







原文:RealPython
用 Python 编写注释(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 写评论
当用 Python 写代码时,确保你的代码能被其他人容易地理解是很重要的。给变量起一个明显的名字,定义显式函数,以及组织你的代码都是很好的方法。
增加代码可读性的另一个简单又棒的方法是使用注释!
在本教程中,您将了解用 Python 编写注释的一些基础知识。你将学习如何写干净简洁的评论,以及什么时候你可能根本不需要写任何评论。
您还将了解:
- 为什么注释代码如此重要
- 用 Python 编写注释的最佳实践
- 您可能希望避免的评论类型
- 如何练习写更干净的评论
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
为什么注释你的代码如此重要
注释是任何程序不可或缺的一部分。它们可以以模块级文档字符串的形式出现,甚至可以是有助于阐明复杂函数的内联解释。
在深入不同类型的注释之前,让我们仔细看看为什么注释代码如此重要。
考虑下面两种情况,其中一个程序员决定不注释他们的代码。
当读取自己的代码时
客户端 A 想要对他们的 web 服务进行最后的部署。你已经在一个紧张的最后期限,所以你决定让它工作。所有那些“额外”的东西——文档、适当的注释等等——您将在以后添加。
截止日期到了,您准时部署了服务。咻!
你在心里记下回去更新评论,但是在你把它放到你的任务清单上之前,你的老板带着一个你需要立即开始的新项目过来了。几天之内,你已经完全忘记了你应该回去适当地注释你为客户 a 写的代码。
快进六个月,客户端 A 需要为相同的服务构建一个补丁,以符合一些新的要求。维护它是你的工作,因为你是最初建造它的人。你打开你的文本编辑器…
你到底写了什么?!
你花了几个小时解析你的旧代码,但你完全迷失在混乱中。当时你太匆忙了,以至于没有正确命名变量,甚至没有在正确的控制流中设置函数。最糟糕的是,你在脚本中没有任何注释来告诉你什么是什么!
开发人员总是忘记他们自己的代码是做什么的,特别是如果它是很久以前或者在很大压力下写的。当最后期限快到了,在电脑前的几个小时已经导致眼睛充血,双手抽筋,这种压力可以以比平时更混乱的代码形式反映出来。
一旦提交了项目,许多开发人员就懒得回去评论他们的代码了。当以后需要重新审视它的时候,他们会花上几个小时试图解析他们所写的内容。
边走边写注释是防止上述情况发生的好方法。对未来的你好点!
当别人阅读你的代码时
想象一下,你是唯一一个从事小型 Django 项目的开发人员。您非常了解自己的代码,所以您不倾向于使用注释或任何其他类型的文档,并且您喜欢这样。评论是需要时间去写和维护的,你就是看不到重点。
唯一的问题是,到年底,你的“小 Django 项目”已经变成了“20,000 行代码”的项目,你的主管带来了额外的开发人员来帮助维护它。
新的开发人员努力工作以快速达到速度,但是在一起工作的头几天,你已经意识到他们遇到了一些麻烦。您使用了一些古怪的变量名,并用超级简洁的语法编写。新员工花大量时间一行一行地检查你的代码,试图弄清楚它是如何工作的。他们甚至需要几天时间才能帮你维护它!
在你的代码中使用注释可以帮助其他开发者。注释有助于其他开发人员浏览您的代码,并很快理解它是如何工作的。通过选择从项目一开始就对代码进行注释,可以帮助确保平稳的过渡。
如何用 Python 写注释
既然你已经理解了注释你的代码的重要性,让我们回顾一些基础知识,这样你就知道如何正确地做了。
Python 注释基础知识
评论是给开发者看的。它们在必要的地方描述了代码的各个部分,以方便程序员的理解,包括你自己。
要用 Python 写注释,只需在您想要的注释前加上散列符号#:
# This is a comment
Python 会忽略散列标记之后直到行尾的所有内容。您可以将它们插入代码中的任何位置,甚至与其他代码内联:
print("This will run.") # This won't run
当你运行上面的代码时,你只会看到输出This will run.,其他的都被忽略了。
评论应该简短、甜蜜、切中要害。虽然 PEP 8 建议每行代码保持在 79 个字符或更少,但它建议行内注释和文档字符串最多 72 个字符。如果你的评论接近或超过了这个长度,那么你需要把它分散到多行中。
Python 多行注释
不幸的是,Python 无法像其他语言一样编写多行注释,比如 C 、 Java 和 Go:
# So you can't
just do this
in python
在上面的例子中,第一行将被程序忽略,但是其他行将引发一个语法错误。
相比之下,像 Java 这样的语言将允许您非常容易地将注释分散到多行中:
/* You can easily
write multiline
comments in Java */
程序会忽略/*和*/之间的所有内容。
虽然 Python 本身没有多行注释功能,但是您可以在 Python 中创建多行注释。有两种简单的方法可以做到这一点。
第一种方法是在每一行之后按下return键,添加一个新的散列标记,然后从那里继续您的注释:
def multiline_example():
# This is a pretty good example
# of how you can spread comments
# over multiple lines in Python
以散列符号开头的每一行都将被程序忽略。
另一种方法是使用多行字符串,将注释放在一组三重引号中:
"""
If I really hate pressing `enter` and
typing all those hash marks, I could
just do this instead
"""
这就像 Java 中的多行注释,三重引号中的所有内容都将作为注释。
虽然这为您提供了多行功能,但从技术上讲,这并不是注释。它是一个没有赋值给任何变量的字符串,所以你的程序不会调用或引用它。尽管如此,因为它在运行时会被忽略,不会出现在字节码中,所以它可以有效地充当注释。(你可以看看这篇文章来证明这些字符串不会出现在字节码中。)
但是,在放置这些多行“注释”时要小心根据它们在程序中的位置,它们可能会变成文档串,这些文档串是与函数或方法相关联的文档。如果你在一个函数定义后面加上一个坏男孩,那么你原本打算作为注释的东西将会和这个对象相关联。
在使用这些的时候要小心,如果有疑问,就在后面的每一行加上一个散列符号。如果您有兴趣了解更多关于 docstrings 以及如何将它们与模块、类等相关联的信息,请查看我们关于记录 Python 代码的教程。
Python 注释快捷键
每次需要添加注释时,都要键入所有这些散列符号,这可能很乏味。那么,你能做些什么来加快速度呢?这里有几个技巧可以帮助你在评论时摆脱困境。
您可以做的第一件事就是使用多个游标。听起来就是这样:在屏幕上放置多个光标来完成一项任务。只需按住 Ctrl 或 Cmd 键,同时单击鼠标左键,您应该会在屏幕上看到闪烁的线条:

当你需要在几个地方评论同一件事时,这是最有效的。
如果你有一段很长的文本需要注释掉呢?假设您不希望运行一个已定义的函数来检查 bug。点击每一行注释掉它会花费很多时间!在这种情况下,您需要切换注释。只需选择所需代码,在 PC 上按 Ctrl + / ,在 Mac 上按 Cmd + / :
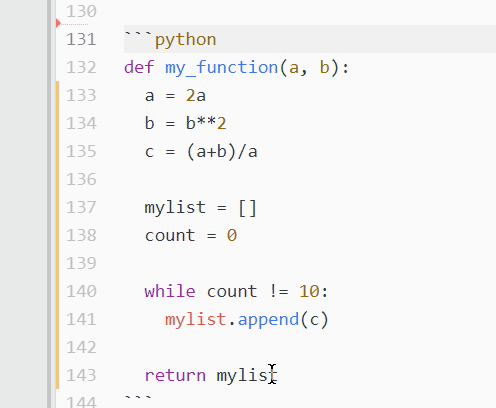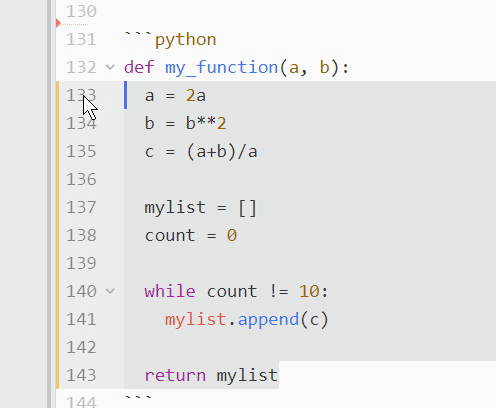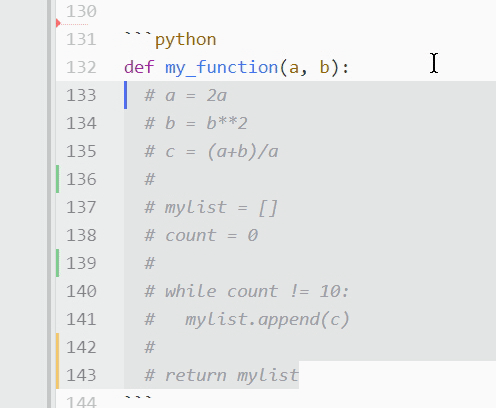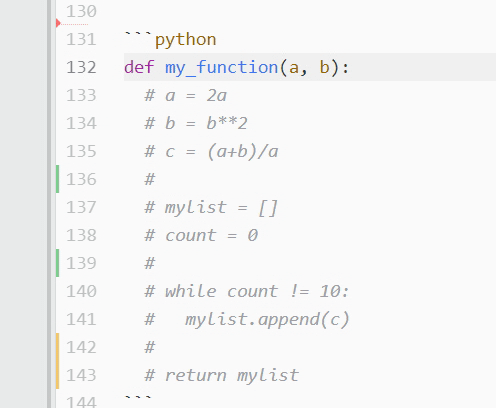
所有突出显示的文本都将加上一个散列标记,并被程序忽略。
如果您的注释变得过于笨拙,或者您正在阅读的脚本中的注释非常长,那么您的文本编辑器可能会让您选择使用左侧的小向下箭头折叠它们:

只需点击箭头隐藏评论。这最适用于多行的长注释,或者占据程序大部分开头的文档字符串。
结合这些技巧将会使你的代码注释变得快速、简单、轻松!
Python 注释最佳实践
虽然知道如何用 Python 写注释是很好的,但确保您的注释可读且易于理解也同样重要。
看看这些提示,帮助你写出真正支持你的代码的注释。
给自己写代码的时候
通过适当地注释您自己的代码,您可以让自己的生活更轻松。即使没有其他人会看到它,你也会看到它,这就足够让它变得正确。毕竟你是一名开发人员,所以你的代码也应该易于理解。
使用注释的一个非常有用的方法是作为代码的大纲。如果你不确定你的程序结果如何,那么你可以使用注释作为一种跟踪剩余工作的方式,或者甚至作为一种跟踪程序高级流程的方式。例如,使用注释来概述伪代码中的函数:
from collections import defaultdict
def get_top_cities(prices):
top_cities = defaultdict(int)
# For each price range
# Get city searches in that price
# Count num times city was searched
# Take top 3 cities & add to dict
return dict(top_cities)
这些评论策划出来get_top_cities()。一旦你确切地知道你想要你的函数做什么,你就可以把它翻译成代码。
使用这样的评论可以帮助你保持头脑清醒。当你浏览你的程序时,你会知道为了有一个功能完整的脚本还需要做什么。在将注释“翻译”成代码之后,记得删除任何多余的注释,这样你的代码就会保持清晰和整洁。
您也可以使用注释作为调试过程的一部分。注释掉旧代码,看看这会如何影响您的输出。如果你同意这个改变,那么不要在你的程序中把代码注释掉,因为这会降低可读性。如果需要恢复它,请删除它并使用版本控制。
最后,使用注释来定义您自己代码中的棘手部分。如果你放下一个项目,几个月或几年后再回来,你会花很多时间试图重新熟悉你写的东西。万一你忘记了你自己的代码是做什么的,那就帮你自己一个忙,把它记下来,这样以后就可以更容易地恢复速度了。
为他人编写代码时
人们喜欢在文本中快速浏览和来回跳转,阅读代码也不例外。你可能一行一行地通读代码的唯一时间是当它不工作的时候,你必须弄清楚发生了什么。
在大多数其他情况下,您将快速浏览一下变量和函数定义,以便获得要点。在这种情况下,用简单的英语来解释正在发生的事情确实可以帮助开发人员。
善待你的开发伙伴,使用注释来帮助他们浏览你的代码。内联注释应该有节制地使用,以清除那些本身不明显的代码。(当然,您的首要任务应该是让您的代码独立存在,但是行内注释在这方面会很有用。)
如果你有一个复杂的方法或函数,它的名字不容易理解,你可能想在def行后面加上一个简短的注释来说明一些问题:
def complicated_function(s):
# This function does something complicated
这可以帮助其他浏览你的代码的开发人员了解这个函数的功能。
对于任何公共函数,您都希望包含一个关联的 docstring,不管它是否复杂:
def sparsity_ratio(x: np.array) -> float:
"""Return a float
Percentage of values in array that are zero or NaN
"""
该字符串将成为函数的.__doc__属性,并正式与该特定方法相关联。PEP 257 docstring 指南将帮助你构建你的 docstring。这些是开发人员在构造文档字符串时通常使用的一组约定。
PEP 257 指南对多行文档字符串也有约定。这些文档字符串出现在文件的顶部,包括对整个脚本及其功能的高级概述:
# -*- coding: utf-8 -*-
"""A module-level docstring
Notice the comment above the docstring specifying the encoding.
Docstrings do appear in the bytecode, so you can access this through
the ``__doc__`` attribute. This is also what you'll see if you call
help() on a module or any other Python object.
"""
像这样的模块级 docstring 将包含开发人员阅读它时需要知道的任何相关信息。当编写一个时,建议列出所有的类、异常和函数,并为每个列出一行摘要。
Python 评论最差实践
正如编写 Python 注释有标准一样,有几种类型的注释不会导致 Python 代码。这里只是几个。
避免:W.E.T .评论
你的评论应该是 D.R.Y .缩写代表编程格言“不要重复自己。”这意味着你的代码应该很少或者没有冗余。你不需要注释一段足以解释它自己的代码,就像这样:
return a # Returns a
我们可以清楚地看到,a被返回,所以没有必要在注释中明确声明这一点。这使得注释成为 W.E.T .,意味着你“每件事都写了两遍。”(或者,对于更愤世嫉俗的人来说,“浪费了每个人的时间。”)
W.E.T .注释可能是一个简单的错误,特别是如果你在写代码之前使用注释来规划代码。但是一旦你让代码运行良好,一定要回去删除那些变得不必要的注释。
忌:臭评论
注释可能是“代码味道”的标志,这意味着您的代码可能存在更深层次的问题。代码味道试图掩盖程序的潜在问题,而注释是试图隐藏这些问题的一种方式。评论应该支持你的代码,而不是试图解释它。如果你的代码写得很差,再多的注释也无法修复它。
让我们举一个简单的例子:
# A dictionary of families who live in each city
mydict = {
"Midtown": ["Powell", "Brantley", "Young"],
"Norcross": ["Montgomery"],
"Ackworth": []
}
def a(dict):
# For each city
for p in dict:
# If there are no families in the city
if not mydict[p]:
# Say that there are no families
print("None.")
这段代码相当难懂。每一行之前都有一个注释来解释代码的作用。通过为变量、函数和集合指定明显的名称,这个脚本可以变得更简单,如下所示:
families_by_city = {
"Midtown": ["Powell", "Brantley", "Young"],
"Norcross": ["Montgomery"],
"Ackworth": [],
}
def no_families(cities):
for city in cities:
if not families_by_city[city]:
print(f"No families in {city}.")
通过使用显而易见的命名约定,我们能够删除所有不必要的注释并减少代码长度!
您的注释应该很少比它们支持的代码长。如果你花了太多时间来解释你做了什么,那么你需要回去重构,使你的代码更加清晰和简洁。
避免:粗鲁的评论
这是在开发团队中工作时可能会遇到的事情。当几个人都在处理同一个代码时,其他人会进去检查你写的东西并进行修改。有时,你可能会碰到有人敢写这样的评论:
# Put this here to fix Ryan's stupid-a** mistake
老实说,不这么做是个好主意。如果是你朋友的代码就没关系,你确定他们不会因此而被冒犯。你永远不知道什么可能会被发布到产品中,如果你不小心把那个评论留在那里,然后被客户发现了,会是什么样子?你是专业人士,在你的评论中包含粗俗的词语不是展示这一点的方式。
如何练习评论
开始写更多 Pythonic 注释的最简单的方法就是去做!
开始用自己的代码为自己写注释。从现在开始,在必要的地方加入简单的评论。为复杂的函数增加一些清晰度,并在所有脚本的顶部放置一个 docstring。
另一个很好的练习方法是回顾你写的旧代码。看看哪些地方可能没有意义,并清理代码。如果它仍然需要一些额外的支持,添加一个简短的注释来帮助阐明代码的目的。
如果你的代码在 GitHub 上,并且人们正在分叉你的回购,这是一个特别好的主意。通过引导他们完成您已经完成的工作来帮助他们开始。
也可以通过评论别人的代码来回馈社区。如果你已经从 GitHub 下载了一些东西,并且在筛选的时候遇到了困难,当你开始理解每段代码是做什么的时候,添加注释。
在您的评论上“签名”您的姓名首字母和日期,然后提交您的更改作为拉请求。如果您的更改被合并,您可能会帮助几十个甚至几百个像您一样的开发人员在他们的下一个项目中取得优势。
结论
学会好好评论是一个很有价值的工具。一般来说,你不仅会学到如何更清晰、更简洁地写作,而且毫无疑问,你也会对 Python 有更深的理解。
知道如何用 Python 写注释可以让所有开发者的生活变得更轻松,包括你自己!他们可以帮助其他开发人员了解你的代码所做的事情,并帮助你重新熟悉你自己的旧代码。
通过注意当你使用注释来尝试和支持写得很差的代码时,你将能够回过头来修改你的代码,使之更加健壮。注释以前编写的代码,无论是您自己的还是其他开发人员的,都是练习用 Python 编写简洁注释的好方法。
随着您对编写代码了解的越来越多,您可以考虑进入下一个文档级别。查看我们的教程记录 Python 代码以采取下一步行动。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 写评论******
python 社区采访黄铁矿的 bob 和 julian
原文:https://realpython.com/python-community-interview-bob-and-julian-pybites/
本周,我和 PyBites 乐队的鲍勃·贝尔德博斯和 T2·朱利安·塞杰拉在一起。Bob 是西班牙甲骨文公司的一名软件开发人员。Julian 是澳大利亚亚马逊网络服务公司的一名数据中心技术人员。
加入我们,一起讨论 PyBites 是如何起步的,以及他们对未来有什么打算。我们还会调查鲍勃对绘画的秘密爱好以及朱利安对好酒的秘密爱好。
里基: 欢迎,鲍勃和朱利安!或者是朱利安和鲍勃?不管是哪种情况,谢谢你参加这次面试。让我们从通常的第一个问题开始。你是怎么进入编程的?你是什么时候开始用 Python 的?

朱利安:我们更喜欢用“布尔”不完全是,但是让我们坚持下去。
我第一次被编程错误(双关语!)回到高中,但在 2015 年末真正投身于编程。
我需要一种方法来跟踪我在 Oracle 担任现场工程师时的加班时间,以确保我得到正确的报酬。输入 Python(在 Bob 的推荐下)。
我给自己做了一个 CLI 加班跟踪器,包括一个基本的菜单系统,带有简单的选项来计算我的税后加班工资。这是最基本的,非常有效,让我迷上了 Python。
提示:是真实世界的用例让学习变得更有意义!
与我使用 C++的高中时代相比,Python 的速度和简单性让我着迷。然后我们开始 PyBites,蟒蛇变得真实。(真正的 Python ,懂了吗?)

对我来说,这一切要追溯到 2009 年的太阳微系统公司。我加入了系统支持小组,找到了一个合适的位置来开发一个 web 应用程序来解析诊断输出,我们每个月都会收到数千个这样的输出。这成为支持组织的主要工具,每天为他们节省了无数小时的繁琐工作。
这个诊断工具是 shell 脚本(bash/sed/awk)、Perl、PHP 和一些 jQuery 的混合。企业决定转向服务请求的完全自动化,为此我用 Perl 编写了一个新的框架,这很快成为维护的噩梦,所以我开始寻找其他解决方案。
这是在 2012 年。我偶然发现了 Python 并开始学习它。这是一见钟情:它干净优雅的设计( type import this in your REPL ),没有括号和其他类似 C 的语法,读起来就像英语!学习 Python 的基础很简单,但是在幕后,它是非常通用的。
在 Linux Journal 上有一篇 Eric Raymond 的很棒的文章,题目是 为什么是 Python? ,描述了他从 Perl 转向 Python 时的启示。
我也经历过类似的事情。在用 Python 快速重写自动化框架之后,进行更改变得相对“容易”,并且我们用许多令人兴奋的新特性对其进行了扩展,所有这些都没有大的麻烦。虽然我转换到了另一个角色,但解决方案仍然得到了积极的维护。从那以后,我有幸在几乎所有的工作中使用 Python。
瑞奇: 你们两个都是最出名的(不管是好是坏),因为你们都是皮比特的联合创始人。对于不了解 PyBites 的人来说,它是什么,又是怎么开始的?
PyBites 最初只是一个简单的博客,分享我们在 Python 领域的学习。(我们使用名为鹈鹕的静态站点生成器。)我们热衷于推动自己超越仅仅阅读书籍和观看视频。写博客文章让我们真正深入下去,以确保我们传达的是正确的概念。
它成立后不久,我们就开始试验一些想法。一个是挑战自我,受到诺亚·卡根的咖啡挑战的启发。所以有一天 Bob 提出了一个 Python 练习,让我们在周末之前解决。
我们发现了一个 JavaScript 课程页面,上面有每个视频的mm:ss计时,但没有总时长。任务是浏览网站,把所有的视频时间戳加起来,计算课程的总时长。
在周末(sprint),我们比较了我们的解决方案,回顾了我们的学习成果。我们有“搏击俱乐部时刻”(也许没有那么暴力……)“我们应该找个时间再来一次”,这就是我们的博客/社区代码挑战热线的诞生。
我们研究了 GitHub,为我们建立了一个挑战报告来发布我们的挑战和解决方案,然后创建了一个单独的社区分支,让其他人请求他们的工作。
我们从中获得的动力激发了这个想法,这个想法成为了我们的编码平台: CodeChalleng.es 。它由不断增长的近 200 个 Python 练习(称为 Py 的片段)组成,您可以在自己的浏览器中舒适地编写代码。
对我们来说,另一件大事是完成 #100DaysOfCode 挑战,我们在博客和社交媒体上积极分享了这一挑战。这让我们在 Talk Python 播客上接受了采访,反过来,也让我们与 Michael Kennedy 一起制作了 #100DaysOfCode in Python 课程。
对我们来说,重要的一课是,你只需要开始行动,放弃完美主义。发生的许多令人敬畏的事情不是计划好的,而是因为我们把一些产生兴趣的东西放在那里而来到我们身边,我们在这个过程中根据我们收到的有价值的反馈采取行动!
朱利安,你白天不是程序员,你在亚马逊网络服务公司做数据中心技术员。和像 Bob 这样有成就的人一起学习编程感觉如何?我认为找一个更有经验的人做你的生意伙伴会有帮助?在你学习编码的过程中,有什么让你感到惊讶或感到困难的事情吗?
我和鲍勃之间的鸿沟一直是 PyBites 的基石。实际上,我们认为这会给我们的博客一个独特的旋转!
为此,情况有点复杂。当你和像 Bob 这样有能力的人一起编码时,第一感觉是敬畏。你可以看到他们代码的优雅,以及他们在瞬间解决你花了几个小时解决的问题的能力。真的很励志!
但并不总是如此。很容易陷入冒名顶替综合症的陷阱:
- “我的代码还会一样好吗?”
- “我为什么要烦恼?”
- “他总是会变得更好!”
现实是,总会有更好的人来写代码,总会有更好的人来生活!我很快认识到,与其关注技能差距,我应该关注我自己的代码,为我的成就感到自豪,并拥抱我带来的东西。
有趣的是,这适用于我们两个人,我们在学习和管理代码时遇到的困难可以忽略不计。也就是我们接受它,热爱它。(我现在这样说,但绝不是在当下!)
令人惊讶的困难部分是 PyBites 的实际业务方面!我还要补充一点,我不做专业程序员的日子可能要结束了!(嘘!)
鲍勃,用你自己的话来说,当你在日常工作中“不为男人努力工作”时,你喜欢在业余时间修补和建造项目。你目前有什么样的项目在进行中?
目前,我几乎所有的时间都花在了制作课程内容和通过增加更多练习和功能来改进我们的平台上。随着使用的增加,会有更多的问题和反馈/请求,但是我很喜欢它的每一分钟,因为它提供了一个教授 Python 和指导其他开发人员的好方法,这是我非常喜欢的。
我还参加了 Coursera 应用数据科学专业,因为我热爱数据,并希望在日常工作中更多地融入这些数据。
当这个和我们即将开始的课程(悬念… )完成后,我的默认工作流程仍然是相似的:
- 接受一个新概念(Python 模块、数据、web 技术、自动化机会等等)
- 研究一下
- 做一些很酷的东西,然后写博客/分享这个过程
这是我所热爱的,也是 PyBites 不断增长的内容的一部分。
这实际上是我推荐给任何程序员/开发人员的。简历是遗产。开始建立你的博客/GitHub/品牌,这样你就有一个可以展示的作品集了。它还使您能够在未来的项目中重复使用您所构建的内容,这是一种与他人建立网络/协作的好方法。
里基: 很明显,你们俩都有企业家的基因。(你只要看看鲍勃的书架就能看到证据。)对你来说,创业/副业(PyBites)最困难或最具挑战性的部分是什么?你发现你们各自的才能互相抵消了吗?
最具挑战性的部分无疑是管理我们的优先事项。
我们两个人生活中最重要的事情碰巧非常相似:
- 家人/孩子
- 全职工作
- 学问
- 硫化铁矿
随着 PyBites 的增长,所需的时间投资也在增长。我们不能把这些时间从日常工作或家庭中抽出来,所以这无疑是试图找到一个可接受的平衡的最大障碍。
我们采取的观点是“如果我们有时间看网飞,那么我们就有时间研究俾比特人。”
为此,我们常常有意识地选择不看电视、不玩游戏或不出门,把这些时间变成我们的时间。这听起来没什么,但是在漫长的一天工作和哄孩子睡觉之后,重新使用工具来研究 PyBites 是非常具有挑战性的!
也就是说,我们公开告诉任何愿意倾听的人,如果没有彼此的相互支持,我们就不会有今天。
如果你在做任何有价值的事情,那么给自己找一个负责任的伙伴。我们让对方对我们接手的项目负责,当事情不尽如人意时,我们互相扶持。
我们不同的才能肯定会互相抵消。Julian 更倾向于作家、讲故事者、营销者、业务经理和“代言人”,而 Bob 深入研究代码,构建和维护工具,提出令人难以置信的想法,并在技术上支持社区。结合这两种才能,你就有了一台运转良好的 PyBites 机器。
最好的部分(并且坚持我们的核心信念,即你从实践中学习)是我们互相学习。我们互相推动,不断改进,跳出框框,不断尝试新事物。
里基: 现在我的最后一个问题。你在业余时间还做些什么?除了 Python 和编码,你还有什么其他的爱好和兴趣?
哈哈,Python 和编码是一大块,但除此之外,我喜欢和我的妻子和两个孩子在一起的每一分钟。
我也热衷于坚持每天的健身计划,尤其是当我们的工作需要这么多坐着和看屏幕的时间的时候!我喜欢看书和听播客。当我有更多的空闲时间时,语言学习和绘画是我真正喜欢的另外两件事。
Julian: 好了,切掉编码和 Python,唷!
像鲍勃一样,首要任务是花时间陪伴我的妻子和两个孩子。任何有小孩的人都会知道,在他们结束后,你真的没有太多的时间,所以现在的业余爱好时间是有限的。
当我抓住几分钟不重要的时间时,我喜欢弹电吉他,玩电子游戏,阅读,摆弄我的树莓派和家庭自动化设备。
此外,作为一个交际花,我喜欢和朋友出去玩,喝几杯啤酒。带我去酒吧,给我一杯好酒,我会是你最好的朋友!
(等一下。鲍勃刚才说他喜欢画画吗?)
你有什么项目想和我们的读者分享吗?我们在哪里可以找到更多关于你们的信息以及你们在做什么?

Boolean: 除了博客,我们目前最引以为豪的是我们的在线 Python 编码练习平台。
我们还与 Michael Kennedy 一起在 Python 课程中创建了 #100DaysOfCode】并成为了 Talk Python to Me 培训平台的培训师。同样,这也是我们非常自豪的事情。(更多内容请见此处!)
你可以在下面黑暗的地方找到并跟踪朱利安:
- 推特: @_juliansequeira
- 领英:【https://www.linkedin.com/in/juliansequeira/】T2
- 我还在 Udemy 上创建了一个入门烧瓶课程!
- 个人博客:【https://www.techmoneykids.com/】T2
鲍勃:
- 推特: @bbelderbos
- 领英:【https://www.linkedin.com/in/bbelderbos/】T2
- 个人博客:【https://bobbelderbos.com】T2
谢谢朱利安和鲍勃的有趣采访。如果你最近没有去过 PyBites,那么我鼓励你去看看。如果你想让我采访某个人作为这个系列的一部分,请在下面留下评论。编码快乐!
Python 社区采访教授 Python 的 Kelly 和 Sean
原文:https://realpython.com/python-community-interview-kelly-and-sean-teaching-python/
本周,我和凯利·帕雷德斯和肖恩·蒂博尔一起参加了教学 Python 播客的主持人。加入我们,讨论在代码本身之外学习 Python 的好处,以及当你不打算成为专业开发人员时学习 Python 是什么感觉。那么,事不宜迟,让我们见见凯利和肖恩吧!
瑞奇: 欢迎来到真正的巨蟒,凯利和肖恩。我很高兴你能和我一起参加这次面试。让我们像对待所有客人一样开始吧。你是如何开始编程的,你是什么时候开始使用 Python 的?

凯利:我可能是你最不典型的编码员/程序员。直到大约一年半以前,我才真正开始接触编程。我小时候玩过一点 MS-DOS,但除了从手册上抄东西之外,我从来没有更进一步。此外,我是一名大学医学预科生,但从未真正上过编码课。
在研究生院期间,我上过一些网页设计课,我喜欢在网上玩,但那是我年轻时做的最多的编码。我后来教学生如何在 Dreamweaver 中用 HTML 制作网站,那时候这在教育界是一件大事。然后,后来我用 EV3 思维风暴软件给乐高机器人编程,和学生们一起玩积木代码。
然而,Python 是我第一门真正的编码语言,从那以后我一直在自学如何编码。我认为 Python 适合新手,因为它的可读性和逻辑组织结构。
Sean: 我是在电脑周围长大的,我想我最早的编码经历是在教室里用 Apple II 电脑。我记得从杂志和书上输入基本程序来解谜和解码密码。
我认真的编程始于大学,在那里我学习信息系统,必须学习数据库以及用 Java 和 PHP 进行 web 编程。我爱上了通过实用代码让事情变得更高效、更优雅的能力。我将这一点应用到我的软件开发和市场营销职业生涯中,总是找到一种方法让代码变得更好,即使当我成为一名经理,不再将编码作为我日常工作的一部分时也是如此。
大约一年半前,我决定转行,开始全职教授计算机科学。我们想用 Python 作为我们基于文本的基础语言,所以我开始自学。由于其优雅的实现和广泛的用途,它已经成为最令人满意的学习、使用和教授语言之一。
瑞奇: 你是 2018 年 12 月开始的教学 Python 播客的共同主持人。对于那些还没有听的人,你为什么开始播客?此外,当你开始的时候,谁是你的目标听众?随着你的进步,这种情况有变化吗?
凯莉:肖恩和我在同一个教室一起工作。我们在一起的九个小时里,大部分时间都在谈论非常酷的事情,比如编码、教育学、课堂管理、课程设计、如何让酷项目进入课堂,以及那天任何能激起我们兴趣的事情。当我们中的一个人在教学的时候,我们经常在一起,当我们可以的时候,我们会一起指导。
我们意识到我们拥有独一无二的东西。我是他的教学导师,因为这是他第一次教学,他是我的 Python 编码导师,因为,嗯,他在编码方面真的很聪明!我们开始这个播客是因为我们注意到很难找到愿意教书的训练有素的软件工程师和愿意学习如何编码的老师。
如果你是一名程序员,你通常不希望开始教书时薪水较低,而且没有多少有丰富编程经验的老师。如果你没有既懂代码又懂教学法的优秀教师,就很难开设计算机科学课程。
我们坚信,来自其他学科领域的好老师也可以成为伟大的计算机科学老师,只需要一点指导和大量的毅力。与此同时,我们希望帮助其他教师学习如何编写代码,这样我们就可以帮助培养能够批判性思考、解决问题的学生,并培养对他们的未来有所帮助的社交和情感技能。
Sean: 我们原本以为我们的许多听众会是专攻计算机科学或相关 STEM 领域的教师。有趣的是,我们发现有如此多的 Python 开发者对教育和向他人展示如何开始将计算思维和问题解决应用到他们周围的世界充满热情!
关于这个播客,我们最喜欢的事情之一是与来自 Python 世界的人们见面,他们正在做着如此有趣而重要的工作。无论是使用代码探索文学概念的英语教师,向理科研究生教授数据科学原理的大学教师,还是向贫困或代表性不足的群体教授课后 Python 程序的忙碌的专业人员,看到 Python 如何被用来让世界变得更美好都是令人鼓舞的。
瑞奇: 你给中学生教 Python。我很想听听它给你个人带来的挑战。与成人相比,你对那个年龄组的教学方法有什么不同?
凯莉:我教了二十多年的中学生。我喜欢这个年龄组,尤其是七年级学生——他们是海绵!如果给他们机会和适当的支持,他们可以完成令人惊奇的事情。
在我看来,教中学生是容易的部分。有时候,向他们的父母解释编码很难,我们在“推动”他们的孩子去做他们认为他们做不到的事情,这才是最难的部分。父母通常不知道如何让他们的孩子挣扎。而且大多数父母自己也不懂编码,所以他们在试图帮助孩子时感到失落。
然而,Sean 和我相信,找到合适的理想困难不仅仅是帮助学生学习如何编码。最后,父母对他们的孩子所取得的成就非常满意!
Sean: 即使在成年人中间工作了这么多年,第一次教中学生还是有点害怕,因为他们通常把老师视为主要的知识来源。我们学校有非常优秀的学生,中学通常是他们寻求大量知识、了解自己和周围世界的时候。
我发现,作为一名教师,我能做的最重要的事情之一就是向他们表明,我并非无所不知。然后,我可以指导他们获取新信息,并将其应用到他们试图解决的问题或他们试图创建的程序中。我必须感谢 Kelly,作为一名新老师,她帮助我如此迅速地理解了这种方法的重要性。
我认为公平地说,并不是你所有的学生将来都会成为软件工程师或类似的人。你的学生在学习 Python 编程和完成项目集的过程中获得了什么好处?
凯莉:我认为公平地说,大多数计算机科学教师并不期望他们的学生成为软件工程师,我们也没有为他们寻找那个目标。我从自己的学习过程中学到的是,“学习如何编码”不仅仅是开发一个很酷的应用程序,或者另一个版本的“猜数字”游戏。
我对自己和如何解决问题有了更多的了解,而我对此一无所知或没有背景知识,甚至没有参考资料。然而,我已经发展了一些技能,帮助我建立自信,提高我的研究技能,让我能够阅读我知道不到 80%词汇的内容,并坚持解决一个有多个解决方案的问题。
我希望我的学生也有同样的经历。我想建立他们的信心,让他们明白在考试中获得“A”是很好的,但是能够解决问题,批判性地思考问题的含义和结果,以及勇于面对未知比获得“A”或成为“程序员”更重要。我们真的希望培养渴望接受任何挑战的终身学习者。
Sean: 我经常告诉学生们,我们很幸运能够用 Python 编程,因为对于初学者来说,它是一种非常棒的语言,而且它还会随着你的成长而解决手边的问题。
我认为公平地说,我们现在教的最不重要的东西是 Python 的语言、语法和词汇。我们真正教授的是研究、解决问题、坚持不懈、应对挫折和失败,以及如何在某方面发展真正的能力。这些特质和技能在许多不同的学科中都是持久的,不仅仅是计算机科学。
用 Kelly 的话来说,我们的学生中只有一小部分人会继续接受传统的计算机科学教育,但所有人都需要思考和解决问题,学习和掌握主题,并在他们选择的领域发展真正的能力。我们的赌注是,知道如何通过代码和技术解决问题将在 21 世纪的职业道路上很好地为他们服务。
里基: 现在,我的最后几个问题。你在业余时间还做些什么?除了教 Python 和编码,你还有什么其他的爱好和兴趣?
Kelly: 在教学,学习如何更好的编码,和录制教学 Python 之间,我不做太多别的!我喜欢和我的两个小男孩在一起,享受南佛罗里达的生活。我们喜欢游泳、去海滩、钓鱼和运动——真的,任何户外运动。然而,我真的很想有一天写一本书,并已经开始了这个过程,但很难用我一天中剩余的时间来完成它。
我还想在我的编码中找到一个点,在那里我可以做出一些真正有用的东西,帮助教师更好地了解他们的学生在学校的学业、情感和社会进步。后面这两个目标都是“近”的未来希望和梦想,我试图保持在我的掌握之中。
Sean: 如果我没有教 Python 或写代码,那么你通常会发现我在和我的孩子玩耍,咨询一些营销客户,或者想办法让我的房子变得更智能。我还试图通过长跑和跆拳道来保持健康,每周至少有几个早上是在上学前。
幸运的是,南佛罗里达全年都有温暖的天气,所以你也可以看到我在运河和湖泊里钓鱼,放飞我的无人机,或者尝试摄影。有时,我甚至可以玩视频游戏或从事一些兼职项目,比如为我的客户进行基于熊猫的 CRM 系统数据科学分析。
感谢凯利和肖恩参加这次采访!很高兴收到你们俩的来信。
你可以在他们的网站上查看教学 Python 播客,或者在你最喜欢的播客播放器中搜索。你也可以在推特上关注凯利和肖恩。一如既往,如果你想让我在未来采访某人,请在下面留下评论或在 Twitter 上给我发消息。
用 Python 简化复数
大多数通用编程语言要么不支持,要么有限支持复数。你的典型选择是学习一些专门的工具,比如 MATLAB 或者找一个第三方库。Python 是一个罕见的例外,因为它内置了复数。
顾名思义,复数并不复杂!它们在处理实际问题时很方便,您将在本教程中体会到这一点。你将探索矢量图形和声音频率分析,但是复数也可以帮助绘制分形,例如曼德尔布罗集合。
在本教程中,您将学习如何:
- 用 Python 中的文字定义复数
- 在直角和极坐标中表示复数
- 在算术表达式中使用复数
- 利用内置的
cmath模块 - 将数学公式直接翻译成 Python 代码
如果你需要快速复习或者对复数理论有一个温和的介绍,那么你可以看看汗学院的视频系列。要下载本教程中使用的示例代码,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的复数。
在 Python 中创建复数
在 Python 中创建和操作复数与其他内置数据类型没有太大区别,尤其是数值类型。这是可能的,因为这种语言将他们视为一等公民。这意味着你可以用很少的开销来表达包含复数的数学公式。
Python 允许你在算术表达式中使用复数,并对它们调用函数,就像你在 Python 中处理其他数一样。它产生了优雅的语法,读起来几乎像一本数学教科书。
复数文字
在 Python 中定义复数的最快方法是直接在源代码中键入它的文字:
>>> z = 3 + 2j
虽然这看起来像一个代数公式,但等号右边的表达式已经是一个固定值,不需要进一步计算。当您检查它的类型时,您将确认它确实是一个复数:
>>> type(z)
<class 'complex'>
这与用加号运算符将两个数字相加有何不同?一个明显的例子是粘在第二个数字上的字母j,它完全改变了表达的意思。如果您删除字母,您将得到一个熟悉的整数结果:
>>> z = 3 + 2
>>> type(z)
<class 'int'>
顺便说一下,您也可以使用浮点数来创建复数:
>>> z = 3.14 + 2.71j
>>> type(z)
<class 'complex'>
Python 中的复数文字模拟数学符号,也称为复数的标准形式、代数形式,或者有时称为标准形式。在 Python 中,可以在这些文字中使用小写的j或大写的J。
如果你在数学课上学过复数,你可能会看到用i而不是j来表示它们。如果你对 Python 为什么使用j而不是i感到好奇,那么你可以展开下面的可折叠部分来了解更多。
传统的复数符号使用字母i代替j,因为它代表虚数单位。如果你有数学背景,你可能会对 Python 的约定感到有点不舒服。然而,有几个原因可以证明 Python 有争议的选择是正确的:
- 这是工程师已经采用的惯例,以避免与电流的名称冲突,电流用字母
i表示。 - 在计算中,字母
i通常用于循环中的索引变量。 - 字母
i在源代码中很容易与l或1混淆。
这是十多年前 Python 的 bug 追踪器提出来的,Python 的创造者吉多·范·罗苏姆本人用下面的评论结束了这个问题:
这个问题不会得到解决。首先,字母“I”或大写字母“I”看起来太像数字了。语言解析器(在源代码中)或内置函数(int、float、complex)解析数字的方式不应以任何方式进行本地化或配置;这是在自找巨大的失望。如果你想用“I”而不是“j”来解析复数,你已经有很多解决方案了。(来源)
所以你有它。除非你想开始使用 MATLAB,否则你将不得不忍受使用j来表示你的复数。
复数的代数形式遵循代数的标准规则,这便于执行算术运算。例如,加法有一个可交换属性,它允许你交换一个复数文字的两个部分的顺序,而不改变它的值:
>>> 3 + 2j == 2j + 3
True
同样,您可以在复数文字中用加法代替减法,因为减号只是等价形式的简写符号:
>>> 3 - 2j == 3 + (-2j)
True
Python 中的复数文字一定要由两个数字组成吗?它能有更多吗?它们被订购了吗?为了回答这些问题,让我们进行一些实验。不出所料,如果您只指定一个数字,没有字母j,那么您将得到一个常规整数或浮点数:
>>> z = 3.14
>>> type(z)
<class 'float'>
另一方面,将字母j附加到数字文字会立即将它变成一个复数:
>>> z = 3.14j
>>> type(z)
<class 'complex'>
严格地说,从数学的角度来看,您刚刚创建了一个纯虚数,但是 Python 不能将其表示为独立的数据类型。因此,没有另一部分,它只是一个复数。
反过来呢?要创建一个没有虚数部分的复数*,你可以利用零,像这样加或减它:*
>>> z = 3.14 + 0j
>>> type(z)
<class 'complex'>
事实上,复数的两个部分总是存在的。当你看不到 1 时,意味着它的值为零。让我们来看看当你尝试把比以前更多的项填入总和时会发生什么:
>>> 2 + 3j + 4 + 5j
(6+8j)
这一次,您的表达式不再是一个文字,因为 Python 将其计算为一个仅包含两部分的复数。请记住,代数的基本规则适用于复数,所以如果您将相似的术语分组并应用组件式加法,那么您将得到6 + 8j。
注意 Python 默认显示复数的方式。它们的文本表示包含一对括号、一个小写字母j,没有空格。此外,虚部次之。
恰好也是纯虚数的复数没有括号,只显示它们的虚部:
>>> 3 + 0j
(3+0j)
>>> 0 + 3j
3j
这有助于区分虚数和大多数由实部和虚部组成的复数。
complex()工厂功能
Python 有一个内置函数complex(),您可以使用它作为复数文字的替代:
>>> z = complex(3, 2)
在这种形式下,它类似于一个元组或者一对有序的普通数字。这个类比并没有那么牵强。复数在笛卡儿坐标系中有一个几何解释,稍后您将对其进行探究。你可以认为复数是二维的。
**有趣的事实:**在数学中,复数传统上用字母z表示,因为它是字母表中继x和y之后的下一个字母,通常代表坐标。
复数工厂函数接受两个数值参数。第一个代表实部,而第二个代表虚部在你之前看到的字面上用字母j表示:
>>> complex(3, 2) == 3 + 2j
True
这两个参数都是可选的,默认值为零,这使得定义没有虚部或实部和虚部的复数变得不那么笨拙:
>>> complex(3) == 3 + 0j
True
>>> complex() == 0 + 0j
True
单参数版本在类型转换中很有用。例如,您可以传递一个非数字值,比如一个字符串文本,以获得一个对应的complex对象。请注意,该字符串不能包含任何空格,尽管:
>>> complex("3+2j")
(3+2j)
>>> complex("3 + 2j")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: complex() arg is a malformed string
稍后,您将了解如何让您的类与这种类型转换机制兼容。有趣的是,当您将一个复数传递给complex()时,您将得到相同的实例:
>>> z = complex(3, 2)
>>> z is complex(z)
True
这与 Python 中其他类型的数字的工作方式一致,因为它们都是不可变的。要制作一个复数的不同副本,必须再次调用带有两个参数的函数,或者用复数文本声明另一个变量:
>>> z = complex(3, 2)
>>> z is complex(3, 2)
False
当你给函数提供两个参数时,它们必须总是数字,比如int、float或complex。否则,您会得到一个运行时错误。从技术上讲, bool 是int的子类,所以它也可以工作:
>>> complex(False, True) # Booleans, same as complex(0, 1)
1j
>>> complex(3, 2) # Integers
(3+2j)
>>> complex(3.14, 2.71) # Floating-point numbers
(3.14+2.71j)
>>> complex("3", "2") # Strings
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: complex() can't take second arg if first is a string
当您向complex()工厂函数提供复数作为参数时,事情似乎变得更加奇怪。但是,如果只提供第一个参数,它将像以前一样充当代理:
>>> complex(complex(3, 2))
(3+2j)
但是,当存在两个参数并且其中至少有一个是复数时,您将得到乍一看可能难以解释的结果:
>>> complex(1, complex(3, 2))
(-1+3j)
>>> complex(complex(3, 2), 1)
(3+3j)
>>> complex(complex(3, 2), complex(3, 2))
(1+5j)
为了得到答案,让我们看一看工厂函数的 docstring 或在线文档,它们解释了当您调用complex(real, imag)时发生了什么:
返回一个值为实数 + imag *1j 的复数,或者将字符串或数字转换为复数。(来源)
在本说明中,real和imag是函数自变量的名称。第二个参数乘以虚数单位j,结果加到第一个参数上。如果还是没有任何意义也不用担心。当你读到复数算术时,你可以回到这一部分。您将学习的规则将使这变得简单明了。
什么时候你想在字面上使用complex()工厂函数?这要视情况而定,但是例如,当您处理动态生成的数据时,调用该函数可能更方便。
了解 Python 复数
在数学中,复数是实数的超集,也就是说每一个实数也是虚数部分等于零的复数。Python 通过一个叫做数字塔的概念来模拟这种关系,在 PEP 3141 中有描述:
>>> import numbers
>>> issubclass(numbers.Real, numbers.Complex)
True
内置的numbers模块通过抽象类定义了数字类型的层次结构,这些抽象类可用于类型检查和数字分类。例如,要确定一个值是否属于一组特定的数字,可以对它调用isinstance():
>>> isinstance(3.14, numbers.Complex)
True
>>> isinstance(3.14, numbers.Integral)
False
浮点值3.14是一个实数,恰好也是一个复数,但不是整数。请注意,您不能在这样的测试中直接使用内置类型:
>>> isinstance(3.14, complex)
False
complex和numbers.Complex的区别在于,它们属于数值型层次树中单独的分支,后者是一个抽象基类,没有任何实现:
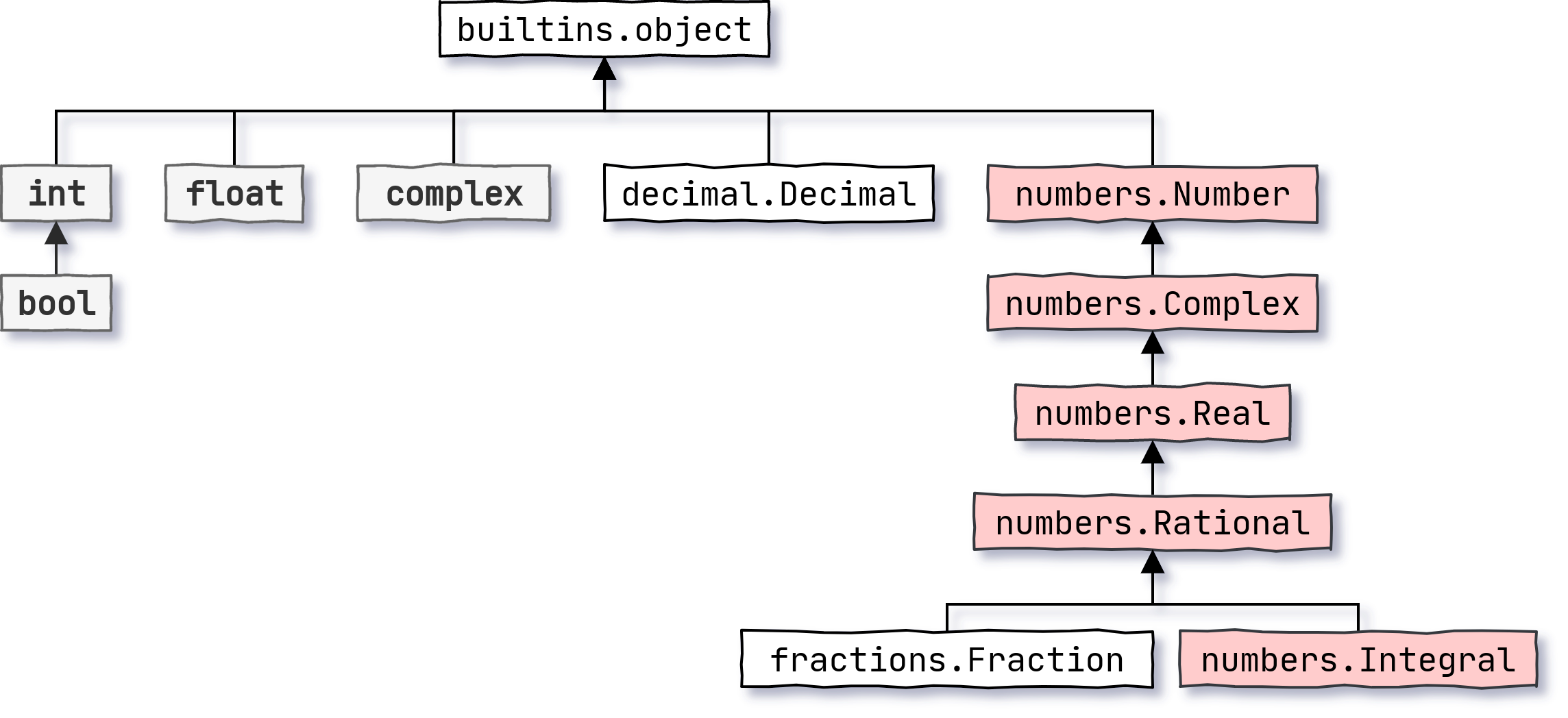
抽象基类,在上图中用红色表示,可以通过将不相关的类注册为它们的虚拟子类来绕过常规的继承检查机制。这就是为什么示例中的浮点值看起来是numbers.Complex的实例,而不是complex的实例。
访问实部和虚部
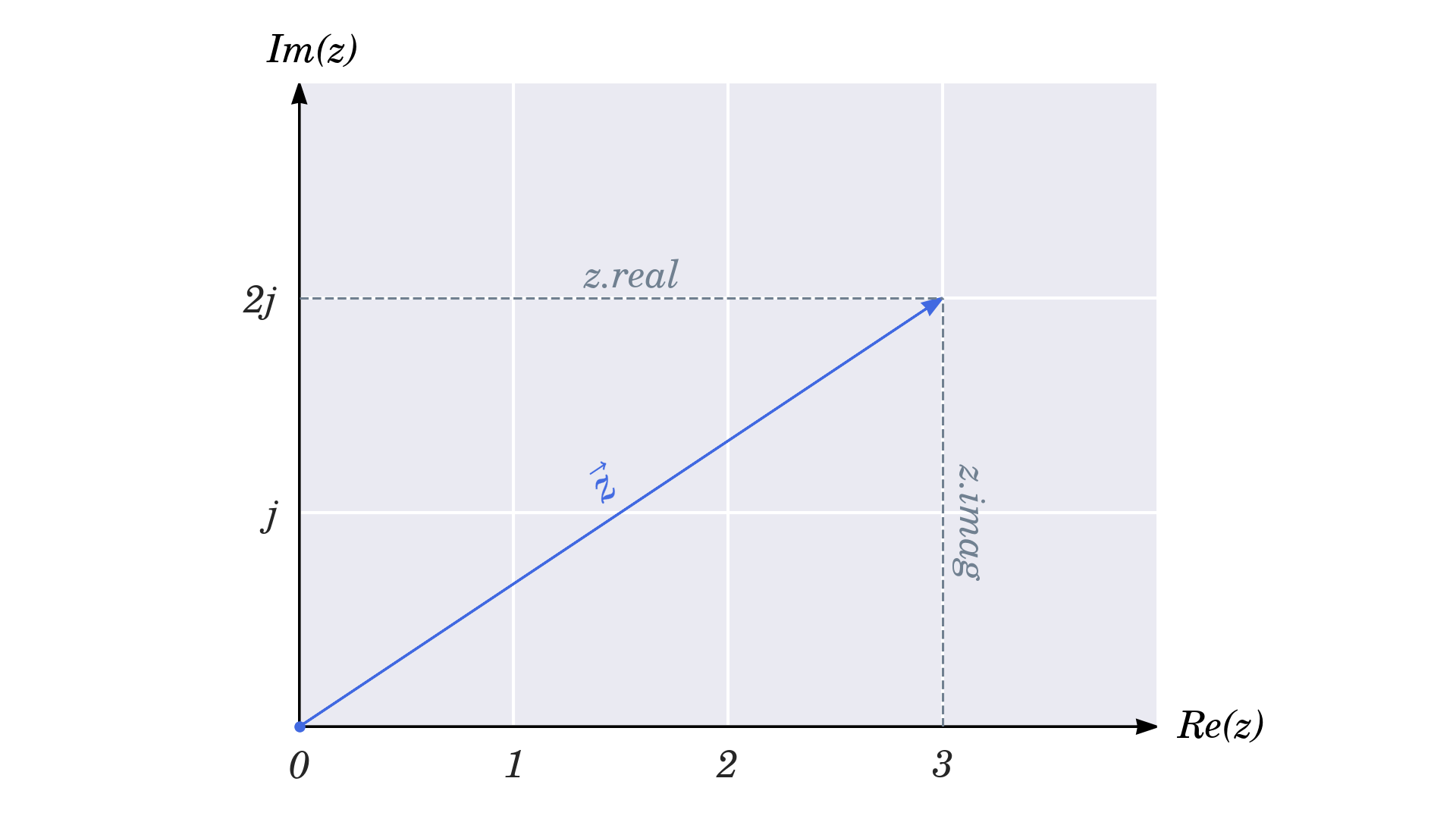
为了在 Python 中获得复数的实部和虚部,您可以使用相应的.real和.imag属性:
>>> z = 3 + 2j
>>> z.real
3.0
>>> z.imag
2.0
两个属性都是只读的,因为复数是不可变的,所以试图给它们中的任何一个赋值都会失败:
>>> z.real = 3.14
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: readonly attribute
因为 Python 中的每个数字都是一个更具体的复数类型,所以在numbers.Complex中定义的属性和方法也适用于所有数字类型,包括int和float:
>>> x = 42
>>> x.real
42
>>> x.imag
0
这类数字的虚部总是零。
计算复数的共轭
Python 复数只有三个公共成员。除了.real和.imag属性,它们还公开了.conjugate()方法,该方法翻转虚部的符号:
>>> z = 3 + 2j
>>> z.conjugate()
(3-2j)
对于虚数部分等于零的数字,它不会有任何影响:
>>> x = 3.14
>>> x.conjugate()
3.14
这个操作是它自己的逆操作,所以调用它两次将得到开始时的原始数字:
>>> z.conjugate().conjugate() == z
True
虽然看起来没什么价值,但复共轭有一些有用的算术属性,可以帮助用笔和纸计算两个复数的除法,以及其他许多东西。
复数算术
由于complex是 Python 中的原生数据类型,您可以将复数插入到算术表达式中,并调用其中的许多内置函数。更高级的复数函数在cmath模块中定义,它是标准库的一部分。在本教程的后面部分,您将会看到对它的介绍。
现在,记住一个规则将让你运用小学的算术知识来计算涉及复数的基本运算。需要记住的规则是虚数单位的定义,它满足以下等式:

把j想成实数看起来不太对,但是不要慌。如果你暂时忽略它,把每一次出现的j 2 都用-1代替,就好像它是一个常数一样,那么你就设定好了。让我们看看它是如何工作的。
加法
两个或更多复数之和相当于将它们的实部和虚部按分量相加:
>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 + z2
(6+8j)
之前,你发现由实数和虚数组成的代数表达式遵循代数的标准规则。当你用代数的方式写下它时,你将能够应用分配性质并通过分解和分组常见术语来简化公式:

当您添加混合数值类型的值时,Python 会自动将操作数提升为complex数据类型:
>>> z = 2 + 3j
>>> z + 7 # Add complex to integer
(9+3j)
这类似于您可能更熟悉的从int到float的隐式转换。
减法
复数的减法类似于复数的加法,这意味着您也可以按元素应用它:
>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 - z2
(-2-2j)
然而,与求和不同的是,操作数的顺序很重要,并且产生不同的结果,就像实数一样:
>>> z1 + z2 == z2 + z1
True
>>> z1 - z2 == z2 - z1
False
您也可以使用一元减号运算符(-) 来求复数的负数:
>>> z = 3 + 2j
>>> -z
(-3-2j)
这将反转复数的实部和虚部。
乘法运算
两个或更多复数的乘积变得更加有趣:
>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 * z2
(-7+22j)
你究竟是如何在只有正数的情况下得到负数的呢?要回答这个问题,你必须回忆一下虚部的定义,并用实部和虚部改写这个表达式:
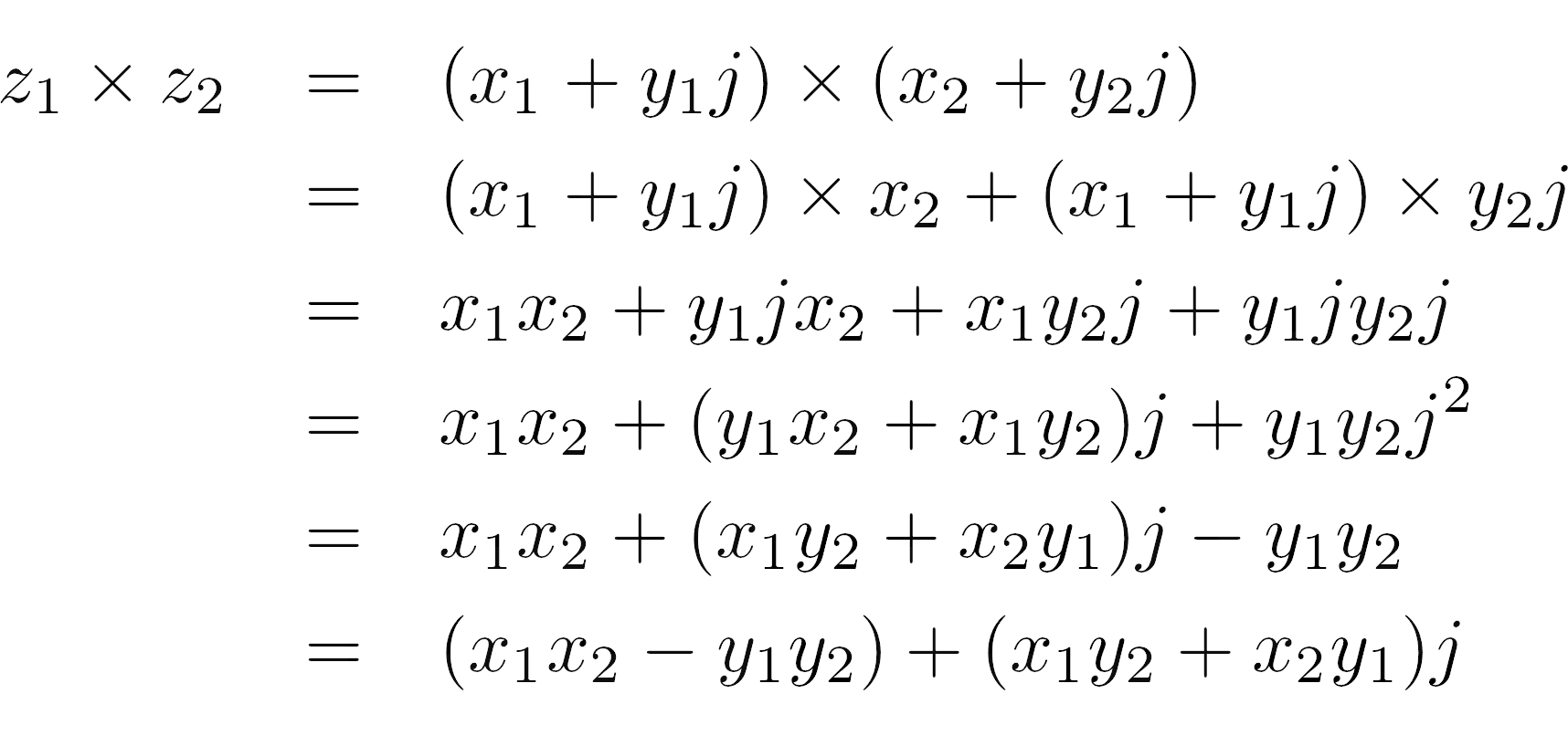
要重点观察的是,j乘以j得出j 2 ,可以用-1代替。这将反转其中一个被加数的符号,而其余的规则保持不变。
分部
初看起来,将复数相除可能有些吓人:
>>> z1 = 2 + 3j
>>> z2 = 4 + 5j
>>> z1 / z2
(0.5609756097560976+0.0487804878048781j)
信不信由你,你只用纸和笔就能得到同样的结果!(好吧,一个计算器可能会让你以后不再头疼。)当两个数都以标准形式表示时,技巧是将分子和分母乘以后者的共轭:
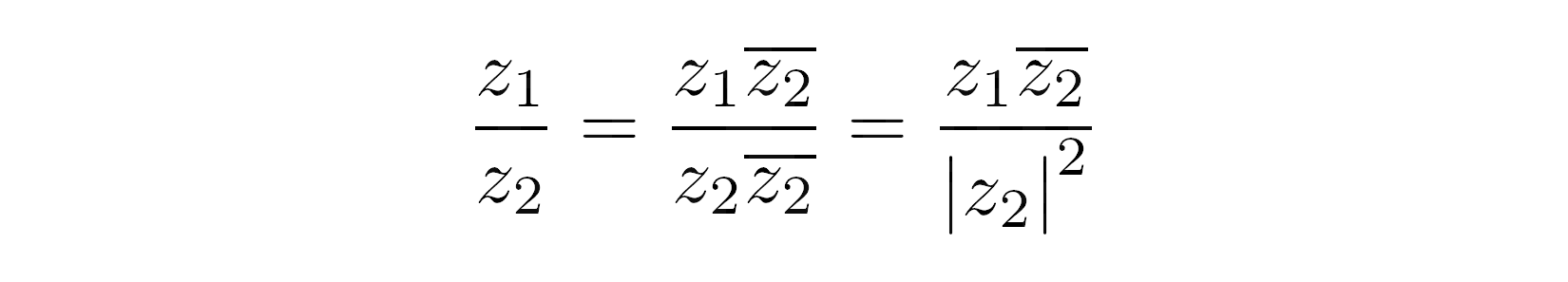
分母变成除数的平方模数。稍后你会学到更多关于复数的模数。当你继续推导这个公式时,你会得到:
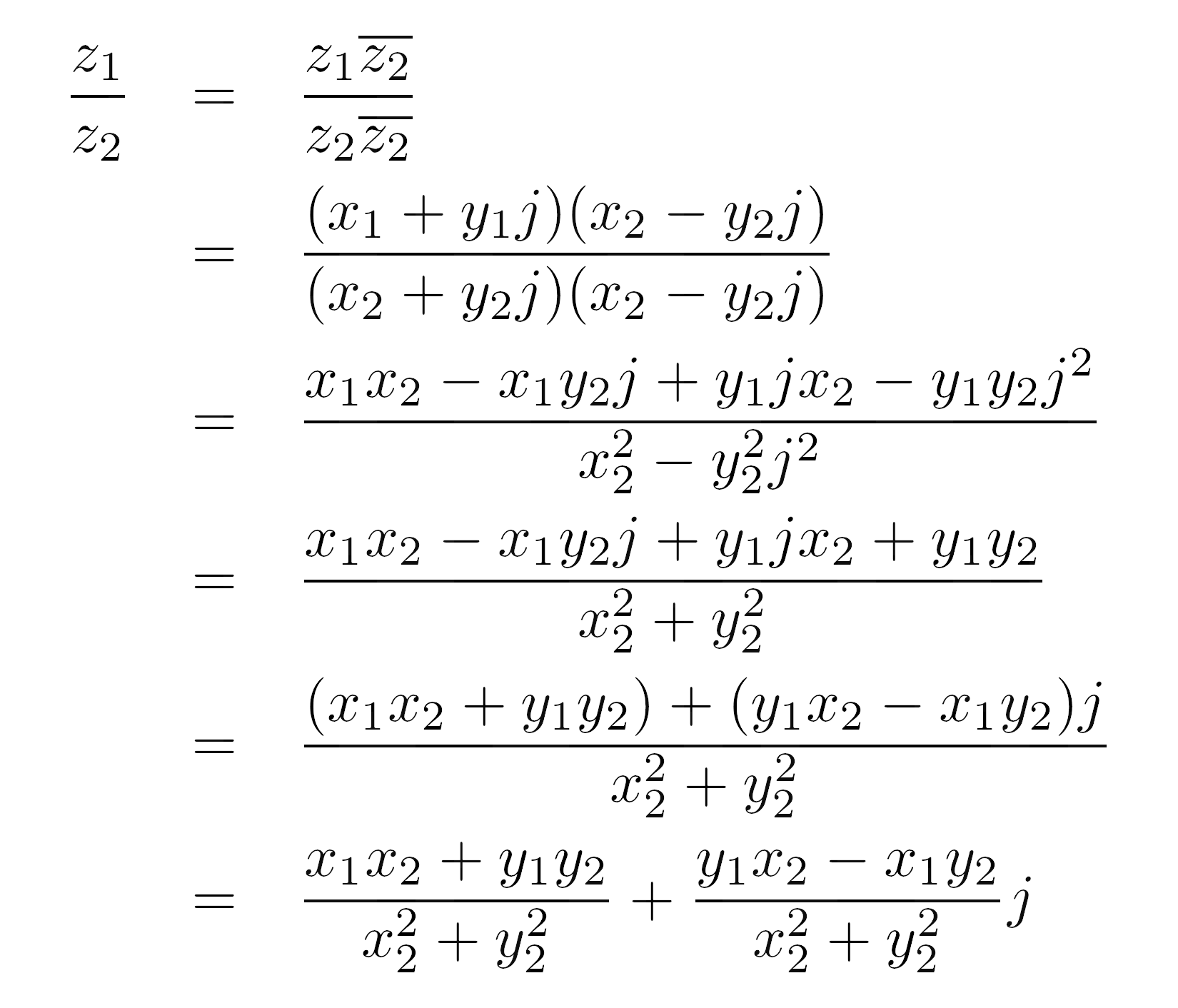
注意,复数不支持底数除法,也称为整数除法:
>>> z1 // z2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't take floor of complex number.
>>> z1 // 3.14
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't take floor of complex number.
这在 Python 2.x 中曾经有效,但后来为了避免歧义而被删除了。
求幂运算
您可以使用二进制取幂运算符(** ) 或内置的pow()对复数进行幂运算,但不能使用在math模块中定义的运算符,后者仅支持浮点值:
>>> z = 3 + 2j
>>> z**2
(5+12j)
>>> pow(z, 2)
(5+12j)
>>> import math
>>> math.pow(z, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert complex to float
底数和指数可以是任何数字类型,包括整数、浮点、虚数或复数:
>>> 2**z
(1.4676557979464138+7.86422192328995j)
>>> z**2
(5+12j)
>>> z**0.5
(1.8173540210239707+0.5502505227003375j)
>>> z**3j
(-0.13041489185767086-0.11115341486478239j)
>>> z**z
(-5.409738793917679-13.410442370412747j)
当复数以标准形式表示时,手动求幂变得非常困难。将三角形式中的数字重写,用一些基本的三角学计算幂就方便多了。如果你对所涉及的数学感兴趣,看看德莫维尔的公式,它能让你做到这一点。
使用 Python 复数作为 2D 向量
你可以把复数想象成笛卡尔或 T4 直角坐标系统中欧几里得平面上的点 T1 或 T2 向量 T3:

复平面上的 X 轴,也称为高斯平面或阿甘图,代表一个复数的实部,而 Y 轴代表其虚部。
这个事实导致了 Python 中complex数据类型最酷的特性之一,它免费实现了二维向量的基本实现。虽然不是所有的运算在两者中都以相同的方式工作,但是向量和复数有许多相似之处。
获取坐标
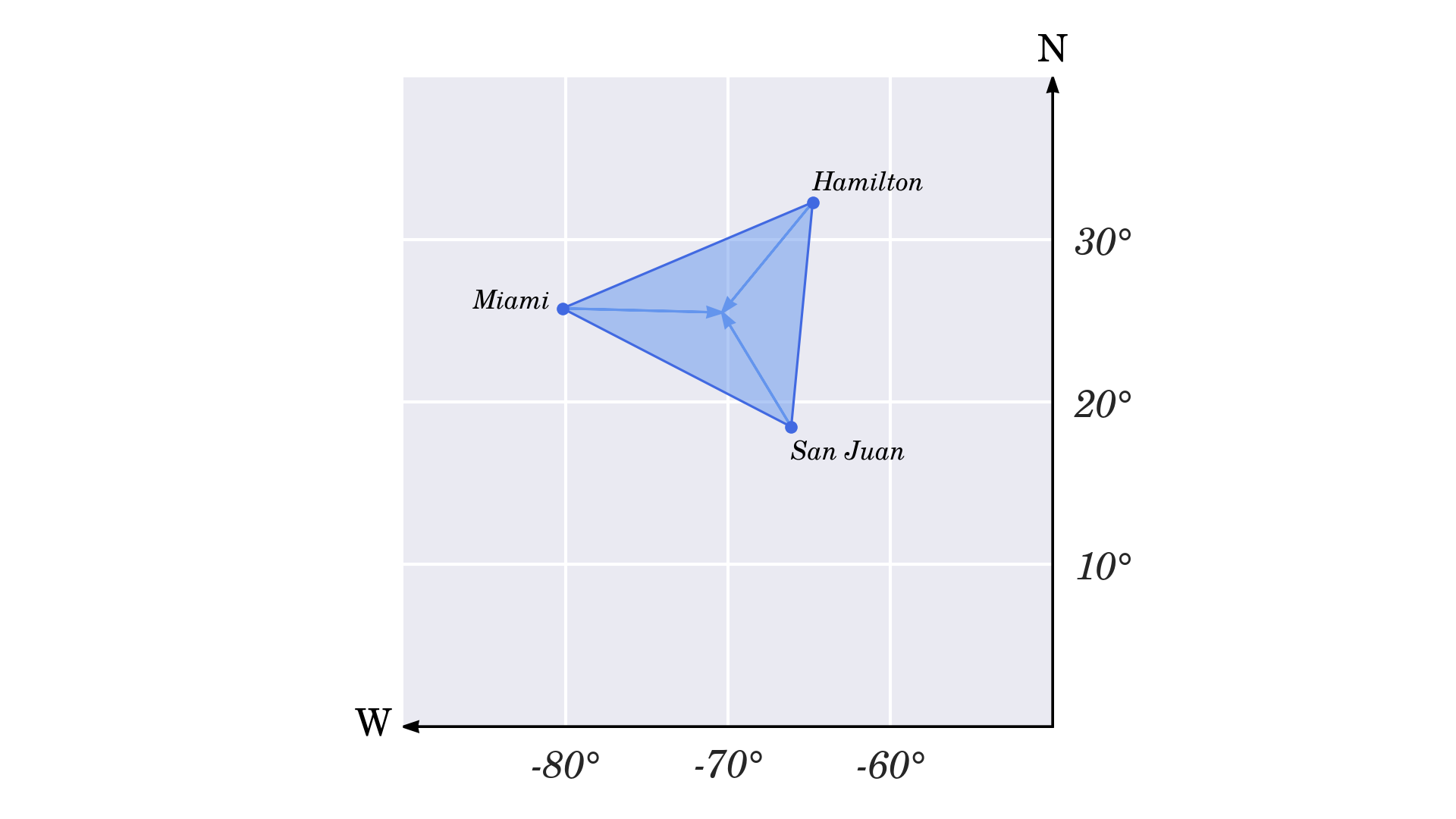
百慕大三角是一个以超自然现象闻名的传奇地区,横跨佛罗里达南端、波多黎各和百慕大小岛。其顶点大致由三个主要城市指定,其地理坐标如下:
- 迈阿密:北纬 25° 45 ’ 42.054 英寸,西经 80° 11 ’ 30.438 英寸
- 圣胡安:北纬 18° 27 ’ 58.8 英寸,西经 66° 6 ’ 20.598 英寸
- 汉密尔顿:北纬 32° 17 ’ 41.64 ",西经 64° 46 ’ 58.908 "
将这些坐标转换成十进制度数后,每个城市将有两个浮点数。您可以使用complex数据类型来存储有序的数字对。由于纬度是纵坐标,而经度是横坐标,因此按照笛卡尔坐标的传统顺序将它们互换可能会更方便:
miami_fl = complex(-80.191788, 25.761681)
san_juan = complex(-66.105721, 18.466333)
hamilton = complex(-64.78303, 32.2949)
负经度值代表西半球,而正纬度值代表北半球。
记住这些是球坐标。为了正确地将它们投影到一个平面上,你需要考虑地球的曲率。地图学中最早使用的地图投影之一是墨卡托投影,它帮助水手们为他们的船只导航。但是让我们忽略所有这些,假设值已经在直角坐标系中表示了。
当你在一个复平面上绘制这些数字时,你会得到百慕大三角的粗略描绘:

在配套资料中,你会发现一个交互式的 Jupyter 笔记本,它使用 Matplotlib 库绘制了百慕大三角。要下载本教程的源代码和材料,请单击下面的链接:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的复数。
如果你不喜欢调用complex()工厂函数,你可以用一个更合适的名字创建一个类型的别名,或者使用复数的字面形式来节省一些击键次数:
CityCoordinates = complex
miami_fl = CityCoordinates(-80.191788, 25.761681)
miami_fl = -80.191788 + 25.761681j
如果您需要在一个城市上打包更多的属性,您可以使用一个名为 tuple 的或者一个数据类或者创建一个自定义类。
计算震级
一个复数的大小,也称为模数或半径,是在一个复平面上描述它的向量的长度:
你可以从勾股定理通过取实部平方和虚部平方之和的平方根来计算:

你可能会认为 Python 会让你用内置的len()来计算这样一个向量的长度,但事实并非如此。要得到一个复数的大小,你必须调用另一个名为 abs() 的全局函数,它通常用于计算一个数的绝对值:
>>> len(3 + 2j)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: object of type 'complex' has no len()
>>> abs(3 + 2j)
3.605551275463989
这个函数从您传入的整数中删除符号,但是对于复数,它返回幅度或向量长度:
>>> abs(-42)
42
>>> z = 3 + 2j
>>> abs(z)
3.605551275463989
>>> from math import sqrt
>>> sqrt(z.real**2 + z.imag**2)
3.605551275463989
您可能记得在前面的章节中,一个复数乘以它的共轭会产生它的大小的平方。
求两点间的距离
让我们找到百慕大三角的几何中心和形成其边界的三个城市到它的距离。首先,您需要将所有坐标相加,然后将结果除以它们的数量,得到平均值:
geometric_center = sum([miami_fl, san_juan, hamilton]) / 3
这会给你一个位于大西洋的点,在三角形内的某个地方:
现在,您可以创建锚定在城市中并指向三角形几何中心的向量。向量是通过从目标点减去源点得到的:
v1 = geometric_center - miami_fl
v2 = geometric_center - san_juan
v3 = geometric_center - hamilton
因为减去复数,所以每个向量也是由两部分组成的复数。要获得距离,请计算每个矢量的大小:
>>> abs(v1)
9.83488994681275
>>> abs(v2)
8.226809506084367
>>> abs(v3)
8.784732429678444
这些向量长度并不能反映有意义的距离,但对于这样的玩具示例来说是很好的近似值。为了用有形的单位表示精确的结果,你必须首先将坐标从球形转换成矩形,或者使用大圆方法来计算距离。
平移、翻转、缩放和旋转
三角形出现在笛卡尔坐标系的第二个象限可能会困扰你。让我们移动它,使它的几何中心与原点对齐。所有三个顶点将被平移由几何中心指示的矢量长度,但方向相反:
triangle = miami_fl, san_juan, hamilton
offset = -geometric_center
centered_triangle = [vertex + offset for vertex in triangle]
请注意,您将两个复数加在一起,这将执行它们的元素相加。这是一个仿射变换,因为它不会改变三角形的形状或其顶点的相对位置:

围绕实轴或虚轴的三角形的镜像需要反转其顶点中的相应分量。例如,要将水平翻转,您必须使用实数部分的负数,这对应于水平方向。要垂直翻转它,你要取虚部的负值:
flipped_horizontally = [complex(-v.real, v.imag) for v in centered_triangle]
flipped_vertically = [complex(v.real, -v.imag) for v in centered_triangle]
后者本质上与计算复数共轭是一样的,所以你可以在每个顶点上直接调用.conjugate()来为你做这项艰苦的工作:
flipped_vertically = [v.conjugate() for v in centered_triangle]
自然,没有什么可以阻止你在任一方向上或同时在两个方向上应用对称性。在这种情况下,您可以在复数前面使用一元减号运算符来翻转其实部和虚部:
flipped_in_both_directions = [-v for v in centered_triangle]
继续使用可下载资料中的交互式 Jupyter 笔记本摆弄不同的翻盖组合。以下是沿两个轴翻转三角形时的样子:

缩放类似于平移,但不是添加偏移,而是将每个顶点乘以一个常数因子,该常数因子必须是一个实数:
scaled_triangle = [1.5*vertex for vertex in centered_triangle]
这样做的结果是每个复数的两个分量都乘以相同的量。它应该拉伸百慕大三角,使它在图上看起来更大:

另一方面,将三角形的顶点乘以另一个复数,会产生围绕坐标系原点旋转的效果。这与通常的向量相乘有很大的不同。例如,两个向量的点积将产生一个标量,而它们的叉积将返回三维空间中的一个新向量,该向量垂直于它们定义的表面。
注意:两个复数的乘积不代表向量乘法。而是定义为二维向量空间中的矩阵乘法,以 1 和j为标准基。将(x1+y1j)乘以(x2+y2j)对应如下矩阵乘法:

这是左边的旋转矩阵,这使得数学计算很好。
当你把顶点乘以虚数单位时,它会把三角形逆时针旋转 90 度。如果你不断重复,你最终会到达你开始的地方:

如何找到一个特定的复数,当两个复数相乘时,它可以将另一个复数旋转任意角度?首先,看一下下表,它总结了连续旋转 90°的情况:
| 90 度旋转 | 总角度 | 公式 | 指数 | 价值 |
|---|---|---|---|---|
| Zero | 0° | z | j 0 | one |
| one | 90° | z × j | j 1 | j |
| Two | 180° | z × j × j | j 2 | -1 |
| three | 270° | z × j × j × j | j 3 | - j |
| four | 360° | z × j × j × j × j | j 4 | one |
| five | 450° | z×j×j×j×j×j | j 5 | j |
| six | 540° | z×j×j×j×j×j×j | j 6 | -1 |
| seven | 630° | z×j×j×j×j×j×j×j | j 7 | - j |
| eight | 720° | z×j×j×j×j×j×j×j×j | j 8 | one |
当你用正整数指数来表示与j的重复乘法时,就会出现一种模式。请注意虚数单位的后续幂如何使其重复循环相同的值。你可以将此推断到分数指数上,并期望它们对应于中间角度。
例如,第一次旋转中途的指数等于 0.5,代表 45 度角:
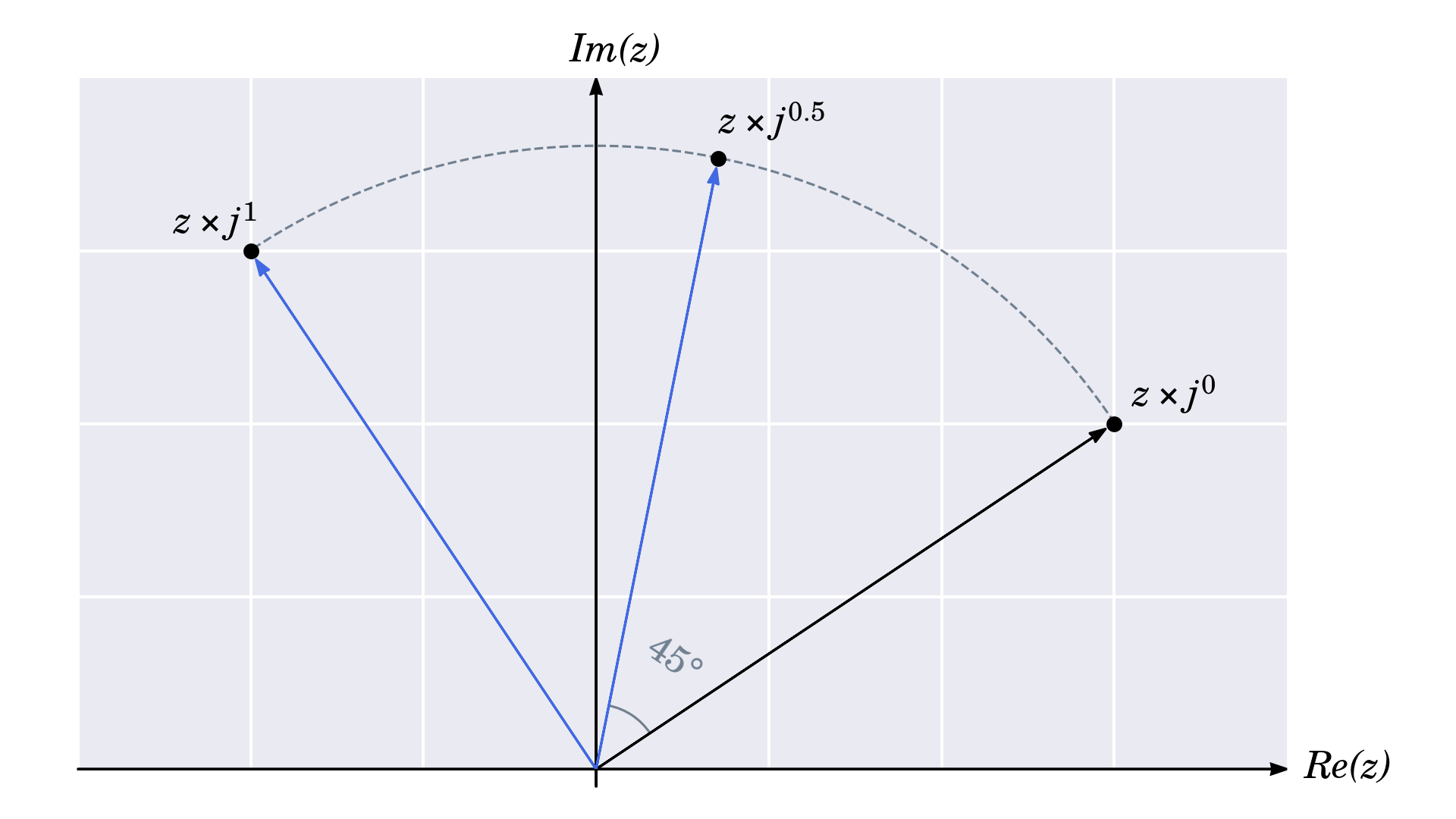
因此,如果您知道 1 的幂代表直角,并且两者之间的任何值都按比例缩放,那么您就可以推导出任意旋转的通用公式:
def rotate(z: complex, degrees: float) -> complex:
return z * 1j**(degrees/90)
请注意,当您在极坐标中表示复数时,旋转变得更加自然,极坐标已经描述了角度。然后,您可以利用指数形式使计算更加简单明了:
使用极坐标旋转数字有两种方法:
import math, cmath
def rotate1(z: complex, degrees: float) -> complex:
radius, angle = cmath.polar(z)
return cmath.rect(radius, angle + math.radians(degrees))
def rotate2(z: complex, degrees: float) -> complex:
return z * cmath.rect(1, math.radians(degrees))
你可以对角度求和,或者将你的复数乘以一个单位向量。
在下一节中,您将了解到更多关于这些内容的信息。
探索复数的数学模块:cmath
您已经看到了一些内置函数,如abs()和pow()接受复数,而其他的则不接受。例如,你不能round()一个复数,因为这样的运算没有意义:
>>> round(3 + 2j)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: type complex doesn't define __round__ method
许多高级数学函数,如三角函数、双曲线函数或对数函数都可以在标准库中找到。可悲的是,即使你对 Python math模块了如指掌,也无济于事,因为它的函数都不支持复数。您需要将它与cmath模块结合起来,后者为复数定义了相应的函数。
cmath模块重新定义了来自math的所有浮点常量,因此它们唾手可得,无需导入这两个模块:
>>> import math, cmath
>>> for name in "e", "pi", "tau", "nan", "inf":
... print(name, getattr(math, name) == getattr(cmath, name))
...
e True
pi True
tau True
nan False
inf True
注意nan是一个特殊值,它永远不等于任何其他值,包括它本身!这就是为什么你在上面的输出中看到了一个孤独的False。除此之外,cmath还为 NaN (非数字)和 infinity 提供了两个复数对应物,两者的实部都为零:
>>> from cmath import nanj, infj
>>> nanj.real, nanj.imag
(0.0, nan)
>>> infj.real, infj.imag
(0.0, inf)
cmath中的功能大约是标准math模块的一半。它们中的大部分模仿了最初的行为,但也有一些是复数所特有的。它们将允许您在两个坐标系之间进行转换,这将在本节中探讨。
提取复数的根
代数的基本定理说明一个复系数的次数 n 多项式恰好有 n 复数根。如果你仔细想想,那是相当重要的,所以让它沉淀一会儿。
现在,我们以二次函数 x 2 + 1 为例。从视觉上看,这条抛物线不与 X 轴相交,因为它位于原点上方一个单位处。该函数的判别式为负,这从算术上证实了这一观察结果。同时,它是一个二次多项式,所以它必须有两个复数根,尽管它没有任何实数根!
为了找到这些根,你可以将函数重写为一个二次方程,然后将常数移到右边,取两边的平方根:
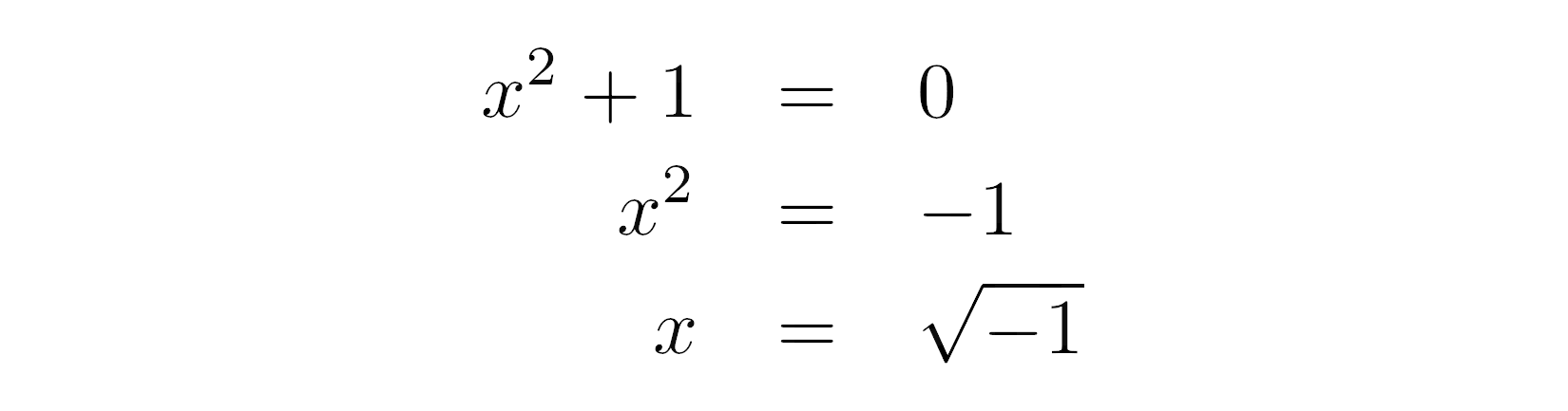
在实数域中,平方根仅针对非负输入值定义。因此,在 Python 中调用这个函数将引发一个异常,并显示相应的错误消息:
>>> import math
>>> math.sqrt(-1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: math domain error
然而,当您将√-1 视为复数并从cmath模块调用相关函数时,您将获得更有意义的结果:
>>> import cmath
>>> cmath.sqrt(-1)
1j
有道理。毕竟,二次方程的中间形式 x 2 = -1 正是虚数单位的定义。但是,等一下。另一个复杂的根去了哪里?高次多项式的复根怎么办?
比如一个四次多项式 x 4 + 1,可以写成方程 x 4 = -1,有这四个复数根:
- z0= 2/2+2/2
j - z1= 2/2-√2/2
j - z2=【T2/2+2/2
j - z=【T2/2】-【T2/2】
j
将每个根提升到四次幂会得到一个等于-1 + 0 j的复数或一个实数-1:
>>> import cmath
>>> z0 = -cmath.sqrt(2)/2 + cmath.sqrt(2)/2*1j
>>> z0**4
(-1.0000000000000004-0j)
>>> (z0**4).real
-1.0000000000000004
您会注意到,由于浮点运算中的舍入误差,结果值并不完全是-1。为了说明这一点,只要需要判断两个复数的值是否接近,就可以调用cmath.isclose():
>>> cmath.isclose(z0**4, -1)
True
不幸的是,您不能用纯 Python 计算其他复杂的根,因为正则求幂总是给出一个解:
>>> pow(-1, 1/4)
(0.7071067811865476+0.7071067811865475j)
这只是之前列出的词根之一。寻找所有复数根的数学公式利用了复数的三角形式:

r 和 φ 是复数的极坐标,而 n 是多项式的次数, k 是根的索引,从零开始。好消息是你不需要自己费力地计算这些根。找到它们最快的方法是通过安装一个第三方库,比如 NumPy 和将导入到您的项目中:
>>> import numpy as np
>>> np.roots([1, 0, 0, 0, 1]) # Coefficients of the polynomial x**4 + 1
array([-0.70710678+0.70710678j, -0.70710678-0.70710678j,
0.70710678+0.70710678j, 0.70710678-0.70710678j])
了解各种复数形式及其坐标系会很有用。如你所见,它有助于解决实际问题,如寻找复杂的根。因此,在下一节中,您将深入研究更多的细节。
在直角坐标和极坐标之间转换
几何上,你可以把一个复数看两遍。一方面,它是一个点,它离原点的水平和垂直距离唯一地标识了它的位置。这些被称为包含实部和虚部的直角坐标。
另一方面,你可以在极坐标中描述同一点,这也让你用两个距离明确地找到它:
- 径向距离是从原点测量的半径长度。
- 角距离是水平轴和半径之间测得的角度。
半径,也被称为模数,对应于复数的幅度,或者矢量的长度。该角度通常被称为复数的相位或幅角。使用三角函数时,用弧度而不是度数来表示角度很有用。
以下是对两个坐标系中的复数的描述:

因此,笛卡尔坐标系中的点(3,2)具有大约 3.6 的半径和大约 33.7 的角度,或者大约π超过 5.4 弧度。
两个坐标系之间的转换可以通过cmath模块中的几个函数来实现。具体来说,要获得一个复数的极坐标,必须将其传递给cmath.polar():
>>> import cmath
>>> cmath.polar(3 + 2j)
(3.605551275463989, 0.5880026035475675)
它将返回一个元组,其中第一个元素是半径,第二个元素是以弧度表示的角度。注意,半径的值与星等相同,可以通过在复数上调用abs()来计算。相反,如果您只对获取一个复数的角度感兴趣,那么您可以调用cmath.phase():
>>> z = 3 + 2j
>>> abs(z) # Magnitude is also the radial distance
3.605551275463989
>>> import cmath
>>> cmath.phase(3 + 2j)
0.5880026035475675
>>> cmath.polar(z) == (abs(z), cmath.phase(z))
True
由于实部、虚部和幅度一起形成了一个直角三角形,因此可以使用基本的三角学获得角度:

您可以从math或cmath使用反三角函数,如反正弦,但后者会产生虚部等于零的复数值:
>>> z = 3 + 2j
>>> import math
>>> math.acos(z.real / abs(z))
0.5880026035475675
>>> math.asin(z.imag / abs(z))
0.5880026035475676
>>> math.atan(z.imag / z.real) # Prefer math.atan2(z.imag, z.real)
0.5880026035475675
>>> import cmath
>>> cmath.acos(z.real / abs(z))
(0.5880026035475675-0j)
不过,在使用反正切函数时,有一个小细节需要小心,这导致许多编程语言开发了一个名为 atan2() 的替代实现。计算虚部和实部之间的比率有时会由于例如被零除而产生奇点。此外,在此过程中,两个值的单个符号会丢失,从而无法确定地判断角度:
>>> import math
>>> math.atan(1 / 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> math.atan2(1, 0)
1.5707963267948966
>>> math.atan(1 / 1) == math.atan(-1 / -1)
True
>>> math.atan2(1, 1) == math.atan2(-1, -1)
False
注意atan()是如何无法识别位于坐标系相对象限的两个不同点的。另一方面,atan2()期望两个参数而不是一个参数来保留各个符号,然后再将它们分开,这样也避免了其他问题。
要获得角度而不是弧度,您可以再次使用math模块进行必要的转换:
>>> import math
>>> math.degrees(0.5880026035475675) # Radians to degrees
33.690067525979785
>>> math.radians(180) # Degrees to radians
3.141592653589793
反转该过程(即将极坐标转换为直角坐标)依赖于另一个函数。然而,你不能只传递从cmath.polar()得到的相同的元组,因为cmath.rect()需要两个独立的参数:
>>> cmath.rect(cmath.polar(3 + 2j))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: rect expected 2 arguments, got 1
在进行赋值时,最好先解包元组,并给这些元素起一个更具描述性的名字。现在您可以正确地调用cmath.rect():
>>> radius, angle = cmath.polar(3 + 2j)
>>> cmath.rect(radius, angle)
(3+1.9999999999999996j)
在 Python 进行计算的过程中,您可能会遇到舍入误差。在幕后,它调用三角函数来检索实部和虚部:
>>> import math
>>> radius*(math.cos(angle) + math.sin(angle)*1j)
(3+1.9999999999999996j)
>>> import cmath
>>> radius*(cmath.cos(angle) + cmath.sin(angle)*1j)
(3+1.9999999999999996j)
同样,在这种情况下使用math还是cmath并不重要,因为结果是一样的。
以不同方式表示复数
不管坐标系如何,您都可以用几种数学上等价的形式来表示同一个复数:
- 代数(标准)
- 几何学的
- 三角法的
- 指数的
这个列表并不详尽,因为还有更多表示法,比如复数的矩阵表示法。
拥有选择权可以让你选择最方便的方法来解决给定的问题。例如,在下一节中,您将需要指数形式来计算离散傅立叶变换。使用这种形式也适用于复数的乘除运算。
以下是单个复数形式及其坐标的简要概述:
| 形式 | 矩形的 | 极地的 |
|---|---|---|
| 代数的 | z=x+yj | - |
| 几何学的 | z = ( x , y ) | z = ( r ,φ) |
| 三角法的 | z= |z|(cos(x/|z|)+jsin(y/|z|)) | z=r(cos(φ)+jsin(φ)) |
| 指数的 | z= |z| eatan2(y/x)jT6】 | z=r(eT0】φ |
当您使用文字指定复数时,代数形式是 Python 固有的。您也可以将它们视为笛卡尔或极坐标系统中欧几里得平面上的点。虽然 Python 中没有三角或指数形式的单独表示,但您可以验证数学原理是否成立。
例如,将欧拉公式代入三角形式,就会变成指数形式。你可以调用cmath模块的exp()或者提升e常数的幂来得到相同的结果:
>>> import cmath
>>> algebraic = 3 + 2j
>>> geometric = complex(3, 2)
>>> radius, angle = cmath.polar(algebraic)
>>> trigonometric = radius * (cmath.cos(angle) + 1j*cmath.sin(angle))
>>> exponential = radius * cmath.exp(1j*angle)
>>> for number in algebraic, geometric, trigonometric, exponential:
... print(format(number, "g"))
...
3+2j
3+2j
3+2j
3+2j
所有的形式实际上都是同一数字的不同编码方式。但是不能直接比较,因为其间可能会出现舍入误差。使用cmath.isclose()进行安全比较,或者适当地使用 format()作为字符串。在下一节中,您将了解如何格式化这样的字符串。
解释为什么不同形式的复数是等价的需要微积分,远远超出了本教程的范围。然而,如果你对数学感兴趣,那么你会发现由复数表现出来的不同数学领域之间的联系非常迷人。
在 Python 中剖析复数
您已经学习了很多关于 Python 复数的知识,并且已经看到了初步的例子。然而,在进一步讨论之前,有必要讨论一些最终的主题。在这一节中,您将研究比较复数、格式化包含复数的字符串等等。
测试复数的相等性
在数学上,当两个复数具有相同的值时,不管所采用的坐标系如何,它们都等于。然而,极坐标和直角坐标之间的转换通常会在 Python 中引入舍入误差,因此在比较它们时需要注意细微的差异。
例如,当您考虑半径等于 1 且倾斜 60°的单位圆上的一个点时,三角学很好地解决了这个问题,使得用笔和纸进行转换很简单:
>>> import math, cmath
>>> z1 = cmath.rect(1, math.radians(60))
>>> z2 = complex(0.5, math.sqrt(3)/2)
>>> z1 == z2
False
>>> z1.real, z2.real
(0.5000000000000001, 0.5)
>>> z1.imag, z2.imag
(0.8660254037844386, 0.8660254037844386)
即使你知道z1和z2是同一点,Python 也无法确定,因为存在舍入误差。幸运的是, PEP 485 文档定义了近似相等的函数,这些函数在math和cmath模块中可用:
>>> math.isclose(z1.real, z2.real)
True
>>> cmath.isclose(z1, z2)
True
记住在比较复数时一定要使用它们!如果默认容差对您的计算不够好,您可以通过指定附加参数来更改它。
复数排序
如果你熟悉元组,那么你知道 Python 可以对它们进行排序:
>>> planets = [
... (6, "saturn"),
... (4, "mars"),
... (1, "mercury"),
... (5, "jupiter"),
... (8, "neptune"),
... (3, "earth"),
... (7, "uranus"),
... (2, "venus"),
... ]
>>> from pprint import pprint
>>> pprint(sorted(planets))
[(1, 'mercury'),
(2, 'venus'),
(3, 'earth'),
(4, 'mars'),
(5, 'jupiter'),
(6, 'saturn'),
(7, 'uranus'),
(8, 'neptune')]
默认情况下,单个元组从左到右进行比较:
>>> (6, "saturn") < (4, "mars")
False
>>> (3, "earth") < (3, "moon")
True
在第一种情况下,数字6大于4,所以根本不考虑行星名称。不过,它们可以帮助解决平局。然而,复数就不是这样了,因为它们没有定义自然的排序关系。例如,如果您试图比较两个复数,就会得到一个错误:
>>> (3 + 2j) < (2 + 3j)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'complex' and 'complex'
虚维度是否应该比实维度更有分量?是否应该比较它们的大小?这取决于你,答案会有所不同。由于不能直接比较复数,所以需要通过指定一个自定义的键函数,比如abs(),告诉 Python 如何排序:
>>> cities = {
... complex(-64.78303, 32.2949): "Hamilton",
... complex(-66.105721, 18.466333): "San Juan",
... complex(-80.191788, 25.761681): "Miami"
... }
>>> for city in sorted(cities, key=abs, reverse=True):
... print(abs(city), cities[city])
...
84.22818453809096 Miami
72.38647347392259 Hamilton
68.63651945864338 San Juan
这将把复数按大小降序排列。
将复数格式化为字符串
没有任何特定于复数的格式代码,但是您可以使用浮点数的标准代码分别格式化它们的实部和虚部。下面,你会发现一些技术来证明这一点。他们中的一些人实际上将你的格式说明符同时应用到实部和虚部。
**注意:**字符串格式化可以让你忽略浮点表示错误,假装它不存在:
>>> import cmath
>>> z = abs(3 + 2j) * cmath.exp(1j*cmath.phase(3 + 2j))
>>> str(z)
'(3+1.9999999999999996j)'
>>> format(z, "g")
'3+2j'
格式说明符中的字母"g"代表通用格式,它将您的数字四舍五入到要求的精度。默认精度为六位有效数字。
让我们以下面的复数为例,将其格式化为两部分都有两位小数:
>>> z = pow(3 + 2j, 0.5)
>>> print(z)
(1.8173540210239707+0.5502505227003375j)
一种快速的方法是用数字格式说明符调用format(),或者创建一个适当格式化的 f 字符串:
>>> format(z, ".2f")
'1.82+0.55j'
>>> f"{z:.2f}"
'1.82+0.55j'
如果您想要更多的控制,例如,在加号运算符周围添加额外的填充,那么 f 字符串将是更好的选择:
>>> f"{z.real:.2f} + {z.imag:.2f}j"
'1.82 + 0.55j'
你也可以在一个字符串对象上调用 .format(),并将位置或关键字参数传递给它:
>>> "{0:.2f} + {0:.2f}j".format(z.real, z.imag)
'1.82 + 1.82j'
>>> "{re:.2f} + {im:.2f}j".format(re=z.real, im=z.imag)
'1.82 + 0.55j'
位置参数提供了一系列值,而关键字参数允许您通过名称引用它们。类似地,可以将字符串模操作符 ( %)与元组或字典一起使用:
>>> "%.2f + %.2fj" % (z.real, z.imag)
'1.82 + 0.55j'
>>> "%(re).2f + %(im).2fj" % {"re": z.real, "im": z.imag}
'1.82 + 0.55j'
但是,这使用了不同的占位符语法,有点过时。
创建自己的复杂数据类型
Python 数据模型定义了一组特殊的方法,您可以实现这些方法来使您的类与某些内置类型兼容。假设你正在处理点和向量,并且想要得到两个约束向量之间的角度。你可能会计算它们的点积,并做一些三角学。或者,你可以利用复数。
让我们首先定义您的类:
from typing import NamedTuple
class Point(NamedTuple):
x: float
y: float
class Vector(NamedTuple):
start: Point
end: Point
一个Point具有x和y坐标,而一个Vector连接两个点。你可能记得cmath.phase(),它计算一个复数的角距离。现在,如果你将矢量视为复数,并知道它们的相位,那么你可以减去它们,以获得所需的角度。
要让 Python 将向量实例识别为复数,必须在类体中提供.__complex__():
class Vector(NamedTuple):
start: Point
end: Point
def __complex__(self):
real = self.end.x - self.start.x
imag = self.end.y - self.start.y
return complex(real, imag)
里面的代码必须总是返回一个complex数据类型的实例,所以它通常从你的对象中构造一个新的复数。在这里,你减去初始点和终点,得到水平和垂直位移,作为实部和虚部。当您在 vector 实例上调用全局complex()时,该方法将通过委托运行:
>>> vector = Vector(Point(-2, -1), Point(1, 1))
>>> complex(vector)
(3+2j)
在某些情况下,您不必自己制作这种类型的铸件。让我们看一个实践中的例子:
>>> v1 = Vector(Point(-2, -1), Point(1, 1))
>>> v2 = Vector(Point(10, -4), Point(8, -1))
>>> import math, cmath
>>> math.degrees(cmath.phase(v2) - cmath.phase(v1))
90.0
你有两个向量,由四个不同的点标识。接下来,您将它们直接传递给cmath.phase(),它会将它们转换成复数并返回相位。相位差是两个向量之间的角度。
那不是很美吗?通过使用复数和一点 Python 技巧,您避免了键入大量容易出错的代码。
用复数计算离散傅立叶变换
虽然您可以使用实数通过傅立叶变换来计算周期函数频率的正弦和余弦系数,但通常更方便的是每个频率只处理一个复系数。复域中的离散傅立叶变换由以下公式给出:

对于每个频率仓 k ,它测量信号和以指数形式表示为复数的特定正弦波的相关性。(谢谢你,莱昂哈德·欧拉!)波的角频率可以通过将圆角(2π弧度)乘以离散样本数的 k 来计算:
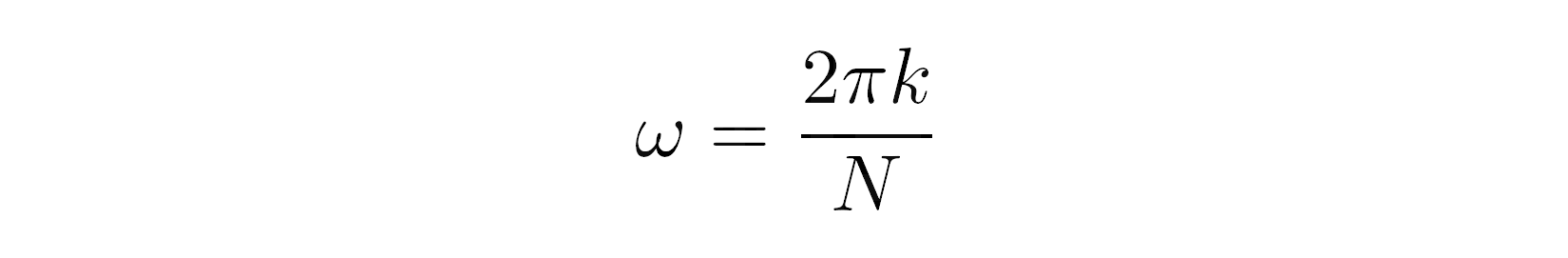
当您利用complex数据类型时,用 Python 编写这些代码看起来非常简洁:
from cmath import pi, exp
def discrete_fourier_transform(x, k):
omega = 2 * pi * k / (N := len(x))
return sum(x[n] * exp(-1j * omega * n) for n in range(N))
这个函数是上面公式的文字转录。现在,您可以对使用 Python 的wave模块从音频文件加载的声音或从头合成的声音进行频率分析。本教程附带的一个 Jupyter 笔记本可以让您交互式地进行音频合成和分析。
要用 Matplotlib 绘制频谱,你必须知道采样频率,它决定了你的频率仓分辨率以及奈奎斯特极限:
import matplotlib.pyplot as plt
def plot_frequency_spectrum(
samples,
samples_per_second,
min_frequency=0,
max_frequency=None,
):
num_bins = len(samples) // 2
nyquist_frequency = samples_per_second // 2
magnitudes = []
for k in range(num_bins):
magnitudes.append(abs(discrete_fourier_transform(samples, k)))
# Normalize magnitudes
magnitudes = [m / max(magnitudes) for m in magnitudes]
# Calculate frequency bins
bin_resolution = samples_per_second / len(samples)
frequency_bins = [k * bin_resolution for k in range(num_bins)]
plt.xlim(min_frequency, max_frequency or nyquist_frequency)
plt.bar(frequency_bins, magnitudes, width=bin_resolution)
频谱中频段的数量等于样本的一半,而奈奎斯特频率限制了您可以测量的最高频率。该变换返回一个复数,其幅度对应于给定频率的正弦波的振幅,而其角度是相位。
**注意:**要获得正确的振幅值,必须将数值加倍,并将结果振幅除以样本数。另一方面,如果您只关心频率直方图,那么您可以通过它们的总和或最大频率来归一化幅度。
这是一个声波频率图示例,它包含三个振幅相等的音调,即 440 Hz、1.5 kHz 和 5 kHz:
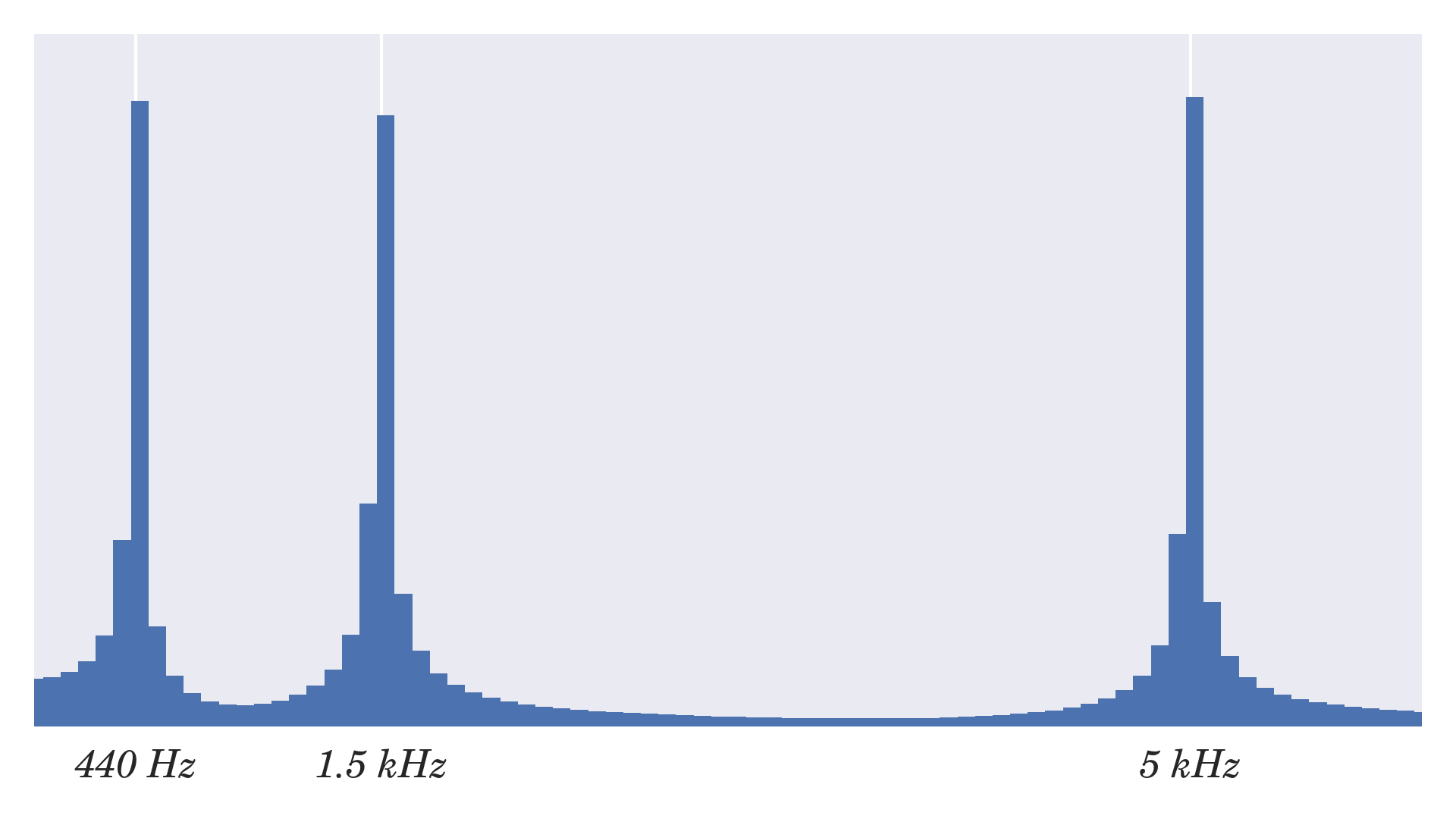
请注意,这是一个纯粹的学术示例,因为使用嵌套迭代计算离散傅立叶变换具有O(n2)的时间复杂度,这使得它在实践中无法使用。对于实际应用,您希望使用最好在 C 库中实现的快速傅立叶变换(FFT) 算法,例如 SciPy 中的 FFT。
结论
在 Python 中使用复数的便利性使它们成为一个非常有趣和实用的工具。你看到了实际上免费实现的二维向量,多亏了它们,你才能够分析声音频率。复数让你可以优雅地用代码表达数学公式,而没有太多样板语法的阻碍。
在本教程中,您学习了如何:
- 用 Python 中的文字定义复数
- 在直角和极坐标中表示复数
- 在算术表达式中使用复数
- 利用内置的
cmath模块 - 将数学公式直接翻译成 Python 代码
到目前为止,你对 Python 复数有什么体验?你被他们吓倒过吗?你认为他们还会让你解决什么有趣的问题?
您可以单击下面的链接来获得本教程的完整源代码:
获取示例代码: 单击此处获取示例代码,您将在本教程中使用来学习 Python 中的复数。**********
通过并发加速您的 Python 程序
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用并发加速 Python
如果你听说过很多关于将asyncio 添加到 Python 的讨论,但是很好奇它与其他并发方法相比如何,或者想知道什么是并发以及它如何加速你的程序,那么你来对地方了。
在这篇文章中,你将学到以下内容:
- 什么是并发
- 什么是平行度
- 如何比较一些 Python 的并发方法,包括
threading、asyncio、multiprocessing - 什么时候在你的程序中使用并发以及使用哪个模块
本文假设您对 Python 有基本的了解,并且至少使用 3.6 版本来运行这些示例。你可以从 真实 Python GitHub repo 下载例子。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
***参加测验:***通过我们的交互式“Python 并发性”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
什么是并发?
并发的字典定义是同时发生。在 Python 中,同时发生的事情有不同的名称(线程、任务、进程),但在高层次上,它们都指的是按顺序运行的指令序列。
我喜欢把它们看作不同的思路。每一个都可以在特定的点停止,处理它们的 CPU 或大脑可以切换到不同的点。每一个的状态都被保存,这样它就可以在被中断的地方重新启动。
您可能想知道为什么 Python 对同一个概念使用不同的词。原来线程、任务、进程只有从高层次来看才是一样的。一旦你开始挖掘细节,它们都代表着略有不同的东西。随着示例的深入,您将会看到更多的不同之处。
现在我们来谈谈这个定义的同时部分。你必须小心一点,因为当你深入到细节时,只有multiprocessing实际上同时运行这些思路。 Threading 和asyncio都运行在一个处理器上,因此一次只运行一个。他们只是巧妙地想办法轮流加速整个过程。即使它们不同时运行不同的思路,我们仍然称之为并发。
线程或任务轮流的方式是threading和asyncio的最大区别。在threading中,操作系统实际上知道每个线程,并可以随时中断它,开始运行不同的线程。这被称为抢先多任务,因为操作系统可以抢先你的线程进行切换。
抢先式多任务处理非常方便,因为线程中的代码不需要做任何事情来进行切换。因为“在任何时候”这个短语,它也可能是困难的。这种切换可能发生在一条 Python 语句的中间,甚至是像x = x + 1这样微不足道的语句。
另一方面,Asyncio使用协同多任务。当任务准备好被切换时,它们必须通过宣布来协作。这意味着任务中的代码必须稍加修改才能实现这一点。
预先做这些额外工作的好处是你总是知道你的任务将在哪里被交换。它不会在 Python 语句中间被换出,除非该语句被标记。稍后您将看到这是如何简化设计的。
什么是并行?
到目前为止,您已经看到了发生在单个处理器上的并发性。你的酷炫新笔记本电脑拥有的所有 CPU 内核呢?你如何利用它们?multiprocessing就是答案。
使用multiprocessing,Python 创建了新的流程。这里的进程可以被认为是一个几乎完全不同的程序,尽管从技术上来说,它们通常被定义为资源的集合,其中的资源包括内存、文件句柄等等。一种思考方式是,每个进程都在自己的 Python 解释器中运行。
因为它们是不同的进程,所以你在多处理程序中的每一个思路都可以在不同的内核上运行。在不同的内核上运行意味着它们实际上可以同时运行,这太棒了。这样做会产生一些复杂的问题,但是 Python 在大多数情况下做得很好。
现在,您已经了解了什么是并发和并行,让我们回顾一下它们的区别,然后我们可以看看它们为什么有用:
| 并发类型 | 转换决策 | 处理器数量 |
|---|---|---|
抢先多任务(threading) | 操作系统决定何时切换 Python 外部的任务。 | one |
协作多任务(asyncio) | 任务决定何时放弃控制权。 | one |
多重处理(multiprocessing) | 这些进程同时在不同的处理器上运行。 | 许多 |
这些并发类型中的每一种都很有用。让我们来看看它们能帮助你加速哪些类型的程序。
并发什么时候有用?
并发性对于两种类型的问题有很大的不同。这些通常被称为 CPU 绑定和 I/O 绑定。
I/O 相关的问题会导致你的程序变慢,因为它经常需要等待来自外部资源的输入/输出。当你的程序处理比你的 CPU 慢得多的东西时,它们经常出现。
比你的 CPU 慢的例子举不胜举,但是谢天谢地你的程序没有和它们中的大部分进行交互。你的程序最常与之交互的是文件系统和网络连接。
让我们看看这是什么样子:
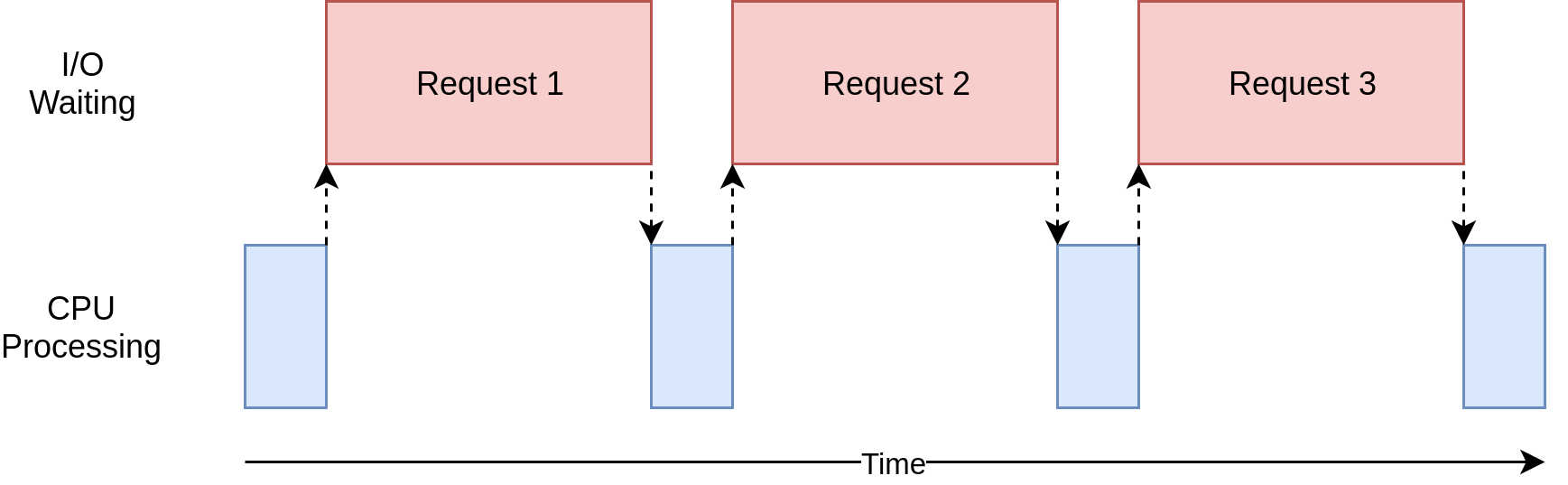
在上图中,蓝框表示程序工作的时间,红框表示等待 I/O 操作完成的时间。这个图不是按比例绘制的,因为互联网上的请求可能比 CPU 指令多花几个数量级的时间,所以你的程序可能会花费大部分时间等待。这是你的浏览器大部分时间在做的事情。
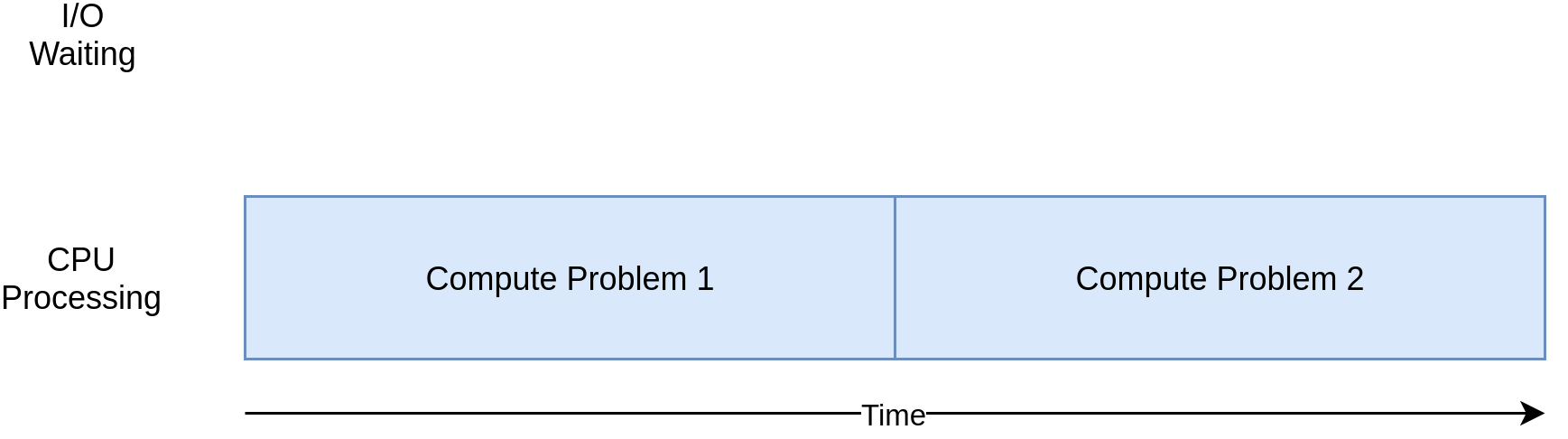
另一方面,有些程序可以在不与网络通信或不访问文件的情况下进行大量计算。这些是 CPU 受限的程序,因为限制程序速度的资源是 CPU,而不是网络或文件系统。
下面是一个 CPU 受限程序的相应图表:
通过下一节中的例子,您将看到不同形式的并发在 CPU 受限和 I/O 受限的程序中工作得更好或更差。向程序中添加并发性会增加额外的代码和复杂性,因此您需要决定潜在的加速是否值得付出额外的努力。到本文结束时,您应该有足够的信息来开始做决定。
这里有一个简短的总结来阐明这个概念:
| 输入输出绑定进程 | CPU 限制的进程 |
|---|---|
| 你的程序大部分时间都在和一个慢速设备对话,比如网络连接,硬盘,或者打印机。 | 你的程序大部分时间都在做 CPU 操作。 |
| 加速包括重叠等待这些设备的时间。 | 加快速度需要找到在相同时间内完成更多计算的方法。 |
您将首先看到 I/O 绑定的程序。然后,您将看到一些处理 CPU 受限程序的代码。
如何加速一个 I/O 绑定的程序
让我们首先关注 I/O 绑定程序和一个常见问题:通过网络下载内容。对于我们的例子,您将从几个站点下载网页,但它实际上可能是任何网络流量。它只是更容易可视化和设置网页。
同步版本
我们将从这个任务的非并发版本开始。注意,这个程序需要 requests 模块。你应该在运行它之前运行pip install requests,可能使用一个虚拟器。这个版本根本不使用并发:
import requests
import time
def download_site(url, session):
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with requests.Session() as session:
for url in sites:
download_site(url, session)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
如你所见,这是一个相当短的程序。从 URL 下载内容并打印尺寸。需要指出的一件小事是,我们使用了来自requests的 Session 对象。
可以简单地直接使用来自requests的get(),但是创建一个Session对象允许requests做一些奇特的网络技巧并真正加速。
download_all_sites()创建Session然后遍历列表中的站点,依次下载每个站点。最后,它打印出这个过程花了多长时间,这样您就可以满意地看到在下面的例子中并发性给我们带来了多大的帮助。
这个程序的处理图看起来很像上一节中的 I/O 绑定图。
**注意:**网络流量取决于多种因素,这些因素可能会因时而异。我看到由于网络问题,这些测试的次数从一次运行到另一次运行增加了一倍。
为什么同步版摇滚
这个版本的代码的伟大之处在于,它很简单。它相对容易编写和调试。考虑起来也更直截了当。只有一个思路贯穿其中,所以你可以预测下一步是什么,它会如何表现。
同步版本的问题
这里的大问题是,与我们将提供的其他解决方案相比,它相对较慢。下面是我的机器上最终输出的一个例子:
$ ./io_non_concurrent.py
[most output skipped]
Downloaded 160 in 14.289619207382202 seconds
**注意:**您的结果可能会有很大差异。运行这个脚本时,我看到时间从 14.2 秒到 21.9 秒不等。对于本文,我选择了三次跑步中最快的一次作为时间。这些方法之间的差异仍然很明显。
然而,速度慢并不总是一个大问题。如果您正在运行的程序在同步版本中只需要 2 秒钟,并且很少运行,那么可能不值得添加并发性。你可以停在这里。
如果你的程序经常运行怎么办?如果要跑几个小时呢?让我们通过使用threading重写这个程序来讨论并发性。
threading版本
正如你可能猜到的,编写一个线程化的程序需要更多的努力。然而,对于简单的情况,您可能会惊讶地发现几乎不需要额外的努力。下面是使用threading的相同程序的样子:
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
当你添加threading时,整体结构是一样的,你只需要做一些改变。download_all_sites()从每个站点调用一次函数变成了更复杂的结构。
在这个版本中,您正在创建一个ThreadPoolExecutor,这似乎是一件复杂的事情。让我们来分解一下:ThreadPoolExecutor = Thread + Pool + Executor。
你已经知道了Thread部分。那只是我们之前提到的一个思路。Pool部分是开始变得有趣的地方。这个对象将创建一个线程池,每个线程都可以并发运行。最后,Executor是控制池中每个线程如何以及何时运行的部分。它将在池中执行请求。
有益的是,标准库将ThreadPoolExecutor实现为上下文管理器,因此您可以使用with语法来管理Threads池的创建和释放。
一旦你有了一个ThreadPoolExecutor,你就可以使用它方便的.map()方法。该方法在列表中的每个站点上运行传入的函数。最重要的是,它使用自己管理的线程池自动并发运行它们。
那些来自其他语言,甚至 Python 2 的人,可能想知道在处理threading、Thread.start()、Thread.join()和Queue时,管理您习惯的细节的常用对象和函数在哪里。
这些仍然存在,您可以使用它们来实现对线程运行方式的细粒度控制。但是,从 Python 3.2 开始,标准库增加了一个名为Executors的高级抽象,如果您不需要这种细粒度的控制,它可以为您管理许多细节。
我们示例中另一个有趣的变化是每个线程都需要创建自己的requests.Session()对象。当你在看requests的文档时,不一定容易分辨,但是阅读这一期,似乎很清楚你需要为每个线程建立一个单独的会话。
这是关于threading的有趣且困难的问题之一。因为操作系统控制着您的任务何时被中断以及另一个任务何时开始,所以线程之间共享的任何数据都需要受到保护,或者说是线程安全的。不幸的是requests.Session()不是线程安全的。
根据数据是什么以及如何使用数据,有几种策略可以使数据访问线程安全。其中之一是使用线程安全的数据结构,比如 Python 的queue模块中的Queue。
这些对象使用像 threading.Lock 这样的低级原语来确保同一时间只有一个线程可以访问一块代码或一点内存。您通过ThreadPoolExecutor对象间接地使用了这个策略。
这里使用的另一个策略是线程本地存储。创建一个看起来像全局的对象,但却是特定于每个线程的。在您的示例中,这是通过thread_local和get_session()完成的:
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
local()是在threading模块中专门解决这个问题的。这看起来有点奇怪,但是您只想创建这些对象中的一个,而不是为每个线程创建一个。对象本身负责分离不同线程对不同数据的访问。
当调用get_session()时,它查找的session是特定于它运行的特定线程的。所以每个线程在第一次调用get_session()时都会创建一个会话,然后在整个生命周期中的每个后续调用中都会使用这个会话。
最后,关于选择线程数量的一个简短说明。您可以看到示例代码使用了 5 个线程。你可以随意摆弄这个数字,看看总的时间是如何变化的。您可能认为每次下载一个线程是最快的,但至少在我的系统上不是这样。我发现最快的结果出现在 5 到 10 个线程之间。如果超过这个值,那么创建和销毁线程的额外开销会抵消所有节省的时间。
这里很难回答的一个问题是,线程的正确数量对于不同的任务来说并不是一个常数。需要做一些实验。
为什么threading版摇滚
好快啊!这是我最快的一次测试。请记住,非并发版本耗时超过 14 秒:
$ ./io_threading.py
[most output skipped]
Downloaded 160 in 3.7238826751708984 seconds
下面是它的执行时序图:
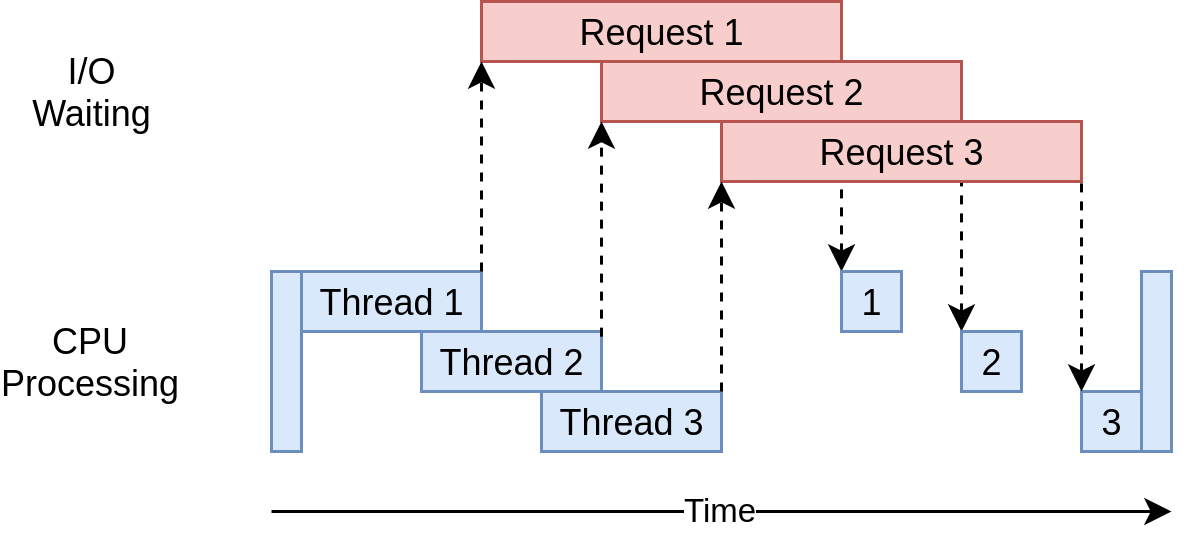
它使用多线程同时向网站发出多个打开的请求,允许您的程序重叠等待时间并更快地获得最终结果!耶!这就是目标。
版本threading的问题
正如你从例子中看到的,这需要更多的代码来实现,你真的需要考虑一下线程之间共享什么数据。
线程可以以微妙且难以察觉的方式进行交互。这些交互会导致竞争条件,这种竞争条件经常会导致难以发现的随机的、间歇性的错误。那些不熟悉竞争条件概念的人可能想扩展阅读下面的部分。
竞争条件是一整类微妙的错误,在多线程代码中可能并且经常发生。竞争情况的发生是因为程序员没有充分保护数据访问,以防止线程相互干扰。在编写线程代码时,您需要采取额外的步骤来确保事情是线程安全的。
这里发生的事情是操作系统控制你的线程何时运行,何时被换出让另一个线程运行。这种线程交换可以在任何时候发生,甚至在执行 Python 语句的子步骤时。举个简单的例子,看看这个函数:
import concurrent.futures
counter = 0
def increment_counter(fake_value):
global counter
for _ in range(100):
counter += 1
if __name__ == "__main__":
fake_data = [x for x in range(5000)]
counter = 0
with concurrent.futures.ThreadPoolExecutor(max_workers=5000) as executor:
executor.map(increment_counter, fake_data)
这段代码与您在上面的threading示例中使用的结构非常相似。不同之处在于,每个线程都在访问同一个全局变量 counter并递增它。Counter没有受到任何保护,所以它不是线程安全的。
为了增加counter,每个线程需要读取当前值,给它加 1,然后将该值保存回变量。发生在这一行:counter += 1。
因为操作系统对您的代码一无所知,并且可以在执行的任何时候交换线程,所以这种交换可能发生在线程读取值之后,但在它有机会写回值之前。如果正在运行的新代码也修改了counter,那么第一个线程就有了数据的旧拷贝,问题就会随之而来。
可以想象,碰到这种情况是相当罕见的。你可以运行这个程序成千上万次,永远看不到问题。这就是为什么这种类型的问题很难调试,因为它可能很难重现,并可能导致随机出现的错误。
作为进一步的例子,我想提醒你requests.Session()不是线程安全的。这意味着,如果多个线程使用同一个Session,在某些地方可能会发生上述类型的交互。我提出这个问题并不是要诽谤requests,而是要指出这些问题很难解决。
asyncio版本
在您开始研究asyncio示例代码之前,让我们更多地讨论一下asyncio是如何工作的。
asyncio基础知识
这将是asyncio的简化版。这里忽略了许多细节,但它仍然传达了其工作原理。
asyncio的一般概念是,一个称为事件循环的 Python 对象控制每个任务如何以及何时运行。事件循环知道每个任务,并且知道它处于什么状态。实际上,任务可能处于许多状态,但现在让我们想象一个只有两种状态的简化事件循环。
就绪状态将指示任务有工作要做并准备好运行,等待状态意味着任务正在等待一些外部事情完成,例如网络操作。
简化的事件循环维护两个任务列表,每个列表对应一种状态。它选择一个就绪任务,并让它重新开始运行。该任务处于完全控制中,直到它合作地将控制权交还给事件循环。
当正在运行的任务将控制权交还给事件循环时,事件循环会将该任务放入就绪或等待列表中,然后遍历等待列表中的每个任务,以查看它是否在 I/O 操作完成时已就绪。它知道就绪列表中的任务仍然是就绪的,因为它知道它们还没有运行。
一旦所有的任务都被重新排序到正确的列表中,事件循环就会选择下一个要运行的任务,并重复这个过程。简化的事件循环挑选等待时间最长的任务并运行它。这个过程重复进行,直到事件循环结束。
asyncio很重要的一点是,任务永远不会放弃控制,除非有意这样做。他们从不在行动中被打断。这使得我们在asyncio比在threading更容易共享资源。您不必担心使您的代码线程安全。
这是对正在发生的asyncio的高级视图。如果你想要更多的细节,这个 StackOverflow 答案提供了一些很好的细节,如果你想深入挖掘的话。
async和await
现在来说说 Python 中新增的两个关键词:async和await。根据上面的讨论,您可以将await视为允许任务将控制权交还给事件循环的魔法。当您的代码等待函数调用时,这是一个信号,表明调用可能需要一段时间,任务应该放弃控制。
最简单的方法是将async看作 Python 的一个标志,告诉它将要定义的函数使用了await。在某些情况下,这并不完全正确,比如异步发电机,但它适用于许多情况,并在您开始时为您提供一个简单的模型。
您将在下一段代码中看到的一个例外是async with语句,它从您通常等待的对象创建一个上下文管理器。虽然语义略有不同,但想法是一样的:将这个上下文管理器标记为可以被换出的东西。
我相信您可以想象,管理事件循环和任务之间的交互是很复杂的。对于从asyncio开始的开发者来说,这些细节并不重要,但是你需要记住任何调用await的函数都需要用async来标记。否则会出现语法错误。
回码
现在你已经对什么是asyncio有了一个基本的了解,让我们浏览一下示例代码的asyncio版本,并弄清楚它是如何工作的。注意这个版本增加了 aiohttp 。您应该在运行之前运行pip install aiohttp:
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print("Read {0} from {1}".format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download_site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")
这个版本比前两个版本稍微复杂一点。它有相似的结构,但是设置任务比创建ThreadPoolExecutor要多一点工作。让我们从示例的顶部开始。
T2download_site()
除了函数定义行上的async关键字和实际调用session.get()时的async with关键字之外,顶部的download_site()几乎与threading版本相同。稍后您将看到为什么Session可以在这里传递,而不是使用线程本地存储。
T2download_all_sites()
download_all_sites()是与threading示例相比最大的变化。
您可以在所有任务之间共享该会话,因此该会话在这里被创建为上下文管理器。这些任务可以共享会话,因为它们都运行在同一个线程上。当会话处于不良状态时,一个任务不可能中断另一个任务。
在上下文管理器中,它使用asyncio.ensure_future()创建了一个任务列表,并负责启动它们。一旦创建了所有的任务,这个函数就使用asyncio.gather()来保持会话上下文活动,直到所有的任务都完成。
threading代码做了一些类似的事情,但是细节在ThreadPoolExecutor中可以方便地处理。目前还没有一个AsyncioPoolExecutor类。
然而,这里的细节隐藏了一个微小但重要的变化。还记得我们如何讨论要创建的线程数量吗?在threading的例子中,线程的最佳数量并不明显。
asyncio的一个很酷的优势是它的伸缩性比threading好得多。与线程相比,创建每个任务需要的资源和时间要少得多,因此创建和运行更多的任务效果会更好。这个例子只是为每个站点创建了一个单独的下载任务,这样做效果很好。
T2__main__
最后,asyncio的性质意味着您必须启动事件循环并告诉它运行哪些任务。文件底部的__main__部分包含了get_event_loop()和run_until_complete()的代码。如果不说别的,他们在命名这些函数方面做得非常好。
如果你已经升级到了 Python 3.7 ,Python 核心开发者为你简化了这个语法。你可以用asyncio.run()代替asyncio.get_event_loop().run_until_complete()绕口令。
为什么asyncio版摇滚
真的很快!在我的机器上进行的测试中,这是最快的代码版本,远远超过其他版本:
$ ./io_asyncio.py
[most output skipped]
Downloaded 160 in 2.5727896690368652 seconds
执行时序图看起来与threading示例中发生的事情非常相似。只是 I/O 请求都是由同一个线程完成的:
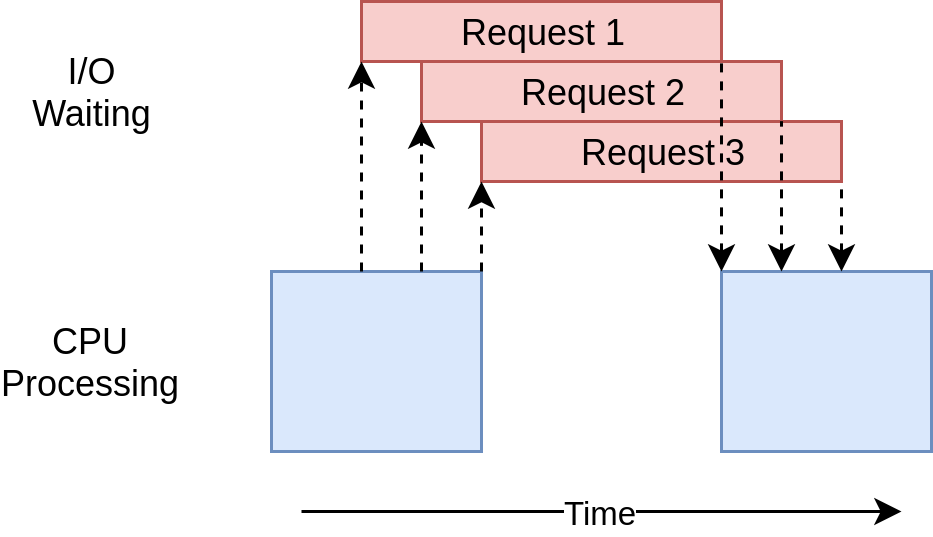
缺少像ThreadPoolExecutor这样的包装器使得这段代码比threading的例子要复杂一些。在这种情况下,您必须做一些额外的工作才能获得更好的性能。
还有一个常见的论点是,必须在适当的位置添加async和await会增加额外的复杂性。在某种程度上,这是真的。这个论点的另一面是,它迫使你去思考一个给定的任务什么时候会被交换出去,这可以帮助你创造一个更好、更快的设计。
缩放问题在这里也很突出。用一个线程为每个站点运行上面的threading例子明显比用少量线程运行慢。运行有数百个任务的asyncio示例丝毫没有降低它的速度。
版本asyncio的问题
在这一点上,asyncio有几个问题。你需要特殊的异步版本的库来获得asyncio的全部优势。如果你只是使用requests来下载网站,它会慢得多,因为requests不是用来通知事件循环它被阻止的。随着时间的推移,这个问题越来越小,越来越多的图书馆接受了asyncio。
另一个更微妙的问题是,如果其中一个任务不合作,合作多任务的所有优势都会被抛弃。代码中的一个小错误会导致一个任务停止运行,并长时间占用处理器,使其他需要运行的任务无法运行。如果任务不将控制权交还给它,事件循环就无法中断。
考虑到这一点,让我们采用一种完全不同的方法来实现并发性。
multiprocessing版本
与之前的方法不同,multiprocessing版本的代码充分利用了您的新电脑拥有的多个 CPU。或者,在我的情况下,我的笨重,旧笔记本电脑。让我们从代码开始:
import requests
import multiprocessing
import time
session = None
def set_global_session():
global session
if not session:
session = requests.Session()
def download_site(url):
with session.get(url) as response:
name = multiprocessing.current_process().name
print(f"{name}:Read {len(response.content)} from {url}")
def download_all_sites(sites):
with multiprocessing.Pool(initializer=set_global_session) as pool:
pool.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 80
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
这比asyncio的例子短得多,实际上看起来与threading的例子非常相似,但是在我们深入研究代码之前,让我们快速浏览一下multiprocessing为您做了什么。
multiprocessing总而言之
到目前为止,本文中的所有并发示例都只在计算机的单个 CPU 或内核上运行。其原因与 CPython 当前的设计和一种叫做全局解释器锁(或 GIL)的东西有关。
这篇文章不会深入到 GIL 的方式和原因。现在知道这个例子的同步、threading和asyncio版本都运行在单个 CPU 上就足够了。
标准库中的旨在打破这一障碍,并在多个 CPU 上运行您的代码。在高层次上,它通过创建一个新的 Python 解释器实例来运行在每个 CPU 上,然后将程序的一部分移植到它上面来运行。
可以想象,启动一个单独的 Python 解释器不如在当前的 Python 解释器中启动一个新线程快。这是一个重量级的操作,并带有一些限制和困难,但对于正确的问题,它可以产生巨大的差异。
multiprocessing代号
代码与我们的同步版本相比有一些小的变化。第一个在download_all_sites()里。它不是简单地重复调用download_site(),而是创建一个multiprocessing.Pool对象,并让它将download_site映射到可迭代的sites。从threading示例来看,这应该很熟悉。
这里发生的是,Pool创建了许多独立的 Python 解释器进程,并让每个进程对 iterable 中的一些项目运行指定的函数,在我们的例子中,iterable 是站点列表。主进程和其他进程之间的通信由multiprocessing模块为您处理。
创建Pool的行值得你关注。首先,它没有指定在Pool中创建多少个流程,尽管这是一个可选参数。默认情况下,multiprocessing.Pool()会决定你电脑中的 CPU 数量并与之匹配。这通常是最好的答案,对我们来说也是如此。
对于这个问题,增加流程的数量并没有让事情变得更快。它实际上减慢了速度,因为设置和拆除所有这些进程的成本大于并行执行 I/O 请求的好处。
接下来是通话的initializer=set_global_session部分。记住我们的Pool中的每个进程都有自己的内存空间。这意味着他们不能共享像Session对象这样的东西。您不希望每次调用函数时都创建一个新的Session,而是希望为每个进程创建一个。
initializer功能参数就是为这种情况建立的。没有办法将返回值从initializer传递回进程download_site()调用的函数,但是您可以初始化一个全局session变量来保存每个进程的单个会话。因为每个进程都有自己的内存空间,所以每个进程的全局内存空间都是不同的。
这就是事情的全部。代码的其余部分与您之前看到的非常相似。
为什么multiprocessing版摇滚
这个例子的multiprocessing版本很棒,因为它相对容易设置,只需要很少的额外代码。它还充分利用了计算机的 CPU 能力。这段代码的执行时序图如下所示:
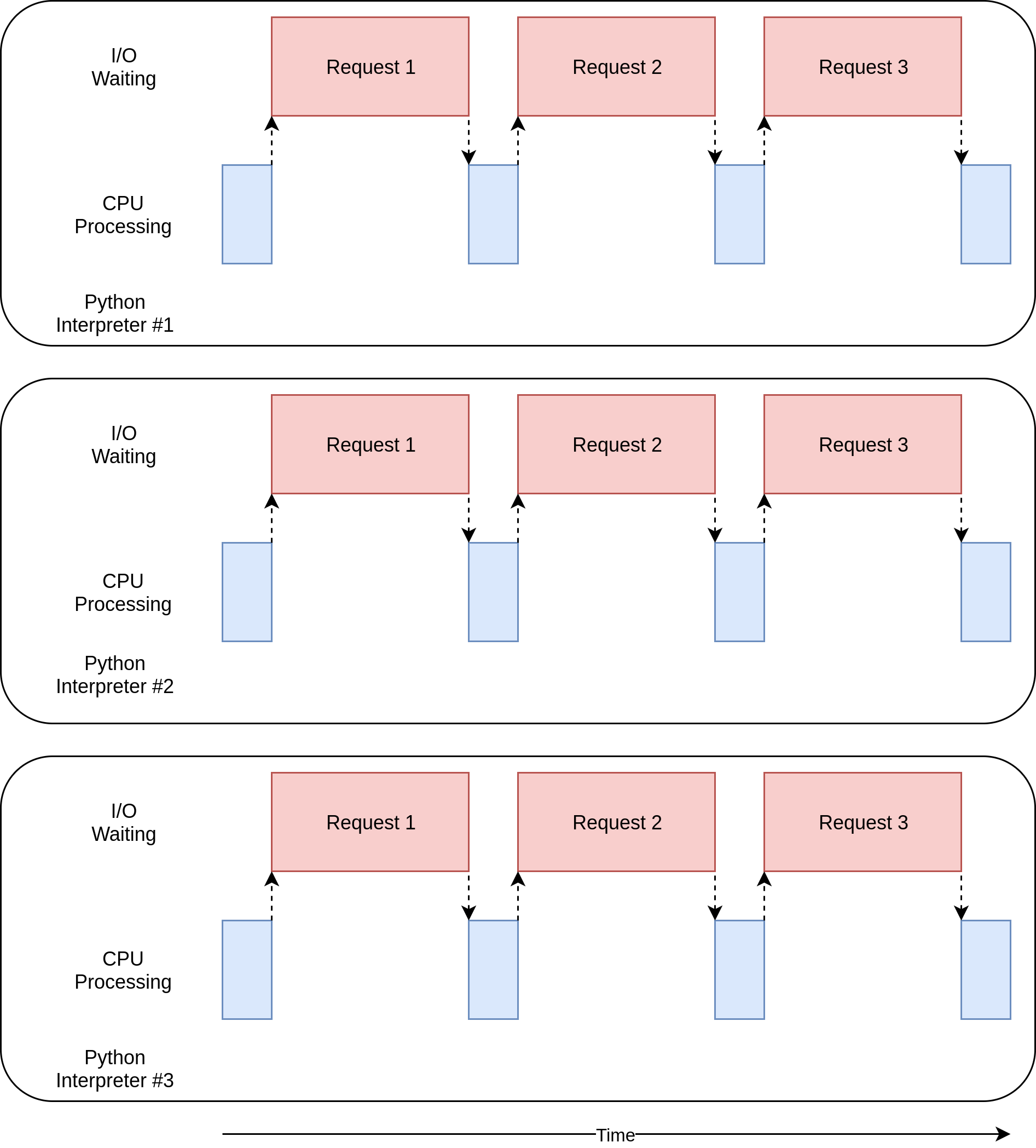
版本multiprocessing的问题
这个版本的例子确实需要一些额外的设置,而且全局session对象很奇怪。你必须花一些时间考虑在每个进程中哪些变量将被访问。
最后,它显然比本例中的asyncio和threading版本慢:
$ ./io_mp.py
[most output skipped]
Downloaded 160 in 5.718175172805786 seconds
这并不奇怪,因为 I/O 绑定问题并不是multiprocessing存在的真正原因。当您进入下一节并查看 CPU 相关的示例时,您将会看到更多内容。
如何加速一个 CPU 受限的程序
让我们稍微改变一下思路。到目前为止,这些例子都处理了一个 I/O 绑定的问题。现在,您将研究一个 CPU 相关的问题。正如您所看到的,一个 I/O 绑定的问题大部分时间都在等待外部操作(如网络调用)的完成。另一方面,与 CPU 相关的问题很少进行 I/O 操作,它的总执行时间是它处理所需数据速度的一个因素。
出于我们示例的目的,我们将使用一个有点傻的函数来创建一些需要在 CPU 上运行很长时间的东西。此函数计算从 0 到传入值的每个数字的平方和:
def cpu_bound(number):
return sum(i * i for i in range(number))
您将传入大量的数字,所以这将需要一段时间。请记住,这只是你的代码的占位符,它实际上做了一些有用的事情,需要大量的处理时间,比如计算方程的根或者对大型数据结构进行排序。
CPU 绑定的同步版本
现在让我们来看看这个例子的非并发版本:
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
for number in numbers:
cpu_bound(number)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")
这段代码调用cpu_bound() 20 次,每次都使用不同的大数。它在单个 CPU 上的单个进程中的单个线程上完成所有这些工作。执行时序图如下所示:
与 I/O 相关的示例不同,CPU 相关的示例通常在运行时相当一致。在我的机器上,这个大约需要 7.8 秒:
$ ./cpu_non_concurrent.py
Duration 7.834432125091553 seconds
显然我们可以做得更好。这一切都在一个 CPU 上运行,没有并发性。让我们看看我们能做些什么来使它变得更好。
threading和asyncio版本
你认为使用threading或asyncio重写这段代码会提高多少速度?
如果你回答“一点也不”,给自己一块饼干。如果你回答“它会让你慢下来”,给自己两块饼干。
原因如下:在上面的 I/O 绑定示例中,总时间的大部分都花在了等待缓慢的操作完成上。threading和asyncio通过让你的等待时间重叠来加快速度,而不是按顺序进行。
然而,在 CPU 受限的问题上,没有等待。中央处理器正在尽可能快地处理这个问题。在 Python 中,线程和任务都在同一个进程的同一个 CPU 上运行。这意味着一个 CPU 负责非并发代码的所有工作,外加设置线程或任务的额外工作。需要超过 10 秒钟:
$ ./cpu_threading.py
Duration 10.407078266143799 seconds
我已经写了这段代码的一个threading版本,并把它和其他示例代码一起放在了 GitHub repo 中,这样你就可以自己去测试了。不过,我们先不要看这个。
受 CPU 限制的multiprocessing版本
现在你终于到达了multiprocessing真正闪耀的地方。与其他并发库不同,multiprocessing被明确设计为在多个 CPU 之间共享繁重的 CPU 工作负载。下面是它的执行时序图:
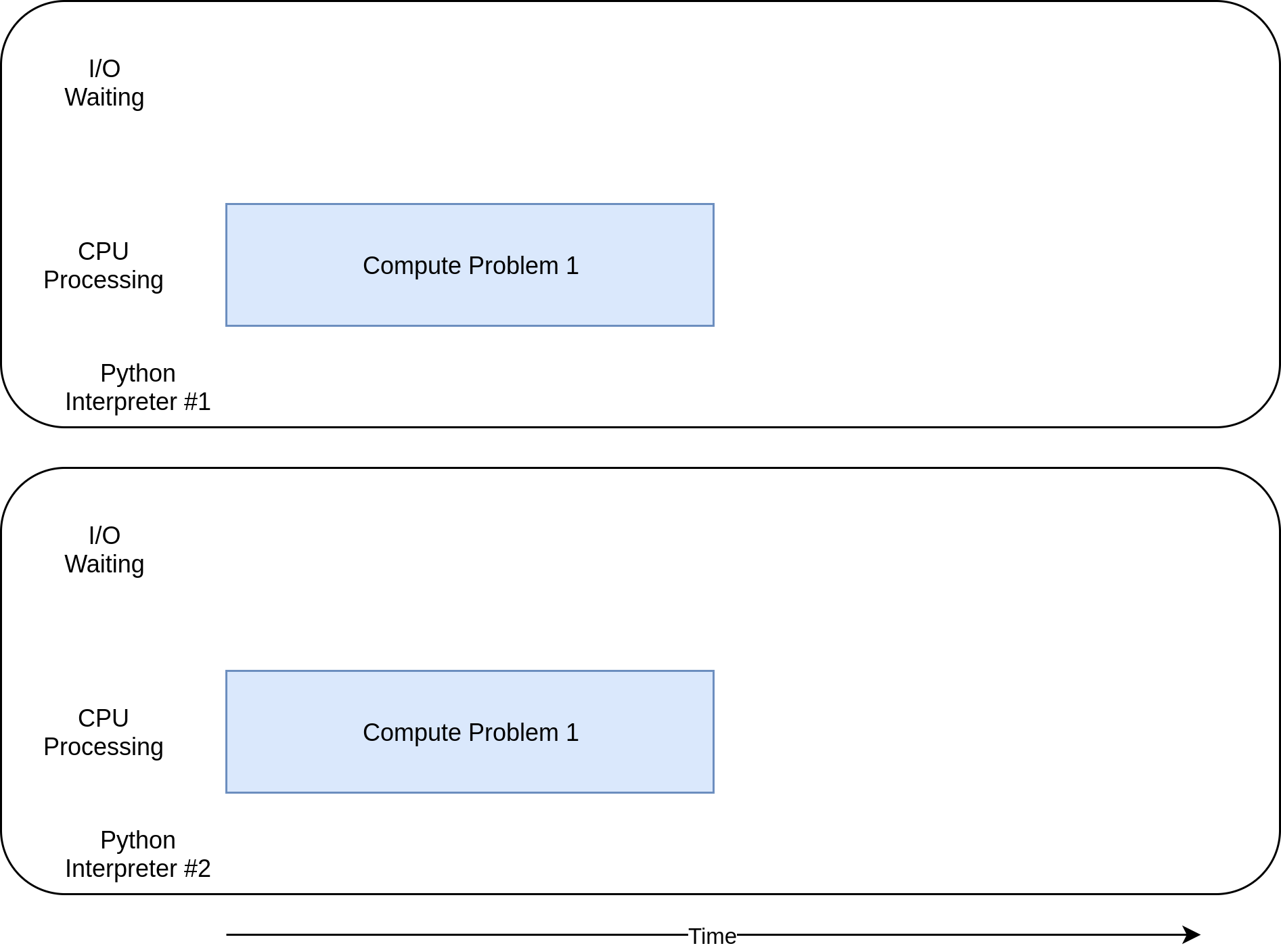
下面是代码的样子:
import multiprocessing
import time
def cpu_bound(number):
return sum(i * i for i in range(number))
def find_sums(numbers):
with multiprocessing.Pool() as pool:
pool.map(cpu_bound, numbers)
if __name__ == "__main__":
numbers = [5_000_000 + x for x in range(20)]
start_time = time.time()
find_sums(numbers)
duration = time.time() - start_time
print(f"Duration {duration} seconds")
非并发版本的代码几乎没有什么变化。你不得不import multiprocessing然后从循环遍历数字变成创建一个multiprocessing.Pool对象,并使用它的.map()方法在工人进程空闲时向它们发送单独的数字。
这正是你对 I/O 绑定的multiprocessing代码所做的,但是这里你不需要担心Session对象。
如上所述,multiprocessing.Pool()构造函数的processes可选参数值得注意。您可以指定想要在Pool中创建和管理多少个Process对象。默认情况下,它将确定您的机器中有多少个 CPU,并为每个 CPU 创建一个进程。虽然这对于我们的简单示例来说非常有用,但是您可能希望在生产环境中有更多的控制。
此外,正如我们在第一部分提到的threading,multiprocessing.Pool代码是建立在像Queue和Semaphore这样的构建模块之上的,这对于那些用其他语言编写过多线程和多处理代码的人来说是很熟悉的。
为什么multiprocessing版摇滚
这个例子的multiprocessing版本很棒,因为它相对容易设置,只需要很少的额外代码。它还充分利用了计算机的 CPU 能力。
哎,上次我们看multiprocessing的时候我也是这么说的。最大的不同在于,这一次它显然是最佳选择。在我的机器上需要 2.5 秒:
$ ./cpu_mp.py
Duration 2.5175397396087646 seconds
这比我们看到的其他选项要好得多。
版本multiprocessing的问题
使用multiprocessing有一些缺点。在这个简单的例子中,它们并没有真正显示出来,但是将您的问题分解开来,使每个处理器都可以独立工作,有时会很困难。
此外,许多解决方案需要进程间更多的通信。这会给你的解决方案增加一些非并发程序不需要处理的复杂性。
何时使用并发
您已经讨论了很多内容,所以让我们回顾一些关键的想法,然后讨论一些决策点,这些决策点将帮助您确定您希望在项目中使用哪个并发模块(如果有的话)。
这个过程的第一步是决定你是否应该使用并发模块。虽然这里的例子使每个库看起来都很简单,但是并发总是带来额外的复杂性,并且经常会导致难以发现的错误。
坚持添加并发性,直到您发现一个已知的性能问题,然后再决定您需要哪种类型的并发性。正如 Donald Knuth 所说,“过早优化是编程中所有罪恶(或者至少是大部分罪恶)的根源。”
一旦你决定你应该优化你的程序,弄清楚你的程序是受 CPU 限制的还是受 I/O 限制的是一个很好的下一步。请记住,I/O 绑定的程序是那些花费大部分时间等待事情发生的程序,而 CPU 绑定的程序花费时间尽可能快地处理数据或计算数字。
如您所见,CPU 限制的问题只有通过使用multiprocessing才能真正解决。threading和asyncio对这类问题一点帮助都没有。
对于 I/O 相关的问题,Python 社区有一条通用的经验法则:“尽可能使用asyncio,必要时使用threading”asyncio可以为这种类型的程序提供最好的速度,但有时你会需要尚未移植的关键库来利用asyncio。请记住,任何没有放弃对事件循环的控制的任务都会阻塞所有其他任务。
结论
现在,您已经看到了 Python 中可用的基本并发类型:
threadingasynciomultiprocessing
您已经理解了决定对于给定的问题应该使用哪种并发方法,或者是否应该使用任何一种并发方法!此外,您对使用并发时可能出现的一些问题有了更好的理解。
我希望您从这篇文章中学到了很多,并且在您自己的项目中发现了并发的巨大用途!请务必参加下面链接的“Python 并发性”测验,检查您的学习情况:
***参加测验:***通过我们的交互式“Python 并发性”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用并发加速 Python********

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









