







原文:RealPython
python“for”循环(明确迭代)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: For Loops in Python(定迭代)
本教程将向你展示如何用 Python for循环执行确定迭代。
在本介绍性系列的之前的教程中,您学习了以下内容:
- 同一代码块的反复执行被称为迭代。
- 迭代有两种类型:
- 确定的迭代,其中预先明确指定重复的次数
- 不定迭代,其中代码块执行直到满足某个条件
- 在 Python 中,无限迭代是通过一个
while循环来执行的。
以下是你将在本教程中涉及的内容:
-
您将从编程语言用来实现明确迭代的一些不同范例的比较开始。
-
然后你将学习 iterables 和 iterators ,这两个概念构成了 Python 中确定迭代的基础。
-
最后,您将把它们联系在一起,并了解 Python 的
for循环。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
程序设计中的有限迭代综述
明确迭代循环经常被称为 for 循环,因为for是用于在几乎所有编程语言中引入它们的关键字,包括 Python。
历史上,编程语言提供了几种不同风格的for循环。这些将在下面的章节中简要介绍。
数字范围循环
最基本的for循环是一个带有起始值和结束值的简单数值范围语句。确切的格式因语言而异,但通常如下所示:
for i = 1 to 10
<loop body>
这里,循环体执行了十次。变量 i在第一次迭代时取值1,在第二次迭代时取值2,依此类推。这种for循环在 BASIC、Algol 和 Pascal 语言中使用。
三表达式循环
由 C 编程语言推广的另一种形式的for循环包含三个部分:
- 初始化
- 指定结束条件的表达式
- 每次迭代结束时要执行的操作。
这种类型的循环具有以下形式:
for (i = 1; i <= 10; i++) <loop body>
**技术说明:**在 C 编程语言中,i++递增变量i。它大致相当于 Python 中的i += 1。
该循环解释如下:
- 将
i初始化为1。 - 只要
i <= 10继续循环。 - 每次循环迭代后,将
i增加1。
三表达式for循环很受欢迎,因为为这三部分指定的表达式几乎可以是任何东西,所以这比上面显示的更简单的数值范围形式有更多的灵活性。这些for循环在 C++ 、 Java 、PHP 和 Perl 语言中也很常见。
基于集合或基于迭代器的循环
这种类型的循环迭代对象集合,而不是指定数值或条件:
for i in <collection>
<loop body>
每次循环时,变量i取<collection>中下一个对象的值。这种类型的for循环可以说是最一般化和最抽象的。Perl 和 PHP 也支持这种类型的循环,但是它是由关键字foreach而不是for引入的。
**延伸阅读:**查看 For 循环 Wikipedia 页面,深入了解跨编程语言的明确迭代的实现。
Python for循环
在上面列出的循环类型中,Python 只实现了最后一种:基于集合的迭代。乍一看,这似乎是一个不公平的交易,但是请放心,Python 对确定迭代的实现是如此通用,以至于您最终不会感到被欺骗!
很快,您将详细探究 Python 的for循环。但是现在,让我们从一个快速原型和例子开始,只是为了熟悉一下。
Python 的for循环是这样的:
for <var> in <iterable>:
<statement(s)>
<iterable>是对象的集合,例如,列表或元组。与所有 Python 控制结构一样,循环体中的<statement(s)>用缩进表示,并且对<iterable>中的每一项执行一次。每次循环时,循环变量<var>取<iterable>中下一个元素的值。
这里有一个代表性的例子:
>>> a = ['foo', 'bar', 'baz']
>>> for i in a:
... print(i)
...
foo
bar
baz
在这个例子中,<iterable>是列表a,而<var>是变量i。每次通过循环,i在a中承担一个连续的项目,因此 print() 分别显示值'foo'、'bar'和'baz'。像这样的for循环是处理 iterable 中项目的 Pythonic 方式。
但是什么是可迭代的呢?在进一步检查for循环之前,更深入地研究 Python 中的可迭代对象是有益的。
可重复项
在 Python 中, iterable 意味着一个对象可以在迭代中使用。该术语用作:
- 形容词:一个物体可以被描述为可重复的。
- 名词:一个对象可以被描述为可重复的。
如果一个对象是可迭代的,它可以被传递给内置的 Python 函数iter(),后者返回一个叫做迭代器的东西。是的,术语有点重复。坚持住。最后一切都解决了。
下例中的每个对象都是可迭代的,当传递给iter()时,返回某种类型的迭代器:
>>> iter('foobar') # String
<str_iterator object at 0x036E2750>
>>> iter(['foo', 'bar', 'baz']) # List
<list_iterator object at 0x036E27D0>
>>> iter(('foo', 'bar', 'baz')) # Tuple
<tuple_iterator object at 0x036E27F0>
>>> iter({'foo', 'bar', 'baz'}) # Set
<set_iterator object at 0x036DEA08>
>>> iter({'foo': 1, 'bar': 2, 'baz': 3}) # Dict
<dict_keyiterator object at 0x036DD990>
另一方面,这些对象类型是不可迭代的:
>>> iter(42) # Integer
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
iter(42)
TypeError: 'int' object is not iterable
>>> iter(3.1) # Float
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
iter(3.1)
TypeError: 'float' object is not iterable
>>> iter(len) # Built-in function
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
iter(len)
TypeError: 'builtin_function_or_method' object is not iterable
到目前为止,您遇到的所有集合或容器类型的数据类型都是可迭代的。其中包括字符串,列表,元组,字典,集合,以及 frozenset 类型。
但是这些绝不是唯一可以迭代的类型。Python 中内置的或模块中定义的许多对象都被设计成可迭代的。例如,Python 中的打开文件是可迭代的。正如您将在关于文件 I/O 的教程中看到的,迭代一个打开的文件对象会从文件中读取数据。
事实上,Python 中的几乎任何对象都可以变成可迭代的。即使是用户定义的对象,也可以通过迭代的方式进行设计。(在下一篇关于面向对象编程的文章中,您会发现这是如何做到的。)
迭代器
好了,现在你知道了一个对象是可迭代的意味着什么,你也知道了如何使用iter()从它那里获得一个迭代器。一旦你有了一个迭代器,你能用它做什么?
迭代器本质上是一个值生成器,它从相关的可迭代对象中产生连续的值。内置函数next()用于从迭代器中获取下一个值。
下面是一个使用上述相同列表的示例:
>>> a = ['foo', 'bar', 'baz']
>>> itr = iter(a)
>>> itr
<list_iterator object at 0x031EFD10>
>>> next(itr)
'foo'
>>> next(itr)
'bar'
>>> next(itr)
'baz'
在这个例子中,a是一个可迭代列表,itr是相关的迭代器,通过iter()获得。每个next(itr)调用从itr获得下一个值。
注意迭代器是如何在内部保持状态的。它知道已经获得了哪些值,所以当您调用next()时,它知道接下来要返回什么值。
当迭代器用完值时会发生什么?让我们对上面的迭代器再进行一次next()调用:
>>> next(itr)
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
next(itr)
StopIteration
如果迭代器中的所有值都已经返回,那么后续的next()调用将引发一个StopIteration异常。从迭代器获取值的任何进一步尝试都将失败。
只能从一个方向的迭代器中获取值。你不能倒退。没有prev()功能。但是您可以在同一个 iterable 对象上定义两个独立的迭代器:
>>> a
['foo', 'bar', 'baz']
>>> itr1 = iter(a)
>>> itr2 = iter(a)
>>> next(itr1) 'foo'
>>> next(itr1)
'bar'
>>> next(itr1)
'baz'
>>> next(itr2) 'foo'
即使迭代器itr1已经在列表的末尾,itr2仍然在列表的开头。每个迭代器维护自己的内部状态,相互独立。
如果想一次从迭代器中获取所有值,可以使用内置的list()函数。在其他可能的用法中,list()将迭代器作为它的参数,并返回一个由迭代器产生的所有值组成的列表:
>>> a = ['foo', 'bar', 'baz']
>>> itr = iter(a)
>>> list(itr)
['foo', 'bar', 'baz']
类似地,内置的tuple()和set()函数分别从迭代器产生的所有值中返回一个元组和一个集合:
>>> a = ['foo', 'bar', 'baz']
>>> itr = iter(a)
>>> tuple(itr)
('foo', 'bar', 'baz')
>>> itr = iter(a)
>>> set(itr)
{'baz', 'foo', 'bar'}
不建议你养成这种习惯。迭代器的优雅之处在于它们“懒惰”这意味着当你创建一个迭代器的时候,它不会生成所有它当时能产生的项。它会一直等待,直到你用next()请求它们。项目直到被请求时才会被创建。
当您使用list()、tuple()等时,您是在强迫迭代器一次生成它的所有值,所以它们都可以被返回。如果迭代器返回的对象总数非常大,这可能需要很长时间。
事实上,可以使用生成器函数和 itertools 在 Python 中创建一个迭代器,返回一系列无穷无尽的对象。如果你试图从一个无限的迭代器中一次获取所有的值,程序将挂起。
Python 的内部for循环
现在已经向您介绍了完全理解 Python 的for循环如何工作所需的所有概念。继续之前,让我们回顾一下相关术语:
| 学期 | 意义 |
|---|---|
| 迭代 | 遍历集合中的对象或项目的过程 |
| 可迭代 | 可以被重复的物体(或用来描述物体的形容词) |
| 迭代器 | 从关联的 iterable 中产生连续项或值的对象 |
T2iter() | 用于从 iterable 中获取迭代器的内置函数 |
现在,再次考虑本教程开始时出现的简单的for循环:
>>> a = ['foo', 'bar', 'baz']
>>> for i in a:
... print(i)
...
foo
bar
baz
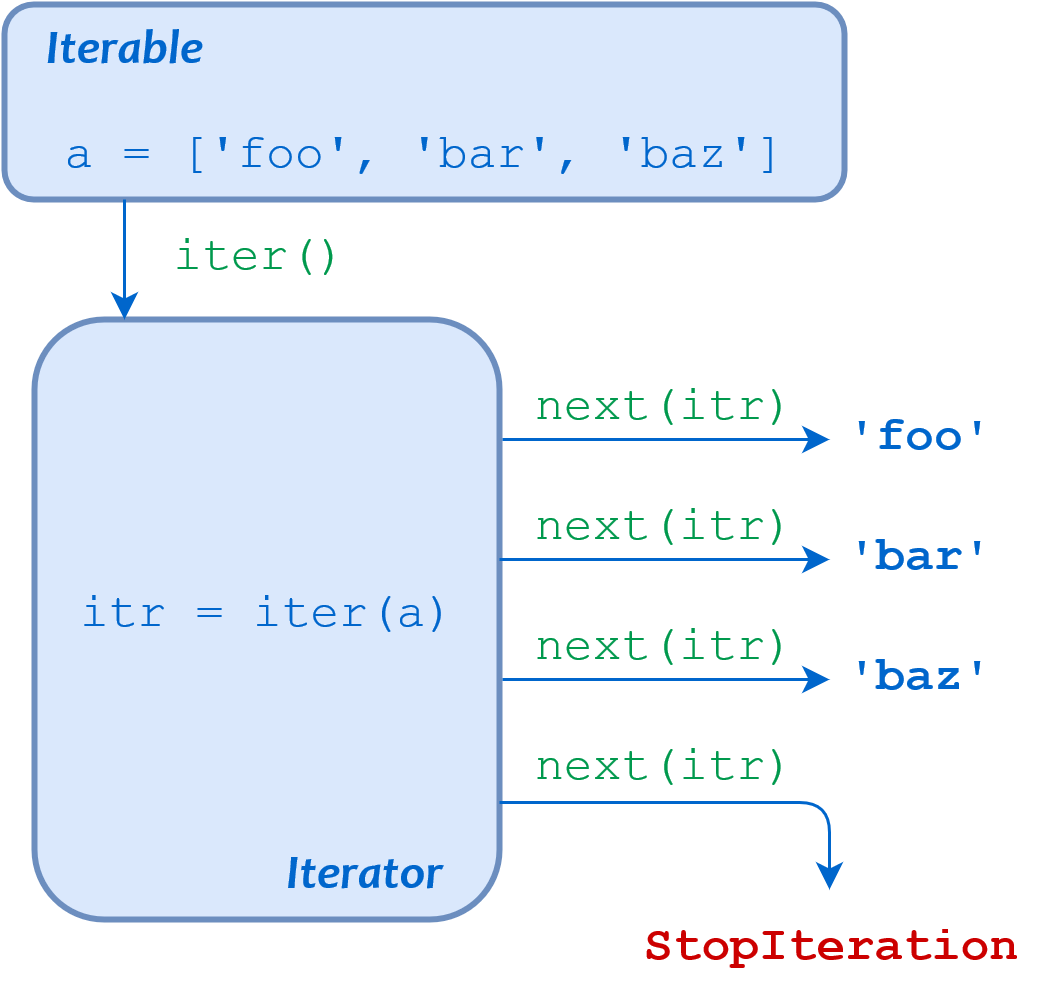
这个循环可以完全用你刚刚学到的概念来描述。为了执行这个for循环描述的迭代,Python 执行以下操作:
- 调用
iter()来获得a的迭代器 - 反复调用
next()从迭代器中依次获取每一项 - 当
next()引发StopIteration异常时终止循环
对于每一项next()返回,循环体被执行一次,循环变量i被设置为每次迭代的给定项。
下图总结了这一系列事件:
也许这看起来像是许多不必要的恶作剧,但好处是巨大的。Python 完全以这种方式处理所有可迭代对象的循环,在 Python 中,可迭代对象和迭代器比比皆是:
-
许多内置对象和库对象是可迭代的。
-
有一个名为
itertools的标准库模块,包含许多返回 iterables 的函数。 -
使用 Python 的面向对象功能创建的用户定义对象可以是可迭代的。
-
Python 有一个称为生成器的构造,它允许您以简单、直接的方式创建自己的迭代器。
在这一系列文章中,您将会发现更多关于上述内容的信息。它们都可以是一个for循环的目标,并且语法都是相同的。它简洁优雅,功能多样。
遍历字典
您之前看到迭代器可以从带有iter()的字典中获得,所以您知道字典必须是可迭代的。当你在字典中循环时会发生什么?让我们看看:
>>> d = {'foo': 1, 'bar': 2, 'baz': 3}
>>> for k in d:
... print(k)
...
foo
bar
baz
如您所见,当一个for循环遍历一个字典时,循环变量被分配给字典的键。
要访问循环中的字典值,您可以像往常一样使用键进行字典引用:
>>> for k in d:
... print(d[k])
...
1
2
3
您还可以使用.values()直接遍历字典的值:
>>> for v in d.values():
... print(v)
...
1
2
3
事实上,您可以同时遍历字典的键和值。这是因为for循环的循环变量不仅限于单个变量。它也可以是元组,在这种情况下,使用打包和解包从 iterable 中的项进行赋值,就像赋值语句一样:
>>> i, j = (1, 2) >>> print(i, j)
1 2
>>> for i, j in [(1, 2), (3, 4), (5, 6)]: ... print(i, j)
...
1 2
3 4
5 6
正如在 Python 字典的教程中所提到的,字典方法.items()有效地返回了一列作为元组的键/值对:
>>> d = {'foo': 1, 'bar': 2, 'baz': 3}
>>> d.items()
dict_items([('foo', 1), ('bar', 2), ('baz', 3)])
因此,遍历字典访问键和值的 Pythonic 方法如下所示:
>>> d = {'foo': 1, 'bar': 2, 'baz': 3}
>>> for k, v in d.items():
... print('k =', k, ', v =', v)
...
k = foo , v = 1
k = bar , v = 2
k = baz , v = 3
range()功能
在本教程的第一部分中,您看到了一种称为数值范围循环的for循环,其中指定了起始和结束数值。虽然这种形式的for循环没有直接内置到 Python 中,但是很容易实现。
例如,如果您想迭代从0到4的值,您可以简单地这样做:
>>> for n in (0, 1, 2, 3, 4):
... print(n)
...
0
1
2
3
4
当只有几个数字时,这个解决方案还不错。但是如果数字范围大得多,它会很快变得乏味。
令人高兴的是,Python 提供了一个更好的选项——内置的range()函数,它返回一个产生整数序列的 iterable。
range(<end>)返回一个 iterable,该 iterable 产生从0开始的整数,直到但不包括<end>:
>>> x = range(5)
>>> x
range(0, 5)
>>> type(x)
<class 'range'>
请注意,range()返回的是一个类range的对象,而不是一个值的列表或元组。因为range对象是可迭代的,所以可以通过用for循环迭代它们来获得值:
>>> for n in x:
... print(n)
...
0
1
2
3
4
你也可以用list()或tuple()一次抓取所有的值。在 REPL 会话中,这是快速显示值的便捷方式:
>>> list(x)
[0, 1, 2, 3, 4]
>>> tuple(x)
(0, 1, 2, 3, 4)
然而,当range()被用在一个更大的应用程序的代码中时,以这种方式使用list()或tuple()通常被认为是不良的做法。像迭代器一样,range对象是懒惰的——指定范围内的值直到被请求时才会生成。在一个range对象上使用list()或tuple()强制所有的值一次返回。这很少是必要的,如果列表很长,会浪费时间和内存。
range(<begin>, <end>, <stride>)返回一个 iterable,该 iterable 产生从<begin>开始的整数,直到但不包括<end>。如果指定,<stride>表示值之间的跳跃量(类似于用于字符串和列表切片的跨距值):
>>> list(range(5, 20, 3))
[5, 8, 11, 14, 17]
如果省略<stride>,则默认为1:
>>> list(range(5, 10, 1))
[5, 6, 7, 8, 9]
>>> list(range(5, 10))
[5, 6, 7, 8, 9]
指定给range()的所有参数必须是整数,但其中任何一个都可以是负数。自然,如果<begin>大于<end>,<stride>一定是负数(如果你想要任何结果的话):
>>> list(range(-5, 5))
[-5, -4, -3, -2, -1, 0, 1, 2, 3, 4]
>>> list(range(5, -5))
[]
>>> list(range(5, -5, -1))
[5, 4, 3, 2, 1, 0, -1, -2, -3, -4]
**技术说明:**严格来说,range()并不完全是一个内置函数。它被实现为一个创建不可变序列类型的可调用类。但出于实用目的,它的行为就像一个内置函数。
更多关于range()的信息,请看真正的 Python 文章 Python 的range()函数(指南)。
改变for循环行为
在本介绍性系列的上一篇教程中,您已经看到了如何使用 break和continue语句中断while循环的执行,并使用 else子句对其进行修改。这些功能在for循环中也是可用的。
break和continue报表
break和continue与for回路的工作方式与while回路相同。break完全终止循环,并继续执行循环后的第一条语句:
>>> for i in ['foo', 'bar', 'baz', 'qux']:
... if 'b' in i:
... break ... print(i)
...
foo
continue终止当前迭代并进行下一次迭代:
>>> for i in ['foo', 'bar', 'baz', 'qux']:
... if 'b' in i:
... continue ... print(i)
...
foo
qux
else条款
一个for循环也可以有一个else子句。这种解释类似于一个while循环。如果循环因 iterable 用尽而终止,将执行else子句:
>>> for i in ['foo', 'bar', 'baz', 'qux']:
... print(i)
... else:
... print('Done.') # Will execute
...
foo
bar
baz
qux
Done.
如果列表被一个break语句分解,则else子句不会被执行:
>>> for i in ['foo', 'bar', 'baz', 'qux']:
... if i == 'bar':
... break ... print(i)
... else:
... print('Done.') # Will not execute
...
foo
结论
本教程介绍了for循环,它是 Python 中确定迭代的主力。
您还了解了 iterables 和 iterators 的内部工作原理,这两种重要的对象类型是定义迭代的基础,但在其他各种 Python 代码中也很重要。
在这个介绍性系列的下两个教程中,您将稍微改变一下思路,探索 Python 程序如何通过从键盘的输入和从控制台的输出与用户交互。
« Python “while” Loops (Indefinite Iteration)Python “for” Loops (Definite Iteration)Basic Input and Output in Python »
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: For Loops in Python(定迭代)******
面向社会科学家的 Python
Python 是社会科学家中越来越流行的数据分析工具。在许多已经成熟的库的支持下,R 和 Stata 用户越来越多地转向 Python,以便在不牺牲这些老程序多年来积累的功能的情况下利用 Python 的美丽、灵活和性能。
但是,尽管 Python 提供了很多东西,但现有的 Python 资源并不总是很适合社会科学家的需求。考虑到这一点,我最近创建了一个新资源——www.data-analysis-in-python.org(DAP)——专门为社会科学家 Python 用户的目标和愿望量身定制。
然而,这个网站并不是一套新的教程——世界上有比足够多的 Python 教程还要多的 T2 教程。更确切地说,该网站的目的是管理和注释现有资源,并为用户提供关注哪些主题和跳过哪些主题的指导。
为什么是社会科学家的网站?
社会科学家——事实上,大多数数据科学家——花费大部分时间试图将个体的、特殊的数据集整合成运行统计分析所需的形状。这使得大多数社会科学家使用 Python 的方式与大多数软件开发人员使用 Python 的方式有着根本的不同。
社会科学家主要对编写执行一系列命令(记录变量、合并数据集、解析文本文档等)的相对简单的程序(脚本)感兴趣。)将他们的数据整理成他们可以分析的形式。因为他们通常为特定的、特殊的应用程序和数据集编写脚本,他们通常不会专注于编写具有大量抽象的代码。
换句话说,社会科学家倾向于主要对学习如何有效地使用现有工具感兴趣,而不是开发新工具。
正因为如此,学习 Python 的社会科学家在技能发展方面比软件开发人员有着不同的优先权。然而,大多数在线教程是为开发人员或计算机科学学生编写的,所以 DAP 的目的之一是为社会科学家提供一些指导,让他们知道在早期培训中应该优先考虑的技能。特别是, DAP 建议:
立即需要:
- 数据类型:整数、浮点数、字符串、布尔值、列表、字典和集合(元组是可选的)
- 定义函数
- 写循环
- 理解可变和不可变数据类型
- 操作字符串的方法
- 导入第三方模块
- 阅读和解释错误
你在某个时候会想知道,但不是马上就要知道的事情:
- 高级调试工具(如 pdb
- 文件输入/输出(您将使用的大多数库都有工具来简化这一过程)
不需要:
- 定义或编写类
- 了解异常
熊猫
今天,大多数实证社会科学仍然围绕表格数据组织,这意味着数据在每一列中以不同的变量呈现,在每一行中以不同的观察值呈现。因此,当许多使用 Python 的社会科学家在 Python 入门教程中找不到表格数据结构时,他们会感到有些困惑。为了解决这一困惑,DAP 尽最大努力尽快向用户介绍熊猫图书馆,提供教程链接和一些关于注意陷阱的提示。
pandas 库复制了社会科学家习惯于在 Stata 或 R 中发现的许多功能——数据可以用表格格式表示,列变量可以很容易地标记,不同类型的列(如 floats 和 strings)可以组合在同一个数据集中。
熊猫也是社会科学家可能使用的许多其他工具的门户,如图形库( seaborn 和 ggplot2 )和 statsmodels 计量经济学库。
按研究领域分类的其他图书馆
虽然所有希望使用 Python 的社会科学家都需要理解核心语言,并且大多数人都希望熟悉pandas,但是 Python 生态系统充满了特定于应用程序的库,这些库只对一部分用户有用。考虑到这一点,DAP 提供了图书馆的概述,以帮助在不同主题领域工作的研究人员,以及最佳使用材料的链接,以及相关注意事项的指导:
- 网络分析 : iGraph
- 文本分析 : NLTK,如果需要的话还有 coreNLP
- 计量经济学:统计模型
- 绘图 : ggplot 和 seaborn
- 大数据 : dask 和 pyspark
- 地理空间分析 : arcpy 或 geopandas
- 让代码更快:iPython(用于评测)和 numba(用于 JIT 编译)
想参与进来吗?
这个网站是年轻的,所以我们渴望尽可能多的内容和设计的投入。如果你有这方面的经验,你想分享请给我发一封的电子邮件或者在 Github 上发一条的评论。
这是范德比尔特大学民主制度研究中心的博士后尼克·尤班克的客座博文*
较新的 Python 字符串格式技术指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 格式化 Python 字符串
在这个介绍性系列的之前的教程中,您已经初步了解了如何用 Python f-strings 格式化您的字符串。在本教程的末尾,您会学到更多关于这种技术的知识。
由于 f-string 对于 Python 语言来说相对较新,所以熟悉第二种稍微老一点的技术也是有好处的。您可能会在较旧的 Python 代码中遇到它。
在本教程中,您将了解到:
- 弦
.format()法 - 格式的字符串文字,或者 f-string
您将详细了解这些格式化技术,并将它们添加到 Python 字符串格式化工具包中。
**注意:**有一个名为string的标准模块,包含一个名为 Template 的类,它也通过插值提供一些字符串格式。一种相关的技术,字符串模操作符,提供了或多或少相同的功能。在本教程中,您不会涉及这些技术中的任何一种,但是如果您必须使用 Python 2 编写的代码,您会希望阅读一下字符串模操作符。
您可能会注意到,在 Python 中有许多不同的方法来格式化字符串,这违背了 Python 自己的一条原则:
应该有一种——最好只有一种——显而易见的方法来做这件事。—蒂姆·彼得斯,Python 的禅宗
在 Python 存在和发展的这些年里,不同的字符串格式化技术得到了历史性的发展。旧的技术被保留下来以确保向后兼容性,有些甚至有特定的用例。
如果你刚开始使用 Python,并且正在寻找一种格式化字符串的单一方法,那么请坚持使用 Python 3 的 f 字符串。如果您遇到了看起来很奇怪的字符串格式代码并想了解更多,或者您需要使用旧版本的 Python,那么学习其他技术也是一个好主意。
Python 字符串.format()方法
Python string .format()方法是在 2.6 版本中引入的。它在很多方面都类似于字符串模操作符,但是.format()在通用性方面远远超过它。Python .format()调用的一般形式如下所示:
<template>.format(<positional_argument(s)>, <keyword_argument(s)>)
请注意,这是一个方法,而不是一个运算符。您调用<template>上的方法,这是一个包含替换字段的字符串。该方法的<positional_arguments>和<keyword_arguments>指定插入到<template>中代替替换字段的值。得到的格式化字符串是该方法的返回值。
在<template>字符串中,替换字段用花括号({})括起来。花括号中没有包含的内容是直接从模板复制到输出中的文本。如果您需要在模板字符串中包含一个文字花括号字符,如{或},那么您可以通过将它加倍来转义该字符:
>>> '{{ {0} }}'.format('foo')
'{ foo }'
现在输出中包含了花括号。
字符串.format()方法:参数
在深入了解如何在 Python 中使用这个方法格式化字符串的更多细节之前,让我们从一个简单的例子开始。回顾一下,这里是上一篇教程中关于字符串模操作符的第一个例子:
>>> print('%d %s cost $%.2f' % (6, 'bananas', 1.74))
6 bananas cost $1.74
这里,您使用 Python 中的字符串模操作符来格式化字符串。现在,您可以使用 Python 的 string .format()方法来获得相同的结果,如下所示:
>>> print('{0} {1} cost ${2}'.format(6, 'bananas', 1.74))
6 bananas cost $1.74
在本例中,<template>是字符串'{0} {1} cost ${2}'。替换字段是{0}、{1}和{2},它们包含与从零开始的位置参数6、'bananas'和1.74相对应的数字。每个位置参数都被插入到模板中,代替其对应的替换字段:
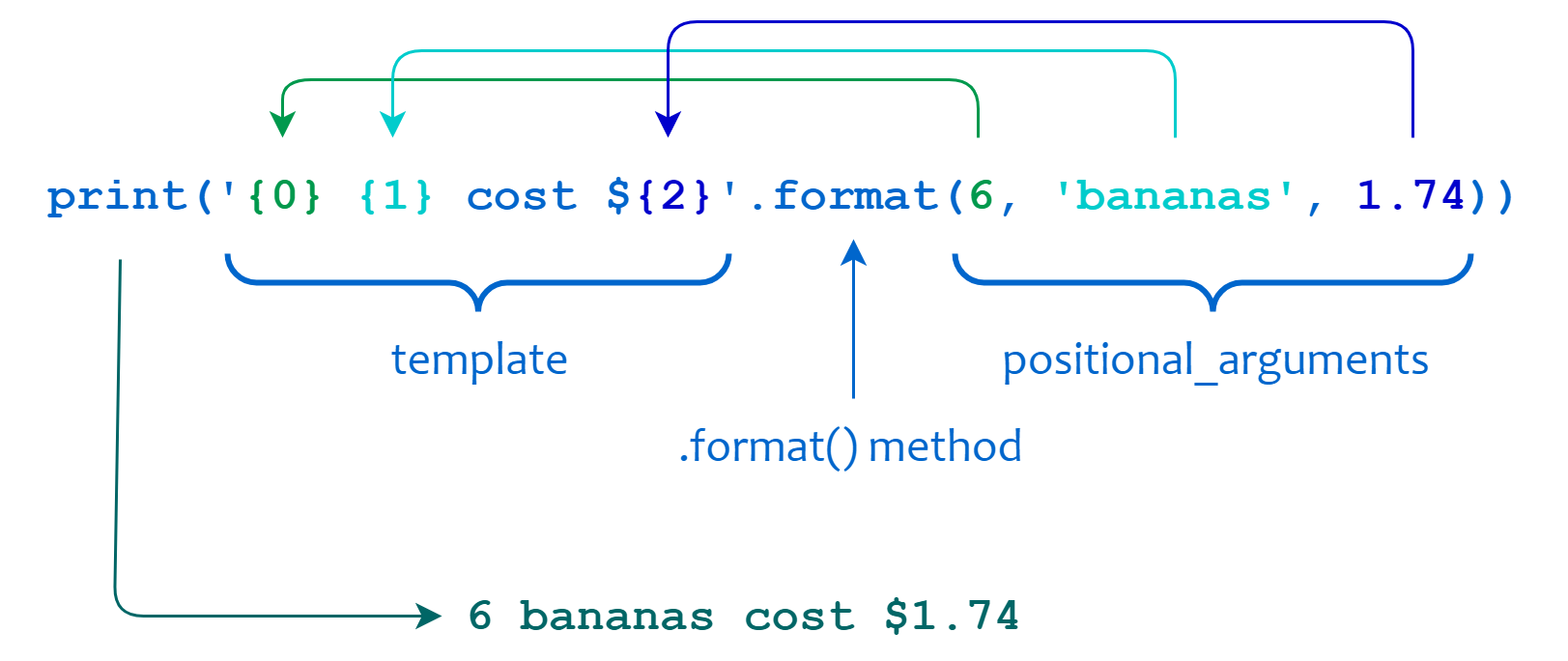
下一个例子使用关键字参数而不是位置参数来产生相同的结果:
>>> print('{quantity} {item} cost ${price}'.format(
... quantity=6,
... item='bananas',
... price=1.74))
6 bananas cost $1.74
在这种情况下,替换字段是{quantity}、{item}和{price}。这些字段指定对应于关键字参数quantity=6、item='bananas'和price=1.74的关键字。每个关键字值都被插入到模板中,代替其对应的替换字段:

在这个介绍性系列的下一篇教程中,您将了解到更多关于位置和关键字参数的知识,该教程将探索函数和参数传递。现在,接下来的两节将向您展示如何在 Python .format()方法中使用它们。
位置参数
位置参数被插入到模板中,代替编号的替换字段。像列表索引一样,替换字段的编号是从零开始的。第一个位置参数编号为0,第二个编号为1,依此类推:
>>> '{0}/{1}/{2}'.format('foo', 'bar', 'baz')
'foo/bar/baz'
请注意,替换字段不必按数字顺序出现在模板中。它们可以按任何顺序指定,并且可以出现多次:
>>> '{2}.{1}.{0}/{0}{0}.{1}{1}.{2}{2}'.format('foo', 'bar', 'baz')
'baz.bar.foo/foofoo.barbar.bazbaz'
当你指定一个超出范围的替换字段号时,你会得到一个错误。在下面的例子中,位置参数被编号为0、1和2,但是您在模板中指定了{3}:
>>> '{3}'.format('foo', 'bar', 'baz')
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
'{3}'.format('foo', 'bar', 'baz')
IndexError: tuple index out of range
这引发了一个IndexError 异常。
从 Python 3.1 开始,您可以省略替换字段中的数字,在这种情况下,解释器会假定顺序。这被称为自动字段编号:
>>> '{}/{}/{}'.format('foo', 'bar', 'baz')
'foo/bar/baz'
指定自动字段编号时,必须提供至少与替换字段一样多的参数:
>>> '{}{}{}{}'.format('foo','bar','baz')
Traceback (most recent call last):
File "<pyshell#27>", line 1, in <module>
'{}{}{}{}'.format('foo','bar','baz')
IndexError: tuple index out of range
在这种情况下,模板中有四个替换字段,但只有三个参数,所以出现了一个IndexError异常。另一方面,如果参数比替换字段多也没关系。多余的参数根本不用:
>>> '{}{}'.format('foo', 'bar', 'baz')
'foobar'
这里,参数'baz'被忽略。
请注意,您不能混合使用这两种技术:
>>> '{1}{}{0}'.format('foo','bar','baz')
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
'{1}{}{0}'.format('foo','bar','baz')
ValueError: cannot switch from manual field specification to automatic field
numbering
当使用 Python 格式化带有位置参数的字符串时,必须在自动或显式替换字段编号之间进行选择。
关键字参数
关键字参数被插入到模板字符串中,代替具有相同名称的关键字替换字段:
>>> '{x}/{y}/{z}'.format(x='foo', y='bar', z='baz')
'foo/bar/baz'
在这个例子中,关键字参数x、y和z的值分别代替替换字段{x}、{y}和{z}。
如果您引用了一个丢失的关键字参数,那么您将看到一个错误:
>>> '{x}/{y}/{w}'.format(x='foo', y='bar', z='baz')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'w'
这里,您指定了替换字段{w},但是没有相应的名为w的关键字参数。巨蟒召唤出 KeyError异常。
虽然必须按顺序指定位置参数,但是可以按任意顺序指定关键字参数:
>>> '{0}/{1}/{2}'.format('foo', 'bar', 'baz')
'foo/bar/baz'
>>> '{0}/{1}/{2}'.format('bar', 'baz', 'foo')
'bar/baz/foo'
>>> '{x}/{y}/{z}'.format(x='foo', y='bar', z='baz')
'foo/bar/baz'
>>> '{x}/{y}/{z}'.format(y='bar', z='baz', x='foo')
'foo/bar/baz'
您可以在一个 Python .format()调用中同时指定位置参数和关键字参数。请注意,如果您这样做,那么所有的位置参数必须出现在任何关键字参数之前:
>>> '{0}{x}{1}'.format('foo', 'bar', x='baz')
'foobazbar'
>>> '{0}{x}{1}'.format('foo', x='baz', 'bar')
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument
事实上,所有位置参数出现在任何关键字参数之前的要求并不仅仅适用于 Python 格式的方法。这通常适用于任何函数或方法调用。在本系列的下一篇教程中,您将了解到更多关于函数和函数调用的内容。
在迄今为止的所有示例中,传递给 Python .format()方法的值都是文字值,但是您也可以指定变量:
>>> x = 'foo'
>>> y = 'bar'
>>> z = 'baz'
>>> '{0}/{1}/{s}'.format(x, y, s=z)
'foo/bar/baz'
在这种情况下,将变量x和y作为位置参数值传递,将z作为关键字参数值传递。
字符串.format()方法:简单替换字段
如您所见,当您调用 Python 的.format()方法时,<template>字符串包含了替换字段。它们指示在模板中的什么位置插入方法的参数。替换字段由三部分组成:
{[<name>][!<conversion>][:<format_spec>]}
这些组件解释如下:
| 成分 | 意义 |
|---|---|
<name> | 指定要格式化的值的来源 |
<conversion> | 指示使用哪个标准 Python 函数来执行转换 |
<format_spec> | 指定了有关如何转换值的更多详细信息 |
每个组件都是可选的,可以省略。让我们更深入地看看每个组件。
<name>组件
<name>组件是替换字段的第一部分:
{**[<name>]**T2】
<name>表示将参数列表中的哪个参数插入到 Python 格式字符串的给定位置。它要么是位置参数的数字,要么是关键字参数的关键字。在下面的例子中,替换字段的<name>组件分别是0、1和baz:
>>> x, y, z = 1, 2, 3
>>> '{0}, {1}, {baz}'.format(x, y, baz=z)
'1, 2, 3'
如果一个参数是一个列表,那么您可以使用带有<name>的索引来访问列表的元素:
>>> a = ['foo', 'bar', 'baz']
>>> '{0[0]}, {0[2]}'.format(a)
'foo, baz'
>>> '{my_list[0]}, {my_list[2]}'.format(my_list=a)
'foo, baz'
类似地,如果相应的参数是一个字典,那么您可以使用带有<name>的键引用:
>>> d = {'key1': 'foo', 'key2': 'bar'}
>>> d['key1']
'foo'
>>> '{0[key1]}'.format(d)
'foo'
>>> d['key2']
'bar'
>>> '{my_dict[key2]}'.format(my_dict=d)
'bar'
您也可以从替换字段中引用对象属性。在本系列的之前的教程中,您了解到 Python 中的几乎每一项数据都是一个对象。对象可能有分配给它们的属性,这些属性使用点符号来访问:
obj.attr
这里,obj是一个属性名为attr的对象。使用点符号来访问对象的属性。让我们看一个例子。Python 中的复数具有名为.real和.imag的属性,分别代表数字的实部和虚部。您也可以使用点符号来访问它们:
>>> z = 3+5j
>>> type(z)
<class 'complex'>
>>> z.real
3.0
>>> z.imag
5.0
本系列中有几个即将推出的关于面向对象编程的教程,在这些教程中,您将学到更多关于像这样的对象属性的知识。
在这种情况下,对象属性的相关性在于您可以在 Python .format()替换字段中指定它们:
>>> z
(3+5j)
>>> 'real = {0.real}, imag = {0.imag}'.format(z)
'real = 3.0, imag = 5.0'
如您所见,在 Python 中使用.format()方法格式化复杂对象的组件相对简单。
<conversion>组件
<conversion>组件是替换字段的中间部分:
{[<name>]**[!<conversion>]**T2】
Python 可以使用三种不同的内置函数将对象格式化为字符串:
str()repr()ascii()
默认情况下,Python .format()方法使用str(),但是在某些情况下,您可能想要强制.format()使用另外两个中的一个。您可以使用替换字段的<conversion>组件来实现这一点。<conversion>的可能值如下表所示:
| 价值 | 意义 |
|---|---|
!s | 用str()转换 |
!r | 用repr()转换 |
!a | 用ascii()转换 |
以下示例分别使用str()、repr()和ascii()强制 Python 执行字符串转换:
>>> '{0!s}'.format(42)
'42'
>>> '{0!r}'.format(42)
'42'
>>> '{0!a}'.format(42)
'42'
在许多情况下,无论您使用哪种转换函数,结果都是一样的,正如您在上面的示例中所看到的。也就是说,您不会经常需要<conversion>组件,所以您不会在这里花费太多时间。但是,在有些情况下会有所不同,所以最好意识到,如果需要,您可以强制使用特定的转换函数。
<format_spec>组件
<format_spec>组件是替换字段的最后一部分:
{[<name>][!<conversion>]**[:<format_spec>]**T2】
<format_spec>代表 Python .format()方法功能的核心。它包含在将值插入模板字符串之前对如何格式化值进行精细控制的信息。一般形式是这样的:
:
[[<fill>]<align>][<sign>][#][0][<width>][<group>][.<prec>][<type>]
<format_spec>的十个子组件按所示顺序指定。它们控制格式,如下表所述:
| 亚成分 | 影响 |
|---|---|
: | 将<format_spec>与替换字段的其余部分分开 |
<fill> | 指定如何填充未占据整个字段宽度的值 |
<align> | 指定如何对齐未占据整个字段宽度的值 |
<sign> | 控制数值中是否包含前导符号 |
# | 为某些演示类型选择替代输出形式 |
0 | 使值在左边用零而不是 ASCII 空格字符填充 |
<width> | 指定输出的最小宽度 |
<group> | 指定了数字输出的分组字符 |
.<prec> | 指定浮点表示类型小数点后的位数,以及字符串表示类型的最大输出宽度 |
<type> | 指定表示类型,这是对相应参数执行的转换类型 |
这些函数类似于字符串模操作符转换说明符中的组件,但是功能更强大。在接下来的几节中,您将看到对它们的功能更全面的解释。
<type> 子组件
先说 <type> ,这是<format_spec>的最后一部分。<type>子组件指定表示类型,表示类型是对相应值执行的转换类型,以产生输出。可能的值如下所示:
| 价值 | 演示类型 |
|---|---|
b | 二进制整数 |
c | 单字符 |
d | 十进制整数 |
e或E | 指数的 |
f或F | 浮点 |
g或G | 浮点或指数 |
o | 八进制整数 |
s | 线 |
x或X | 十六进制整数 |
% | 百分率 |
这些就像与字符串模运算符一起使用的转换类型,在许多情况下,它们的功能是相同的。以下示例展示了相似性:
>>> '%d' % 42
'42'
>>> '{:d}'.format(42)
'42'
>>> '%f' % 2.1
'2.100000'
>>> '{:f}'.format(2.1)
'2.100000'
>>> '%s' % 'foobar'
'foobar'
>>> '{:s}'.format('foobar')
'foobar'
>>> '%x' % 31
'1f'
>>> '{:x}'.format(31)
'1f'
然而,在一些 Python .format()表示类型和字符串模操作符转换类型之间有一些细微的差别:
| 类型 | .format()方法 | 字符串模运算符 |
|---|---|---|
| b | 指定二进制整数转换 | 不支持 |
| i,u | 不支持 | 指定整数转换 |
| c | 指定字符转换,相应的值必须是整数 | 指定字符转换,但相应的值可以是整数或单个字符串 |
| g,G | 在浮点或指数输出之间选择,但是控制选择的规则稍微复杂一些 | 根据指数的大小和为<prec>指定的值,选择浮点或指数输出 |
| r,a | 不支持(尽管该功能由替换字段中的!r和!a转换组件提供) | 分别用repr()或ascii()指定转换 |
| % | 将数值参数转换为百分比 | 在输出中插入一个文字字符'%' |
接下来,您将看到几个说明这些差异的例子,以及 Python .format()方法表示类型的一些附加特性。您将看到的第一个演示类型是b,它指定了二进制整数转换:
>>> '{:b}'.format(257)
'100000001'
模运算符根本不支持二进制转换类型:
>>> '%b' % 257
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: unsupported format character 'b' (0x62) at index 1
然而,模操作符允许十进制整数转换为d、i和u类型。只有d表示类型使用 Python .format()方法表示十进制整数转换。不支持i和u演示类型,也没有必要。
接下来是单字转换。模运算符允许整数或单个字符值使用c转换类型:
>>> '%c' % 35
'#'
>>> '%c' % '#'
'#'
另一方面,Python 的.format()方法要求对应于c表示类型的值是一个整数:
>>> '{:c}'.format(35)
'#'
>>> '{:c}'.format('#')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Unknown format code 'c' for object of type 'str'
当你试图传递一个不同类型的值时,你会得到一个ValueError。
对于字符串模运算符和 Python 的.format()方法, g转换类型根据指数的大小和为<prec>指定的值选择浮点或指数输出:
>>> '{:g}'.format(3.14159)
'3.14159'
>>> '{:g}'.format(-123456789.8765)
'-1.23457e+08'
管理选择的精确规则在.format()中比在模运算符中稍微复杂一些。一般来说,你可以相信这个选择是有意义的。
G 与g相同,除了当输出是指数时,在这种情况下'E'将是大写的:
>>> '{:G}'.format(-123456789.8765)
'-1.23457E+08'
结果与前面的例子相同,但是这次使用了大写的'E'。
**注意:**在其他一些情况下,你会发现g和G演示类型的不同。
在某些情况下,浮点运算可以产生一个基本上是无限的值。这样的数字在 Python 中的字符串表示是 'inf' 。浮点运算也可能产生无法用数字表示的值。Python 用字符串'NaN'来表示这一点,它代表而不是数字**。*
*当您将这些值传递给 Python 的.format()方法时,g表示类型产生小写输出,G产生大写输出:
>>> x = 1e300 * 1e300
>>> x
inf
>>> '{:g}'.format(x)
'inf'
>>> '{:g}'.format(x * 0)
'nan'
>>> '{:G}'.format(x)
'INF'
>>> '{:G}'.format(x * 0)
'NAN'
您还会看到f和F演示类型的类似行为:
>>> '{:f}'.format(x)
'inf'
>>> '{:F}'.format(x)
'INF'
>>> '{:f}'.format(x * 0)
'nan'
>>> '{:F}'.format(x * 0)
'NAN'
有关浮点表示、inf和NaN的更多信息,请查看维基百科关于 IEEE 754-1985 的页面。** **模运算符支持 r和a转换类型,分别通过repr()和ascii()强制转换。Python 的.format()方法不支持r和a表示类型,但是您可以使用替换字段中的!r和!a转换组件完成同样的事情。
最后,您可以使用带有模运算符的 %转换类型将文字'%'字符插入到输出中:
>>> '%f%%' % 65.0
'65.000000%'
在 Python .format()方法的输出中插入文字'%'字符并不需要任何特殊的东西,因此%表示类型为百分比输出提供了不同的方便用途。它将指定值乘以 100,并附加一个百分号:
>>> '{:%}'.format(0.65)
'65.000000%'
<format_spec>的其余部分指示如何格式化所选的表示类型,与字符串模操作符的宽度和精度说明符和转换标志非常相似。这些将在以下章节中进行更全面的描述。
<fill> 和 <align> 子组件
<fill>和<align>控制如何在指定的字段宽度内填充和定位格式化的输出。这些子组件只有在格式化字段值没有占据整个字段宽度时才有意义,这种情况只有在用<width>指定最小字段宽度时才会发生。如果没有指定<width>,那么<fill>和<align>将被忽略。在本教程的后面部分,您将会谈到<width>。
以下是<align>子组件的可能值:
<>^=
使用小于号(<)的值表示输出是左对齐的:
>>> '{0:<8s}'.format('foo')
'foo '
>>> '{0:<8d}'.format(123)
'123 '
这是字符串值的默认行为。
使用大于号(>)的值表示输出应该右对齐:
>>> '{0:>8s}'.format('foo')
' foo'
>>> '{0:>8d}'.format(123)
' 123'
这是数值的默认行为。
使用插入符号(^)的值表示输出应该在输出字段中居中:
>>> '{0:^8s}'.format('foo')
' foo '
>>> '{0:^8d}'.format(123)
' 123 '
最后,您还可以使用等号(=)为<align>子组件指定一个值。这只对数值有意义,并且只在输出中包含符号时才有意义。
当数字输出包含符号时,它通常直接放在数字第一个数字的左边,如上所示。如果<align>被设置为等号(=,则符号出现在输出字段的左边缘,并且在符号和数字之间放置填充符:
>>> '{0:+8d}'.format(123)
' +123'
>>> '{0:=+8d}'.format(123)
'+ 123'
>>> '{0:+8d}'.format(-123)
' -123'
>>> '{0:=+8d}'.format(-123)
'- 123'
您将在下一节详细介绍<sign>组件。
<fill>指定当格式化值没有完全填充输出宽度时,如何填充额外的空间。可以是除花括号({})以外的任何字符。(如果你真的觉得必须用花括号填充一个字段,那么你只能另寻他法了!)
使用<fill>的一些例子如下所示:
>>> '{0:->8s}'.format('foo')
'-----foo'
>>> '{0:#<8d}'.format(123)
'123#####'
>>> '{0:*^8s}'.format('foo')
'**foo***'
如果您为<fill>指定了一个值,那么您也应该为<align>包含一个值。
<sign> 子组件
您可以使用<sign>组件控制符号是否出现在数字输出中。例如,在下面的例子中,<format_spec>中指定的加号(+)表示该值应该总是以前导符号显示:
>>> '{0:+6d}'.format(123)
' +123'
>>> '{0:+6d}'.format(-123)
' -123'
在这里,您使用加号(+),因此正值和负值都将包含一个符号。如果使用减号(-),则只有负数值会包含前导符号,而正值不会:
>>> '{0:-6d}'.format(123)
' 123'
>>> '{0:-6d}'.format(-123)
' -123'
当您使用单个空格(' ')时,这意味着负值包含一个符号,正值包含一个 ASCII 空格字符:
>>> '{0:*> 6d}'.format(123)
'** 123'
>>> '{0:*>6d}'.format(123)
'***123'
>>> '{0:*> 6d}'.format(-123)
'**-123'
因为空格字符是默认的填充字符,所以只有在指定了替代的<fill>字符时,您才会注意到它的影响。
最后,回想一下上面的内容,当您为<align>指定等号(=)并包含一个<sign>说明符时,填充位于符号和值之间,而不是符号的左边。
# 子组件
当您在<format_spec>中指定一个散列字符(#)时,Python 将为某些表示类型选择一个替代的输出形式。这类似于字符串模运算符的#转换标志。对于二进制、八进制和十六进制表示类型,哈希字符(#)导致在值的左侧包含一个显式的基本指示符:
>>> '{0:b}, {0:#b}'.format(16)
'10000, 0b10000'
>>> '{0:o}, {0:#o}'.format(16)
'20, 0o20'
>>> '{0:x}, {0:#x}'.format(16)
'10, 0x10'
如您所见,基本指示器可以是0b、0o或0x。
对于浮点或指数表示类型,哈希字符强制输出包含小数点,即使输出由整数组成:
>>> '{0:.0f}, {0:#.0f}'.format(123)
'123, 123.'
>>> '{0:.0e}, {0:#.0e}'.format(123)
'1e+02, 1.e+02'
对于除上述显示类型之外的任何显示类型,散列字符(#)不起作用。
0 子组件
如果输出小于指示的字段宽度,并且您在<format_spec>中指定了数字零(0),那么值将在左边用零填充,而不是 ASCII 空格字符:
>>> '{0:05d}'.format(123)
'00123'
>>> '{0:08.1f}'.format(12.3)
'000012.3'
您通常将它用于数值,如上所示。但是,它也适用于字符串值:
>>> '{0:>06s}'.format('foo')
'000foo'
如果您同时指定了<fill>和<align>,那么<fill>将覆盖0:
>>> '{0:*>05d}'.format(123)
'**123'
<fill>和0本质上控制相同的东西,所以没有必要指定两者。事实上,0真的是多余的,可能是为了方便熟悉字符串模运算符类似的0转换标志的开发人员而包含进来的。
<width> 子组件
<width>指定输出字段的最小宽度:
>>> '{0:8s}'.format('foo')
'foo '
>>> '{0:8d}'.format(123)
' 123'
注意,这是一个最小字段宽度。假设您指定了一个比最小值长的值:
>>> '{0:2s}'.format('foobar')
'foobar'
在这种情况下,<width>实际上被忽略了。
<group> 子组件
<group>允许您在数字输出中包含一个分组分隔符。对于十进制和浮点表示类型,<group>可以指定为逗号字符(,)或下划线字符(_)。然后,该字符在输出中分隔每组三位数:
>>> '{0:,d}'.format(1234567)
'1,234,567'
>>> '{0:_d}'.format(1234567)
'1_234_567'
>>> '{0:,.2f}'.format(1234567.89)
'1,234,567.89'
>>> '{0:_.2f}'.format(1234567.89)
'1_234_567.89'
使用下划线(_)的<group>值也可以用二进制、八进制和十六进制表示类型来指定。在这种情况下,输出中的每组四位数由下划线字符分隔:
>>> '{0:_b}'.format(0b111010100001)
'1110_1010_0001'
>>> '{0:#_b}'.format(0b111010100001)
'0b1110_1010_0001'
>>> '{0:_x}'.format(0xae123fcc8ab2)
'ae12_3fcc_8ab2'
>>> '{0:#_x}'.format(0xae123fcc8ab2)
'0xae12_3fcc_8ab2'
如果您试图用除了上面列出的那些之外的任何表示类型来指定<group>,那么您的代码将会引发一个异常。
.<prec> 子组件
.<prec>指定浮点显示类型小数点后的位数:
>>> '{0:8.2f}'.format(1234.5678)
' 1234.57'
>>> '{0:8.4f}'.format(1.23)
' 1.2300'
>>> '{0:8.2e}'.format(1234.5678)
'1.23e+03'
>>> '{0:8.4e}'.format(1.23)
'1.2300e+00'
对于字符串类型,.<prec>指定转换输出的最大宽度:
>>> '{:.4s}'.format('foobar')
'foob'
如果输出比指定的值长,那么它将被截断。
字符串.format()方法:嵌套替换字段
回想一下,您可以使用字符串模运算符通过星号指定或者<width>或者<prec>:
>>> w = 10
>>> p = 2
>>> '%*.*f' % (w, p, 123.456) # Width is 10, precision is 2
' 123.46'
然后从参数列表中获取相关的值。这允许在运行时动态地评估<width>和<prec>,如上面的例子所示。Python 的.format()方法使用嵌套替换字段提供了类似的能力。
在替换字段中,您可以指定一组嵌套的花括号({}),其中包含引用方法的位置或关键字参数之一的名称或数字。然后,替换字段的这一部分将在运行时进行计算,并使用相应的参数进行替换。您可以使用嵌套替换字段实现与上述字符串模运算符示例相同的效果:
>>> w = 10
>>> p = 2
>>> '{2:{0}.{1}f}'.format(w, p, 123.456)
' 123.46'
这里,替换字段的<name>成分是2,表示值为123.456的第三个位置参数。这是要格式化的值。嵌套替换字段{0}和{1}对应于第一和第二位置参数w和p。这些占据了<format_spec>中的<width>和<prec>位置,允许在运行时评估字段宽度和精度。
您也可以在嵌套替换字段中使用关键字参数。此示例在功能上与上一个示例相同:
>>> w = 10
>>> p = 2
>>> '{val:{wid}.{pr}f}'.format(wid=w, pr=p, val=123.456)
' 123.46'
在任一情况下,w和p的值在运行时被评估并用于修改<format_spec>。结果实际上与此相同:
>>> '{0:10.2f}'.format(123.456)
' 123.46'
字符串模运算符只允许以这种方式在运行时对<width>和<prec>求值。相比之下,使用 Python 的.format()方法,您可以使用嵌套替换字段指定<format_spec>的任何部分。
在以下示例中,演示类型<type>由嵌套的替换字段指定并动态确定:
>>> bin(10), oct(10), hex(10)
('0b1010', '0o12', '0xa')
>>> for t in ('b', 'o', 'x'):
... print('{0:#{type}}'.format(10, type=t)) ...
0b1010
0o12
0xa
这里,分组字符<group>是嵌套的:
>>> '{0:{grp}d}'.format(123456789, grp='_')
'123_456_789'
>>> '{0:{grp}d}'.format(123456789, grp=',')
'123,456,789'
咻!那是一次冒险。模板字符串的规范实际上是一种语言!
正如您所看到的,当您使用 Python 的.format()方法时,可以非常精细地调整字符串格式。接下来,您将看到另一种字符串和输出格式化技术,它提供了.format()的所有优点,但是使用了更直接的语法。
Python 格式的字符串文字(f-String)
在 3.6 版本中,引入了一种新的 Python 字符串格式化语法,称为格式化字符串文字。这些也被非正式地称为 f 弦,这个术语最初是在 PEP 498 中创造的,在那里它们被首次提出。
f 字符串语法
一个 f 字符串看起来非常像一个典型的 Python 字符串,除了它被字符f加在前面:
>>> f'foo bar baz'
'foo bar baz'
也可以使用大写的F:
>>> s = F'qux quux'
>>> s
'qux quux'
效果完全一样。就像任何其他类型的字符串一样,您可以使用单引号、双引号或三引号来定义 f 字符串:
>>> f'foo'
'foo'
>>> f"bar"
'bar'
>>> f'''baz'''
'baz'
f-strings 的神奇之处在于,您可以将 Python 表达式直接嵌入其中。用花括号({})括起来的 f 字符串的任何部分都被视为一个表达式。计算表达式并将其转换为字符串表示形式,然后将结果插入到原始字符串的该位置:
>>> s = 'bar'
>>> print(f'foo.{s}.baz')
foo.bar.baz
解释器将 f 字符串的剩余部分——不在花括号内的任何内容——视为普通字符串。例如,转义序列按预期进行处理:
>>> s = 'bar'
>>> print(f'foo\n{s}\nbaz')
foo
bar
baz
这是前面使用 f 弦的例子:
>>> quantity = 6
>>> item = 'bananas'
>>> price = 1.74
>>> print(f'{quantity} {item} cost ${price}')
6 bananas cost $1.74
这相当于以下内容:
>>> quantity = 6
>>> item = 'bananas'
>>> price = 1.74
>>> print('{0} {1} cost ${2}'.format(quantity, item, price))
6 bananas cost $1.74
f 字符串中嵌入的表达式几乎可以任意复杂。以下示例显示了一些可能性:
-
变量:
>>> quantity, item, price = 6, 'bananas', 1.74 >>> f'{quantity} {item} cost ${price}' '6 bananas cost $1.74'` -
算术表达式:
>>> quantity, item, price = 6, 'bananas', 1.74 >>> print(f'Price per item is ${price/quantity}') Price per item is $0.29 >>> x = 6 >>> print(f'{x} cubed is {x**3}') 6 cubed is 216` -
复合类型的对象:
>>> a = ['foo', 'bar', 'baz'] >>> d = {'foo': 1, 'bar': 2} >>> print(f'a = {a} | d = {d}') a = ['foo', 'bar', 'baz'] | d = {'foo': 1, 'bar': 2}` -
索引、切片和键引用:
>>> a = ['foo', 'bar', 'baz'] >>> d = {'foo': 1, 'bar': 2} >>> print(f'First item in list a = {a[0]}') First item in list a = foo >>> print(f'Last two items in list a = {a[-2:]}') Last two items in list a = ['bar', 'baz'] >>> print(f'List a reversed = {a[::-1]}') List a reversed = ['baz', 'bar', 'foo'] >>> print(f"Dict value for key 'bar' is {d['bar']}") Dict value for key 'bar' is 2` -
函数和方法调用:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux'] >>> print(f'List a has {len(a)} items') List a has 5 items >>> s = 'foobar' >>> f'--- {s.upper()} ---' '--- FOOBAR ---' >>> d = {'foo': 1, 'bar': 2} >>> print(f"Dict value for key 'bar' is {d.get('bar')}") Dict value for key 'bar' is 2` -
条件表达式:
>>> x = 3 >>> y = 7 >>> print(f'The larger of {x} and {y} is {x if x > y else y}') The larger of 3 and 7 is 7 >>> age = 13 >>> f'I am {"a minor" if age < 18 else "an adult"}.' 'I am a minor.'` -
对象属性:
>>> z = 3+5j >>> z (3+5j) >>> print(f'real = {z.real}, imag = {z.imag}') real = 3.0, imag = 5.0`
要在 f-string 中包含一个文字花括号,通过将它加倍来对其进行转义,就像在 Python 的.format()方法的模板字符串中一样:
>>> z = 'foobar'
>>> f'{{ {z[::-1]} }}'
'{ raboof }'
你可以在 f 字符串前加上'r'或'R'来表示它是一个原始 f 字符串。在这种情况下,反斜杠序列保持不变,就像普通字符串一样:
>>> z = 'bar'
>>> print(f'foo\n{z}\nbaz')
foo
bar
baz
>>> print(rf'foo\n{z}\nbaz') foo\nbar\nbaz
>>> print(fr'foo\n{z}\nbaz') foo\nbar\nbaz
请注意,您可以先指定'r',然后指定'f',反之亦然。
f 字符串表达式限制
f 字符串表达式有一些小的限制。这些不是太限制性的,但是你应该知道它们是什么。首先,f 字符串表达式不能为空:
>>> f'foo{}bar'
File "<stdin>", line 1
SyntaxError: f-string: empty expression not allowed
不清楚你为什么想这么做。但是如果你觉得不得不去尝试,那就知道这是行不通的。
此外,f 字符串表达式不能包含反斜杠(\)字符。其中,这意味着您不能在 f 字符串表达式中使用反斜杠转义序列:
>>> print(f'foo{\n}bar')
File "<stdin>", line 1
SyntaxError: f-string expression part cannot include a backslash
>>> print(f'foo{\'}bar')
File "<stdin>", line 1
SyntaxError: f-string expression part cannot include a backslash
您可以通过创建一个包含要插入的转义序列的临时变量来绕过这一限制:
>>> nl = '\n'
>>> print(f'foo{nl}bar')
foo
bar
>>> quote = '\''
>>> print(f'foo{quote}bar')
foo'bar
最后,用三重引号引起的 f 字符串中的表达式不能包含注释:
>>> z = 'bar'
>>> print(f'''foo{
... z
... }baz''')
foobarbaz
>>> print(f'''foo{
... z # Comment
... }''')
File "<stdin>", line 3
SyntaxError: f-string expression part cannot include '#'
但是,请注意,多行 f 字符串可能包含嵌入的换行符。
f 字符串格式化
像 Python 的.format()方法一样,f 字符串支持大量的修饰符,它们控制输出字符串的最终外观。还有更多好消息。如果你已经掌握了 Python 的.format()方法,那么你已经知道如何使用 Python 来格式化 f 字符串了!
f 字符串中的表达式可以通过<conversion>或<format_spec>来修改,就像在.format()模板中使用的替换字段一样。语法是相同的。事实上,在这两种情况下,Python 都将使用相同的内部函数来格式化替换字段。在下面的示例中,!r被指定为.format()模板字符串中的<conversion>组件:
>>> s = 'foo'
>>> '{0!r}'.format(s)
"'foo'"
这将强制由repr()执行转换。相反,您可以使用 f 字符串获得基本相同的代码:
>>> s = 'foo'
>>> f'{s!r}'
"'foo'"
所有与.format()一起工作的<format_spec>组件也与 f 弦一起工作:
>>> n = 123
>>> '{:=+8}'.format(n)
'+ 123'
>>> f'{n:=+8}'
'+ 123'
>>> s = 'foo'
>>> '{0:*^8}'.format(s)
'**foo***'
>>> f'{s:*^8}'
'**foo***'
>>> n = 0b111010100001
>>> '{0:#_b}'.format(n)
'0b1110_1010_0001'
>>> f'{n:#_b}'
'0b1110_1010_0001'
嵌套也可以工作,比如用 Python 的.format()方法嵌套替换字段:
>>> a = ['foo', 'bar', 'baz', 'qux', 'quux']
>>> w = 4
>>> f'{len(a):0{w}d}'
'0005'
>>> n = 123456789
>>> sep = '_'
>>> f'{(n * n):{sep}d}'
'15_241_578_750_190_521'
这意味着格式化项可以在运行时计算。
f-strings 和 Python 的.format()方法或多或少是做同一件事的两种不同方式,f-strings 是一种更简洁的简写方式。以下表达式本质上是相同的:
f'{<expr>!<conversion>:<format_spec>}'
'{0!<conversion>:<format_spec>}'.format(<expr>)
如果你想进一步探索 f 字符串,那么看看 Python 3 的 f 字符串:一个改进的字符串格式语法(教程)。
结论
在本教程中,您掌握了另外两种可以在 Python 中用来格式化字符串数据的技术。现在,您应该拥有了为输出或显示准备字符串数据所需的所有工具!
您可能想知道应该使用哪种 Python 格式化技术。什么情况下你会选择 .format() 而不是 f 弦?参见 Python 字符串格式化最佳实践了解一些需要考虑的事项。
在下一篇教程中,您将学习更多关于 Python 中的函数的知识。在本系列教程中,您已经看到了许多 Python 的内置函数的例子。在 Python 中,就像在大多数编程语言中一样,你也可以定义自己的自定义用户定义函数。如果你迫不及待地想了解如何继续下一个教程!
« Basic Input, Output, and String Formatting in PythonPython String Formatting TechniquesDefining Your Own Python Function »
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: 格式化 Python 字符串*********
用 Python 分数表示有理数
Python 中的fractions模块可以说是标准库中使用最少的元素之一。尽管它可能不太出名,但它是一个非常有用的工具,因为它可以帮助解决二进制浮点运算的缺点。如果你打算处理财务数据或者如果你需要无限精确进行计算,这是必不可少的。
在本教程的末尾,你会看到一些动手的例子,其中分数是最合适和优雅的选择。你还将了解他们的弱点,以及如何在这个过程中充分利用它们。
在本教程中,您将学习如何:
- 在十进制和小数记数法之间转换
- 执行有理数运算
- 近似无理数
- 用无限精度精确表示分数
- 知道什么时候选择
Fraction而不是Decimal或float
本教程的大部分内容都是关于fractions模块的,它本身不需要深入的 Python 知识,只需要理解它的数值类型。然而,如果您熟悉更高级的概念,比如 Python 的内置 collections模块、、itertools模块和生成器,那么您将能够很好地完成后面的所有代码示例。如果您想充分利用本教程,您应该已经熟悉了这些主题。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
十进制与分数记数法
让我们沿着记忆之路走一走,回忆一下你在学校学到的数字知识,避免可能的困惑。这里有四个概念:
- 数学中的数字类型
- 数字系统
- 数字的符号
- Python 中的数字数据类型
现在,您将快速了解其中的每一个,以便更好地理解 Python 中Fraction数据类型的用途。
数字分类
如果你不记得数字的分类,这里有一个快速复习:
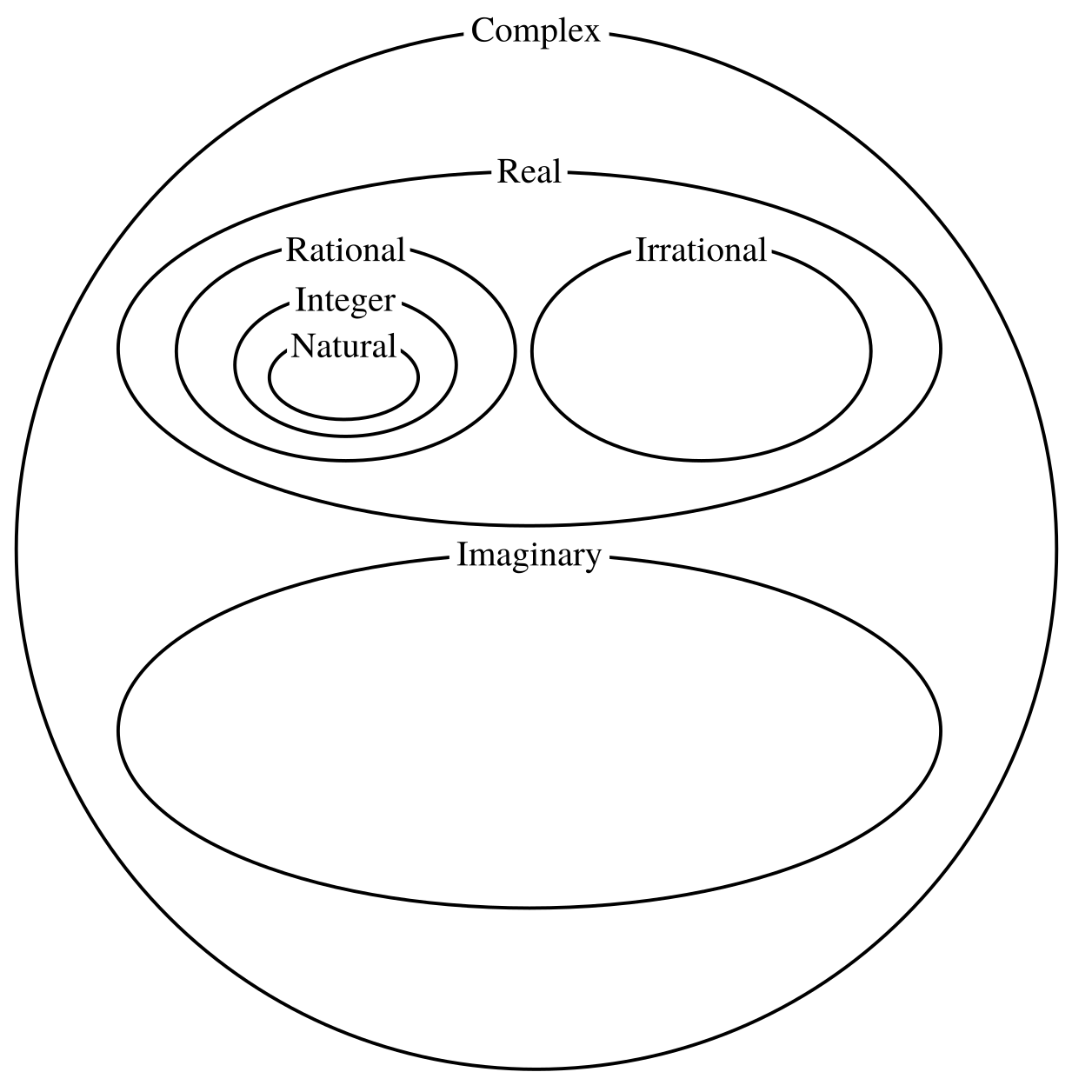
数学中有更多类型的数字,但这些是与日常生活最相关的。在最顶端,你会发现复数,包括虚数和实数。实数依次由有理数和无理数和无理数组成。最后,有理数包含整数和自然数。
数字系统和符号
几个世纪以来,有各种各样的视觉表达数字的系统。今天,大多数人使用基于印度-阿拉伯符号的位置数字系统。对于这样的系统,你可以选择任意的基或基数。然而,尽管人们更喜欢十进制(基数为 10),计算机在二进制(基数为 2)中工作得最好。
在十进制系统中,您可以使用其他符号来表示一些数字:
- Decimal: 0.75
- 分数:
这两者都不比另一个更好或更精确。用十进制表示数字可能更直观,因为它类似于一个百分比。比较小数也更简单,因为它们已经有了一个共同的分母——系统的基础。最后,十进制数字可以通过保持尾随零和前导零来传达精度。
另一方面,分数在手工进行符号代数时更方便,这就是为什么它们主要在学校使用。但是你能回忆起你最后一次使用分数是什么时候吗?如果你不能,那是因为十进制是当今计算器和计算机的核心。
分数符号通常只与有理数相关联。毕竟,有理数的定义表明,只要分母不为零,它就可以表示为两个整数的商,或 T2 分数。然而,当你考虑到可以近似无理数的无限连分数时,这还不是故事的全部:
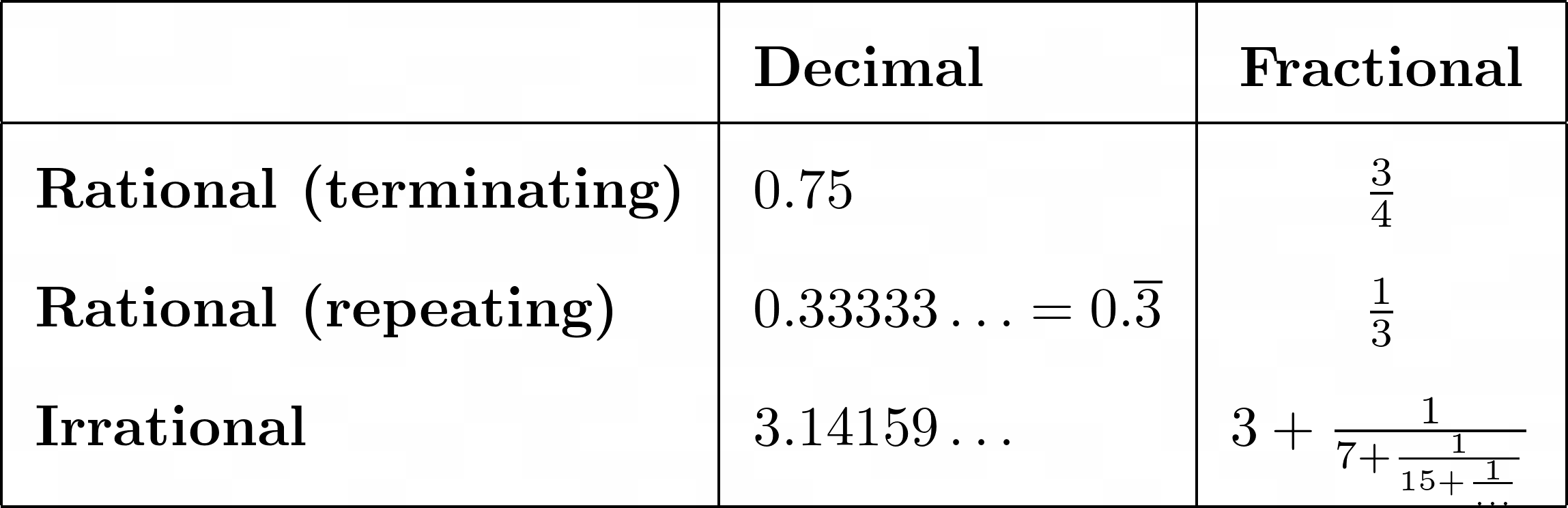
无理数总是有一个无终止无重复的小数展开式。例如,圆周率(π)的十进制展开式永远不会用完看起来具有随机分布的数字。如果你画出它们的直方图,那么每个数字将有一个大致相似的频率。
另一方面,大多数有理数都有终止的十进制展开。然而,有些可以有一个无限循环的十进制展开,一个或多个数字在一个周期内重复。重复的数字通常用十进制符号中的省略号(0.33333…)表示。不管它们的十进制扩展如何,有理数(如代表三分之一的数)在分数记数法中总是看起来优雅而紧凑。
Python 中的数字数据类型
当在计算机内存中以浮点数据类型存储时,具有无限小数扩展的数字会导致舍入误差,而计算机内存本身是有限的。更糟糕的是,用二进制的终止十进制扩展通常不可能准确地表示数字!
这就是所谓的浮点表示错误,它影响所有编程语言,包括 Python 。每个程序员迟早都会面临这个问题。例如,您不能在像银行这样的应用程序中使用float,在这些应用程序中,必须在不损失任何精度的情况下存储和处理数字。
Python 的Fraction就是这些障碍的解决方案之一。虽然它代表一个有理数,但名称Rational已经代表了 numbers 模块中的一个抽象基类。numbers模块定义了抽象数字数据类型的层次结构,以模拟数学中的数字分类:
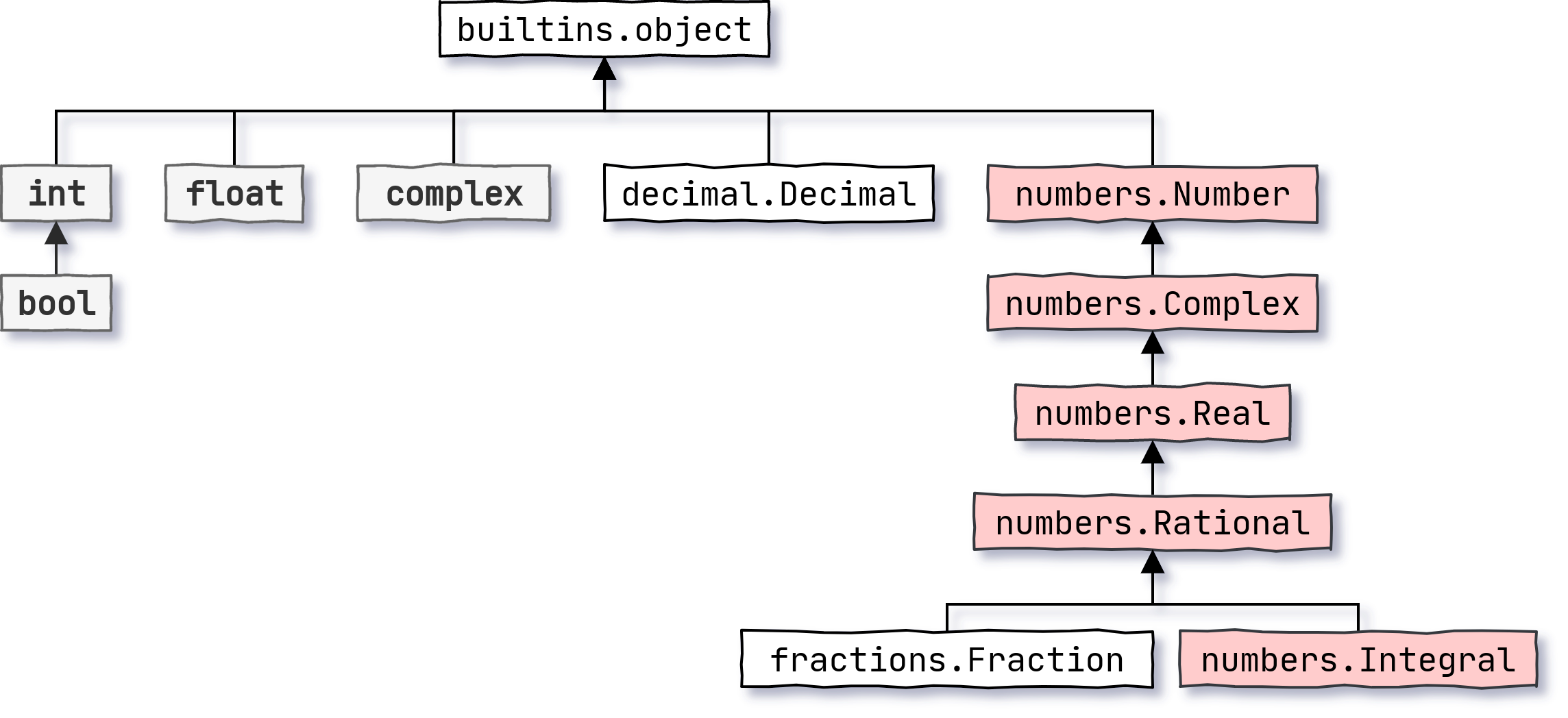
Fraction是Rational的直接和具体的子类,它提供了 Python 中有理数的完整实现。像int和bool这样的整型也来源于Rational,但是那些更具体。
有了这些理论背景,是时候创建你的第一个分数了!
从不同的数据类型创建 Python 片段
与int或float不同,分数不是 Python 中的内置数据类型,这意味着您必须从标准库中导入相应的模块才能使用它们。然而,一旦你通过了这个额外的步骤,你会发现分数只是代表了另一种数字类型,你可以在算术表达式中自由地与其他数字和数学运算符混合。
**注意:**分数是用纯 Python 实现的,并且比可以直接在硬件上运行的浮点数慢得多。在大多数需要大量计算的情况下,性能比精度更重要。另一方面,如果你既需要性能又需要精度,那么考虑一种叫做 quicktions 的分数替代方法,它可能会在某种程度上提高你的执行速度。
在 Python 中有几种创建分数的方法,它们都涉及到使用Fraction类。这是您唯一需要从fractions模块导入的东西。类构造函数接受零个、一个或两个不同类型的参数:
>>> from fractions import Fraction
>>> print(Fraction())
0
>>> print(Fraction(0.75))
3/4
>>> print(Fraction(3, 4))
3/4
当您调用不带参数的类构造函数时,它会创建一个表示数字零的新分数。单参数风格试图将另一种数据类型的值转换为分数。传入第二个参数使得构造函数期望一个分子和一个分母,它们必须是Rational类或其后代的实例。
注意,您必须 print() 一个分数,以显示其友好的文本表示,在分子和分母之间使用斜杠字符(/)。如果不这样做,它将退回到由一段 Python 代码组成的稍微显式一些的字符串表示。在本教程的后面,你将学习如何将分数转换成字符串。
有理数
当你用两个参数调用Fraction()构造函数时,它们必须都是有理数,比如整数或其他分数。如果分子或分母都不是有理数,那么您将无法创建新的分数:
>>> Fraction(3, 4.0)
Traceback (most recent call last):
...
raise TypeError("both arguments should be "
TypeError: both arguments should be Rational instances
你反而得到了一个TypeError。虽然4.0在数学上是一个有理数,但 Python 并不这么认为。这是因为值存储为浮点数据类型,这种数据类型太宽泛,可以用来表示任何实数。
注:浮点数据类型不能在计算机内存中精确地存储无理数,因为它们的十进制展开没有终止和不重复。然而实际上,这没什么大不了的,因为他们的近似值通常就足够好了。唯一真正可靠的方法是对π这样的传统符号使用符号计算。
同样,你不能创建一个分母为零的分数,因为这将导致被零除,这在数学上没有定义和意义:
>>> Fraction(3, 0)
Traceback (most recent call last):
...
raise ZeroDivisionError('Fraction(%s, 0)' % numerator)
ZeroDivisionError: Fraction(3, 0)
Python 抛出了ZeroDivisionError。然而,当你指定一个有效的分子和一个有效的分母时,只要它们有一个公约数,它们就会自动被规范化:
>>> Fraction(9, 12) # GCD(9, 12) = 3
Fraction(3, 4)
>>> Fraction(0, 12) # GCD(0, 12) = 12
Fraction(0, 1)
这两个数值都通过它们的最大公约数(GCD) 得到简化,恰好分别是 3 和 12。当您定义负分数时,归一化也会考虑负号:
>>> -Fraction(9, 12)
Fraction(-3, 4)
>>> Fraction(-9, 12)
Fraction(-3, 4)
>>> Fraction(9, -12)
Fraction(-3, 4)
无论您将减号放在构造函数之前还是放在任何一个参数之前,为了一致性,Python 总是将分数的符号与其分子相关联。目前有一种方法可以禁用这种行为,但它没有记录在案,将来可能会被删除。
你通常将分数定义为两个整数的商。只要你只提供一个整数,Python 就会通过假设分母为1将这个数字转化为不适当的分数:
>>> Fraction(3)
Fraction(3, 1)
相反,如果跳过这两个参数,分子将是0:
>>> Fraction()
Fraction(0, 1)
不过,您不必总是为分子和分母提供整数。该文档声明它们可以是任何有理数,包括其他分数:
>>> one_third = Fraction(1, 3)
>>> Fraction(one_third, 3)
Fraction(1, 9)
>>> Fraction(3, one_third)
Fraction(9, 1)
>>> Fraction(one_third, one_third)
Fraction(1, 1)
在每种情况下,结果都是一个分数,即使它们有时代表像 9 和 1 这样的整数值。稍后,您将看到如何将分数转换为其他数据类型。
如果给Fraction构造函数一个参数,这个参数恰好是一个分数,会发生什么?尝试此代码以找出:
>>> Fraction(one_third) == one_third
True
>>> Fraction(one_third) is one_third
False
您得到的是相同的值,但是它是输入分数的不同副本。这是因为调用构造函数总是会产生一个新的实例,这与分数是不可变的这一事实不谋而合,就像 Python 中的其他数值类型一样。
浮点数和十进制数
到目前为止,您只使用了有理数来创建分数。毕竟,Fraction构造函数的双参数版本要求两个数字都是Rational实例。然而,单参数构造函数就不是这样了,它可以接受任何实数,甚至是字符串这样的非数值。
Python 中实数数据类型的两个主要例子是float和 decimal.Decimal 。虽然只有后者可以精确地表示有理数,但两者都可以很好地近似无理数。与此相关,如果你想知道,Fraction在这方面与Decimal相似,因为它是Real的后代。
与float或Fraction不同,Decimal类没有正式注册为numbers.Real的子类,尽管实现了它的方法:
>>> from numbers import Real
>>> issubclass(float, Real)
True
>>> from fractions import Fraction
>>> issubclass(Fraction, Real)
True
>>> from decimal import Decimal
>>> issubclass(Decimal, Real) False
这是故意的,因为十进制浮点数与二进制数不太协调:
>>> from decimal import Decimal
>>> Decimal("0.75") - 0.25
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'decimal.Decimal' and 'float'
另一方面,在上面的例子中,用等价的Fraction替换Decimal会产生一个float结果。
在 Python 3.2 之前,您只能使用.from_float()和.from_decimal()类方法从实数创建分数。虽然没有被弃用,但今天它们是多余的,因为Fraction构造函数可以直接将这两种数据类型作为参数:
>>> from decimal import Decimal
>>> Fraction(0.75) == Fraction(Decimal("0.75"))
True
无论是从float还是Decimal对象制作Fraction对象,它们的值都是一样的。您以前见过从浮点值创建的分数:
>>> print(Fraction(0.75))
3/4
结果是用分数表示的相同数字。然而,这段代码只是巧合地按预期工作。在大多数情况下,由于影响float数字的表示错误,您不会得到预期的值,无论它们是否合理:
>>> print(Fraction(0.1))
3602879701896397/36028797018963968
哇哦。这里发生了什么?
让我们用慢动作分解一下。前一个数字可以表示为 0.75 或,也可以表示为和的和,它们是 2 的负幂,具有精确的二进制表示。另一方面,数字⅒只能用二进制数字的无终止重复扩展来近似为:

由于内存有限,二进制字符串最终必须结束,所以它的尾部变圆了。默认情况下,Python 只显示在sys.float_info.dig中定义的最重要的数字,但是如果你想的话,你可以格式化一个任意位数的浮点数:
>>> str(0.1)
'0.1'
>>> format(0.1, ".17f")
'0.10000000000000001'
>>> format(0.1, ".18f")
'0.100000000000000006'
>>> format(0.1, ".19f")
'0.1000000000000000056'
>>> format(0.1, ".55f")
'0.1000000000000000055511151231257827021181583404541015625'
当您将一个float或一个Decimal数字传递给Fraction构造函数时,它会调用它们的.as_integer_ratio()方法来获得一个由两个不可约整数组成的元组,这两个整数的比值给出了与输入参数完全相同的十进制展开。然后,这两个数字被指定为新分数的分子和分母。
**注意:**从 Python 3.8 开始,Fraction也实现了.as_integer_ratio()来补充其他数值类型。例如,它可以帮助您将分数转换为元组。
现在,你可以拼凑出这两个大数字的来源:
>>> Fraction(0.1)
Fraction(3602879701896397, 36028797018963968)
>>> (0.1).as_integer_ratio()
(3602879701896397, 36028797018963968)
如果你拿出你的袖珍计算器,输入这些数字,那么你将得到 0.1 作为除法的结果。然而,如果你用手或者使用像 WolframAlpha 这样的工具来划分它们,那么你会得到之前看到的 55 位小数。
有一种方法可以找到更接近你分数的近似值,它们有更实际的价值。例如,您可以使用.limit_denominator(),稍后您将在本教程中了解更多:
>>> one_tenth = Fraction(0.1)
>>> one_tenth
Fraction(3602879701896397, 36028797018963968)
>>> one_tenth.limit_denominator()
Fraction(1, 10)
>>> one_tenth.limit_denominator(max_denominator=int(1e16))
Fraction(1000000000000000, 9999999999999999)
不过,这可能并不总是给你最好的近似值。底线是,如果你想避免可能出现的舍入误差,你应该永远不要试图直接从实数如float中创建分数。如果你不够小心,即使是Decimal类也可能受到影响。
无论如何,分数让你在它们的构造函数中用字符串最准确地表达十进制符号。
字符串
Fraction构造函数接受两种字符串格式,分别对应于十进制和小数表示法:
>>> Fraction("0.1")
Fraction(1, 10)
>>> Fraction("1/10")
Fraction(1, 10)
这两种记数法都可以有一个加号(+)或减号(-),而十进制记数法可以额外包含指数,以防您想要使用科学记数法:
>>> Fraction("-2e-3")
Fraction(-1, 500)
>>> Fraction("+2/1000")
Fraction(1, 500)
两个结果唯一的区别就是一个是负的,一个是正的。
使用分数符号时,不能在斜杠字符(/)周围使用空白字符:
>>> Fraction("1 / 10")
Traceback (most recent call last):
...
raise ValueError('Invalid literal for Fraction: %r' %
ValueError: Invalid literal for Fraction: '1 / 10'
要确切地找出哪些字符串是有效的或无效的,可以探索一下模块的源代码中的正则表达式。记住从字符串或正确实例化的Decimal对象创建分数,而不是从float值创建分数,这样可以保持最大精度。
现在你已经创建了一些分数,你可能想知道除了第二组数字之外,它们还能为你做什么。这是一个很好的问题!
检查 Python 片段
Rational抽象基类定义了两个只读属性,用于访问分数的分子和分母:
>>> from fractions import Fraction
>>> half = Fraction(1, 2)
>>> half.numerator
1
>>> half.denominator
2
因为分数是不可变的,你不能改变它们的内部状态:
>>> half.numerator = 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute
如果您尝试为分数的一个属性指定一个新值,那么您将会得到一个错误。事实上,当您想要修改一个片段时,您必须创建一个新的片段。例如,为了反转你的分数,你可以调用.as_integer_ratio()得到一个元组,然后使用切片语法反转它的元素:
>>> Fraction(*half.as_integer_ratio()[::-1])
Fraction(2, 1)
一元星形运算符(* ) 解包你的反转元组,并将其元素传递给Fraction构造函数。
每一个分数都有另一个有用的方法,可以让你找到最接近十进制记数法中给定数字的有理逼近。这是.limit_denominator()方法,您在本教程的前面已经提到过。您可以选择请求近似值的最大分母:
>>> pi = Fraction("3.141592653589793")
>>> pi
Fraction(3141592653589793, 1000000000000000)
>>> pi.limit_denominator(20_000)
Fraction(62813, 19994)
>>> pi.limit_denominator(100)
Fraction(311, 99)
>>> pi.limit_denominator(10)
Fraction(22, 7)
初始近似值可能不是最方便使用的,但却是最可靠的。这个方法还可以帮助你恢复一个以浮点数据类型存储的有理数。记住float可能不会精确地表示所有的有理数,即使它们有终止的十进制展开:
>>> pi = Fraction(3.141592653589793)
>>> pi
Fraction(884279719003555, 281474976710656)
>>> pi.limit_denominator()
Fraction(3126535, 995207)
>>> pi.limit_denominator(10)
Fraction(22, 7)
与前面的代码块相比,您会注意到高亮显示的行上有不同的结果,即使float实例看起来与您之前传递给构造函数的字符串文字相同!稍后,您将探索一个使用.limit_denominator()寻找无理数近似值的例子。
将 Python 片段转换成其他数据类型
您已经学习了如何从以下数据类型创建分数:
strintfloatdecimal.Decimalfractions.Fraction
反过来呢?如何将一个Fraction实例转换回这些类型?你将在这一部分找到答案。
浮点数和整数
Python 中本地数据类型之间的转换通常涉及调用一个内置函数,比如对象上的int()或float()。只要对象实现了相应的特殊方法,如.__int__()或.__float__(),这些转换就会起作用。分数恰好从Rational抽象基类中继承了后者:
>>> from fractions import Fraction
>>> three_quarters = Fraction(3, 4)
>>> float(three_quarters)
0.75
>>> three_quarters.__float__() # Don't call special methods directly
0.75
>>> three_quarters.__int__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Fraction' object has no attribute '__int__'
您不应该直接调用对象上的特殊方法,但这有助于演示。这里,你会注意到分数只实现了.__float__()而没有实现.__int__()。
当您研究源代码时,您会注意到.__float__()方法很方便地将一个分数的分子除以它的分母,从而得到一个浮点数:
>>> three_quarters.numerator / three_quarters.denominator
0.75
请记住,将一个Fraction实例转换成一个float实例可能会导致一个有损转换,这意味着您可能会得到一个稍微有些偏差的数字:
>>> float(Fraction(3, 4)) == Fraction(3, 4)
True
>>> float(Fraction(1, 3)) == Fraction(1, 3)
False
>>> float(Fraction(1, 10)) == Fraction(1, 10)
False
虽然分数不提供整数转换的实现,但是所有的实数都可以被截断,这是int()函数的一个后备:
>>> fraction = Fraction(14, 5)
>>> int(fraction)
2
>>> import math
>>> math.trunc(fraction)
2
>>> fraction.__trunc__() # Don't call special methods directly
2
稍后,在关于舍入分数的章节中,您会发现其他一些相关的方法。
十进制数字
如果您尝试从一个Fraction实例创建一个Decimal数字,那么您会很快发现这样的直接转换是不可能的:
>>> from decimal import Decimal
>>> Decimal(Fraction(3, 4))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: conversion from Fraction to Decimal is not supported
当你尝试时,你会得到一个TypeError。因为一个分数代表一个除法,但是,你可以通过仅用Decimal包装其中一个数字并手动分割它们来绕过这个限制:
>>> fraction = Fraction(3, 4)
>>> fraction.numerator / Decimal(fraction.denominator)
Decimal('0.75')
与float不同,但与Fraction相似,Decimal数据类型没有浮点表示错误。因此,当您转换一个无法用二进制浮点精确表示的有理数时,您将保留该数的精度:
>>> fraction = Fraction(1, 10)
>>> decimal = fraction.numerator / Decimal(fraction.denominator)
>>> fraction == decimal
True
>>> fraction == 0.1
False
>>> decimal == 0.1
False
同时,具有无终止重复十进制展开的有理数将在从小数转换为十进制时导致精度损失:
>>> fraction = Fraction(1, 3)
>>> decimal = fraction.numerator / Decimal(fraction.denominator)
>>> fraction == decimal
False
>>> decimal
Decimal('0.3333333333333333333333333333')
这是因为在三分之一的十进制扩展中有无限个三,或者说Fraction(1, 3),而Decimal类型有一个固定的精度。默认情况下,它只存储 28 位小数。如果你想的话,你可以调整它,但是它仍然是有限的。
字符串
分数的字符串表示使用熟悉的分数符号显示它们的值,而它们的规范表示输出一段 Python 代码,其中包含对Fraction构造函数的调用:
>>> one_third = Fraction(1, 3)
>>> str(one_third)
'1/3'
>>> repr(one_third)
'Fraction(1, 3)'
不管你用str()还是repr(),结果都是一个字符串,只是它们的内容不同。
与其他数值类型不同,分数不支持 Python 中的字符串格式:
>>> from decimal import Decimal
>>> format(Decimal("0.3333333333333333333333333333"), ".2f")
'0.33'
>>> format(Fraction(1, 3), ".2f")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported format string passed to Fraction.__format__
如果你尝试,你会得到一个TypeError。例如,如果您想在字符串模板中引用一个Fraction实例来填充占位符,这可能是一个问题。另一方面,您可以通过将分数转换为浮点数来快速解决这个问题,特别是在这种情况下,您不需要关心精度。
如果你在 Jupyter 笔记本上工作,那么你可能想要基于你的分数而不是它们的常规文本表示来呈现 LaTeX 公式。为此,您必须 monkey 通过添加 Jupyter Notebook 能够识别的新方法 ._repr_pretty_() 来修补数据类型:
from fractions import Fraction
from IPython.display import display, Math
Fraction._repr_pretty_ = lambda self, *args: \
display(Math(rf"$$\frac{{{self.numerator}}}{{{self.denominator}}}"))
它将一段 LaTeX 标记包装在一个Math对象中,并将其发送到您笔记本的富显示器,该显示器可以使用 MathJax 库来呈现标记:

下一次您评估包含Fraction实例的笔记本单元格时,它将绘制一个漂亮的数学公式,而不是打印文本。
对分数进行有理数运算
如前所述,您可以在由其他数值类型组成的算术表达式中使用分数。分数将与大多数数字类型互操作,除了decimal.Decimal,它有自己的一套规则。此外,另一个操作数的数据类型,无论它位于分数的左边还是右边,都将决定算术运算结果的类型。
加法
您可以将两个或更多分数相加,而不必考虑将它们简化为公分母:
>>> from fractions import Fraction
>>> Fraction(1, 2) + Fraction(2, 3) + Fraction(3, 4)
Fraction(23, 12)
结果是一个新分数,它是所有输入分数的总和。当你把整数和分数相加时,也会发生同样的情况:
>>> Fraction(1, 2) + 3
Fraction(7, 2)
但是,一旦您开始将分数与非有理数混合,即不是numbers.Rational的子类的数字,那么您的分数在被添加之前将首先被转换为该类型:
>>> Fraction(3, 10) + 0.1
0.4
>>> float(Fraction(3, 10)) + 0.1
0.4
无论是否显式使用float(),都会得到相同的结果。这种转换可能会导致精度损失,因为分数和结果现在都以浮点形式存储。尽管数字 0.4 看起来是对的,但它并不完全等于分数 4/10。
减法
分数相减和相加没有什么不同。Python 将为您找到共同点:
>>> Fraction(3, 4) - Fraction(2, 3) - Fraction(1, 2)
Fraction(-5, 12)
>>> Fraction(4, 10) - 0.1
0.30000000000000004
这一次,精度损失非常显著,一目了然。请注意,在十进制扩展的末尾,有一长串的零后跟一个数字4。这是对一个值进行舍入的结果,否则它将需要无限多的二进制数字。
乘法运算
当您将两个分数相乘时,它们的分子和分母会逐元素相乘,如果需要,结果分数会自动减少:
>>> Fraction(1, 4) * Fraction(3, 2)
Fraction(3, 8)
>>> Fraction(1, 4) * Fraction(4, 5) # The result is 4/20
Fraction(1, 5)
>>> Fraction(1, 4) * 3
Fraction(3, 4)
>>> Fraction(1, 4) * 3.0
0.75
同样,根据另一个操作数的类型,结果中会有不同的数据类型。
分部
Python 中有两种除法运算符,分数支持这两种运算符:
- 真师:
/ - 楼层划分:
//
真正的除法会产生另一个分数,而底数除法总是会返回一个小数部分被截断的整数:
>>> Fraction(7, 2) / Fraction(2, 3)
Fraction(21, 4)
>>> Fraction(7, 2) // Fraction(2, 3)
5
>>> Fraction(7, 2) / 2
Fraction(7, 4)
>>> Fraction(7, 2) // 2
1
>>> Fraction(7, 2) / 2.0
1.75
>>> Fraction(7, 2) // 2.0
1.0
请注意,地板除法的结果并不总是整数!结果可能以一个float结束,这取决于与分数一起使用的数据类型。分数还支持模运算符(% ) 以及 divmod() 函数,这可能有助于从不适当的分数创建混合分数:
>>> def mixed(fraction):
... floor, rest = divmod(fraction.numerator, fraction.denominator)
... return f"{floor} and {Fraction(rest, fraction.denominator)}"
...
>>> mixed(Fraction(22, 7))
'3 and 1/7'
您可以更新函数,返回一个由整数部分和小数余数组成的元组,而不是像上面的输出那样生成一个字符串。继续尝试修改函数的返回值,看看有什么不同。
求幂运算
你可以用二进制的取幂运算符(** ) 或者内置的 pow() 函数来计算分数的幂。你也可以用分数本身作为指数。现在回到你的 Python 解释器,开始探索如何计算分数的幂:
>>> Fraction(3, 4) ** 2
Fraction(9, 16)
>>> Fraction(3, 4) ** (-2)
Fraction(16, 9)
>>> Fraction(3, 4) ** 2.0
0.5625
您会注意到,您可以使用正指数值和负指数值。当指数不是一个Rational数时,您的分数在继续之前会自动转换为float。
当指数是一个Fraction实例时,事情变得更加复杂。因为分数幂通常产生无理数,所以两个操作数都转换为float,除非基数和指数是整数:
>>> 2 ** Fraction(2, 1)
4
>>> 2.0 ** Fraction(2, 1)
4.0
>>> Fraction(3, 4) ** Fraction(1, 2)
0.8660254037844386
>>> Fraction(3, 4) ** Fraction(2, 1)
Fraction(9, 16)
唯一一次得到分数的结果是当指数的分母等于 1,并且你正在产生一个Fraction实例。
对 Python 分数进行舍入
在 Python 中有很多舍入数字的策略,在数学中甚至更多。分数和小数可以使用同一套内置的全局函数和模块级函数。它们可以让你将一个整数赋给一个分数,或者生成一个对应于更少小数位数的新分数。
当您将分数转换为int时,您已经了解了一种粗略的舍入方法,即截断小数部分,只留下整部分(如果有的话):
>>> from fractions import Fraction
>>> int(Fraction(22, 7))
3
>>> import math
>>> math.trunc(Fraction(22, 7))
3
>>> math.trunc(-Fraction(22, 7))
-3
在这种情况下,调用int()相当于调用math.trunc(),它向下舍入正分数,向上舍入负分数。这两种操作分别被称为地板和天花板。如果需要,您可以直接使用两者:
>>> math.floor(-Fraction(22, 7))
-4
>>> math.floor(Fraction(22, 7))
3
>>> math.ceil(-Fraction(22, 7))
-3
>>> math.ceil(Fraction(22, 7))
4
将math.floor()和math.ceil()的结果与您之前对math.trunc()的调用进行比较。每个函数都有不同的舍入偏差,这可能会影响舍入数据集的统计属性。幸运的是,有一种策略叫做四舍五入成偶数,它比截断、下限或上限更少偏差。
本质上,它将分数舍入到最接近的整数,而对于等距的两部分,则更倾向于最接近的偶数。您可以调用round()来利用这一策略:
>>> round(Fraction(3, 2)) # 1.5
2
>>> round(Fraction(5, 2)) # 2.5
2
>>> round(Fraction(7, 2)) # 3.5
4
注意这些分数是如何根据最接近的偶数的位置向上或向下舍入的?自然地,这条规则只适用于左边最接近的整数和右边最接近的整数的距离相同的情况。否则,舍入方向基于到整数的最短距离,而不管它是否是偶数。
您可以选择为round()函数提供第二个参数,该参数指示您想要保留多少个小数位。当你这样做时,你将总是得到一个Fraction而不是一个整数,即使你请求的是零位数:
>>> fraction = Fraction(22, 7) # 3.142857142857143
>>> round(fraction, 0)
Fraction(3, 1)
>>> round(fraction, 1) # 3.1
Fraction(31, 10)
>>> round(fraction, 2) # 3.14
Fraction(157, 50)
>>> round(fraction, 3) # 3.143
Fraction(3143, 1000)
然而,请注意调用round(fraction)和round(fraction, 0)之间的区别,它们产生相同的值,但是使用不同的数据类型:
>>> round(fraction)
3
>>> round(fraction, 0)
Fraction(3, 1)
当您省略第二个参数时,round()将返回最接近的整数。否则,您将得到一个缩减的分数,它的分母最初是 10 的幂,对应于您所请求的十进制位数。
在 Python 中比较分数
在现实生活中,比较用分数表示的数字可能比比较用十进制表示的数字更困难,因为分数表示由两个值组成,而不是只有一个值。为了理解这些数字,通常将它们简化为一个公分母,并且只比较它们的分子。例如,尝试根据分数的值以升序排列以下分数:
- 2/3
- 5/8
- 8/13
它不像十进制记数法那样方便。混合符号的情况会变得更糟。然而,当你用一个共同的分母重写这些分数时,对它们进行排序就变得简单了:
- 208/312
- 195/312
- 192/312
3,8,13 的最大公约数是 1。这意味着所有三个分数的最小公分母是它们的乘积 312。一旦你把所有的分数转换成最小的公分母,你就可以忽略分母,专注于比较分子。
在 Python 中,当您比较和排序Fraction对象时,这在幕后工作:
>>> from fractions import Fraction
>>> Fraction(8, 13) < Fraction(5, 8)
True
>>> sorted([Fraction(2, 3), Fraction(5, 8), Fraction(8, 13)])
[Fraction(8, 13), Fraction(5, 8), Fraction(2, 3)]
Python 可以使用内置的sorted()函数对Fraction对象进行快速排序。有益的是,所有的比较操作符都按照预期工作。您甚至可以将它们用于除复数以外的其他数值类型:
>>> Fraction(2, 3) < 0.625
False
>>> from decimal import Decimal
>>> Fraction(2, 3) < Decimal("0.625")
False
>>> Fraction(2, 3) < 3 + 2j
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'Fraction' and 'complex'
比较运算符适用于浮点数和小数,但是当您尝试使用复数3 + 2j时会出现错误。这与复数没有定义自然排序关系的事实有关,所以你不能将它们与任何东西进行比较——包括分数。
在Fraction、Decimal、Float和之间选择
如果你需要从阅读本教程中挑选一件事情来记住,那么它应该是什么时候选择Fraction而不是Decimal和float。所有这些数字类型都有它们的用例,所以了解它们的优缺点是有好处的。在本节中,您将简要了解数字在这三种数据类型中是如何表示的。
二进制浮点:float
在大多数情况下,float数据类型应该是表示实数的默认选择。例如,它适用于科学、工程和计算机图形学,在这些领域中,执行速度比精度更重要。几乎没有任何程序需要比浮点更高的精度。
**注意:**如果你只需要使用整数,那么int将是一个速度和内存效率更高的数据类型。
浮点运算无与伦比的速度源于其在硬件而非软件中的实现。几乎所有的数学协处理器都符合 IEEE 754 标准,该标准描述了如何用二进制浮点 T2 表示数字。如你所料,使用二进制的缺点是臭名昭著的表示错误。
然而,除非你有特定的理由使用不同的数字类型,否则如果可能的话,你应该坚持使用float或int。
十进制浮点和定点:Decimal
有时使用二进制系统不能为实数提供足够的精度。一个显著的例子是金融计算,它涉及同时处理非常大和非常小的数字。他们还倾向于一遍又一遍地重复相同的算术运算,这可能会累积显著的舍入误差。
您可以使用十进制浮点算法来存储实数,以缓解这些问题并消除二进制表示错误。它类似于float,因为它移动小数点以适应更大或更小的幅度。然而,它以十进制而不是二进制运行。
另一种提高数值精度的策略是定点算术,它为十进制扩展分配特定的位数。例如,最多四位小数的精度要求将分数存储为放大 10,000 倍的整数。为了恢复原来的分数,它们将被相应地缩小。
Python 的decimal.Decimal数据类型是十进制浮点和定点表示的混合。它还遵循以下两个标准:
- 通用十进制算术规范()
- 独立于基数的浮点运算( IEEE 854-1987
它们是在软件中模拟的,而不是在硬件中模拟的,这使得这种数据类型在时间和空间上比float效率低得多。另一方面,它可以用任意和有限精度表示数字,您可以自由调整。请注意,如果算术运算超过最大小数位数,您仍可能面临舍入误差。
然而,今天由固定精度提供的安全缓冲明天可能会变得不足。考虑恶性通货膨胀或处理汇率差异巨大的多种货币,如比特币(0.000029 BTC)和伊朗里亚尔(42,105.00 IRR)。如果你想要无限的精度,那么使用Fraction。
无限精度有理数:Fraction
Fraction和Decimal类型有一些相似之处。它们解决了二进制表示错误,它们在软件中实现,你可以在货币应用中使用它们。尽管如此,分数的主要用途是表示 T2 有理数 T3,所以比起小数来说,它们可能不太方便存储金钱。
**注意:**虽然Fraction数据类型是用纯 Python 实现的,但大多数 Python 发行版都为Decimal类型提供了一个编译好的动态链接库。如果它对您的平台不可用,那么 Python 也将退回到纯 Python 实现。然而,即使是编译版也不会像float那样充分利用硬件。
使用Fraction比Decimal有两个好处。第一个是无限精度,只受可用内存的限制。这使您可以用无终止和循环的十进制展开来表示有理数,而不会丢失任何信息:
>>> from fractions import Fraction
>>> one_third = Fraction(1, 3)
>>> print(3 * one_third)
1
>>> from decimal import Decimal
>>> one_third = 1 / Decimal(3)
>>> print(3 * one_third)
0.9999999999999999999999999999
用 1/3 乘以 3 得到的分数正好是 1,但结果在十进制中是四舍五入的。它有 28 个小数位,这是Decimal类型的默认精度。
再来看看分数的另一个好处,这是你之前已经开始学习的。与Decimal不同,分数可以与二进制浮点数交互操作:
>>> Fraction("0.75") - 0.25
0.5
>>> Decimal("0.75") - 0.25
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'decimal.Decimal' and 'float'
当您将分数与浮点数混合时,结果会得到一个浮点数。另一方面,如果您试图用一个Decimal数据类型混合分数,那么您将遇到一个TypeError。
正在研究 Python 片段
在这一节中,您将浏览一些在 Python 中使用Fraction数据类型的有趣且实用的例子。你可能会惊讶于分数是多么的方便,同时它们又是多么的被低估。准备好开始吧!
近似无理数
无理数在数学中起着重要的作用,这就是为什么它们出现在算术、微积分和几何等许多子领域的原因。一些你可能听说过的最著名的例子是:
- 二的平方根(√2)
- 阿基米德常数(π)
- 黄金比例(φ)
- 欧拉数( e
在数学史上,圆周率(π)一直特别有趣,这导致许多人试图找到它的精确近似值。
虽然古代哲学家不得不竭尽全力,今天你可以用 Python 找到相当不错的圆周率的估计,使用蒙特卡罗方法,比如布冯针或类似的。然而,在大多数日常问题中,只有一个方便的分数形式的粗略近似值就足够了。以下是确定两个整数的商的方法,这两个整数逐渐逼近无理数:
from fractions import Fraction
from itertools import count
def approximate(number):
history = set()
for max_denominator in count(1):
fraction = Fraction(number).limit_denominator(max_denominator)
if fraction not in history:
history.add(fraction)
yield fraction
该函数接受一个无理数,将其转换为一个分数,并找到一个小数位数较少的不同分数。 Python 集合通过保留历史数据来防止产生重复值,而 itertools 模块的count()迭代器计数到无穷大。
现在,您可以使用此函数来查找圆周率的前十个分数近似值:
>>> from itertools import islice
>>> import math
>>> for fraction in islice(approximate(math.pi), 10):
... print(f"{str(fraction):>7}", "→", float(fraction))
...
3 → 3.0
13/4 → 3.25
16/5 → 3.2
19/6 → 3.1666666666666665
22/7 → 3.142857142857143
179/57 → 3.1403508771929824
201/64 → 3.140625
223/71 → 3.140845070422535
245/78 → 3.141025641025641
267/85 → 3.1411764705882352
不错!有理数 22/7 已经很接近了,这表明圆周率可以很早就被逼近,而且毕竟不是特别无理。islice()迭代器在收到请求的十个值后停止无限迭代。继续玩这个例子,增加结果的数量或者寻找其他无理数的近似值。
获取显示器的宽高比
图像或显示器的纵横比是其宽度与高度的商,方便地表示比例。它通常用于电影和数字媒体,而电影导演喜欢利用纵横比作为艺术手段。举例来说,如果你一直在寻找一部新的智能手机,那么说明书可能会提到屏幕比例,比如 16:9。
您可以通过使用官方 Python 发行版附带的 Tkinter 来测量电脑显示器的宽度和高度,从而找出显示器的长宽比:
>>> import tkinter as tk
>>> window = tk.Tk()
>>> window.winfo_screenwidth()
2560
>>> window.winfo_screenheight()
1440
请注意,如果您连接了多台显示器,则此代码可能不会按预期运行。
计算纵横比就是创建一个会自我缩小的分数:
>>> from fractions import Fraction
>>> Fraction(2560, 1440)
Fraction(16, 9)
给你。显示器的分辨率为 16:9。但是,如果您使用的是屏幕尺寸较小的笔记本电脑,那么您的分数一开始可能无法计算出来,您需要相应地限制其分母:
>>> Fraction(1360, 768)
Fraction(85, 48)
>>> Fraction(1360, 768).limit_denominator(10)
Fraction(16, 9)
请记住,如果您正在处理移动设备的垂直屏幕,您应该交换尺寸,以便第一个尺寸大于下面的尺寸。您可以将此逻辑封装在一个可重用的函数中:
from fractions import Fraction
def aspect_ratio(width, height, max_denominator=10):
if height > width:
width, height = height, width
ratio = Fraction(width, height).limit_denominator(max_denominator)
return f"{ratio.numerator}:{ratio.denominator}"
这将确保一致的纵横比,而不管参数的顺序如何:
>>> aspect_ratio(1080, 2400)
'20:9'
>>> aspect_ratio(2400, 1080)
'20:9'
无论你看的是水平屏幕还是垂直屏幕,长宽比都是一样的。
到目前为止,宽度和高度都是整数,但是分数值呢?例如,一些佳能相机有一个 APS-C 作物传感器,其尺寸为 22.8 毫米乘 14.8 毫米。分数在浮点数和十进制数中难以表达,但您可以将其转换为有理近似值:
>>> aspect_ratio(22.2, 14.8)
Traceback (most recent call last):
...
raise TypeError("both arguments should be "
TypeError: both arguments should be Rational instances
>>> aspect_ratio(Fraction("22.2"), Fraction("14.8"))
'3:2'
在这种情况下,纵横比恰好为 1.5 或 3:2,但许多相机的传感器宽度略长,因此纵横比为 1.555…或 14:9。当你做数学计算时,你会发现它是宽格式(16:9) 和四三分制(4:3) 的算术平均值,这是一种妥协,让你在这两种流行格式下都能很好地显示图片。
计算照片的曝光值
在数字图像中嵌入元数据的标准格式 Exif(可交换图像文件格式),使用比率来存储多个值。一些最重要的比率描述了照片的曝光度:
- 光圈值
- 曝光时间
- 曝光偏差
- 焦距
- 光圈挡
- 快门速度
快门速度在口语中与曝光时间同义,但它是使用基于对数标度的 APEX 系统以分数形式存储在元数据中的。这意味着照相机会取你曝光时间的倒数,然后计算它的以 2 为底的对数。因此,例如,1/200 秒的曝光时间将作为 7643856/1000000 写入文件。你可以这样计算:
>>> from fractions import Fraction
>>> exposure_time = Fraction(1, 200)
>>> from math import log2, trunc
>>> precision = 1_000_000
>>> trunc(log2(Fraction(1, exposure_time)) * precision)
7643856
如果您在没有任何外部库的帮助下手动读取这些元数据,您可以使用 Python 片段来恢复原始曝光时间:
>>> shutter_speed = Fraction(7643856, 1_000_000)
>>> Fraction(1, round(2 ** shutter_speed))
Fraction(1, 200)
当你组合拼图的各个部分时——即光圈、快门速度和 ISO 速度——你将能够计算出单个曝光值(EV) ,它描述了捕捉到的光的平均量。然后,您可以使用它来获得拍摄场景中亮度的对数平均值,这在后期处理和应用特殊效果时非常有用。
计算曝光值的公式如下:
from math import log2
def exposure_value(f_stop, exposure_time, iso_speed):
return log2(f_stop ** 2 / exposure_time) - log2(iso_speed / 100)
请记住,它没有考虑其他因素,如曝光偏差或闪光灯,你的相机可能适用。无论如何,用一些样本值试一试:
>>> exposure_value(
... f_stop=Fraction(28, 5),
... exposure_time=Fraction(1, 750),
... iso_speed=400
... )
12.521600439723727
>>> exposure_value(f_stop=5.6, exposure_time=1/750, iso_speed=400)
12.521600439723727
您可以使用分数或其他数值类型作为输入值。这种情况下曝光值在+13 左右,比较亮。这张照片是在一个阳光明媚的日子拍摄的,尽管是在阴凉处。
解决变革问题
你可以用分数来解决计算机科学经典的改变问题,你可能会在求职面试中遇到。它要求获得一定金额的最少硬币数。例如,如果您考虑最受欢迎的美元硬币,那么您可以将 2.67 美元表示为 10 个 25 美分硬币(10 × $0.25)、1 个 1 角硬币(1 × $0.10)、1 个 5 分硬币(1 × $0.05)和 2 个 1 分硬币(2 × $0.01)。
分数可以是表示钱包或收银机中硬币的方便工具。你可以用以下方式定义美元硬币:
from fractions import Fraction
penny = Fraction(1, 100)
nickel = Fraction(5, 100)
dime = Fraction(10, 100)
quarter = Fraction(25, 100)
其中一些会自动缩减,但没关系,因为您将使用十进制表示法对它们进行格式化。你可以用这些硬币来计算你钱包的总价值:
>>> wallet = [8 * quarter, 5 * dime, 3 * nickel, 2 * penny]
>>> print(f"${float(sum(wallet)):.2f}")
$2.67
你的钱包总共是 2.67 美元,但是里面有多达 18 个硬币。同样数量的硬币可以用更少的硬币。解决改变问题的一种方法是使用贪婪算法,比如这个:
def change(amount, coins):
while amount > 0:
for coin in sorted(coins, reverse=True):
if coin <= amount:
amount -= coin
yield coin
break
else:
raise Exception("There's no solution")
该算法试图找到一个最高面额的硬币,它不大于剩余金额。虽然实现起来相对简单,但它可能无法在所有硬币系统中给出最佳解决方案。这里有一个美元硬币的例子:
>>> from collections import Counter
>>> amount = Fraction("2.67")
>>> usd = [penny, nickel, dime, quarter]
>>> for coin, count in Counter(change(amount, usd)).items():
... print(f"{count:>2} × ${float(coin):.2f}")
...
10 × $0.25
1 × $0.10
1 × $0.05
2 × $0.01
使用有理数来寻找解决方案是强制性的,因为浮点值不能解决问题。由于change()是一个生成可能重复的硬币的函数,你可以使用 Counter 将它们分组。
你可以通过问一个稍微不同的问题来修改这个问题。例如,给定总价格、收银机中可用的顾客硬币和卖家硬币,最佳硬币组合是什么?
产生和扩展连分数
在本教程开始时,您已经了解到无理数可以表示为无限连分数。这样的分数需要无限量的内存才能存在,但是你可以选择什么时候停止产生它们的系数来得到一个合理的近似值。
下面的发生器函数将以惰性评估的方式不断产生给定数字的系数:
1def continued_fraction(number):
2 while True:
3 yield (whole_part := int(number))
4 fractional_part = number - whole_part
5 try:
6 number = 1 / fractional_part
7 except ZeroDivisionError:
8 break
该函数截断数字,并将剩余的分数表示为作为输入反馈的倒数。为了消除代码重复,它在第 3 行使用了一个赋值表达式,通常称为 Python 3.8 中引入的 walrus 操作符。
有趣的是,您也可以为有理数创建连分数:
>>> list(continued_fraction(42))
[42]
>>> from fractions import Fraction
>>> list(continued_fraction(Fraction(3, 4)))
[0, 1, 3]
数字 42 只有一个系数,没有小数部分。相反,3/4 没有完整的部分和一个由 1/1+1/3 组成的连分数:

像往常一样,您应该注意当您切换到float时可能会出现的浮点表示错误:
>>> list(continued_fraction(0.75))
[0, 1, 3, 1125899906842624]
虽然可以用二进制精确地表示 0.75,但它的倒数有无限的十进制扩展,尽管它是一个有理数。当你研究其余的系数时,你最终会在分母中发现这个巨大的数值,代表一个可以忽略不计的小值。这是你的近似误差。
您可以通过用 Python 分数替换实数来消除此错误:
from fractions import Fraction
def continued_fraction(number):
while True:
yield (whole_part := int(number))
fractional_part = Fraction(number) - whole_part try:
number = Fraction(1, fractional_part) except ZeroDivisionError:
break
这个小小的改变让你能够可靠地生成对应于十进制数的连分式的系数。否则,即使终止十进制展开,也可能陷入无限循环。
好吧,让我们做一些更有趣的事情,生成无理数的系数,它们的十进制展开在第五十个小数位被截断。为了精确起见,将它们定义为Decimal实例:
>>> from decimal import Decimal
>>> pi = Decimal("3.14159265358979323846264338327950288419716939937510")
>>> sqrt2 = Decimal("1.41421356237309504880168872420969807856967187537694")
>>> phi = Decimal("1.61803398874989484820458683436563811772030917980576")
现在,您可以使用熟悉的islice()迭代器检查连分数的前几个系数:
>>> from itertools import islice
>>> numbers = {
... " π": pi,
... "√2": sqrt2,
... " φ": phi
... }
>>> for label, number in numbers.items():
... print(label, list(islice(continued_fraction(number), 20)))
...
π [3, 7, 15, 1, 292, 1, 1, 1, 2, 1, 3, 1, 14, 2, 1, 1, 2, 2, 2, 2]
√2 [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
φ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
圆周率的前四个系数给出了一个令人惊讶的好的近似值,随后是一个无关紧要的余数。然而,其他两个常数的连分数看起来非常奇怪。他们一遍又一遍地重复同样的数字,直到无穷。知道了这一点,您可以通过将这些系数展开成十进制形式来近似计算它们:
def expand(coefficients):
if len(coefficients) > 1:
return coefficients[0] + Fraction(1, expand(coefficients[1:]))
else:
return Fraction(coefficients[0])
递归地定义这个函数是很方便的,这样它可以在更小的系数列表中调用自己。在基本情况下,只有一个整数,这是可能的最粗略的近似值。如果有两个或更多,则结果是第一个系数之和,后面是其余展开系数的倒数。
您可以通过调用它们相反的返回值来验证这两个函数是否按预期工作:
>>> list(continued_fraction(3.14159))
[3, 7, 15, 1, 25, 1, 7, 4, 851921, 1, 1, 2, 880, 1, 2]
>>> float(expand([3, 7, 15, 1, 25, 1, 7, 4, 851921, 1, 1, 2, 880, 1, 2]))
3.14159
完美!如果你把continued_fraction()的结果输入到expand()中,那么你就回到了开始时的初始值。不过,在某些情况下,为了更精确,您可能需要将扩展分数转换为Decimal类型,而不是float。
结论
在阅读本教程之前,你可能从未想过计算机是如何存储分数**的。毕竟,也许你的老朋友看起来可以很好地处理它们。然而,历史已经表明,这种误解可能最终导致灾难性的失败可能会花大钱。*
*使用 Python 的Fraction是避免这种灾难的一种方法。您已经看到了分数记数法的优缺点、它的实际应用以及在 Python 中使用它的方法。现在,您可以明智地选择哪种数值类型最适合您的用例。
在本教程中,您学习了如何:
- 在十进制和小数记数法之间转换
- 执行有理数运算
- 近似无理数
- 用无限精度精确表示分数
- 知道什么时候选择
Fraction而不是Decimal或float************


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









