







PSM - SQL:用于文本到 SQL 的多粒度语义渐进式模式学习
论文地址:https://arxiv.org/abs/2502.05237
摘要
在文本转SQL(Text-to-SQL)任务中,由于存在大量冗余的数据库模式,干扰了语义学习,且自然语言(NL)和结构化查询语言(SQL)之间存在领域差异,因此将自然语言问题转换为可执行的SQL查询具有挑战性。在本文中,我们提出了一种具有多粒度语义的渐进式模式链接(PSM - SQL)框架,以减少文本转SQL中的冗余数据库模式。PSM - SQL使用多粒度模式链接(MSL)模块,在列、表和数据库级别学习模式语义。更具体地说,在列级别使用三元组损失来学习嵌入表示,而在数据库级别通过微调大语言模型(LLM)进行模式推理。MSL在表级别采用分类器和相似度得分来建模模式链接的交互。特别地,PSM - SQL采用链式循环策略,通过不断减少模式数量来降低模式链接的任务难度,同时牺牲了算法精度的上限。在文本转SQL数据集上进行的实验表明,所提出的PSM - SQL具有优越的性能。
1 引言
文本到SQL转换(秦等人,2022年;邓等人,2022年;高等人,2024年;普尔雷扎和拉菲伊,2024年)近年来受到了越来越多的关注,其目标是将自然语言(NL)问题转换为可执行的结构化查询语言(SQL)查询,从而使用户更轻松地访问关系数据库中的数据。然而,数据库模式(如表格、列、值等)日益复杂,以及自然语言和SQL之间的领域差距,使得生成可执行且准确的SQL查询变得困难。通过利用大语言模型(LLM)强大的理解和生成能力,包括模式链接和SQL生成任务的文本到SQL转换在解决这些问题方面取得了显著进展。
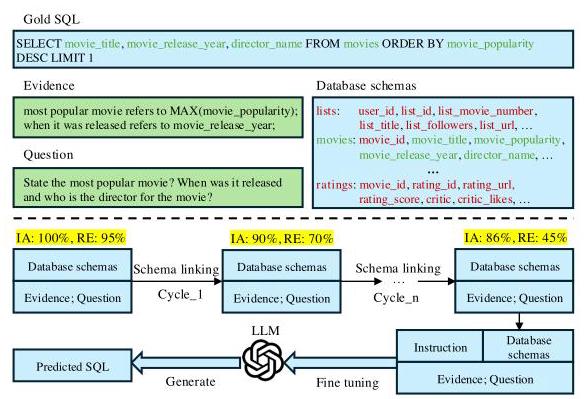
图1:PSM - SQL解决的文本到SQL转换示例说明。IA和RE分别表示包含准确率和冗余率。
基于大语言模型(LLMs)的文本到SQL(Text-to-SQL)工作可分为两类:基于提示的方法和基于微调的方法。它们通常利用特定领域的知识来构建提示或微调大语言模型,使大语言模型能够学习推理和生成SQL查询的模式。例如,C3(董等人,2023年)、DIN - SQL(波雷扎和拉菲埃,2023年)、MAC - SQL(王等人,2024年)通过思维链(CoT)(魏等人,2022年)将文本到SQL任务分解为多个子问题。DAIL - SQL(高等人,2024年)、DTS - SQL(波雷扎和拉菲埃,2024年)、CODES(李等人,2024年)采用有监督的微调策略对开源大语言模型进行微调以实现文本到SQL转换。然而,这些方法专注于激活和增强大语言模型在文本到SQL任务中的理解和生成能力,尤其是SQL生成能力,却忽略了对任务本身的优化,如模式链接。如图1所示,我们提出的PSM - SQL注重对任务本身进行优化,以持续降低文本到SQL的难度。一方面,PSM - SQL在表、列和数据库层面学习模式的语义,以链接相关模式进行生成。另一方面,PSM - SQL迭代执行作为链式任务的模式链接,目标是在允许高度冗余的同时保持较高的查找准确率,从而持续降低文本到SQL的难度。
在本文中,我们通过减少冗余的数据库模式提出了用于文本到SQL(Text-to-SQL)的PSM - SQL(渐进式模式链接与多粒度语义框架)。更具体地说,PSM - SQL利用多语义学习(MSL)模块在多粒度级别上捕捉模式的语义。在列级别,PSM - SQL使用三元组损失来微调嵌入模型,该模型奖励正确的模式,同时惩罚错误的模式。在数据库级别,PSM - SQL微调大语言模型(LLM)以推理与SQL生成相关的数据库模式。在表级别,PSM - SQL设计分类器和相似度得分,以在嵌入空间中对模式交互进行建模,用于模式链接。特别是,应用了一种链式循环策略,通过减少冗余模式来持续降低任务难度。
这项工作的贡献总结如下:
-
我们为文本到SQL提出了一种具有多粒度语义的渐进式模式链接(PSM - SQL)框架,该框架有效地减少了冗余的数据库模式,以增强模式的语义学习,并消除自然语言(NL)和SQL之间的领域差异。
-
我们设计了一个多语义学习(MSL)模块,以在表、列和数据库级别学习模式的多语义,并采用链式循环策略来持续降低模式链接的难度。
-
我们在包括Spider和Bird(鸟)在内的文本到SQL(Text-to-SQL)数据集上进行了广泛的实验,证明了PSM - SQL相对于最先进的文本到SQL方法的有效性。
本文的其余部分组织如下。第2节回顾相关工作。第3节介绍所提出的PSM - SQL的详细信息。第4节进行实验,第5节给出结论。
2 相关工作
文本到SQL(Text-to-SQL)旨在将自然语言(NL)问题转换为可执行的结构化查询语言(SQL)查询。早期,文本到SQL采用编码器 - 解码器架构对问题和数据库模式表示进行编码,并解码出SQL查询。例如,RESDSQL(李等人,2023a)提出了一种排名增强编码器来选择相关模式,以及一种骨架感知解码器,通过骨架隐式引导SQL解析。SADGA(蔡等人,2021)和LGESQL(曹等人,2021)引入图神经网络来学习问题和数据库模式之间的关系。Graphix - T5(李等人,2023b)设计了专门的图感知层来编码语义和结构信息的混合信息,在保留预训练T5的上下文编码能力的同时,提升了T5的结构编码能力。然而,由于模型中参数数量较少导致生成能力有限,它们在生成SQL查询方面并非最优。
最近,研究人员引入大语言模型(LLMs)来理解数据库模式并为文本到SQL(Text-to-SQL)生成SQL查询,这些方法大致可分为两类:基于提示的方法和基于微调的方法。更具体地说,基于提示的方法通过上下文学习设计特定提示,以增强大语言模型在文本到SQL领域的推理能力。DAIL - SQL(高等人,2024年)根据示例的骨架相似度选择示例,并从示例中去除跨领域知识以提高标记效率。DIN - SQL(波雷扎和拉菲伊,2023年)将生成问题分解为子问题,并将这些子问题的解决方案作为提示输入到大语言模型中以生成SQL查询。MAC - SQL(王等人,2024年)采用核心分解器代理进行文本到SQL生成,并进行少样本思维链推理,同时采用两个辅助代理通过利用外部工具来修正错误的SQL查询。TA - SQL(曲等人,2024年)提出任务对齐(TA)策略,以减轻文本到SQL每个阶段的幻觉问题,减轻SQL生成的负担。基于微调的方法使用具有特定领域知识的数据来微调大语言模型,促使大语言模型学习文本到SQL的知识。DTS - SQL(波雷扎和拉菲伊,2024年)引入了两阶段微调方法,将文本到SQL任务分解为两个更简单的任务以保护数据隐私,使小型开源模型能够与大型模型相媲美。CODES(李等人,2024年)提出了一种全面的数据库提示构建策略和一种双向数据增强方法,使用他们收集的以SQL为重点的语料库对一系列参数从 1 B 1\mathrm{\;B} 1B 到 15 B {15}\mathrm{\;B} 15B 的语言模型进行微调。然而,它们通常侧重于优化SQL生成,而忽略了模式链接的优化。
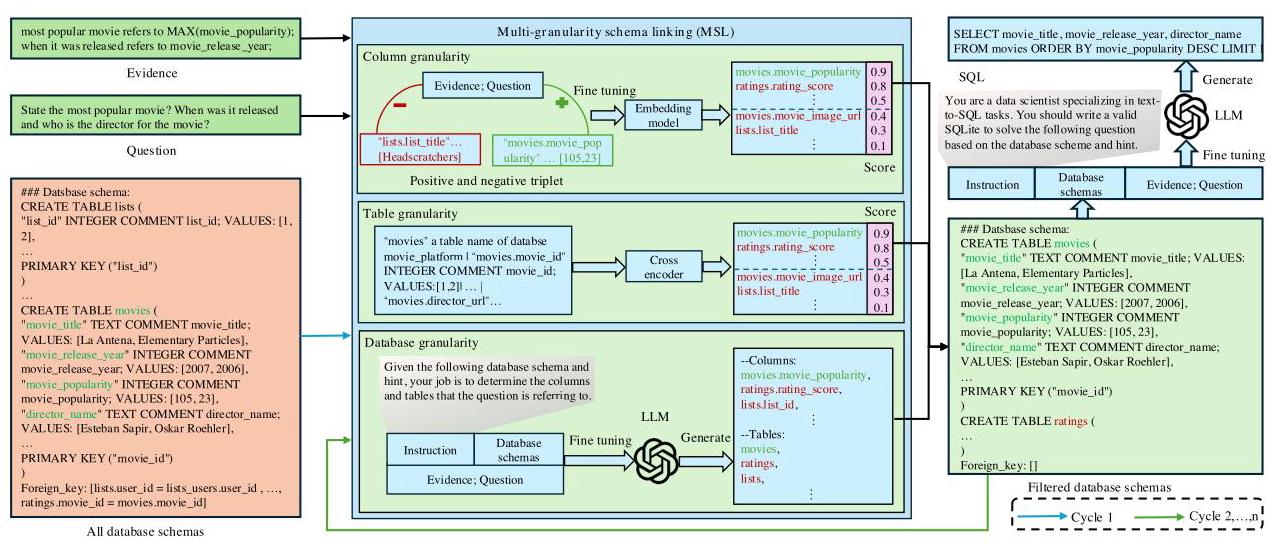
图2:PSM - SQL(PSM-SQL)的框架。
3 问题定义
在本节中,我们对文本到SQL(Text-to-SQL)的符号进行形式化定义,其目标是将自然语言(NL)问题转换为SQL查询。不失一般性,文本到SQL可以分为两个子任务:模式链接和SQL生成。
给定问题 Q = { q i } i = 1 n Q = {\left\{ {q}_{i}\right\} }_{i = 1}^{n} Q={qi}i=1n 、作为外部知识的证据 K = { k i } i = 1 n K = {\left\{ {k}_{i}\right\} }_{i = 1}^{n} K={ki}i=1n 以及关系数据库 D = { { t j , c j 1 , … , c j ∣ C j ∣ } j = 1 ∣ T ∣ } i = 1 n D = {\left\{ {\left\{ {t}_{j},{c}_{j}^{1},\ldots ,{c}_{j}^{\left| {C}_{j}\right| }\right\} }_{j = 1}^{\left| T\right| }\right\} }_{i = 1}^{n} D={{tj,cj1,…,cj∣Cj∣}j=1∣T∣}i=1n ,文本到SQL进行模式链接,以从原始数据库中预测用于SQL生成的相关模式,如下所示。 D f = Filter ( Q , K , D ) (1) {D}_{f} = \operatorname{Filter}\left( {Q, K, D}\right) \tag{1} Df=Filter(Q,K,D)(1) 其中 Filter ( ⋅ ) \operatorname{Filter}\left( \cdot \right) Filter(⋅) 表示模式链接(schema linking)函数, D f {D}_{f} Df 表示由预测模式组成的过滤后数据库, n n n 表示文本到 SQL(Text-to-SQL)样本的数量, ∣ T ∣ \left| T\right| ∣T∣ 表示关系数据库中表的数量, ∣ C j ∣ \left| {C}_{j}\right| ∣Cj∣ 是第 j j j 个表中的列数, t j {t}_{j} tj 和 c j {c}_{j} cj 分别是第 j j j 个表中的表名和列信息。
此外,文本到 SQL(Text-to-SQL)生成如下 SQL 查询 S \mathrm{S} S 来回答问题: S = Parse ( Q , K , D f ) (2) S = \operatorname{Parse}\left( {Q, K,{D}_{f}}\right) \tag{2} S=Parse(Q,K,Df)(2) 其中 Parse ( ⋅ ) \operatorname{Parse}\left( \cdot \right) Parse(⋅) 表示 SQL 生成(SQL generation)函数。
4 方法
4.1 框架概述
针对带有证据和数据库模式的问题,我们提出了一种基于多粒度语义网络的渐进式模式链接方法(记为PSM - SQL),如图2所示。该方法由链式循环策略和多粒度模式链接(MSL)模块组成。PSM - SQL采用链式循环策略持续减少冗余模式的数量,并采用MSL在列、表和数据库级别学习模式语义。具体而言,在列级别使用三元组损失来学习嵌入表示,而在数据库级别使用微调后的大语言模型(LLM)来推理相关模式。在表级别,MSL采用分类器和相似度损失来对表级别的模式交互进行建模。
4.2 模式链接
给定问题 q ∈ Q q \in Q q∈Q 、作为外部知识的证据 k ∈ K k \in K k∈K 以及关系数据库 d = d = d= { t j , c j 1 , … , c j ( ∣ C j ∣ ) } j = 1 ( ∣ T ∣ ) ∈ D {\left\{ {t}_{j},{c}_{j}^{1},\ldots ,{c}_{j}^{\left( \left| {C}_{j}\right| \right) }\right\} }_{j = 1}^{\left( \left| T\right| \right) } \in D {tj,cj1,…,cj(∣Cj∣)}j=1(∣T∣)∈D ,多粒度模式链接(MSL)模块在列、表和数据库级别学习模式的语义以进行模式链接,捕捉模式的多粒度模式。
列级别。在列级别,我们构建三元组 ( a , c j p , c j n ) \left( {a,{c}_{j}^{p},{c}_{j}^{n}}\right) (a,cjp,cjn) ,其中 a = Cat ( k , q ) a = \operatorname{Cat}\left( {k, q}\right) a=Cat(k,q) 用于微调预训练的嵌入模型(例如,BGE-large-en(肖等人,2024 年)等),对模式的得分进行排序,以获得过滤后的数据库 d f c {d}_{f}^{c} dfc ,该数据库由得分超过 0.5 的模式组成,如下所示 d f c = B G E ( a , c j p , c j n ) (3) {d}_{f}^{c} = {BGE}\left( {a,{c}_{j}^{p},{c}_{j}^{n}}\right) \tag{3} dfc=BGE(a,cjp,cjn)(3) 其中 B G E ( ⋅ ) {BGE}\left( \cdot \right) BGE(⋅) 和 Cat ( ⋅ ) \operatorname{Cat}\left( \cdot \right) Cat(⋅) 分别表示BGE操作(BGE operation)和拼接操作(concatenation operation), a a a 是锚点(anchor), c j p ∈ d g t {c}_{j}^{p} \in {d}_{gt} cjp∈dgt 和 c j n ∉ d g t {c}_{j}^{n} \notin {d}_{gt} cjn∈/dgt 表示来自第 j j j 个表的与生成SQL查询相关和不相关的模式(schemas), d g t ∈ D g t = { { t j , c j 1 , … , c j ∣ C j ∣ } j = 1 ∣ T ∣ } i = 1 n {d}_{gt} \in {D}_{gt} = {\left\{ {\left\{ {t}_{j},{c}_{j}^{1},\ldots ,{c}_{j}^{\left| {C}_{j}\right| }\right\} }_{j = 1}^{\left| T\right| }\right\} }_{i = 1}^{n} dgt∈Dgt={{tj,cj1,…,cj∣Cj∣}j=1∣T∣}i=1n 表示与SQL生成相关的真实数据库模式(ground - truth database schemas)。
列级别的损失函数(loss function)可表示如下: L c = max ( φ ( a , c j p ) − φ ( a , c j n ) + β , 0 ) (4) {\mathcal{L}}_{c} = \max \left( {\varphi \left( {a,{c}_{j}^{p}}\right) - \varphi \left( {a,{c}_{j}^{n}}\right) + \beta ,0}\right) \tag{4} Lc=max(φ(a,cjp)−φ(a,cjn)+β,0)(4) 其中 φ ( ⋅ ) \varphi \left( \cdot \right) φ(⋅) 是距离函数(例如,余弦距离等), β \beta β 是正样本对和负样本对之间的恒定松弛边界。
表级别。如图 3 所示,实现了一个交叉编码器来对嵌入空间和分类器空间中模式的交互进行建模。给定带有证据 a = Cat ( k , q ) a = \operatorname{Cat}\left( {k, q}\right) a=Cat(k,q) 的问题以及表模式 { t j , c j 1 , … , c j ( ∣ C j ∣ ) } ∈ d \left\{ {{t}_{j},{c}_{j}^{1},\ldots ,{c}_{j}^{\left( \left| {C}_{j}\right| \right) }}\right\} \in d {tj,cj1,…,cj(∣Cj∣)}∈d ,我们采用预训练的 ROBERTA 模型(刘等人,2019 年)来获取序列嵌入,然后分别通过长短期记忆(LSTM)网络获得问题、表和列的融合嵌入,如下所示, e q , e t , { e c k } k = 1 ∣ C j ∣ = E M B ( a , t j , c j 1 , … , c j ( ∣ C j ∣ ) ) {e}_{q},{e}_{t},{\left\{ {e}_{c}^{k}\right\} }_{k = 1}^{\left| {C}_{j}\right| } = {EMB}\left( {a,{t}_{j},{c}_{j}^{1},\ldots ,{c}_{j}^{\left( \left| {C}_{j}\right| \right) }}\right) eq,et,{eck}k=1∣Cj∣=EMB(a,tj,cj1,…,cj(∣Cj∣)) (5)
其中 E M B ( ⋅ ) = L S T M ( R O B E R T A ( ⋅ ) ) {EMB}\left( \cdot \right) = {LSTM}\left( {{ROBERTA}\left( \cdot \right) }\right) EMB(⋅)=LSTM(ROBERTA(⋅)) 是对特征嵌入进行编码的函数, R O B E R T A ( ⋅ ) {ROBERTA}\left( \cdot \right) ROBERTA(⋅) 和 L S T M ( ⋅ ) {LSTM}\left( \cdot \right) LSTM(⋅) 分别是 ROBERTa(一种预训练语言模型)和 LSTM(长短期记忆网络)操作, e q {e}_{q} eq 和 e t {e}_{t} et 分别表示问题嵌入和表格嵌入, { e c k } k = 1 ∣ C j ∣ {\left\{ {e}_{c}^{k}\right\} }_{k = 1}^{\left| {C}_{j}\right| } {eck}k=1∣Cj∣ 表示列嵌入。
具体来说,我们采用了一个解耦网络(DN),它是一个带有丢弃操作的全连接层,用于从冗余标记(例如“the”、“was”等)中过滤问题嵌入的无关语义,如下所示: [ e q n ; e q s ] = ReLU ( D N ( e q ) ) (6) \left\lbrack {{e}_{q}^{n};{e}_{q}^{s}}\right\rbrack = \operatorname{ReLU}\left( {\mathrm{{DN}}\left( {e}_{q}\right) }\right) \tag{6} [eqn;eqs]=ReLU(DN(eq))(6) 其中 ReLU ( ⋅ ) \operatorname{ReLU}\left( \cdot \right) ReLU(⋅) 是 ReLU 激活函数, e q n {e}_{q}^{n} eqn 和 e q s {e}_{q}^{s} eqs 分别表示与 SQL 生成在语义上不相关和相关的问题嵌入。
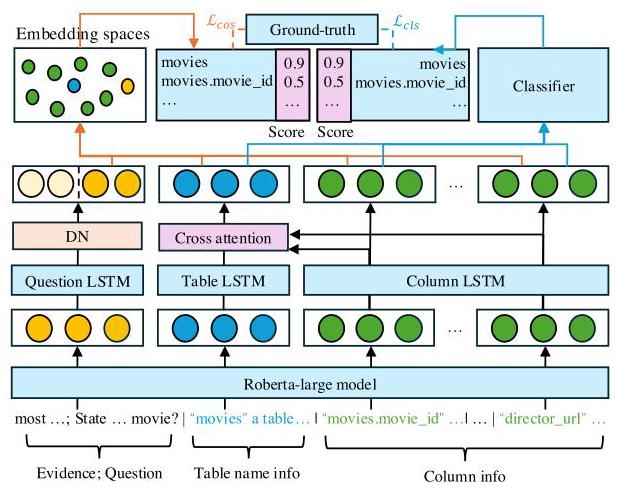
图 3:多粒度模式链接(MSL,Multi-granularity schema linking)模块的详细信息。
为了获得列增强的表嵌入 e t c {e}_{t}^{c} etc ,采用多头缩放点积注意力层和特征融合层将列的语义融合到表嵌入中,具体如下: e t a = MultiHeadAttn ( e t , { e c k } k = 1 ∣ C j ∣ , { e c k } k = 1 ∣ C j ∣ , h ) {e}_{t}^{a} = \operatorname{MultiHeadAttn}\left( {{e}_{t},{\left\{ {e}_{c}^{k}\right\} }_{k = 1}^{\left| {C}_{j}\right| },{\left\{ {e}_{c}^{k}\right\} }_{k = 1}^{\left| {C}_{j}\right| }, h}\right) eta=MultiHeadAttn(et,{eck}k=1∣Cj∣,{eck}k=1∣Cj∣,h) (7) e t c = Norm ( e t , e t a ) (8) {e}_{t}^{c} = \operatorname{Norm}\left( {{e}_{t},{e}_{t}^{a}}\right) \tag{8} etc=Norm(et,eta)(8) 其中 MultiHeadAttn ( ⋅ ) \left( \cdot \right) (⋅) 表示多头注意力函数, h \mathrm{h} h 是头的数量, Norm ( ⋅ ) \operatorname{Norm}\left( \cdot \right) Norm(⋅) 是按行进行的 L_2 归一化函数。
此外,我们使用距离函数 φ ( ⋅ ) \varphi \left( \cdot \right) φ(⋅) (例如,余弦距离等)和分类器 C l a s s i f i e r ( ⋅ ) {Classifier}\left( \cdot \right) Classifier(⋅) 来获取模式的得分,这些得分表示模型中属于真实模式的概率,如下所示: score cos = 1 − φ ( e q s , { e t c , { e c k } k = 1 ∣ C j ∣ } ) (9) {\text{score}}_{\text{cos }} = 1 - \varphi \left( {{e}_{q}^{s},\left\{ {{e}_{t}^{c},{\left\{ {e}_{c}^{k}\right\} }_{k = 1}^{\left| {C}_{j}\right| }}\right\} }\right) \tag{9} scorecos =1−φ(eqs,{etc,{eck}k=1∣Cj∣})(9) score c l = Classifier ( e q s , { e t c , { e c k } k = 1 ∣ C j ∣ } ) (10) {\operatorname{score}}_{\mathrm{{cl}}} = \operatorname{Classifier}\left( {{e}_{q}^{s},\left\{ {{e}_{t}^{c},{\left\{ {e}_{c}^{k}\right\} }_{k = 1}^{\left| {C}_{j}\right| }}\right\} }\right) \tag{10} scorecl=Classifier(eqs,{etc,{eck}k=1∣Cj∣})(10) 其中, score cos {\text{score}}_{\text{cos }} scorecos 和 score cl {\text{score}}_{\text{cl }} scorecl 分别是通过余弦相似度距离和分类器获得的模式得分。
最后,我们保留得分超过0.5的数据库模式作为预测的数据库模式,分别从 score c o s {\operatorname{score}}_{\mathrm{{cos}}} scorecos 和 score c l {\operatorname{score}}_{\mathrm{{cl}}} scorecl 得到的预测模式为 d pred cos {d}_{\text{pred }}^{\text{cos }} dpred cos 和 d pred c l {d}_{\text{pred }}^{cl} dpred cl 。对于推理,交叉编码器的预测模式为 d f t = d pred cos ∪ d pred c l {d}_{f}^{t} = {d}_{\text{pred }}^{\text{cos }} \cup {d}_{\text{pred }}^{\mathrm{{cl}}} dft=dpred cos ∪dpred cl 。因此,我们使用交叉熵损失 CrossEntropy ( ⋅ ) \operatorname{CrossEntropy}\left( \cdot \right) CrossEntropy(⋅) 从余弦相似度距离和分类器的角度来训练交叉编码器,如下所示 L cos = CrossEntropy ( d pred cos , d gt ) (11) {\mathcal{L}}_{\text{cos }} = \text{ CrossEntropy }\left( {{d}_{\text{pred }}^{\cos },{d}_{\text{gt }}}\right) \tag{11} Lcos = CrossEntropy (dpred cos,dgt )(11) L c l = CrossEntropy ( d pred c l , d g t ) (12) {\mathcal{L}}_{\mathrm{{cl}}} = \text{ CrossEntropy }\left( {{d}_{\text{pred }}^{\mathrm{{cl}}},{d}_{\mathrm{{gt}}}}\right) \tag{12} Lcl= CrossEntropy (dpred cl,dgt)(12) 其中 d g t ∈ D g t {d}_{gt} \in {D}_{gt} dgt∈Dgt 是真实的数据库模式。
表级别的损失函数可以表示如下 L t = L c o s + L c l (13) {\mathcal{L}}_{t} = {\mathcal{L}}_{cos} + {\mathcal{L}}_{cl} \tag{13} Lt=Lcos+Lcl(13) 数据库级别。给定问题 q ∈ Q q \in Q q∈Q 、作为外部知识的证据 k ∈ K k \in K k∈K 以及关系数据库 d ∈ D d \in D d∈D ,我们使用 LoRA(胡等人,2022 年)构建一条指令来微调预训练的大语言模型(如 Llama3 - 8B 等),在数据库级别推理与 SQL 查询相关的预测模式以进行模式链接,具体如下 d f d = LLM ( inst , d , k , q ) (14) {d}_{f}^{d} = \operatorname{LLM}\left( {\text{ inst }, d, k, q}\right) \tag{14} dfd=LLM( inst ,d,k,q)(14) 其中 inst 是指令, L L M ( ⋅ ) {LLM}\left( \cdot \right) LLM(⋅) 表示大语言模型操作, d f d {d}_{f}^{d} dfd 表示在数据库级别过滤后的数据库模式。
数据库级别的损失函数可表示如下 L d = 1 n ∑ i = 1 n p ( d g t i ∣ d i , k i , q i ) (15) {\mathcal{L}}_{d} = \frac{1}{n}\mathop{\sum }\limits_{{i = 1}}^{n}p\left( {{d}_{\mathrm{{gt}}}^{i} \mid {d}_{i},{k}_{i},{q}_{i}}\right) \tag{15} Ld=n1i=1∑np(dgti∣di,ki,qi)(15) 其中 n n n 是文本到 SQL 实例的数量, d i , k i , q i {d}_{i},{k}_{i},{q}_{i} di,ki,qi 是关系数据库、第 i i i 个实例的证据和问题, d g t i {d}_{gt}^{i} dgti 表示与 SQL 生成相关的第 i i i 个目标数据库模式。
最后,我们得到过滤后的数据库模式 d f = d f c ∪ d f t ∪ d f d {d}_{f} = {d}_{f}^{c} \cup {d}_{f}^{t} \cup {d}_{f}^{d} df=dfc∪dft∪dfd ,它将作为下一轮模式链接的输入数据库。具体而言,我们采用链式循环策略,持续使用多模式链接(MSL,Multi-Schema Linking)处理模式链接,通过不断减少冗余模式的数量来降低模式链接的任务难度。
4.3 SQL生成
给定通过多模式链接(MSL,Multi-Schema Linking)预测得到的数据库模式 d f = d f c ∪ {d}_{f} = {d}_{f}^{c} \cup df=dfc∪ d f t ∪ d f d {d}_{f}^{t} \cup {d}_{f}^{d} dft∪dfd ,我们构建一条指令,使用低秩自适应(Lora,Low-Rank Adaptation)对预训练的大语言模型(LLMs,Large Language Models)进行微调,以生成用于推理的SQL查询,具体如下: s = LLM ( inst , d f , k , q ) (16) s = \operatorname{LLM}\left( {\text{ inst },{d}_{f}, k, q}\right) \tag{16} s=LLM( inst ,df,k,q)(16) 其中 s s s 是预测的SQL查询。
SQL生成的损失函数可表示如下: L S Q L = 1 n ∑ i = 1 n p ( s g t i ∣ d f i , k i , q i ) (17) {\mathcal{L}}_{S}{QL} = \frac{1}{n}\mathop{\sum }\limits_{{i = 1}}^{n}p\left( {{s}_{\mathrm{{gt}}}^{i} \mid {d}_{f}^{i},{k}_{i},{q}_{i}}\right) \tag{17} LSQL=n1i=1∑np(sgti∣dfi,ki,qi)(17) 其中 n n n 是文本到SQL实例的数量, s g t i {s}_{gt}^{i} sgti 是第 i i i 个目标真实SQL查询。
5 实验
5.1 数据集
我们在两个广泛使用的文本到SQL数据集上进行评估,包括Spider数据集(Yu等人,2018年)和Bird数据集(Li等人,2023c)。
-
Spider数据集(Yu等人,2018年)。它包含200个数据库模式,其中160个数据库模式用于训练和验证,40个数据库模式用于测试。训练集包含8659个样本,其中包括7000个手动标注的样本以及从之前的六个文本到SQL数据集(例如,Restaurants数据集(Popescu等人,2003年;Tang和Mooney,2001年)、GeoQuery数据集(Zelle和Mooney,1996年)等)中获取的1659个补充样本,而开发集包含1034个样本,测试集是隐藏的。每个实例由针对特定数据库模式的自然语言问题和相应的SQL查询组成。
-
Bird数据集(Li等人,2023c)。它涵盖了95个大型数据库,其中分别有69个、11个和15个数据库用于训练、开发和测试。这个总大小为 33.4 G B {33.4}\mathrm{{GB}} 33.4GB 的数据集涵盖了37个专业领域,包括区块链、体育、医疗保健等。训练集有9428个样本,开发集包含1543个样本,测试集是隐藏的。每个样本由一个自然语言问题、作为外部知识的证据、一个特定的数据库和一个相应的SQL查询组成。
5.2 评估指标
为了进行全面比较,我们评估了文本到SQL(Text-to-SQL)在模式链接和SQL生成方面的性能。
- 模式链接。在模式链接的评估方面,我们采用匹配准确率(MA)、包含准确率(IA)和冗余率(RE)来报告性能。
匹配准确率:MA指标用于评估预测的模式是否与真实模式相同。 M A = ∑ n i 1 if match ( s i , y i ) = True else 0 n {MA} = \frac{\mathop{\sum }\limits_{n}^{i}1\text{ if }\operatorname{match}\left( {{s}_{i},{y}_{i}}\right) = \text{ True else }0}{n} MA=nn∑i1 if match(si,yi)= True else 0 (18)
表1:在Bird数据集上与最先进的文本到SQL方法的比较。* 表示我们使用作者发布的代码得到的结果。最佳结果以粗体标记。
| 方法 | 开发 | 测试 | |||
| 示例 | VES(原文未明确含义,保留英文) | 示例 | VES(原文未明确含义,保留英文) | ||
| 基于提示的方法 | GPT - 4 | 46.35 | 49.77 | 54.89 | 60.77 |
| DIN - SQL+GPT - 4(波雷扎(Pourreza)和拉菲伊(Rafiei),2023年) | 50.72 | 58.79 | 55.90 | 59.44 | |
| DAIL - SQL+GPT - 4(高(Gao)等人,2024年) | 54.76 | 56.08 | 57.41 | 61.95 | |
| MCS - SQL+GPT - 4(李(Lee)等人,2024年) | 63.4 | 64.8 | 65.5 | 71.4 | |
| MAC - SQL+GPT - 4(王(Wang)等人,2024年) | 59.39 | 66.39 | 59.59 | 67.68 | |
| MAC - SQL+GPT - 3.5 - 极速版(王(Wang)等人,2024年) | 50.56 | 61.25 | - | - | |
| MAC - SQL+GPT - 3.5 - 特鲁博*(MAC-SQL+GPT-3.5-Trubo*) | 49.15 | 56.93 | - | - | |
| MAC - SQL+GPT - 3.5 - 特鲁博* +我们预测的模式(MAC-SQL+GPT-3.5-Trubo* +Our predicted schemas) | 52.28 | 56.14 | - | - | |
| MAC - SQL+大羊驼3 - 70B*(MAC-SQL+Llama3-70B*) | 53.72 | 57.03 | - | - | |
| MAC - SQL+大羊驼3 - 70B* +我们预测的模式(MAC-SQL+Llama3-70B* +Our predicted schemas) | 54.95 | 58.76 | - | - | |
| 基于微调的方法(Fine-tuning -based methods) | DTS - SQL+深度探索7B(普尔雷扎和拉菲伊,2024年)(DTS-SQL+DeepSeek-7B (Pourreza and Rafiei, 2024)) | 55.8 | - | 60.31 | - |
| SFT代码 - 7B(李等人,2024年) | 57.17 | 58.80 | 59.25 | 63.62 | |
| SFT代码 - 15B(李等人,2024年) | 58.47 | 59.87 | 60.37 | 64.22 | |
| 国际象棋(塔拉伊等人,2024年) | 65.00 | 65.43 | 66.69 | 72.63 | |
| PSM - SQL + DeepSeek - 7B(我们的) | 60.30 | 61.57 | - | - | |
| PSM - SQL + Llama3 - 8B(我们的) | 59.71 | 65.15 | - | - | |
| PSM - SQL + Llama3 - 70B(我们的) | 65.06 | 67.87 | - | - | |
其中 n \mathrm{n} n 表示样本数量, s i {s}_{i} si 和 y i {y}_{i} yi 分别表示第 i i i 个预测模式和真实模式, match ( ⋅ ) \operatorname{match}\left( \cdot \right) match(⋅) 表示用于确定两个模式是否相同的函数。
包含准确率(Including Accuracy):IA 指标用于评估预测模式是否包含真实模式。 I A = ∑ n i 1 if s i ⊇ y i else 0 n (19) {IA} = \frac{\mathop{\sum }\limits_{n}^{i}1\text{ if }{s}_{i} \supseteq {y}_{i}\text{ else }0}{n} \tag{19} IA=nn∑i1 if si⊇yi else 0(19) 冗余度(Redundancy):RE 指标用于评估预测模式中的冗余情况。 R E = ∑ n i ∑ m j 0 if s i j ∈ y i else 1 n × m (20) {RE} = \frac{\mathop{\sum }\limits_{n}^{i}\mathop{\sum }\limits_{m}^{j}0\text{ if }{s}_{i}^{j} \in {y}_{i}\text{ else }1}{n \times m} \tag{20} RE=n×mn∑im∑j0 if sij∈yi else 1(20) 其中 m \mathrm{m} m 表示第 i i i 个预测模式中的模式数量, s i j {s}_{i}^{j} sij 表示第 i i i 个预测模式中的第 j j j 个模式。
表 2:在 Spider 数据集上与最先进的文本到 SQL(Text-to-SQL)方法进行比较。* 表示我们使用作者发布的代码得到的结果。最佳结果用粗体标记。
| 方法 | 开发 | 测试 | |||
| 示例(EX) | 精确匹配(EM) | 示例(EX) | 精确匹配(EM) | ||
| 基于提示的方法 | C3+ChatGPT(董等人,2023年) | 81.80 | - | 82.30 | - |
| DIN - SQL+GPT - 4(波雷扎和拉菲伊,2023年) | 74.2 | 60.1 | 85.30 | 60 | |
| DAIL - SQL+GPT - 4(高等人,2024年) | 84.40 | 74.4 | 86.60 | - | |
| MCS - SQL+GPT - 4(李等人,2024年) | 89.5 | - | 89.6 | - | |
| MAC - SQL+GPT - 4(王等人,2024年) | 86.75 | 63.20 | 82.80 | - | |
| MAC - SQL+GPT - 3.5 - 极速版(王等人,2024年) | 80.56 | - | 75.53 | - | |
| MAC-SQL+GPT-3.5-特鲁博* | 75.0 | 19.1 | - | - | |
| MAC-SQL+GPT-3.5-特鲁博* +我们预测的模式 | 75.4 | 20.5 | - | - | |
| MAC-SQL+大羊驼3-70B* | 76.6 | 27.5 | - | - | |
| MAC-SQL+大羊驼3-70B* +我们预测的模式 | 78.1 | 28.7 | - | - | |
| 基于微调的方法 | RESDSQL-3B(李等人,2023a) | 84.1 | 80.5 | 79.9 | 72 |
| DTS - SQL + DeepSeek - 7B(普尔雷扎(Pourreza)和拉菲伊(Rafiei),2024年) | 85.5 | 79.1 | 84.4 | 73.7 | |
| SFT CODES - 7B(李(Li)等人,2024年) | 85.5 | - | - | - | |
| SFT CODES - 15B(李(Li)等人,2024年) | 84.9 | - | - | - | |
| CHESS(塔莱伊(Talaei)等人,2024年) | - | - | 87.2 | - | |
| PSM - SQL + DeepSeek - 7B(我们的) | 86.9 | 79.5 | - | - | |
| PSM - SQL + Llama3 - 8B(我们的) | 84.1 | 79.5 | - | - | |
| PSM-SQL+大羊驼3-70B(我们的) | 88.6 | 82.2 | - | - | |
- SQL生成。对于Spider数据集,我们使用执行准确率(EX)和完全匹配准确率(EM)来评估性能。在对Bird数据集的评估方面,我们采用执行准确率(EX)和有效效率得分(VES)作为评估指标。
执行准确率:EX指标用于评估预测的SQL查询和真实的SQL查询在数据库上是否产生相同的执行结果。 E X = ∑ n i 1 if match ( ex ( S Q L i pred ) , ex ( S Q L i g t ) ) = True else 0 n (21) {EX} = \frac{\mathop{\sum }\limits_{n}^{i}1\text{ if match }\left( {\operatorname{ex}\left( {{SQ}{L}_{i}^{\text{pred }}}\right) ,\operatorname{ex}\left( {{SQ}{L}_{i}^{gt}}\right) }\right) = \text{ True else }0}{n} \tag{21} EX=nn∑i1 if match (ex(SQLipred ),ex(SQLigt))= True else 0(21) 其中ex ( ⋅ ) \left( \cdot \right) (⋅) 是用于在数据库中执行SQL查询并返回结果的函数, ( S Q L i pred \left( {{SQ}{L}_{i}^{\text{pred }}}\right. (SQLipred 和 ( S Q L i gt \left( {{SQ}{L}_{i}^{\text{gt }}}\right. (SQLigt 分别表示第 i i i 个预测的SQL查询和真实的SQL查询。
有效效率得分:VES指标用于评估准确生成的SQL查询的执行效率。 V E S = E X × ∑ n i time ( e x ( S Q L i g t ) ) time ( e x ( S Q L i p r e d ) ) n (22) {VES} = \frac{{EX} \times \mathop{\sum }\limits_{n}^{i}\frac{\operatorname{time}\left( {{ex}\left( {{SQ}{L}_{i}^{gt}}\right) }\right) }{\operatorname{time}\left( {{ex}\left( {{SQ}{L}_{i}^{pred}}\right) }\right) }}{n} \tag{22} VES=nEX×n∑itime(ex(SQLipred))time(ex(SQLigt))(22) 其中time ( ⋅ ) \left( \cdot \right) (⋅) 表示执行时间。
表3:在模式链接任务上与最先进的文本到SQL方法进行比较。* 表示我们使用作者发布的代码获得的结果。最佳结果以粗体显示。
| BIRD的开发集 | SPIDER的开发集 | |||||||||||
| 方法 | 表格 | 列 | 表格 | 列 | ||||||||
| 平均准确率(MA)↑ | 信息获取(IA)↑ | 检索效果(RE)↓ | 平均准确率(MA)↑ | 信息获取(IA)↑ | 检索效果(RE)↓ | 平均准确率(MA)↑ | 信息获取(IA)↑ | 检索效果(RE)↓ | 平均准确率(MA)↑ | 信息获取(IA)↑ | 检索效果(RE)↓ | |
| MAC - SQL + GPT3.5 - 特鲁博(GPT3.5-Trubo)* | 1.04 | 100 | 72.77 | 0 | 81.68 | 88.21 | 5.22 | 100 | 66.54 | 0 | 88.88 | 93.36 |
| MAC - SQL + 大羊驼3 - 70B(Llama3 - 70B)* | 1.04 | 100 | 72.77 | 0 | 89.31 | 89.97 | 5.22 | 100 | 66.54 | 0 | 91.88 | 93.33 |
| PSM - SQL + 大羊驼3 - 8B(Llama3 - 8B)(我们的) | 56.65 | 97.91 | 25.43 | 17.99 | 86.05 | 45.66 | 83.08 | 98.84 | 10.54 | 59.96 | 95.16 | 23.1 |
表4:BIRD数据集上不同变体的性能。最佳结果以粗体标记。
| 循环 | BIRD的开发集 | ||||||
| 表格 | 列 | ||||||
| 平均准确率(MA)↑ | 个体准确率(IA)↑ | 相关性下降(RE↓) | 平均准确率(MA)↑ | 个体准确率(IA)↑ | 相关性下降(RE↓) | ||
| 循环1(Cycle_1) | 交叉编码器(Cross_encoder) | 37.87 | 82.4 | 36.29 | 15.45 | 48.63 | 48.73 |
| 嵌入大语言模型(Emb_LLM) | 28.81 | 89.96 | 48.18 | 5.93 | 46.41 | 68.53 | |
| 生成大语言模型(Gen_LLM) | 68.12 | 67.34 | 6.68 | 30.7 | 33.05 | 33.82 | |
| 交叉编码器 + 生成大语言模型(Cross_encoder +Gen_LLM) | 39.31 | 91.07 | 35.49 | 13.17 | 66.36 | 50.44 | |
| 平均海平面(所有)(MSL (All)) | 24.32 | 96.81 | 50.87 | 2.09 | 74.9 | 69.07 | |
| 周期2 | 交叉编码器(Cross_encoder) | 49.54 | 81.1 | 27.43 | 17.8 | 55.02 | 48.99 |
| 嵌入大语言模型(Emb_LLM) | 34.16 | 79.86 | 41.64 | 8.15 | 36.9 | 62.96 | |
| 生成大语言模型(Gen_LLM) | 94.2 | 94.65 | 2.11 | 54.95 | 62.97 | 11.16 | |
| 交叉编码器 + 生成大语言模型(Cross_encoder +Gen_LLM) | 56.65 | 97.91 | 25.43 | 17.99 | 86.05 | 45.66 | |
| 平均海平面(所有)(MSL (All)) | 32.79 | 98.63 | 43.07 | 3.26 | 89.05 | 62.32 | |
表5:BIRD数据集上不同变体的性能。最佳结果以粗体显示。
| 循环 | BIRD的开发集 | ||
| 示例 | VES(未明确专业含义,保留原文) | ||
| 循环_1 | 交叉编码器+生成式大语言模型 | 57.11 | 58.7 |
| 平均海平面(所有)(MSL (All)) | 57.63 | 59.76 | |
| 周期2 (Cycle_2) | 交叉编码器+生成式大语言模型 | 59.71 | 65.15 |
| 平均海平面(所有)(MSL (All)) | 58.80 | 53.28 | |
精确匹配准确率:EM指标用于评估预测的SQL和真实SQL的抽象语法树结构是否相同。 E X = ∑ n i 1 if match ( st ( S Q L i pred ) , st ( S Q L i g t ) ) = True else 0 n (23) {EX} = \frac{\mathop{\sum }\limits_{n}^{i}1\text{ if match }\left( {\operatorname{st}\left( {{SQ}{L}_{i}^{\text{pred }}}\right) ,\operatorname{st}\left( {{SQ}{L}_{i}^{gt}}\right) }\right) = \text{ True else }0}{n} \tag{23} EX=nn∑i1 if match (st(SQLipred ),st(SQLigt))= True else 0(23) 其中st ( ⋅ ) \left( \cdot \right) (⋅) 是用于获取SQL查询抽象语法树结构的函数。
5.3 基线模型
我们纳入了9种文本转SQL方法作为基线模型,分为两类,包括基于提示的方法和基于微调的方法。详情如下。
-
基于提示的方法:C3(董等人,2023年)提出了三个关键组件,包括清晰提示、带提示的校准和一致输出,从模型输入、模型偏差和模型输出的角度提高文本到SQL(结构化查询语言)的性能。DIN - SQL(波尔雷扎和拉菲埃,2023年)将文本到SQL的任务分解为多个子任务,以解决自然语言(NL)和SQL之间的差异。DAIL - SQL(高等人,2024年)提出了一种新颖的上下文学习技术,通过学习问题和查询之间的映射来解决示例质量和数量之间的权衡问题。MCS - SQL(李等人,2024年)利用多个提示生成各种候选答案,并根据置信度分数有效地聚合这些答案。MAC - SQL(王等人,2024年)将大语言模型(LLMs)用作具有不同功能的智能代理,用于文本到SQL的解析。
-
基于微调的方法:RESDSQL(李等人,2023a)采用了一种骨架感知解码器,通过由排名增强编码器选择的骨架和相关模式来隐式引导SQL解析。DTS - SQL(普尔雷扎和拉菲伊,2024)将文本到SQL的任务分解为两个简单任务,并微调开源大语言模型以生成SQL查询。利用收集到的专注于SQL的语料库,CODES(李等人,2024)提出了一种数据库提示构建策略和一种双向数据增强机制,以微调一系列参数范围从 1 B 1\mathrm{\;B} 1B 到 15 B {15}\mathrm{\;B} 15B 的语言模型。CHESS(塔莱伊等人,2024)引入了一种分层检索方法来选择相关实体和上下文,以及一种三阶段模式剪枝协议来提取最小充分模式。
5.4 实现细节
在MSL模块的列级别方面,采用预训练的BGE-large-en-v1.5模型作为嵌入模型进行微调,并在推理阶段以0.5作为阈值来预测模式。在MSL模块的表级别方面,我们基于ROBERTA设计了一个交叉编码器模型,用于对嵌入空间和分类器空间中模式之间的交互进行建模。具体而言,由于ROBERTA的限制,输入标记中超过512的部分会被截断,这会干扰语义学习。为解决这个问题,在训练阶段,输入批次中表的列顺序将被打乱。在推理阶段,交叉编码器首先选择得分大于0.5的表。然后,我们为得分前2的表选择前8列,为其余表选择前4列,作为预测的模式。在MSL模块的数据库级别方面,我们使用预训练的Llama3 - 8 B 8\mathrm{\;B} 8B 模型进行微调,以推理与SQL生成相关的模式。
5.5 测试方法的性能
表1和表2总结了各方法在BIRD(Bird)和SPIDER(Spider)数据集上的SQL生成性能,从中我们有以下几点观察。1) 作为基于提示的方法,使用我们预测模式的MAC - SQL在EX和VES指标上的表现优于原始的MC - SQL。原因在于我们预测的模式包含的冗余模式更少,输入令牌也更少,从而减少了对大语言模型(LLMs)SQL生成的干扰。2) 作为使用DeepSeek - 7B的基于微调的方法,PSM - SQL + DeepSeek - 7B在EX和VES指标上的表现优于DTS - SQL + DeepSeek - 7B。原因是冗余信息较少的预测模式有助于大语言模型学习生成正确的SQL查询。3) PSM - SQL + Llama3 - 70B在BIRD数据集上取得了最佳性能。原因是对于冗余信息较少的预测模式,更大的模型能够更好地展现其语义准确性,从而更准确地生成SQL查询。
表3总结了各方法在BIRD和SPIDER数据集上的模式链接性能,从中我们可以观察到,PSM - SQL + Llama3 - 8B(大语言模型Llama3的80亿参数版本)在表级和列级的MA和RE指标上取得了最佳性能,但代价是IA指标的得分略有降低。原因在于PSM - SQL采用MSL(多模式学习)来学习模式的多粒度语义,并利用循环策略不断减少冗余模式,这有助于识别相关模式并在模式链接时舍弃冗余模式。
5.6 消融实验
PSM - SQL(模式感知语义匹配的结构化查询语言,Pattern - Sensitive Semantic Matching for SQL)主要由链式循环策略和列、表及数据库级别的MSL(多尺度链接,Multi - Scale Linking)模块组成。为验证其有效性,我们评估了PSM - SQL的不同变体,包括PSM - SQL进行一轮或两轮模式链接(分别记为Cycle_1和Cycle_2),PSM - SQL采用MSL在列、表和数据库级别进行模式链接(分别记为Emb_LLM、Cross_encoder和Gen_LLM)。这些变体的性能总结在表4和表5中,从中我们有以下发现。1) 在SQL生成和模式链接任务上,Cycle_2的性能优于Cycle_1。原因是链式循环策略可以持续降低任务难度,有助于模型学会舍弃冗余模式。2) MSL的性能优于Cross_encoder、Emb_LLM和Gen_LLM,并且在IA指标上表现最佳。原因是MSL学习了列、表和数据库级别的模式多粒度模式,比单一级别更全面。3) 在推理的SQL生成性能方面,Cross_encoder + Gen_LLM的表现优于MSL。原因是Emb_LLM关注难以区分的列的语义,导致保留了大量冗余模式。
6 结论
在本文中,我们提出了一种具有多粒度语义框架的渐进式模式链接方法,该方法包含一个多粒度模式链接模块和一种链式循环策略,用于将黄金模式与自然语言(NL)问题进行链接以生成 SQL 查询。更具体地说,PSM - SQL 使用多粒度模式链接(MSL)在列、表和数据库级别捕获多粒度语义,并采用链式循环策略循环减少模式的数量,从而有效提高模式链接的准确性。在 Spider 和 Bird 数据集上进行的实验结果证明了所提出的 PSM - SQL 的有效性。
7 局限性
我们的工作存在两个局限性。首先,我们没有对用于处理模式链接和 SQL 生成的提示进行广泛的设计,这可能不是最优的。其次,模式链接的链式循环策略在降低任务难度的同时不可避免地降低了模型的上限,因为它可能在循环过程中丢弃一些与 SQL 生成相关的正确模式,这是一个权衡问题。


















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











