>>> HTTPStatus(404).phrase
'Not Found'
在 Python 3.9 中,新的 HTTP 状态代码 103(早期提示)和 425(过早)被添加到http:
>>> from http import HTTPStatus
>>> HTTPStatus.EARLY_HINTS.value
103
>>> HTTPStatus(425).phrase
'Too Early'
如您所见,您可以根据号码和名称访问新代码。
超文本咖啡壶控制协议(HTCPCP) 于 1998 年 4 月 1 日引入,用于控制、监控和诊断咖啡壶。它引入了像BREW这样的新方法,同时主要重用现有的 HTTP 状态代码。一个例外是新的 418(我是一把茶壶)状态码,意在防止因在茶壶里煮咖啡而毁坏一把好茶壶的灾难。
用于茶流出设备的超文本咖啡壶控制协议(HTCPCP-茶)也包括 418(我是茶壶)并且该代码也找到了进入许多主流 HTTP 库的方法,包括 requests 。
2017 年发起的从主要图书馆移除 418(我是茶壶)的倡议遭到了的迅速抵制。最终,辩论以 418 被提议为保留的 HTTP 状态码而结束。418(我是茶壶)也加入了http:
>>> from http import HTTPStatus
>>> HTTPStatus(418).phrase
"I'm a Teapot"
>>> HTTPStatus.IM_A_TEAPOT.description
'Server refuses to brew coffee because it is a teapot.'
你可以在一些地方看到 418 错误,包括在谷歌上。
删除不赞成使用的兼容性代码
Python 去年的一个重要里程碑是 Python 2 的日落。Python 2.7 是在 2010 年首次发布的。2020 年 1 月 1 日,官方对 Python 2 的支持结束。
Python 2 已经为社区服务了近 20 年,并且被许多人亲切地怀念。同时,不用担心 Python 3 与 Python 2 的兼容性,核心开发人员可以专注于 Python 3 的持续改进,并在此过程中做一些清理工作。
Python 3.9 中移除了许多不推荐使用但为了向后兼容 Python 2 而保留下来的函数。Python 3.10 中还会移除一些。如果您想知道您的代码是否使用了这些旧特性,那么尝试在开发模式下运行它:
$ python -X dev script_name.py
使用开发模式会向您显示更多的警告,帮助您的代码经得起未来的考验。参见Python 3.9 新特性了解更多关于被移除特性的信息。
Python 的下一个版本是什么时候?
Python 3.9 中与代码无关的最后一个变化由 PEP 602 描述——Python 的年度发布周期。传统上,Python 的新版本大约每十八个月发布一次。
从 Python 的当前版本开始,大约每隔 12 个月,即每年的 10 月,就会发布新的版本。这带来了几个好处,最明显的是更可预测和一致的发布时间表。对于年度发布,更容易计划和同步其他重要的开发者活动,如PyCon USsprint 和年度核心 sprint。
虽然发布会越来越频繁,但 Python 不会更快变得不兼容,也不会更快获得新特性。所有版本将在最初发布后的五年内得到支持,因此 Python 3.9 将在 2025 年前获得安全修复。
随着发布周期的缩短,新特性的发布会更快。同时,新版本将带来更少的变化,使更新变得不那么重要。
Python 的指导委员会的选举在每次 Python 发布后举行。今后,这意味着指导委员会的五个职位将每年选举一次。
尽管 Python 的新版本将每 12 个月发布一次,但新版本的开发在发布前大约 17 个月就开始了。这是因为在 beta 测试阶段,没有新的特性被添加到一个版本中,这个阶段持续了大约五个月。
换句话说,Python 的下一个版本 Python 3.10 的开发已经在进行中。你已经可以通过运行最新的核心开发者 Docker 镜像来测试 Python 3.10 的第一个 alpha 版本。
Python 3.10 的最终特性仍有待确定。然而,版本号有些特殊,因为它是第一个带有两位数次要版本的 Python 版本。这可能会导致一些问题,例如,如果您的代码将版本作为字符串进行比较,因为"3.9" > "3.10"。更好的解决方案是将版本作为元组进行比较:(3, 9) < (3, 10)。包 flake8-2020 测试代码中的这些和类似的问题。
那么,应该升级到 Python 3.9 吗?
首先,如果您想尝试本教程中展示的任何很酷的新特性,那么您需要使用 Python 3.9。可以将最新版本与当前版本的 Python 并行安装。最简单的方法就是使用类似 pyenv 或者 conda 这样的环境管理器。通过 Docker 运行新版本会更少干扰。
当您考虑升级到 Python 3.9 时,您应该问自己两个不同的问题:
- 您应该将开发人员或生产环境升级到 Python 3.9 吗?
- 您是否应该让您的项目依赖于 Python 3.9,以便能够利用新特性?
如果您的代码在 Python 3.8 中运行流畅,那么在 Python 3.9 中运行相同的代码应该不会遇到什么问题。主要的绊脚石是,如果你依赖的函数在 Python 的早期版本中已经被否决,现在被移除。
新的 PEG 解析器自然没有像旧的那样经过广泛的测试。如果你运气不好,你可能会遇到一些奇怪的棘手问题。但是,请记住,您可以使用命令行标志切换回旧的解析器。
总之,在方便的时候尽早将自己的环境升级到 Python 的最新版本应该是相当安全的。如果你想保守一点,那么你可以等待第一个维护版本,Python 3.9.1。
您是否能够开始真正利用自己代码中的新特性,很大程度上取决于您的用户群。如果您的代码只在您可以控制和升级到 Python 3.9 的环境中运行,那么使用zoneinfo或新的字典合并操作符没有任何害处。
然而,如果你正在分发一个被许多人使用的库,那么最好保守一点。上一个版本的 Python 3.5 发布于 9 月,现在已经不支持了。如果可能的话,你应该仍然致力于让你的库与 Python 3.6 和更高版本兼容,这样尽可能多的人可以享受你的成果。
有关为 Python 3.9 准备代码的详细信息,请参见官方文档中的移植到 Python 3.9 。
结论
新 Python 版本的发布是社区的一个重要里程碑。您可能无法立即开始使用这些很酷的新特性,但是几年后 Python 3.9 将会像现在的 Python 3.6 一样普及。
在本教程中,您已经看到了像这样的新功能:
zoneinfo模块用于处理时区- Union 运算符可以更新字典
- 更具表现力的装饰语法
- 除了类型提示之外,还可以用于其他事情的注释
要了解更多 Python 3.9 技巧以及与真正的 Python 团队成员的小组讨论,请查看以下附加资源:
留出几分钟时间来尝试最让你兴奋的功能,然后在下面的评论中分享你的体验!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.9 中很酷的新特性********
PyTorch vs TensorFlow,用于您的 Python 深度学习项目
PyTorch vs TensorFlow:有什么区别?两者都是开源 Python 库,使用图形对数据进行数值计算。两者都在学术研究和商业代码中广泛使用。两者都被各种 API、云计算平台和模型库所扩展。
如果它们如此相似,那么哪个最适合你的项目呢?
在本教程中,您将学习:
- PyTorch 和 TensorFlow 有什么区别
- 每个人都有哪些工具和资源
- 如何为您的特定用例选择最佳选项
您将从仔细研究这两个平台开始,从稍旧的 TensorFlow 开始,然后探索一些可以帮助您确定哪个选择最适合您的项目的考虑因素。我们开始吧!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
什么是张量流?
TensorFlow 由谷歌开发,于 2015 年开源发布。它源于谷歌自主开发的机器学习软件,该软件经过重构和优化,可用于生产。
“TensorFlow”这个名称描述了如何组织和执行数据操作。TensorFlow 和 PyTorch 的基本数据结构是一个张量。当你使用 TensorFlow 时,你通过构建一个有状态数据流图,对这些张量中的数据执行操作,有点像记忆过去事件的流程图。
谁用 TensorFlow?
TensorFlow 有着生产级深度学习库的美誉。它拥有大量活跃的用户,以及大量用于培训、部署和服务模型的官方和第三方工具和平台。
2016 年 PyTorch 发布后,TensorFlow 人气下滑。但在 2019 年末,谷歌发布了 TensorFlow 2.0 ,这是一次重大更新,简化了库,使其更加用户友好,引发了机器学习社区的新兴趣。
代码样式和功能
在 TensorFlow 2.0 之前,TensorFlow 需要你通过调用tf.* API 来手动拼接一个抽象语法树——图形。然后,它要求您通过向一个session.run()调用传递一组输出张量和输入张量来手动编译模型。
一个Session对象是一个用于运行 TensorFlow 操作的类。它包含了评估Tensor对象和执行Operation对象的环境,它可以像tf.Variable对象一样拥有资源。使用Session最常见的方式是作为上下文管理器。
在 TensorFlow 2.0 中,您仍然可以用这种方式构建模型,但是使用急切执行更容易,这是 Python 通常的工作方式。急切执行会立即评估操作,因此您可以使用 Python 控制流而不是图形控制流来编写代码。
为了看出区别,让我们看看如何用每种方法将两个张量相乘。下面是一个使用旧 TensorFlow 1.0 方法的示例:
>>> import tensorflow as tf
>>> tf.compat.v1.disable_eager_execution()
>>> x = tf.compat.v1.placeholder(tf.float32, name = "x")
>>> y = tf.compat.v1.placeholder(tf.float32, name = "y")
>>> multiply = tf.multiply(x, y)
>>> with tf.compat.v1.Session() as session:
... m = session.run(
... multiply, feed_dict={x: [[2., 4., 6.]], y: [[1.], [3.], [5.]]}
... )
... print(m)
[[ 2\. 4\. 6.]
[ 6\. 12\. 18.]
[10\. 20\. 30.]]
这段代码使用 TensorFlow 2.x 的tf.compat API 来访问 TensorFlow 1.x 方法,并禁用急切执行。
首先使用 tf.compat.v1.placeholder 张量对象声明输入张量x和y。然后定义要对它们执行的操作。接下来,使用tf.Session对象作为上下文管理器,创建一个容器来封装运行时环境,并通过用feed_dict将实值输入占位符来执行乘法。最后,还是在会话里面,你 print() 的结果。
借助 TensorFlow 2.0 中的热切执行,您只需 tf.multiply() 即可实现相同的结果:
>>> import tensorflow as tf
>>> x = [[2., 4., 6.]]
>>> y = [[1.], [3.], [5.]]
>>> m = tf.multiply(x, y)
>>> m
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 6., 12., 18.],
[10., 20., 30.]], dtype=float32)>
在这段代码中,您使用 Python 列表表示法声明您的张量,当您调用时,tf.multiply()立即执行元素级乘法。
如果你不想或者不需要构建底层组件,那么推荐使用 TensorFlow 的方式是 Keras 。它具有更简单的 API,将常见用例转化为预制组件,并提供比 base TensorFlow 更好的错误消息。
特殊功能
TensorFlow 拥有庞大而成熟的用户群,以及大量帮助生产机器学习的工具。对于移动开发,它有用于 JavaScript 和 Swift 的 API,而 TensorFlow Lite 可以让你压缩和优化物联网设备的模型。
您可以快速开始使用 TensorFlow,因为谷歌和第三方都提供了丰富的数据、预训练模型和谷歌 Colab 笔记本。
TensorFlow 内置了很多流行的机器学习算法和数据集,随时可以使用。除了内置的数据集,你可以访问谷歌研究数据集或使用谷歌的数据集搜索来找到更多。
Keras 使模型的建立和运行变得更加容易,因此您可以在更短的时间内尝试新的技术。事实上,Keras 是 Kaggle 上五个获胜团队中使用最多的深度学习框架。
一个缺点是,从 TensorFlow 1.x 到 TensorFlow 2.0 的更新改变了太多的功能,你可能会发现自己很困惑。升级代码繁琐且容易出错。许多资源,如教程,可能包含过时的建议。
PyTorch 没有同样大的向后兼容性问题,这可能是选择它而不是 TensorFlow 的一个原因。
Tensorflow Ecosystem
TensorFlow 扩展生态系统的 API、扩展和有用工具的一些亮点包括:
- TensorFlow Hub ,一个可重用机器学习模块的库
- 模型花园,使用 TensorFlow 高级 API 的官方模型集合
- 用 Scikit-Learn、Keras 和 TensorFlow 进行动手机器学习,全面介绍使用 TensorFlow 进行机器学习
PyTorch 是什么?
PyTorch 由脸书开发,于 2016 年首次公开发布。创建它是为了提供类似 TensorFlow 的生产优化,同时使模型更容易编写。
因为 Python 程序员发现它使用起来如此自然,PyTorch 迅速获得了用户,激励 TensorFlow 团队在 TensorFlow 2.0 中采用了 PyTorch 的许多最受欢迎的功能。
谁用 PyTorch?
PyTorch 以在研究中比在生产中应用更广泛而闻名。然而,自从在 TensorFlow 发布一年后,PyTorch 被专业开发人员大量使用。
2020 Stack Overflow 开发者调查最受欢迎的“其他框架、库和工具”列表显示,10.4%的专业开发者选择 TensorFlow,4.1%选择 PyTorch。在 2018 中,TensorFlow 的比例为 7.6%,PyTorch 仅为 1.6%。
至于研究,PyTorch 是一个受欢迎的选择,像斯坦福大学的计算机科学项目现在用它来教授深度学习。
代码样式和功能
PyTorch 基于 Torch ,这是一个用 c 语言编写的快速计算框架。Torch 有一个用于构建模型的 Lua 包装器。
PyTorch 将相同的 C 后端包装在 Python 接口中。但它不仅仅是一个包装纸。开发人员从头开始构建它是为了让 Python 程序员更容易编写模型。底层的低级 C 和 C++代码针对运行 Python 代码进行了优化。由于这种紧密集成,您可以:
- 更好的内存和优化
- 更合理的错误消息
- 模型结构的细粒度控制
- 更透明的模型行为
- 与 NumPy 的兼容性更好
这意味着你可以直接用 Python 编写高度定制的神经网络组件,而不必使用大量的底层函数。
PyTorch 的 eager execution ,可以立即动态地计算张量运算,启发了 TensorFlow 2.0,所以两者的 API 看起来非常相似。
将 NumPy 对象转换成张量是 PyTorch 的核心数据结构。这意味着您可以轻松地在torch.Tensor对象和numpy.array对象之间来回切换。
例如,您可以使用 PyTorch 将 NumPy 数组转换为张量的本机支持来创建两个numpy.array对象,使用torch.from_numpy()将每个对象转换为torch.Tensor对象,然后获取它们的元素级乘积:
>>> import torch
>>> import numpy as np
>>> x = np.array([[2., 4., 6.]])
>>> y = np.array([[1.], [3.], [5.]])
>>> m = torch.mul(torch.from_numpy(x), torch.from_numpy(y))
>>> m.numpy()
array([[ 2., 4., 6.],
[ 6., 12., 18.],
[10., 20., 30.]])
使用torch.Tensor.numpy()可以将矩阵乘法的结果——它是一个torch.Tensor对象——作为一个numpy.array对象打印出来。
一个torch.Tensor对象和一个numpy.array对象最重要的区别就是torch.Tensor 类有不同的方法和属性,比如 backward() ,它计算渐变, CUDA 兼容性。
特殊功能
PyTorch 为 Torch 后端添加了一个用于自动分化的 C++模块。自动微分在反向传播期间自动计算torch.nn中定义的函数的梯度。
默认情况下,PyTorch 使用急切模式计算。您可以在构建神经网络时一行一行地运行它,这样更容易调试。这也使得构造具有条件执行的神经网络成为可能。对于大多数 Python 程序员来说,这种动态执行更加直观。
PyTorch 生态系统
PyTorch 扩展生态系统的 API、扩展和有用工具的一些亮点包括:
- fast . ai API,这使得快速构建模型变得非常容易
- TorchServe ,AWS 和脸书合作开发的开源模型服务器
- TorchElastic 使用 Kubernetes 大规模训练深度神经网络
- PyTorch Hub ,一个分享和推广前沿模型的活跃社区
PyTorch vs TensorFlow 决策指南
使用哪个库取决于您自己的风格和偏好、您的数据和模型以及您的项目目标。当您开始您的项目时,稍微研究一下哪个库最好地支持这三个因素,您将为自己的成功做好准备!
风格
如果你是一个 Python 程序员,那么 PyTorch 会感觉很容易上手。开箱即可按照您的预期方式运行。
另一方面,TensorFlow 比 PyTorch 支持更多的编码语言,py torch 有一个 C++ API。在 JavaScript 和 Swift 中都可以使用 TensorFlow。如果你不想写太多的底层代码,那么 Keras 抽象出了很多常见用例的细节,这样你就可以构建 TensorFlow 模型,而不用担心细节。
数据和模型
你用的是什么型号?如果你想使用一个特定的预训练模型,像伯特或深梦,那么你应该研究它与什么兼容。一些预训练的模型只在一个库中可用,而一些在两个库中都可用。模型花园、PyTorch 和 TensorFlow 中心也是很好的资源。
需要什么数据?如果您想要使用预处理数据,那么它可能已经被构建到一个或另一个库中。查看文档,这将使你的开发更快!
项目目标
你的模特会住在哪里?如果您想在移动设备上部署模型,那么 TensorFlow 是一个不错的选择,因为 TensorFlow Lite 及其 Swift API。对于服务模型,TensorFlow 与 Google Cloud 紧密集成,但 PyTorch 集成到 AWS 上的 TorchServe 中。如果你想参加 Kaggle 比赛,那么 Keras 会让你快速迭代实验。
在项目开始时考虑这些问题和例子。确定两三个最重要的组件,TensorFlow 或 PyTorch 将成为正确的选择。
结论
在本教程中,您已经了解了 PyTorch 和 TensorFlow,了解了谁使用它们以及它们支持哪些 API,并了解了如何为您的项目选择 PyTorch 和 TensorFlow。您已经看到了每种语言支持的不同编程语言、工具、数据集和模型,并了解了如何选择最适合您独特风格和项目的语言。
在本教程中,您学习了:
- PyTorch 和 TensorFlow 有什么区别
- 如何使用张量在每个中进行计算
- 对于不同类型的项目,哪个平台最适合
- 各自支持哪些工具和数据
既然已经决定了使用哪个库,就可以开始用它们构建神经网络了。查看进一步阅读中的链接以获取想法。
延伸阅读
以下教程是实践 PyTorch 和 TensorFlow 的好方法:
-
用 Python 和 Keras 进行实用的文本分类教你用 PyTorch 构建一个自然语言处理应用。
-
在 Windows 上设置 Python 进行机器学习有关于在 Windows 上安装 PyTorch 和 Keras 的信息。
-
纯 Python vs NumPy vs TensorFlow 性能对比教你如何使用 TensorFlow 和 NumPy 做梯度下降,以及如何对你的代码进行基准测试。
-
Python 上下文管理器和“with”语句将帮助您理解为什么需要在 TensorFlow 1.0 中使用
with tf.compat.v1.Session() as session。 -
生成对抗网络:构建您的第一个模型将带您使用 PyTorch 构建一个生成对抗网络来生成手写数字!
-
Python 系列中的机器学习是更多项目想法的伟大来源,比如构建语音识别引擎或执行人脸识别。****
Qt Designer 和 Python:更快地构建您的 GUI 应用程序
要在 PyQt 中为你的窗口和对话框创建一个 GUI,你可以采取两个主要的途径:你可以使用 Qt Designer ,或者你可以用普通的 Python 代码手工编写GUI。第一种方法可以极大地提高您的工作效率,而第二种方法可以让您完全控制应用程序的代码。
GUI 应用程序通常由一个主窗口和几个 T2 对话框组成。如果你想以一种高效和用户友好的方式创建这些图形组件,那么 Qt Designer 就是你的工具。在本教程中,您将学习如何使用 Qt Designer 高效地创建 GUI。
在本教程中,您将学习:
- 什么是 Qt Designer 以及如何在您的系统上安装它
- 什么时候使用 Qt Designer 和手工编码来构建你的 GUI
- 如何使用 Qt Designer 构建和布局应用程序主窗口的 GUI
- 如何用 Qt Designer 创建和布局你的对话框的 GUI
- 如何在你的 GUI 应用中使用 Qt Designer 的
.ui文件
为了更好地理解本教程中的主题,您可以查看以下资源:
- Python 和 PyQt:构建 GUI 桌面计算器
- Python 和 PyQt:创建菜单、工具栏和状态栏
- PyQt 布局:创建专业外观的 GUI 应用程序
您将通过在一个示例文本编辑器应用程序中使用 Qt Designer 构建的 GUI 将所有这些知识结合在一起。您可以通过单击下面的链接获得构建该应用程序所需的代码和所有资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。
Qt Designer 入门
Qt Designer 是一个 Qt 工具,它为你提供了一个所见即所得(WYSIWYG) 用户界面,为你的 PyQt 应用程序高效地创建 GUI。使用这个工具,你可以通过在一个空表单上拖拽 QWidget 对象来创建图形用户界面。之后,您可以使用不同的布局管理器将它们排列到一个连贯的 GUI 中。
Qt Designer 还允许你使用不同的风格和分辨率预览图形用户界面,连接信号和插槽,创建菜单和工具栏,等等。
Qt Designer 独立于平台和编程语言。它不产生任何特定编程语言的代码,但是它创建 .ui文件。这些文件是XML文件,详细描述了如何生成基于 Qt 的 GUI。
可以用 PyQt 自带的命令行工具 pyuic5 将.ui文件的内容翻译成 Python 代码。然后,您可以在 GUI 应用程序中使用这些 Python 代码。你也可以直接读取.ui文件并加载它们的内容来生成相关的 GUI。
安装和运行 Qt Designer
根据您当前的平台,有几种方法可以获得和安装 Qt Designer。如果您使用 Windows 或 Linux,则可以从终端或命令行运行以下命令:
$ python3 -m venv ./venv
$ source venv/bin/activate
(venv) $ pip install pyqt5 pyqt5-tools
在这里,你创建一个 Python 虚拟环境,激活它,安装pyqt5和pyqt5-tools。pyqt5安装 PyQt 和所需的 Qt 库的副本,而pyqt5-tools安装一套包括 Qt Designer 的 Qt 工具。
安装会根据您的平台将 Qt Designer 可执行文件放在不同的目录中:
- **Linux:**T0】
- 视窗:
...Lib\site-packages\pyqt5_tools\designer.exe
在 Linux 系统上,比如 Debian 和 Ubuntu,您也可以通过使用系统包管理器和以下命令来安装 Qt Designer:
$ sudo apt install qttools5-dev-tools
这个命令在您的系统上下载并安装 Qt Designer 和其他 Qt 工具。换句话说,你将有一个系统范围的安装,你可以通过点击文件管理器或系统菜单中的图标来运行 Qt Designer。
在 macOS 上,如果你已经使用brew install qt命令安装了来自家酿的 Qt,那么你的系统上应该已经安装了 Qt Designer。
最后,您可以从官方下载网站下载适用于您当前平台的 Qt 安装程序,然后按照屏幕上的说明进行操作。在这种情况下,要完成安装过程,你需要注册一个 Qt 账号。
如果您已经安装了 Qt Designer,并使用了到目前为止讨论过的选项之一,那么继续运行并启动应用程序。您应该会在屏幕上看到以下两个窗口:
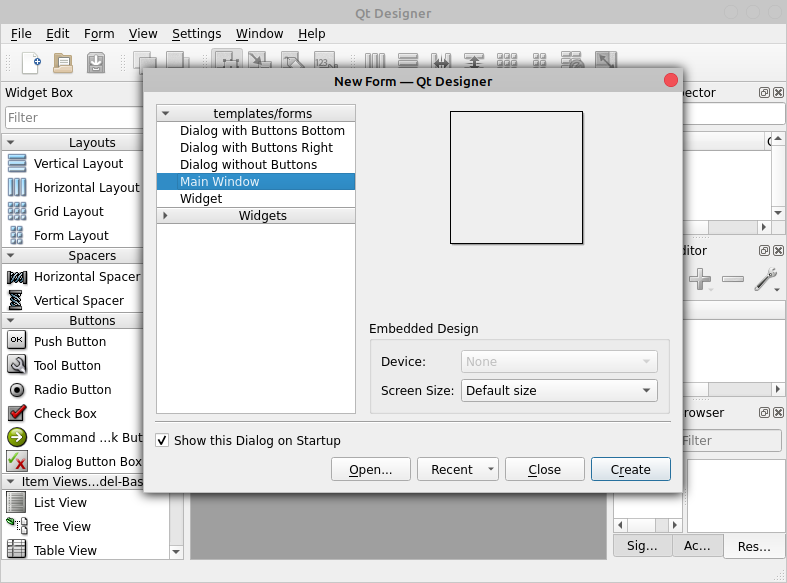
前台的窗口是 Qt Designer 的新表单对话框。背景中的窗口是 Qt Designer 的主窗口。在接下来的两节中,您将学习如何使用 Qt Designer 界面的这些组件的基础知识。
使用 Qt Designer 的新表单对话框
当您运行 Qt Designer 时,您会看到应用程序的主窗口和新表单对话框。在此对话框中,您可以从五个可用的 GUI 模板中进行选择。这些模板包括创建对话框、主窗口和自定义小部件的选项:
| 模板 | 表单类型 | 小工具 | 基础类 |
|---|---|---|---|
| 底部有按钮的对话框 | 对话 | 确定和取消按钮水平布置在右下角 | T2QDialog |
| 右边有按钮的对话框 | 对话 | 确定和取消右上角垂直排列的按钮 | QDialog |
| 没有按钮的对话框 | 对话 | 不 | QDialog |
| 主窗口 | 主窗口 | 顶部的菜单栏和底部的状态栏 | T2QMainWindow |
| 小部件 | 小部件 | 不 | T2QWidget |
默认情况下,当运行 Qt Designer 时,新表单对话框出现在前台。如果没有,那么你可以点击 Qt Designer 工具栏上的新建。也可以点击主菜单中的文件→新建或者按键盘上的 Ctrl + N 。
在新建表单对话框中,您可以选择想要启动的表单模板,然后点击创建生成一个新表单:
https://player.vimeo.com/video/500145925?background=1
要使用 Qt Designer 模板创建一个新的空表单,您只需从新表单对话框中选择所需的模板,然后单击创建或按键盘上的 Alt + R 。
注意,前两个对话框模板有自己的默认按钮。这些是 QDialogButtonBox 中包含的标准按钮。这个类自动处理不同平台上按钮的位置或顺序。
例如,如果你使用一个取消按钮和一个确定按钮,那么 Linux 和 macOS 上的标准是以同样的顺序显示这些按钮。但在 Windows 上,按钮的顺序会对调,先出现 OK ,再出现 Cancel 。QDialogButtonBox自动为您处理此问题。
使用 Qt Designer 的主窗口
Qt Designer 的主窗口提供了一个菜单栏选项,用于保存和管理表单、编辑表单和更改编辑模式、布局和预览表单,以及调整应用程序的设置和访问其帮助文档:
主窗口还提供了一个显示常用选项的工具栏。在编辑和布局表单时,您会用到这些选项中的大部分。这些选项在主菜单中也是可用的,特别是在文件、编辑和表单菜单中:

Qt Designer 的主窗口还包括几个 dock 窗口,它们提供了一组丰富的特性和工具:
- 部件盒
- 对象检查器
- 属性编辑器
- 资源浏览器
- 动作编辑器
- 信号/插槽编辑器
小部件框提供了一系列布局管理器、间隔器、标准小部件和其他对象,您可以用它们来为您的对话框和窗口创建 GUI:
https://player.vimeo.com/video/500146161?background=1
微件框在窗口顶部提供了一个过滤器选项。您可以键入给定对象或 widget 的名称并快速访问它。这些对象被分组到反映其特定用途的类别中。通过单击类别标签旁边的手柄,可以显示或隐藏类别中的所有可用对象。
当您创建表单时,您可以用鼠标指针从小部件框中取出对象,然后将它们拖放到表单上以构建 GUI。
小部件框还在窗口底部提供了一个便签本部分。在此部分中,您可以将常用对象分组到单独的类别中。通过将当前放在表单上的任何小部件拖放回小部件框中,可以用这些小部件填充便签簿类别。您可以通过右键单击小部件并在上下文菜单中选择移除来移除小部件。
对象检查器提供了当前表单上所有对象的树视图。对象检查器的顶部还有一个过滤框,允许您在树中查找对象。您可以使用对象检查器来设置表单及其小部件的名称和其他属性。您也可以右键单击任何小部件来访问带有附加选项的上下文菜单:
https://player.vimeo.com/video/500145888?background=1
使用对象检查器,您可以管理表单上的小部件。您可以重命名它们,更新它们的一些属性,从表单中删除它们,等等。对象检查器中的树形视图反映了当前表单上小部件和对象的父子关系。
属性编辑器是出现在 Qt Designer 主窗口中的另一个 dock 窗口。该窗口包含一个两列表格,其中包含活动对象的属性及其值。顾名思义,您可以使用属性编辑器来编辑对象的属性值:
https://player.vimeo.com/video/500146210?background=1
属性编辑器提供了一种用户友好的方式来访问和编辑活动对象的属性值,如名称、大小、字体、图标等。编辑器上列出的属性将根据您在表单上选择的对象而变化。
这些属性根据类的层次结构从上到下列出。例如,如果您在表单上选择了一个 QPushButton ,那么属性编辑器会显示QWidget的属性,然后是 QAbstractButton 的属性,最后是QPushButton本身的属性。请注意,编辑器上的行显示不同的颜色,以便直观地区分基础类。
最后,您有三个 dock 窗口,它们通常以标签的形式出现在右下角:
- 资源浏览器提供了一种快速向应用程序添加资源的方式,例如图标、翻译文件、图像和其他二进制文件。
- 动作编辑器提供了一种创建动作并将它们添加到表单中的方法。
- 信号/插槽编辑器提供了一种在表单中连接信号和插槽的方法。
以下是这些工具提供的一些选项:
就是这样!这三个 dock 窗口完善了 Qt Designer 为您创建和定制对话框和窗口的 GUI 提供的工具和选项。
使用 Qt Designer 与手工编写图形用户界面
使用 PyQt,您至少有两种选择来创建窗口或对话框的 GUI:您可以使用 Qt Designer,或者您可以用普通的 Python 代码手工编写 GUI。两种选择各有利弊。有时很难决定何时使用其中之一。
Qt Designer 提供了一个用户友好的图形界面,允许您快速创建 GUI。这可以提高开发人员的工作效率,缩短开发周期。
另一方面,手工编写图形用户界面可以给你更多的控制权。使用这种方法,添加新的组件和特性不需要除了您的代码编辑器或 IDE 之外的任何额外工具,这在一些开发环境中非常方便。
你是使用 Qt 设计器还是手工编码你的 GUI 是一个个人决定。以下是这两种方法的一些一般注意事项:
| 特征 | Qt 设计器 | 手工编码 |
|---|---|---|
| 开发人员的生产力 | 高的 | 如果您熟悉 PyQt,则为高,否则为低 |
| GUI 逻辑与业务逻辑的分离 | 高的 | 低的 |
| 对 GUI 组件的控制 | 低的 | 高的 |
| 动态添加和删除小部件的能力 | 低的 | 高的 |
| 探索、学习、原型制作和草图绘制的灵活性 | 高的 | 低的 |
| 使用定制小部件的灵活性 | 低的 | 高的 |
| 样板代码的数量 | 高的 | 低的 |
除了这些问题,如果您刚刚开始使用 PyQt,那么 Qt Designer 可以帮助您发现可用的小部件、布局管理器、基类、属性及其典型值,等等。
使用 Qt Designer 和手工编写 GUI 之间的最后一个区别是,在使用 Qt Designer 时,您需要运行一个额外的步骤:将.ui文件翻译成 Python 代码。
用 Qt Designer 和 Python 构建主窗口
使用 PyQt,您可以构建主窗口风格的和对话框风格的应用程序。主窗口风格的应用程序通常由一个带有菜单栏、一个或多个工具栏、中央小部件和状态栏的主窗口组成。它们也可以包括几个对话框,但是这些对话框独立于主窗口。
Qt Designer 使您能够使用预定义的主窗口模板快速构建主窗口的 GUI。一旦基于该模板创建了表单,您将拥有执行以下操作的工具:
- 创建主菜单
- 添加和填充工具栏
- 布局小部件
Qt Designer 的主窗口模板还提供了一个默认的中央小部件和一个位于窗口底部的状态栏:
https://player.vimeo.com/video/500145960?background=1
Qt Designer 将其表单保存在.ui文件中。这些是XML文件,包含您稍后在应用程序中重新创建 GUI 所需的所有信息。
要保存表格,进入文件→保存,在将表格另存为对话框中输入main_window.ui,选择保存文件的目录,点击保存。您也可以通过按键盘上的 Ctrl + S 进入保存表单为对话框。
不要关闭 Qt Designer 会话——待在那里继续向刚刚创建的主窗口添加菜单和工具栏。
创建主菜单
Qt Designer 的主窗口模板在表单顶部提供了一个空的菜单栏。您可以使用菜单编辑器将菜单添加到菜单栏。菜单是选项的下拉列表,提供对应用程序选项的快速访问。回到 Qt Designer 和你新创建的主窗口。在表单的顶部,您会看到一个菜单栏,带有占位符文本在此输入。
如果您在这个占位符文本上双击或按下 Enter ,那么您可以键入您的第一个菜单的名称。要确认菜单名称,只需按下 Enter 。
假设您想要创建自己的文本编辑器。通常,这种应用程序有一个文件菜单,其中至少有以下一些选项:
- 新建 用于新建一个文档
- 打开 打开已有文档
- 打开最近的 打开最近查看的文档
- 保存 用于保存文档
- 退出 退出应用程序
以下是如何使用 Qt Designer 创建此菜单:
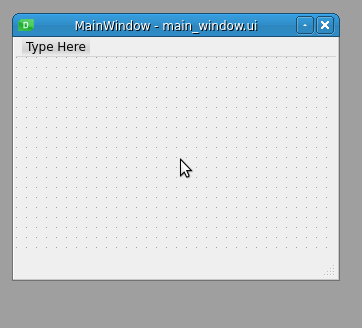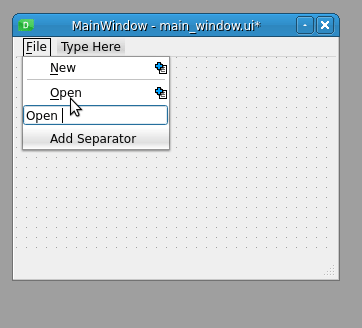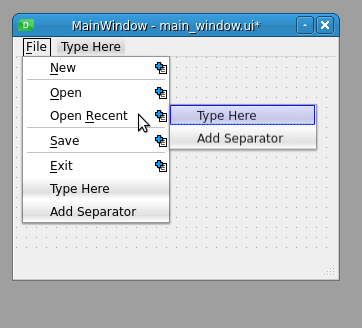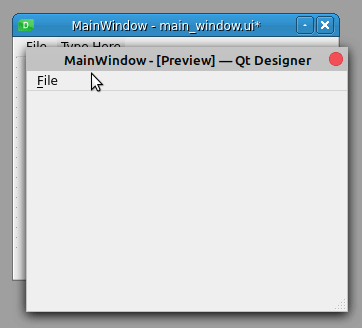
Qt Designer 的菜单编辑器允许您以用户友好的方式向菜单栏添加菜单。当您输入菜单或菜单选项的名称时,您可以在给定的字母前使用一个&符号(&)来提供一个键盘快捷键。
例如,如果您在文件菜单中的 F 前添加了一个&符号,那么您可以通过按 Alt + F 来访问该菜单。同样,如果您在新建中的 N 前添加了一个&符号,那么一旦您启动了文件菜单,您就可以通过按 N 来访问新建选项。
使用菜单编辑器,您还可以将分隔符添加到菜单中。这是在视觉上分离菜单选项并按逻辑分组的好方法。要添加分隔符,双击菜单编辑器中活动菜单末端的添加分隔符选项。右键点击现有分隔符,然后在上下文菜单中选择移除分隔符,即可移除该分隔符。此菜单还允许您添加新的分隔符。
如果您需要将分隔符移动到给定菜单中的另一个位置,那么您可以将分隔符拖动到所需的位置并将其放在那里。一条红线将指示分离器的放置位置。
您也可以将子菜单添加到给定的菜单选项中。为此,点击你想要附加子菜单的菜单选项右侧的图标,就像你在上面的例子中使用打开最近的选项一样。
要运行表单的预览,请转到表单→预览,或者点击键盘上的组合键 Ctrl + R 。
当您在示例文本编辑器中创建类似于文件菜单的菜单时,一个新的QMenu对象会自动添加到您的菜单栏中。当您向给定菜单添加菜单选项时,您创建了一个动作。Qt Designer 提供了一个动作编辑器,用于创建、定制和管理动作。该工具提供了一些方便的选项,您可以使用它们来微调您的操作:
https://player.vimeo.com/video/500146019?background=1
使用动作编辑器,您可以微调、更新或设置以下选项:
- 动作的文本,将显示在菜单选项和工具栏按钮上
- 对象名,您将在代码中使用它来引用 action 对象
- 将显示在菜单选项和工具栏按钮上的图标
- 动作的可检查的属性
- 键盘快捷键,它将为用户提供一种快速访问该操作的方式
菜单选项文本中的最后一个省略号(...)是一种广泛使用的命名约定,它不执行立即操作,而是启动一个弹出对话框来执行进一步的操作。
对于图标,你需要将这些图标作为独立的文件打包到你的应用程序中,或者你可以创建一个资源文件,也称为.qrc文件。对于此示例,您可以通过单击下面的链接下载所需的图标和其他资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。
下载完图标后,在main_window.ui文件旁边创建一个resources目录,并将图标复制到那里。然后回到动作编辑器,像这样给你的动作添加图标:
https://player.vimeo.com/video/500145992?background=1
请注意,您的菜单选项现在会在左边显示一个图标。这为您的用户提供了额外的视觉信息,并帮助他们找到所需的选项。现在继续添加一个带有以下选项的编辑菜单:
- 复制 用于复制一些文字
- 粘贴 用于粘贴一些文字
- 剪切 用于剪切一些文字
- 查找和替换 用于查找和替换文本
接下来,添加一个帮助菜单,带有一个关于选项,用于启动一个对话框,提供关于你的文本编辑器的一般信息。最后,转到属性编辑器,将窗口的标题设置为Sample Editor。添加这些内容后,您的主窗口应该如下所示:
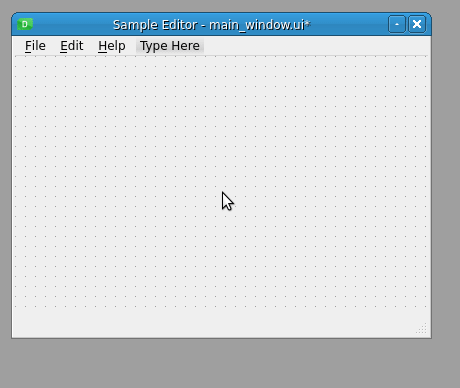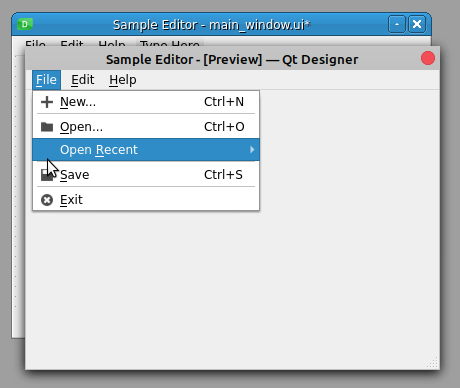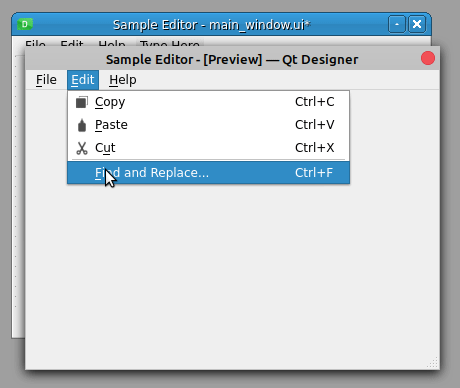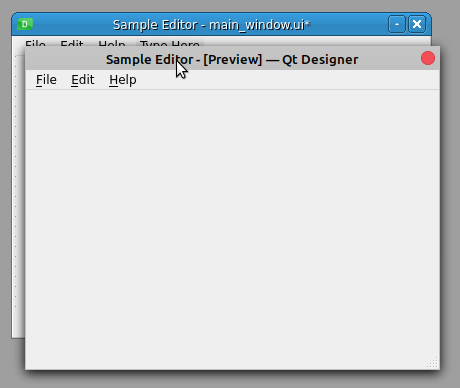
有了这些补充,您的示例文本编辑器的主菜单开始看起来像真正的文本编辑器的菜单了!
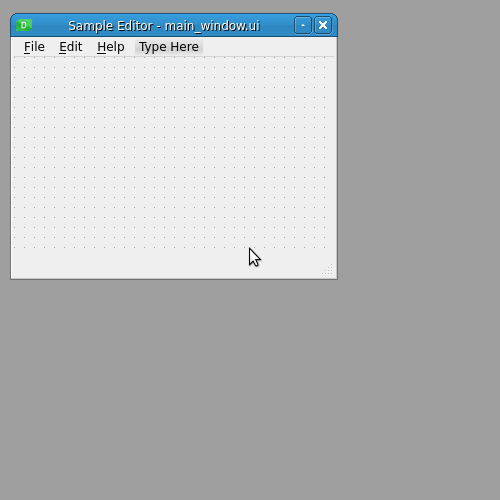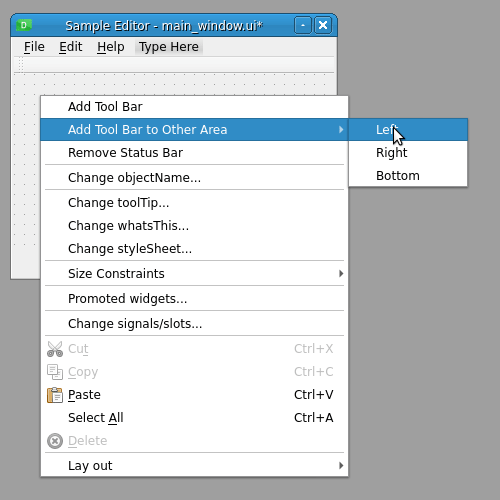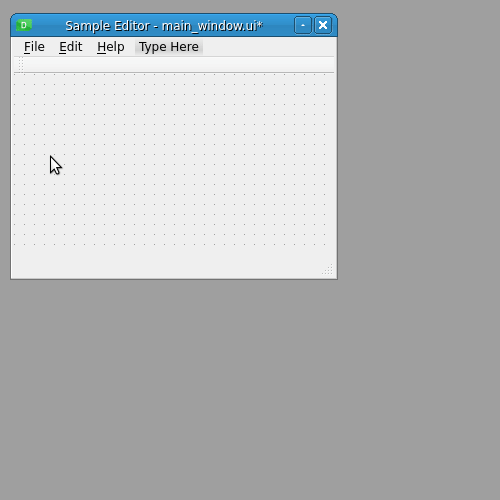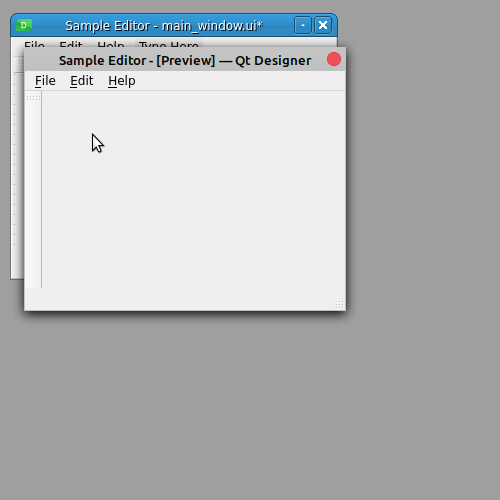
创建工具栏
您可以使用 Qt Designer 在主窗口的 GUI 中添加任意数量的工具栏。为此,右键单击表单并从上下文菜单中选择添加工具栏。这将在窗口顶部添加一个空工具栏。或者,您可以通过选择将工具栏添加到其他区域来预定义您想要放置给定工具栏的工具栏区域:
一旦你的工具栏就位,你就可以用按钮来填充它们。为此,您使用动作而不是小部件框中的特定工具栏按钮。要将动作添加到工具栏,可以使用动作编辑器:
https://player.vimeo.com/video/500146235?background=1
操作可以在菜单选项和工具栏按钮之间共享,因此在这种情况下,您可以重用在上一节填充菜单时创建的操作。要填充工具栏,单击动作编辑器上的动作,然后将其拖放到工具栏上。请注意,通过右键单击工具栏,您可以添加分隔符来直观地分隔工具按钮。
布局单个中央部件
Qt Designer 使用QMainWindow构建它的主窗口模板。这个类提供了一个默认布局,允许您创建一个菜单栏、一个或多个工具栏、一个或多个 dock 小部件、一个状态栏和一个中央小部件。默认情况下,Qt Designer 使用一个QWidget对象作为主窗口模板上的中心小部件。
使用一个基本的QWidget对象作为主窗口 GUI 的中心部件是一个很好的选择,因为在这个部件之上,你可以在一个连贯的布局中放置一个单个部件或者多个部件。
例如,在您的示例文本编辑器中,您可能希望使用一个小部件为您的用户提供一个工作区来键入、复制、粘贴和编辑他们的文本。为此,您可以使用一个QTextEdit对象,然后添加一个垂直(或水平)布局作为中心小部件的布局:
https://player.vimeo.com/video/500146185?background=1
在本例中,首先将一个QTextEdit拖到表单上。然后你点击表单来选择你的中心部件。最后,通过点击 Qt Designer 工具栏上的垂直布局,将垂直布局应用到您的中心小部件。
由于QTextEdit周围的间距看起来不合适,您使用对象检查器将布局的边距从9像素更改为1像素。
使用 Qt Designer,您可以使用不同的布局管理器来快速排列您的小部件。可以说,用 Qt Designer 布局 GUI 最容易的方法是使用主工具栏上与布局相关的部分:

从左到右,您会发现以下选项用于创建不同类型的布局:
| [计]选项 | 小部件排列 | 布局类 | 键盘快捷键 |
|---|---|---|---|
| 水平布局 | 水平地排成一行和几列 | T2QHBoxLayout | Ctrl + 1 |
| 垂直布局 | 垂直排列成一列和几行 | T2QVBoxLayout | Ctrl + 2 |
| 在分离器中水平布置 | 在可调整大小的拆分器中水平显示 | T2QSplitter | Ctrl + 3 |
| 在分离器中垂直布置 | 在可调整大小的拆分器中垂直显示 | QSplitter | Ctrl + 4 |
| 布置成网格 | 有几行和几列的表格 | T2QGridLayout | Ctrl + 5 |
| 以表格形式布局 | 在两列表格中 | T2QFormLayout | Ctrl + 6 |
工具栏中的最后两个选项与布局相关,但不创建布局:
-
打破布局 允许你打破一个已有的布局。一旦在布局中排列了小部件,您就不能单独移动它们或调整它们的大小,因为它们的几何图形是由布局控制的。要修改单个部件,您可能需要中断布局并在以后重做。要访问此选项,您可以按键盘上的
Ctrl+0。 -
调整大小 调整布局的大小,以容纳所包含的小工具,并确保每个小工具都有足够的空间可见。要访问此选项,您可以按键盘上的
Ctrl+J。
您也可以通过 Qt Designer 的主菜单栏,在表单菜单下访问所有这些布局相关的选项:
在表单菜单中,您可以访问所有与布局相关的选项,以及访问这些选项的完整键盘快捷键参考。您也可以通过表单的上下文菜单,在布局选项下访问这些选项。
布局一个复合中心部件
当你创建你的主窗口时,你可能会遇到这样的情况,你需要在给定的布局中使用多个窗口部件作为你的中心窗口部件。由于 Qt Designer 的主窗口模板附带了一个QWidget对象作为其中心小部件,因此您可以利用它来创建您自己的定制小部件排列,然后将其设置为中心小部件的顶层布局。
通过 Qt Designer,您可以使用布局管理器来布局您的小部件,正如您在上一节中已经看到的那样。如果您需要主窗口 GUI 的复合小部件布局,那么您可以通过运行以下步骤来构建它:
- 将小部件拖放到您的表单上,并尝试将它们放置在所需的位置附近。
- 选择应该由给定布局一起管理的小部件。
- 使用 Qt Designer 的工具栏或主菜单,或者使用表单的上下文菜单应用适当的布局。
虽然您可以将布局拖到表单上,然后将小部件拖到布局上,但最佳做法是首先拖动所有小部件和间隔器,然后重复选择相关的小部件和间隔器,以将布局应用于它们。
例如,假设你正在构建一个计算器应用程序。你需要一个 QLineEdit 对象在你的窗体顶部显示操作和它们的结果。在线编辑下,您需要一些用于数字和操作的QPushButton对象。这给了你一个这样的窗口:
这看起来有点像一个计算器,但是 GUI 是杂乱的。要将它安排到一个更加完美的计算器 GUI 中,您可以为按钮使用网格布局,并使用垂直框布局作为计算器的顶层布局:
https://player.vimeo.com/video/492155782?background=1
你的计算器还需要一些额外的润色,但它现在看起来好多了。要获得更完美的版本,您可以使用属性编辑器来调整按钮上某些属性的值,例如它们的最大和最小大小。您还可以为计算器的主窗口设置固定的大小,等等。来吧,试一试!
拥有状态栏
Qt Designer 的主窗口模板默认提供了一个状态栏。状态栏是一个水平面板,通常位于 GUI 应用程序主窗口的底部。它的主要目的是显示关于应用程序当前状态的信息。
您可以将状态栏分成几个部分,并在每个部分显示不同的信息。状态栏上的信息可以是临时的或者永久的,大部分时间都是以短信的形式出现。状态栏上显示的信息的目的是让你的用户了解应用程序当前正在做什么,以及它在给定时间的一般状态。
您还可以使用状态栏来显示帮助提示,这是描述给定按钮或菜单选项功能的简短帮助消息。当用户将鼠标指针悬停在工具栏按钮或菜单选项上时,这种消息会出现在状态栏上。
用 Qt Designer 和 Python 创建对话框
对话框是小尺寸窗口,通常用于提供辅助功能,如首选项对话框,或通过显示错误消息或给定操作的一般信息与用户交流。您还可以使用对话框向用户询问一些必需的信息,或者确认即将发生的操作。
PyQt 提供了一组丰富的内置对话框,可以直接在应用程序中使用。你只需要从 PyQt5.QtWidgets 中导入即可。这里有一个总结:
| 对话类 | 目的 |
|---|---|
T2QFontDialog | 选择和设置给定文本的字体 |
T2QPrintDialog | 指定打印机的设置 |
T2QProgressDialog | 显示长期运行操作的进度 |
T2QColorDialog | 选择和设置颜色 |
T2QInputDialog | 从用户处获取单个值 |
T2QFileDialog | 选择文件和目录 |
T2QMessageBox | 显示错误、一般信息、警告和问题等消息 |
T2QErrorMessage | 显示错误消息 |
所有这些内置对话框都可以直接在代码中使用。它们中的大多数都提供了类方法来根据您的需要构建特定类型的对话框。除了这些对话框,PyQt 还提供了 QDialog 类。您可以使用这个类在代码中创建您自己的对话框,但是您也可以使用 Qt Designer 快速创建您的对话框。
在接下来的几节中,您将学习如何使用 Qt Designer 及其对话框模板来创建、布局和定制您的对话框。
创建对话框图形用户界面
要用 Qt Designer 创建自定义对话框,从新表单对话框中选择合适的对话框模板。将所需的小部件拖放到表单上,正确地布置它们,并将表单保存在一个.ui文件中,供以后在应用程序中使用。
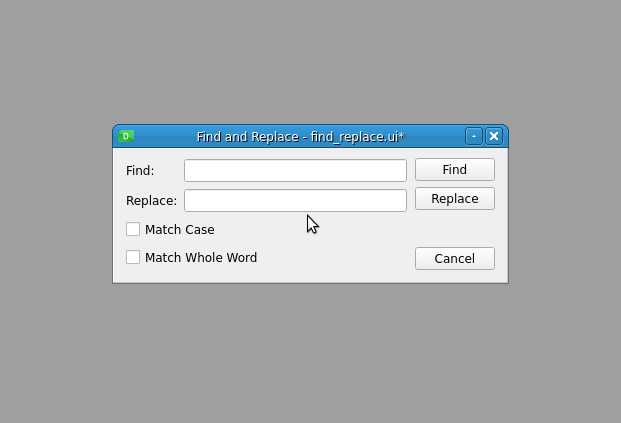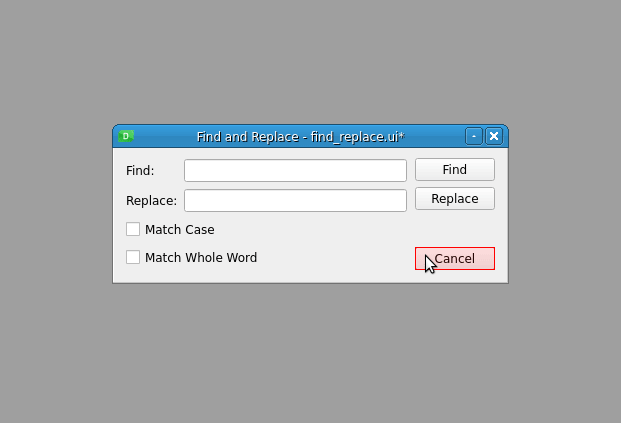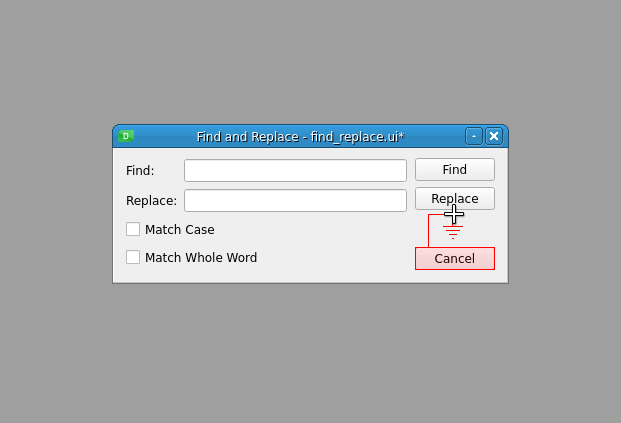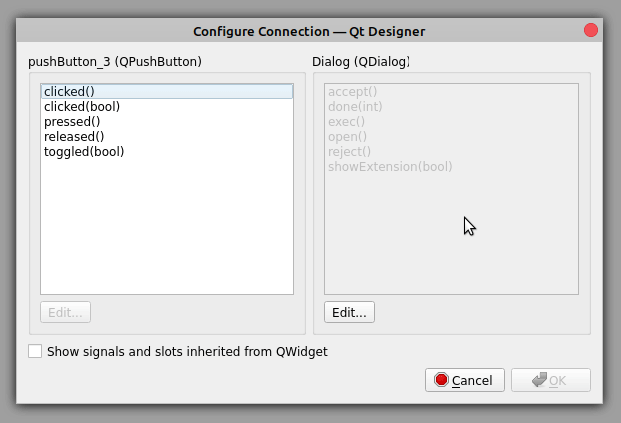
回到您的示例文本编辑器,假设您想要添加一个查找和替换对话框,如下所示:
要创建这个对话框,从没有按钮的对话框模板开始,向表单添加所需的小部件:
https://player.vimeo.com/video/500146098?background=1
这里,首先使用无按钮对话框模板创建一个空对话框,并在对象检查器中将窗口标题设置为查找并替换。然后使用小部件框将两个 QLabel 对象拖放到表单上。这些标签向用户询问他们需要查找和替换的单词。这些单词将被输入到标签附近相应的QLineEdit对象中。
接下来,将三个QPushButton对象拖放到表单上。这些按钮将允许您的用户在当前文档中查找和替换单词。最后,您添加两个 QCheckBox 对象来提供匹配大小写和匹配全字选项。
一旦表单上有了所有的小部件,请确保将它们放置在与您希望在最终对话框中实现的目标相似的位置。现在是时候布置小部件了。
布局对话框 GUI
正如您之前看到的,要在一个表单中排列小部件,您可以使用几个布局管理器。要布置您的查找和替换对话框,请为标签、线条编辑和复选框使用网格布局。对于按钮,使用垂直布局。最后,使用水平布局作为对话框的顶层布局管理器:
https://player.vimeo.com/video/500146036?background=1
在这里,您用鼠标指针选择标签、线条编辑和复选框,并对它们应用网格布局。之后,在替换和取消按钮之间添加一个垂直间隔,使它们在视觉上保持分离。
最后一步是设置对话框的顶层布局。在这种情况下,使用水平布局管理器。就是这样!您已经用 Qt Designer 构建了查找和替换对话框的 GUI。用文件名find_replace.ui保存。
使用 Qt Designer,您可以在对话框中调整许多其他属性和特性。例如,您可以设置输入小部件的 tab 键顺序,以改善用户使用键盘导航对话框的体验。还可以提供键盘快捷键,连接信号和插槽等等。
连接信号和插槽
到目前为止,您已经在 Edit Widgets 模式下使用了 Qt Designer,这是它的默认模式。在这种模式下,您可以向表单添加小部件,编辑小部件的属性,在表单上布置小部件,等等。但是,Qt Designer 有多达四种不同的模式,允许您处理表单的不同功能:
| 方式 | 目的 | 菜单选项 | 键盘快捷键 |
|---|---|---|---|
| 编辑小部件 | 编辑小部件 | 编辑→编辑小工具 | T2F3 |
| 编辑信号/插槽 | 连接内置信号和插槽 | 编辑→编辑信号/插槽 | T2F4 |
| 编辑好友 | 设置键盘快捷键 | 编辑→编辑好友 | 不 |
| 编辑 Tab 键顺序 | 设置小部件的 tab 键顺序 | 编辑→编辑标签顺序 | 不 |
您也可以通过单击 Qt Designer 工具栏中与模式相关部分的相应按钮来访问这些模式,如下所示:

为了能够编辑部件和表单的内置信号和插槽,首先需要切换到编辑信号/插槽模式。
注意:在 Qt 中,术语好友指的是标签和小部件之间的特殊关系,其中标签提供了键盘快捷键或快捷方式,允许您使用键盘访问好友小部件。
用户在小部件和表单上的动作,比如点击或按键,在 PyQt 中被称为事件。当事件发生时,手边的小工具发出一个信号。这种机制允许您运行操作来响应事件。这些动作被称为槽,它们是方法或函数。
要执行一个插槽来响应一个事件,您需要选择一个由小部件发出的信号来响应一个事件,并将其连接到所需的插槽。
大多数小部件,包括对话框和窗口,都实现了内置的信号,当给定的事件在小部件上发生时,就会发出这些信号。小部件还提供了内置的插槽,允许您执行某些标准化的操作。
要使用 Qt Designer 在两个小部件之间建立信号和插槽连接,您需要用鼠标选择信号提供器小部件,然后将它拖放到插槽提供器小部件上。这将启动 Qt Designer 的配置连接对话框。现在回到查找和替换对话框,切换到 Qt Designer 的编辑信号/插槽模式。然后将取消按钮拖放到表单上:
配置连接对话框有两个面板。在左侧面板上,您可以从信号提供商小部件中选择一个信号,在右侧面板上,您可以从插槽提供商小部件中选择一个插槽。要创建连接,按下 OK :
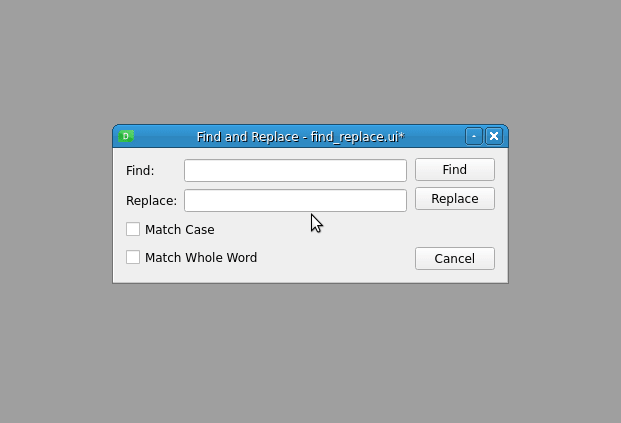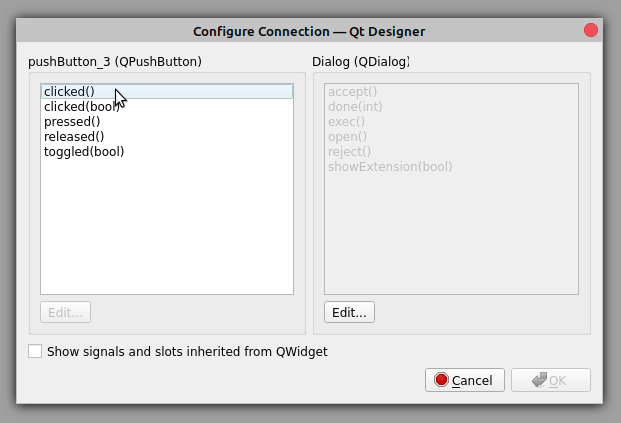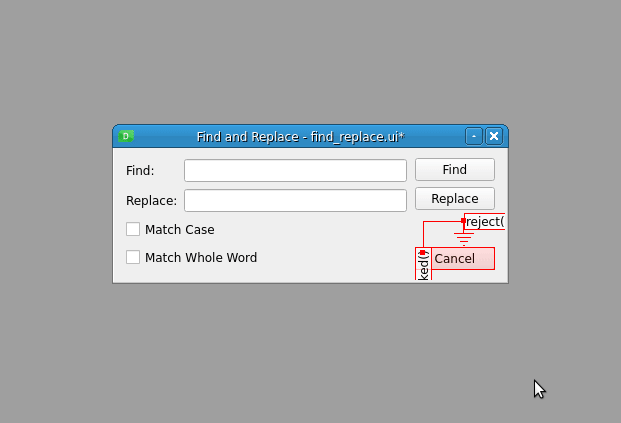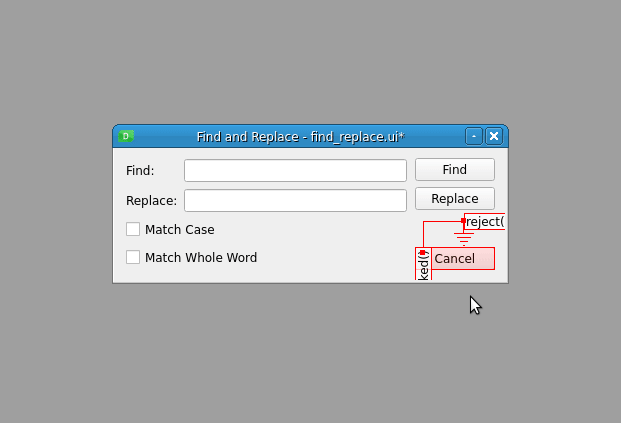
连接显示为从信号提供者小部件到插槽提供者小部件的箭头,表示连接已经建立。您还会看到信号的名称和您刚刚连接的插槽。
在这种情况下,您将取消按钮的 clicked() 信号与对话框的 reject() 槽相连。现在,当您点击取消时,您的操作将被忽略,对话框将关闭。
要修改连接,请双击箭头或其中一个标签。这将显示配置连接对话框,在该对话框中,您可以根据需要更改信号或连接所涉及的插槽。
要删除连接,选择代表连接的箭头或识别信号和插槽的标签之一,然后按 Del 。
设置微件的标签顺序
为了提高你的对话框的可用性,你可以为你的输入部件设置一致的标签顺序。tab 键顺序是当您在键盘上按下 Tab 或 Shift + Tab 时,表单上的小部件成为焦点的顺序。
如果您使用 Qt Designer 创建表单,那么小部件的默认 tab 键顺序是基于您在表单上放置每个小部件的顺序。有时这个顺序不对,当你点击 Tab 或 Shift + Tab 时,焦点会跳到一个意想不到的小部件上。查看一下查找和替换对话框中的 tab 键顺序行为:
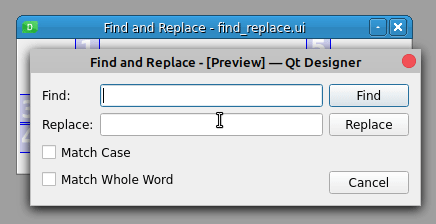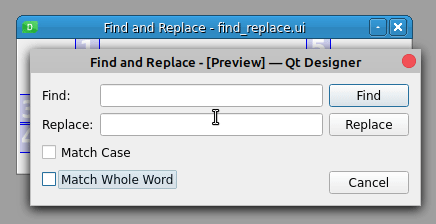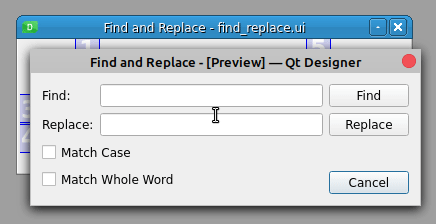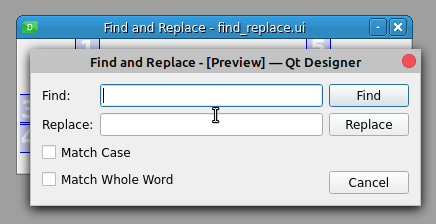
焦点从查找行编辑开始,然后经过替换行编辑,然后通过复选框,最后通过按钮。如果您希望焦点从查找行编辑跳到替换行编辑,然后跳到查找按钮,该怎么办?在这种情况下,您可以更改对话框中输入小部件的 tab 键顺序。在 Qt Designer 中切换到编辑 Tab 键顺序模式。您会看到类似这样的内容:
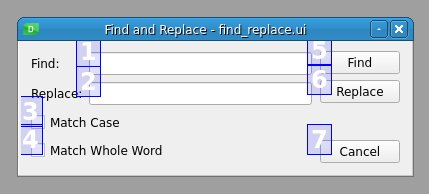
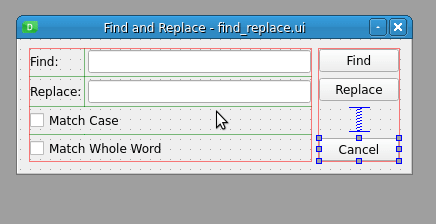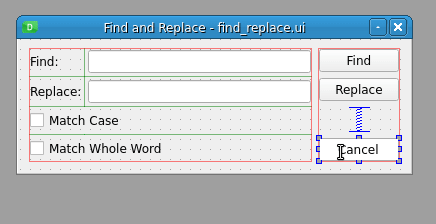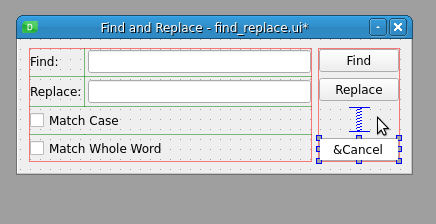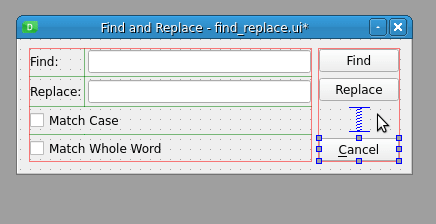
在编辑 tab 键顺序模式下,表单中的每个输入小部件都显示一个数字,标识它在 Tab 键顺序链中的位置。您可以通过点击所需顺序的数字来更改顺序:
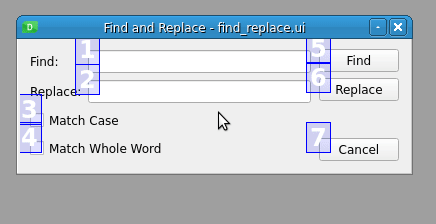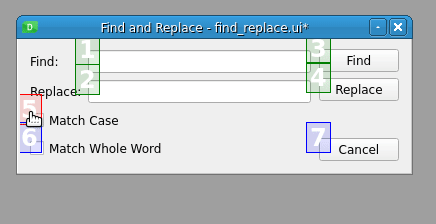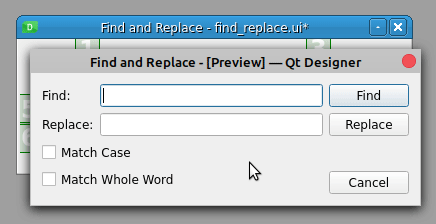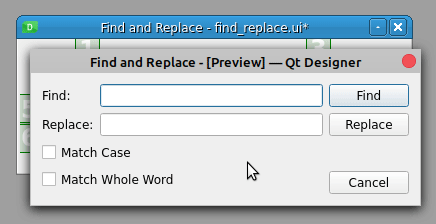
您可以通过按所需顺序单击数字来更改输入小部件的 tab 键顺序。请注意,当您选择一个数字时,它会变为红色,表示这是 tab 键顺序链中当前编辑的位置。未设置的号码显示为蓝色,已设置的号码显示为绿色。如果你犯了一个错误,那么你可以通过从表单的上下文菜单中选择 Restart 来重新开始排序。
提供键盘快捷键
一个键盘快捷键是一个组合键,你可以在键盘上按下它来快速移动焦点到一个对话框或窗口的给定部件上。通常,键盘快捷键由 Alt 键和一个字母组成,该字母标识您想要访问的小工具或选项。这可以帮助您提高应用程序的可用性。
要在包含标签(如按钮或复选框)的小部件上定义键盘快捷键,只需在要在快捷键中使用的标签文本中的字母前放置一个&符号(&)。例如,在查找和替换对话框的取消按钮上的 C 前放置一个&符号,运行预览,然后按下 Alt + C ,如下例所示:
通过在取消按钮文本中的字母 C 前放置一个&符号,您就创建了一个键盘快捷键。如果按下键盘上的 Alt + C ,则取消按钮被选中,对话框关闭。
要在不包含标签的小部件上定义键盘快捷键,例如行编辑,您需要使该小部件成为标签对象的伙伴。如果您想要创建好友连接,需要采取四个步骤:
- 在标签文本中选择一个字母来标识好友连接,并提供键盘快捷键。
- 在标签文本中的选定字母前放置一个&符号(
&)。 - 在 Qt Designer 中切换到编辑好友模式。
- 将标签拖放到好友小部件上。
以下是如何在 Find 标签及其相关的行编辑之间创建伙伴关系:
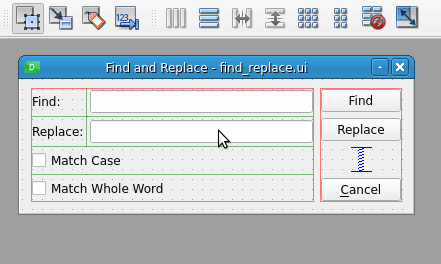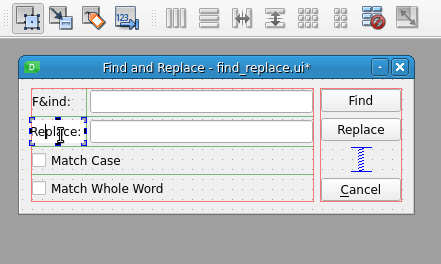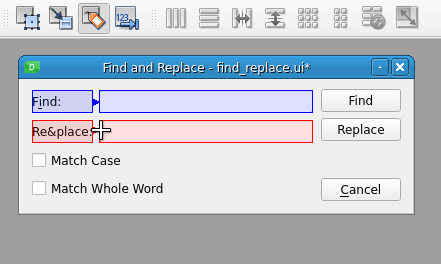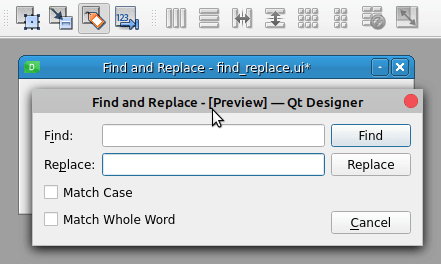
要在标签和小部件之间创建伙伴关系,请用鼠标选择标签,并将其拖到要设置为伙伴的输入小部件上。标签和输入部件将成为伙伴。从这一点开始,您可以按下 Alt 加上标签文本中选定的字母,将焦点移动到相关的小部件。
需要注意的是,在给定的表单中,不应该有两个带有相同键盘快捷键的小部件。这意味着您需要为每个键盘快捷键选择一个唯一的字母。
继续使用 Qt Designer 为您的查找和替换对话框上的小部件设置键盘快捷键。最终的结果应该像你在创建对话框 GUI 一节开始时看到的对话框。
在应用程序中集成窗口和对话框
至此,您已经学习了如何使用 Qt Designer 为您的主窗口和对话框创建 GUI。在本节中,您将学习如何将这些 GUI 集成到您的 Python 代码中,并构建一个真正的应用程序。在 PyQt 中有两种主要的方法:
- 使用
pyuic5将.ui文件的内容转化为 Python 代码 - 加载
.ui文件的内容动态使用uic.loadUi()
第一种方法使用pyuic5,它是 PyQt 安装中包含的一个工具,允许您将.ui文件的内容翻译成 Python 代码。这种方法因其高效而被广泛使用。但是,它有一个缺点:每次用 Qt Designer 修改 GUI 时,都需要重新生成代码。
第二种方法利用uic.loadUi()将.ui文件的内容动态加载到您的应用程序中。当您使用不涉及大量加载时间的小型 GUI 时,这种方法是合适的。
设置使用的窗口和对话框
现在是时候设置您的窗口和对话框了,以便在实际应用程序中使用(在本例中,是一个示例文本编辑器)。如果你一直遵循这个教程,那么你应该至少有两个.ui文件:
main_window.ui带有文本编辑器的 GUI 示例应用程序find_replace.ui用一个的 GUI 找到并替换对话框
继续创建一个名为sample_editor/的新目录。在这个目录中,创建另一个名为ui/的目录,并将您的.ui文件复制到其中。另外,将包含菜单选项和工具栏按钮图标的resources/目录复制到sample_editor/ui/目录。到目前为止,您的应用程序的结构应该如下所示:
sample_editor/
│
└── ui/
├── resources/
│ ├── edit-copy.png
│ ├── edit-cut.png
│ ├── edit-paste.png
│ ├── file-exit.png
│ ├── file-new.png
│ ├── file-open.png
│ ├── file-save.png
│ └── help-content.png
│
├── find_replace.ui
└── main_window.ui
由于主窗口 GUI 相对复杂,您可以使用pyuic5将main_window.ui的内容翻译成 Python 代码。
您可以通过单击下面的链接下载构建示例文本编辑器所需的所有代码和资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。
现在打开一个终端,导航到sample_editor/目录。一旦到达那里,运行以下命令:
$ pyuic5 -o main_window_ui.py ui/main_window.ui
这个命令从ui/main_window.ui文件生成一个名为main_window_ui.py的 Python 模块,并将其放在您的sample_editor/目录中。这个模块包含了主窗口 GUI 的 Python 代码。下面是代码的一个小样本:
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'ui/main_window.ui'
#
# Created by: PyQt5 UI code generator 5.15.1
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(413, 299)
self.centralwidget = QtWidgets.QWidget(MainWindow)
# Snip...
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "Sample Editor"))
self.menu_File.setTitle(_translate("MainWindow", "&File"))
# Snip...
Ui_MainWindow拥有生成样本编辑器主窗口 GUI 的所有代码。注意.setupUi()包含了创建所有需要的小部件并在 GUI 上展示它们的代码。.retranslateUi()包含了国际化和本地化的代码,但是这个主题超出了本教程的范围。
**注意:**如果pyuic5对您不起作用,那么您需要检查您当前的 PyQt 安装。如果您在 Python 虚拟环境中安装了 PyQt,那么您可能需要激活该环境。您还可以移动到您的虚拟环境目录,并从那里运行pyuic5。通常,你会在bin/目录下找到这个应用程序。
如果您在系统范围内安装了 PyQt,那么您应该能够直接从命令行运行pyuic5,而不需要激活虚拟环境。
现在,您的工作目录应该如下所示:
sample_editor/
│
├── ui/
│ ├── resources/
│ │ ├── edit-copy.png
│ │ ├── edit-cut.png
│ │ ├── edit-paste.png
│ │ ├── file-exit.png
│ │ ├── file-new.png
│ │ ├── file-open.png
│ │ ├── file-save.png
│ │ └── help-content.png
│ │
│ ├── find_replace.ui
│ └── main_window.ui
│
└── main_window_ui.py
由于您的查找和替换对话框非常小,您可以使用uic.loadUi()直接从您的.ui文件加载它的 GUI。这个函数将一个带有.ui文件路径的字符串作为参数,并返回一个实现 GUI 的QWidget子类。
这种动态加载.ui文件的方式在实践中很少使用。你可以用它来加载不需要太多努力的小对话框。使用这种方法,您不需要在每次使用 Qt Designer 修改.ui文件时都为对话框的 GUI 生成 Python 代码,这在某些情况下可以提高生产率和可维护性。
既然您已经选择了构建每个 GUI 的策略,那么是时候将所有东西放在一个真正的应用程序中了。
将所有东西放在一个应用程序中
示例文本编辑器的所有部分就绪后,您可以创建应用程序并编写所需的代码来使用主窗口和查找和替换对话框。在您的sample_editor/目录中启动您最喜欢的代码编辑器或 IDE,并创建一个名为app.py的新文件。向其中添加以下代码:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication, QDialog, QMainWindow, QMessageBox
5)
6from PyQt5.uic import loadUi
7
8from main_window_ui import Ui_MainWindow
9
10class Window(QMainWindow, Ui_MainWindow):
11 def __init__(self, parent=None):
12 super().__init__(parent)
13 self.setupUi(self)
14 self.connectSignalsSlots()
15
16 def connectSignalsSlots(self):
17 self.action_Exit.triggered.connect(self.close)
18 self.action_Find_Replace.triggered.connect(self.findAndReplace)
19 self.action_About.triggered.connect(self.about)
20
21 def findAndReplace(self):
22 dialog = FindReplaceDialog(self)
23 dialog.exec()
24
25 def about(self):
26 QMessageBox.about(
27 self,
28 "About Sample Editor",
29 "<p>A sample text editor app built with:</p>"
30 "<p>- PyQt</p>"
31 "<p>- Qt Designer</p>"
32 "<p>- Python</p>",
33 )
34
35class FindReplaceDialog(QDialog):
36 def __init__(self, parent=None):
37 super().__init__(parent)
38 loadUi("ui/find_replace.ui", self)
39
40if __name__ == "__main__":
41 app = QApplication(sys.argv)
42 win = Window()
43 win.show()
44 sys.exit(app.exec())
下面是这段代码的作用:
- 第 3 行 导入构建应用程序和 GUI 所需的 PyQt 类。
- 6 号线从
uic模块导入loadUi()。这个函数提供了一种动态加载.ui文件内容的方法。 - 第 8 行导入了
Ui_MainWindow,它包含了主窗口的 GUI。 - 第 10 行定义了
Window,它将提供你的应用程序的主窗口。在这种情况下,该类使用多重继承。它继承了QMainWindow的主窗口功能和Ui_MainWindow的 GUI 功能。 - 第 13 行调用
.setupUi(),为你的主窗口创建整个 GUI。 - 第 16 行定义
.connectSignalsSlots(),连接所需的信号和插槽。 - 第 21 行定义
.findAndReplace()。这个方法创建了一个查找和替换对话框的实例并执行它。 - 第 25 行定义了
.about(),它创建并启动一个小对话框来提供关于应用程序的信息。在这种情况下,您使用基于QMessageBox的内置对话框。 - 第 35 行定义了
FindReplaceDialog,提供了查找和替换对话框。 - 第 38 行调用
loadUi()从文件ui/find_replace.ui中加载对话框的 GUI。
最后,在第 41 到 44 行,您创建应用程序,创建并显示主窗口,并通过调用 application 对象上的.exec()运行应用程序的主循环。
值得注意的是,Qt Designer 可以用与上面代码中不同的方式来命名您的操作。例如,您可能会发现名字.actionE_xit而不是.action_Exit是指退出动作。因此,为了让这个例子正常工作,您需要确保您使用了正确的名称。
如果您想使用自己的名字而不是 Qt Designer 生成的名字,那么您可以进入属性编辑器,将.objectName属性更改为适合您的名字。
**注意:**你也可以用合成而不是多重继承来创建Window。
例如,您可以这样定义Window及其初始化器:
class Window(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.ui = Ui_MainWindow() self.ui.setupUi(self) self.connectSignalsSlots()
def connectSignalsSlots(self):
self.ui.action_Exit.triggered.connect(self.close) self.ui.action_Find_Replace.triggered.connect( self.findAndReplace
)
self.ui.action_About.triggered.connect(self.about) # Snip...
在这种情况下,您创建了.ui,它是Ui_MainWindow的一个实例。从现在开始,您需要使用.ui来访问主窗口 GUI 上的小部件和对象。
如果您运行此应用程序,您将在屏幕上看到以下窗口:
https://player.vimeo.com/video/500233090?background=1
就是这样!您已经使用 Qt Designer 创建了一个简单的文本编辑器。请注意,要编写这个应用程序,您只需编写 44 行 Python 代码,这远远少于您从头开始编写等效应用程序的 GUI 所需的代码。
结论
在 PyQt 中创建应用程序时,通常会构建一个主窗口和几个对话框。如果您手工编写代码,构建这些窗口和对话框的 GUI 会花费很多时间。幸运的是, Qt 提供了 Qt Designer ,这是一个强大的工具,旨在使用用户友好的图形界面快速高效地创建 GUI。
有了 Qt Designer,您可以将所有需要的小部件拖放到一个空的表单上,对它们进行布局,然后马上创建您的 GUI。这些图形用户界面保存在.ui文件中,您可以将其翻译成 Python 代码并在您的应用程序中使用。
在本教程中,您学习了如何:
- 在你的系统上安装 Qt Designer
- 决定什么时候使用 Qt Designer vs 手动编码你的 GUI
- 使用 Qt Designer 构建应用程序主窗口的 GUI
- 使用 Qt Designer 创建和布局您的对话框的 GUI
- 在你的 GUI 应用程序中使用 Qt Designer 的
.ui文件
最后,通过使用 Qt Designer 创建构建示例文本编辑器应用程序所需的窗口和对话框的 GUI,将所有这些知识付诸实践。您可以通过单击下面的链接获得构建此应用程序所需的所有代码和资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。*********
实践中的 Python 堆栈、队列和优先级队列
队列是游戏、人工智能、卫星导航和任务调度中众多算法的支柱。它们是计算机科学学生在早期教育中学习的顶级抽象数据类型。同时,软件工程师经常利用更高级的消息队列来实现微服务架构更好的可扩展性。另外,在 Python 中使用队列非常有趣!
Python 提供了一些内置的队列风格,您将在本教程中看到它们的作用。您还将快速入门关于队列及其类型的理论。最后,您将看到一些外部库**,用于连接主要云平台提供商上可用的流行消息代理。**
在本教程中,您将学习如何:
- 区分各种类型的队列
- 在 Python 中实现队列数据类型
- 通过应用正确的队列解决实际问题
- 使用 Python 的线程安全、异步和进程间队列
- 通过库将 Python 与分布式消息队列代理集成在一起
为了充分利用本教程,您应该熟悉 Python 的序列类型,例如列表和元组,以及标准库中更高级别的集合。
您可以通过单击下面框中的链接下载本教程的完整源代码以及相关的示例数据:
获取源代码: 单击此处获取源代码和示例数据,您将使用它们来探索 Python 中的队列。
了解队列的类型
队列是一种抽象数据类型,表示根据一组规则排列的元素的序列。在本节中,您将了解最常见的队列类型及其相应的元素排列规则。至少,每个队列都提供了使用大 O 符号在常数时间或 O(1)中添加和删除元素的操作。这意味着无论队列大小如何,这两个操作都应该是即时的。
一些队列可能支持其他更具体的操作。是时候多了解他们了!
队列:先进先出
单词 queue 根据上下文可以有不同的含义。然而,当人们在没有使用任何限定词的情况下提到队列时,他们通常指的是 FIFO 队列,这类似于你可能在杂货店收银台或旅游景点看到的队列:

请注意,与照片中人们并排聚集的队伍不同,严格意义上的队列是一列纵队,一次只允许一个人进入。
FIFO 是先进先出的缩写,它描述了元素通过队列的流动。这种队列中的元素将按照先到先服务的原则进行处理,这是大多数真实队列的工作方式。为了更好地观察 FIFO 队列中元素的移动,请看下面的动画:
https://player.vimeo.com/video/723390369?background=1
请注意,在任何给定的时间,新元素只允许在称为尾的一端加入队列,在本例中是在右边,而最旧的元素必须从另一端离开队列。当一个元素离开队列时,它的所有跟随者向队列的头移动一个位置。这几条规则确保了元素按照到达的顺序进行处理。
注意:你可以把 FIFO 队列中的元素想象成停在交通灯前的汽车。
向 FIFO 队列中添加一个元素通常被称为入队操作,而从其中检索一个元素被称为出列操作。不要将出列操作与dequee(双端队列)数据类型混淆,稍后您将了解到这一点!
入队和出队是两个独立的操作,可能以不同的速度进行。这一事实使得 FIFO 队列成为完美的工具,用于在流场景中缓冲数据以及调度需要等待直到某些共享资源可用的任务。例如,被 HTTP 请求淹没的 web 服务器可能会将它们放入队列中,而不是立即错误地拒绝它们。
**注意:**在利用并发的程序中,一个 FIFO 队列通常成为共享资源本身,以促进异步工作者之间的双向通信。通过临时锁定对其元素的读或写访问,阻塞队列可以优雅地协调生产者池和消费者池。在后面关于多线程和多处理中队列的章节中,你会找到更多关于这个用例的信息。
关于上面描述的队列,值得注意的另一点是,随着新元素的到来,它可以无限制地增长。想象一下,在繁忙的购物季节,结账队伍一直排到了商店的后面!然而,在某些情况下,您可能更喜欢使用一个预先知道固定容量的有界队列。有界队列有助于以两种方式控制稀缺资源:
- 通过不可逆地拒绝不适合的元素
- 通过重写队列中最老的元素
在第一种策略下,一旦一个 FIFO 队列饱和,它就不会再占用更多的元素,直到其他人离开队列来腾出一些空间。您可以在下面的动画示例中看到这种工作方式:
https://player.vimeo.com/video/723396777?background=1
这个队列的容量为三,这意味着它最多可以容纳三个元素。如果你试图往里面塞更多的元素,那么它们会弹开消失,不留任何痕迹。同时,一旦占据队列的元素数量减少,队列将再次开始接受新元素。
在野外哪里可以找到这样一个有界的 FIFO 队列?
大多数数码相机都支持连拍模式,以尽可能快的速度连续拍摄一系列照片,希望能捕捉到至少一张运动物体的清晰照片。因为将数据保存到存储卡上是瓶颈,通常有一个内部缓冲使相机能够在压缩和保存早期照片的同时继续拍摄新照片。
在老式静态相机中,缓冲区通常很小,几秒钟内就会填满。当这种情况发生时,按住快门按钮将不再有任何效果,或者拍摄新照片的速度将明显降低。只有在清空数据缓冲区后,摄像机的最大速度才能完全恢复。
处理有界 FIFO 队列中的传入元素的第二个策略是让您实现一个基本的缓存,它会忘记最老的元素,而不考虑您访问它的次数或频率。当新的元素比旧的元素更有可能被重用时,FIFO 缓存工作得最好。例如,您可以使用 FIFO 缓存回收策略强制注销很久以前登录的用户,而不管他们是否仍然活跃。
**注意:**为了简单比较其他缓存回收策略,请阅读使用 LRU 缓存策略的 Python 中的缓存。
下面是一个有界 FIFO 队列的可视化描述,它最多可以容纳三个元素,但与以前不同的是,它不会阻止您添加更多元素:
https://player.vimeo.com/video/723397721?background=1
当该队列达到其最大容量时,添加新元素将首先将所有现有元素向头部移动一个位置,丢弃最旧的元素并为新元素腾出空间。请注意,被丢弃的元素会被它的近邻覆盖。
虽然无界 FIFO 队列及其两个有界对应队列涵盖了广泛的用例,但它们都有一个共同的特征,即具有独立的入口点和出口点。在下一节中,您将了解另一种流行的队列类型,它的布局略有不同。
堆栈:后进先出(LIFO)
堆栈是一种更特殊的队列,也称为 LIFO 或后进先出队列。它的工作方式几乎和普通队列完全一样,除了元素现在必须通过称为栈顶的一端加入和离开。名称 top 反映了现实世界的书库往往是垂直的这一事实。厨房水槽中的一堆盘子就是一堆的例子:

当洗碗机装满时,员工们会在吃完饭后把他们的脏盘子推到最上面。一旦橱柜里没有更多的干净盘子,饥饿的员工将不得不从堆叠的顶部弹出最后一个脏盘子,并用海绵擦干净,然后用微波炉加热他们的午餐。
如果在盘子堆的底部有一把非常需要的叉子,那么一些可怜的人将不得不一个接一个地翻遍上面所有的盘子,才能找到想要的餐具。类似地,当清洁人员在一天工作结束后来到办公室时,他们必须以相反的顺序检查盘子,然后才能检查最后一个盘子。
您将在以下动画堆栈中看到此元素移动:
https://player.vimeo.com/video/723398613?background=1
尽管上面的 LIFO 队列是水平方向的,但它保留了堆栈的一般概念。新元素通过仅在右端连接来增加堆栈,如前面的示例所示。然而,这一次,只有最后一个推入堆栈的元素可以离开它。其余的必须等待,直到没有更多的元素后来加入堆栈。
堆栈广泛用于各种目的的计算中。也许程序员最熟悉的上下文是调用栈,其中包含了按调用顺序排列的函数。在出现未处理的异常的情况下,Python 会通过回溯向你揭示这个堆栈。它通常是一个容量有限的有界堆栈,你会在过多的递归调用导致的堆栈溢出错误中发现。
在具有静态类型检查的编译语言中,局部变量被分配在堆栈上,这是一个快速内存区域。堆栈可以帮助检测代码块中不匹配的括号,或者评估用反向波兰符号(RPN) 表示的算术表达式。您还可以使用堆栈来解决河内的塔难题,或者跟踪使用深度优先搜索(DFS) 算法遍历的图或树中访问过的节点。
**注意:**当你在 DFS 算法中用一个 FIFO 队列替换堆栈,或者 LIFO 队列,并做一些小的调整,那么你将几乎免费得到广度优先搜索(BFS) 算法!在本教程的后面,您将更详细地研究这两种算法。
虽然堆栈是队列的一种特化,但是双端队列是一种一般化的队列,可以用来作为实现 FIFO 和 LIFO 队列的基础。在下一节中,您将看到 deques 是如何工作的,以及在什么地方可以使用它们。
队列:双端队列
双端队列或双端队列(发音为 deck )是一种更通用的数据类型,它结合并扩展了堆栈和队列背后的思想。它允许您在任何给定的时刻,在恒定的时间内将元素从两端入队或出队。因此,一个 deque 可以作为 FIFO 或 LIFO 队列工作,也可以作为介于两者之间的任何队列工作。
使用与前面相同的一行人的例子,您可以利用 deque 来建模更复杂的极限情况。在现实生活中,队列中的最后一个人可能会不耐烦,决定提前离开队列,或者在刚刚开放的新收银台加入另一个队列。相反,提前在网上预定了某个特定日期和时间的人可能会被允许在前面排队,而无需等待。
下面是一个动画,展示了一个无界队列的运行:
https://player.vimeo.com/video/723399870?background=1
在这个特殊的例子中,大多数元素通常遵循一个方向,加入右边的队列,离开左边的队列,就像普通的 FIFO 队列一样。但是,一些特权元素被允许从左端加入队列,而最后一个元素可以通过相对端离开队列。****
将一个元素添加到已经达到其最大容量的有界队列中将会覆盖当前位于另一端的元素。这个特性对于从序列中分离出前几个或后几个元素可能很方便。您可能还想在该序列中的任何位置停止,然后以较小的步长向左或向右移动:
https://player.vimeo.com/video/723401029?background=1
假设您正在计算光栅图像的扫描线中像素强度的移动平均值。向左或向右移动可以预览几个连续的像素值,并动态计算它们的平均值。这或多或少就是卷积核在高级图像处理中应用过滤器的工作方式。
大多数 deques 支持两个额外的操作,称为向左旋转和向右旋转,它们以循环的方式在一个或另一个方向上移动元素指定的位置。因为 deque 的大小保持不变,突出的元素会在末端缠绕,就像在模拟汽车里程表中一样:
https://player.vimeo.com/video/723405800?background=1
向右旋转时,队列中的最后一个元素成为第一个。另一方面,向左旋转时,第一个元素成为最后一个元素。也许你可以更容易地想象这个过程,把德克的元素排成一个圆圈,使两端相交。那么,向右和向左旋转将分别对应于顺时针和逆时针旋转。
旋转与 deque 的核心功能相结合,开启了有趣的可能性。例如,您可以使用一个队列来实现一个负载平衡器或者一个以循环方式工作的任务调度器。在一个 GUI 应用中,你可以使用一个队列来存储最近打开的文件,允许用户撤销和重做他们的操作,或者让用户在他们的网页浏览历史中来回导航。
正如您所看到的,deques 有许多实际用途,尤其是在跟踪最近的活动方面。然而,有些问题需要您利用另一种类型的队列,您将在接下来读到这一点。
优先级队列:从高到低排序
一个优先级队列与你目前看到的不同,因为它不能存储普通元素。相反,每个元素现在必须有一个关联的优先级,以便与其他元素进行比较。队列将保持一个排序的顺序,让新元素在需要的地方加入,同时根据需要调整现有元素。当两个元素具有相同的优先级时,它们将遵循它们的插入顺序。
**注意:**确保通过比较运算符为您的优先级选择一个值为可比的数据类型,例如小于(<)。例如,整数和时间戳可以,而复数不能用来表示优先级,因为它们没有实现任何相关的比较操作符。
这种排队方式类似于飞机上的优先登机:

普通乘客会排在队伍的最后,除非他们有小孩陪伴,有残疾,或者有积分,在这种情况下,他们会被快速排到队伍的前面。商务舱乘客通常享受单独的、小得多的队列,但即使是他们有时也不得不让头等舱乘客通过。
下面的动画演示了通过无限优先级队列的具有三个不同优先级的元素的示例流:
https://player.vimeo.com/video/723407699?background=1
蓝色方块代表最低优先级,黄色三角形在层级中较高,红色圆圈最重要。一个新元素被插入到一个具有更高或相等优先级的元素和另一个具有较低优先级的元素之间。这个规则类似于插入排序算法,它恰好是稳定的,因为具有相同优先级的元素从不交换它们的初始位置。
您可以使用优先级队列来按照给定的键对一系列元素进行排序,或者获取前几个元素。然而,这可能有些矫枉过正,因为有更有效的排序算法可用。优先级队列更适合元素可以动态进出的情况。其中一种情况是使用 Dijkstra 算法在加权图中搜索最短路径**,稍后您将会读到这一点。**
**注意:**尽管优先级队列在概念上是一个序列,但它最有效的实现是建立在堆数据结构之上的,这是一种二叉树。因此,术语堆和优先级队列有时可以互换使用。
这是对队列理论和分类的一个比较长的介绍。在此过程中,您了解了 FIFO 队列、堆栈(LIFO 队列)、deques 和优先级队列。您还看到了有界队列和无界队列之间的区别,并且对它们的潜在应用有了一定的了解。现在,是时候尝试自己实现一些队列了。
用 Python 实现队列
首先,是否应该用 Python 自己实现一个队列?在大多数情况下,这个问题的答案将是决定性的否。语言自带电池,队列也不例外。事实上,您会发现 Python 有大量适合解决各种问题的队列实现。
也就是说,尝试从零开始构建东西是一种非常宝贵的学习经历。在技术面试中,你可能还会被要求提供一个队列实现。所以,如果你觉得这个话题有趣,那么请继续读下去。否则,如果您只是想在实践中使用队列,那么完全可以跳过这一部分。
用队列表示 FIFO 和 LIFO 队列
为了表示计算机内存中的 FIFO 队列,您需要一个具有 O(1)或常数时间的序列,一端用于入队操作,另一端用于类似的高效出列操作。正如您现在已经知道的,双端队列可以满足这些要求。另外,它的通用性足以适应 LIFO 队列。
然而,因为编写代码超出了本教程的范围,所以您将利用 Python 标准库中的 deque 集合。
注意:dequee 是一种抽象数据类型,你可以用几种方式实现它。使用双向链表作为底层实现将确保从两端访问和移除元素将具有期望的 O(1)时间复杂度。如果你的 deque 有一个固定的大小,那么你可以使用一个循环缓冲区,让你在固定的时间内访问任何元素。与链表不同,循环缓冲区是一种随机存取的数据结构。
为什么不用 Python list代替collections.deque作为 FIFO 队列的构建模块呢?
这两个序列都允许用它们的.append()方法以相当低的代价将元素入队,并为列表保留一点空间,当元素数量超过某个阈值时,偶尔需要将所有元素复制到一个新的内存位置。
不幸的是,用list.pop(0)将一个元素从列表的前面退出,或者用list.insert(0, element)插入一个元素,效率要低得多。这种操作总是移动剩余的元素,导致线性或 O(n)时间复杂度。相比之下,deque.popleft()和deque.appendleft()完全避免了这一步。
这样,您就可以基于 Python 的deque集合来定义您的自定义Queue类。
构建队列数据类型
既然您已经选择了合适的队列表示,那么您可以启动您最喜欢的代码编辑器,例如 Visual Studio 代码或 PyCharm ,并为不同的队列实现创建一个新的 Python 模块。您可以调用文件queues.py(复数形式)以避免与 Python 标准库中已经可用的类似命名的queue(单数形式)模块冲突。
**注意:**在后面专门讨论 Python 中的线程安全队列的章节中,您将更仔细地了解内置的queue模块。
因为您希望您的自定义 FIFO 队列至少支持入队和出队操作,所以继续编写一个基本的Queue类,将这两个操作分别委托给deque.append()和deque.popleft()方法:
# queues.py
from collections import deque
class Queue:
def __init__(self):
self._elements = deque()
def enqueue(self, element):
self._elements.append(element)
def dequeue(self):
return self._elements.popleft()
这个类仅仅包装了一个collections.deque实例,并将其称为._elements。属性名中的前导下划线表示实现的一个内部位,只有该类可以访问和修改。这种字段有时被称为 private,因为它们不应该在类体之外可见。
您可以通过在一个交互式 Python 解释器会话中从本地模块导入来测试您的 FIFO 队列:
>>> from queues import Queue
>>> fifo = Queue()
>>> fifo.enqueue("1st")
>>> fifo.enqueue("2nd")
>>> fifo.enqueue("3rd")
>>> fifo.dequeue()
'1st'
>>> fifo.dequeue()
'2nd'
>>> fifo.dequeue()
'3rd'
正如预期的那样,入队的元素会以它们原来的顺序返回给您。如果你愿意,你可以改进你的类,使它成为可迭代的,并且能够报告它的长度和可选地接受初始元素:
# queues.py
from collections import deque
class Queue:
def __init__(self, *elements): self._elements = deque(elements)
def __len__(self): return len(self._elements)
def __iter__(self): while len(self) > 0: yield self.dequeue()
def enqueue(self, element):
self._elements.append(element)
def dequeue(self):
return self._elements.popleft()
一个deque接受一个可选的 iterable,您可以在初始化器方法中通过不同数量的位置参数*elements来提供它。通过实现特殊的.__iter__()方法,您将使您的类实例在 for循环中可用,而实现.__len__()将使它们与len()函数兼容。上面的.__iter__()方法是一个生成器迭代器的例子,它产生元素和。
注意:.__iter__()的实现通过在迭代时将元素从队列中取出来,减少了自定义队列的大小。
重新启动 Python 解释器并再次导入您的类,以查看运行中的更新代码:
>>> from queues import Queue
>>> fifo = Queue("1st", "2nd", "3rd")
>>> len(fifo)
3
>>> for element in fifo:
... print(element)
...
1st
2nd
3rd
>>> len(fifo)
0
该队列最初有三个元素,但是在一个循环中消耗完所有元素后,它的长度下降为零。接下来,您将实现一个 stack 数据类型,它将以相反的顺序将元素出队。
构建堆栈数据类型
构建一个栈数据类型要简单得多,因为您已经完成了大部分艰苦的工作。由于大部分实现保持不变,您可以使用继承来扩展您的Queue类,并覆盖.dequeue()方法以从堆栈顶部移除元素:
# queues.py
# ...
class Stack(Queue):
def dequeue(self):
return self._elements.pop()
就是这样!现在,元素从您之前推送它们的队列的同一端弹出。您可以在交互式 Python 会话中快速验证这一点:
>>> from queues import Stack
>>> lifo = Stack("1st", "2nd", "3rd")
>>> for element in lifo:
... print(element)
...
3rd
2nd
1st
使用与前面相同的设置和测试数据,元素以相反的顺序返回给您,这是 LIFO 队列的预期行为。
**注意:**在本教程中,您将继承作为一种方便的重用代码的机制。然而,当前的类关系在语义上是不正确的,因为堆栈不是队列的子类型。您也可以先定义堆栈,然后让队列扩展它。在现实世界中,你可能应该让两个类都从一个抽象基类继承,因为它们共享相同的接口。
在一次性脚本中,如果您不介意不时复制值的额外开销,那么您可能可以使用普通的旧 Python list作为基本堆栈:
>>> lifo = []
>>> lifo.append("1st")
>>> lifo.append("2nd")
>>> lifo.append("3rd")
>>> lifo.pop()
'3rd'
>>> lifo.pop()
'2nd'
>>> lifo.pop()
'1st'
Python 列表是开箱即用的。他们可以报告自己的长度,并有一个合理的文本表示。在下一节中,您将选择它们作为优先级队列的基础。
用堆表示优先级队列
您将在本教程中实现的最后一个队列是优先级队列。与堆栈不同,优先级队列不能扩展前面定义的Queue类,因为它不属于同一个类型层次结构。FIFO 或 LIFO 队列中元素的顺序完全由元素的到达时间决定。在优先级队列中,元素的优先级和插入顺序共同决定了它在队列中的最终位置。
有许多方法可以实现优先级队列,例如:
- 一个由元素及其优先级组成的无序列表,每次在将优先级最高的元素出队之前都要搜索这个列表
- 元素及其优先级的有序列表,每次新元素入队时都会对其进行排序
- 一个元素及其优先级的有序列表,通过使用二分搜索法为新元素找到合适的位置来保持排序
- 一棵二叉树,它在入队和出列操作后保持堆不变
您可以将优先级队列想象成一个列表,每次新元素到达时都需要对其进行排序,以便在执行出列操作时能够删除最后一个优先级最高的元素。或者,您可以忽略元素顺序,直到删除优先级最高的元素,这可以使用线性搜索算法找到。
在无序列表中查找元素的时间复杂度为 O(n)。对整个队列进行排序会更加昂贵,尤其是在经常使用的情况下。Python 的list.sort()方法采用了一种叫做 Timsort 的算法,该算法具有 O(n log(n))的最坏情况时间复杂度。用 bisect.insort() 插入元素稍微好一点,因为它可以利用已经排序的列表,但是这种好处被后面缓慢的插入抵消了。
幸运的是,您可以聪明地通过使用一个堆数据结构来保持元素在优先级队列中排序。它提供了比前面列出的那些更有效的实现。下表快速比较了这些不同实现提供的入队和出队操作的时间复杂度:
| 履行 | 使…入队 | 出列 |
|---|---|---|
| 在出列时查找最大值 | O(1) | O(n) |
| 排队时排序 | O(n log(n)) | O(1) |
| 入队时对分和插入 | O(n) | O(1) |
| 排队时推到堆上 | O(log(n)) | O(log(n)) |
对于大型数据卷,堆具有最佳的整体性能。虽然使用二分法为新元素找到合适的位置是 O(log(n)),但是该元素的实际插入是 O(n),这使得它不如堆理想。
Python 有heapq模块,它方便地提供了一些函数,可以将一个常规列表变成一个堆,并有效地操纵它。帮助您构建优先级队列的两个函数是:
heapq.heappush()heapq.heappop()
当你把一个新元素放到一个非空的堆上时,它会在正确的位置结束,保持堆不变。请注意,这并不一定意味着结果元素将被排序:
>>> from heapq import heappush
>>> fruits = []
>>> heappush(fruits, "orange")
>>> heappush(fruits, "apple")
>>> heappush(fruits, "banana")
>>> fruits
['apple', 'orange', 'banana']
上例中结果堆中的水果名称没有按照字母顺序排列。但是,如果你以不同的顺序推动它们,它们可以!
堆的意义不在于对元素进行排序,而是让它们保持某种关系,以便快速查找。真正重要的是,堆中的第一个元素总是具有最小(最小堆)或最大(最大堆)的值,这取决于您如何定义上述关系的条件。Python 的堆是最小堆,这意味着第一个元素具有最小的值。
当你从一个堆中取出一个元素时,你总是得到第一个,而其余的元素可能会有一点混乱:
>>> from heapq import heappop
>>> heappop(fruits)
'apple'
>>> fruits
['banana', 'orange']
请注意香蕉和橙子如何交换位置,以确保第一个元素仍然是最小的。当您告诉 Python 按值比较两个字符串对象时,它开始从左到右成对地查看它们的字符,并逐个检查每一对。具有较低的 Unicode 码位的字符被认为较小,这决定了单词顺序。
现在,你如何将优先级放入混合中?毕竟,堆通过值而不是优先级来比较元素。要解决这个问题,您可以利用 Python 的元组比较,它考虑了元组的组成部分,从左向右查看,直到结果已知:
>>> person1 = ("John", "Brown", 42)
>>> person2 = ("John", "Doe", 42)
>>> person3 = ("John", "Doe", 24)
>>> person1 < person2
True
>>> person2 < person3
False
在这里,你有三个元组代表不同的人。每个人都有名字、姓氏和年龄。Python 根据他们的姓氏决定person1应该在person2之前,因为他们有相同的名字,但是 Python 不考虑他们的年龄,因为顺序已经知道了。在第二次比较person2和person3时,年龄变得很重要,他们碰巧有相同的姓和名。
通过存储第一个元素是优先级的元组,可以在堆上强制执行优先顺序。然而,有一些细节你需要小心。在下一节中,您将了解更多关于它们的内容。
构建优先级队列数据类型
假设您正在为一家汽车公司开发软件。现代车辆实际上是车轮上的计算机,它利用控制器局域网(CAN)总线来广播关于汽车中正在发生的各种事件的信息,例如解锁车门或给安全气囊充气。显然,其中一些事件比其他事件更重要,应该相应地排列优先次序。
**有趣的事实:**你可以为你的智能手机下载一个移动应用程序,例如 Torque ,它可以让你通过蓝牙或特设的 WiFi 网络连接到你汽车的 can 总线,通过一个小的扫描设备连接到你汽车的车载诊断(OBD) 端口。
这种设置将允许您实时监控您的车辆参数,即使它们没有显示在仪表板上!这包括冷却液温度、电池电压、每加仑行驶英里数和排放量。此外,你还可以检查汽车的ECU是否报告了任何故障代码。
错过一个有故障的大灯信息或者多等一会儿音量降低也没关系。然而,当您踩下制动踏板时,您会期望它立即产生效果,因为它是一个安全关键子系统。在 CAN 总线协议中,每条消息都有一个优先级,它告诉中间单元是应该进一步转发该消息还是完全忽略该消息。
尽管这是一个过于简单化的问题,但是你可以把 can 总线看作是一个优先级队列,它根据消息的重要性对消息进行排序。现在,返回到代码编辑器,在之前创建的 Python 模块中定义以下类:
# queues.py
from collections import deque
from heapq import heappop, heappush
# ...
class PriorityQueue:
def __init__(self):
self._elements = []
def enqueue_with_priority(self, priority, value):
heappush(self._elements, (priority, value))
def dequeue(self):
return heappop(self._elements)
这是一个基本的优先级队列实现,它使用一个 Python 列表和两个操作它的方法定义了一堆元素。.enqueue_with_priority()方法接受两个参数,一个优先级和一个对应的值,然后它将这些参数封装在一个元组中,并使用heapq模块推送到堆上。注意,优先级在值之前,以利用 Python 比较元组的方式。
不幸的是,上面的实现有一些问题,当您尝试使用它时,这些问题变得很明显:
>>> from queues import PriorityQueue
>>> CRITICAL = 3
>>> IMPORTANT = 2
>>> NEUTRAL = 1
>>> messages = PriorityQueue()
>>> messages.enqueue_with_priority(IMPORTANT, "Windshield wipers turned on")
>>> messages.enqueue_with_priority(NEUTRAL, "Radio station tuned in")
>>> messages.enqueue_with_priority(CRITICAL, "Brake pedal depressed")
>>> messages.enqueue_with_priority(IMPORTANT, "Hazard lights turned on")
>>> messages.dequeue()
(1, 'Radio station tuned in')
您定义了三个优先级:关键、重要和中立。接下来,您实例化了一个优先级队列,并使用它将一些具有这些优先级的消息入队。但是,您没有将具有最高优先级的消息出队,而是获得了与具有最低优先级的消息相对应的元组。
注意:最终,你要如何定义你的优先顺序取决于你自己。在本教程中,较低的优先级对应于较低的数值,而较高的优先级具有较大的值。
也就是说,在某些情况下,颠倒这个顺序会更方便。例如,在 Dijkstra 的最短路径算法中,您会希望将总成本较小的路径优先于总成本较高的路径。为了处理这种情况,稍后您将实现另一个类。
因为 Python 的堆是最小堆,所以它的第一个元素总是有最低的值。要解决这个问题,您可以在将一个元组推到堆上时翻转优先级的符号,使优先级成为一个负数,这样最高的优先级就变成了最低的:
# queues.py
# ...
class PriorityQueue:
def __init__(self):
self._elements = []
def enqueue_with_priority(self, priority, value):
heappush(self._elements, (-priority, value))
def dequeue(self):
return heappop(self._elements)[1]
有了这个小小的改变,你将会把关键信息放在重要和中立的信息之前。此外,在执行出列操作时,您将通过使用方括号([])语法访问元组的第二个组件(位于第一个索引处)来解包该值。
现在,如果您回到交互式 Python 解释器,导入更新的代码,并再次将相同的消息排队,那么它们会以更合理的顺序返回给您:
>>> messages.dequeue()
'Brake pedal depressed'
>>> messages.dequeue()
'Hazard lights turned on'
>>> messages.dequeue()
'Windshield wipers turned on'
>>> messages.dequeue()
'Radio station tuned in'
你首先得到关键的信息,然后是两个重要的信息,然后是中性的信息。到目前为止,一切顺利,对吧?但是,您的实现有两个问题。其中一个您已经可以在输出中看到,而另一个只会在特定的情况下出现。你能发现这些问题吗?
处理优先队列中的疑难案例
您的队列可以正确地按优先级对元素进行排序,但同时,在比较具有相同优先级的元素时,它违反了排序稳定性。这意味着在上面的例子中,闪烁危险灯优先于启动挡风玻璃雨刷器,即使这种顺序并不遵循事件的时间顺序。两条消息具有相同的优先级,重要,因此队列应该按照它们的插入顺序对它们进行排序。
明确地说,这是 Python 中元组比较的直接结果,如果前面的元组没有解决比较问题,就移动到元组中的下一个组件。因此,如果两条消息具有相同的优先级,那么 Python 将通过值来比较它们,在您的示例中,值是一个字符串。字符串遵循的字典顺序,其中单词 Hazard 在单词挡风玻璃之前,因此顺序不一致。
与此相关的还有另一个问题,这在极少数情况下会完全破坏元组比较。具体来说,如果您试图将一个不支持任何比较操作符的元素入队,比如一个自定义类的实例,并且队列中已经包含了至少一个您想要使用的具有相同优先级的元素,那么它将会失败。考虑下面的数据类来表示队列中的消息:
>>> from dataclasses import dataclass
>>> @dataclass
... class Message:
... event: str
...
>>> wipers = Message("Windshield wipers turned on")
>>> hazard_lights = Message("Hazard lights turned on")
>>> wipers < hazard_lights
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'Message' and 'Message'
对象可能比普通的字符串更方便,但是与字符串不同,它们是不可比较的,除非你告诉 Python 如何执行比较。如您所见,默认情况下,自定义类实例不提供小于(<)操作符的实现。
只要使用不同的优先级对消息进行排队,Python 就不会按值对它们进行比较:
>>> messages = PriorityQueue()
>>> messages.enqueue_with_priority(CRITICAL, wipers)
>>> messages.enqueue_with_priority(IMPORTANT, hazard_lights)
例如,当您对关键消息和重要消息进行排队时,Python 会通过查看相应的优先级来明确确定它们的顺序。但是,一旦您尝试将另一个关键消息排入队列,您将会得到一个熟悉的错误:
>>> messages.enqueue_with_priority(CRITICAL, Message("ABS engaged"))
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'Message' and 'Message'
这一次,比较失败了,因为两条消息具有相同的优先级,Python 退回到通过值来比较它们,而您还没有为您的自定义Message类实例定义值。
您可以通过向堆中存储的元素引入另一个组件来解决这两个问题,即排序不稳定性和坏元组比较。这个额外的分量应该是可比较的,并且代表到达时间。当放置在元组中元素的优先级和值之间时,如果两个元素具有相同的优先级,它将解析顺序,而不管它们的值。
表示优先级队列中的到达时间的最直接的方式可能是一个单调递增的计数器。换句话说,您希望计算执行的入队操作的数量,而不考虑可能发生的潜在出队操作。然后,您将在每个入队的元素中存储计数器的当前值,以反映当时队列的状态。
可以使用 itertools 模块中的count()迭代器,以简洁的方式从零计数到无穷大:
# queues.py
from collections import deque
from heapq import heappop, heappush
from itertools import count
# ...
class PriorityQueue:
def __init__(self):
self._elements = []
self._counter = count()
def enqueue_with_priority(self, priority, value):
element = (-priority, next(self._counter), value) heappush(self._elements, element)
def dequeue(self):
return heappop(self._elements)[-1]
当您创建一个新的PriorityQueue实例时,计数器被初始化。每当您将一个值排入队列时,计数器都会递增,并在推送到堆上的元组中保留其当前状态。因此,如果您稍后将另一个具有相同优先级的值排入队列,则较早的值将优先,因为您用较小的计数器将其排入队列。
在元组中引入这个额外的计数器组件后,需要记住的最后一个细节是在出列操作期间更新弹出的值索引。因为现在元素是由三个部分组成的元组,所以应该返回位于索引二而不是索引一的值。然而,更安全的做法是使用负数作为索引来指示元组的最后一个组件*,而不考虑它的长度。*
您的优先级队列几乎准备好了,但是它缺少两个特殊的方法,.__len__()和.__iter__(),您在其他两个队列类中实现了这两个方法。虽然您不能通过继承重用他们的代码,因为优先级队列是而不是FIFO 队列的一个子类型,Python 提供了一个强大的机制让您解决这个问题。
使用 Mixin 类重构代码
为了跨不相关的类重用代码,您可以识别它们的最小公分母,然后将代码提取到一个 mixin 类中。mixin 类就像一种调味品。它不能独立存在,所以你通常不会实例化它,但是一旦你把它混合到另一个类中,它可以增加额外的味道。下面是它在实践中的工作方式:
# queues.py
# ...
class IterableMixin:
def __len__(self): return len(self._elements) def __iter__(self): while len(self) > 0: yield self.dequeue()
class Queue(IterableMixin):
# ...
class Stack(Queue):
# ...
class PriorityQueue(IterableMixin):
# ...
您将.__len__()和.__iter__()方法从Queue类移到了一个单独的IterableMixin类,并让前者扩展了 mixin。你也让PriorityQueue继承了同一个 mixin 类。这与标准继承有何不同?
不像像 Scala 这样的编程语言用特征直接支持混合,Python 使用多重继承来实现相同的概念。然而,扩展 mixin 类在语义上不同于扩展常规类,后者不再是类型专门化的一种形式。为了强调这个区别,有人称之为 mixin 类的包含而不是纯粹的继承。
注意你的 mixin 类引用了一个._elements属性,你还没有定义它!它是由具体的类提供的,比如Queue和PriorityQueue,这些类是在很久以后才加入进来的。Mixins 非常适合封装行为而不是状态,很像 Java 接口中的默认方法。通过用一个或多个 mixins 组成一个类,您可以改变或增加它的原始行为。
展开下面的可折叠部分以显示完整的源代码:
# queues.py
from collections import deque
from heapq import heappop, heappush
from itertools import count
class IterableMixin:
def __len__(self):
return len(self._elements)
def __iter__(self):
while len(self) > 0:
yield self.dequeue()
class Queue(IterableMixin):
def __init__(self, *elements):
self._elements = deque(elements)
def enqueue(self, element):
self._elements.append(element)
def dequeue(self):
return self._elements.popleft()
class Stack(Queue):
def dequeue(self):
return self._elements.pop()
class PriorityQueue(IterableMixin):
def __init__(self):
self._elements = []
self._counter = count()
def enqueue_with_priority(self, priority, value):
element = (-priority, next(self._counter), value)
heappush(self._elements, element)
def dequeue(self):
return heappop(self._elements)[-1]
有了这三个队列类,您终于可以应用它们来解决一个实际问题了!
在实践中使用队列
正如本教程介绍中提到的,队列是许多重要算法的支柱。一个特别有趣的应用领域是访问图中的节点,例如,它可能代表城市之间的道路地图。在寻找两个地方之间的最短或最佳路径时,队列非常有用。
在本节中,您将使用刚刚构建的队列来实现经典的图遍历算法。用代码表示图形的方法有很多,同样数量的 Python 库已经做得很好了。为了简单起见,您将利用 networkx 和 pygraphviz 库,以及广泛使用的 DOT 图形描述语言。
您可以使用pip将这些库安装到您的虚拟环境中:
(venv) $ python -m pip install networkx pygraphviz
或者,您可以按照补充资料中的README文件中的说明,一步安装本教程剩余部分所需的所有依赖项。注意,安装 pygraphviz 可能有点困难,因为它需要一个 C 编译器工具链。查看官方安装指南了解更多详情。
样本数据:英国路线图
一旦您安装了所需的库,您将从一个 DOT 文件中读取英国城市的加权和无向图,您可以在随附的资料中找到:
获取源代码: 单击此处获取源代码和示例数据,您将使用它们来探索 Python 中的队列。
该图有 70 个节点代表英国城市,137 条边按连接城市之间的估计英里距离加权:

请注意,上面描述的图表是英国道路网络的简化模型,因为它没有考虑道路类型、通行能力、速度限制、交通或旁路。它还忽略了一个事实,那就是连接两个城市的道路通常不止一条。因此,由卫星导航或谷歌地图确定的最短路径很可能与你在本教程中找到的排队路径不同。
也就是说,上面的图表代表了城市之间的实际道路连接,而不是直线。即使这些边缘在视觉上看起来像直线,但在现实生活中它们肯定不是。在图形上,您可以用多种方式来表示同一个图形。
接下来,您将使用 networkx 库将这个图读入 Python。
城市和道路的对象表示
虽然 networkx 本身不能读取点文件,但是该库提供了一些帮助函数,将这项任务委托给其他第三方库。在本教程中,您将使用 pygraphviz 来读取示例点文件:
>>> import networkx as nx
>>> print(nx.nx_agraph.read_dot("roadmap.dot"))
MultiGraph named 'Cities in the United Kingdom' with 70 nodes and 137 edges
虽然在某些操作系统上安装 pygraphviz 可能有点困难,但它是迄今为止最快的,并且最符合点格式的高级特性。默认情况下,networkx 使用文本标识符表示图节点,这些文本标识符可以选择具有关联的属性字典:
>>> import networkx as nx
>>> graph = nx.nx_agraph.read_dot("roadmap.dot")
>>> graph.nodes["london"]
{'country': 'England',
'latitude': '51.507222',
'longitude': '-0.1275',
'pos': '80,21!',
'xlabel': 'City of London',
'year': 0}
例如,"london"字符串映射到一个相应的键值对字典。 pos 属性包含将墨卡托投影应用于纬度和经度后的归一化坐标,该属性由 Graphviz 用于在图形可视化中放置节点。year属性表示一个城市何时获得它的地位。当等于零时,表示自古以来。
因为这不是考虑图表的最方便的方式,所以您将定义一个自定义数据类型来表示您的道路地图中的一个城市。继续,创建一个名为graph.py的新文件,并在其中实现以下类:
# graph.py
from typing import NamedTuple
class City(NamedTuple):
name: str
country: str
year: int | None
latitude: float
longitude: float
@classmethod
def from_dict(cls, attrs):
return cls(
name=attrs["xlabel"],
country=attrs["country"],
year=int(attrs["year"]) or None,
latitude=float(attrs["latitude"]),
longitude=float(attrs["longitude"]),
)
您扩展了一个名为 tuple 的,以确保您的节点对象是可散列的,这是 networkx 所需要的。您可以使用正确配置的数据类来代替,但是一个命名的元组是现成的。它也是可比较的,稍后您可能需要它来确定图的遍历顺序。.from_dict()类方法从一个点文件中提取一个属性字典,并返回一个City类的新实例。
为了利用您的新类,您需要创建一个新的 graph 实例,并注意节点标识符到 city 实例的映射。将以下助手函数添加到您的graph模块中:
# graph.py
import networkx as nx
# ...
def load_graph(filename, node_factory):
graph = nx.nx_agraph.read_dot(filename)
nodes = {
name: node_factory(attributes)
for name, attributes in graph.nodes(data=True)
}
return nodes, nx.Graph(
(nodes[name1], nodes[name2], weights)
for name1, name2, weights in graph.edges(data=True)
)
该函数为节点对象接受一个文件名和一个可调用工厂,比如你的City.from_dict()类方法。它首先读取一个点文件,并构建节点标识符到图节点的面向对象的 T4 表示的映射。最后,它返回该映射和一个包含节点和加权边的新图。
现在,您可以在交互式 Python 解释器会话中再次开始使用英国路线图:
>>> from graph import City, load_graph
>>> nodes, graph = load_graph("roadmap.dot", City.from_dict)
>>> nodes["london"]
City(
name='City of London',
country='England',
year=None,
latitude=51.507222,
longitude=-0.1275
)
>>> print(graph)
Graph with 70 nodes and 137 edges
从模块中导入 helper 函数和City类后,从一个示例点文件中加载图形,并将结果存储在两个变量中。nodes变量让您通过指定的名称获得对City类实例的引用,而graph变量保存整个 networkx Graph对象。
当寻找两个城市之间的最短路径时,您会想要识别给定城市的紧邻邻居,以找到可用的路径。使用 networkx 图形,您可以通过几种方式做到这一点。在最简单的情况下,您将使用指定的节点作为参数在图上调用.neighbors()方法:
>>> for neighbor in graph.neighbors(nodes["london"]):
... print(neighbor.name)
...
Bath
Brighton & Hove
Bristol
Cambridge
Canterbury
Chelmsford
Coventry
Oxford
Peterborough
Portsmouth
Southampton
Southend-on-Sea
St Albans
Westminster
Winchester
这仅显示相邻结点,而不显示连接边的可能权重,例如距离或估计行驶时间,您可能需要了解这些信息来选择最佳路径。如果您想包括权重,那么使用方括号语法访问一个节点:
>>> for neighbor, weights in graph[nodes["london"]].items():
... print(weights["distance"], neighbor.name)
...
115 Bath
53 Brighton & Hove
118 Bristol
61 Cambridge
62 Canterbury
40 Chelmsford
100 Coventry
58 Oxford
85 Peterborough
75 Portsmouth
79 Southampton
42 Southend-on-Sea
25 St Albans
1 Westminster
68 Winchester
邻居总是以您在点文件中定义它们的相同顺序列出。要按一个或多个权重对它们进行排序,可以使用下面的代码片段:
>>> def sort_by(neighbors, strategy):
... return sorted(neighbors.items(), key=lambda item: strategy(item[1]))
...
>>> def by_distance(weights):
... return float(weights["distance"])
...
>>> for neighbor, weights in sort_by(graph[nodes["london"]], by_distance):
... print(f"{weights['distance']:>3} miles, {neighbor.name}")
...
1 miles, Westminster
25 miles, St Albans
40 miles, Chelmsford
42 miles, Southend-on-Sea
53 miles, Brighton & Hove
58 miles, Oxford
61 miles, Cambridge
62 miles, Canterbury
68 miles, Winchester
75 miles, Portsmouth
79 miles, Southampton
85 miles, Peterborough
100 miles, Coventry
115 miles, Bath
118 miles, Bristol
首先,定义一个 helper 函数,该函数返回一个邻居列表以及按照指定策略排序的邻居权重。该策略采用与边相关联的所有权重的字典,并返回排序关键字。接下来,定义一个具体的策略,该策略根据输入字典生成浮点距离。最后,迭代伦敦的邻居,按距离升序排序。
有了这些关于 networkx 库的基本知识,现在就可以根据前面构建的定制队列数据类型来实现图遍历算法了。
使用 FIFO 队列的广度优先搜索
在广度优先搜索算法中,通过在同心层或级别中探索图来寻找满足特定条件的节点。您从任意选择的源节点开始遍历该图,除非该图是树数据结构,在这种情况下,您通常从该树的根节点开始。在每一步,你都要在深入之前访问当前节点的所有近邻。
**注意:**当图中包含循环时,为了避免陷入循环,请跟踪您访问过的邻居,并在下次遇到它们时跳过它们。例如,您可以将访问过的节点添加到 Python 集合中,然后使用in操作符检查该集合是否包含给定的节点。
例如,假设您想在英国找到一个在二十世纪被授予城市地位的地方,从爱丁堡开始搜索。networkx 库已经实现了许多算法,包括广度优先搜索,它可以帮助交叉检查您未来的实现。调用图中的nx.bfs_tree()函数来揭示广度优先的遍历顺序:
>>> import networkx as nx
>>> from graph import City, load_graph
>>> def is_twentieth_century(year):
... return year and 1901 <= year <= 2000
...
>>> nodes, graph = load_graph("roadmap.dot", City.from_dict)
>>> for node in nx.bfs_tree(graph, nodes["edinburgh"]):
... print("📍", node.name)
... if is_twentieth_century(node.year):
... print("Found:", node.name, node.year)
... break
... else:
... print("Not found")
...
📍 Edinburgh
📍 Dundee 📍 Glasgow 📍 Perth 📍 Stirling 📍 Carlisle 📍 Newcastle upon Tyne 📍 Aberdeen
📍 Inverness
📍 Lancaster
Found: Lancaster 1937
```py
突出显示的线条表示爱丁堡的所有六个近邻,这是您的源节点。请注意,在移动到图形的下一层之前,它们会被连续不间断地访问。后续层由从源节点开始的第二级邻居组成。
你探索突出显示的城市的未访问的邻居。第一个是邓迪,它的邻居包括阿伯丁和珀斯,但你已经去过珀斯了,所以你跳过它,只去阿伯丁。格拉斯哥没有任何未到访的邻居,而珀斯只有因弗内斯。同样,你去了斯特灵的邻居,却没有去卡莱尔的,卡莱尔与兰开斯特相连。你停止搜索,因为兰开斯特就是你的答案。
搜索结果有时可能会有所不同,这取决于您对起始点的选择,以及相邻结点的顺序(如果有多个结点满足某个条件)。为了确保结果一致,您可以根据某些标准对邻域进行排序。例如,您可以先访问纬度较高的城市:
>>>
def order(neighbors):
… def by_latitude(city):
… return city.latitude
… return iter(sorted(neighbors, key=by_latitude, reverse=True))
for node in nx.bfs_tree(graph, nodes[“edinburgh”], sort_neighbors=order):
… print(“📍”, node.name)
… if is_twentieth_century(node.year):
… print(“Found:”, node.name, node.year)
… break
… else:
… print(“Not found”)
…
📍 Edinburgh
📍 Dundee 📍 Perth 📍 Stirling 📍 Glasgow 📍 Newcastle upon Tyne 📍 Carlisle 📍 Aberdeen
📍 Inverness
📍 Sunderland
Found: Sunderland 1992
现在,答案不同了,因为纽卡斯尔比卡莱尔先被访问,因为它的纬度略高。反过来,这使得广度优先搜索算法在兰卡斯特之前找到桑德兰,这是一个符合你条件的备选节点。
**注意:**如果你想知道为什么`order()`在对`iter()`的调用中包装一个排序邻居列表,那是因为 [`nx.bfs_tree()`](https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.traversal.breadth_first_search.bfs_tree.html) 期望一个迭代器对象作为其`sort_neighbors`参数的输入。
现在您已经对广度优先搜索算法有了大致的了解,是时候自己实现它了。因为广度优先遍历是其他有趣算法的基础,所以您将把它的逻辑提取到一个单独的函数中,您可以将它委托给:
graph.py
from queues import Queue
…
def breadth_first_traverse(graph, source):
queue = Queue(source)
visited = {source}
while queue:
yield (node := queue.dequeue())
for neighbor in graph.neighbors(node):
if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
def breadth_first_search(graph, source, predicate):
for node in breadth_first_traverse(graph, source):
if predicate(node):
return node
第一个函数将 networkx 图和源节点作为参数,同时产生用广度优先遍历访问的节点。请注意,它使用来自`queues`模块的 **FIFO 队列**来跟踪节点邻居,确保您将在每一层上依次探索它们。该函数还通过将被访问的节点添加到一个 [Python 集合](https://realpython.com/python-sets/)中来标记它们,这样每个邻居最多被访问一次。
**注意:**不要使用`while`循环和 [walrus 操作符(`:=` )](https://realpython.com/python-walrus-operator/) 在一个表达式中产生一个出列节点,您可以利用这样一个事实,即您的定制队列是可迭代的,通过使用`for`循环使元素出列:
def breadth_first_traverse(graph, source):
queue = Queue(source)
visited = {source}
for node in queue:
yield node
for neighbor in graph.neighbors(node):
if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
然而,这依赖于您的`Queue`类中一个不明显的实现细节,所以在本教程的剩余部分,您将坚持使用更传统的`while`循环。
第二个函数建立在第一个函数的基础上,循环遍历生成的节点,一旦当前节点满足预期标准,就停止。如果没有节点使谓词为真,那么函数隐式返回 [`None`](https://realpython.com/null-in-python/) 。
为了测试广度优先搜索和遍历实现,可以用自己的函数替换 networkx 内置的便利函数:
>>>
from graph import (
… City,
… load_graph,
… breadth_first_traverse,
… breadth_first_search as bfs,
… )
def is_twentieth_century(city):
… return city.year and 1901 <= city.year <= 2000
nodes, graph = load_graph(“roadmap.dot”, City.from_dict)
city = bfs(graph, nodes[“edinburgh”], is_twentieth_century)
city.name
‘Lancaster’
for city in breadth_first_traverse(graph, nodes[“edinburgh”]):
… print(city.name)
…
Edinburgh
Dundee
Glasgow
Perth
Stirling
Carlisle
Newcastle upon Tyne
Aberdeen
Inverness
Lancaster
⋮
正如您所看到的,遍历顺序与您第一次尝试使用 networkx 时是一样的,这证实了您的算法对于这个数据集是正确的。但是,您的函数不允许以特定的顺序对邻居进行排序。尝试修改代码,使其接受可选的排序策略。您可以单击下面的可折叠部分查看一个可能的解决方案:
graph.py
…
def breadth_first_traverse(graph, source, order_by=None):
queue = Queue(source)
visited = {source}
while queue:
yield (node := queue.dequeue())
neighbors = list(graph.neighbors(node)) if order_by: neighbors.sort(key=order_by) for neighbor in neighbors: if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
def breadth_first_search(graph, source, predicate, order_by=None):
for node in breadth_first_traverse(graph, source, order_by): if predicate(node):
return node
广度优先搜索算法确保在搜索满足所需条件的节点时,您最终会探索图中所有连接的节点。例如,你可以用它来解决一个迷宫。广度优先遍历也是在无向图和无权重图中寻找两个节点之间的最短路径的基础。在下一节中,您将修改您的代码来做到这一点。
[*Remove ads*](/account/join/)
### 使用广度优先遍历的最短路径
在许多情况下,从源到目的地的路径上的节点越少,距离就越短。如果您的城市之间的连接没有权重,您可以利用这一观察来估计最短距离。这相当于每条边的权重相等。
使用广度优先方法遍历图将产生保证具有最少*个*节点的路径。有时两个节点之间可能有不止一条最短路径。例如,当您忽略道路距离时,在阿伯丁和珀斯之间有两条这样的最短路径。和以前一样,这种情况下的实际结果将取决于如何对相邻节点进行排序。
您可以使用 networkx 显示两个城市之间的所有最短路径,这两个城市具有相同的最小长度:
>>>
import networkx as nx
from graph import City, load_graph
nodes, graph = load_graph(“roadmap.dot”, City.from_dict)
city1 = nodes[“aberdeen”]
city2 = nodes[“perth”]
for i, path in enumerate(nx.all_shortest_paths(graph, city1, city2), 1):
… print(f"{i}.", " → ".join(city.name for city in path))
…
1. Aberdeen → Dundee → Perth
2. Aberdeen → Inverness → Perth
加载图表后,你[列举出](https://realpython.com/python-enumerate/)两个城市之间的最短路径,并将它们打印到屏幕上。你可以看到在阿伯丁和珀斯之间只有两条最短的路径。相比之下,伦敦和爱丁堡有四条不同的最短路径,每条路径有九个节点,但它们之间存在许多更长的路径。
广度优先遍历是如何帮助你准确找到最短路径的?
无论何时访问一个节点,都必须通过将该信息作为一个键-值对保存在字典中来跟踪引导您到该节点的前一个节点。稍后,您将能够通过跟随前面的节点从目的地追溯到源。回到您的代码编辑器,通过复制和改编您之前的`breadth_first_traverse()`函数的代码来创建另一个函数:
graph.py
…
def shortest_path(graph, source, destination, order_by=None):
queue = Queue(source)
visited = {source}
previous = {} while queue:
node = queue.dequeue() neighbors = list(graph.neighbors(node))
if order_by:
neighbors.sort(key=order_by)
for neighbor in neighbors:
if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
previous[neighbor] = node if neighbor == destination: return retrace(previous, source, destination)
这个新函数将另一个节点作为参数,并允许您使用自定义策略对邻居进行排序。它还定义了一个空字典,在访问邻居时,通过将它与路径上的前一个节点相关联来填充该字典。该字典中的所有键值对都是直接邻居,它们之间没有任何节点。
如果在您的源和目的地之间存在一条路径,那么该函数返回一个用另一个帮助函数构建的节点列表,而不是像`breadth_first_traverse()`那样产生单个节点。
**注意:**如果你愿意,你可以通过将`shortest_path()`和`breadth_first_traverse()`组合成一个函数来尝试重构这段代码。然而,有经验的程序员普遍认为,只要能让你的代码更容易理解并专注于一项职责,有一点重复有时是没问题的。
要重新创建源和目的地之间的最短路径,您可以迭代地查找之前使用广度优先方法遍历图时构建的字典:
graph.py
from collections import deque
…
def retrace(previous, source, destination):
path = deque()
current = destination
while current != source:
path.appendleft(current)
current = previous.get(current)
if current is None:
return None
path.appendleft(source)
return list(path)
因为您从目的地开始,然后往回走,所以在左侧使用 Python `deque`集合和快速追加操作会很有帮助。在每次迭代中,将当前节点添加到路径中,并移动到前一个节点。重复这些步骤,直到到达源节点或者没有前一个节点。
当您调用最短路径的基于队列的实现时,您会得到与 networkx:
>>>
from graph import shortest_path
" → ".join(city.name for city in shortest_path(graph, city1, city2))
‘Aberdeen → Dundee → Perth’
def by_latitude(city):
… return -city.latitude
…
" → ".join(
… city.name
… for city in shortest_path(graph, city1, city2, by_latitude)
… )
‘Aberdeen → Inverness → Perth’
第一条路径遵循点文件中相邻点的自然顺序,而第二条路径更喜欢纬度较高的相邻点,这是通过自定义排序策略指定的。要强制执行降序,您需要在`.latitude`属性前添加减号(`-`)。
请注意,对于某些节点,路径可能根本不存在。例如,贝尔法斯特和格拉斯哥没有陆地连接,因为它们位于两个独立的岛屿上。你需要乘渡船从一个城市到另一个城市。广度优先遍历可以告诉你两个节点是否保持**连接**。下面是实现这种检查的方法:
graph.py
…
def connected(graph, source, destination):
return shortest_path(graph, source, destination) is not None
从源节点开始,遍历连接节点的整个子图,比如北爱尔兰,之前节点的字典不会包括你的目的节点。因此,回溯将立即停止并返回`None`,让您知道在源和目的地之间没有路径。
您可以在交互式 Python 解释器会话中验证这一点:
>>>
from graph import connected
connected(graph, nodes[“belfast”], nodes[“glasgow”])
False
connected(graph, nodes[“belfast”], nodes[“derry”])
True
厉害!使用自定义的 FIFO 队列,您可以遍历图形,找到两个节点之间的最短路径,甚至确定它们是否相连。通过在代码中添加一个小的调整,您将能够将遍历从广度优先改为深度优先,这就是您现在要做的。
### 使用 LIFO 队列的深度优先搜索
顾名思义,深度优先遍历沿着从源节点开始的路径,在**回溯**到最后一个边交叉并尝试另一个分支之前,尽可能深地陷入图中。注意当您通过用`nx.dfs_tree()`替换`nx.bfs_tree()`来修改前面的示例时,遍历顺序的不同:
>>>
import networkx as nx
from graph import City, load_graph
def is_twentieth_century(year):
… return year and 1901 <= year <= 2000
…
nodes, graph = load_graph(“roadmap.dot”, City.from_dict)
for node in nx.dfs_tree(graph, nodes[“edinburgh”]): … print(“📍”, node.name)
… if is_twentieth_century(node.year):
… print(“Found:”, node.name, node.year)
… break
… else:
… print(“Not found”)
…
📍 Edinburgh
📍 Dundee 📍 Aberdeen
📍 Inverness
📍 Perth 📍 Stirling 📍 Glasgow 📍 Carlisle 📍 Lancaster
Found: Lancaster 1937
现在,不再按顺序浏览源节点的突出显示的邻居。到达邓迪后,算法继续沿着相同的路径前进,而不是访问第一个图层上爱丁堡的下一个邻居。
为了便于回溯,您可以在广度优先遍历函数中用一个 **LIFO 队列**来替换 FIFO 队列,您将非常接近深度优先遍历。然而,它只有在遍历树数据结构时才会正确运行。有圈的图有细微的差别,这需要在代码中做额外的修改。否则,您将实现一个基于[堆栈的图遍历](https://11011110.github.io/blog/2013/12/17/stack-based-graph-traversal.html),它的工作方式完全不同。
**注意:**在[二叉树](https://en.wikipedia.org/wiki/Binary_tree)遍历中,深度优先搜索算法定义了几个众所周知的[排序](https://en.wikipedia.org/wiki/Tree_traversal#Depth-first_search)供子节点访问——例如,前序、按序、后序。
在经典的深度优先遍历中,除了用堆栈替换队列之外,最初不会将源节点标记为已访问:
graph.py
from queues import Queue, Stack
…
def depth_first_traverse(graph, source, order_by=None):
stack = Stack(source)
visited = set()
while stack:
if (node := stack.dequeue()) not in visited:
yield node
visited.add(node)
neighbors = list(graph.neighbors(node))
if order_by:
neighbors.sort(key=order_by)
for neighbor in reversed(neighbors):
stack.enqueue(neighbor)
请注意,在开始从堆栈中弹出元素之前,您访问过的节点被初始化为一个空集。您还要检查该节点是否比广度优先遍历中更早就被访问过。当迭代邻居时,您颠倒它们的顺序以考虑 LIFO 队列的颠倒。最后,在将邻居推入堆栈后,不要立即将其标记为已访问。
因为深度优先遍历依赖于堆栈数据结构,所以您可以利用内置的**调用堆栈**来保存当前的搜索路径,以便稍后进行回溯,并递归地重写您的函数:
graph.py
…
def recursive_depth_first_traverse(graph, source, order_by=None):
visited = set()
def visit(node):
yield node
visited.add(node)
neighbors = list(graph.neighbors(node))
if order_by:
neighbors.sort(key=order_by)
for neighbor in neighbors:
if neighbor not in visited:
yield from visit(neighbor)
return visit(source)
通过这样做,您可以避免维护自己的堆栈,因为 Python 会在后台为您将每个函数调用推到一个堆栈上。当相应的函数返回时,它弹出一个。您只需要跟踪被访问的节点。递归实现的另一个优点是,迭代时不必反转邻居,也不必将已经访问过的邻居推到堆栈上。
有了遍历函数,现在可以实现深度优先搜索算法了。因为广度优先和深度优先搜索算法看起来几乎相同,只是遍历顺序不同,所以可以通过将两种算法的公共部分委托给模板函数来重构代码:
graph.py
…
def breadth_first_search(graph, source, predicate, order_by=None):
return search(breadth_first_traverse, graph, source, predicate, order_by)
…
def depth_first_search(graph, source, predicate, order_by=None):
return search(depth_first_traverse, graph, source, predicate, order_by)
def search(traverse, graph, source, predicate, order_by=None):
for node in traverse(graph, source, order_by):
if predicate(node):
return node
现在,你的`breadth_first_search()`和`depth_first_search()`函数用相应的遍历策略调用`search()`。继续在交互式 Python 解释器会话中测试它们:
>>>
from graph import (
… City,
… load_graph,
… depth_first_traverse,
… depth_first_search as dfs,
… )
def is_twentieth_century(city):
… return city.year and 1901 <= city.year <= 2000
…
nodes, graph = load_graph(“roadmap.dot”, City.from_dict)
city = dfs(graph, nodes[“edinburgh”], is_twentieth_century)
city.name
‘Lancaster’
for city in depth_first_traverse(graph, nodes[“edinburgh”]):
… print(city.name)
…
Edinburgh
Dundee
Aberdeen
Inverness
Perth
Stirling
Glasgow
Carlisle
Lancaster
⋮
即使搜索结果恰好与广度优先搜索算法相同,您也可以清楚地看到,遍历的顺序现在不同了,而是遵循一条线性路径。
您已经看到了在 FIFO 和 LIFO 队列之间进行选择会如何影响底层的图遍历算法。到目前为止,在寻找两个城市之间的最短路径时,您只考虑了中间节点的数量。在下一节中,您将更进一步,利用优先级队列来查找最佳路径,该路径有时可能包含更多的节点。
### 使用优先级队列的 Dijkstra 算法
根据样本点文件中的图表,伦敦和爱丁堡之间节点数最少的路径有 9 个站点,总距离从 451 英里到 574 英里不等。有四条这样的路径:
| 451 英里 | 460 英里 | 465 英里 | 574 英里 |
| --- | --- | --- | --- |
| 伦敦城 | 伦敦城 | 伦敦城 | 伦敦城 |
| 考文垂 | 彼得伯勒 | 彼得伯勒 | 布里斯托尔 |
| 伯明翰 | 林肯 | 诺丁汉 | 纽波特 |
| 斯托克 | 设菲尔德 | 设菲尔德 | St Asaph |
| 利物浦 | 韦克菲尔德 | 韦克菲尔德 | 利物浦 |
| 普雷斯顿 | 约克 | 约克 | 普雷斯顿 |
| 兰克斯特 | 达勒姆 | 达勒姆 | 兰克斯特 |
| 卡莱尔 | 泰恩河畔的纽卡斯尔 | 泰恩河畔的纽卡斯尔 | 卡莱尔 |
| 爱丁堡 | 爱丁堡 | 爱丁堡 | 爱丁堡 |
这些路径之间有很大的重叠,因为它们在到达目的地之前会在几个十字路口迅速汇合。在某种程度上,它们也与伦敦和爱丁堡之间距离**最短的路径**重叠,相当于 436 英里,尽管还有两个停靠站:
1. 伦敦城
2. 圣奥尔本斯
3. 考文垂
4. 伯明翰
5. 斯托克
6. 曼彻斯特
7. 索尔福德
8. 普雷斯顿
9. 兰克斯特
10. 卡莱尔
11. 爱丁堡
有时,为了节省时间、燃料或里程,绕道而行是值得的,即使这意味着沿途要经过更多的地方。
当你在组合中加入边缘砝码时,有趣的可能性就会出现在你面前。例如,您可以在视频游戏中实现基本的人工智能,方法是将导致虚拟敌人的负权重分配给边缘,将指向某种奖励的正权重分配给边缘。你也可以把像[魔方](https://rubiks.com/)这样的游戏中的移动表示为[决策树](https://en.wikipedia.org/wiki/Game_tree)来寻找最优解。
也许遍历加权图最常见的用途是当[计划路线](https://en.wikipedia.org/wiki/Journey_planner)时。在加权图或有许多并行连接的[多重图](https://en.wikipedia.org/wiki/Multigraph)中寻找最短路径的一个方法是 [Dijkstra 的算法](https://en.wikipedia.org/wiki/Dijkstra%27s_algorithm),它建立在广度优先搜索算法的基础上。然而,Dijkstra 的算法使用了一个特殊的**优先级队列**,而不是常规的 FIFO 队列。
解释 [Dijkstra 的最短路径算法](https://www.youtube.com/watch?v=pVfj6mxhdMw)超出了本教程的范围。然而,简而言之,你可以把它分解成以下两个步骤:
1. 构建从一个固定源节点到图中所有其他节点的三条最短路径。
2. 使用与之前使用普通最短路径算法相同的方式,追溯从目的节点到源节点的路径。
第一部分是关于以贪婪的方式扫描每个未访问节点的加权边,检查它们是否提供了从源到当前邻居之一的更便宜的连接。从源到邻居的路径的总成本是边的权重和从源到当前访问的节点的累积成本之和。有时,包含更多节点的路径总开销会更小。
以下是 Dijkstra 算法第一步对源自贝尔法斯特的路径的示例结果:
| 城市 | 以前的 | 总成本 |
| --- | --- | --- |
| 阿马 | 利斯本 | Forty-one |
| 贝尔法斯特 | - | Zero |
| 存有偏见 | 贝尔法斯特 | Seventy-one |
| 利斯本 | 贝尔法斯特 | nine |
| 纽里 | 利斯本 | Forty |
上表中的第一列表示从出发地到目的地的最短路径上的城市。第二列显示了从源头到目的地的最短路径上的前一个城市。最后一列包含从源到城市的总距离信息。
贝尔法斯特是源城市,因此它没有前一个节点通向它,距离为零。源与 Derry 和 Lisburn 相邻,可以从贝尔法斯特直接到达,代价是相应的边。要去阿马或纽瑞,穿过利斯本会给你从贝尔法斯特最短的总距离。
现在,如果你想找到贝尔法斯特和阿玛之间的最短路径,那么从你的目的地开始,跟随前一篇专栏文章。要到达阿玛,你必须经过利斯本,而要到达利斯本,你必须从贝尔法斯特出发。那是你逆序的最短路径。
您只需要实现 Dijkstra 算法的第一部分,因为您已经有了第二部分,第二部分负责根据之前的节点重新寻找最短路径。然而,为了将未访问的节点排队,您必须使用 min-heap 的**可变版本,这样您就可以在发现更便宜的连接时更新元素优先级。展开下面的可折叠部分以实现这个新队列:**
在内部,这个专门的优先级队列存储数据类元素,而不是元组,因为元素必须是可变的。注意附加的`order`标志,它使元素具有可比性,就像元组一样:
queues.py
from collections import deque
from dataclasses import dataclass
from heapq import heapify, heappop, heappush
from itertools import count
from typing import Any
…
@dataclass(order=True)
class Element:
priority: float
count: int
value: Any
class MutableMinHeap(IterableMixin):
def init(self):
super().init()
self._elements_by_value = {}
self._elements = []
self._counter = count()
def __setitem__(self, unique_value, priority):
if unique_value in self._elements_by_value:
self._elements_by_value[unique_value].priority = priority
heapify(self._elements)
else:
element = Element(priority, next(self._counter), unique_value)
self._elements_by_value[unique_value] = element
heappush(self._elements, element)
def __getitem__(self, unique_value):
return self._elements_by_value[unique_value].priority
def dequeue(self):
return heappop(self._elements).value
这个可变的最小堆的行为与您之前编写的常规优先级队列基本相同,但是它还允许您使用方括号语法查看或修改元素的优先级。
一旦所有元素都就位,您就可以最终将它们连接在一起了:
graph.py
from math import inf as infinity
from queues import MutableMinHeap, Queue, Stack
…
def dijkstra_shortest_path(graph, source, destination, weight_factory):
previous = {}
visited = set()
unvisited = MutableMinHeap()
for node in graph.nodes:
unvisited[node] = infinity
unvisited[source] = 0
while unvisited:
visited.add(node := unvisited.dequeue())
for neighbor, weights in graph[node].items():
if neighbor not in visited:
weight = weight_factory(weights)
new_distance = unvisited[node] + weight
if new_distance < unvisited[neighbor]:
unvisited[neighbor] = new_distance
previous[neighbor] = node
return retrace(previous, source, destination)
最初,到所有目的地城市的距离都是未知的,因此您为每个未访问的城市分配一个无限的成本,但源城市除外,其距离等于零。稍后,当您找到一条到邻居的更便宜的路径时,您将更新它与优先级队列中的源的总距离,这将重新平衡自身,以便下次具有最短距离的未访问节点将首先弹出。
您可以交互式地测试您的 Dijkstra 算法,并将其与 networkx 实现进行比较:
>>>
import networkx as nx
from graph import City, load_graph, dijkstra_shortest_path
nodes, graph = load_graph(“roadmap.dot”, City.from_dict)
city1 = nodes[“london”]
city2 = nodes[“edinburgh”]
def distance(weights):
… return float(weights[“distance”])
…
for city in dijkstra_shortest_path(graph, city1, city2, distance):
… print(city.name)
…
City of London
St Albans
Coventry
Birmingham
Stoke-on-Trent
Manchester
Salford
Preston
Lancaster
Carlisle
Edinburgh
def weight(node1, node2, weights):
… return distance(weights)
…
for city in nx.dijkstra_path(graph, city1, city2, weight):
… print(city.name)
…
City of London
St Albans
Coventry
Birmingham
Stoke-on-Trent
Manchester
Salford
Preston
Lancaster
Carlisle
Edinburgh
成功!这两个函数在伦敦和爱丁堡之间产生完全相同的最短路径。
这就结束了本教程的理论部分,这是相当激烈的。至此,您已经对不同种类的队列有了相当扎实的理解,您可以从头开始高效地实现它们,并且您知道在给定的算法中选择哪一种。然而,在实践中,您更可能依赖 Python 提供的高级抽象。
## 使用线程安全队列
现在假设你已经写了一个有不止一个执行流的程序。除了作为一个有价值的算法工具,队列还可以帮助抽象出[多线程](https://realpython.com/intro-to-python-threading/)环境中对共享资源的[并发](https://realpython.com/python-concurrency/)访问,而不需要显式锁定。Python 提供了一些**同步队列**类型,您可以安全地在多线程上使用它们来促进它们之间的通信。
在本节中,您将使用 Python 的[线程安全](https://en.wikipedia.org/wiki/Thread_safety)队列来实现经典的[多生产者、多消费者问题](https://en.wikipedia.org/wiki/Producer%E2%80%93consumer_problem)。更具体地说,您将创建一个命令行脚本,让您决定生产者和消费者的数量、它们的相对速度以及队列的类型:
$ python thread_safe_queues.py --producers 3
–consumers 2
–producer-speed 1
–consumer-speed 1
–queue fifo
所有参数都是可选的,并且有合理的默认值。运行该脚本时,您将看到生产者和消费者线程通过同步队列进行通信的动画模拟:
[](https://files.realpython.com/media/queue_fifo.4bfb28b845b0.png)
<figcaption class="figure-caption text-center">Visualization of the Producers, Consumers, and the Thread-Safe Queue</figcaption>
该脚本使用丰富的库,您需要首先将它安装到您的虚拟环境中:
(venv) $ python -m pip install rich
这将允许你添加颜色、[表情符号](https://en.wikipedia.org/wiki/Emoji)和可视组件到你的终端。请注意,有些终端可能不支持这种富文本格式。请记住,如果您还没有下载本教程中提到的脚本的完整源代码,可以随时通过下面的链接下载:
**获取源代码:** [单击此处获取源代码和示例数据](https://realpython.com/bonus/queue-code/),您将使用它们来探索 Python 中的队列。
在开始使用队列之前,您必须做一些搭建工作。创建一个名为`thread_safe_queues.py`的新文件,并定义脚本的入口点,脚本将使用 [`argparse`](https://realpython.com/command-line-interfaces-python-argparse/) 模块解析参数:
thread_safe_queues.py
import argparse
from queue import LifoQueue, PriorityQueue, Queue
QUEUE_TYPES = {
“fifo”: Queue,
“lifo”: LifoQueue,
“heap”: PriorityQueue
}
def main(args):
buffer = QUEUE_TYPESargs.queue
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(“-q”, “–queue”, choices=QUEUE_TYPES, default=“fifo”)
parser.add_argument(“-p”, “–producers”, type=int, default=3)
parser.add_argument(“-c”, “–consumers”, type=int, default=2)
parser.add_argument(“-ps”, “–producer-speed”, type=int, default=1)
parser.add_argument(“-cs”, “–consumer-speed”, type=int, default=1)
return parser.parse_args()
if name == “main”:
try:
main(parse_args())
except KeyboardInterrupt:
pass
首先,将必要的模块和队列类导入到全局名称空间中。`main()`函数是您的入口点,它接收由`parse_args()`提供的解析后的参数,定义如下。`QUEUE_TYPES`字典将队列名称映射到它们各自的类,您可以调用它来基于命令行参数的值创建一个新的队列实例。
接下来,您定义您的生产商将随机挑选并假装正在生产的产品:
thread_safe_queues.py
…
PRODUCTS = (
“🎈”,
“🍪”,
“🔮”,
“:diving_mask:”,
“🔦”,
“💎”,
“🎁”,
“:kite:”,
“:party_popper:”,
“📯”,
“🎀”,
“🚀”,
“:teddy_bear:”,
“:thread:”,
“:yo-yo:”,
)
…
这些是文本代码,里奇最终会用相应的表情符号[符号](https://en.wikipedia.org/wiki/Glyph)来替换它们。例如,`:balloon:`将呈现为🎈。您可以在您的终端中运行`python -m rich.emoji`来查找 Rich 中所有可用的表情代码。
您的生产者线程和消费者线程将共享大量属性和行为,您可以将它们封装在一个公共基类中:
```py
# thread_safe_queues.py
import threading
# ...
class Worker(threading.Thread):
def __init__(self, speed, buffer):
super().__init__(daemon=True)
self.speed = speed
self.buffer = buffer
self.product = None
self.working = False
self.progress = 0
worker 类扩展了threading.Thread类,并将自己配置为守护进程线程,这样当主线程结束时,它的实例不会阻止你的程序退出,例如,由于键盘中断信号。一个 worker 对象需要一个速度和一个缓冲队列来存放或取出成品。
除此之外,您还可以检查工作线程的状态,并请求它模拟一些工作或空闲时间:
# thread_safe_queues.py
from random import randint
from time import sleep
# ...
class Worker(threading.Thread):
# ...
@property
def state(self):
if self.working:
return f"{self.product} ({self.progress}%)"
return ":zzz: Idle"
def simulate_idle(self):
self.product = None
self.working = False
self.progress = 0
sleep(randint(1, 3))
def simulate_work(self):
self.working = True
self.progress = 0
delay = randint(1, 1 + 15 // self.speed)
for _ in range(100):
sleep(delay / 100)
self.progress += 1
.state 属性返回一个字符串,该字符串包含产品名称和工作进度,或者是一条通用消息,表明工作人员当前处于空闲状态。.simulate_idle()方法重置工作线程的状态,并随机选择几秒钟进入睡眠状态。类似地,.simulate_work()根据工人的速度随机选择延迟时间,并在工作中不断进步。
研究基于 Rich library 的表示层对于理解这个例子并不重要,但是可以随意展开下面的可折叠部分以获得更多细节:
下面的代码定义了一个视图,该视图以每秒十次的速度呈现生产者、消费者和队列的当前状态:
# thread_safe_queues.py
from itertools import zip_longest
from rich.align import Align
from rich.columns import Columns
from rich.console import Group
from rich.live import Live
from rich.panel import Panel
# ...
class View:
def __init__(self, buffer, producers, consumers):
self.buffer = buffer
self.producers = producers
self.consumers = consumers
def animate(self):
with Live(
self.render(), screen=True, refresh_per_second=10
) as live:
while True:
live.update(self.render())
def render(self):
match self.buffer:
case PriorityQueue():
title = "Priority Queue"
products = map(str, reversed(list(self.buffer.queue)))
case LifoQueue():
title = "Stack"
products = list(self.buffer.queue)
case Queue():
title = "Queue"
products = reversed(list(self.buffer.queue))
case _:
title = products = ""
rows = [
Panel(f"[bold]{title}:[/] {', '.join(products)}", width=82)
]
pairs = zip_longest(self.producers, self.consumers)
for i, (producer, consumer) in enumerate(pairs, 1):
left_panel = self.panel(producer, f"Producer {i}")
right_panel = self.panel(consumer, f"Consumer {i}")
rows.append(Columns([left_panel, right_panel], width=40))
return Group(*rows)
def panel(self, worker, title):
if worker is None:
return ""
padding = " " * int(29 / 100 * worker.progress)
align = Align(
padding + worker.state, align="left", vertical="middle"
)
return Panel(align, height=5, title=title)
# ...
注意使用结构模式匹配来基于队列类型设置标题和产品。一旦生产者和消费者就位,您将创建一个视图实例并调用它的.animate()方法。
接下来,您将定义生产者和消费者类,并将这些部分连接在一起。
排队。队列
您将尝试的第一个同步队列是一个无界 FIFO 队列,或者简单地说,是一个队列。你需要把它传递给你的生产者和消费者,所以现在就去定义他们吧。producer 线程将扩展一个 worker 类,并获取额外的产品集合以供选择:
# thread_safe_queues.py
from random import choice, randint
# ...
class Producer(Worker):
def __init__(self, speed, buffer, products):
super().__init__(speed, buffer)
self.products = products
def run(self):
while True:
self.product = choice(self.products)
self.simulate_work()
self.buffer.put(self.product)
self.simulate_idle()
# ...
方法是所有魔法发生的地方。生产者在一个无限循环中工作,选择一个随机的产品并在将该产品放入队列之前模拟一些工作,称为buffer。然后它会随机休眠一段时间,当它再次醒来时,这个过程会重复。
消费者非常相似,但比生产者更直接:
# thread_safe_queues.py
# ...
class Consumer(Worker):
def run(self):
while True:
self.product = self.buffer.get() self.simulate_work()
self.buffer.task_done() self.simulate_idle()
# ...
它还在无限循环中工作,等待一个产品出现在队列中。默认情况下,.get()方法是阻塞,这将使消费者线程停止并等待,直到队列中至少有一个产品。这样,当操作系统将宝贵的资源分配给其他线程做有用的工作时,等待的消费者不会浪费任何 CPU 周期。
**注意:**为了避免死锁,您可以通过传递一个带有放弃前等待秒数的timeout关键字参数,在.get()方法上设置一个超时。
每次从同步队列中获取数据时,它的内部计数器都会增加,让其他线程知道队列还没有被清空。因此,当您完成处理一个出列任务时,将它标记为 done 是很重要的,除非您没有任何线程加入队列。这样做会减少队列的内部计数器。
现在,回到您的main()函数,创建生产者和消费者线程,并启动它们:
# thread_safe_queues.py
# ...
def main(args):
buffer = QUEUE_TYPES[args.queue]()
producers = [
Producer(args.producer_speed, buffer, PRODUCTS)
for _ in range(args.producers)
]
consumers = [
Consumer(args.consumer_speed, buffer) for _ in range(args.consumers)
]
for producer in producers:
producer.start()
for consumer in consumers:
consumer.start()
view = View(buffer, producers, consumers)
view.animate()
生产者和消费者的数量由传递给函数的命令行参数决定。一旦您启动它们,它们就会开始工作并使用队列进行线程间通信。底部的View实例不断地重新呈现屏幕,以反映应用程序的当前状态:
https://player.vimeo.com/video/723346276?background=1
生产商总是会把他们的成品通过这个队列推向消费者。尽管有时看起来好像消费者直接从生产者那里获取元素,但这只是因为事情发生得太快,以至于没有注意到入队和出队操作。
**注意:**值得注意的是,每当生产者将某个元素放入同步队列时,至多一个消费者会将该元素出队并处理它,而其他消费者不会知道。如果您希望将程序中的某个特定事件通知给多个用户,那么看看 threading 模块中的其他线程协调原语。
您可以增加生成器的数量,提高它们的速度,或者两者都提高,以查看这些变化如何影响系统的整体容量。因为队列是无限的,它永远不会减慢生产者的速度。但是,如果您指定了队列的maxsize参数,那么它将开始阻塞它们,直到队列中再次有足够的空间。
使用 FIFO 队列使得生产者将元素放在上面可视化的队列的左端。同时,消费者相互竞争队列中最右边的产品。在下一节中,您将看到当您使用--queue lifo选项调用脚本时,这种行为是如何变化的。
尾巴!尾巴!LIFO queue〔t0〕
从员工的角度来看,完全没有必要为了修改他们的交流方式而对代码做任何修改。仅仅通过向它们注入不同类型的同步队列,您就可以修改工人通信的规则。现在使用 LIFO 队列运行您的脚本:
$ python thread_safe_queues.py --queue lifo
使用 LIFO 队列或堆栈时,刚创建的每个新产品都将优先于队列中的旧产品:
https://player.vimeo.com/video/723358546?background=1
在极少数情况下,当新产品的开发速度快于消费者的应对速度时,旧产品可能会遭遇饥饿,因为它们被困在堆栈的底部,永远不会被消费掉。另一方面,当你有足够大的消费者群体或者当你没有获得同样多的新产品时,这可能不是一个问题。饥饿还可能涉及到优先级队列中的元素,您将在接下来读到这一点。
排队。优先级队列
要使用同步优先级队列或堆,您需要在代码中做一些调整。首先,您将需要一种具有相关优先级的新产品,因此定义两种新的数据类型:
# thread_safe_queues.py
from dataclasses import dataclass, field
from enum import IntEnum
# ...
@dataclass(order=True)
class Product:
priority: int
label: str = field(compare=False)
def __str__(self):
return self.label
class Priority(IntEnum):
HIGH = 1
MEDIUM = 2
LOW = 3
PRIORITIZED_PRODUCTS = (
Product(Priority.HIGH, ":1st_place_medal:"),
Product(Priority.MEDIUM, ":2nd_place_medal:"),
Product(Priority.LOW, ":3rd_place_medal:"),
)
为了表示产品,您使用了一个数据类,并启用了定制的字符串表示和排序,但是您要注意不要通过标签来比较产品。在这种情况下,您希望标签是一个字符串,但通常,它可以是任何可能根本不可比的对象。您还定义了一个具有已知优先级值的 enum 类和三个优先级从高到低递减的产品。
**注意:**与之前的优先级队列实现相反,Python 的线程安全队列首先对优先级数值最低的元素进行排序。
此外,当用户在命令行中提供--queue heap选项时,您必须向您的生产者线程提供正确的产品集合:
# thread_safe_queues.py
# ...
def main(args):
buffer = QUEUE_TYPES[args.queue]()
products = PRIORITIZED_PRODUCTS if args.queue == "heap" else PRODUCTS producers = [
Producer(args.producer_speed, buffer, products) for _ in range(args.producers)
]
# ...
您可以根据使用条件表达式的命令行参数来提供普通产品或优先产品。
只要生产者和消费者知道如何处理新的产品类型,您的代码的其余部分就可以对这种变化保持不可知。因为这只是一个模拟,工作线程并不真正对产品做任何有用的事情,所以您可以用--queue heap标志运行您的脚本,看看效果:
https://player.vimeo.com/video/723371195?background=1
请记住,堆数据结构是一棵二叉树,它的元素之间保持着特定的关系。因此,尽管优先级队列中的产品看起来排列不太正确,但它们实际上是按照正确的顺序被消费的。此外,由于多线程编程的不确定性,Python 队列并不总是报告它们最新的大小。
好了,您已经看到了使用三种类型的同步队列来协调工作线程的传统方式。Python 线程非常适合于受 I/O 约束的任务,这些任务大部分时间都在等待网络、文件系统或数据库上的数据。然而,最近出现了同步队列的单线程替代方案,利用了 Python 的异步特性。这就是你现在要看的。
使用异步队列
如果您想在异步上下文中使用队列,那么 Python 可以满足您。 asyncio 模块提供了来自threading模块的队列的异步副本,您可以在单线程上的协程函数中使用。因为两个队列族共享一个相似的接口,所以从一个队列族切换到另一个队列族应该相对容易。
在本节中,您将编写一个基本的网络爬虫,它递归地跟踪指定网站上的链接,直到给定的深度级别,并计算每个链接的访问量。要异步获取数据,您将使用流行的 aiohttp 库,而要解析 HTML 超链接,您将依赖 beautifulsoup4 。在继续之前,请确保将这两个库都安装到您的虚拟环境中:
(venv) $ python -m pip install aiohttp beautifulsoup4
现在,您可以异步发出 HTTP 请求,并从从服务器接收的所谓的标记汤中选择 HTML 元素。
**注:**你可以用美汤和 Python搭建一个网页刮刀,在访问网页的同时收集有价值的数据。
为了给你的网络爬虫打基础,你首先要做几个构件。创建一个名为async_queues.py的新文件,并在其中定义以下结构:
# async_queues.py
import argparse
import asyncio
from collections import Counter
import aiohttp
async def main(args):
session = aiohttp.ClientSession()
try:
links = Counter()
display(links)
finally:
await session.close()
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("url")
parser.add_argument("-d", "--max-depth", type=int, default=2)
parser.add_argument("-w", "--num-workers", type=int, default=3)
return parser.parse_args()
def display(links):
for url, count in links.most_common():
print(f"{count:>3} {url}")
if __name__ == "__main__":
asyncio.run(main(parse_args()))
与大多数异步程序一样,您将您的main()协程传递给asyncio.run(),以便它可以在默认的事件循环上执行它。协程接受一些用下面定义的 helper 函数解析的命令行参数,启动一个新的aiohttp.ClientSession,并定义一个已访问链接的计数器。稍后,协程会显示按访问次数降序排列的链接列表。
要运行脚本,您需要指定一个根 URL,还可以选择最大深度和工作线程数。这里有一个例子:
$ python async_queues.py https://www.python.org/ --max-depth 2 \
--num-workers 3
仍然缺少一些部分,如获取内容和解析 HTML 链接,所以将它们添加到您的文件中:
# async_queues.py
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# ...
async def fetch_html(session, url):
async with session.get(url) as response:
if response.ok and response.content_type == "text/html":
return await response.text()
def parse_links(url, html):
soup = BeautifulSoup(html, features="html.parser")
for anchor in soup.select("a[href]"):
href = anchor.get("href").lower()
if not href.startswith("javascript:"):
yield urljoin(url, href)
只要接收的内容是 HTML,你就只返回它,这可以通过查看Content-Type HTTP 头来判断。当从 HTML 内容中提取链接时,您将跳过href属性中的内联 JavaScript ,并可选地加入一个带有当前 URL 的相对路径。
接下来,您将定义一个新的数据类型,表示您将放入队列的作业,以及执行该作业的异步工作器:
# async_queues.py
import sys
from typing import NamedTuple
# ...
class Job(NamedTuple):
url: str
depth: int = 1
# ...
async def worker(worker_id, session, queue, links, max_depth):
print(f"[{worker_id} starting]", file=sys.stderr)
while True:
url, depth = await queue.get() links[url] += 1
try:
if depth <= max_depth:
print(f"[{worker_id} {depth=} {url=}]", file=sys.stderr)
if html := await fetch_html(session, url):
for link_url in parse_links(url, html):
await queue.put(Job(link_url, depth + 1))
except aiohttp.ClientError:
print(f"[{worker_id} failed at {url=}]", file=sys.stderr)
finally:
queue.task_done()
作业由要访问的 URL 地址和当前深度组成,工作人员将使用该深度停止递归爬行。由于将一个作业指定为一个命名元组,所以在将它出队之后,您可以在突出显示的行上解包它的各个组件。如果不指定作业的深度,则默认为 1。
该工人坐在无限循环中,等待队列中的作业到达。消耗完一个作业后,工人可以将一个或多个深度提升的新作业放入队列中,由自己或其他工人消耗。
因为你的工人既是的生产者又是的消费者,所以在try … finally条款中无条件地将一项工作标记为已完成以避免僵局是至关重要的。您还应该处理您的 worker 中的错误,因为未处理的异常将使您的 worker 停止接受新的任务。
**注意:**你可以在异步代码中使用 print() 函数——例如,记录诊断消息——因为一切都运行在一个线程上。另一方面,你必须在多线程代码中用 logging 模块替换它,因为print()函数不是线程安全的。
另外,请注意,您将诊断消息打印到标准错误(stderr) ,而您的程序的输出打印到标准输出(stdout) ,这是两个完全独立的流。例如,这允许您将一个或两个重定向到一个文件。
您的员工在访问 URL 时会增加点击次数。此外,如果当前 URL 的深度没有超过允许的最大深度,那么 worker 将获取 URL 指向的 HTML 内容,并遍历其链接。walrus 操作符(:=)允许您等待 HTTP 响应,检查内容是否返回,并在单个表达式中将结果赋给html变量。
剩下的最后一步是创建异步队列的实例,并将其传递给工作线程。
阿辛西奥。队列
在本节中,您将通过创建队列和运行工作线程的异步任务来更新您的main()协程。每个 worker 将收到一个唯一的标识符,以便在日志消息、aiohttp会话、队列实例、访问特定链接的计数器和最大深度中区分它。因为您使用的是单线程,所以不需要确保互斥访问共享资源:
1# async_queues.py
2
3# ...
4
5async def main(args):
6 session = aiohttp.ClientSession()
7 try:
8 links = Counter()
9 queue = asyncio.Queue()
10 tasks = [
11 asyncio.create_task(
12 worker(
13 f"Worker-{i + 1}",
14 session,
15 queue,
16 links,
17 args.max_depth,
18 )
19 )
20 for i in range(args.num_workers)
21 ]
22
23 await queue.put(Job(args.url))
24 await queue.join()
25
26 for task in tasks:
27 task.cancel()
28
29 await asyncio.gather(*tasks, return_exceptions=True)
30
31 display(links)
32 finally:
33 await session.close()
34
35# ...
下面是更新代码的逐行分解:
- 第 9 行实例化一个异步 FIFO 队列。
- 第 10 行到第 21 行创建了许多包装在异步任务中的工作协程,这些任务在事件循环的后台尽快开始运行。
- 第 23 行将第一个作业放入队列,开始爬行。
- 第 24 行使主协程等待,直到队列被清空,并且不再有作业要执行。
- 第 26 到 29 行在不再需要后台任务时进行优雅的清理。
请不要对一个实际的在线网站运行网络爬虫。它会导致网络流量出现不必要的峰值,给你带来麻烦。为了测试您的爬虫,您最好启动 Python 内置的 HTTP 服务器,它会将文件系统中的本地文件夹转换为可导航的网站。例如,以下命令将使用 Python 虚拟环境启动本地文件夹中的服务器:
$ cd venv/
$ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
不过,这与现实世界的网站不太相似,因为文件和文件夹构成了树状层次结构,而网站通常由带有反向链接的密集多图表示。无论如何,当您在另一个终端窗口中针对一个选定的 URL 地址运行网络爬虫时,您会注意到爬虫会按照链接出现的自然顺序进行搜索:
$ python async_queues.py http://localhost:8000 --max-depth=4
[Worker-1 starting]
[Worker-1 depth=1 url='http://localhost:8000']
[Worker-2 starting]
[Worker-3 starting]
[Worker-1 depth=2 url='http://localhost:8000/bin/']
[Worker-2 depth=2 url='http://localhost:8000/include/']
[Worker-3 depth=2 url='http://localhost:8000/lib/']
[Worker-2 depth=2 url='http://localhost:8000/lib64/']
[Worker-1 depth=2 url='http://localhost:8000/pyvenv.cfg']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate.csh']
[Worker-1 depth=3 url='http://localhost:8000/bin/activate.fish']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate.ps1']
[Worker-2 depth=3 url='http://localhost:8000/bin/pip']
[Worker-3 depth=3 url='http://localhost:8000/bin/pip3']
[Worker-1 depth=3 url='http://localhost:8000/bin/pip3.10']
[Worker-2 depth=3 url='http://localhost:8000/bin/python']
[Worker-3 depth=3 url='http://localhost:8000/bin/python3']
[Worker-1 depth=3 url='http://localhost:8000/bin/python3.10']
[Worker-2 depth=3 url='http://localhost:8000/lib/python3.10/']
[Worker-3 depth=3 url='http://localhost:8000/lib64/python3.10/']
[Worker-2 depth=4 url='http://localhost:8000/lib/python3.10/site-packages/']
[Worker-3 depth=4 url='http://localhost:8000/lib64/python3.10/site-packages/']
⋮
它访问第一层上深度等于 1 的唯一 URL。然后,在访问了第二层上的所有链接之后,爬虫前进到第三层,等等,直到到达所请求的最大深度层。一旦浏览了给定级别上的所有链接,爬行器就不会返回到更早的级别。这是使用 FIFO 队列的直接结果,它不同于使用堆栈或 LIFO 队列。
阿辛西奥。LifoQueue
与同步队列一样,它们的异步伙伴让您可以在不修改代码的情况下更改工作线程的行为。回到您的async_queues模块,用 LIFO 队列替换现有的 FIFO 队列:
# async_queues.py
# ...
async def main(args):
session = aiohttp.ClientSession()
try:
links = Counter()
queue = asyncio.LifoQueue() tasks = [
asyncio.create_task(
worker(
f"Worker-{i + 1}",
session,
queue,
links,
args.max_depth,
)
)
for i in range(args.num_workers)
]
await queue.put(Job(args.url))
await queue.join()
for task in tasks:
task.cancel()
await asyncio.gather(*tasks, return_exceptions=True)
display(links)
finally:
await session.close()
# ...
在不停止 HTTP 服务器的情况下,再次使用相同的选项运行 web crawler:
$ python async_queues.py http://localhost:8000 --max-depth=4
[Worker-1 starting]
[Worker-1 depth=1 url='http://localhost:8000']
[Worker-2 starting]
[Worker-3 starting]
[Worker-1 depth=2 url='http://localhost:8000/pyvenv.cfg']
[Worker-2 depth=2 url='http://localhost:8000/lib64/']
[Worker-3 depth=2 url='http://localhost:8000/lib/']
[Worker-1 depth=2 url='http://localhost:8000/include/']
[Worker-2 depth=3 url='http://localhost:8000/lib64/python3.10/']
[Worker-3 depth=3 url='http://localhost:8000/lib/python3.10/']
[Worker-1 depth=2 url='http://localhost:8000/bin/'] [Worker-2 depth=4 url='http://localhost:8000/lib64/python3.10/site-packages/']
[Worker-1 depth=3 url='http://localhost:8000/bin/python3.10'] [Worker-2 depth=3 url='http://localhost:8000/bin/python3']
[Worker-3 depth=4 url='http://localhost:8000/lib/python3.10/site-packages/']
[Worker-1 depth=3 url='http://localhost:8000/bin/python'] [Worker-2 depth=3 url='http://localhost:8000/bin/pip3.10']
[Worker-1 depth=3 url='http://localhost:8000/bin/pip3']
[Worker-3 depth=3 url='http://localhost:8000/bin/pip']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate.ps1']
[Worker-1 depth=3 url='http://localhost:8000/bin/activate.fish']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate.csh']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate']
⋮
假设自上次运行以来内容没有改变,爬虫访问相同的链接,但是顺序不同。突出显示的行表示访问了先前探索的深度级别上的链接。
**注意:**如果您跟踪已经访问过的链接,并在随后的遭遇中跳过它们,那么这可能会导致不同的输出,具体取决于所使用的队列类型。这是因为许多不同的路径可能起源于不同的深度水平,但却通向同一个目的地。
接下来,您将看到一个异步优先级队列在运行。
异步的。优先权队列〔t0〕
要在优先级队列中使用您的作业,您必须指定在决定它们的优先级时如何比较它们。例如,您可能想先访问较短的 URL。继续将.__lt__()特殊方法添加到您的Job类中,当比较两个作业实例时,小于(<)操作符将委托给该类:
# async_queues.py
# ...
class Job(NamedTuple):
url: str
depth: int = 1
def __lt__(self, other): if isinstance(other, Job): return len(self.url) < len(other.url)
如果你把一个作业和一个完全不同的数据类型做比较,那么你不能说哪个更小,所以你隐式地返回None。另一方面,当比较Job类的两个实例时,通过检查它们对应的.url字段的长度来解析它们的优先级:
>>> from async_queues import Job
>>> job1 = Job("http://localhost/")
>>> job2 = Job("https://localhost:8080/")
>>> job1 < job2
True
URL 越短,优先级越高,因为较小的值在最小堆中优先。
脚本中的最后一个变化是使用异步优先级队列,而不是另外两个队列:
# async_queues.py
# ...
async def main(args):
session = aiohttp.ClientSession()
try:
links = Counter()
queue = asyncio.PriorityQueue() tasks = [
asyncio.create_task(
worker(
f"Worker-{i + 1}",
session,
queue,
links,
args.max_depth,
)
)
for i in range(args.num_workers)
]
await queue.put(Job(args.url))
await queue.join()
for task in tasks:
task.cancel()
await asyncio.gather(*tasks, return_exceptions=True)
display(links)
finally:
await session.close()
# ...
尝试使用更大的最大深度值运行网络爬虫——比方说,5:
$ python async_queues.py http://localhost:8000 --max-depth 5
[Worker-1 starting]
[Worker-1 depth=1 url='http://localhost:8000']
[Worker-2 starting]
[Worker-3 starting]
[Worker-1 depth=2 url='http://localhost:8000/bin/']
[Worker-2 depth=2 url='http://localhost:8000/lib/']
[Worker-3 depth=2 url='http://localhost:8000/lib64/']
[Worker-3 depth=2 url='http://localhost:8000/include/']
[Worker-2 depth=2 url='http://localhost:8000/pyvenv.cfg']
[Worker-1 depth=3 url='http://localhost:8000/bin/pip']
[Worker-3 depth=3 url='http://localhost:8000/bin/pip3']
[Worker-2 depth=3 url='http://localhost:8000/bin/python']
[Worker-1 depth=3 url='http://localhost:8000/bin/python3']
[Worker-3 depth=3 url='http://localhost:8000/bin/pip3.10']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate']
[Worker-1 depth=3 url='http://localhost:8000/bin/python3.10']
[Worker-3 depth=3 url='http://localhost:8000/lib/python3.10/']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate.ps1']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate.csh']
[Worker-1 depth=3 url='http://localhost:8000/lib64/python3.10/']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate.fish']
[Worker-3 depth=4 url='http://localhost:8000/lib/python3.10/site-packages/']
[Worker-1 depth=4 url='http://localhost:8000/lib64/python3.10/site-packages/']
⋮
您会立即注意到,链接通常是按照 URL 长度决定的顺序浏览的。当然,由于服务器回复时间的不确定性,每次运行的确切顺序会略有不同。
异步队列是 Python 标准库的一个相当新的补充。它们故意模仿相应线程安全队列的接口,这应该让任何经验丰富的 python 爱好者有宾至如归的感觉。您可以使用异步队列在协程之间交换数据。
在下一节中,您将熟悉 Python 标准库中可用的最后一类队列,它允许您跨两个或更多操作系统级进程进行通信。
使用multiprocessing.Queue进行进程间通信(IPC)
到目前为止,您已经研究了只能在严格 I/O 受限的任务场景中有所帮助的队列,这些任务的进度不依赖于可用的计算能力。另一方面,使用 Python 在多个 CPU 内核上并行运行受 CPU 限制的任务的传统方法利用了对解释器进程的克隆。您的操作系统提供了用于在这些进程间共享数据的进程间通信(IPC) 层。
例如,您可以使用 multiprocessing 启动一个新的 Python 进程,或者从 concurrent.futures 模块中使用一个这样的进程池。这两个模块都经过精心设计,以尽可能平稳地从线程切换到进程,这使得并行化现有代码变得相当简单。在某些情况下,只需要替换一个 import 语句,因为代码的其余部分遵循标准接口。
你只能在multiprocessing模块中找到 FIFO 队列,它有三种变体:
multiprocessing.Queuemultiprocessing.SimpleQueuemultiprocessing.JoinableQueue
它们都是模仿基于线程的queue.Queue的,但是在完整性级别上有所不同。JoinableQueue通过添加.task_done()和.join()方法扩展了multiprocessing.Queue类,允许您等待直到所有排队的任务都被处理完。如果不需要这个功能,那就用multiprocessing.Queue代替。SimpleQueue是一个独立的、显著简化的类,只有.get()、.put()和.empty()方法。
**注意:**在操作系统进程之间共享一个资源,比如一个队列,比在线程之间共享要昂贵得多,而且受到限制。与线程不同,进程不共享公共内存区域,所以每次从一个进程向另一个进程传递消息时,数据必须在两端进行编组和解组。
而且 Python 使用 pickle 模块进行数据序列化,不处理每种数据类型,相对较慢且不安全。因此,只有当并行运行代码带来的性能提升可以抵消额外的数据序列化和引导开销时,才应该考虑多个进程。
为了看到一个关于multiprocessing.Queue的实际例子,您将通过尝试使用蛮力方法反转一个短文本的 MD5 哈希值来模拟一个计算密集型任务。虽然有更好的方法来解决这个问题,无论是算法上的还是程序上的和,并行运行多个进程将会让你显著减少处理时间。
在单线程上反转 MD5 哈希
在并行化您的计算之前,您将关注于实现算法的单线程版本,并根据一些测试输入来测量执行时间。创建一个名为multiprocess_queue的新 Python 模块,并将以下代码放入其中:
1# multiprocess_queue.py
2
3import time
4from hashlib import md5
5from itertools import product
6from string import ascii_lowercase
7
8def reverse_md5(hash_value, alphabet=ascii_lowercase, max_length=6):
9 for length in range(1, max_length + 1):
10 for combination in product(alphabet, repeat=length):
11 text_bytes = "".join(combination).encode("utf-8")
12 hashed = md5(text_bytes).hexdigest()
13 if hashed == hash_value:
14 return text_bytes.decode("utf-8")
15
16def main():
17 t1 = time.perf_counter()
18 text = reverse_md5("a9d1cbf71942327e98b40cf5ef38a960")
19 print(f"{text} (found in {time.perf_counter() - t1:.1f}s)")
20
21if __name__ == "__main__":
22 main()
第 8 行到第 14 行定义了一个函数,该函数试图反转作为第一个参数提供的 MD5 哈希值。默认情况下,该函数只考虑最多包含六个小写 ASCII 字母的文本。您可以通过提供另外两个可选参数来更改要猜测的字母表和文本的最大长度。
对于字母表中给定长度的每个可能的字母组合,reverse_md5()计算一个哈希值,并将其与输入进行比较。如果有匹配,那么它停止并返回猜测的文本。
**注意:**现在,MD5 被认为是密码不安全的,因为你可以快速计算这样的摘要。然而,从 26 个 ASCII 字母中抽取的 6 个字符给出了总共 308,915,776 种不同的组合,这对 Python 程序来说已经足够了。
第 16 行到第 19 行调用函数,将样本 MD5 哈希值作为参数传递,并使用 Python 定时器测量其执行时间。在一台经验丰富的台式计算机上,可能需要几秒钟才能找到指定输入的散列组合:
$ python multiprocess_queue.py
queue (found in 6.9s)
如您所见,单词 queue 就是答案,因为它有一个 MD5 摘要,与您在第 18 行上的硬编码哈希值相匹配。七秒钟并不可怕,但是通过利用空闲的 CPU 内核,您可能会做得更好,这些内核渴望为您做一些工作。为了利用它们的潜力,您必须将数据分块并将其分发给您的工作进程。
分块平均分配工作负载
您希望通过将整个字母组合集分成几个更小的不相交的子集来缩小每个 worker 中的搜索空间。为了确保工作人员不会浪费时间去做已经由另一个工作人员完成的工作,这些集合不能有任何重叠。虽然您不知道单个块的大小,但是您可以提供与 CPU 核心数量相等的块。
要计算后续块的索引,请使用下面的帮助函数:
# multiprocess_queue.py
# ...
def chunk_indices(length, num_chunks):
start = 0
while num_chunks > 0:
num_chunks = min(num_chunks, length)
chunk_size = round(length / num_chunks)
yield start, (start := start + chunk_size)
length -= chunk_size
num_chunks -= 1
它产生由当前块的第一个索引和它的最后一个索引加 1 组成的元组,这使得元组可以方便地用作内置range()函数的输入。由于对后续数据块长度的取整,那些不同长度的数据块最终很好地交错在一起:
>>> from multiprocess_queue import chunk_indices
>>> for start, stop in chunk_indices(20, 6):
... print(len(r := range(start, stop)), r)
...
3 range(0, 3)
3 range(3, 6)
4 range(6, 10) 3 range(10, 13)
4 range(13, 17) 3 range(17, 20)
例如,分成六个块的总长度 20 产生在三个和四个元素之间交替的索引。
为了最大限度地降低进程间数据序列化的成本,每个 worker 将根据出列作业对象中指定的索引范围生成自己的字母组合块。您需要为特定的索引找到一个字母组合或 m-set 的一个 n 元组。为了让您的生活更轻松,您可以将公式封装到一个新的类中:
# multiprocess_queue.py
# ...
class Combinations:
def __init__(self, alphabet, length):
self.alphabet = alphabet
self.length = length
def __len__(self):
return len(self.alphabet) ** self.length
def __getitem__(self, index):
if index >= len(self):
raise IndexError
return "".join(
self.alphabet[
(index // len(self.alphabet) ** i) % len(self.alphabet)
]
for i in reversed(range(self.length))
)
该自定义数据类型表示给定长度的字母组合的集合。多亏了这两个特殊的方法和当所有组合都用尽时抛出的IndexError异常,您可以使用一个循环迭代Combinations类的实例。
上面的公式确定了由索引指定的组合中给定位置的字符,就像汽车中的里程表或数学中的定位系统一样。最右边的字母变化最频繁,而越靠左的字母变化越少。
现在,您可以更新您的 MD5-reversing 函数,以使用新的类并删除itertools.product import 语句:
# multiprocess_queue.py
# ...
def reverse_md5(hash_value, alphabet=ascii_lowercase, max_length=6):
for length in range(1, max_length + 1):
for combination in Combinations(alphabet, length): text_bytes = "".join(combination).encode("utf-8")
hashed = md5(text_bytes).hexdigest()
if hashed == hash_value:
return text_bytes.decode("utf-8")
# ...
不幸的是,用纯 Python 函数替换用 C 实现的内置函数并在 Python 中进行一些计算会使代码慢一个数量级:
$ python multiprocess_queue.py
queue (found in 38.8s)
你可以做一些优化来获得几秒钟的时间。例如,你可以在你的Combinations类中实现.__iter__(),以避免产生if语句或引发异常。您还可以将字母表的长度存储为实例属性。然而,对于这个例子来说,这些优化并不重要。
接下来,您将创建工作进程、作业数据类型和两个单独的队列,以便在主进程及其子进程之间进行通信。
以全双工模式通信
每个工作进程都将有一个对包含要消费的作业的输入队列的引用,以及一个对预期解决方案的输出队列的引用。这些引用支持工人和主进程之间的同步双向通信,称为全双工通信。要定义一个工作进程,您需要扩展Process类,它提供了我们熟悉的.run()方法,就像一个线程:
# multiprocess_queue.py
import multiprocessing
# ...
class Worker(multiprocessing.Process):
def __init__(self, queue_in, queue_out, hash_value):
super().__init__(daemon=True)
self.queue_in = queue_in
self.queue_out = queue_out
self.hash_value = hash_value
def run(self):
while True:
job = self.queue_in.get()
if plaintext := job(self.hash_value):
self.queue_out.put(plaintext)
break
# ...
稍后,主进程将定期检查是否有一个工人在输出队列中放置了一个反转的 MD5 文本,并在这种情况下提前终止程序。工人是守护进程,所以他们不会耽误主进程。另请注意,workers 存储输入哈希值以进行反转。
添加一个Job类,Python 将序列化该类并将其放在输入队列中供工作进程使用:
# multiprocess_queue.py
from dataclasses import dataclass
# ...
@dataclass(frozen=True)
class Job:
combinations: Combinations
start_index: int
stop_index: int
def __call__(self, hash_value):
for index in range(self.start_index, self.stop_index):
text_bytes = self.combinations[index].encode("utf-8")
hashed = md5(text_bytes).hexdigest()
if hashed == hash_value:
return text_bytes.decode("utf-8")
通过在作业中实现特殊的方法.__call__(),你可以调用你的类的对象。由于这个原因,当工人收到这些任务时,他们可以像调用常规函数一样调用这些任务。该方法的主体与reverse_md5()相似,但略有不同,您现在可以移除它,因为您不再需要它了。
最后,在启动工作进程之前,创建两个队列并用作业填充输入队列:
# multiprocess_queue.py
import argparse
# ...
def main(args):
queue_in = multiprocessing.Queue()
queue_out = multiprocessing.Queue()
workers = [
Worker(queue_in, queue_out, args.hash_value)
for _ in range(args.num_workers)
]
for worker in workers:
worker.start()
for text_length in range(1, args.max_length + 1):
combinations = Combinations(ascii_lowercase, text_length)
for indices in chunk_indices(len(combinations), len(workers)):
queue_in.put(Job(combinations, *indices))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("hash_value")
parser.add_argument("-m", "--max-length", type=int, default=6)
parser.add_argument(
"-w",
"--num-workers",
type=int,
default=multiprocessing.cpu_count(),
)
return parser.parse_args()
# ...
if __name__ == "__main__":
main(parse_args())
和前面的例子一样,您使用argparse模块解析命令行参数。脚本的唯一强制参数是要反转的哈希值,例如:
(venv) $ python multiprocess_queue.py a9d1cbf71942327e98b40cf5ef38a960
您可以使用--num-workers命令行参数指定工作进程的数量,该参数默认为您的 CPU 内核的数量。由于上下文切换的额外成本,将工作者的数量增加到超过硬件中的物理或逻辑处理单元的数量通常没有好处,这种成本开始增加。
另一方面,在 I/O 绑定的任务中,上下文切换变得几乎可以忽略不计,在这种情况下,您可能最终拥有数千个工作线程或协程。流程是一个不同的故事,因为它们的创建成本要高得多。即使您使用一个进程池预先加载这个成本,也有一定的限制。
此时,您的工作人员通过输入和输出队列与主流程进行双向通信。然而,程序在启动后突然退出,因为主进程没有等待它的守护进程子进程处理完它们的作业就结束了。现在是时候定期轮询输出队列,寻找潜在的解决方案,当您找到一个解决方案时,就可以跳出循环了:
1# multiprocess_queue.py
2
3import queue
4import time
5
6# ...
7
8def main(args):
9 t1 = time.perf_counter() 10
11 queue_in = multiprocessing.Queue()
12 queue_out = multiprocessing.Queue()
13
14 workers = [
15 Worker(queue_in, queue_out, args.hash_value)
16 for _ in range(args.num_workers)
17 ]
18
19 for worker in workers:
20 worker.start()
21
22 for text_length in range(1, args.max_length + 1):
23 combinations = Combinations(ascii_lowercase, text_length)
24 for indices in chunk_indices(len(combinations), len(workers)):
25 queue_in.put(Job(combinations, *indices))
26
27 while any(worker.is_alive() for worker in workers): 28 try: 29 solution = queue_out.get(timeout=0.1) 30 if solution: 31 t2 = time.perf_counter() 32 print(f"{solution} (found in {t2 - t1:.1f}s)") 33 break 34 except queue.Empty: 35 pass 36 else: 37 print("Unable to find a solution") 38
39# ...
您在队列的.get()方法上设置可选的timeout参数,以避免阻塞并允许 while 循环运行其条件。找到解决方案后,将它从输出队列中取出,在标准输出中打印匹配的文本以及估计的执行时间,然后退出循环。注意,multiprocessing.Queue引发了在queue模块中定义的异常,您可能需要导入这些异常。
然而,当没有匹配的解决方案时,循环将永远不会停止,因为您的工人仍然活着,等待更多的作业来处理,即使已经消耗了所有的作业。他们被困在queue_in.get()通话中,这是阻塞。您将在接下来的部分中解决这个问题。
用毒丸杀死一名工人
因为要消耗的作业数量是预先知道的,所以您可以告诉工人在清空队列后优雅地关闭。请求线程或进程停止工作的典型模式是将一个特殊的标记值放在队列的末尾。每当一个工人发现哨兵,它会做必要的清理,并逃离无限循环。这种哨兵被称为毒丸,因为它会杀死工人。
为 sentinel 选择值可能很棘手,尤其是对于multiprocessing模块,因为它处理全局名称空间的方式。查看官方文档中的编程指南了解更多细节。最安全的方法可能是坚持使用预定义的值,比如None,它在任何地方都有一个已知的身份:
# multiprocess_queue.py
POISON_PILL = None
# ...
如果您使用一个定义为全局变量的自定义object()实例,那么您的每个工作进程都将拥有该对象的自己的副本,并具有惟一的标识。一个 worker 入队的 sentinel 对象将被反序列化为另一个 worker 中的一个全新实例,该实例具有与其全局变量不同的标识。因此,您无法在队列中检测出毒丸。
另一个需要注意的细微差别是,在使用完毒丸之后,要小心地将它放回源队列中:
# multiprocess_queue.py
# ...
class Worker(multiprocessing.Process):
def __init__(self, queue_in, queue_out, hash_value):
super().__init__(daemon=True)
self.queue_in = queue_in
self.queue_out = queue_out
self.hash_value = hash_value
def run(self):
while True:
job = self.queue_in.get()
if job is POISON_PILL: self.queue_in.put(POISON_PILL) break if plaintext := job(self.hash_value):
self.queue_out.put(plaintext)
break
# ...
这将会给其他工人一个吞下毒丸的机会。或者,如果您知道您的员工的确切人数,那么您可以让那么多的毒丸入队,每个人一粒。在消耗完哨兵并将其放回队列后,一个工人跳出了无限循环,结束了它的生命。
最后,不要忘记将毒丸作为最后一个元素添加到输入队列中:
# multiprocess_queue.py
# ...
def main(args):
t1 = time.perf_counter()
queue_in = multiprocessing.Queue()
queue_out = multiprocessing.Queue()
workers = [
Worker(queue_in, queue_out, args.hash_value)
for _ in range(args.num_workers)
]
for worker in workers:
worker.start()
for text_length in range(1, args.max_length + 1):
combinations = Combinations(ascii_lowercase, text_length)
for indices in chunk_indices(len(combinations), len(workers)):
queue_in.put(Job(combinations, *indices))
queue_in.put(POISON_PILL)
while any(worker.is_alive() for worker in workers):
try:
solution = queue_out.get(timeout=0.1)
t2 = time.perf_counter()
if solution:
print(f"{solution} (found in {t2 - t1:.1f}s)")
break
except queue.Empty:
pass
else:
print("Unable to find a solution")
# ...
现在,您的脚本已经完成,可以处理查找匹配文本以及面对 MD5 哈希值不可逆转的情况。在下一节中,您将运行几个基准测试,看看整个练习是否值得。
分析并行执行的性能
当您比较原始单线程版本和多处理版本的执行速度时,您可能会感到失望。虽然您注意最小化数据序列化成本,但是将代码重写为纯 Python 才是真正的瓶颈。
更令人惊讶的是,速度似乎随着输入哈希值以及工作进程数量的变化而变化:
您可能会认为增加工作线程的数量会减少总的计算时间,在一定程度上确实如此。从单个工人到多个工人的比例大幅下降。然而,随着您添加更多的工作线程,执行时间会周期性地来回跳动。这里有几个因素在起作用。
首先,如果匹配的组合位于包含您的解决方案的块的末尾附近,那么被分配到该块的幸运工人将运行更长时间。根据搜索空间中的分割点(来源于工人的数量),您将在一个块中获得不同的解决方案距离。其次,即使距离保持不变,你创造的工人越多,环境切换的影响就越大。
另一方面,如果你的所有员工总是有同样多的工作要做,那么你会观察到一个大致的线性趋势,没有突然的跳跃。如您所见,并行化 Python 代码的执行并不总是一个简单的过程。也就是说,只要有一点点耐心和坚持,你肯定可以优化这几个瓶颈。例如,您可以:
- 想出一个更聪明的公式
- 通过缓存和预先计算中间结果来换取速度
- 内联函数调用和其他昂贵的构造
- 查找带有 Python 绑定的第三方 C 库
- 编写一个 Python C 扩展模块或者使用 ctypes 或者 Cython
- 为 Python 带来实时(JIT) 编译工具
- 切换到另一个 Python 解释器,比如 PyPy
至此,您已经了解了 Python 标准库中所有可用的队列类型,包括同步线程安全队列、异步队列和基于进程的并行性的 FIFO 队列。在下一节中,您将简要了解几个第三方库,它们将允许您与独立的消息队列代理集成。
将 Python 与分布式消息队列集成
在有许多移动部件的分布式系统中,通常希望使用中间的消息代理来分离应用程序组件,它承担生产者和消费者服务之间弹性消息传递的负担。它通常需要自己的基础架构,这既是优势也是劣势。
一方面,它是另一个增加复杂性和需要维护的抽象层,但是如果配置正确,它可以提供以下好处:
- **松耦合:**您可以修改一个组件或用另一个组件替换它,而不会影响系统的其余部分。
- **灵活性:**您可以通过更改代理配置和消息传递规则来改变系统的业务规则,而无需编写代码。
- **可伸缩性:**您可以动态添加更多给定种类的组件,以处理特定功能领域中增加的工作量。
- **可靠性:**消费者可能需要在代理从队列中删除消息之前确认消息,以确保安全交付。在集群中运行代理可以提供额外的容错能力。
- **持久性:**当消费者由于故障而离线时,代理可以在队列中保留一些消息。
- **性能:**为消息代理使用专用的基础设施可以减轻应用程序服务的负担。
有许多不同类型的消息代理和您可以使用它们的场景。在这一节中,您将领略其中的一些。
RabbitMQ: pika
RabbitMQ 可能是最受欢迎的开源消息代理之一,它允许您以多种方式将消息从生产者发送到消费者。通过运行一个临时的 Docker 容器,您可以方便地启动一个新的 RabbitMQ 代理,而无需在您的计算机上安装它:
$ docker run -it --rm --name rabbitmq -p 5672:5672 rabbitmq
一旦启动,您就可以在本地主机和默认端口 5672 上连接到它。官方文档推荐使用 Pika 库来连接 Python 中的 RabbitMQ 实例。这是一个初级制作人的样子:
# producer.py
import pika
QUEUE_NAME = "mailbox"
with pika.BlockingConnection() as connection:
channel = connection.channel()
channel.queue_declare(queue=QUEUE_NAME)
while True:
message = input("Message: ")
channel.basic_publish(
exchange="",
routing_key=QUEUE_NAME,
body=message.encode("utf-8")
)
您使用默认参数打开一个连接,这假设 RabbitMQ 已经在您的本地机器上运行。然后,创建一个新的通道,它是 TCP 连接之上的轻量级抽象。您可以拥有多个独立的频道进行单独的传输。在进入循环之前,确保代理中存在一个名为mailbox的队列。最后,您继续发布从用户那里读取的消息。
消费者只是稍微长一点,因为它需要定义一个回调函数来处理消息:
# consumer.py
import pika
QUEUE_NAME = "mailbox"
def callback(channel, method, properties, body):
message = body.decode("utf-8")
print(f"Got message: {message}")
with pika.BlockingConnection() as connection:
channel = connection.channel()
channel.queue_declare(queue=QUEUE_NAME)
channel.basic_consume(
queue=QUEUE_NAME,
auto_ack=True,
on_message_callback=callback
)
channel.start_consuming()
大多数样板代码看起来与您的生产者相似。但是,您不需要编写显式循环,因为使用者将无限期地监听消息。
继续,在单独的终端选项卡中启动一些生产者和消费者。请注意,在队列已经有一些未使用的消息之后,或者如果有多个消费者连接到代理,当第一个消费者连接到 RabbitMQ 时会发生什么情况。
再说一遍:redis
Redis 是远程词典服务器的简称,其实真的是很多东西在伪装。它是一个内存中的键值数据存储,通常作为传统的 SQL 数据库和服务器之间的超高速缓存。同时,它可以作为一个持久化的 NoSQL 数据库,也可以作为发布-订阅模型中的消息代理。您可以使用 Docker 启动本地 Redis 服务器:
$ docker run -it --rm --name redis -p 6379:6379 redis
这样,您将能够使用 Redis 命令行界面连接到正在运行的容器:
$ docker exec -it redis redis-cli
127.0.0.1:6379>
看一下官方文档中的命令列表,并在连接到 Redis 服务器时试用它们。或者,您可以直接跳到 Python 中。Redis 官方页面上列出的第一个库是 redis ,但值得注意的是,您可以从许多备选库中进行选择,包括异步库。
编写一个基本的发布者只需要几行 Python 代码:
# publisher.py
import redis
with redis.Redis() as client:
while True:
message = input("Message: ")
client.publish("chatroom", message)
您连接到一个本地 Redis 服务器实例,并立即开始在chatroom通道上发布消息。您不必创建通道,因为 Redis 会为您创建。订阅频道需要一个额外的步骤,创建PubSub对象来调用.subscribe()方法:
# subscriber.py
import redis
with redis.Redis() as client:
pubsub = client.pubsub()
pubsub.subscribe("chatroom")
for message in pubsub.listen():
if message["type"] == "message":
body = message["data"].decode("utf-8")
print(f"Got message: {body}")
订阅者收到的消息是带有一些元数据的 Python 字典,这让您可以决定如何处理它们。如果有多个活动订阅者在一个频道上收听,那么所有订阅者都会收到相同的消息。另一方面,默认情况下,消息不会被持久化。
查看如何使用 Redis 和 Python 来了解更多信息。
Apache Kaka:kafka-python3
到目前为止,Kafka 是你在本教程中遇到的三个消息代理中最高级、最复杂的一个。这是一个用于实时事件驱动应用的分布式流媒体平台。它的主要卖点是处理大量数据而几乎没有性能延迟的能力。
要运行 Kafka,您需要设置一个分布式集群。您可以使用 Docker Compose 一次性启动一个多容器 Docker 应用程序。比如可以抢比特纳米打包的阿帕奇卡夫卡:
# docker-compose.yml version: "3" services: zookeeper: image: 'bitnami/zookeeper:latest' ports: - '2181:2181' environment: - ALLOW_ANONYMOUS_LOGIN=yes kafka: image: 'bitnami/kafka:latest' ports: - '9092:9092' environment: - KAFKA_BROKER_ID=1 - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 - ALLOW_PLAINTEXT_LISTENER=yes depends_on: - zookeeper
当您将此配置保存在名为docker-compose.yml的文件中时,您可以通过运行以下命令来启动这两个服务:
$ docker-compose up
有时,当 Kafka 版本与您的客户端库版本不匹配时,您可能会遇到问题。似乎支持最近的 Kafka 的 Python 库是 kafka-python3 ,模仿 Java 客户端。
您的制作人可以就给定主题发送消息,如下所示:
# producer.py
from kafka3 import KafkaProducer
producer = KafkaProducer(bootstrap_servers="localhost:9092")
while True:
message = input("Message: ")
producer.send(
topic="datascience",
value=message.encode("utf-8"),
)
.send()方法是异步的,因为它返回一个未来对象,你可以通过调用它的阻塞.get()方法来等待它。在消费者端,您将能够通过迭代消费者来读取发送的消息:
# consumer.py
from kafka3 import KafkaConsumer
consumer = KafkaConsumer("datascience")
for record in consumer:
message = record.value.decode("utf-8")
print(f"Got message: {message}")
消费者的构造函数接受一个或多个它可能感兴趣的主题。
自然,对于这些强大的消息代理,您仅仅触及了皮毛。您在这一部分的目标是获得一个快速概览和一个起点,以防您想自己探索它们。
结论
现在,您已经对计算机科学中的队列理论有了很好的理解,并且知道了它们的 T2 实际应用,从寻找图中的最短路径到同步并发工作者和分离分布式系统。你能够认识到队列可以优雅地解决的问题。
你可以在 Python 中使用不同的数据结构从头开始实现 FIFO 、 LIFO 和优先级队列,理解它们的权衡。同时,您知道构建到标准库中的每个队列,包括线程安全队列、异步队列和一个用于基于进程的并行的队列。您还知道这些库允许 Python 与云中流行的消息代理队列集成。
在本教程中,您学习了如何:
- 区分各种类型的队列
- 在 Python 中实现队列数据类型
- 通过应用正确的队列解决实际问题
- 使用 Python 的线程安全、异步和进程间队列
- 通过库将 Python 与分布式消息队列代理集成在一起
一路走来,你已经实现了广度优先搜索 (BFS) 、深度优先搜索 (DFS) 和 Dijkstra 的最短路径算法。您已经构建了一个多生产者、多消费者问题的可视化模拟,一个异步的网络爬虫和一个并行的 MD5 散列反转程序。要获得这些实践示例的源代码,请访问以下链接:
获取源代码: 单击此处获取源代码和示例数据,您将使用它们来探索 Python 中的队列。**********


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}