







CHESS:高效SQL合成的上下文利用
论文:https://arxiv.org/abs/2405.16755
Github:https://github.com/ShayanTalaei/CHESS
摘要
将自然语言问题转换为SQL查询,即文本到SQL(text-to-SQL),是一个长期存在的研究问题。有效的文本到SQL合成可能会极具挑战性,原因如下:(i)数据库目录(表及其列的描述)和数据库值的规模庞大;(ii)需要对大型数据库模式进行推理;(iii)要确保生成的查询在功能上的有效性;(iv)需要处理自然语言问题的歧义性。我们推出了CHESS,这是一个基于大语言模型(LLM)的多智能体框架,用于高效且可扩展的SQL合成,它包含四个专门的智能体,每个智能体针对上述挑战之一:信息检索器(IR)提取相关数据,模式选择器(SS)修剪大型模式,候选生成器(CG)生成高质量的候选查询并迭代优化查询,单元测试器(UT)通过基于大语言模型的自然语言单元测试来验证查询。我们的框架提供了可配置的特性,以适应各种部署限制,包括:1)支持工业规模的数据库:借助模式选择器智能体,CHESS能有效地将非常大的数据库模式缩小为可管理的子模式,将系统准确率提高约2%,并减少 × 5 \times 5 ×5 个大语言模型的标记数。2)最先进的隐私保护性能:在使用开源模型的方法中,CHESS实现了最先进的性能,打造出一个高性能、保护隐私的系统,适合工业部署。3)在增加计算预算时具有可扩展性:在计算预算充足的情况下,CHESS在BIRD测试集上的准确率达到71.10%,与领先的专有方法相差不到2%,同时所需的大语言模型调用次数大约减少 83 % {83}\% 83% 次。
1 引言
从自然语言问题生成SQL查询,通常称为文本到SQL(text-to-SQL),是一个长期存在且影响重大的研究问题。近年来,数据库的复杂性不断增加,这加剧了该问题,原因在于数据库中存储的模式(列和表的集合)、值(内容)和目录(描述模式和值的元数据)的规模不断增大。即使是一些最大的专有模型,如GPT - 4,在文本到SQL基准测试中的表现也明显落后于人类,存在显著的准确率差距 40 % {40}\% 40% (Li等人,2024b)。除了编写SQL查询本身的复杂性之外,这一巨大差距主要是由于需要有效检索和整合多种不同格式的信息源,包括数据库值、目录和模式,这使得过程变得复杂。考虑到所有这些复杂性,文本到SQL系统在推理阶段缺乏可靠的验证方法会降低生成的SQL查询的可靠性。 ∗ {}^{ * } ∗ 同等贡献作者。
图1展示了现代文本转SQL系统面临的一些挑战。例如,用户的问题可能与数据库中存储的值并不直接匹配(甘等人,2021),因此准确识别值的格式对于有效制定SQL查询至关重要。此外,现实世界的数据库模式通常包含含义模糊的列名、表名和杂乱的数据,这进一步使SQL翻译过程变得复杂,因此需要一个强大的检索系统来识别相关信息(波雷扎和拉菲埃,2023)。此外,一些问题本身可能存在歧义,导致大语言模型(LLM)在生成SQL查询时出现细微错误。例如,在图1右侧所示的问题中,一种方法可能使用ORDER BY和LIMIT 1来确定最高平均分,从而仅返回单个结果。另一种方法可能涉及使用MAX ( )函数的子查询,该方法将返回所有与最大AvgScrRead值匹配的条目。这种方法上的差异可能会导致不同的输出。
CHESS框架。为应对这些挑战,我们推出了CHESS(高效SQL合成的上下文利用,Contextual Harnessing for Efficient SQL Synthesis),这是一个多智能体框架,旨在改进复杂现实世界数据库中的SQL查询生成。CHESS中的每个智能体都专门设计用于应对上述一项或多项挑战:

图1. 文本到SQL翻译中的挑战示例。(1)用户的问题可能不包含确切的数据库值。(2)列名可能无法准确反映其内容,因此数据库目录至关重要。(3)问题解释的歧义可能导致不同但看似有效的SQL查询。
信息检索器(IR)代理旨在检索相关实体(数据库中的值)和上下文(数据库目录中提供的模式描述)。为实现这一目标,我们提出了可扩展且高效的方法,利用局部敏感哈希从数百万行中检索数据库值,借助关键词检测和向量数据库从数据库目录中提取上下文信息。我们的方法利用数据库内容与用户查询之间的语义和句法相似性来提高检索质量。
正如先前的研究(格雷罗等人,2022年)和我们的消融实验(图3)所证实的,用冗余信息过载大语言模型(LLM)的上下文会降低其在下游任务中的性能。为解决这一问题,模式选择器(SS)代理专门设计用于修剪非常大的数据库模式,使候选生成器代理(CG)在合成SQL查询时能够进行更有效的推理。该SS代理配备了三个工具,即过滤列(filter_column)、选择表(select_tables)和选择列(select_columns),这使其即使在处理具有4000多列的复杂真实世界模式时也能保持可扩展的性能。
候选生成器(CG)代理根据向数据库提出的问题生成SQL查询。然后,它会根据结果按需执行和修改这些查询。
单元测试器(Unit Tester,UT)代理通过生成多个自然语言单元测试并根据这些测试评估候选查询,来评估最终查询的质量。UT 根据通过的测试为每个候选查询分配一个分数,选择得分最高的查询,从而确保生成可靠的查询。
总之,CHESS 框架利用协作式多智能体方法来改进复杂数据库的 SQL 生成。每个智能体都发挥着专门的功能,从检索相关数据和筛选模式信息到生成和验证 SQL 查询,共同确保准确、高效且具有上下文感知能力的查询合成。
CHESS 对部署约束的适应性。文本到 SQL 系统在现实世界中的部署必须考虑各种约束,例如大语言模型(Large Language Models,LLMs)的推理能力和采样预算,以及数据隐私问题。CHESS 被设计为一个可配置的框架,能够在保持高性能的同时适应不同的部署场景。在 4.2 小节中,我们将讨论各种部署设置,以及如何对 CHESS 进行定制,以在遵守这些约束的同时满足性能要求。
为应对复杂工业数据库模式的挑战,CHESS(跨异构模式的上下文感知文本到SQL系统)集成了一个模式选择器(Schema Selector,SS)代理,该代理能有效地将大型模式缩小为可管理的子模式,确保有足够的信息来准确回答查询。对于计算资源有限的环境,CHESS通过尽量减少对频繁且成本高昂的大语言模型(LLM)调用的依赖来优化性能,使用资源消耗较少的模型取得了相当的效果。在数据隐私方面,CHESS支持使用可在本地部署的完全开源模型,消除了将私有数据发送给第三方供应商的需求。这些特性共同使CHESS能够适应各种部署限制,为工业领域的文本转SQL应用提供了一个灵活且高性能的解决方案。
实验。为验证CHESS的有效性,我们在包括BIRD和Spider在内的具有挑战性的基准测试上,针对各种部署场景进行了全面实验。我们的评估包括在大规模模式上进行测试、在计算资源有限的情况下运行,以及通过使用完全开源模型来确保数据隐私。我们还进行了消融实验,以评估CHESS中每个组件的贡献。
实验结果表明,CHESS在各种不同的设置下都优于许多现有的先进方法。具体而言,CHESS在BIRD测试集上达到了71.10%的准确率,与领先的专有方法(Pourreza等人,2024年)的差距在 2 % 2\% 2% 以内,同时所需的大语言模型(LLM)调用次数大约减少了 83 % {83}\% 83% 。在使用开源模型的方法中,CHESS在BIRD开发集上以 61.5 % {61.5}\% 61.5% 的准确率树立了新的基准。此外,我们在拥有超过4000列的超大型工业规模数据库模式上对CHESS进行了测试。借助模式选择器代理,CHESS有效地修剪了无关列,从而使准确率提高了 2 % 2\% 2% ,并使令牌使用量减少了 × 5 \times 5 ×5 。消融研究证实了信息检索器和单元测试器等组件在提升整体性能方面的关键作用,每个组件都对系统的准确性和效率做出了重大贡献。最后,研究表明,即使在计算资源受限的情况下,CHESS仍能保持与现有方法相当的高准确率,这使其适用于资源有限的部署场景,同时还能解决数据隐私问题。
贡献。具体来说,我们的贡献如下:
-
新型多智能体框架:我们提出了CHESS,这是一个多智能体框架,它利用四个专门的智能体:信息检索器(IR)、模式选择器(SS)、候选生成器(CG)和单元测试器(UT),显著提高了在复杂的真实世界数据库上进行文本到SQL转换的性能和效率。
-
创新的单元测试生成:我们引入了一种用于文本到SQL的新型自然语言单元测试生成方法,能够在推理过程中有效评估生成的SQL查询。
-
计算高效的可扩展检索方法:我们开发了一种高效的分层检索方法,用于从海量数据集中提取相关实体和上下文,显著提高了SQL预测的准确性。
-
适用于工业规模数据库模式的模式选择协议:我们的模式选择协议能够有效修剪非常大的工业规模模式,包括那些具有超过4000列的模式。据我们所知,这是第一种能够处理如此复杂程度的大规模模式的方法。
-
最先进的隐私保护性能:在使用开源模型的方法中,我们实现了最先进的性能,从而构建了一个高性能、保护隐私的系统,适合工业部署。本文的其余部分组织如下:第2节回顾相关工作,第3节详细介绍CHESS框架,第4节展示实验结果,第5节对未来工作进行讨论并总结。本文报告结果的所有复现代码均可在我们的GitHub仓库中获取。 ∗ {}^{ * } ∗ ## 2 相关工作
从自然语言问题生成准确的SQL查询,即文本到SQL(text-to-SQL),是自然语言处理(NLP)和数据库领域的一个活跃研究领域。早期的进展涉及自定义模板(泽勒和穆尼,1996年),需要大量的人工工作。最近的方法利用基于Transformer的序列到序列模型(瓦斯瓦尼等人,2017年;苏茨克弗等人,2014年),这些模型非常适合涉及序列生成的任务,包括文本到SQL(秦等人,2022年)。早期的序列到序列模型,如IRNet(郭等人,2019年),使用具有自注意力机制的双向长短期记忆网络(LSTM)架构来编码查询和数据库模式。为了更好地整合模式信息,像RAT - SQL(王等人,2019年)和RASAT(齐等人,2022年)这样的模型引入了关系感知自注意力机制,而SADGA(蔡等人,2021年)和LGESQL(曹等人,2021年)则采用图神经网络来处理模式 - 查询关系。尽管取得了这些进展,但序列到序列模型的性能仍未达到人类水平,在Spider保留测试集上没有一个模型的执行准确率超过 80 % {80}\% 80% (于等人,2018年)。
随着大语言模型(LLM)在各个自然语言处理(NLP)领域的广泛应用,文本到SQL(Structured Query Language,结构化查询语言)领域同样受益于近期基于大语言模型的方法创新,从而提升了性能。早期方法(拉杰库马尔等人,2022年)利用大语言模型的零样本上下文学习能力来生成SQL语句。在此基础上,后续的模型,包括DIN - SQL(波雷扎和拉菲埃,2024a)、DAIL - SQL(高等人,2023年)、MAC - SQL(王等人,2023年)和C3(董等人,2023年)通过任务分解提升了大语言模型的性能。除了上下文学习之外,DAIL - SQL(高等人,2023年)、DTS - SQL(波雷扎和拉菲埃,2024b)和CodeS(李等人,2024a)中的提议试图通过有监督微调来提升开源大语言模型的能力,目标是与更大的专有模型相媲美甚至超越它们。然而,利用上下文学习方法的专有大语言模型取得了最显著的性能提升(李等人,2024b)。与以往的研究不同,本文引入了一种混合方法,将上下文学习和有监督微调相结合,以进一步提升性能。此外,我们提出了新颖的方法,将数据库值和数据库目录等上下文数据集成到文本到SQL的流程中,利用了丰富但常被忽视的信息源。此外,我们还提出了用于SQL查询生成的自然语言生成方法,以提高文本到SQL系统的可靠性。与以往大多数研究不同,蒸馏器方法(马马里等人,2024年)表明,最新版本的大语言模型可以在其提示中有效处理多达200列的数据库模式信息,从而无需单独的模式链接步骤,因为该步骤可能会在流程中引入错误。在我们的研究中,我们证实,对于像BIRD(李等人,2024b)这样的基准测试,其模式包含约100列,模式链接变得不必要。然而,对于约有4000列的更大模式,由于提示大小增加,性能仍然会下降,因此需要单独的模式链接步骤。
与我们的工作独立但同时进行的是,《大型语言猴》(Large Language Monkeys,布朗等人,2024年)、《执政官》(Archon,萨德 - 法尔孔等人,2024年)、《MCS - SQL》(MCS - SQL,李等人,2024年)以及《CHASE - SQL》(CHASE - SQL,波雷扎等人,2024年)介绍了一些方法,这些方法依赖于在推理时为给定问题生成大量候选响应。后两种方法是专门为文本到SQL领域设计的,它们使用一种选择算法来比较并选择最佳候选响应。然而,与这些需要大量大语言模型(LLM)调用的方法不同,我们提出了一个多智能体框架,该框架可以根据可用的计算预算进行自适应使用。这个框架既可以生成多个候选方案并使用单元测试对其进行筛选,或者在尽量减少大语言模型调用至关重要的情况下,它允许组合不同的智能体,从而在预算限制内实现准确的结果。
3 方法
“CHESS:高效SQL合成的上下文利用”(CHESS: Contextual Harnessing for Efficient SQL Synthesis)是一个多智能体框架,由四个智能体组成,每个智能体都配备了专门的工具以实现特定目标。下面,我们将详细解释每个智能体的功能和工具。CHESS的整体结构图示见图2。
文本到SQL系统的实际部署必须考虑各种限制因素,例如大语言模型(LLM)的推理能力和采样预算,以及数据隐私问题。CHESS被设计为一个可配置的框架,能够在适应不同部署场景的同时保持高性能。在4.2小节中,我们将讨论各种部署设置,以及如何对CHESS进行定制,使其在满足这些限制条件的同时达到性能要求。
3.1 代理:描述与工具
在本小节中,我们将介绍CHESS框架的核心代理及其各自的工具,每个代理和工具都是专门为应对文本到SQL任务的独特挑战而设计的。四个代理——信息检索器(IR)、模式选择器(SS)、候选生成器(CG)和单元测试器(UT)——在框架中发挥着重要作用,它们利用专门的工具来执行分配给它们的功能。下面,我们将详细解释每个代理的角色以及它们为实现高效、高性能的SQL查询生成所采用的工具。实现细节和提示模板见附录A和C。
信息检索器(IR)配备了提取关键词、实体检索和上下文检索等工具的信息检索器代理,会收集与输入相关的信息,包括问题中提及的实体以及数据库目录中提供的上下文信息。这些工具介绍如下:
提取关键词。为了在数据库和模式描述中搜索相似值,代理需要从自然语言问题中提取主要关键词。此工具使用少样本大语言模型(LLM)调用来从输入中提取主要关键词和关键短语。
实体检索。从问题中提取的关键词列表中,有些可能对应数据库中存在的实体。该工具允许代理在数据库中搜索相似值,并为每个关键词返回最相关的匹配项及其对应的列。为了评估关键词与数据库值之间的句法相似度,我们采用编辑距离相似度指标。此外,为了提高检索效率,我们提出了一种基于局部敏感哈希(LSH)和语义(嵌入)相似度度量的分层检索策略,我们将在附录A中详细解释。这种方法使代理能够有效地检索与关键词在句法和语义上都相似的值。
检索上下文。除了检索值之外,信息检索(IR)代理还可以访问数据库目录,该目录通常包含模式元数据,如列描述、扩展列名(用于解析缩写)和值描述。如图1所示,这些信息很有用,如果不将其提供给模型,可能会导致性能欠佳。信息检索代理使用此工具通过查询在预处理期间构建的描述向量数据库,从数据库目录中检索最相关的描述。检索基于语义(嵌入)相似度,以确保向模型提供最相关的上下文。
模式选择器(SS) 模式选择器(SS)代理的目标是通过仅选择生成SQL查询所需的必要表和列来减小模式大小。为实现这一目标,模式选择器代理配备了三个工具:过滤列(filter_column)、选择表(select_tables)和选择列(select_columns)。
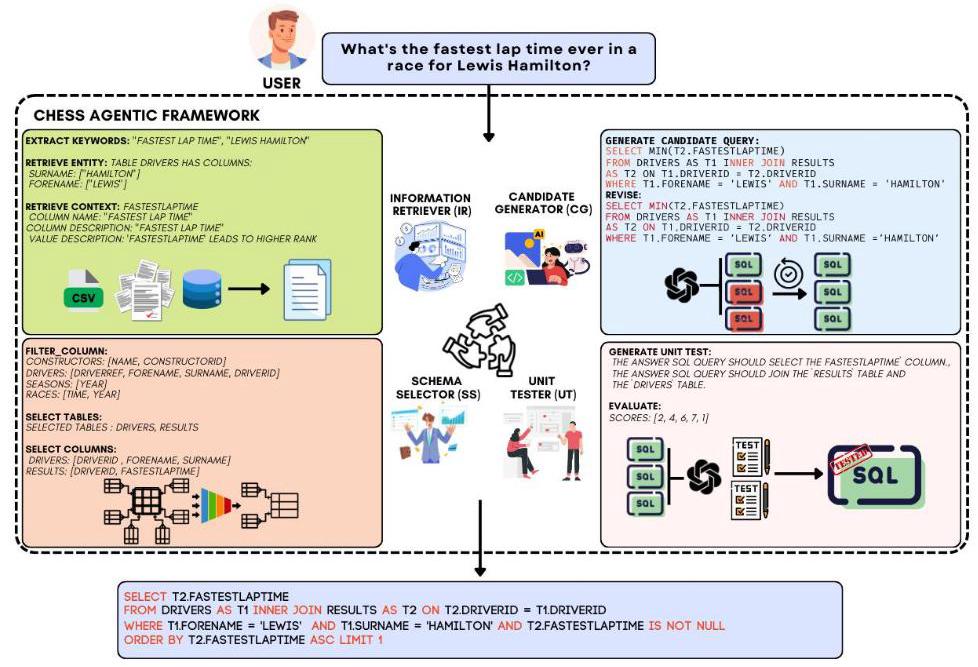
图2. 用于文本到SQL任务的CHESS多代理框架,包括四个代理:信息检索器(IR)、模式选择器(SS)、候选生成器(CG)和单元测试器(UT)。
过滤列 数据库通常包含数百列,其中许多列在语义上可能与用户的查询无关。受这一观察结果的启发,我们设计了这个工具,它以列名和问题作为输入,并确定该列是否相关。虽然可以使用基于嵌入的相似性方法来执行此任务,但我们选择使用相对成本较低的大语言模型(LLM)以确保高精度。
尽管此工具在过滤无关列方面很有效,但准确识别相关的模式元素通常需要一起处理多个模式项。以下工具通过处理此类场景来补充这一过程。
选择表 此工具以数据库的子模式和问题作为输入,并通过大语言模型(LLM)提示,返回回答查询所需的表。
选择列 为了进一步缩小相关模式项的范围,可以使用选择列工具。通过输入子模式和问题,智能体仅检索必要的列。
SS代理可以根据其配置单独或组合使用这些工具。然而,在选择相关模式项时,其操作涉及到精确率和召回率之间的权衡。值得注意的是,在处理包含超过4000列的超大型数据库时,该代理可以显著减少无关信息。第4.2.2节对SS代理的重要性进行了详细讨论。
候选生成器(Candidate Generator,CG) 候选生成器(CG)负责合成能从数据库中回答问题的SQL查询。为实现这一目标,CG代理首先调用generate_candidate_query工具生成候选查询。然后,它在数据库上执行这些候选查询,检查结果,并识别出任何有问题的查询(包含语法错误或结果为空的查询)。对于每个有问题的候选查询,代理会反复尝试修改查询,直到问题解决或达到允许的最大修改次数。
generate_candidate_query 此工具生成一个能回答问题的候选查询。它将问题、模式和上下文(实体和描述)作为输入,并促使大语言模型(LLM)遵循多步推理指南编写一个候选SQL查询。
修订 有时,生成的候选查询可能包含语法错误或产生空结果。在这种情况下,代理通过在数据库上执行查询来识别问题,然后使用此工具进行修复。该工具将问题、模式、上下文、有问题的查询以及问题描述作为输入。然后,它会将这些信息提供给大语言模型(LLM),要求其修订查询。请注意,问题描述(或执行日志)在引导模型方面至关重要,因为它直接指出了查询的失败点。
单元测试器(UT) 单元测试器(UT)代理负责从候选生成器(CG)代理生成的候选查询池中选择最准确的SQL查询。UT通过以下方式识别最佳候选查询:1)生成多个单元测试,以突出候选查询之间的差异;2)根据这些单元测试评估候选查询。然后,它根据每个查询通过的单元测试数量为其分配分数,选择得分最高的候选查询作为给定问题的最终SQL查询。
生成单元测试 此工具会促使大语言模型(LLM)生成 k k k 个单元测试,其中 k k k 是一个输入参数,这些单元测试的设计使得只有正确的SQL查询才能通过每一个测试。提示信息经过精心构建,以生成高质量的单元测试,突出候选查询之间的语义差异。用于生成单元测试的详细提示信息见附录C。
评估 生成单元测试后,单元测试(UT)代理会根据这些测试对候选查询进行评估。此工具将多个候选查询和单个单元测试作为输入,促使大语言模型对每个候选查询进行推理,以确定其是否通过单元测试。虽然可以实现同时针对多个单元测试评估单个候选查询,但我们在4.2.1节的实验表明,当前每次针对一个单元测试评估多个候选查询的方法能产生更好的结果。
3.2 预处理
为了加速信息检索(IR)代理的工具(即实体检索和上下文检索工具)并提高其效率,我们在运行系统之前对数据库值和目录进行预处理。对于数据库值,我们通过创建局部敏感哈希(Locality-Sensitive Hashing,LSH)索引进行句法搜索,具体方法在实体检索部分有说明。对于包含需要语义理解的较长文本的数据库目录,我们使用向量数据库检索方法来衡量语义相似度。
值的局部敏感哈希索引。为了优化实体检索过程,我们采用一种能够高效搜索大型数据库(可能包含数百万行数据)的方法,以检索最相似的值。这个过程不需要绝对精确,但应返回一组数量合理少的相似值,例如大约一百个元素。局部敏感哈希(Locality Sensitive Hashing,LSH)是一种用于近似最近邻搜索的有效技术,它使我们能够检索出与给定关键字最相似的数据库值。在预处理阶段,我们使用LSH对唯一的数据库值进行索引。然后,在实体检索工具中,我们查询该索引以快速找到与关键字最相似的前几个值。
用于描述的向量数据库。从数据库目录中提取语义上最相关的信息片段对于生成准确的 SQL 查询至关重要。这些目录可能内容繁多,有数百页来解释数据库中的实体及其关系,因此需要一种高效的检索方法。为了实现高效的语义相似性搜索,我们将数据库目录预处理为向量数据库。在上下文检索步骤中,我们查询这个向量数据库,以找到与当前问题最相关的信息。
有关我们的框架和预处理阶段的更详细描述,请参阅附录 A。
3.3 使文本转 SQL 系统适应现实世界的部署
我们设计了多智能体框架,以允许智能体进行灵活组合,使其能够适应各种部署、数据库设置和约束条件。在计算资源预算较高且可使用更强大的大语言模型(LLM)的环境中,CHESS可以通过利用这些资源来配置以实现最高的准确性。具体而言,可以对候选生成器(Candidate Generator,CG)和单元测试器(Unit Tester,UT)智能体进行编程,使其生成多个候选查询和单元测试,从而得到更准确的最终SQL查询(布朗等人,2024年)。如4.2.1节所示,这种增加的采样方式使系统能够优化其查询生成过程,从而提高性能。
有趣的是,与(Maamari等人,2024年)的研究结果相似,我们观察到,当模式(schema)规模相对较小且可用的大语言模型(LLM)能力较强时,引入模式选择器(Schema Selector,SS)代理可能会导致精确率 - 召回率权衡问题,从而对准确性产生负面影响。在这些情况下,不使用SS代理可能会得到更好的结果。
然而,正如我们将在4.2.2节中展示的,对于更大的模式,即使是强大的大语言模型也难以保持性能。在这种情况下,四个代理的协作对于实现更高的准确性至关重要,因为SS代理对于管理模式的复杂性变得至关重要。
最后,当计算资源有限,或者为了确保数据隐私只能使用较弱的大语言模型(如小型开源模型)时,可以对CHESS进行重新配置以提高效率。在这些场景中,我们通过排除UT代理并限制CG代理仅生成一个候选查询来简化系统。这种方法在合成可靠的SQL查询的同时,将计算开销降至最低,使CHESS适用于资源受限的环境。
4 实验与结果
4.1 数据集与指标
4.1.1 数据集
蜘蛛(Spider)。蜘蛛数据集(Yu等人,2018年)包含200个数据库模式,其中160个模式用于训练和开发,40个模式留作测试。值得注意的是,训练集、开发集和测试集中使用的数据库是不同的,且没有重叠。
鸟(BIRD)。最近推出的BIRD数据集(Li等人,2024b)有12751个独特的问题 - SQL对,涵盖95个大型数据库,总大小为 33.4 G B {33.4}\mathrm{{GB}} 33.4GB 。该数据集涵盖37个专业领域,包括区块链、曲棍球、医疗保健和教育等行业。BIRD通过整合外部知识并提供详细的数据库目录(包括列和数据库描述)来改进SQL查询生成,从而消除潜在的歧义。BIRD中的SQL查询通常比蜘蛛数据集中的查询更复杂。
子采样开发集(Subsampled Development Set,SDS)。为了便于进行消融研究、降低成本并保持BIRD开发集的分布,我们对开发集中每个数据库的10%进行了子采样,从而得到了子采样开发集,我们称之为SDS。这个SDS包含147个样本:81个简单问题、54个中等问题和12个具有挑战性的问题。为了保证可重复性,我们将SDS包含在了我们的GitHub仓库中。
合成工业级数据库模式。生产级文本转SQL系统通常在具有极大模式的真实世界数据库上运行,这些模式包含数千列,远远超出了像BIRD(Li等人,2024b)这样的学术基准的范围。正如《迷失在中间》论文(Liu等人,2024)所强调的,大语言模型(LLM)可能难以处理过长的提示,从而导致混淆。然而,最近的进展,如Gemini(团队等人,2023)和GPT - 4o(OpenAI,2024b),已经证明了无需过滤提示或排除数据库模式的任何部分就能生成准确SQL查询的能力(Maamari等人,2024)。为了评估这些模型在大规模数据库上的可扩展性,我们合成了极大的数据集以模拟真实世界的条件。这涉及合并BIRD训练集和开发集中的多个数据库,从而得到最多包含4337列的模式,这是我们实验中最大的模式。这种方法使我们能够重现大型生产级数据库的复杂性和挑战。
评估指标。在本文中,我们主要沿用以往的研究(Pourreza等人,2024年;Maamari等人,2024年;Pourreza和Rafiei,2024a),使用执行准确率作为比较指标。执行准确率(EX)通过将预测查询在特定数据库实例上执行的结果与参考查询的执行结果进行比较,来衡量SQL输出的正确性。该指标考虑到了对于给定问题,不同的有效SQL查询可能产生相同结果的情况,从而提供了细致的评估。此外,鉴于在某些场景下,大语言模型(LLM)的调用次数和提示中使用的标记数量可能相当可观,我们还报告了我们的方法所需的标记总数和大语言模型的调用次数。
4.2 根据部署约束的CHESS不同配置
在本节中,我们将讨论各种部署限制,详细说明针对每种场景如何配置CHESS(象棋),以及相应的实验和结果。首先,在第1节中,我们考虑一种计算资源充足的场景,该场景允许在推理过程中使用强大的大语言模型(LLM)进行多次调用。针对这种情况,我们在BIRD(鸟类)数据集上评估使用信息检索(IR)、代码生成(CG)和单元测试(UT)代理(记为 C H E S S ( I R , C G , U T ) {\mathrm{{CHESS}}}_{\left( IR, CG, UT\right) } CHESS(IR,CG,UT) )的CHESS的性能。接下来,在4.2.2节中,我们将解决超出BIRD数据集范围的工业规模数据库模式的挑战,在这种情况下,像Gemini - 1.5 - pro这样强大的专有模型的推理能力可能不足。为解决这一问题,我们将语义搜索(SS)代理引入团队,展示其在处理非常大的模式时的有效性。然后,为适应计算资源有限的场景,我们将单元测试(UT)代理从团队中移除,并将代码生成(CG)生成的候选数量限制为一个。这种配置标记为 C H E S S ( I R , S S , C G ) {\mathrm{{CHESS}}}_{\left( IR, SS, CG\right) } CHESS(IR,SS,CG) ,我们使用不太强大的专有模型和开源模型对其进行评估。最后,在4.2.3节中,我们进行消融研究,以评估每个组件对我们系统端到端性能的贡献。
4.2.1 高计算预算下的CHESS ( I R , C G , U T ) {}_{\left( IR, CG, UT\right) } (IR,CG,UT) (CHESS)
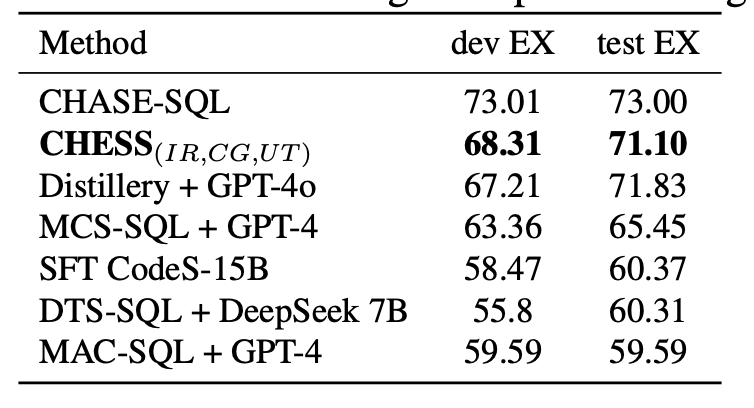
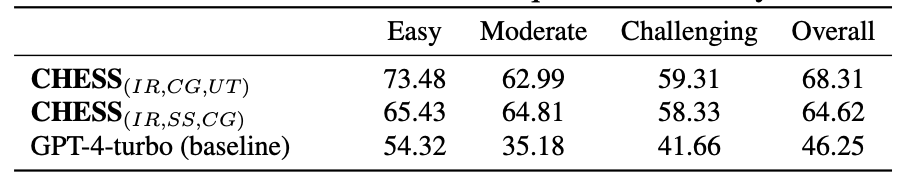
近期的研究,如MCS - SQL(Lee等人,2024年)和CHASE - SQL(Pourreza等人,2024年),通过扩展大语言模型(LLM)调用、生成大量候选SQL查询并从中选择最佳候选查询,在文本到SQL基准测试中取得了最先进的性能。遵循类似的策略,我们通过使用Gemini - 1.5 - pro模型为每个样本问题生成20个候选SQL查询,来评估我们的文本到SQL多智能体框架的性能。然后,我们创建了十个自然语言单元测试,以有效区分正确和错误的候选查询。鉴于在BIRD基准测试(Maamari等人,2024年)中的小型数据库不需要模式链接,我们在本次实验中排除了SS智能体,仅保留了IR、CG和UT智能体。我们使用Gemini - 1.5 - pro模型的框架与先前方法的性能比较见表1。如表所示,除了CHASE - SQL之外,我们的方法优于所有先前的方法,CHASE - SQL使用了专门为BIRD基准测试选择最佳候选SQL查询而微调的模型。相比之下,我们的框架无需任何微调,就超越了所有其他方法,证明了它在各个基准测试中无需特定任务优化的鲁棒性。此外,我们在两种不同的设置下评估了UT智能体的性能。在第一种设置中,一次大语言模型调用接收一个单元测试,并为所有候选查询分配分数。在第二种设置中,一次大语言模型调用接收所有单元测试,并为一个候选查询分配分数。第一种场景的结果见表1,我们在此场景中获得了68.31分。相比之下,第二种场景的得分较低,为66.78分,这凸显了在评估单元测试时让大语言模型比较候选查询的重要性。
表1. C H E S S ( I R , C G , U T ) {\mathrm{{CHESS}}}_{\left( IR, CG, UT\right) } CHESS(IR,CG,UT) 在BIRD数据集上的性能,与高计算预算的方法进行比较。
4.2.2 引入用于大型数据库模式的模式选择代理
在本节中,我们使用我们合成生成的数据集——合成工业规模数据库模式(Synthetic Industrial-scale Database Schema),来评估我们的多智能体框架在超大型模式上的性能,并分析大型提示对近期大语言模型(LLMs)性能的影响。我们使用合成数据集作为目标数据库,在BIRD开发集上使用单查询通过率(Pass@1)和五查询通过率(Pass@5)指标评估了双子座(Gemini)模型的性能。对于小于最大规模(4337)的数据库,我们在确保保留真实模式的同时随机选择列。单查询通过率衡量的是模型被允许生成单个执行准确率为1的SQL查询时的成功率,而五查询通过率衡量的是模型在五次尝试中至少生成一个正确查询的比率。我们测试了双子座1.5专业版(Gemini-1.5-pro)模型,并将结果展示在图3中,该图比较了不同模式规模下的单查询通过率和五查询通过率。结果显示,在提供确切的真实模式(即正确的列和表)的场景与提示中包含大量列的场景之间,存在11%的性能差距。随着列数量的减少,模型的性能有所提升,这凸显了模式链接对于过滤无关列和表的重要性。
模式选择代理的有效性。为了衡量我们的模式选择代理(SS代理)在处理非常大的模式时的有效性,我们重复了之前的实验,这次加入了SS代理。将SS代理应用于具有4337列的最大模式后,Pass@1和Pass@5得分分别提高到了61%和63%,与没有模式链接时的性能相比提高了2%。这表明模式链接在增强超大型数据库的查询生成方面起着关键作用。
请注意,包含SS代理的系统的Pass@1性能略优于没有任何模式链接的系统的Pass @ 5 @5 @5 ,这表明在使用的令牌方面效率提高了超过 × 5 \times 5 ×5 的同时,性能也更高。这表明对于非常大的模式,模式选择代理可以提高系统的准确性和效率。
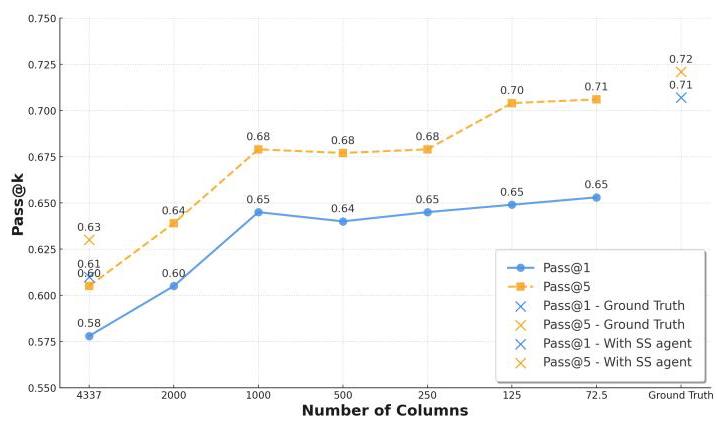
图3. Gemini - 1.5 - pro模型的文本到SQL的Pass@1和Pass@5性能与数据库中列数的关系。
4.2.3 适用于有限计算预算的CHESS ( I R , S S , C G ) {}_{\left( IR, SS, CG\right) } (IR,SS,CG) 在现实世界的部署场景中,诸如计算能力低、因预算限制无法使用强大模型,或数据隐私问题等各种限制因素,可能会使使用配备强大专有模型的高计算量方法(例如,(李等人,2024年;普尔 - 礼萨等人,2024年))变得不可行。为了适应这些情况,我们提出了一种多智能体系统的配置 CHESS ( I R , S S , C G ) {\text{CHESS}}_{\left( IR, SS, CG\right) } CHESS(IR,SS,CG) ,该配置在遵守这些限制的同时实现了高性能。
为了限制大语言模型(LLM)的调用次数,我们将用户意图(UT)代理从框架中排除,并将候选生成和修订的次数分别限制为仅1次和3次,其中候选生成和修订的次数由 G C \mathrm{{GC}} GC 控制。由于我们不能依赖多次大语言模型调用生成候选查询,因此提高传递给候选生成器的模式的效率变得至关重要。因此,模式选择器(SS)在提高效率方面起着至关重要的作用,它在候选生成之前将模式缩小到最相关的子集。此外,为了展示使用性能较弱的模型时系统的性能,我们使用较旧的专有模型(如GPT - 3.5/4 - turbo)以及开源模型(如Llama - 3 - 70B和经过微调的DeepSeek模型)进行了实验。
BIRD基准测试结果。由于BIRD基准测试的测试集不可用,我们在开发集上进行了消融实验和性能评估。我们使用1) 专有模型和2) 开源模型对我们提出的方法进行了评估。在第一种情况下,我们使用经过微调的DeepSeek Coder模型(深度探索编码器模型)来生成候选方案,使用GPT - 3.5 - turbo进行列过滤,并使用GPT - 4 - turbo进行其余的大语言模型调用。在第二种情况下,我们使用经过微调的DeepSeek Coder模型来生成候选方案,所有其他大语言模型调用由Llama - 3 - 70B处理。
如表2所示,我们使用专有模型的方法在BIRD的开发集和测试集上都实现了较高的执行准确率。我们想强调在这种配置下我们方法的效率,在这种配置中我们仅调用GPT - 4 - turbo模型6次,而其他一些方法(如MCS - SQL)大约需要进行100次大语言模型调用。
使用开源模型的CHESS(基于开源模型的文本到SQL转换系统)。在大多数工业用例中,数据隐私是首要考虑因素,这限制了专有模型的使用,如(普尔雷扎等人,2024年)、(马马里等人,2024年)和(李等人,2024年)的研究所示。对于此类情况,公司更倾向于完全在本地部署仅使用开源模型的文本到SQL系统。我们采用开源大语言模型(LLMs)的方法在所有开源方法中取得了最高性能,非常适合这些场景。
表2. C H E S S ( I R , S S , C G ) {\mathrm{{CHESS}}}_{\left( IR, SS, CG\right) } CHESS(IR,SS,CG) 在BIRD数据集上的性能,与低计算预算的方法进行比较。
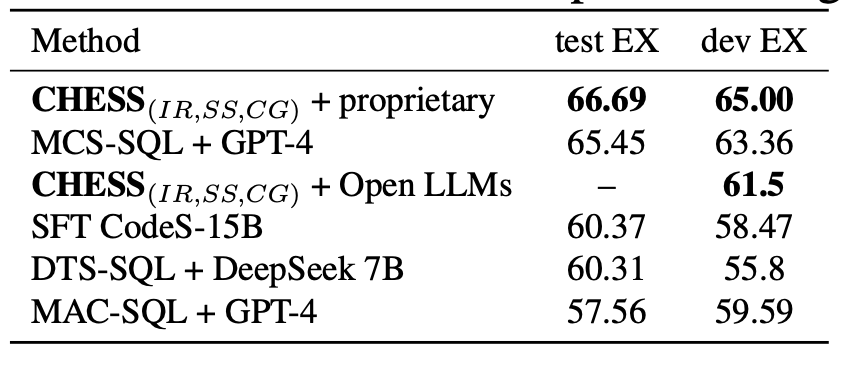
表3. C H E S S ( I R , S S , C G ) {\mathrm{{CHESS}}}_{\left( IR, SS, CG\right) } CHESS(IR,SS,CG) 在Spider测试集上的性能,与所有已发表的方法进行比较。
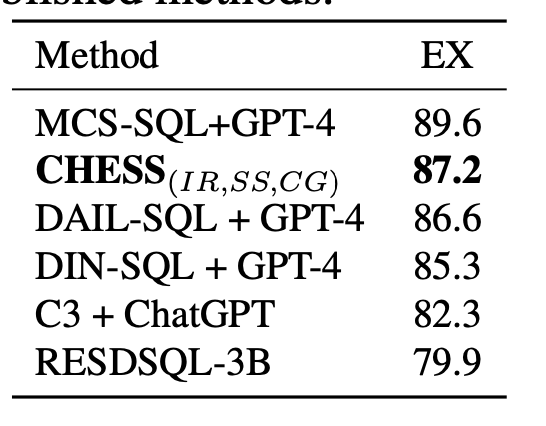
Spider测试结果。为了评估我们提出的方法在BIRD基准测试之外的泛化能力,我们在Spider测试集上对其进行了测试,而没有专门为候选生成微调新模型或修改上下文学习样本。我们采用了默认的引擎设置。我们对设置所做的唯一调整是移除了retrieve_context工具,因为Spider测试集缺少列或表的描述,而这些描述是我们方法不可或缺的部分。如表3所示,我们的方法在测试集上实现了 87.2 % {87.2}\% 87.2% 的执行准确率,在已发表的方法中排名第二。这凸显了我们的方法在无需任何修改的情况下,在不同数据库中的鲁棒性。值得注意的是,Spider测试集排行榜上表现最佳的专有(且未公开)方法是Miniseek,准确率为91.2%。
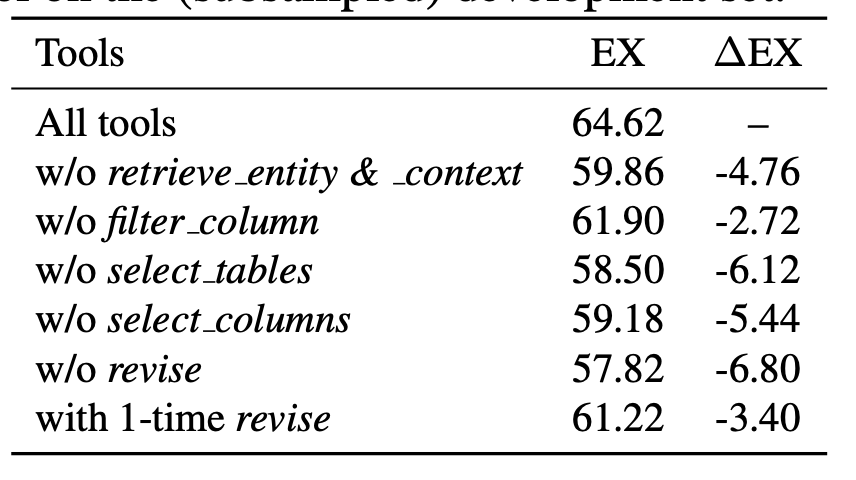
表4. 在(子采样的)开发集上移除每个工具后,该框架的执行准确率(EX)。
4.3 消融研究
表4展示了在省略不同模块或组件时的执行准确率(EX)。在没有实体和上下文检索的配置中,我们随机检索了一个示例,并包含了所有列的列描述。这种方法凸显了我们选择性检索的显著影响,其执行准确率比简单的上下文增强方法高出4.76%。此外,我们评估了移除SS代理每个工具的效果,结果表明select_tables工具最为关键,使性能提升了6.12%。该表还说明了修订工具的显著影响,有 6.80 % {6.80}\% 6.80% 的提升。增加用于自我一致性的修订样本数量会带来更高的性能提升,这与(Lee等人,2024年)的研究结果一致。
单元测试可提升性能。为评估单元测试(UT)代理在生成高质量单元测试以区分正确和错误的SQL候选语句方面的有效性,我们通过改变单元测试的数量来评估基于代理的框架的性能,并从20个候选语句中选择得分最高的候选语句。图4展示了不同数量单元测试下的性能表现。如图所示,性能随着单元测试数量的增加而提升,在进行10次测试时达到峰值。超过这一点后,性能趋于平稳,这表明额外的测试带来的回报逐渐减少。
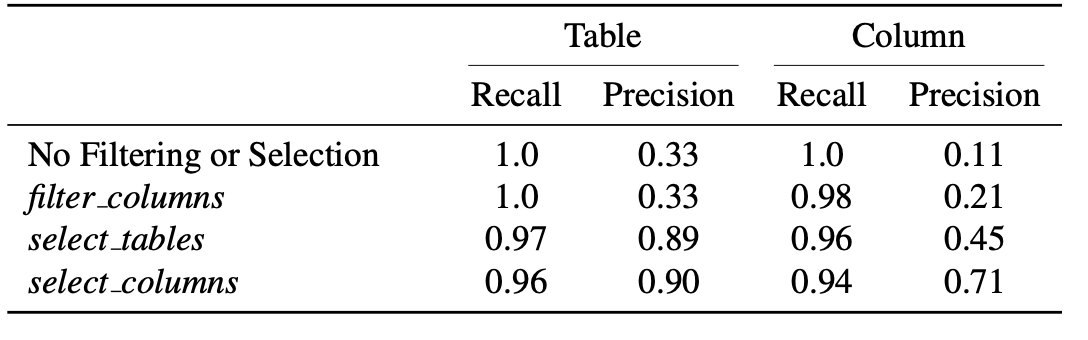
模式选择代理的评估 除了进行消融研究以评估上下文检索、模式选择和修订方法的影响外,我们还评估了它们对模型为生成最终SQL查询所识别的表和列的精确率和召回率的具体影响。精确率和召回率是通过将正确SQL查询中使用的表和列作为真实值进行比较来计算的。如表5所示,模式选择代理提高了所选表和列的精确率,而召回率仅略有下降。
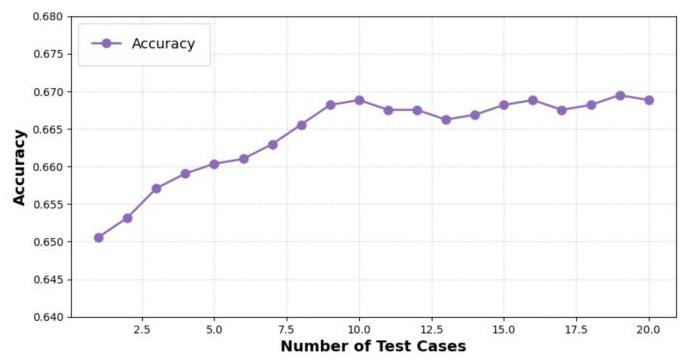
图4. CHESS在BIRD开发集上针对不同数量单元测试的文本到SQL性能。
这种高精度和高召回率的平衡使模型能够在紧凑的上下文窗口中处理最相关的信息,从而提高了SQL生成的准确性。图16展示了这一过程,其中模式选择(Schema Selection,SS)代理成功缩小了表和列的范围,选择了两个表和五列,其中包括正确SQL查询中使用的两列。有关模式选择过程的完整示例,请参阅附录E。
此外,图5展示了模式选择代理如何在每一步有效地缩小列的数量,根据问题的复杂程度而非数据库模式本身来调整剩余的列。这种方法始终将列的数量减少到约10列,通过仅关注SQL生成最相关的信息,使我们的方法具有可扩展性,适用于不同复杂程度的数据库。
表5. 模式选择代理应用每个工具(过滤列、选择表和选择列)后,对正确SQL中使用的表和列的模式项的精度和召回率进行评估。
跨不同复杂度查询的性能评估 BIRD基准测试根据所使用的SQL关键字的数量和类型,将问题 - SQL对分为三类:简单、中等和具有挑战性。在本节中,我们评估我们方法的性能:1)使用信息检索(IR)、上下文生成(CG)和通用工具(UT)代理,无计算约束的情况;2)使用信息检索(IR)、子空间搜索(SS)和上下文生成(CG)代理,计算预算有限的情况。我们将结果与BIRD论文中的原始GPT - 4基线进行比较,在该基线中,问题、证据以及包含所有表和列的完整模式会与思维链推理提示一起提供给GPT - 4。
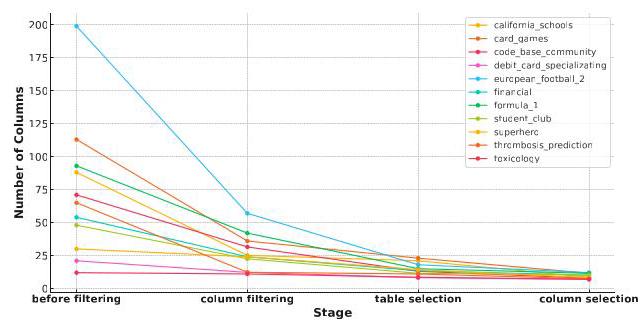
图5. 在11个BIRD开发数据库的模式选择过程的每个阶段后剩余的平均列数。初始计数显示了每个数据库中的总列数,并且无论数据库复杂度如何,模式选择代理始终将该数量减少到约10列以进行候选生成。
该分析在SDS数据集上进行,结果详情见表6。我们提出的方法在两种设置下的所有类别中都显著提高了性能。这证明了我们的多代理框架在不同难度级别和约束条件下提高性能的有效性。
表6. 在不同问题难度级别下,比较CHESS(棋类启发式搜索引擎)在两种不同设置下的性能与简单的GPT - 4基线(我们在其上下文中传递所有信息)的性能。
5 结论与局限性
在本文中,我们介绍了CHESS(原文未变),这是一个能够处理复杂的工业级数据库的多智能体框架。CHESS设计了4个专门的智能体,即信息检索器(Information Retriever)、模式选择器(Schema Selector)、候选生成器(Candidate Generator)和单元测试器(Unit Tester),以应对高效数据检索、模式剪枝、SQL查询生成和验证等关键挑战。我们进行了广泛的消融研究,以展示这些智能体及其工具的有效性。我们证明,对于大型工业级模式规模,仅依赖推理时扩展采样的方法效果会变差,而CHESS的模式选择智能体在处理少于 × 5 \times 5 ×5 个标记时仍能实现较高的准确率。我们还表明,在控制计算预算的情况下,CHESS达到了当前的最优性能。在具有挑战性的BIRD(原文未变)测试集上,CHESS的准确率达到了71.10%,与领先方法(一种专有方法)的差距在 2 % 2\% 2% 以内,同时所需的大语言模型(LLM)调用次数约减少了 83 % {83}\% 83% 。
正如实验部分所讨论的,非常需要一个广泛的文本到SQL(Structured Query Language,结构化查询语言)基准,以准确反映大规模数据库带来的挑战。在我们的论文中,我们尝试通过组合不同的数据库来实现这一目标;然而,能够访问更大的真实世界数据库将显著推动该领域的研究。此外,先前的研究(Pourreza等人,2024年)表明,微调可以提高大语言模型(Large Language Model,LLM)在查询选择方面的性能。作为未来的工作,我们计划专门针对测试用例生成和评估对模型进行微调,以进一步提高性能。


















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











