







在人工智能浪潮的巅峰,一款名为 SQLCoder-7b 的模型惊人地发布在 Hugging Face 上,与 GPT-4 在文本到 SQL 生成方面展开竞争,并在数据处理速度和准确性方面取得了显著突破,甚至显示出超越 GPT-4 的潜力。
然而,这引发了人们对这个模型如何实现这样的飞跃以及它的秘密武器可能是什么的好奇。
模型特点
你有没有在尝试理解 SQL 数据库中的数据时感到困惑?通过 SQLCoder-7B-2 和 SQLCoder-70B-Alpha 模型,这些问题得到了有效解决。
面向非技术用户设计,这些强大的工具允许轻松分析数据库内容,无需深入专业知识。
令人振奋的是,SQLCoder-70B-Alpha 在文本到 SQL 转换能力方面超越了所有通用模型,包括 GPT-4,这意味着它可以更准确地理解您的需求并生成相应的 SQL 查询。
SQLCoder-7B-2 也表现出色,在自然语言到 SQL 生成方面表现卓越。
然而,这些模型旨在实现只读访问,以确保数据安全,并未经过训练以处理恶意写入请求。
开源精神在推动技术进步中发挥着关键作用。
SQLCoder2 和 SQLCoder-7B 现在向公众开放,扩大了对它们功能的访问。
SQLCoder2 在原始 SQLCoder 的基础上有了显著改进,而 SQLCoder-7B 则以 70 亿参数的规模首次亮相,表现与其前身相当。
所有这一切背后是开发团队对用户反馈的深刻理解和持续改进。
他们解决了原始 SQLCoder 在日期时间函数方面的困难,以及偶尔生成不正确的列或表名的问题。此外,社区对能够在较小 GPU 上运行的模型有着重大需求。
因此,SQLCoder2 和 SQLCoder-7B 的开发不仅解决了这些问题,而且更适合生产环境。
SQLCoder 如何评估具有高准确性的 AI 模型?
评估和性能
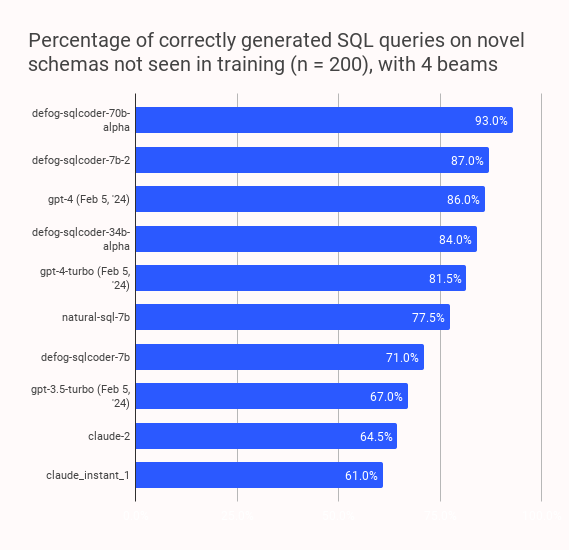
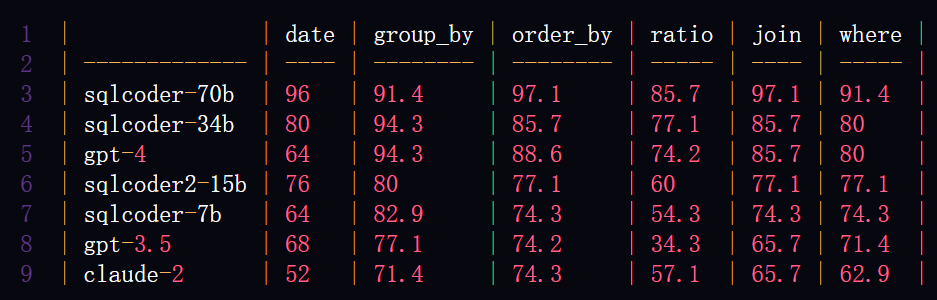
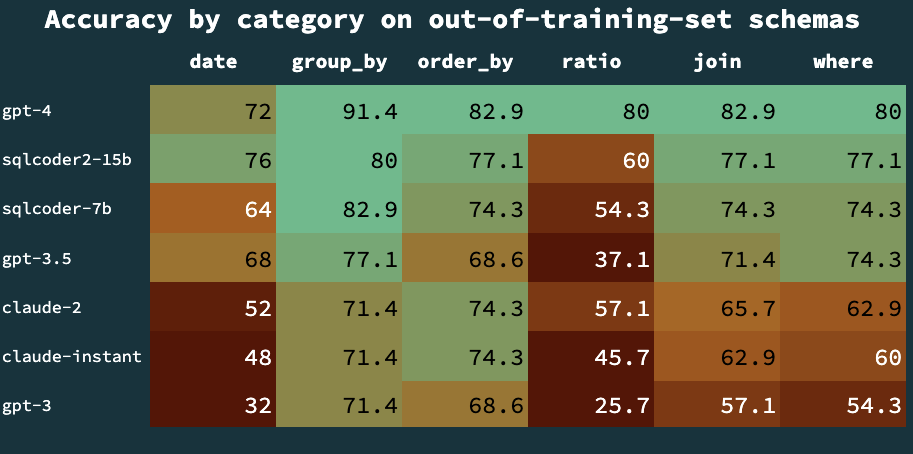
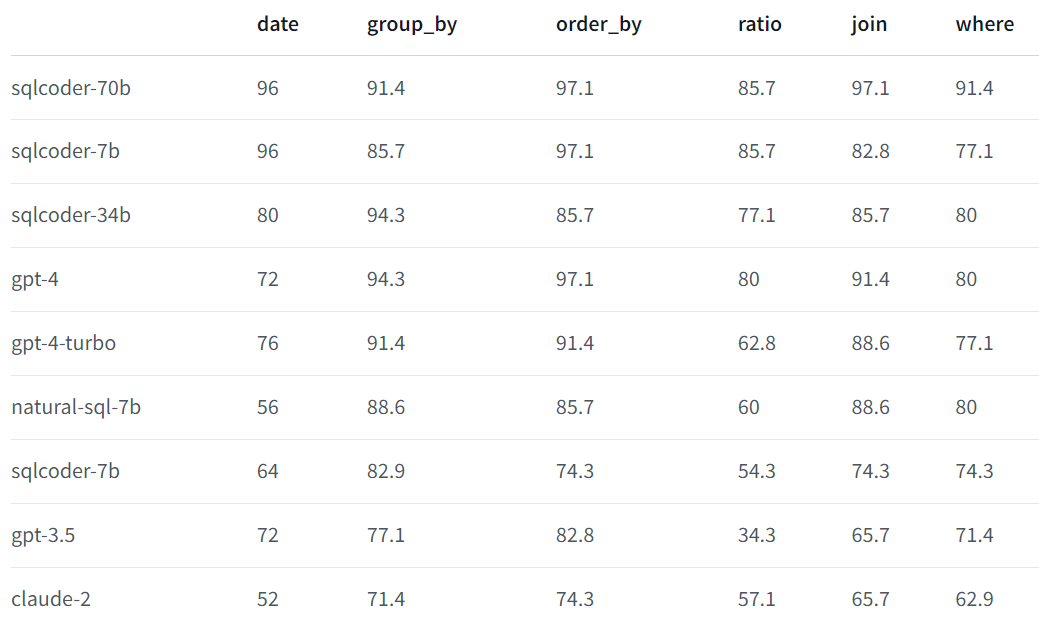
SQLCoder 将每个生成的问题分类为六个主要类别。以下表格将展示每个模型在回答这些类别问题时的准确率。
在数据的海洋中,SQL 是捕鱼的网。LLM 生成的 SQL 语句有多可靠?SQL-Eval 就在这里评判!
正如其名称所示,SQL-Eval 的使命是评估 LLM 生成的 SQL 语句的正确性。
在开发过程中,开发人员经常面临一个困境:
如何确定一个 SQL 查询是否“正确”?毕竟,对于同一个问题可能有多种正确的编写 SQL 的方式。
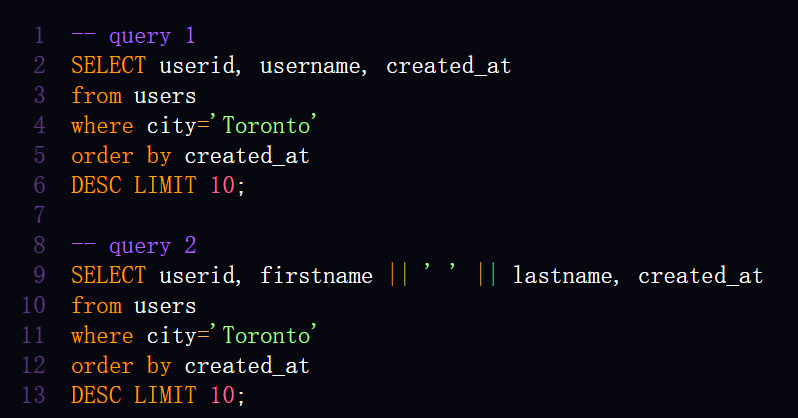
例如,如果您想找到来自多伦多的最后 10 位用户,以下两个查询都是正确的:
- 查询 A 检索用户的 ID、用户名和创建时间;
- 查询 B 选择用户的 ID、全名和创建时间。
如何快速开始使用 SQLCoder-7b
提示格式
### 任务
生成一个 SQL 查询来回答 [问题]{user_question}[/问题]
### 数据库架构
该查询将在具有以下架构的数据库上运行:
{table_metadata_string_DDL_statements}
### 答案
鉴于数据库架构,这是 SQL 查询,用于 [问题]{user_question}[/问题]
[SQL]
使用环境
示例:https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7
演示:https://defog.ai/sqlcoder-demo/
模型:https://huggingface.co/defog/sqlcoder-7b-2
Github:https://github.com/defog-ai/sqlcoder/
结论
SQLCoder-7b 的崛起不仅代表了技术的飞跃,也是朝着数据洞察民主化的重要一步。


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











