







原文:RealPython
Python 的集合:专门化数据类型的自助餐
Python 的 collections 模块提供了一组丰富的专用容器数据类型,这些数据类型经过精心设计,以 python 化且高效的方式处理特定的编程问题。该模块还提供了包装类,使得创建行为类似于内置类型dict、list和str的定制类更加安全。
学习collections中的数据类型和类将允许你用一套有价值的可靠而有效的工具来扩充你的编程工具包。
在本教程中,您将学习如何:
- 用
namedtuple编写可读和显式代码 - 使用
deque构建高效队列和堆栈 - 用
Counter快速计数物体 - 用
defaultdict处理缺失的字典键 - 用
OrderedDict保证插入顺序 - 使用
ChainMap将多个字典作为一个单元进行管理
为了更好地理解collections中的数据类型和类,你应该知道使用 Python 内置数据类型的基础知识,比如列表、元组和字典。另外,文章的最后一部分需要一些关于 Python 中面向对象编程的基础知识。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 的collections 入门
回到 Python 2.4 , Raymond Hettinger 为标准库贡献了一个名为 collections 的新模块。目标是提供各种专门的集合数据类型来解决特定的编程问题。
当时,collections只包含一个数据结构, deque ,专门设计为一个双端队列,支持序列两端高效的追加和弹出操作。从这一点开始,标准库中的几个模块利用了deque来提高它们的类和结构的性能。一些突出的例子是 queue 和 threading 。
随着时间的推移,一些专门的容器数据类型填充了该模块:
| 数据类型 | Python 版本 | 描述 |
|---|---|---|
T2deque | 2.4 | 一个类似序列的集合,支持从序列的任意一端有效地添加和移除项 |
T2defaultdict | 2.5 | 字典子类,用于为缺失的键构造默认值,并自动将它们添加到字典中 |
T2namedtuple() | 2.6 | 一个用于创建tuple子类的工厂函数,提供命名字段,允许通过名称访问项目,同时保持通过索引访问项目的能力 |
T2OrderedDict | 2.7 , 3.1 | 字典子类,根据插入键的时间保持键-值对的顺序 |
T2Counter | 2.7 , 3.1 | 字典子类,支持对序列或可重复项中的唯一项进行方便的计数 |
T2ChainMap | 3.3 | 一个类似字典的类,允许将多个映射作为单个字典对象处理 |
除了这些专门的数据类型,collections还提供了三个基类来帮助创建定制列表、字典和字符串:
| 班级 | 描述 |
|---|---|
T2UserDict | 围绕字典对象的包装类,便于子类化dict |
T2UserList | 围绕列表对象的包装类,便于子类化list |
T2UserString | 一个围绕字符串对象的包装类,便于子类化string |
对这些包装类的需求部分被相应的标准内置数据类型的子类化能力所掩盖。但是,有时使用这些类比使用标准数据类型更安全,也更不容易出错。
有了对collections的简要介绍以及本模块中的数据结构和类可以解决的具体用例,是时候更仔细地研究它们了。在此之前,需要指出的是,本教程整体上是对collections的介绍。在接下来的大部分章节中,您会发现一个蓝色的警告框,它会引导您找到关于这个类或函数的专门文章。
提高代码可读性:namedtuple()
Python 的namedtuple()是一个工厂函数,允许你用命名字段创建tuple子类。这些字段使用点符号让您直接访问给定命名元组中的值,就像在obj.attr中一样。
之所以需要这个特性,是因为使用索引来访问常规元组中的值很烦人,难以阅读,而且容易出错。如果您正在处理的元组有几个项,并且是在远离您使用它的地方构造的,这一点尤其正确。
**注:**查看使用 namedtuple 编写 Python 和 Clean 代码,深入了解如何在 Python 中使用namedtuple。
在 Python 2.6 中,开发人员可以用点符号访问带有命名字段的 tuple 子类,这似乎是一个理想的特性。这就是namedtuple()的由来。如果与常规元组相比,用这个函数构建的元组子类在代码可读性方面是一大优势。
为了正确看待代码可读性问题,考虑一下 divmod() 。这个内置函数接受两个(非复杂的)数字,并返回一个元组,该元组具有输入值的整数除法的商和余数:
>>> divmod(12, 5)
(2, 2)
它工作得很好。然而,这个结果是否具有可读性?你能说出输出中每个数字的含义吗?幸运的是,Python 提供了一种改进方法。您可以使用namedtuple编写带有显式结果的自定义版本的divmod():
>>> from collections import namedtuple
>>> def custom_divmod(x, y):
... DivMod = namedtuple("DivMod", "quotient remainder")
... return DivMod(*divmod(x, y))
...
>>> result = custom_divmod(12, 5)
>>> result
DivMod(quotient=2, remainder=2)
>>> result.quotient
2
>>> result.remainder
2
现在你知道结果中每个值的含义了。您还可以使用点符号和描述性字段名称来访问每个独立的值。
要使用namedtuple()创建新的 tuple 子类,需要两个必需的参数:
typename是您正在创建的类的名称。它必须是一个带有有效 Python 标识符的字符串。field_names是字段名列表,您将使用它来访问结果元组中的项目。它可以是:- 一个可迭代的字符串,比如
["field1", "field2", ..., "fieldN"] - 由空格分隔的字段名组成的字符串,例如
"field1 field2 ... fieldN" - 用逗号分隔字段名的字符串,如
"field1, field2, ..., fieldN"
- 一个可迭代的字符串,比如
例如,以下是使用namedtuple()创建具有两个坐标(x和y)的样本 2D Point的不同方法:
>>> from collections import namedtuple
>>> # Use a list of strings as field names
>>> Point = namedtuple("Point", ["x", "y"])
>>> point = Point(2, 4)
>>> point
Point(x=2, y=4)
>>> # Access the coordinates
>>> point.x
2
>>> point.y
4
>>> point[0]
2
>>> # Use a generator expression as field names
>>> Point = namedtuple("Point", (field for field in "xy"))
>>> Point(2, 4)
Point(x=2, y=4)
>>> # Use a string with comma-separated field names
>>> Point = namedtuple("Point", "x, y")
>>> Point(2, 4)
Point(x=2, y=4)
>>> # Use a string with space-separated field names
>>> Point = namedtuple("Point", "x y")
>>> Point(2, 4)
Point(x=2, y=4)
在这些例子中,首先使用字段名的list创建Point。然后你实例化Point来制作一个point对象。请注意,您可以通过字段名和索引来访问x和y。
剩下的例子展示了如何用一串逗号分隔的字段名、生成器表达式和一串空格分隔的字段名创建一个等价的命名元组。
命名元组还提供了一系列很酷的特性,允许您定义字段的默认值,从给定的命名元组创建字典,替换给定字段的值,等等:
>>> from collections import namedtuple
>>> # Define default values for fields
>>> Person = namedtuple("Person", "name job", defaults=["Python Developer"])
>>> person = Person("Jane")
>>> person
Person(name='Jane', job='Python Developer')
>>> # Create a dictionary from a named tuple
>>> person._asdict()
{'name': 'Jane', 'job': 'Python Developer'}
>>> # Replace the value of a field
>>> person = person._replace(job="Web Developer")
>>> person
Person(name='Jane', job='Web Developer')
这里,首先使用namedtuple()创建一个Person类。这一次,您使用一个名为defaults的可选参数,它接受元组字段的一系列默认值。注意namedtuple()将默认值应用于最右边的字段。
在第二个例子中,您使用 ._asdict() 从现有的命名元组创建一个字典。该方法返回一个使用字段名作为键的新字典。
最后,你用 ._replace() 替换job的原始值。这个方法不更新 tuple 的位置,而是返回一个新命名的 tuple,其新值存储在相应的字段中。你知道为什么._replace()返回一个新的命名元组吗?
构建高效的队列和堆栈:deque
Python 的 deque 是collections中第一个数据结构。这种类似序列的数据类型是对堆栈和队列的概括,旨在支持数据结构两端的高效内存和快速追加和弹出操作。
注:字deque读作“deck”,代表ddouble-eenddqueUE。
在 Python 中,在list对象的开头或左侧进行追加和弹出操作效率很低,时间复杂度O(n)。如果处理大型列表,这些操作的开销会特别大,因为 Python 必须将所有项目移到右边,以便在列表的开头插入新项目。
另一方面,列表右侧的 append 和 pop 操作通常是高效的( O (1)),除非 Python 需要重新分配内存来增加底层列表以接受新项。
Python 的deque就是为了克服这个问题而产生的。在一个deque对象两侧的追加和弹出操作是稳定的和同样有效的,因为 deques 被实现为一个双向链表。这就是为什么 deques 对于创建堆栈和队列特别有用。
以一个队列为例。它以先进/先出 ( 先进先出)的方式管理项目。它就像一个管道,你在管道的一端推入新的项目,从另一端弹出旧的项目。将一个项目添加到队列的末尾被称为入队操作。从队列的前面或开始处移除一个项目称为出列。
**注:**查看 Python 的 dequee:implementing Efficient queue and Stacks以深入探究如何在 Python 代码中使用deque。
现在假设你正在为一个排队买电影票的人建模。你可以用一个deque来做。每次有新人来,你就让他们排队。当排在队伍前面的人拿到票时,你让他们出队。
下面是如何使用一个deque对象来模拟这个过程:
>>> from collections import deque
>>> ticket_queue = deque()
>>> ticket_queue
deque([])
>>> # People arrive to the queue
>>> ticket_queue.append("Jane")
>>> ticket_queue.append("John")
>>> ticket_queue.append("Linda")
>>> ticket_queue
deque(['Jane', 'John', 'Linda'])
>>> # People bought their tickets
>>> ticket_queue.popleft()
'Jane'
>>> ticket_queue.popleft()
'John'
>>> ticket_queue.popleft()
'Linda'
>>> # No people on the queue
>>> ticket_queue.popleft()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: pop from an empty deque
在这里,首先创建一个空的deque对象来表示人的队列。要让一个人入队,可以使用 .append() ,它将项目添加到队列的右端。要让一个人出列,可以使用 .popleft() ,它移除并返回队列左端的项目。
**注意:**在 Python 标准库中,你会找到 queue 。该模块实现了多生产者、多消费者队列,有助于在多线程之间安全地交换信息。
deque初始化器有两个可选参数:
iterable持有一个作为初始化器的 iterable。maxlen保存一个指定deque最大长度的整数。
如果你不提供一个iterable,那么你会得到一个空的队列。如果您为 maxlen 提供一个值,那么您的 deque 将只存储最多maxlen个项目。
拥有一个maxlen是一个方便的特性。例如,假设您需要在一个应用程序中实现一个最近文件的列表。在这种情况下,您可以执行以下操作:
>>> from collections import deque
>>> recent_files = deque(["core.py", "README.md", "__init__.py"], maxlen=3)
>>> recent_files.appendleft("database.py")
>>> recent_files
deque(['database.py', 'core.py', 'README.md'], maxlen=3)
>>> recent_files.appendleft("requirements.txt")
>>> recent_files
deque(['requirements.txt', 'database.py', 'core.py'], maxlen=3)
一旦 dequeue 达到其最大大小(本例中为三个文件),在 dequeue 的一端添加新文件会自动丢弃另一端的文件。如果您不为maxlen提供一个值,那么 deque 可以增长到任意数量的项目。
到目前为止,您已经学习了 deques 的基本知识,包括如何创建 deques 以及如何从给定的 deques 的两端追加和弹出项目。Deques 通过类似列表的界面提供了一些额外的特性。以下是其中的一些:
>>> from collections import deque
>>> # Use different iterables to create deques
>>> deque((1, 2, 3, 4))
deque([1, 2, 3, 4])
>>> deque([1, 2, 3, 4])
deque([1, 2, 3, 4])
>>> deque("abcd")
deque(['a', 'b', 'c', 'd'])
>>> # Unlike lists, deque doesn't support .pop() with arbitrary indices
>>> deque("abcd").pop(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: pop() takes no arguments (1 given)
>>> # Extend an existing deque
>>> numbers = deque([1, 2])
>>> numbers.extend([3, 4, 5])
>>> numbers
deque([1, 2, 3, 4, 5])
>>> numbers.extendleft([-1, -2, -3, -4, -5])
>>> numbers
deque([-5, -4, -3, -2, -1, 1, 2, 3, 4, 5])
>>> # Insert an item at a given position
>>> numbers.insert(5, 0)
>>> numbers
deque([-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5])
在这些例子中,您首先使用不同类型的 iterables 创建 deques 来初始化它们。deque和list的一个区别是deque.pop()不支持弹出给定索引处的项目。
注意,deque为.append()、、.pop()、、.extend()、提供了姊妹方法,并带有后缀left来表示它们在底层 deque 的左端执行相应的操作。
Deques 也支持序列操作:
| 方法 | 描述 |
|---|---|
T2.clear() | 从队列中删除所有元素 |
T2.copy() | 创建一个 deque 的浅层副本 |
T2.count(x) | 计算等于x的双队列元素的数量 |
T2.remove(value) | 删除第一次出现的value |
deques 的另一个有趣的特性是能够使用.rotate()旋转它们的元素:
>>> from collections import deque
>>> ordinals = deque(["first", "second", "third"])
>>> ordinals.rotate()
>>> ordinals
deque(['third', 'first', 'second'])
>>> ordinals.rotate(2)
>>> ordinals
deque(['first', 'second', 'third'])
>>> ordinals.rotate(-2)
>>> ordinals
deque(['third', 'first', 'second'])
>>> ordinals.rotate(-1)
>>> ordinals
deque(['first', 'second', 'third'])
该方法向右旋转 deque n步骤。n的默认值为1。如果给n提供一个负值,那么旋转向左。
最后,您可以使用索引来访问 dequee 中的元素,但是您不能对 dequee 进行切片:
>>> from collections import deque
>>> ordinals = deque(["first", "second", "third"])
>>> ordinals[1]
'second'
>>> ordinals[0:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence index must be integer, not 'slice'
Deques 支持索引,但有趣的是,它们不支持切片。当您试图从现有的队列中检索一个切片时,您会得到一个TypeError。这是因为在链表上执行切片操作是低效的,所以该操作不可用。
处理丢失的按键:defaultdict
当你在 Python 中使用字典时,你会面临的一个常见问题是如何处理丢失的键。如果您试图访问一个给定字典中不存在的键,那么您会得到一个KeyError:
>>> favorites = {"pet": "dog", "color": "blue", "language": "Python"}
>>> favorites["fruit"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'fruit'
有几种方法可以解决这个问题。比如可以用 .setdefault() 。该方法将一个键作为参数。如果字典中存在该键,那么它将返回相应的值。否则,该方法插入该键,为其赋一个默认值,并返回该值:
>>> favorites = {"pet": "dog", "color": "blue", "language": "Python"}
>>> favorites.setdefault("fruit", "apple")
'apple'
>>> favorites
{'pet': 'dog', 'color': 'blue', 'language': 'Python', 'fruit': 'apple'}
>>> favorites.setdefault("pet", "cat")
'dog'
>>> favorites
{'pet': 'dog', 'color': 'blue', 'language': 'Python', 'fruit': 'apple'}
在这个例子中,您使用.setdefault()为fruit生成一个默认值。由于这个键在favorites中不存在,.setdefault()创建了它并赋予它apple的值。如果你用一个存在的键调用.setdefault(),那么这个调用不会影响字典,你的键将保持原始值而不是默认值。
如果给定的键丢失,您也可以使用.get()返回一个合适的默认值:
>>> favorites = {"pet": "dog", "color": "blue", "language": "Python"}
>>> favorites.get("fruit", "apple")
'apple'
>>> favorites
{'pet': 'dog', 'color': 'blue', 'language': 'Python'}
这里,.get()返回apple,因为底层字典中缺少该键。然而,.get()并没有为你创建新的密匙。
由于处理字典中丢失的键是一种常见的需求,Python 的collections也为此提供了一个工具。defaultdict类型是dict的子类,旨在帮助你解决丢失的键。
**注意:**查看使用 Python defaultdict 类型处理丢失的键,深入了解如何使用 Python 的defaultdict。
defaultdict的构造函数将一个函数对象作为它的第一个参数。当您访问一个不存在的键时,defaultdict自动调用该函数,不带参数,为手边的键创建一个合适的默认值。
为了提供其功能,defaultdict将输入函数存储在 .default_factory 中,然后覆盖 .__missing__() 以在您访问任何丢失的键时自动调用该函数并生成默认值。
你可以使用任何可调用来初始化你的defaultdict对象。例如,使用 int() 您可以创建一个合适的计数器来计数不同的对象:
>>> from collections import defaultdict
>>> counter = defaultdict(int)
>>> counter
defaultdict(<class 'int'>, {})
>>> counter["dogs"]
0
>>> counter
defaultdict(<class 'int'>, {'dogs': 0})
>>> counter["dogs"] += 1
>>> counter["dogs"] += 1
>>> counter["dogs"] += 1
>>> counter["cats"] += 1
>>> counter["cats"] += 1
>>> counter
defaultdict(<class 'int'>, {'dogs': 3, 'cats': 2})
在本例中,您创建了一个空的defaultdict,将int()作为它的第一个参数。当你访问一个不存在的键时,字典自动调用int(),它返回0作为当前键的默认值。这种defaultdict对象在 Python 中计数时非常有用。
defaultdict的另一个常见用例是将事物分组。在这种情况下,方便的工厂函数是list():
>>> from collections import defaultdict
>>> pets = [
... ("dog", "Affenpinscher"),
... ("dog", "Terrier"),
... ("dog", "Boxer"),
... ("cat", "Abyssinian"),
... ("cat", "Birman"),
... ]
>>> group_pets = defaultdict(list)
>>> for pet, breed in pets:
... group_pets[pet].append(breed)
...
>>> for pet, breeds in group_pets.items():
... print(pet, "->", breeds)
...
dog -> ['Affenpinscher', 'Terrier', 'Boxer']
cat -> ['Abyssinian', 'Birman']
在这个例子中,您有关于宠物及其品种的原始数据,您需要按照宠物对它们进行分组。为此,在创建defaultdict实例时,使用list()作为.default_factory。这使您的字典能够自动创建一个空列表([])作为您访问的每个缺失键的默认值。然后你用这个列表来存储你的宠物的品种。
最后,你应该注意到由于defaultdict是dict的子类,它提供了相同的接口。这意味着你可以像使用普通字典一样使用你的defaultdict对象。
保持字典有序:OrderedDict
有时,您需要字典来记住键值对的插入顺序。多年来,Python 的常规字典是无序的数据结构。所以,回到 2008 年, PEP 372 引入了给collections添加一个新字典类的想法。
新的类会根据钥匙插入的时间记住项目的顺序。这就是 OrderedDict 的由来。
OrderedDict在 Python 3.1 中引入。其应用编程接口(API)与dict基本相同。然而,OrderedDict按照键被第一次插入字典的顺序遍历键和值。如果为现有键分配一个新值,则键-值对的顺序保持不变。如果一个条目被删除并重新插入,那么它将被移动到字典的末尾。
**注:**查看Python 中的 OrderedDict vs dict:工作的正确工具以深入了解 Python 的OrderedDict以及为什么应该考虑使用它。
有几种方法可以创建OrderedDict对象。它们中的大多数与你如何创建一个普通的字典是一样的。例如,您可以通过实例化不带参数的类来创建一个空的有序字典,然后根据需要插入键值对:
>>> from collections import OrderedDict
>>> life_stages = OrderedDict()
>>> life_stages["childhood"] = "0-9"
>>> life_stages["adolescence"] = "9-18"
>>> life_stages["adulthood"] = "18-65"
>>> life_stages["old"] = "+65"
>>> for stage, years in life_stages.items():
... print(stage, "->", years)
...
childhood -> 0-9
adolescence -> 9-18
adulthood -> 18-65
old -> +65
在这个例子中,您通过实例化不带参数的OrderedDict来创建一个空的有序字典。接下来,像处理常规字典一样,将键值对添加到字典中。
当您遍历字典、life_stages时,您将获得键-值对,其顺序与您将它们插入字典的顺序相同。保证物品的顺序是OrderedDict解决的主要问题。
Python 3.6 引入了一个的新实现dict 。这种实现提供了一个意想不到的新特性:现在普通字典按照它们第一次插入的顺序保存它们的条目。
最初,这个特性被认为是一个实现细节,文档建议不要依赖它。然而,自从 Python 3.7 ,特性正式成为语言规范的一部分。那么,用OrderedDict有什么意义呢?
OrderedDict的一些特性仍然让它很有价值:
- **意图传达:**有了
OrderedDict,你的代码会清楚的表明字典中条目的顺序很重要。你清楚地表达了你的代码需要或者依赖于底层字典中的条目顺序。 - **对条目顺序的控制:**使用
OrderedDict,您可以访问.move_to_end(),这是一种允许您操纵字典中条目顺序的方法。您还将拥有一个增强的.popitem()变体,允许从底层字典的任意一端移除条目。 - **相等性测试行为:**使用
OrderedDict,字典之间的相等性测试会考虑条目的顺序。因此,如果您有两个有序的字典,它们包含相同的条目组,但顺序不同,那么您的字典将被认为是不相等的。
使用OrderedDict : 向后兼容至少还有一个原因。在运行 than 3.6 之前版本的环境中,依靠常规的dict对象来保持项目的顺序会破坏您的代码。
好了,现在是时候看看OrderedDict的一些很酷的功能了:
>>> from collections import OrderedDict
>>> letters = OrderedDict(b=2, d=4, a=1, c=3)
>>> letters
OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3)])
>>> # Move b to the right end
>>> letters.move_to_end("b")
>>> letters
OrderedDict([('d', 4), ('a', 1), ('c', 3), ('b', 2)])
>>> # Move b to the left end
>>> letters.move_to_end("b", last=False)
>>> letters
OrderedDict([('b', 2), ('d', 4), ('a', 1), ('c', 3)])
>>> # Sort letters by key
>>> for key in sorted(letters):
... letters.move_to_end(key)
...
>>> letters
OrderedDict([('a', 1), ('b', 2), ('c', 3), ('d', 4)])
在这些例子中,您使用 .move_to_end() 来移动项目并重新排序letters。注意,.move_to_end()接受了一个名为last的可选参数,它允许您控制想要将条目移动到词典的哪一端。当您需要对词典中的条目进行排序或者需要以任何方式操纵它们的顺序时,这种方法非常方便。
OrderedDict和普通词典的另一个重要区别是它们如何比较相等性:
>>> from collections import OrderedDict
>>> # Regular dictionaries compare the content only
>>> letters_0 = dict(a=1, b=2, c=3, d=4)
>>> letters_1 = dict(b=2, a=1, d=4, c=3)
>>> letters_0 == letters_1
True
>>> # Ordered dictionaries compare content and order
>>> letters_0 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_1 = OrderedDict(b=2, a=1, d=4, c=3)
>>> letters_0 == letters_1
False
>>> letters_2 = OrderedDict(a=1, b=2, c=3, d=4)
>>> letters_0 == letters_2
True
这里,letters_1的项目顺序与letters_0不同。当你使用普通的字典时,这种差异并不重要,两种字典比较起来是一样的。另一方面,当你使用有序字典时,letters_0和letters_1并不相等。这是因为有序字典之间的相等测试考虑了内容以及条目的顺序。
一气呵成清点物体:Counter
对象计数是编程中常见的操作。假设你需要计算一个给定的条目在列表或 iterable 中出现了多少次。如果你的清单很短,那么计算清单上的项目会很简单快捷。如果你有一个很长的清单,那么计算清单会更有挑战性。
为了计数对象,你通常使用一个计数器,或者一个初始值为零的整数变量。然后递增计数器以反映给定对象出现的次数。
在 Python 中,你可以使用字典一次计算几个不同的对象。在这种情况下,键将存储单个对象,值将保存给定对象的重复次数,或对象的计数。
这里有一个例子,用一个普通的字典和一个 for循环来计算单词"mississippi"中的字母:
>>> word = "mississippi"
>>> counter = {}
>>> for letter in word:
... if letter not in counter:
... counter[letter] = 0
... counter[letter] += 1
...
>>> counter
{'m': 1, 'i': 4, 's': 4, 'p': 2}
循环遍历word中的字母。条件语句检查字母是否已经在字典中,并相应地将字母的计数初始化为零。最后一步是随着循环的进行增加字母的计数。
正如你已经知道的,defaultdict objects 在计数的时候很方便,因为你不需要检查键是否存在。字典保证任何丢失的键都有适当的默认值:
>>> from collections import defaultdict
>>> counter = defaultdict(int)
>>> for letter in "mississippi":
... counter[letter] += 1
...
>>> counter
defaultdict(<class 'int'>, {'m': 1, 'i': 4, 's': 4, 'p': 2})
在本例中,您创建了一个defaultdict对象,并使用int()对其进行初始化。使用int()作为工厂函数,底层默认字典会自动创建缺失的键,并方便地将其初始化为零。然后增加当前键的值来计算"mississippi"中字母的最终计数。
就像其他常见的编程问题一样,Python 也有一个处理计数问题的有效工具。在collections中,你会发现 Counter ,这是一个专门为计数对象设计的dict子类。
以下是使用Counter编写"mississippi"示例的方法:
>>> from collections import Counter
>>> Counter("mississippi")
Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
哇!真快!一行代码就完成了。在这个例子中,Counter遍历"mississippi",生成一个字典,将字母作为键,将它们的频率作为值。
**注:**查看 Python 的计数器:计算对象的 Python 方式深入了解Counter以及如何使用它高效地计算对象。
有几种不同的方法来实例化Counter。您可以使用列表、元组或任何具有重复对象的 iterables。唯一的限制是你的对象必须是可散列的 T4:
>>> from collections import Counter
>>> Counter([1, 1, 2, 3, 3, 3, 4])
Counter({3: 3, 1: 2, 2: 1, 4: 1})
>>> Counter(([1], [1]))
Traceback (most recent call last):
...
TypeError: unhashable type: 'list'
整数是可散列的,所以Counter可以正常工作。另一方面,列表是不可散列的,所以Counter以一个TypeError失败。
被哈希化意味着你的对象必须有一个哈希值,在它们的生命周期中不会改变。这是一个要求,因为这些对象将作为字典键工作。在 Python 中,不可变的对象也是可散列的。
注:Counter中的,经过高度优化的 C 函数提供计数功能。如果这个函数由于某种原因不可用,那么这个类使用一个等效的但是效率较低的 Python 函数。
由于Counter是dict的子类,所以它们的接口大多相同。但是,也有一些微妙的区别。第一个区别是Counter没有实现 .fromkeys() 。这避免了不一致,比如Counter.fromkeys("abbbc", 2),其中每个字母都有一个初始计数2,而不管它在输入 iterable 中的实际计数。
第二个区别是 .update() 不会用新的计数替换现有对象(键)的计数(值)。它将两个计数相加:
>>> from collections import Counter
>>> letters = Counter("mississippi")
>>> letters
Counter({'i': 4, 's': 4, 'p': 2, 'm': 1})
>>> # Update the counts of m and i
>>> letters.update(m=3, i=4)
>>> letters
Counter({'i': 8, 'm': 4, 's': 4, 'p': 2})
>>> # Add a new key-count pair
>>> letters.update({"a": 2})
>>> letters
Counter({'i': 8, 'm': 4, 's': 4, 'p': 2, 'a': 2})
>>> # Update with another counter
>>> letters.update(Counter(["s", "s", "p"]))
>>> letters
Counter({'i': 8, 's': 6, 'm': 4, 'p': 3, 'a': 2})
在这里,您更新了m和i的计数。现在这些字母保存了它们初始计数的总和加上你通过.update()传递给它们的值。如果您使用一个不存在于原始计数器中的键,那么.update()会用相应的值创建一个新的键。最后,.update()接受可重复项、映射、关键字参数以及其他计数器。
**注意:**因为Counter是dict的一个子类,所以对于您可以在计数器的键和值中存储的对象没有限制。键可以存储任何可散列的对象,而值可以存储任何对象。但是,为了在逻辑上作为计数器工作,这些值应该是表示计数的整数。
Counter和dict的另一个区别是,访问丢失的键会返回0,而不是引发KeyError:
>>> from collections import Counter
>>> letters = Counter("mississippi")
>>> letters["a"]
0
这种行为表明计数器中不存在的对象的计数为零。在这个例子中,字母"a"不在原始单词中,所以它的计数是0。
在 Python 中,Counter也可以用来模拟一个多重集或包。多重集类似于集,但是它们允许给定元素的多个实例。一个元素的实例数量被称为它的多重性。例如,您可以有一个类似{1,1,2,3,3,3,4,4}的多重集。
当您使用Counter来模拟多重集时,键代表元素,值代表它们各自的多重性:
>>> from collections import Counter
>>> multiset = Counter({1, 1, 2, 3, 3, 3, 4, 4})
>>> multiset
Counter({1: 1, 2: 1, 3: 1, 4: 1})
>>> multiset.keys() == {1, 2, 3, 4}
True
在这里,multiset的键相当于一个 Python 集合。这些值包含集合中每个元素的多重性。
Python’ Counter’提供了一些额外的特性,帮助您将它们作为多重集来使用。例如,您可以用元素及其多重性的映射来初始化您的计数器。您还可以对元素的多重性执行数学运算等等。
假设你在当地的宠物收容所工作。你有一定数量的宠物,你需要记录每天有多少宠物被收养,有多少宠物进出收容所。在这种情况下,可以使用Counter:
>>> from collections import Counter
>>> inventory = Counter(dogs=23, cats=14, pythons=7)
>>> adopted = Counter(dogs=2, cats=5, pythons=1)
>>> inventory.subtract(adopted)
>>> inventory
Counter({'dogs': 21, 'cats': 9, 'pythons': 6})
>>> new_pets = {"dogs": 4, "cats": 1}
>>> inventory.update(new_pets)
>>> inventory
Counter({'dogs': 25, 'cats': 10, 'pythons': 6})
>>> inventory = inventory - Counter(dogs=2, cats=3, pythons=1)
>>> inventory
Counter({'dogs': 23, 'cats': 7, 'pythons': 5})
>>> new_pets = {"dogs": 4, "pythons": 2}
>>> inventory += new_pets
>>> inventory
Counter({'dogs': 27, 'cats': 7, 'pythons': 7})
太棒了!现在你可以用Counter记录你的宠物了。请注意,您可以使用.subtract()和.update()来加减计数或重数。您也可以使用加法(+)和减法(-)运算符。
在 Python 中,您可以将Counter对象作为多重集来做更多的事情,所以请大胆尝试吧!
将字典链接在一起:ChainMap
Python 的ChainMap将多个字典和其他映射组合在一起,创建一个单一对象,其工作方式非常类似于常规字典。换句话说,它接受几个映射,并使它们在逻辑上表现为一个映射。
ChainMap对象是可更新的视图,这意味着任何链接映射的变化都会影响到整个ChainMap对象。这是因为ChainMap没有将输入映射合并在一起。它保留了一个映射列表,并在该列表的顶部重新实现了公共字典操作。例如,关键字查找会连续搜索映射列表,直到找到该关键字。
**注意:**查看 Python 的 ChainMap:有效管理多个上下文,深入了解如何在 Python 代码中使用ChainMap。
当你使用ChainMap对象时,你可以有几个字典,或者是唯一的或者是重复的键。
无论哪种情况,ChainMap都允许您将所有的字典视为一个字典。如果您的字典中有唯一的键,您可以像使用单个字典一样访问和更新这些键。
如果您的字典中有重复的键,除了将字典作为一个字典管理之外,您还可以利用内部映射列表来定义某种类型的访问优先级。由于这个特性,ChainMap对象非常适合处理多种上下文。
例如,假设您正在开发一个命令行界面(CLI) 应用程序。该应用程序允许用户使用代理服务连接到互联网。设置优先级包括:
- 命令行选项(
--proxy、-p) - 用户主目录中的本地配置文件
- 全局代理配置
如果用户在命令行提供代理,那么应用程序必须使用该代理。否则,应用程序应该使用下一个配置对象中提供的代理,依此类推。这是ChainMap最常见的用例之一。在这种情况下,您可以执行以下操作:
>>> from collections import ChainMap
>>> cmd_proxy = {} # The user doesn't provide a proxy
>>> local_proxy = {"proxy": "proxy.local.com"}
>>> global_proxy = {"proxy": "proxy.global.com"}
>>> config = ChainMap(cmd_proxy, local_proxy, global_proxy)
>>> config["proxy"]
'proxy.local.com'
ChainMap允许您为应用程序的代理配置定义适当的优先级。一个键查找搜索cmd_proxy,然后是local_proxy,最后是global_proxy,返回当前键的第一个实例。在这个例子中,用户没有在命令行提供代理,所以您的应用程序使用了local_proxy中的代理。
一般来说,ChainMap对象的行为类似于常规的dict对象。但是,它们还有一些附加功能。例如,它们有一个保存内部映射列表的 .maps 公共属性:
>>> from collections import ChainMap
>>> numbers = {"one": 1, "two": 2}
>>> letters = {"a": "A", "b": "B"}
>>> alpha_nums = ChainMap(numbers, letters)
>>> alpha_nums.maps
[{'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'}]
实例属性.maps允许您访问内部映射列表。该列表可更新。您可以手动添加和删除映射,遍历列表,等等。
另外,ChainMap提供了一个 .new_child() 方法和一个 .parents 属性:
>>> from collections import ChainMap
>>> dad = {"name": "John", "age": 35}
>>> mom = {"name": "Jane", "age": 31}
>>> family = ChainMap(mom, dad)
>>> family
ChainMap({'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35})
>>> son = {"name": "Mike", "age": 0}
>>> family = family.new_child(son)
>>> for person in family.maps:
... print(person)
...
{'name': 'Mike', 'age': 0}
{'name': 'Jane', 'age': 31}
{'name': 'John', 'age': 35}
>>> family.parents
ChainMap({'name': 'Jane', 'age': 31}, {'name': 'John', 'age': 35})
使用.new_child(),您创建一个新的ChainMap对象,包含一个新的地图(son),后跟当前实例中的所有地图。作为第一个参数传递的映射成为映射列表中的第一个映射。如果没有传递 map,那么这个方法使用一个空字典。
parents属性返回一个新的ChainMap对象,包含当前实例中除第一个以外的所有地图。当您需要在键查找中跳过第一个映射时,这很有用。
在ChainMap中要强调的最后一个特性是变异操作,比如更新键、添加新键、删除现有键、弹出键和清除字典,作用于内部映射列表中的第一个映射:
>>> from collections import ChainMap
>>> numbers = {"one": 1, "two": 2}
>>> letters = {"a": "A", "b": "B"}
>>> alpha_nums = ChainMap(numbers, letters)
>>> alpha_nums
ChainMap({'one': 1, 'two': 2}, {'a': 'A', 'b': 'B'})
>>> # Add a new key-value pair
>>> alpha_nums["c"] = "C"
>>> alpha_nums
ChainMap({'one': 1, 'two': 2, 'c': 'C'}, {'a': 'A', 'b': 'B'})
>>> # Pop a key that exists in the first dictionary
>>> alpha_nums.pop("two")
2
>>> alpha_nums
ChainMap({'one': 1, 'c': 'C'}, {'a': 'A', 'b': 'B'})
>>> # Delete keys that don't exist in the first dict but do in others
>>> del alpha_nums["a"]
Traceback (most recent call last):
...
KeyError: "Key not found in the first mapping: 'a'"
>>> # Clear the dictionary
>>> alpha_nums.clear()
>>> alpha_nums
ChainMap({}, {'a': 'A', 'b': 'B'})
这些例子表明对一个ChainMap对象的变异操作只影响内部列表中的第一个映射。当您使用ChainMap时,这是一个需要考虑的重要细节。
棘手的是,乍一看,在给定的ChainMap中,任何现有的键值对都有可能发生变异。但是,您只能改变第一个映射中的键-值对,除非您使用.maps来直接访问和改变列表中的其他映射。
自定义内置:UserString、UserList和UserDictT3
有时您需要定制内置类型,如字符串、列表和字典,以添加和修改某些行为。从 Python 2.2 开始,你可以通过直接子类化这些类型来实现。但是,这种方法可能会遇到一些问题,您马上就会看到。
Python 的collections提供了三个方便的包装类,模拟内置数据类型的行为:
UserStringUserListUserDict
通过常规和特殊方法的组合,您可以使用这些类来模拟和定制字符串、列表和字典的行为。
现在,开发人员经常问自己,当他们需要定制内置类型的行为时,是否有理由使用UserString、UserList和UserDict。答案是肯定的。
考虑到的开闭原则,内置类型被设计和实现。这意味着它们对扩展开放,但对修改关闭。允许修改这些类的核心特性可能会破坏它们的不变量。因此,Python 核心开发人员决定保护它们不被修改。
例如,假设您需要一个字典,当您插入键时,它会自动小写。您可以子类化dict并覆盖 .__setitem__() ,这样每当您插入一个键时,字典就会小写这个键名:
>>> class LowerDict(dict):
... def __setitem__(self, key, value):
... key = key.lower()
... super().__setitem__(key, value)
...
>>> ordinals = LowerDict({"FIRST": 1, "SECOND": 2})
>>> ordinals["THIRD"] = 3
>>> ordinals.update({"FOURTH": 4})
>>> ordinals
{'FIRST': 1, 'SECOND': 2, 'third': 3, 'FOURTH': 4}
>>> isinstance(ordinals, dict)
True
当您使用带有方括号([])的字典样式赋值来插入新键时,该字典可以正常工作。然而,当你将一个初始字典传递给类构造函数或者当你使用 .update() 时,它不起作用。这意味着您需要覆盖.__init__().update(),可能还有其他一些方法来让您的自定义词典正确工作。
现在看一下同样的字典,但是使用UserDict作为基类:
>>> from collections import UserDict
>>> class LowerDict(UserDict):
... def __setitem__(self, key, value):
... key = key.lower()
... super().__setitem__(key, value)
...
>>> ordinals = LowerDict({"FIRST": 1, "SECOND": 2})
>>> ordinals["THIRD"] = 3
>>> ordinals.update({"FOURTH": 4})
>>> ordinals
{'first': 1, 'second': 2, 'third': 3, 'fourth': 4}
>>> isinstance(ordinals, dict)
False
有用!您的自定义词典现在会在将所有新键插入词典之前将其转换为小写字母。注意,因为你不直接从dict继承,你的类不像上面的例子那样返回dict的实例。
UserDict在名为.data的实例属性中存储一个常规字典。然后,它围绕该字典实现它的所有方法。UserList和UserString工作方式相同,但是它们的.data属性分别拥有一个list和一个str对象。
如果您需要定制这些类中的任何一个,那么您只需要覆盖适当的方法并根据需要更改它们的功能。
一般来说,当您需要一个行为与底层包装内置类几乎相同的类,并且您想要定制其标准功能的某个部分时,您应该使用UserDict、UserList和UserString。
使用这些类而不是内置的等价类的另一个原因是访问底层的.data属性来直接操作它。
直接从内置类型继承的能力已经在很大程度上取代了UserDict、UserList和UserString的使用。然而,内置类型的内部实现使得在不重写大量代码的情况下很难安全地从它们继承。在大多数情况下,使用collections中合适的类更安全。这会让你避免一些问题和奇怪的行为。
结论
在 Python 的collections模块中,有几个专门的容器数据类型,可以用来处理常见的编程问题,比如计算对象数量、创建队列和堆栈、处理字典中丢失的键等等。
collections中的数据类型和类被设计成高效和 Pythonic 化的。它们对您的 Python 编程之旅非常有帮助,因此了解它们非常值得您花费时间和精力。
在本教程中,您学习了如何:
- 使用
namedtuple编写可读的和显式的代码 - 使用
deque构建高效队列和堆栈 - 使用
Counter有效地计数对象 - 用
defaultdict处理缺失的字典键 - 记住
OrderedDict键的插入顺序 - 用
ChainMap在单个视图中链接多个字典
您还了解了三个方便的包装器类:UserDict、UserList和UserString。当您需要创建模拟内置类型dict、list和str的行为的定制类时,这些类非常方便。*******
Python 命令行参数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的命令行接口
添加处理 Python 命令行参数的功能为基于文本的命令行程序提供了一个用户友好的界面。它类似于由图形元素或小部件操纵的可视化应用程序的图形用户界面。
Python 公开了一种捕获和提取 Python 命令行参数的机制。这些值可以用来修改程序的行为。例如,如果您的程序处理从文件中读取的数据,那么您可以将该文件的名称传递给您的程序,而不是在您的源代码中硬编码该值。
本教程结束时,你会知道:
- Python 命令行参数的起源
- Python 命令行参数的底层支持
- 指导命令行界面设计的标准
- 手动定制和处理 Python 命令行参数的基础知识
- Python 中可用的库简化了复杂命令行界面的开发
如果您想要一种用户友好的方式向您的程序提供 Python 命令行参数,而不需要导入专用的库,或者如果您想要更好地理解专用于构建 Python 命令行界面的现有库的公共基础,那么请继续阅读!
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
命令行界面
命令行界面(CLI) 为用户提供了与运行在基于文本的外壳解释器中的程序进行交互的方式。shell 解释器的一些例子是 Linux 上的 Bash 或 Windows 上的命令提示符。命令行界面由暴露命令提示符的外壳解释器启用。它可以由以下要素来表征:
- 一个命令或程序
- 零个或多个命令行参数
- 代表命令结果的输出
- 称为用法或帮助的文本文档
不是每个命令行界面都提供所有这些元素,但是这个列表也不是详尽的。命令行的复杂性范围很广,从传递单个参数的能力到众多参数和选项,很像一种领域特定语言。例如,一些程序可能从命令行启动 web 文档,或者启动类似 Python 的交互式 shell 解释器。
以下两个 Python 命令示例说明了命令行界面的描述:
$ python -c "print('Real Python')"
Real Python
在第一个例子中,Python 解释器将选项-c用于命令,该命令将选项-c之后的 Python 命令行参数作为 Python 程序来执行。
另一个例子展示了如何用-h调用 Python 来显示帮助:
$ python -h
usage: python3 [option] ... [-c cmd | -m mod | file | -] [arg] ...
Options and arguments (and corresponding environment variables):
-b : issue warnings about str(bytes_instance), str(bytearray_instance)
and comparing bytes/bytearray with str. (-bb: issue errors)
[ ... complete help text not shown ... ]
在您的终端中尝试一下,以查看完整的帮助文档。
C 遗留问题
Python 命令行参数直接继承自 C 编程语言。正如 Guido Van Rossum 在 1993 年的《Unix/C 程序员 Python 入门》中所写的,C 对 Python 有很大的影响。Guido 提到了文字、标识符、操作符和语句的定义,如break、continue或return。Python 命令行参数的使用也受到 C 语言的强烈影响。
为了说明相似之处,请考虑下面的 C 程序:
1// main.c
2#include <stdio.h> 3
4int main(int argc, char *argv[]) { 5 printf("Arguments count: %d\n", argc); 6 for (int i = 0; i < argc; i++) { 7 printf("Argument %6d: %s\n", i, argv[i]); 8 } 9 return 0; 10}
第 4 行定义了 main() ,是一个 C 程序的入口点。请记下这些参数:
argc是一个表示程序参数个数的整数。argv是一个指向字符的数组,在数组的第一个元素中包含程序的名称,在数组的其余元素中后跟程序的自变量(如果有的话)。
您可以在 Linux 上用gcc -o main main.c编译上面的代码,然后用./main执行以获得以下内容:
$ gcc -o main main.c
$ ./main
Arguments count: 1
Argument 0: ./main
除非在命令行用选项-o明确表示, a.out 是由 gcc 编译器生成的可执行文件的默认名称。它代表汇编器输出,让人想起在旧的 UNIX 系统上生成的可执行文件。注意,可执行文件的名称./main是唯一的参数。
让我们通过向同一个程序传递几个 Python 命令行参数来增加这个例子的趣味:
$ ./main Python Command Line Arguments
Arguments count: 5
Argument 0: ./main
Argument 1: Python
Argument 2: Command
Argument 3: Line
Argument 4: Arguments
输出显示参数的数量是5,参数列表包括程序名main,后面是您在命令行传递的短语"Python Command Line Arguments"的每个单词。
注 : argc代表自变量计数,而argv代表自变量向量。要了解更多信息,请查看一点 C Primer/C 命令行参数。
main.c的编译假设你用的是 Linux 或者 Mac OS 系统。在 Windows 上,您还可以使用以下选项之一编译此 C 程序:
- Windows Subsystem for Linux(WSL):它在一些 Linux 发行版中可用,比如 Ubuntu 、 OpenSUSE 和 Debian 等等。您可以从 Microsoft 商店安装它。
- Windows 构建工具: 这包括 Windows 命令行构建工具,微软 C/C++编译器
cl.exe,以及一个名为clang.exe用于 C/C++的编译器前端。 - 微软 Visual Studio: 这是微软主要的集成开发环境(IDE)。要了解更多关于可用于各种操作系统(包括 Windows)上的 Python 和 C 的 ide,请查看Python ide 和代码编辑器(指南)。
- mingw-64 项目: 这个支持 Windows 上的 GCC 编译器。
如果您已经安装了 Microsoft Visual Studio 或 Windows 构建工具,那么您可以如下编译main.c:
C:/>cl main.c
您将获得一个名为main.exe的可执行文件,您可以这样开始:
C:/>main
Arguments count: 1
Argument 0: main
你可以实现一个 Python 程序main.py,它相当于 C 程序main.c,你可以在上面看到:
# main.py
import sys
if __name__ == "__main__":
print(f"Arguments count: {len(sys.argv)}")
for i, arg in enumerate(sys.argv):
print(f"Argument {i:>6}: {arg}")
你看不到像 C 代码例子中的argc 变量。它在 Python 中不存在,因为sys.argv已经足够了。您可以在sys.argv中解析 Python 命令行参数,而不必知道列表的长度,如果您的程序需要参数的数量,您可以调用内置的 len() 。
另外,请注意, enumerate() 在应用于 iterable 时,会返回一个enumerate对象,该对象可以发出将sys.arg中元素的索引与其相应值相关联的对。这允许循环遍历sys.argv的内容,而不必维护列表中索引的计数器。
如下执行main.py:
$ python main.py Python Command Line Arguments
Arguments count: 5
Argument 0: main.py
Argument 1: Python
Argument 2: Command
Argument 3: Line
Argument 4: Arguments
sys.argv包含与 C 程序中相同的信息:
- 节目名称
main.py是列表的第一项。 - 自变量
Python、Command、Line和Arguments是列表中剩余的元素。
通过对 C 语言一些神秘方面的简短介绍,您现在已经掌握了一些有价值的知识,可以进一步掌握 Python 命令行参数。
来自 Unix 世界的两个实用程序
为了在本教程中使用 Python 命令行参数,您将实现 Unix 生态系统中两个实用程序的部分功能:
在下面几节中,您将对这些 Unix 工具有所熟悉。
sha1sum
sha1sum计算SHA-1T3】哈希,常用于验证文件的完整性。对于给定的输入,一个 哈希函数 总是返回相同的值。输入中的任何微小变化都会导致不同的哈希值。在使用带有具体参数的实用程序之前,您可以尝试显示帮助:
$ sha1sum --help
Usage: sha1sum [OPTION]... [FILE]...
Print or check SHA1 (160-bit) checksums.
With no FILE, or when FILE is -, read standard input.
-b, --binary read in binary mode
-c, --check read SHA1 sums from the FILEs and check them
--tag create a BSD-style checksum
-t, --text read in text mode (default)
-z, --zero end each output line with NUL, not newline,
and disable file name escaping
[ ... complete help text not shown ... ]
显示命令行程序的帮助是命令行界面中公开的一个常见功能。
要计算文件内容的 SHA-1 哈希值,请执行以下操作:
$ sha1sum main.c
125a0f900ff6f164752600550879cbfabb098bc3 main.c
结果显示 SHA-1 哈希值作为第一个字段,文件名作为第二个字段。该命令可以将多个文件作为参数:
$ sha1sum main.c main.py
125a0f900ff6f164752600550879cbfabb098bc3 main.c
d84372fc77a90336b6bb7c5e959bcb1b24c608b4 main.py
由于 Unix 终端的通配符扩展特性,还可以为 Python 命令行参数提供通配符。一个这样的字符是星号或星号(*):
$ sha1sum main.*
3f6d5274d6317d580e2ffc1bf52beee0d94bf078 main.c
f41259ea5835446536d2e71e566075c1c1bfc111 main.py
shell 将main.*转换为main.c和main.py,这是当前目录中与模式main.*匹配的两个文件,并将它们传递给sha1sum。程序计算参数列表中每个文件的 SHA1 散列。您将会看到,在 Windows 上,行为是不同的。Windows 没有通配符扩展,所以程序可能必须适应这一点。您的实现可能需要在内部扩展通配符。
没有任何参数,sha1sum从标准输入中读取。你可以通过在键盘上键入字符向程序输入数据。输入可以包含任何字符,包括回车符 Enter 。要终止输入,必须用 Enter 发出文件结束的信号,后面是顺序 Ctrl + D :
1$ sha1sum
2Real
3Python
487263a73c98af453d68ee4aab61576b331f8d9d6 -
你先输入节目名称,sha1sum,接着是 Enter ,然后是Real和Python,每一个后面还跟着 Enter 。要关闭输入流,您可以键入 Ctrl + D 。结果是为文本Real\nPython\n生成的 SHA1 散列值。文件的名称是-。这是指示标准输入的约定。当您执行以下命令时,哈希值是相同的:
$ python -c "print('Real\nPython\n', end='')" | sha1sum
87263a73c98af453d68ee4aab61576b331f8d9d6 -
$ python -c "print('Real\nPython')" | sha1sum
87263a73c98af453d68ee4aab61576b331f8d9d6 -
$ printf "Real\nPython\n" | sha1sum
87263a73c98af453d68ee4aab61576b331f8d9d6 -
接下来,你会读到一段关于seq的简短描述。
seq
seq 生成一个序列的数字。在其最基本的形式中,如生成从 1 到 5 的序列,您可以执行以下内容:
$ seq 5
1
2
3
4
5
为了获得对seq所揭示的可能性的概述,您可以在命令行显示帮助:
$ seq --help
Usage: seq [OPTION]... LAST
or: seq [OPTION]... FIRST LAST
or: seq [OPTION]... FIRST INCREMENT LAST
Print numbers from FIRST to LAST, in steps of INCREMENT.
Mandatory arguments to long options are mandatory for short options too.
-f, --format=FORMAT use printf style floating-point FORMAT
-s, --separator=STRING use STRING to separate numbers (default: \n)
-w, --equal-width equalize width by padding with leading zeroes
--help display this help and exit
--version output version information and exit
[ ... complete help text not shown ... ]
对于本教程,您将编写几个简化的sha1sum和seq变体。在每个示例中,您将了解 Python 命令行参数的不同方面或特性组合。
在 Mac OS 和 Linux 上,sha1sum和seq应该是预装的,尽管不同系统或发行版的特性和帮助信息有时会略有不同。如果你使用的是 Windows 10,那么最方便的方法就是在安装在 WSL 上的 Linux 环境下运行sha1sum和seq。如果您不能访问公开标准 Unix 实用程序的终端,那么您可以访问在线终端:
- 在 PythonAnywhere 上创建一个免费账户,并启动一个 Bash 控制台。
- 在 repl.it 上创建一个临时 Bash 终端。
这是两个例子,你可能会找到其他的。
sys.argv数组
在探索一些公认的惯例和发现如何处理 Python 命令行参数之前,您需要知道对所有 Python 命令行参数的底层支持是由 sys.argv 提供的。下面几节中的例子向您展示了如何处理存储在sys.argv中的 Python 命令行参数,以及如何克服在您试图访问它们时出现的典型问题。您将了解到:
- 如何访问的内容
sys.argv - 如何减轻全球性质的副作用
sys.argv - 如何处理 Python 命令行参数中的空格
- 在访问 Python 命令行参数时,如何处理错误
- 如何摄取按字节传递的 Python 命令行参数的原始格式
我们开始吧!
显示参数
sys模块公开了一个名为argv的数组,它包括以下内容:
argv[0]包含当前 Python 程序的名称。argv[1:],列表的其余部分,包含任何和所有传递给程序的 Python 命令行参数。
下面的例子演示了sys.argv的内容:
1# argv.py
2import sys
3
4print(f"Name of the script : {sys.argv[0]=}")
5print(f"Arguments of the script : {sys.argv[1:]=}")
下面是这段代码的工作原理:
- 第 2 行导入内部 Python 模块
sys。 - 第 4 行通过访问列表的第一个元素
sys.argv提取程序名。 - 第 5 行通过获取列表
sys.argv的所有剩余元素来显示 Python 命令行参数。
注意:在argv.py中使用的 f 字符串语法利用了 Python 3.8 中新的调试说明符。要了解更多关于 f-string 的新特性和其他特性,请查看 Python 3.8 中的新特性。
如果您的 Python 版本低于 3.8,那么只需删除两个 f 字符串中的等号(=)就可以让程序成功执行。输出将只显示变量的值,而不是它们的名称。
使用如下任意参数列表执行上面的脚本argv.py:
$ python argv.py un deux trois quatre
Name of the script : sys.argv[0]='argv.py'
Arguments of the script : sys.argv[1:]=['un', 'deux', 'trois', 'quatre']
输出确认了sys.argv[0]的内容是 Python 脚本argv.py,并且sys.argv列表的剩余元素包含脚本的参数['un', 'deux', 'trois', 'quatre']。
总而言之,sys.argv包含了所有的argv.py Python 命令行参数。当 Python 解释器执行 Python 程序时,它解析命令行并用参数填充sys.argv。
颠倒第一个论点
现在您已经有了足够的关于sys.argv的背景知识,您将对命令行传递的参数进行操作。示例reverse.py反转在命令行传递的第一个参数:
1# reverse.py
2
3import sys
4
5arg = sys.argv[1]
6print(arg[::-1])
在reverse.py中,通过以下步骤执行反转第一个自变量的过程:
- 第 5 行取出存储在
sys.argv的索引1处的程序的第一个自变量。记住程序名存储在sys.argv的索引0中。 - 第 6 行打印反转的字符串。
args[::-1]是使用切片操作的一种 Pythonic 方式来反转一个列表。
您按如下方式执行脚本:
$ python reverse.py "Real Python"
nohtyP laeR
正如所料,reverse.py对"Real Python"进行运算,并反转输出"nohtyP laeR"的唯一参数。请注意,用引号将多单词字符串"Real Python"括起来可以确保解释器将它作为一个唯一的参数来处理,而不是两个参数。在后面的部分中,您将深入研究参数分隔符。
sys.argv变异
sys.argv对你正在运行的 Python 程序来说是全球可用的吗?流程执行过程中导入的所有模块都可以直接访问sys.argv。这种全球访问可能很方便,但sys.argv不是一成不变的。您可能希望实现一种更可靠的机制,将程序参数公开给 Python 程序中的不同模块,尤其是在具有多个文件的复杂程序中。
观察篡改sys.argv会发生什么:
# argv_pop.py
import sys
print(sys.argv)
sys.argv.pop()
print(sys.argv)
您调用 .pop() 删除并返回sys.argv中的最后一项。
执行上面的脚本:
$ python argv_pop.py un deux trois quatre
['argv_pop.py', 'un', 'deux', 'trois', 'quatre']
['argv_pop.py', 'un', 'deux', 'trois']
注意第四个参数不再包含在sys.argv中。
在一个简短的脚本中,您可以安全地依赖对sys.argv的全局访问,但是在一个更大的程序中,您可能希望将参数存储在一个单独的变量中。前面的示例可以修改如下:
# argv_var_pop.py
import sys
print(sys.argv)
args = sys.argv[1:]
print(args)
sys.argv.pop()
print(sys.argv)
print(args)
这一次,sys.argv虽然失去了最后的元素,args却被安全的保存了下来。args不是全局的,你可以传递它来解析程序逻辑中的参数。Python 包管理器 pip 使用这种方法。下面是pip源代码的简短摘录:
def main(args=None):
if args is None:
args = sys.argv[1:]
在这个取自 pip 源代码的代码片段中, main() 将只包含参数而不包含文件名的sys.argv片段保存到args中。sys.argv保持不变,args也不会受到对sys.argv的任何无意更改的影响。
转义空白字符
在reverse.py的例子中你看到了前面的,第一个也是唯一一个参数是"Real Python",结果是"nohtyP laeR"。参数在"Real"和"Python"之间包含一个空格分隔符,需要对其进行转义。
在 Linux 上,可以通过执行以下操作之一来转义空格:
- 围绕的论点用单引号(
') - 用双引号将括起来(
") - 在每个空格前加一个反斜杠(
\)
如果没有一个转义解决方案,reverse.py将存储两个参数,"Real"在sys.argv[1]中,"Python"在sys.argv[2]中:
$ python reverse.py Real Python
laeR
上面的输出显示脚本只反转了"Real"并且忽略了"Python"。为了确保两个参数都被存储,您需要用双引号(")将整个字符串括起来。
您也可以使用反斜杠(\)来转义空格:
$ python reverse.py Real\ Python
nohtyP laeR
使用反斜杠(\),命令 shell 向 Python 公开一个惟一的参数,然后向reverse.py公开。
在 Unix shells 中,内部字段分隔符(IFS) 定义用作分隔符的字符。通过运行以下命令,可以显示 shell 变量IFS的内容:
$ printf "%q\n" "$IFS"
$' \t\n'
从上面的结果中,' \t\n',您发现了三个分隔符:
- 太空 (
' ') - 标签 (
\t) - 换行 (
\n)
在空格前加上反斜杠(\)会绕过空格作为字符串"Real Python"中分隔符的默认行为。这产生了预期的一个文本块,而不是两个。
注意,在 Windows 上,可以通过使用双引号的组合来管理空白解释。这有点违反直觉,因为在 Windows 终端中,双引号(")被解释为禁用并随后启用特殊字符的开关,如空格、制表符或竖线 ( |)。
因此,当你用双引号将多个字符串括起来时,Windows 终端会将第一个双引号解释为命令忽略特殊字符,将第二个双引号解释为命令解释特殊字符。
考虑到这些信息,可以有把握地认为,用双引号将多个字符串括起来会产生预期的行为,即将一组字符串作为单个参数公开。要确认 Windows 命令行上双引号的这种特殊效果,请观察以下两个示例:
C:/>python reverse.py "Real Python"
nohtyP laeR
在上面的例子中,你可以直观地推断出"Real Python"被解释为单个参数。但是,请意识到当您使用单引号时会发生什么:
C:/>python reverse.py "Real Python
nohtyP laeR
命令提示符将整个字符串"Real Python"作为单个参数传递,就像参数是"Real Python"一样。实际上,Windows 命令提示符将唯一的双引号视为禁用空格作为分隔符的开关,并将双引号后面的任何内容作为唯一参数传递。
关于 Windows 终端中双引号的影响的更多信息,请查看了解 Windows 命令行参数引用和转义的更好方法。
处理错误
Python 命令行参数是松散字符串。很多事情都可能出错,所以为程序的用户提供一些指导是个好主意,以防他们在命令行传递不正确的参数。例如,reverse.py需要一个参数,如果忽略它,就会出现错误:
1$ python reverse.py
2Traceback (most recent call last):
3 File "reverse.py", line 5, in <module>
4 arg = sys.argv[1]
5IndexError: list index out of range
Python 异常 IndexError被引发,对应的回溯显示错误是由表达式arg = sys.argv[1]引起的。例外的消息是list index out of range。你没有在命令行传递参数,所以在索引1的列表sys.argv中没有任何内容。
这是一种常见的模式,可以用几种不同的方法来解决。对于这个初始示例,您将通过在一个try块中包含表达式arg = sys.argv[1]来保持它的简短。按如下方式修改代码:
1# reverse_exc.py
2
3import sys
4
5try:
6 arg = sys.argv[1]
7except IndexError:
8 raise SystemExit(f"Usage: {sys.argv[0]} <string_to_reverse>")
9print(arg[::-1])
第 4 行的表达式包含在try块中。第 8 行引出内置异常 SystemExit 。如果没有参数传递给reverse_exc.py,那么在打印用法之后,流程退出,状态代码为1。请注意错误消息中对sys.argv[0]的整合。它在使用消息中公开程序的名称。现在,当您在没有任何 Python 命令行参数的情况下执行相同的程序时,您可以看到以下输出:
$ python reverse.py
Usage: reverse.py <string_to_reverse>
$ echo $?
1
没有在命令行传递参数。结果,程序引发了带有错误消息的SystemExit。这导致程序以1的状态退出,当你用 echo 打印特殊变量 $? 时显示。
计算sha1sum
您将编写另一个脚本来演示,在类似于 Unix 的系统上,Python 命令行参数是按字节从操作系统传递的。该脚本将一个字符串作为参数,并输出该参数的十六进制 SHA-1 散列:
1# sha1sum.py
2
3import sys
4import hashlib
5
6data = sys.argv[1]
7m = hashlib.sha1()
8m.update(bytes(data, 'utf-8'))
9print(m.hexdigest())
这大致是受sha1sum的启发,但是它有意处理一个字符串,而不是文件的内容。在sha1sum.py中,获取 Python 命令行参数并输出结果的步骤如下:
- 第 6 行将第一个参数的内容存储在
data中。 - 第 7 行举例说明了一个 SHA1 算法。
- 第 8 行用第一个程序参数的内容更新 SHA1 散列对象。注意,
hash.update接受一个字节数组作为参数,因此有必要将data从字符串转换为字节数组。 - 第 9 行打印第 8 行计算的 SHA1 散列的十六进制表示。
当您运行带有参数的脚本时,您会得到以下结果:
$ python sha1sum.py "Real Python"
0554943d034f044c5998f55dac8ee2c03e387565
为了保持示例简短,脚本sha1sum.py不处理缺失的 Python 命令行参数。在这个脚本中,可以像在reverse_exc.py中一样处理错误。
**注意:**查看 hashlib 了解 Python 标准库中可用散列函数的更多细节。
从sys.argv 文档中,您了解到为了获得 Python 命令行参数的原始字节,您可以使用 os.fsencode() 。通过直接从sys.argv[1]获取字节,你不需要执行data的字符串到字节的转换:
1# sha1sum_bytes.py
2
3import os
4import sys
5import hashlib
6
7data = os.fsencode(sys.argv[1])
8m = hashlib.sha1()
9m.update(data)
10print(m.hexdigest())
sha1sum.py和sha1sum_bytes.py的主要区别在以下几行中突出显示:
- 第 7 行用传递给 Python 命令行参数的原始字节填充
data。 - 第 9 行将
data作为参数传递给m.update(),后者接收一个类似字节的对象。
执行sha1sum_bytes.py比较输出:
$ python sha1sum_bytes.py "Real Python"
0554943d034f044c5998f55dac8ee2c03e387565
SHA1 散列的十六进制值与前面的sha1sum.py示例中的值相同。
Python 命令行参数剖析
既然您已经研究了 Python 命令行参数的几个方面,最著名的是sys.argv,那么您将应用开发人员在实现命令行接口时经常使用的一些标准。
Python 命令行参数是命令行界面的子集。它们可以由不同类型的参数组成:
- 选项修改特定命令或程序的行为。
- 自变量表示要处理的源或目的地。
- 子命令允许程序用相应的选项和参数集定义多个命令。
在深入研究不同类型的参数之前,您将对指导命令行界面和参数设计的公认标准有一个概述。自从 20 世纪 60 年代中期计算机终端问世以来,这些技术已经得到了改进。
标准
一些可用的标准提供了一些定义和指南,以促进实现命令及其参数的一致性。以下是主要的 UNIX 标准和参考资料:
上面的标准为任何与程序和 Python 命令行参数相关的事物定义了指导方针和术语。以下几点摘自这些参考资料:
- POSIX :
- 程序或实用程序后跟选项、选项参数和操作数。
- 所有选项前面都应该有一个连字符或减号(
-)分隔符。 - 选项参数不应该是可选的。
- GNU :
- 所有程序都应该支持两个标准选项,分别是
--version和--help。 - 长名称选项等效于单字母 Unix 样式的选项。一个例子是
--debug和-d。
- 所有程序都应该支持两个标准选项,分别是
- docopt :
- 短选项可以叠加,意思是
-abc相当于-a -b -c。 - 长选项可以在空格或等号(
=)后指定参数。长选项--input=ARG相当于--input ARG。
- 短选项可以叠加,意思是
这些标准定义了有助于描述命令的符号。当您使用选项-h或--help调用特定命令时,可以使用类似的符号来显示该命令的用法。
GNU 标准非常类似于 POSIX 标准,但是提供了一些修改和扩展。值得注意的是,他们添加了长选项,这是一个以两个连字符(--)为前缀的全名选项。例如,要显示帮助,常规选项是-h,长选项是--help。
注意:你不需要严格遵循那些标准。相反,遵循自 UNIX 出现以来已经成功使用多年的惯例。如果你为你或你的团队编写一套实用程序,那么确保你在不同的实用程序之间保持一致。
在接下来的几节中,您将了解更多关于命令行组件、选项、参数和子命令的信息。
选项
一个选项,有时被称为标志或开关,意在修改程序的行为。例如,Linux 上的命令ls列出了给定目录的内容。没有任何参数,它列出了当前目录中的文件和目录:
$ cd /dev
$ ls
autofs
block
bsg
btrfs-control
bus
char
console
我们来补充几个选项。您可以将-l和-s组合成-ls,改变终端显示的信息:
$ cd /dev
$ ls -ls
total 0
0 crw-r--r-- 1 root root 10, 235 Jul 14 08:10 autofs
0 drwxr-xr-x 2 root root 260 Jul 14 08:10 block
0 drwxr-xr-x 2 root root 60 Jul 14 08:10 bsg
0 crw------- 1 root root 10, 234 Jul 14 08:10 btrfs-control
0 drwxr-xr-x 3 root root 60 Jul 14 08:10 bus
0 drwxr-xr-x 2 root root 4380 Jul 14 15:08 char
0 crw------- 1 root root 5, 1 Jul 14 08:10 console
一个选项可以带一个参数,称为一个选项-参数。参见下面的 od 动作示例:
$ od -t x1z -N 16 main
0000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 >.ELF............<
0000020
od 代表八进制转储。该实用程序以不同的可打印表示显示数据,如八进制(默认)、十六进制、十进制和 ASCII。在上面的例子中,它获取二进制文件main并以十六进制格式显示文件的前 16 个字节。选项-t需要一个类型作为选项参数,而-N需要输入的字节数。
在上面的例子中,-t被赋予类型x1,它代表十六进制,每个整数一个字节。接下来是z,在输入行的末尾显示可打印的字符。-N将16作为选项参数,用于将输入字节数限制为 16。
参数
在 POSIX 标准中,参数也被称为操作数或参数。参数表示命令所作用的数据的源或目标。例如,用于将一个或多个文件复制到一个文件或目录的命令 cp 至少有一个源和一个目标:
1$ ls main
2main
3
4$ cp main main2 5
6$ ls -lt
7main
8main2
9...
在第 4 行,cp有两个参数:
main:源文件main2: 目标文件
然后它将main的内容复制到一个名为main2的新文件中。main和main2都是程序cp的参数或操作数。
子命令
在 POSIX 或 GNU 标准中没有记载子命令的概念,但是它确实出现在 docopt 中。标准的 Unix 实用程序是遵循 Unix 理念的小工具。Unix 程序旨在成为做一件事情并且做好这件事情的程序。这意味着不需要子命令。
相比之下,新一代的程序,包括 git 、 go 、 docker 和 gcloud ,有一个稍微不同的范例,包含子命令。它们不一定是 Unix 环境的一部分,因为它们跨越几个操作系统,而且它们部署在一个完整的生态系统中,需要几个命令。
以git为例。它处理几个命令,每个命令可能都有自己的一组选项、选项参数和参数。以下示例适用于 git 子命令branch:
git branch显示本地 git 仓库的分支。git branch custom_python在本地存储库中创建本地分支custom_python。git branch -d custom_python删除本地分支custom_python。git branch --help显示git branch子命令的帮助。
在 Python 生态系统中, pip 也有子命令的概念。一些pip子命令包括list、install、freeze或uninstall。
窗户
在 Windows 上,关于 Python 命令行参数的约定略有不同,特别是关于命令行选项的约定。为了验证这种差异,以tasklist为例,它是一个本地 Windows 可执行文件,显示当前运行的进程列表。类似于 Linux 或者 macOS 系统上的ps。下面是一个如何在 Windows 的命令提示符下执行tasklist的例子:
C:/>tasklist /FI "IMAGENAME eq notepad.exe"
Image Name PID Session Name Session# Mem Usage
========================= ======== ================ =========== ============
notepad.exe 13104 Console 6 13,548 K
notepad.exe 6584 Console 6 13,696 K
注意,选项的分隔符是正斜杠(/),而不是像 Unix 系统的约定那样的连字符(-)。为了可读性,在程序名taskslist和选项/FI之间有一个空格,但是键入taskslist/FI也是一样正确的。
上面的特定示例使用过滤器执行tasklist,只显示当前运行的记事本进程。您可以看到系统有两个正在运行的记事本进程实例。尽管这并不等同,但这类似于在类似 Unix 的系统上的终端中执行以下命令:
$ ps -ef | grep vi | grep -v grep
andre 2117 4 0 13:33 tty1 00:00:00 vi .gitignore
andre 2163 2134 0 13:34 tty3 00:00:00 vi main.c
上面的ps命令显示了所有当前正在运行的vi进程。这种行为与 Unix 哲学一致,因为ps的输出由两个grep过滤器转换。第一个grep命令选择vi的所有出现,第二个grep命令过滤掉grep本身的出现。
随着 Unix 工具在 Windows 生态系统中的出现,非特定于 Windows 的约定也在 Windows 上被接受。
视觉
在 Python 进程开始时,Python 命令行参数分为两类:
-
**Python 选项:**这些影响 Python 解释器的执行。例如,添加选项
-O是通过删除assert和__debug__语句来优化 Python 程序执行的一种手段。命令行中还有其他的 Python 选项。 -
**Python 程序及其参数:**跟随 Python 选项(如果有的话),你会找到 Python 程序,它是一个文件名,通常有扩展名
.py,以及它的参数。按照惯例,它们也可以由选项和参数组成。
采用下面的命令来执行程序main.py,它带有选项和参数。注意,在这个例子中,Python 解释器还带了一些选项,分别是 -B 和 -v 。
$ python -B -v main.py --verbose --debug un deux
在上面的命令行中,选项是 Python 命令行参数,组织如下:
- 选项
-B告诉 Python 在导入源模块时不要写.pyc文件。关于.pyc文件的更多细节,请查看章节编译器做什么?在您的 CPython 源代码指南中。 - 选项
-v代表冗长并告诉 Python 跟踪所有导入语句。 - 传递给
main.py的参数是虚构的,代表两个长选项(--verbose和--debug)和两个参数(un和deux)。
Python 命令行参数的这个示例可以用图形方式说明如下:
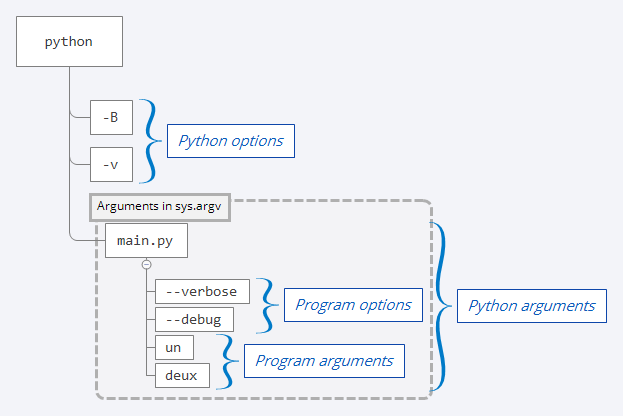
在 Python 程序main.py中,您只能访问 Python 在sys.argv中插入的 Python 命令行参数。Python 选项可能会影响程序的行为,但在main.py中无法访问。
解析 Python 命令行参数的几种方法
现在,您将探索几种理解选项、选项参数和操作数的方法。这是通过解析 Python 命令行参数来完成的。在本节中,您将看到 Python 命令行参数的一些具体方面以及处理它们的技术。首先,您将看到一个例子,它介绍了一种依靠列表理解从参数中收集和分离选项的直接方法。然后你会:
- 使用正则表达式提取命令行的元素
- 学习如何处理命令行传递的文件
- 以与 Unix 工具兼容的方式理解标准输入
- 将程序的正常输出与错误区分开来
- 实现一个定制的解析器来读取 Python 命令行参数
这将为涉及标准库中或外部库中模块的选项做准备,您将在本教程的后面部分了解这些选项。
对于不复杂的情况,下面的模式可能就足够了,它不强制排序,也不处理选项参数:
# cul.py
import sys
opts = [opt for opt in sys.argv[1:] if opt.startswith("-")] args = [arg for arg in sys.argv[1:] if not arg.startswith("-")]
if "-c" in opts:
print(" ".join(arg.capitalize() for arg in args))
elif "-u" in opts:
print(" ".join(arg.upper() for arg in args))
elif "-l" in opts:
print(" ".join(arg.lower() for arg in args))
else:
raise SystemExit(f"Usage: {sys.argv[0]} (-c | -u | -l) <arguments>...")
上面程序的目的是修改 Python 命令行参数的大小写。有三个选项可用:
-c将论据资本化-u将自变量转换为大写-l将自变量转换为小写
代码使用列表理解收集和分离不同的参数类型:
- 第 5 行通过过滤任何以连字符(
-)开头的 Python 命令行参数来收集所有的选项。 - 第 6 行通过过滤选项来组装程序参数。
当您使用一组选项和参数执行上面的 Python 程序时,您会得到以下输出:
$ python cul.py -c un deux trois
Un Deux Trois
这种方法在许多情况下可能已经足够,但在以下情况下会失败:
- 如果顺序很重要,尤其是选项应该出现在参数之前
- 如果需要支持选项参数
- 如果一些参数以连字符(
-)为前缀
在求助于像argparse或click这样的库之前,您可以利用其他选项。
正则表达式
您可以使用一个正则表达式来强制执行特定的顺序、特定的选项和选项参数,甚至是参数的类型。为了说明正则表达式解析 Python 命令行参数的用法,您将实现一个 Python 版本的 seq ,这是一个打印数字序列的程序。遵循 docopt 惯例,seq.py的规范可能是这样的:
Print integers from <first> to <last>, in steps of <increment>.
Usage:
python seq.py --help
python seq.py [-s SEPARATOR] <last>
python seq.py [-s SEPARATOR] <first> <last>
python seq.py [-s SEPARATOR] <first> <increment> <last>
Mandatory arguments to long options are mandatory for short options too.
-s, --separator=STRING use STRING to separate numbers (default: \n)
--help display this help and exit
If <first> or <increment> are omitted, they default to 1\. When <first> is
larger than <last>, <increment>, if not set, defaults to -1.
The sequence of numbers ends when the sum of the current number and
<increment> reaches the limit imposed by <last>.
首先,看一个旨在捕捉上述需求的正则表达式:
1args_pattern = re.compile(
2 r"""
3 ^
4 (
5 (--(?P<HELP>help).*)|
6 ((?:-s|--separator)\s(?P<SEP>.*?)\s)?
7 ((?P<OP1>-?\d+))(\s(?P<OP2>-?\d+))?(\s(?P<OP3>-?\d+))?
8 )
9 $
10""",
11 re.VERBOSE,
12)
为了试验上面的正则表达式,您可以使用记录在正则表达式 101 上的片段。正则表达式捕获并实施了针对seq的需求的几个方面。特别是,该命令可能采用:
- 一个帮助选项,简称
-h或长格式--help,捕获为一个命名组称为HELP - 一个分隔符选项、
-s或--separator,取一个可选参数,并被捕获为命名组**、SEP、** - 最多三个整数操作数,分别捕捉为
OP1、OP2、OP3
为了清楚起见,上面的模式args_pattern在第 11 行使用了标志 re.VERBOSE 。这允许您将正则表达式分散在几行中以增强可读性。该模式验证以下内容:
- 参数顺序:选项和参数应该按照给定的顺序排列。例如,参数前应该有选项。
- 选项值 **:只有
--help、-s或--separator被期望作为选项。 - 论据互斥:选项
--help与其他选项或论据不兼容。 - 参数类型:操作数应为正整数或负整数。
为了让正则表达式能够处理这些事情,它需要在一个字符串中看到所有 Python 命令行参数。您可以使用 str.join() 收集它们:
arg_line = " ".join(sys.argv[1:])
这使得arg_line成为一个包含所有参数的字符串,除了程序名,用空格分开。
给定上面的模式args_pattern,您可以使用下面的函数提取 Python 命令行参数:
def parse(arg_line: str) -> Dict[str, str]:
args: Dict[str, str] = {}
if match_object := args_pattern.match(arg_line):
args = {k: v for k, v in match_object.groupdict().items()
if v is not None}
return args
该模式已经处理了参数的顺序、选项和参数之间的互斥性以及参数的类型。parse()是将 re.match() 应用到参数行,以提取适当的值并将数据存储在字典中。
字典包括每个组的名称作为键和它们各自的值。例如,如果arg_line值是--help,那么字典就是{'HELP': 'help'}。如果arg_line是-s T 10,那么字典就变成了{'SEP': 'T', 'OP1': '10'}。您可以展开下面的代码块来查看带有正则表达式的seq的实现。
下面的代码使用正则表达式实现了 seq 的有限版本,以处理命令行解析和验证:
# seq_regex.py
from typing import List, Dict
import re
import sys
USAGE = (
f"Usage: {sys.argv[0]} [-s <separator>] [first [increment]] last"
)
args_pattern = re.compile(
r"""
^
(
(--(?P<HELP>help).*)|
((?:-s|--separator)\s(?P<SEP>.*?)\s)?
((?P<OP1>-?\d+))(\s(?P<OP2>-?\d+))?(\s(?P<OP3>-?\d+))?
)
$
""",
re.VERBOSE,
)
def parse(arg_line: str) -> Dict[str, str]:
args: Dict[str, str] = {}
if match_object := args_pattern.match(arg_line):
args = {k: v for k, v in match_object.groupdict().items()
if v is not None}
return args
def seq(operands: List[int], sep: str = "\n") -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
if len(operands) == 2:
first, last = operands
if first > last:
increment = -1
if len(operands) == 3:
first, increment, last = operands
last = last + 1 if increment > 0 else last - 1
return sep.join(str(i) for i in range(first, last, increment))
def main() -> None:
args = parse(" ".join(sys.argv[1:]))
if not args:
raise SystemExit(USAGE)
if args.get("HELP"):
print(USAGE)
return
operands = [int(v) for k, v in args.items() if k.startswith("OP")]
sep = args.get("SEP", "\n")
print(seq(operands, sep))
if __name__ == "__main__":
main()
您可以通过运行以下命令来执行上面的代码:
$ python seq_regex.py 3
这将输出以下内容:
1
2
3
尝试此命令与其他组合,包括--help选项。
您没有看到此处提供的版本选项。这样做是为了缩短示例的长度。您可以考虑添加版本选项作为扩展练习。作为提示,您可以通过用(--(?P<HELP>help).*)|(--(?P<VER>version).*)|替换行(--(?P<HELP>help).*)|来修改正则表达式。在main()中还需要一个额外的if块。
至此,您已经知道了一些从命令行提取选项和参数的方法。到目前为止,Python 命令行参数只有字符串或整数。接下来,您将学习如何处理作为参数传递的文件。
文件处理
现在是试验 Python 命令行参数的时候了,这些参数应该是文件名。修改sha1sum.py来处理一个或多个文件作为参数。您将得到一个原始sha1sum实用程序的降级版本,它将一个或多个文件作为参数,并显示每个文件的十六进制 SHA1 散列,后跟文件名:
# sha1sum_file.py
import hashlib
import sys
def sha1sum(filename: str) -> str:
hash = hashlib.sha1()
with open(filename, mode="rb") as f:
hash.update(f.read())
return hash.hexdigest()
for arg in sys.argv[1:]:
print(f"{sha1sum(arg)} {arg}")
sha1sum()应用于从命令行传递的每个文件中读取的数据,而不是字符串本身。请注意,m.update()将一个类似于字节的对象作为参数,在用rb模式打开一个文件后调用read()的结果将返回一个 bytes对象。有关处理文件内容的更多信息,请查看用 Python 读写文件的,尤其是使用字节的部分。
sha1sum_file.py从在命令行处理字符串到操作文件内容的演变让您更接近于sha1sum的最初实现:
$ sha1sum main main.c
9a6f82c245f5980082dbf6faac47e5085083c07d main
125a0f900ff6f164752600550879cbfabb098bc3 main.c
使用相同的 Python 命令行参数执行 Python 程序,结果如下:
$ python sha1sum_file.py main main.c
9a6f82c245f5980082dbf6faac47e5085083c07d main
125a0f900ff6f164752600550879cbfabb098bc3 main.c
因为您与 shell 解释器或 Windows 命令提示符进行交互,所以您还可以受益于 shell 提供的通配符扩展。为了证明这一点,您可以重用main.py,它显示每个参数及其值:
$ python main.py main.*
Arguments count: 5
Argument 0: main.py
Argument 1: main.c
Argument 2: main.exe
Argument 3: main.obj
Argument 4: main.py
您可以看到 shell 自动执行通配符扩展,因此任何基本名称与main匹配的文件,不管扩展名是什么,都是sys.argv的一部分。
通配符扩展在 Windows 上不可用。为了获得相同的行为,您需要在代码中实现它。要重构main.py以处理通配符扩展,您可以使用 glob 。下面的例子适用于 Windows,尽管它不如最初的main.py简洁,但同样的代码在不同平台上的表现是相似的:
1# main_win.py
2
3import sys
4import glob
5import itertools
6from typing import List
7
8def expand_args(args: List[str]) -> List[str]:
9 arguments = args[:1]
10 glob_args = [glob.glob(arg) for arg in args[1:]]
11 arguments += itertools.chain.from_iterable(glob_args)
12 return arguments
13
14if __name__ == "__main__":
15 args = expand_args(sys.argv)
16 print(f"Arguments count: {len(args)}")
17 for i, arg in enumerate(args):
18 print(f"Argument {i:>6}: {arg}")
在main_win.py中,expand_args依靠 glob.glob() 来处理 shell 风格的通配符。您可以在 Windows 和任何其他操作系统上验证结果:
C:/>python main_win.py main.*
Arguments count: 5
Argument 0: main_win.py
Argument 1: main.c
Argument 2: main.exe
Argument 3: main.obj
Argument 4: main.py
这解决了使用通配符如星号(*)或问号(?)处理文件的问题,但是stdin如何呢?
如果您不向原始的sha1sum实用程序传递任何参数,那么它将从标准输入中读取数据。这是您在终端输入的文本,当您在类似 Unix 的系统上键入 Ctrl + D 或在 Windows 上键入 Ctrl + Z 时结束。这些控制序列向终端发送文件结束(EOF ),终端停止从stdin读取并返回输入的数据。
在下一节中,您将在代码中添加从标准输入流中读取的功能。
标准输入
当您使用 sys.stdin 修改前面的sha1sumPython 实现来处理标准输入时,您将更接近最初的sha1sum:
# sha1sum_stdin.py
from typing import List
import hashlib
import pathlib
import sys
def process_file(filename: str) -> bytes:
return pathlib.Path(filename).read_bytes()
def process_stdin() -> bytes:
return bytes("".join(sys.stdin), "utf-8")
def sha1sum(data: bytes) -> str:
sha1_hash = hashlib.sha1()
sha1_hash.update(data)
return sha1_hash.hexdigest()
def output_sha1sum(data: bytes, filename: str = "-") -> None:
print(f"{sha1sum(data)} {filename}")
def main(args: List[str]) -> None:
if not args:
args = ["-"]
for arg in args:
if arg == "-":
output_sha1sum(process_stdin(), "-")
else:
output_sha1sum(process_file(arg), arg)
if __name__ == "__main__":
main(sys.argv[1:])
两个惯例适用于这个新的sha1sum版本:
- 在没有任何参数的情况下,程序期望在标准输入中提供数据,
sys.stdin,这是一个可读的文件对象。 - 当在命令行提供一个连字符(
-)作为文件参数时,程序将其解释为从标准输入中读取文件。
尝试这个没有任何参数的新脚本。输入Python 之禅的第一句警句,然后在类 Unix 系统上用键盘快捷键 Ctrl + D 或在 Windows 上用键盘快捷键 Ctrl + Z 完成输入:
$ python sha1sum_stdin.py
Beautiful is better than ugly.
ae5705a3efd4488dfc2b4b80df85f60c67d998c4 -
您还可以将其中一个参数作为stdin与其他文件参数混合,如下所示:
$ python sha1sum_stdin.py main.py - main.c
d84372fc77a90336b6bb7c5e959bcb1b24c608b4 main.py
Beautiful is better than ugly.
ae5705a3efd4488dfc2b4b80df85f60c67d998c4 -
125a0f900ff6f164752600550879cbfabb098bc3 main.c
类 Unix 系统上的另一种方法是提供/dev/stdin而不是-来处理标准输入:
$ python sha1sum_stdin.py main.py /dev/stdin main.c
d84372fc77a90336b6bb7c5e959bcb1b24c608b4 main.py
Beautiful is better than ugly.
ae5705a3efd4488dfc2b4b80df85f60c67d998c4 /dev/stdin
125a0f900ff6f164752600550879cbfabb098bc3 main.c
在 Windows 上没有与/dev/stdin等价的东西,所以使用-作为文件参数可以达到预期的效果。
脚本sha1sum_stdin.py并没有涵盖所有必要的错误处理,但是您将在本教程的后面部分涵盖一些缺失的特性。
标准输出和标准误差
命令行处理可能与stdin有直接关系,以遵守前一节中详述的约定。标准输出虽然不是直接相关的,但如果你想坚持 Unix 哲学 T2,它仍然是一个问题。为了允许组合小程序,您可能必须考虑三个标准流:
stdinstdoutstderr
一个程序的输出成为另一个程序的输入,允许你链接小的实用程序。例如,如果您想要对 Python 的 Zen 的格言进行排序,那么您可以执行以下内容:
$ python -c "import this" | sort
Although never is often better than *right* now.
Although practicality beats purity.
Although that way may not be obvious at first unless you're Dutch.
...
为了更好的可读性,上面的输出被截断了。现在假设您有一个程序,它输出相同的数据,但也打印一些调试信息:
# zen_sort_debug.py
print("DEBUG >>> About to print the Zen of Python")
import this
print("DEBUG >>> Done printing the Zen of Python")
执行上面的 Python 脚本给出了:
$ python zen_sort_debug.py
DEBUG >>> About to print the Zen of Python
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
...
DEBUG >>> Done printing the Zen of Python
省略号 ( ...)表示输出被截断以提高可读性。
现在,如果您想对格言列表进行排序,那么执行如下命令:
$ python zen_sort_debug.py | sort
Although never is often better than *right* now.
Although practicality beats purity.
Although that way may not be obvious at first unless you're Dutch.
Beautiful is better than ugly.
Complex is better than complicated.
DEBUG >>> About to print the Zen of Python
DEBUG >>> Done printing the Zen of Python
Errors should never pass silently.
...
您可能意识到您并不打算将调试输出作为sort命令的输入。为了解决这个问题,您希望将跟踪发送到标准错误流stderr,而不是:
# zen_sort_stderr.py
import sys
print("DEBUG >>> About to print the Zen of Python", file=sys.stderr)
import this
print("DEBUG >>> Done printing the Zen of Python", file=sys.stderr)
执行zen_sort_stderr.py观察以下内容:
$ python zen_sort_stderr.py | sort
DEBUG >>> About to print the Zen of Python
DEBUG >>> Done printing the Zen of Python
Although never is often better than *right* now.
Although practicality beats purity.
Although that way may not be obvious at first unless you're Dutch
....
现在,轨迹显示在终端上,但是它们不用作sort命令的输入。
自定义解析器
如果参数不太复杂,可以依靠正则表达式来实现seq。然而,正则表达式模式可能会很快使脚本的维护变得困难。在尝试从特定的库获得帮助之前,另一种方法是创建一个定制的解析器。解析器是一个循环,它一个接一个地获取每个参数,并根据程序的语义应用定制的逻辑。
处理seq_parse.py的自变量的可能实现如下:
1def parse(args: List[str]) -> Tuple[str, List[int]]:
2 arguments = collections.deque(args)
3 separator = "\n"
4 operands: List[int] = []
5 while arguments:
6 arg = arguments.popleft()
7 if not operands:
8 if arg == "--help":
9 print(USAGE)
10 sys.exit(0)
11 if arg in ("-s", "--separator"):
12 separator = arguments.popleft()
13 continue
14 try:
15 operands.append(int(arg))
16 except ValueError:
17 raise SystemExit(USAGE)
18 if len(operands) > 3:
19 raise SystemExit(USAGE)
20
21 return separator, operands
给parse()一个没有 Python 文件名的参数列表,并使用 collections.deque() 来获得 .popleft() 的好处,从集合的左边移除元素。随着参数列表中各项的展开,您可以应用程序预期的逻辑。在parse()中,您可以观察到以下内容:
while循环是该函数的核心,当没有更多的参数要解析时,当调用帮助时,或者当出现错误时,该循环终止。- 如果检测到
separator选项,那么下一个参数应该是分隔符。 operands存储用于计算序列的整数。应该至少有一个操作数,最多三个。
下面是parse()的完整版本代码:
# seq_parse.py
from typing import Dict, List, Tuple
import collections
import re
import sys
USAGE = (f"Usage: {sys.argv[0]} "
"[--help] | [-s <sep>] [first [incr]] last")
def seq(operands: List[int], sep: str = "\n") -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
if len(operands) == 2:
first, last = operands
if first > last:
increment = -1
if len(operands) == 3:
first, increment, last = operands
last = last + 1 if increment > 0 else last - 1
return sep.join(str(i) for i in range(first, last, increment))
def parse(args: List[str]) -> Tuple[str, List[int]]:
arguments = collections.deque(args)
separator = "\n"
operands: List[int] = []
while arguments:
arg = arguments.popleft()
if not len(operands):
if arg == "--help":
print(USAGE)
sys.exit(0)
if arg in ("-s", "--separator"):
separator = arguments.popleft() if arguments else None
continue
try:
operands.append(int(arg))
except ValueError:
raise SystemExit(USAGE)
if len(operands) > 3:
raise SystemExit(USAGE)
return separator, operands
def main() -> None:
sep, operands = parse(sys.argv[1:])
if not operands:
raise SystemExit(USAGE)
print(seq(operands, sep))
if __name__ == "__main__":
main()
注意,为了保持例子相对简短,一些错误处理方面被保持在最低限度。
这种手动解析 Python 命令行参数的方法对于一组简单的参数可能就足够了。但是,由于以下原因,当复杂性增加时,它很容易出错:
- 大量的论据
- 参数之间的复杂性和相互依赖性
- 验证根据参数执行
定制方法是不可重用的,需要在每个程序中重新发明轮子。到本教程结束时,您将已经改进了这个手工制作的解决方案,并学会了一些更好的方法。
验证 Python 命令行参数的几种方法
您已经在几个例子中对 Python 命令行参数进行了验证,比如seq_regex.py和seq_parse.py。在第一个例子中,您使用了一个正则表达式,在第二个例子中,您使用了一个定制的解析器。
这两个例子都考虑了相同的方面。他们认为预期的选项是短格式(-s)还是长格式(--separator)。他们考虑了参数的顺序,这样选项就不会放在操作数之后。最后,他们考虑类型、操作数的整数和参数的数量,从一个到三个参数。
使用 Python 数据类进行类型验证
下面是一个概念验证,它试图验证在命令行传递的参数的类型。在以下示例中,您将验证参数的数量及其各自的类型:
# val_type_dc.py
import dataclasses
import sys
from typing import List, Any
USAGE = f"Usage: python {sys.argv[0]} [--help] | firstname lastname age]"
@dataclasses.dataclass
class Arguments:
firstname: str
lastname: str
age: int = 0
def check_type(obj):
for field in dataclasses.fields(obj):
value = getattr(obj, field.name)
print(
f"Value: {value}, "
f"Expected type {field.type} for {field.name}, "
f"got {type(value)}"
)
if type(value) != field.type:
print("Type Error")
else:
print("Type Ok")
def validate(args: List[str]):
# If passed to the command line, need to convert
# the optional 3rd argument from string to int
if len(args) > 2 and args[2].isdigit():
args[2] = int(args[2])
try:
arguments = Arguments(*args)
except TypeError:
raise SystemExit(USAGE)
check_type(arguments)
def main() -> None:
args = sys.argv[1:]
if not args:
raise SystemExit(USAGE)
if args[0] == "--help":
print(USAGE)
else:
validate(args)
if __name__ == "__main__":
main()
除非您在命令行传递了--help选项,否则这个脚本需要两到三个参数:
- 一个强制字符串:
firstname - 一个强制字符串:
lastname - 可选整数:
age
因为sys.argv中的所有项都是字符串,所以如果可选的第三个参数是由数字组成的,您需要将它转换为整数。 str.isdigit() 验证字符串中的所有字符是否都是数字。此外,通过用转换后的参数值构造数据类 Arguments,可以获得两个验证:
- 如果参数的数量与
Arguments所期望的强制字段的数量不一致,那么就会出现一个错误。这是最少两个最多三个字段。 - 如果转换后的类型与
Arguments数据类定义中定义的类型不匹配,那么就会出现错误。
您可以通过下面的执行看到这一点:
$ python val_type_dc.py Guido "Van Rossum" 25
Value: Guido, Expected type <class 'str'> for firstname, got <class 'str'>
Type Ok
Value: Van Rossum, Expected type <class 'str'> for lastname, got <class 'str'>
Type Ok
Value: 25, Expected type <class 'int'> for age, got <class 'int'>
Type Ok
在上面的执行中,参数的数量是正确的,每个参数的类型也是正确的。
现在,执行相同的命令,但省略第三个参数:
$ python val_type_dc.py Guido "Van Rossum"
Value: Guido, Expected type <class 'str'> for firstname, got <class 'str'>
Type Ok
Value: Van Rossum, Expected type <class 'str'> for lastname, got <class 'str'>
Type Ok
Value: 0, Expected type <class 'int'> for age, got <class 'int'>
Type Ok
结果也是成功的,因为字段age是用默认值、0定义的,所以数据类Arguments不需要它。
相反,如果第三个参数的类型不正确,比如说,字符串而不是整数,那么就会出现错误:
python val_type_dc.py Guido Van Rossum
Value: Guido, Expected type <class 'str'> for firstname, got <class 'str'>
Type Ok
Value: Van, Expected type <class 'str'> for lastname, got <class 'str'>
Type Ok
Value: Rossum, Expected type <class 'int'> for age, got <class 'str'>
Type Error
期望值Van Rossum没有用引号括起来,所以它被拆分了。姓氏的第二个单词Rossum,是一个作为年龄处理的字符串,应该是一个int。验证失败。
**注意:**关于 Python 中数据类用法的更多细节,请查看Python 3.7 中数据类的终极指南。
同样,您也可以使用 NamedTuple 来实现类似的验证。你可以用一个从NamedTuple派生的类替换数据类,然后check_type()会如下变化:
from typing import NamedTuple
class Arguments(NamedTuple):
firstname: str
lastname: str
age: int = 0
def check_type(obj):
for attr, value in obj._asdict().items():
print(
f"Value: {value}, "
f"Expected type {obj.__annotations__[attr]} for {attr}, "
f"got {type(value)}"
)
if type(value) != obj.__annotations__[attr]:
print("Type Error")
else:
print("Type Ok")
一个NamedTuple公开了类似于_asdict的函数,这些函数将对象转换成可用于数据查找的字典。它还公开了像__annotations__这样的属性,这是一个为每个字段存储类型的字典,关于__annotations__的更多信息,请查看 Python 类型检查(指南)。
正如在 Python 类型检查(指南)中所强调的,您还可以利用现有的包,如 Enforce 、 Pydantic 和 Pytypes 进行高级验证。
自定义验证
与你之前已经探索过的不同,详细的验证可能需要一些定制的方法。例如,如果您试图使用不正确的文件名作为参数来执行sha1sum_stdin.py,那么您会得到以下结果:
$ python sha1sum_stdin.py bad_file.txt
Traceback (most recent call last):
File "sha1sum_stdin.py", line 32, in <module>
main(sys.argv[1:])
File "sha1sum_stdin.py", line 29, in main
output_sha1sum(process_file(arg), arg)
File "sha1sum_stdin.py", line 9, in process_file
return pathlib.Path(filename).read_bytes()
File "/usr/lib/python3.8/pathlib.py", line 1222, in read_bytes
with self.open(mode='rb') as f:
File "/usr/lib/python3.8/pathlib.py", line 1215, in open
return io.open(self, mode, buffering, encoding, errors, newline,
File "/usr/lib/python3.8/pathlib.py", line 1071, in _opener
return self._accessor.open(self, flags, mode)
FileNotFoundError: [Errno 2] No such file or directory: 'bad_file.txt'
不存在,但程序试图读取它。
重新访问sha1sum_stdin.py中的main(),以处理在命令行传递的不存在的文件:
1def main(args):
2 if not args:
3 output_sha1sum(process_stdin())
4 for arg in args:
5 if arg == "-":
6 output_sha1sum(process_stdin(), "-")
7 continue
8 try: 9 output_sha1sum(process_file(arg), arg) 10 except FileNotFoundError as err: 11 print(f"{sys.argv[0]}: {arg}: {err.strerror}", file=sys.stderr)
要查看这个额外验证的完整示例,请展开下面的代码块:
# sha1sum_val.py
from typing import List
import hashlib
import pathlib
import sys
def process_file(filename: str) -> bytes:
return pathlib.Path(filename).read_bytes()
def process_stdin() -> bytes:
return bytes("".join(sys.stdin), "utf-8")
def sha1sum(data: bytes) -> str:
m = hashlib.sha1()
m.update(data)
return m.hexdigest()
def output_sha1sum(data: bytes, filename: str = "-") -> None:
print(f"{sha1sum(data)} {filename}")
def main(args: List[str]) -> None:
if not args:
output_sha1sum(process_stdin())
for arg in args:
if arg == "-":
output_sha1sum(process_stdin(), "-")
continue
try:
output_sha1sum(process_file(arg), arg)
except (FileNotFoundError, IsADirectoryError) as err:
print(f"{sys.argv[0]}: {arg}: {err.strerror}", file=sys.stderr)
if __name__ == "__main__":
main(sys.argv[1:])
当您执行这个修改后的脚本时,您会得到:
$ python sha1sum_val.py bad_file.txt
sha1sum_val.py: bad_file.txt: No such file or directory
注意,显示到终端的错误被写入stderr,因此它不会干扰读取sha1sum_val.py输出的命令所期望的数据:
$ python sha1sum_val.py bad_file.txt main.py | cut -d " " -f 1
sha1sum_val.py: bad_file.txt: No such file or directory
d84372fc77a90336b6bb7c5e959bcb1b24c608b4
该命令通过管道将sha1sum_val.py的输出传输到 cut 以仅包括第一场。你可以看到cut忽略了错误信息,因为它只接收发送给stdout的数据。
Python 标准库
尽管您采用了不同的方法来处理 Python 命令行参数,但是任何复杂的程序都可能更好地利用现有的库来处理复杂的命令行接口所需的繁重工作。从 Python 3.7 开始,标准库中有三个命令行解析器:
标准库中推荐使用的模块是argparse。标准库也公开了optparse,但是它已经被官方否决了,在这里只是作为参考。在 Python 3.2 中,它被argparse所取代,你不会在本教程中看到对它的讨论。
argparse
你将重访sha1sum的最新克隆sha1sum_val.py,介绍argparse的好处。为此,您将修改main()并添加init_argparse来实例化argparse.ArgumentParser:
1import argparse
2
3def init_argparse() -> argparse.ArgumentParser:
4 parser = argparse.ArgumentParser(
5 usage="%(prog)s [OPTION] [FILE]...",
6 description="Print or check SHA1 (160-bit) checksums."
7 )
8 parser.add_argument(
9 "-v", "--version", action="version",
10 version = f"{parser.prog} version 1.0.0"
11 )
12 parser.add_argument('files', nargs='*')
13 return parser
14
15def main() -> None:
16 parser = init_argparse()
17 args = parser.parse_args()
18 if not args.files:
19 output_sha1sum(process_stdin())
20 for file in args.files:
21 if file == "-":
22 output_sha1sum(process_stdin(), "-")
23 continue
24 try:
25 output_sha1sum(process_file(file), file)
26 except (FileNotFoundError, IsADirectoryError) as err:
27 print(f"{sys.argv[0]}: {file}: {err.strerror}", file=sys.stderr)
与之前的实现相比,只需要多几行代码,就可以获得一种清晰的方法来添加以前不存在的--help和--version选项。对象 argparse.Namespace 的字段files中有所有期望的参数(要处理的文件)。通过调用 parse_args() 在第 17 行填充这个对象。
要查看经过上述修改的完整脚本,请展开下面的代码块:
# sha1sum_argparse.py
import argparse
import hashlib
import pathlib
import sys
def process_file(filename: str) -> bytes:
return pathlib.Path(filename).read_bytes()
def process_stdin() -> bytes:
return bytes("".join(sys.stdin), "utf-8")
def sha1sum(data: bytes) -> str:
sha1_hash = hashlib.sha1()
sha1_hash.update(data)
return sha1_hash.hexdigest()
def output_sha1sum(data: bytes, filename: str = "-") -> None:
print(f"{sha1sum(data)} {filename}")
def init_argparse() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(
usage="%(prog)s [OPTION] [FILE]...",
description="Print or check SHA1 (160-bit) checksums.",
)
parser.add_argument(
"-v", "--version", action="version",
version=f"{parser.prog} version 1.0.0"
)
parser.add_argument("files", nargs="*")
return parser
def main() -> None:
parser = init_argparse()
args = parser.parse_args()
if not args.files:
output_sha1sum(process_stdin())
for file in args.files:
if file == "-":
output_sha1sum(process_stdin(), "-")
continue
try:
output_sha1sum(process_file(file), file)
except (FileNotFoundError, IsADirectoryError) as err:
print(f"{parser.prog}: {file}: {err.strerror}", file=sys.stderr)
if __name__ == "__main__":
main()
为了说明您通过在该程序中引入argparse获得的直接好处,请执行以下操作:
$ python sha1sum_argparse.py --help
usage: sha1sum_argparse.py [OPTION] [FILE]...
Print or check SHA1 (160-bit) checksums.
positional arguments:
files
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
要深入了解argparse的细节,请查看如何用 argparse 在 Python 中构建命令行接口。
getopt
getopt起源于 getopt C 函数。它有助于解析命令行和处理选项、选项参数和参数。从seq_parse.py重游parse到使用getopt:
def parse():
options, arguments = getopt.getopt(
sys.argv[1:], # Arguments
'vhs:', # Short option definitions
["version", "help", "separator="]) # Long option definitions
separator = "\n"
for o, a in options:
if o in ("-v", "--version"):
print(VERSION)
sys.exit()
if o in ("-h", "--help"):
print(USAGE)
sys.exit()
if o in ("-s", "--separator"):
separator = a
if not arguments or len(arguments) > 3:
raise SystemExit(USAGE)
try:
operands = [int(arg) for arg in arguments]
except ValueError:
raise SystemExit(USAGE)
return separator, operands
getopt.getopt() 采取了如下论点:
- 通常的参数列表减去脚本名,
sys.argv[1:] - 定义短选项的字符串
- 长选项的字符串列表
请注意,后跟冒号(:)的短选项需要一个选项参数,后跟等号(=)的长选项需要一个选项参数。
seq_getopt.py的剩余代码与seq_parse.py相同,可在下面折叠的代码块中找到:
# seq_getopt.py
from typing import List, Tuple
import getopt
import sys
USAGE = f"Usage: python {sys.argv[0]} [--help] | [-s <sep>] [first [incr]] last"
VERSION = f"{sys.argv[0]} version 1.0.0"
def seq(operands: List[int], sep: str = "\n") -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
elif len(operands) == 2:
first, last = operands
if first > last:
increment = -1
elif len(operands) == 3:
first, increment, last = operands
last = last - 1 if first > last else last + 1
return sep.join(str(i) for i in range(first, last, increment))
def parse(args: List[str]) -> Tuple[str, List[int]]:
options, arguments = getopt.getopt(
args, # Arguments
'vhs:', # Short option definitions
["version", "help", "separator="]) # Long option definitions
separator = "\n"
for o, a in options:
if o in ("-v", "--version"):
print(VERSION)
sys.exit()
if o in ("-h", "--help"):
print(USAGE)
sys.exit()
if o in ("-s", "--separator"):
separator = a
if not arguments or len(arguments) > 3:
raise SystemExit(USAGE)
try:
operands = [int(arg) for arg in arguments]
except:
raise SystemExit(USAGE)
return separator, operands
def main() -> None:
args = sys.argv[1:]
if not args:
raise SystemExit(USAGE)
sep, operands = parse(args)
print(seq(operands, sep))
if __name__ == "__main__":
main()
接下来,您将看到一些外部包,它们将帮助您解析 Python 命令行参数。
几个外部 Python 包
基于您在本教程中看到的现有约定, Python 包索引(PyPI) 中有一些可用的库,它们需要更多的步骤来简化命令行接口的实现和维护。
以下章节简要介绍了点击和 Python 提示工具包。您将只接触到这些包的非常有限的功能,因为它们都需要完整的教程——如果不是整个系列的话——来公正地对待它们!
点击
在撰写本文时, Click 可能是为 Python 程序构建复杂命令行界面的最先进的库。它被几个 Python 产品使用,最著名的是烧瓶和黑。在尝试下面的例子之前,您需要在一个 Python 虚拟环境或者您的本地环境中安装 Click。如果你不熟悉虚拟环境的概念,那么看看 Python 虚拟环境:初级读本。
要安装 Click,请执行以下步骤:
$ python -m pip install click
那么,Click 如何帮助您处理 Python 命令行参数呢?这里有一个使用 Click 的seq程序的变体:
# seq_click.py
import click
@click.command(context_settings=dict(ignore_unknown_options=True))
@click.option("--separator", "-s",
default="\n",
help="Text used to separate numbers (default: \\n)")
@click.version_option(version="1.0.0")
@click.argument("operands", type=click.INT, nargs=-1)
def seq(operands, separator) -> str:
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
elif len(operands) == 2:
first, last = operands
if first > last:
increment = -1
elif len(operands) == 3:
first, increment, last = operands
else:
raise click.BadParameter("Invalid number of arguments")
last = last - 1 if first > last else last + 1
print(separator.join(str(i) for i in range(first, last, increment)))
if __name__ == "__main__":
seq()
将 ignore_unknown_options 设置为True可以确保 Click 不会将负参数解析为选项。负整数是有效的seq参数。
正如你可能已经观察到的,你可以免费得到很多!几个精心雕琢的装饰者就足以埋葬样板代码,让你专注于主要代码,也就是本例中seq()的内容。
**注意:**要了解更多关于 Python 装饰者的信息,请查看关于 Python 装饰者的入门。
剩下的唯一导入是click。修饰主命令seq()的声明性方法消除了重复的代码。这可能是以下任何一种情况:
- 定义帮助或使用程序
- 处理程序的版本
- 捕捉和设置选项默认值
- 验证参数,包括类型
新的seq实现仅仅触及了表面。Click 提供了许多有助于您打造非常专业的命令行界面的细节:
- 输出着色
- 提示省略参数
- 命令和子命令
- 参数类型验证
- 对选项和参数的回调
- 文件路径验证
- 进度条
还有许多其他功能。查看使用 Click 编写 Python 命令行工具的以查看更多基于 Click 的具体示例。
Python 提示工具包
还有其他流行的 Python 包在处理命令行接口问题,比如 Python 的doc opt。所以,你可能会发现选择提示工具包有点违反直觉。
Python Prompt Toolkit 提供的特性可能会让你的命令行应用偏离 Unix 哲学。然而,它有助于在晦涩难懂的命令行界面和成熟的图形用户界面之间架起一座桥梁。换句话说,它可能有助于使你的工具和程序更加用户友好。
除了像前面的例子中一样处理 Python 命令行参数之外,您还可以使用这个工具,但是这为您提供了一个类似 UI 的方法,而不必依赖于完整的 Python UI 工具包。要使用prompt_toolkit,需要安装pip:
$ python -m pip install prompt_toolkit
您可能会觉得下一个例子有点做作,但是它的目的是激发灵感,让您稍微远离命令行中与您在本教程中看到的约定相关的更严格的方面。
正如您已经看到的这个示例的核心逻辑一样,下面的代码片段只显示了与前面的示例明显不同的代码:
def error_dlg():
message_dialog(
title="Error",
text="Ensure that you enter a number",
).run()
def seq_dlg():
labels = ["FIRST", "INCREMENT", "LAST"]
operands = []
while True:
n = input_dialog(
title="Sequence",
text=f"Enter argument {labels[len(operands)]}:",
).run()
if n is None:
break
if n.isdigit():
operands.append(int(n))
else:
error_dlg()
if len(operands) == 3:
break
if operands:
seq(operands)
else:
print("Bye")
actions = {"SEQUENCE": seq_dlg, "HELP": help, "VERSION": version}
def main():
result = button_dialog(
title="Sequence",
text="Select an action:",
buttons=[
("Sequence", "SEQUENCE"),
("Help", "HELP"),
("Version", "VERSION"),
],
).run()
actions.get(result, lambda: print("Unexpected action"))()
上面的代码涉及交互的方法,可能会引导用户输入预期的输入,并使用三个对话框交互地验证输入:
button_dialogmessage_dialoginput_dialog
Python Prompt Toolkit 公开了许多旨在改善与用户交互的其他特性。对main()中处理程序的调用是通过调用存储在字典中的函数来触发的。如果您以前从未遇到过 Python 习语,请查看 Python 中的仿真 switch/case 语句。
您可以通过展开下面的代码块来查看使用prompt_toolkit的程序的完整示例:
# seq_prompt.py
import sys
from typing import List
from prompt_toolkit.shortcuts import button_dialog, input_dialog, message_dialog
def version():
print("Version 1.0.0")
def help():
print("Print numbers from FIRST to LAST, in steps of INCREMENT.")
def seq(operands: List[int], sep: str = "\n"):
first, increment, last = 1, 1, 1
if len(operands) == 1:
last = operands[0]
elif len(operands) == 2:
first, last = operands
if first > last:
increment = -1
elif len(operands) == 3:
first, increment, last = operands
last = last - 1 if first > last else last + 1
print(sep.join(str(i) for i in range(first, last, increment)))
def error_dlg():
message_dialog(
title="Error",
text="Ensure that you enter a number",
).run()
def seq_dlg():
labels = ["FIRST", "INCREMENT", "LAST"]
operands = []
while True:
n = input_dialog(
title="Sequence",
text=f"Enter argument {labels[len(operands)]}:",
).run()
if n is None:
break
if n.isdigit():
operands.append(int(n))
else:
error_dlg()
if len(operands) == 3:
break
if operands:
seq(operands)
else:
print("Bye")
actions = {"SEQUENCE": seq_dlg, "HELP": help, "VERSION": version}
def main():
result = button_dialog(
title="Sequence",
text="Select an action:",
buttons=[
("Sequence", "SEQUENCE"),
("Help", "HELP"),
("Version", "VERSION"),
],
).run()
actions.get(result, lambda: print("Unexpected action"))()
if __name__ == "__main__":
main()
当您执行上面的代码时,会出现一个对话框提示您采取行动。然后,如果您选择动作序列,将显示另一个对话框。收集完所有必要的数据、选项或参数后,对话框消失,结果在命令行打印出来,如前面的示例所示:
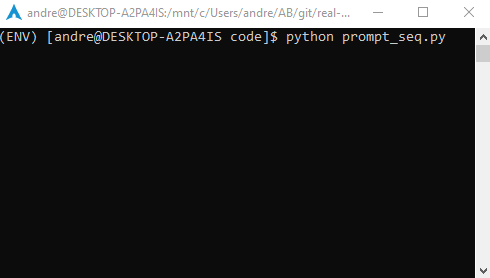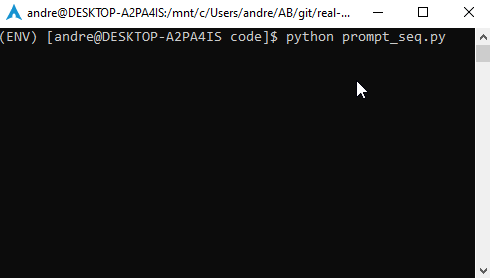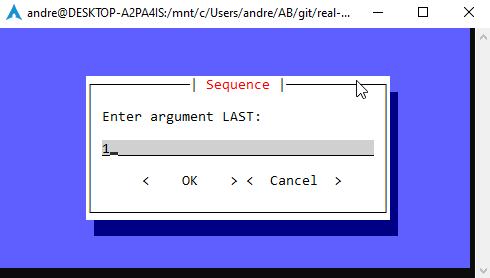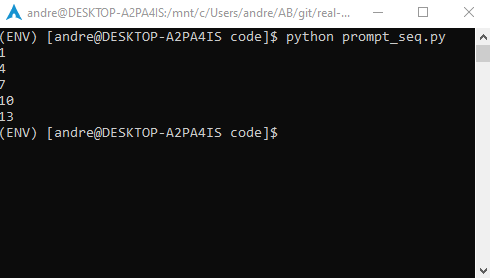
随着命令行的发展,你可以看到一些更有创造性的与用户交互的尝试,其他包如 PyInquirer 也允许你利用一种非常交互式的方法。
为了进一步探索基于文本的用户界面(TUI) 的世界,请查看构建控制台用户界面和您的 Python 打印功能指南中的第三方部分。
如果您有兴趣研究完全依赖图形用户界面的解决方案,那么您可以考虑查看以下资源:
结论
在本教程中,您已经浏览了 Python 命令行参数的许多不同方面。您应该准备好将以下技能应用到您的代码中:
- Python 命令行参数的约定和伪标准
- Python 中
sys.argv的起源 sys.argv的用法提供运行 Python 程序的灵活性- Python 标准库像
argparse或getopt那样抽象命令行处理 - 强大的 Python 包像
click和python_toolkit来进一步提高你的程序的可用性
无论您运行的是小脚本还是复杂的基于文本的应用程序,当您公开一个命令行接口时,您将显著改善 Python 软件的用户体验。事实上,你可能就是这些用户中的一员!
下次使用您的应用程序时,您会感谢您提供的带有--help选项的文档,或者您可以传递选项和参数,而不是修改源代码来提供不同的数据。
额外资源
要进一步了解 Python 命令行参数及其许多方面,您可能希望查阅以下资源:
- 比较 Python 命令行解析库——arg parse、Docopt 和 Click
- Python、Ruby 和 Golang:命令行应用比较
您可能还想尝试其他 Python 库,它们针对相同的问题,同时为您提供不同的解决方案:
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解:Python 中的命令行接口*********


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









