









 本文介绍了无监督机器学习中的K-Means和层次聚类算法。阐述了K-Means确定K值的方法,对比了两种算法的时间复杂度,还介绍了验证聚类模型的技术,如轮廓系数。分析了二者的区别、优缺点,并给出了各自适用场景,助于选择合适算法。
本文介绍了无监督机器学习中的K-Means和层次聚类算法。阐述了K-Means确定K值的方法,对比了两种算法的时间复杂度,还介绍了验证聚类模型的技术,如轮廓系数。分析了二者的区别、优缺点,并给出了各自适用场景,助于选择合适算法。
文章目录
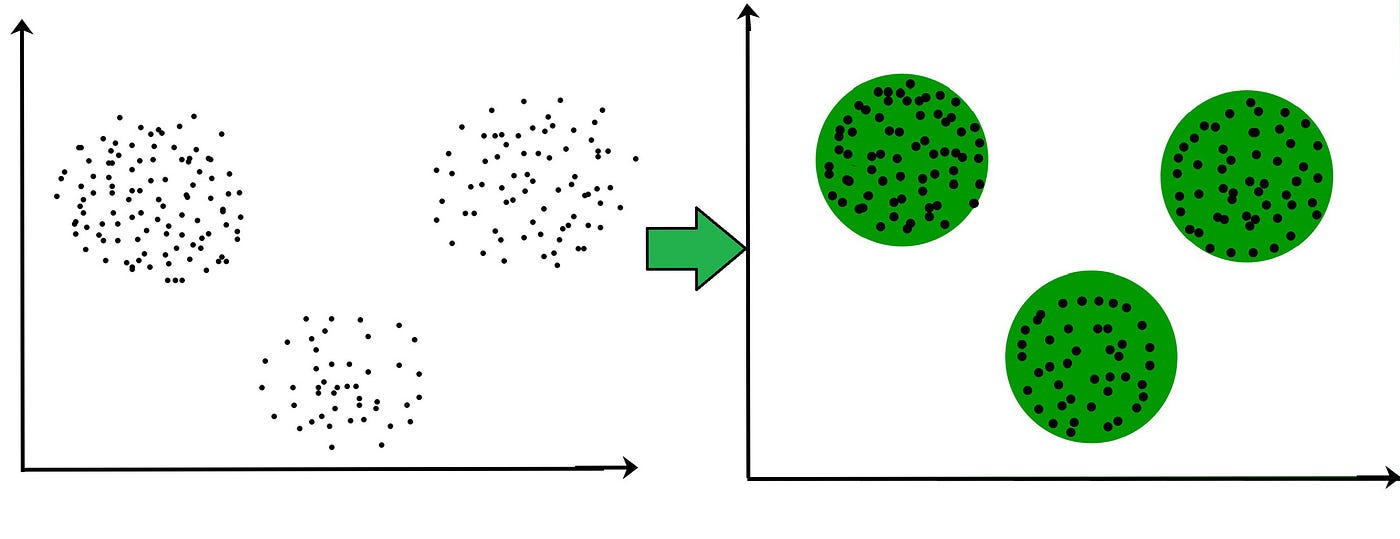
K-Means聚类
在无监督机器学习中,聚类是一种用于分组相似数据的技术。其目标是根据不同的数据输入创建聚类,而不考虑任何特定的输出。其中一种流行的聚类数据的方法是K-means聚类。
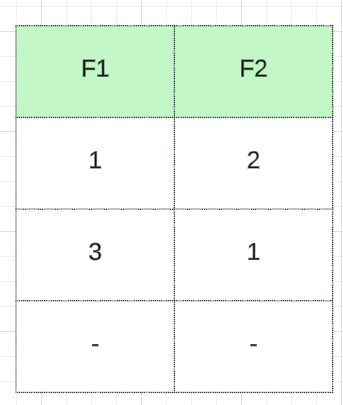
让我们来谈谈简单的数据点。想象一下,你有一组具有两个特征 F1 和 F2 的数据点。我们可以根据这些特征在二维空间中绘制这些点。我们的目标是将相似的数据点分组。假设我们可以从这些聚类中看到我们有两个组。第一组由具有相似特征的数据点组成,第二组由具有相似特征的数据点组成。这就是聚类发挥作用的地方。我们将探讨为什么聚类是有益的,并深入了解其背后的数学直觉。此外,我们还将研究聚类的各种用途。
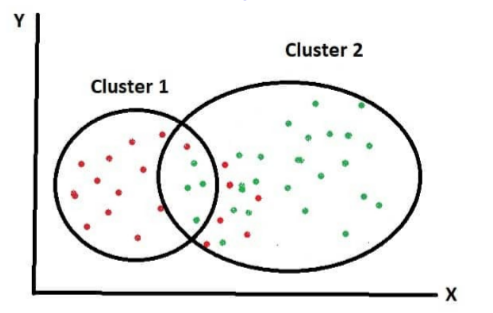
由具有相似特征的数据点组成的群组
在创建自定义集成模型时,我们通常会先对数据集进行聚类。这涉及将聚类算法应用于将数据分组为两个或三个独立的群组。一旦我们有了这些群组,我们就可以对每个群组应用回归或分类算法来解决特定的输出问题。为了更好地理解这个过程,重点关注k-means聚类算法的工作原理是很重要的。K代表有多少个群组(簇)。如果我们有两个群组(簇),那么k将是2。
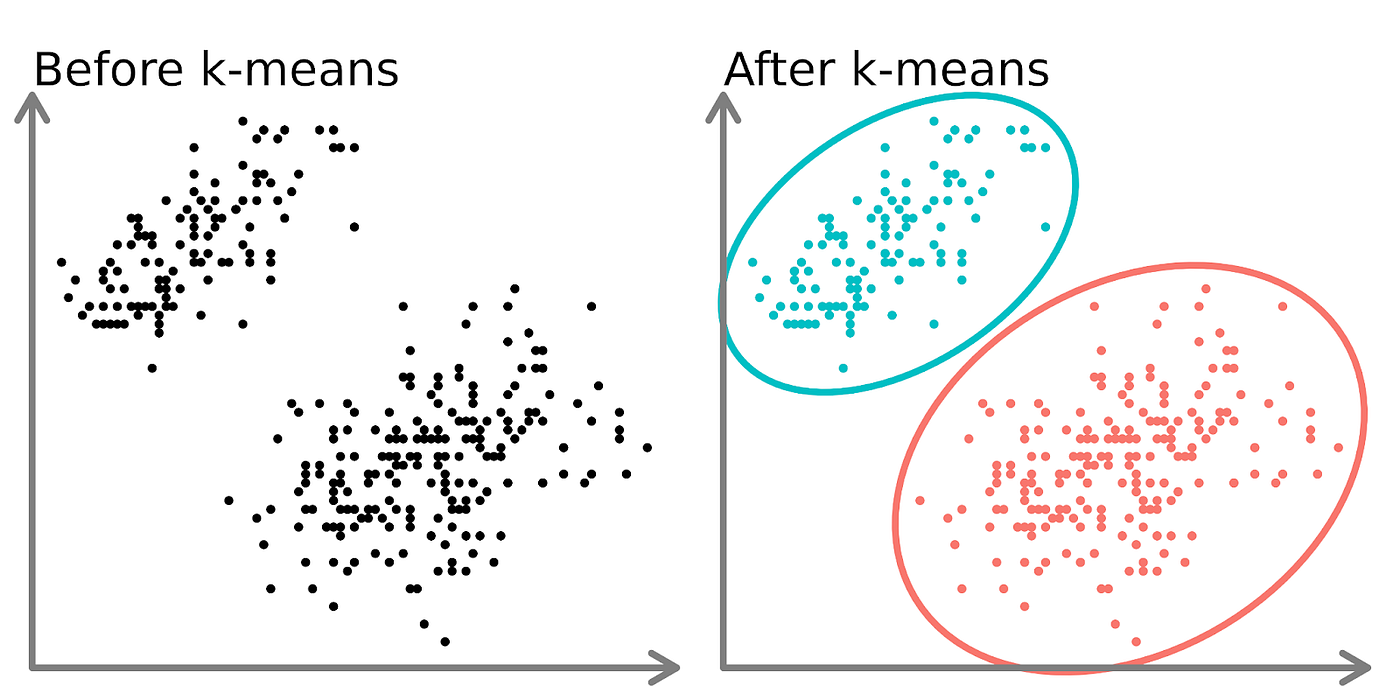
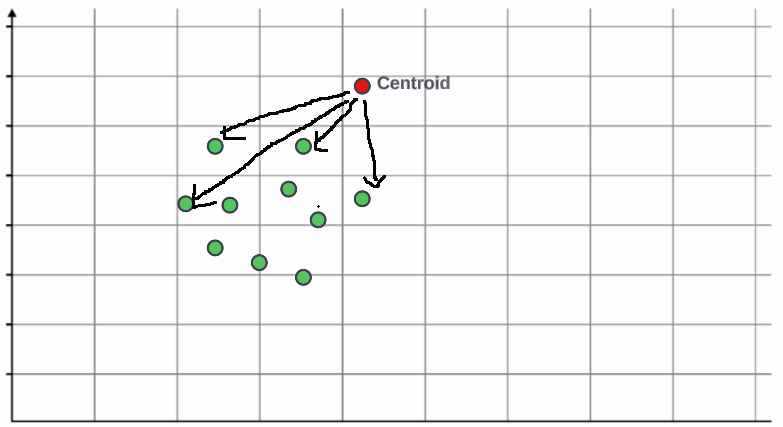
每个群组都有一个质心。如果我们有一个像图片中这样的数据集,我们可以很容易地看出有两个独立的群组,因为有两个维度的数据。然而,请记住,由于高维度,真实世界的数据集会更加复杂。那么你将看不到数据的绘制。你如何得出只有两个群组存在的结论?为此,我们应该遵循一些步骤。
-
首先,我们需要尝试不同的K值。我们可以通过测试不同的质心来实现这一点,直到找到合适的K值。假设我们有一个特定的数据点,我们可以从K值为1、2或3开始测试。在这种情况下,让我们假设我们从K = 2开始。我们是如何得出这个值的?一个关键的概念是簇内平方和。簇内平方和是对每个簇内观察值的变异性的度量。一般来说,簇内平方和较小的簇比簇内平方和较大的簇更紧凑。具有较高值的簇表现出簇内观察值的更大变异性。
-
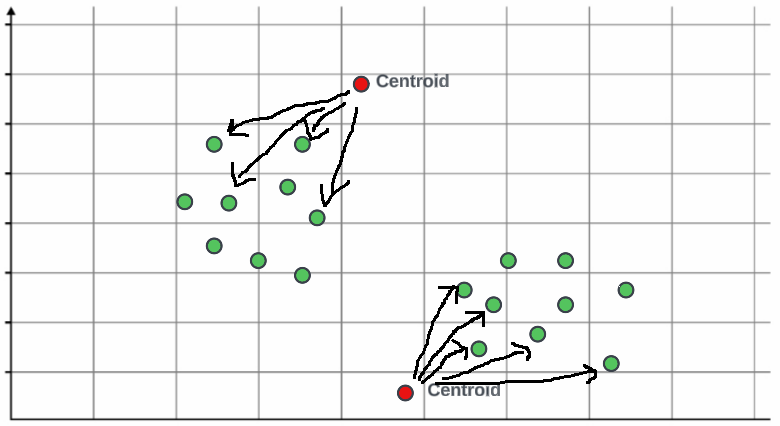
在这种情况下,我们正在使用两个质心。我们将随机初始化它们,并用不同的颜色标记它们。在初始化质心之后,我们需要确定哪些点更接近每个质心。这可以通过计算点之间的距离来完成。为了更容易可视化,我们可以画一条连接两个质心的直线和一条垂直于直线的直线。所有更接近特定质心的点将被标记为相同的颜色。一旦我们确定了所有的点,我们可以使用欧几里得距离计算所有值的总和。这将帮助我们确定每个点属于哪个质心。
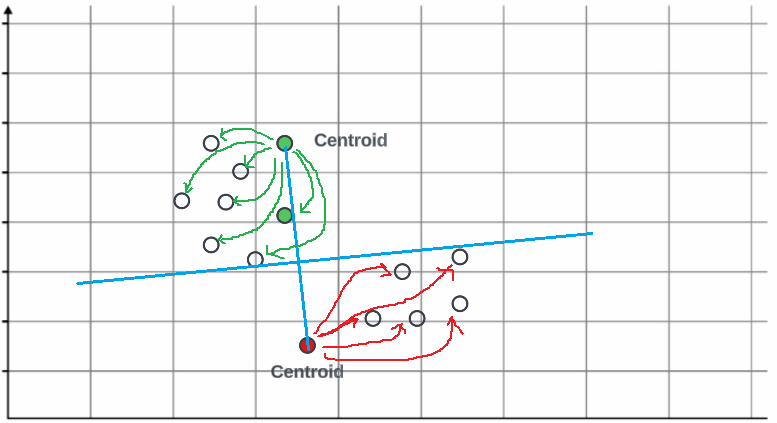
离质心更近的点用相同的颜色标记
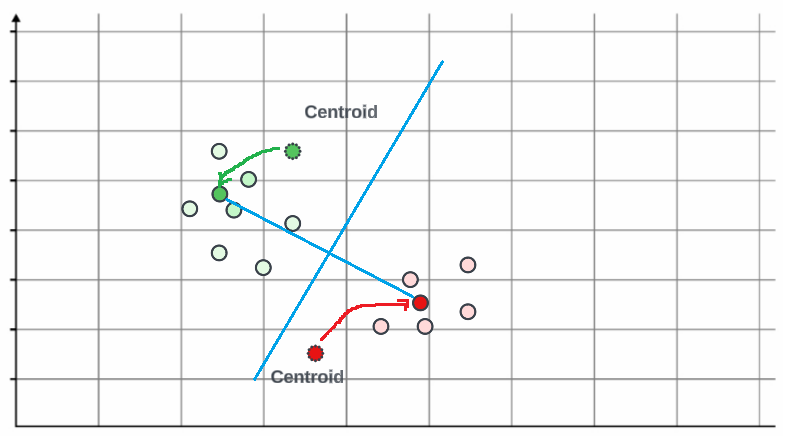
- 在第三步中,我们将计算特定聚类(红色或绿色)中所有点的平均值。这是必要的,因为我们需要更新质心以反映点的新位置。一旦计算出平均值,质心将移动到一个新位置,该位置位于中心的某个地方。我们将再次计算距离和垂直线,您可以看到所有点现在再次靠近质心,并且从垂直线的右侧和左侧进行聚类。
我们如何决定K值?
为了确定K值,我们使用一个叫做[肘部法则](https://www.analyticsvidhya.com/blog/2021/01/in-depth-intuition-of-k-means-clustering-algorithm-in-machine-learning/#:~:text=The elbow method is a technique used in clustering analysis,Q2.)的概念,它帮助我们找到最优化的K值。肘部法则涉及到构建一个图表,将K值和WCSS(簇内平方和)这个概念联系起来,在这个过程中我们从一个质心开始,从1到10进行迭代。对于每次迭代,我们计算每个数据点与质心之间的距离。
在这个例子中,k值为1,距离值将始终大于0。然后,我们可以观察图形并确定WCSS开始水平的K值,表示最佳聚类数。如果k值为2,则会有2个质心。您可以通过将所有距离与质心的总和相加来计算WCSS值。
当你增加k值时,你会发现WCSS值会出现突变,这被称为肘曲线。
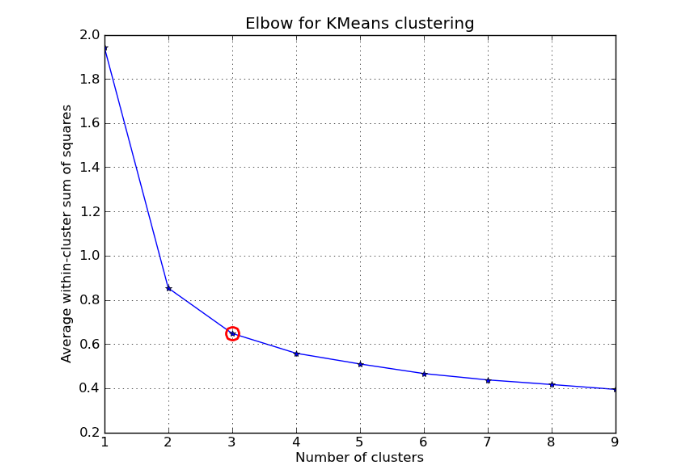
这个曲线被称为“Elbow Curve”,因为它类似于一个肘部,在一个点(红点)处突然变化,然后变成一条直线。它是找到K值的一个重要工具。
为了验证,我们使用Silhouettes Score。K-means聚类涉及更新质心并基于此计算距离。随着K的增加,距离变得正常。我们需要找到可行的K值,即发生突变的K值。一旦找到,我们将其作为我们的K值。总之,如果我们想找到聚类,我们需要取K值并初始化K个质心。我们通过计算平均值和找到距离来更新质心。我们继续这个过程,直到我们得到分离的群组。为了构建Elbow Curve,我们需要检查不同的K值和WCS值,这增加了模型的复杂性。
层次聚类
如果你有数据点P1、P2、P3、P4、P5、P6、P7、P8和P9。层次聚类涉及找到最近的值并将这些点组合成一个聚类。例如,假设P1和P2是最接近的点。我们计算它们之间的距离,并将它们合并成一组。
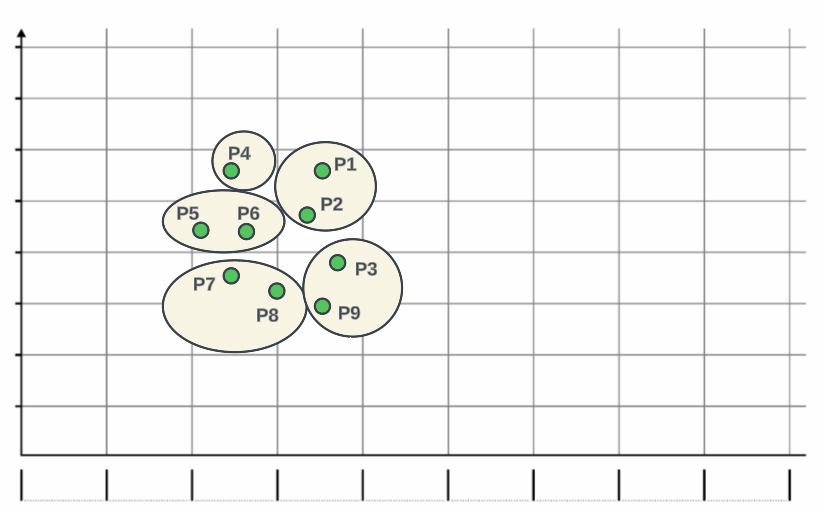
数据点可以组合成群组
接下来,我们找到下一个最近的点,依此类推,直到我们将所有最近的点组合成簇。这是一个逐步的过程,根据它们的接近程度连接点。假设您将所有点分为5个类似这样的组。现在您可以看到P4组靠近P5-P6组。所以我们可以将这两个组合并为一个组。所以我们也可以将最近的组合并为一个组。
代码:
# 定义一个字符串变量corpus,存储语料
corpus = '''
(P4)GROUP + (P5, P6)GROUP
((P4) + (P5, P6))GROUP + (P1, P2)GROUP
(((P4) + (P5, P6)) + (P1, P2))GROUP + (P7 , P8)GROUP
((((P4) + (P5, P6)) + (P1, P2)) + (P7 , P8))GROUP + (P3, P9)GROUP
'''
# 将corpus按行分割成列表
lines = corpus.strip().split('\n')
# 遍历每一行
for line in lines:
# 打印当前行的内容
print(line)
注释:
# 定义一个字符串变量corpus,存储语料
corpus = '''
(P4)GROUP + (P5, P6)GROUP
((P4) + (P5, P6))GROUP + (P1, P2)GROUP
(((P4) + (P5, P6)) + (P1, P2))GROUP + (P7 , P8)GROUP
((((P4) + (P5, P6)) + (P1, P2)) + (P7 , P8))GROUP + (P3, P9)GROUP
'''
# 将corpus按行分割成列表
lines = corpus.strip().split('\n')
# 遍历每一行
for line in lines:
# 打印当前行的内容
print(line)
让我们通过一个例子来更深入地学习层次聚类。为了计算最小距离,您可以使用使用树状图的凝聚层次聚类。
考虑以下一维数据点集合。
# 定义一个列表,包含了一些整数
corpus = [18, 22, 25, 42, 27, 43]
-
应用凝聚层次聚类算法构建层次聚类树状图**。
-
使用最小距离合并聚类,并相应更新相似度矩阵。
-
明确显示算法的每次迭代对应的相似度矩阵。
在第一步中,我们要做的是计算给定数据点之间的距离。首先,我们将数据点写在水平和垂直轴上。你可以说这些是给定给我们的数据点,我们也在这些特定的垂直线上写了同样的东西。此外,现在我们将尝试计算数据点之间的距离;也就是说,18和18之间的距离是0,18和22之间的距离是4。同样,18和25之间的距离是7。18和27之间的距离是9,18和42之间的距离是24,18和43之间的距离是25。
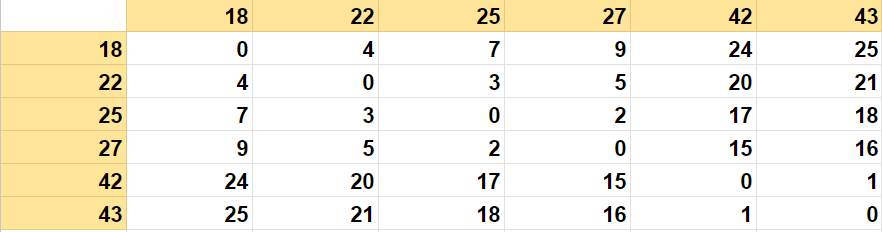
第一次迭代
为了确定两个数据点之间的最小距离,我们分析了一个距离矩阵。发现点42和43之间的距离为1,这是矩阵中最小的距离。我们在第一步中合并了点42和43以形成一个聚类。合并后,我们删除了与点43对应的行和列,并将其与42合并。下面是结果矩阵的显示。
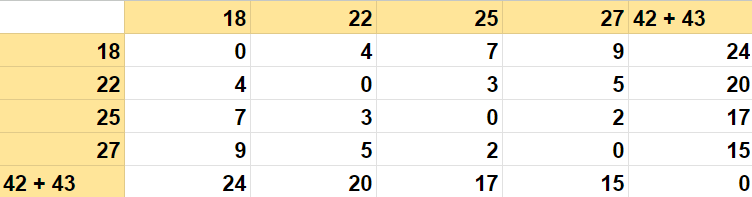
第二次迭代
在第二步中,我们再次尝试找到最小距离。仔细检查矩阵后,发现最小距离在27和25之间。在这种情况下,我们将27与25合并成一个新的聚类。与27对应的行和列将被删除,27合并到第25行和列中。这个过程会得到一个修改后的矩阵,像这样。你可能会问,为什么在合并25和27时是17而不是15?我们在每一步中选择可能的最小值。这样合并不会影响下一步在整个集合中找到最小值的过程。
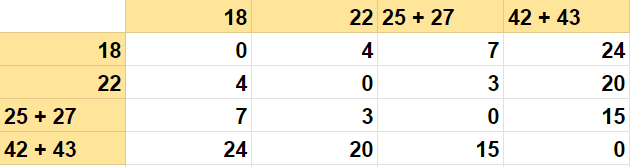
第三次迭代
再次寻找最小距离,我们需要查看矩阵中剩余的数据点。在这种情况下,最小距离在22和25 + 27之间,等于3。因此,我们可以将25和27合并为22。这将导致相应的行和列被删除。合并25,27后,我们将合并22,得到最终矩阵。
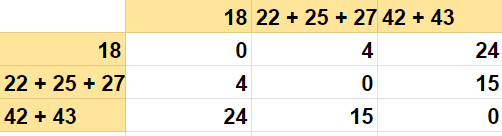
第四次迭代
现在,从这个例子中,如果你看最小距离,4是22 + 25 + 27和18之间的最小距离,所以我们将它合并到18。然后我们移除这一行和列,所以18被合并到22 + 25 + 27。它看起来像这样。

第5次迭代
现在你可以看到这里只有15是距离。这是在合并所有内容后的最终聚类。或者你也可以将18 + 22 + 25 + 27合并成42 + 43,然后我们会得到一个像这样的矩阵。

第六次迭代
在这种情况下,最终输出的树状图如下所示,
# 计算并返回结果
result1 = (42 + 43)
result2 = (25 + 27)
result3 = (22 + (25 + 27))
result4 = (18 + (22 + (25 + 27)))
result5 = (42 + 43) + (18 + (22 + (25 + 27)))
# 打印结果
print(result1)
print(result2)
print(result3)
print(result4)
print(result5)
输出结果:
85
52
74
89
161
同样的事情可以用这样的树状图来展示。
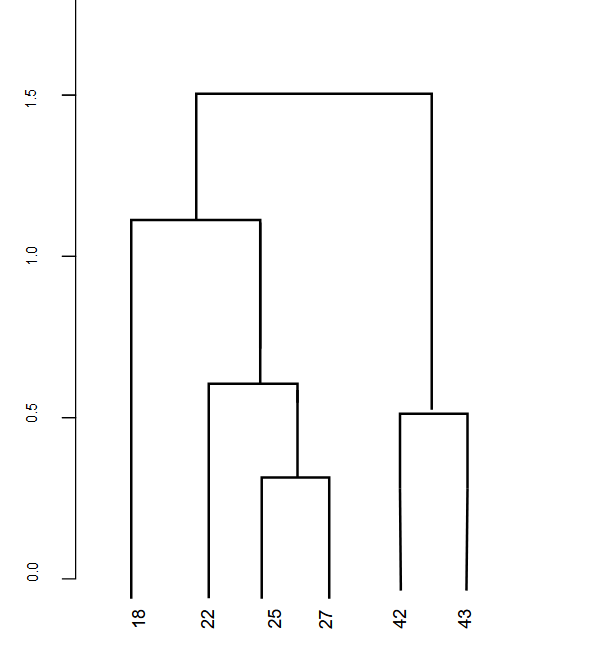
树状图
现在,我们可以设置一个阈值距离并画一条水平线(通常情况下,我们尝试设置阈值,使其切割最高的垂直线)。
树状图中垂直线的距离越大,这些聚类之间的距离就越大。聚类的数量将是使用阈值画出的线与垂直线相交的数量。在上面的例子中,由于红色虚线与2条垂直线相交,我们将有2个聚类。18 + 22 + 25 + 27聚类和42 + 43聚类。
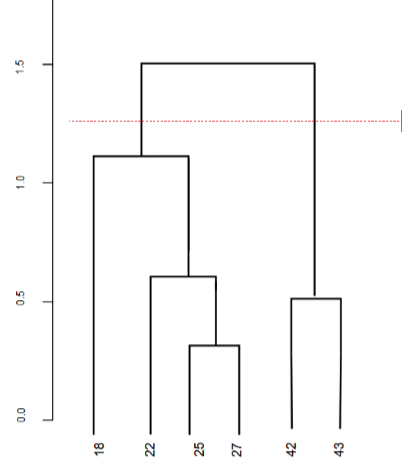
一个带有阈值距离的水平线
k-means聚类和层次聚类哪个需要更多时间?
k-means聚类和层次聚类所需的时间可能会因多种因素而变化,包括数据集的大小、簇的数量、数据的维度以及算法的具体实现。然而,总体而言,与k-means聚类相比,层次聚类往往更具计算复杂性。
k-means聚类的时间复杂度为O(n * k * i * d),其中n是数据点的数量,k是簇的数量,i是迭代次数,d是维度的数量。k-means是一种迭代算法,收敛相对较快,特别是如果数据集表现良好且簇的数量不是过大。
另一方面,层次聚类的时间复杂度为O(n² * log(n))或O(n³),具体取决于所使用的算法。层次聚类通过根据链接准则迭代地合并或分割簇来构建簇的层次结构。在合并或分割过程中需要进行成对距离计算,这可能导致较高的计算成本,特别是对于大型数据集而言。
总之,如果簇的数量相对较小且数据集不是太大,通常情况下k-means聚类比层次聚类更快。然而,对于大型数据集或者在保留层次结构很重要的情况下,尽管计算成本更高,层次聚类可能更合适。
验证聚类模型
验证聚类模型是评估其性能和可靠性的重要步骤。以下是一些常用的验证聚类模型的技术:
-
簇内平方和(WCSS):计算不同k值下的WCSS,并选择WCSS减少不明显的“拐点”处的k值。我们之前学过这个。
-
轮廓系数:计算每个数据点的轮廓系数,并计算所有点的平均值。较高的值表示更好的聚类。
-
间隙统计量:将数据的簇内离散程度与参考空值分布进行比较,并选择最大化间隙统计量的k值。
轮廓系数
轮廓系数是衡量每个数据点与其分配的簇的匹配程度以及与其他簇的分离程度的指标。它通过考虑簇的紧密性和不同簇之间的分离程度来量化聚类的质量。
轮廓系数或轮廓分数是用于计算聚类技术的好坏的度量标准。其值的范围从-1到1。
-
接近1的值表示数据点与其分配的簇非常匹配,并且与相邻簇相对较远。这表明聚类结果较好。
-
接近0的值表示数据点在两个相邻簇之间的决策边界上或非常接近边界上。
-
接近-1的值表示数据点可能被分配到错误的簇,并且与其相邻簇相距较远。
轮廓系数使用以下公式计算单个数据点的值:
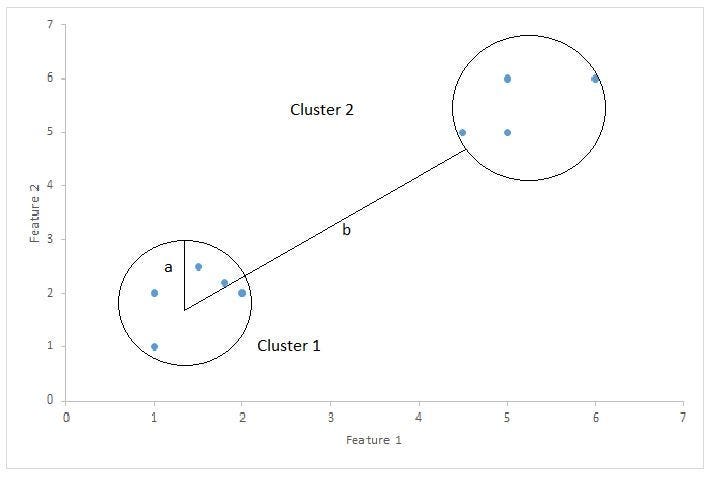
s = (b - a) / max(a, b) # 计算轮廓系数
a - 数据点与同一簇内所有其他点之间的平均距离(簇内距离)。
b - 数据点与最近邻簇内所有点之间的平均距离(簇间距离)。
s - 轮廓系数,用于评估聚类结果的紧密度和分离度。
要获得聚类解决方案的整体轮廓系数,您需要计算所有数据点的平均轮廓系数。
轮廓系数可用于比较不同的聚类解决方案或不同的k值(聚类数)。较高的平均轮廓系数表示更好的聚类性能。需要注意的是,轮廓系数并不适用于所有聚类算法,并且在使用基于距离的测量方法(如k-means聚类)时效果最佳。
在使用轮廓系数时,建议将其与其他验证方法结合使用,以全面了解聚类结果。
K-Means和层次聚类的区别
K-Means和层次聚类之间的主要区别可以分为以下几个方面:
方法:
-
K-means聚类:K-means是一种迭代分区算法。它通过随机初始化k个质心,迭代地将数据点分配给最近的质心,根据分配的点更新质心,并重复该过程直到收敛。
-
层次聚类:层次聚类通过迭代地合并或分割聚类来构建聚类的层次结构。它可以以两种方式执行:凝聚聚类(自下而上)从每个数据点作为单独的聚类开始,根据它们的相似性迭代地合并它们,而分裂聚类(自上而下)从所有数据点开始作为一个聚类,然后递归地将它们分割。
聚类数:
-
K-means聚类:K-means需要预先指定聚类数(k)。该算法旨在将数据分成k个聚类。
-
层次聚类:层次聚类不需要预先指定聚类数。它创建一个聚类的层次结构,允许探索不同粒度的聚类。
聚类形状:
-
K-means聚类:K-means假设聚类是球形且大小相似的。它试图最小化聚类内平方和,适用于具有分离良好的球形聚类的数据集。
-
层次聚类:层次聚类可以处理任意形状的聚类。它不限于假设特定的聚类形状,可以更灵活地捕捉复杂的聚类结构。
可解释性:
-
K-means聚类:K-means产生硬分配,意味着每个数据点只分配给一个聚类。由此产生的聚类易于解释和分析。
-
层次聚类:层次聚类创建一个由树状图表示的聚类层次结构。它提供了聚类关系的可视化表示,并允许在不同粒度上进行探索。
可扩展性:
-
K-means聚类:K-means计算效率高,可以处理具有合理聚类数的大型数据集。适用于效率至关重要的应用程序。
-
层次聚类:层次聚类可能计算成本高,特别是对于大型数据集。随着数据点数量的增加,时间和内存需求也会增加。
对初始化的敏感性:
-
K-means聚类:K-means对质心的初始放置非常敏感。不同的初始化可能导致不同的聚类结果,并且算法可能收敛到次优解。
-
层次聚类:层次聚类对初始化不太敏感,因为它不依赖于随机初始化。聚类结果由基于聚类之间的相似性的合并或分割决策确定。
K-Means聚类的优缺点
优点:
-
简单性:K-means聚类相对容易理解和实现。它是一种简单的算法,根据数据点与质心的距离迭代地将数据点分配给聚类。
-
可扩展性:K-means聚类计算效率高,可以处理具有合理聚类数的大型数据集。它适用于效率至关重要的应用程序。
-
可解释性:K-means聚类的结果可以很容易地解释,因为每个数据点都分配给一个单独的聚类。这使其在探索性数据分析和模式识别中非常有用。
-
多功能性:K-means聚类可以很好地处理各种类型的数据和距离度量。它不限于特定的数据类型或对数据分布的假设。
缺点:
-
对初始化的敏感性:K-means聚类对质心的初始放置非常敏感。不同的初始化可能导致不同的聚类结果,并且算法可能收敛到次优解。
-
固定聚类数:K-means聚类需要预先指定聚类数(k)。确定最佳聚类数可能具有挑战性,并可能需要反复尝试或使用其他验证技术。
-
对异常值的敏感性:K-means聚类将所有数据点视为同等重要,并对异常值敏感。异常值可能会显著影响聚类质心和聚类结果。
-
聚类形状灵活性有限:K-means聚类假设聚类是球形且大小相似的。它可能在处理复杂的聚类形状或具有不同密度的聚类时遇到困难。
-
对噪声的鲁棒性不足:K-means聚类无法很好地处理噪声或异常值。它倾向于将噪声数据点分配给最近的聚类,可能影响整体聚类结构和可解释性。
K-Means聚类的局限性之一是它假设聚类是球形且大小相等的。这种假设可能不适用于所有数据集,导致不准确的结果。此外,K-Means聚类不适用于具有分类变量的数据集,因为它是一种基于距离的算法,需要数值数据。
另一方面,K-Means聚类在客户细分、市场研究和图像分割中可以用于识别模式。它还可以用于异常检测,可以识别不属于任何聚类的数据点。
层次聚类的优缺点
优点:
-
层次结构:层次聚类通过创建称为树状图的树状结构来捕捉数据的层次结构。这可以提供有关数据内部关系和子群的洞察。
-
不需要指定聚类数:层次聚类不需要预先指定聚类数。树状图允许您在不同粒度上探索,可以根据数据和分析目标确定聚类数。
-
聚类形状的灵活性:层次聚类可以处理任意形状的聚类。它不限于假设球形聚类,可以更灵活地捕捉复杂的聚类结构。
-
凝聚和分裂方法:层次聚类提供凝聚和分裂两种方法。凝聚聚类从单个数据点作为聚类开始,并迭代地合并它们,而分裂聚类从所有数据点开始作为一个聚类,然后递归地将它们分割。这提供了聚类过程的灵活性。
-
可视化表示:层次聚类生成的树状图可以具有视觉吸引力和信息量。它允许对聚类结构进行可视化探索,并有助于理解聚类之间的关系。
缺点:
-
计算复杂性:层次聚类可能计算成本高,特别是对于大型数据集。时间复杂度通常比K-means聚类等算法高。
-
内存需求:层次聚类可能需要大量内存来存储距离矩阵或链接信息,特别是对于大型数据集。这可能限制其适用于不适合内存的数据集。
-
缺乏可扩展性:层次聚类不像其他一些聚类算法那样具有可扩展性。随着数据点数量的增加,计算成本和内存需求也会显著增加。
-
确定聚类数的困难:虽然层次聚类不需要预先指定聚类数,但从树状图中确定适当的聚类数可能是主观和具有挑战性的。通常需要进行视觉检查或使用切割树状图或使用聚类指数等其他技术。
-
对噪声的敏感性:层次聚类对噪声和异常值敏感。异常值可能会影响合并或分割决策,导致次优的聚类结果。
层次聚类的另一个优点是它可以有效地处理缺失数据点。它还可以用于识别数据集中的异常值,这在异常检测中非常有用。
然而,层次聚类的一个主要局限性是它不适用于大型数据集。当处理大量数据点时,该算法可能计算成本高且耗时。此外,层次聚类的结果可能高度依赖于用于衡量数据点之间相似性的距离度量的选择。
何时使用K-Means聚类算法?
-
分离良好的聚类:当数据集中的聚类分离良好且具有明显的边界时,K-means聚类表现良好。该算法旨在最小化聚类内的平方和,因此对于识别紧凑且球形的聚类非常有效。
-
大型数据集:K-means聚类计算效率高,可以处理具有合理聚类数的大型数据集。它的可扩展性好,适用于效率至关重要的应用程序。
-
预定义的聚类数:K-means需要预先指定聚类数(k)。如果您对聚类数有先验知识或特定要求,K-means可以是一个合适的选择。
-
数值数据:K-means聚类对数值数据效果好,因为它依赖于计算数据点之间的距离。它适用于连续变量或可以用数值表示的属性。
-
快速原型和探索:由于其简单性和易于实现,K-means聚类对于快速原型和探索性数据分析非常有用。它可以提供对数据结构的初步洞察,并有助于形成假设或进行初步观察。
-
初始聚类中心:如果您对初始聚类中心有一些先验知识或合理的估计,K-means可以更快地收敛并产生更准确的结果。这在您对数据或领域具有一定了解的情况下非常有益。
何时使用层次聚类算法?
-
探索聚类结构:层次聚类通过树状图提供聚类的层次结构。当您希望在不同粒度上探索数据内部关系和子群时,这非常有用。
-
未知聚类数:层次聚类不需要预先指定聚类数。它允许您在树状图的不同级别上进行探索,并根据数据和分析目标确定聚类数。
-
任意聚类形状:层次聚类可以处理任意形状的聚类。它不限于假设特定的聚类形状,允许更灵活地捕捉复杂的聚类结构。
-
可视化表示:层次聚类生成的树状图可以具有视觉吸引力和信息量。它提供了聚类结构的可视化表示,使其更易于解释和分析聚类之间的关系。
-
基于相似性的分析:层次聚类基于数据点之间的相似性或距离的概念。如果您的数据最适合使用距离或相似性度量进行分析,层次聚类可能是一个合适的选择。
-
小到中等大小的数据集:虽然层次聚类对于大型数据集可能计算成本高,但它非常适合小到中等大小的数据集。它可以处理适合内存的数据集,并且不需要过多的计算资源。
聚类算法是机器学习中用于对相似数据对象进行分组的有价值的工具。选择最合适的聚类算法取决于各种因素,如数据集大小和维度、所需的聚类数和可用的计算资源。两种常用的算法是K-Means和层次聚类,每种算法都有其优点和缺点。通过考虑这些算法的优缺点、实际应用和影响因素,您可以自信地选择适合您特定任务的最佳聚类算法。
这就是关于K-Means和层次聚类的全部内容。希望您对聚类算法有了一个良好的了解。


















 3373
3373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











