










0 从数据并行到图并行
自从 04 年 Google 公开了它的 MapReduce 之后,大家就像是发现了什么新大陆一样以极大的热情投入到新型计算框架的研发以及已有框架的优化之中。 如果要说这一系列的工作有什么共同点的话,那就是它们都致力于提供一个简单易用的上层接口,从而将底层的诸如二级存储访问、网络通讯、横向扩展、单点容错等相对来说更复杂的问题透明化,达到普通的软件开发人员只需要聚焦于上层应用的目的。 然而,在应该选择什么样的接口,以及采用何种的底层架构对它进行实现这些问题上,目前仍然处于一个众说纷纭的阶段。 虽然 Spark 系列框架致力于以 RDD 为基础一统天下的愿景值得赞叹,但由于效率上的问题,目前的主流观点仍然认为应该针对数据并行计算、图计算、流计算、和矩阵计算等不同类别的应用分别使用不同的架构与之对应。

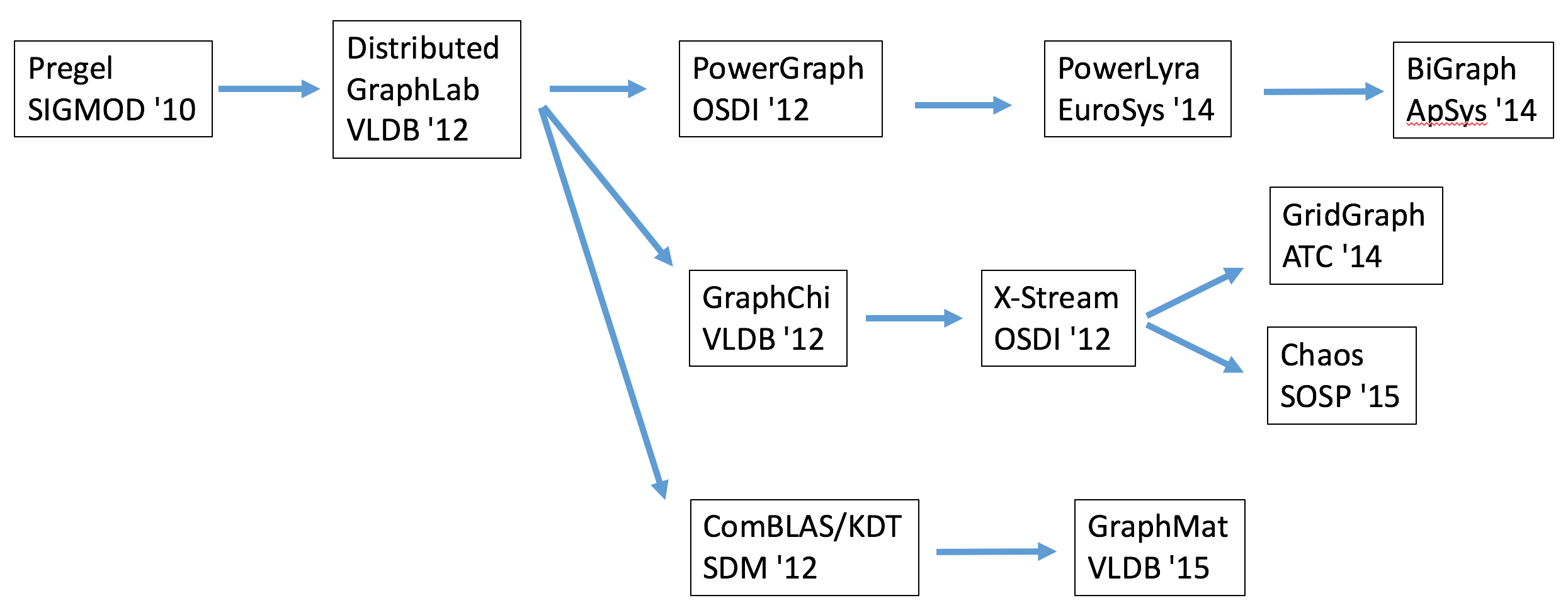
以本文讨论的图计算为例,由于图数据自身具有结构不规则的特点,如果简单地像 MapReduce 那样用点或边的 hash 值对其进行随机划分的话很容易造成负载的不均匀,以及极为庞大的通讯量等诸多问题。 同时,由于图算法在计算时数据局部性不好的特点,如果不进行特定的优化的话也经常会使得系统的 cache 利用率不高,从而极大地影响效率。 针对这一类的问题,许许多多的图计算框架被提出和实现,而它们又分别针对不同的更小规模的应用类型。 这一状况无疑造成了一定程度的混乱。 因此,本文将分别从“同步 V.S. 异步”,“图的划分”,“二级存储的利用”,以及“计算引擎的优化”等四个重要的 design choice 展开,并将依次讨论它们各自的发展过程。 总体来说,本系列将主要讨论下图所示的 11 篇论文。
1 一切的起源:Pregel
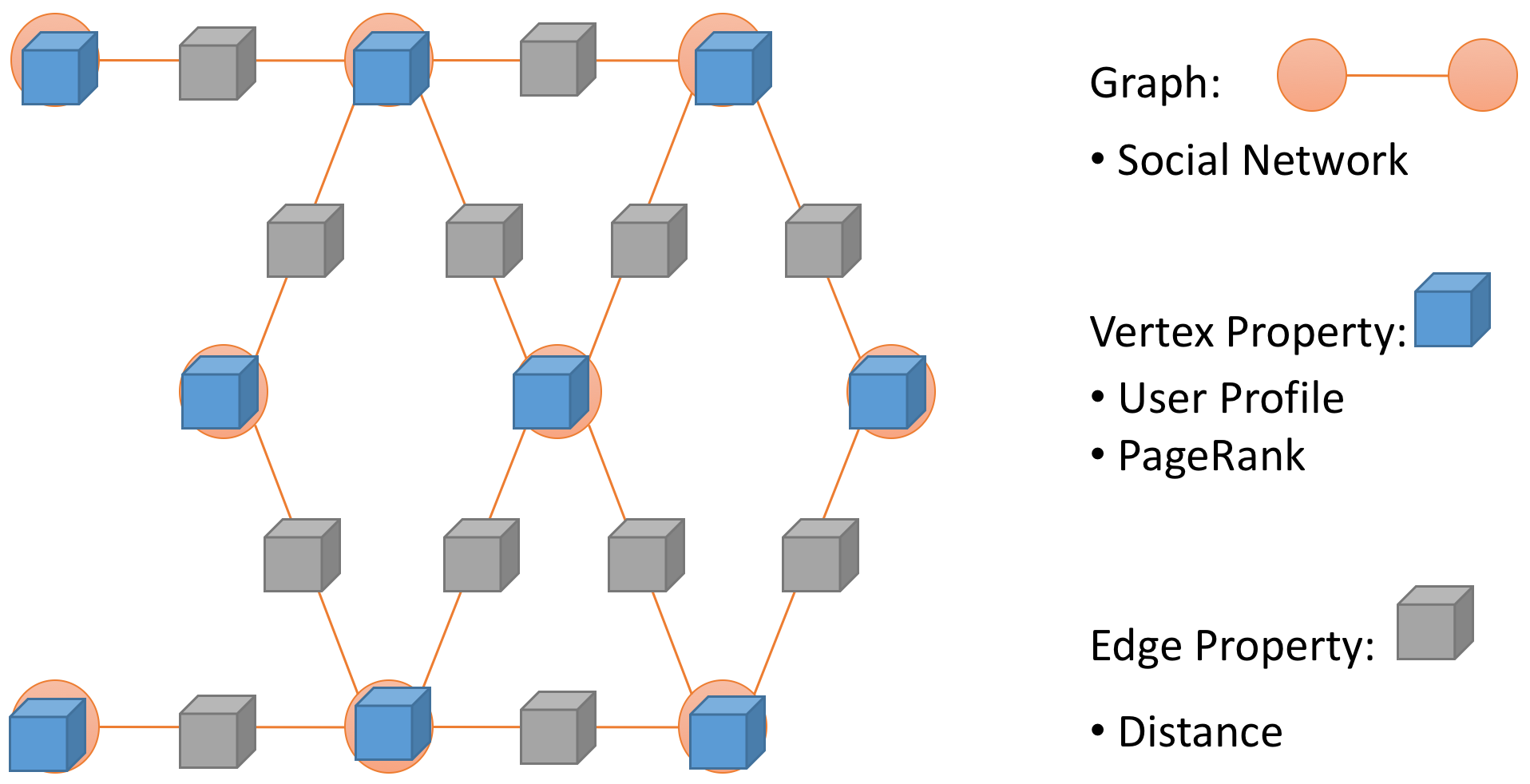
虽然图计算本身的历史比计算机的还要长,但如果说要找一个现代图计算框架的起源的话,由 Google 在 10 年的 SIGMOD 上公开的 Pregel 系统应该是众望所归的。 其定义的数据模型 Data Graph 和编程模型 Vertex-centric Programming 目前仍然是各个后续系统参考和借鉴的对象。 具体来说,所谓数据模型就是定义了如何将一个具体的问题表示成图的形式的方法,而在 Pregel 系统中所有处理的数据都必须要存放在一张 Data Graph 里。 虽然下图并没有明确地标示出来,Data Graph 为一张有向图,其在各个点之间的拓扑关系(Topology)的基础上还允许用户为每一个点或者边定义属性(Property)。 比如在最常见的 PageRank 算法的例子中,各个点的权值一般就是它的 PageRank 值,而边的权值则可以被忽略。
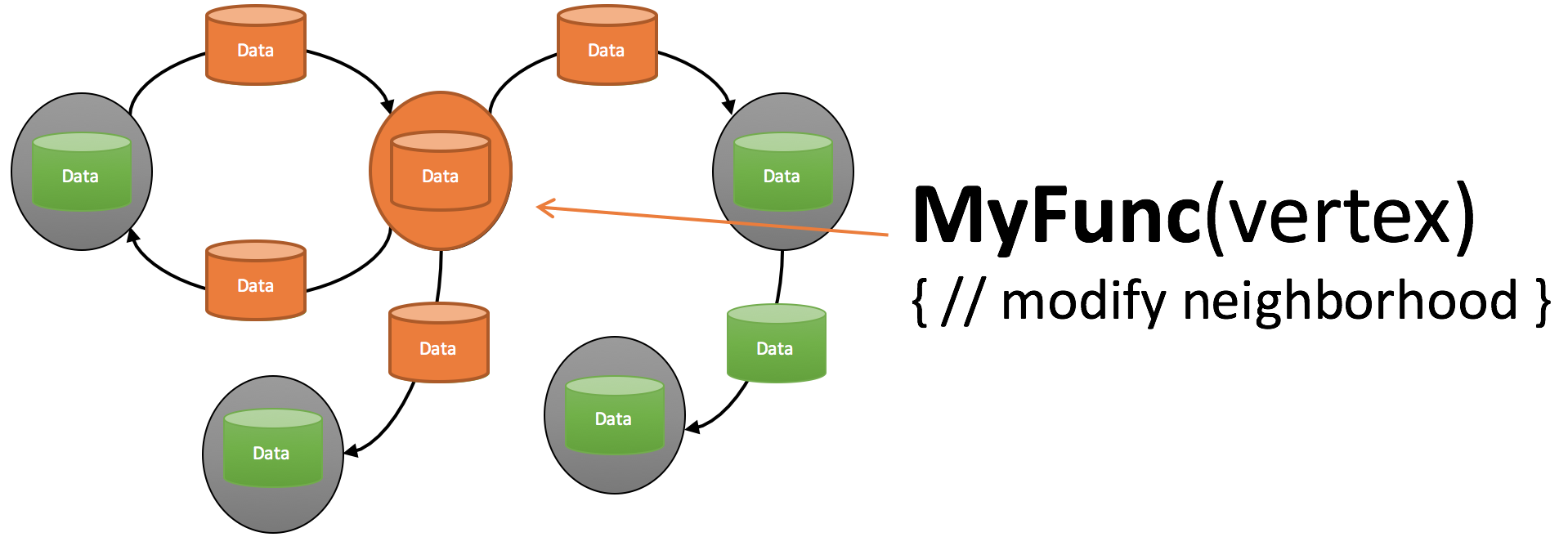
在这一数据模型的基础上,用户只需要通过 Pregel 提供的以点为中心的编程接口(Vertex-centric Programming)进行编程就可以实现各种算法,而无需考虑底层的通讯等具体实现。 一般来说,这一类的编程方法被称之为“Think as a Vertex”。 它要求用户所实现的 Vertex Program 的操作范围仅为对应点的临域(即自己的点权和所有相连的边权),而且只被允许读取入边上的值和修改出边上的值。 这些限制的主要目的在于方便并行的实现,理论上只要没有操作到共享的数据对应两个点的 Vertex Program 就可以并行地执行。 更进一步的,Pregel 的计算系统遵循所谓 Bulk Synchronous Parallell(BSP)的计算模式,即“每一次计算由一系列 superstep 组成,每一个 superstep 又可以分成本地并发计算、全局通信和同步三个步骤;在本地计算时不产生任何通讯,全局通讯时也不进行任何计算”。 这种计算模式的好处在于其非常的简单,基本不需要做任何的并发控制,同时也便于实现基于 checkpoint 的容错机制。 同时缺点就在于同步的开销大,如果负债不均衡的话很容易得到次佳的执行效率。 在 Pregel 系统中,每一个 superstep 的本地并发计算阶段就是各个节点分别执行 Vertex Program 的过程,而全局通信阶段则负责把产生的消息(附带在出边的边权上)送达相应的计算节点。 由于 Pregel 采用的是基于点的图划分方法(即将 Data Graph 中点均匀的划分给不同的机器,每个点与它所有的邻边都存储在一起),每一条被分割的边(即这条边的的两个点被分到了不同的机器上)会产生一次远程通讯。
2 同步 V.S. 异步
上述的 Pregel 系统结构十分简单并且行之有效,但仍然存在很多的问题。 其中一个就是由于 Pregel 的同步计算模式要求运算速度快的节点每一个 superstep 都必须要等待运行速度慢(或负载更高)的节点,从而造成了大量的浪费。 特别是在诸如 BFS 的一类问题中,随着计算的运行可能每一个 superstep 只有对应一部分的点的 Vertex Program 需要被执行,而且每次需要被执行的点集合都是不同的。 这一状况无疑加重了系统可能的浪费情况。 为了解决这一问题,以 GraphLab 为代表的一系列系统都支持被称之为“异步”的计算模式。 在异步模式下不存在 superstep 的概念,每一个计算节点各自维护一个调度队列包含可以被执行的点。 其保证 1)每一个点 Vertex Program 只有当其入边的值被修改了或者被显示地通知了的时候才会被执行;以及 2)如果两个点间有边相连,那么它们不会被同时并行地执行。 前者减少了不必要的开销而后者则保证了不会产生数据读写上的冲突。 在 GraphLab 中,上述的冲突控制是通过在每一个点的 Vertex Program 执行前先对所有相邻边加上锁实现的。
一般来说同步和异步的执行模式各有优劣,异步的模式可以减少负债不均衡带来的性能损失,而在负债基本均衡的情况下,同步的模式由于其更小的调度开销速度更快。 更进一步的,在特定的应用中,有可能在不同的执行阶段其最佳的执行模式也是不同的。 比如说上面提到的 BFS 的例子,在执行的初期和末期,由于需要 active 的点较少异步模式更加合适。 相对的,在 BFS 执行的中期,有可能就是同步模式的执行速度更快。 为了利用这两方的优点,上海交通大学陈海波老师组在 PPoPP '15 上发表的论文“SYNC or ASYNC: Time to Fuse for Distributed Graph-parallel Computation”就提出了一种基于预测的智能切换方法,达到了最高 73% 的加速。
3 图的划分
除了同步和异步的计算模型,在分布式环境下另外一个甚至更加重要的问题就是如何对图进行划分。 早期的 Pregel 和 GraphLab 等系统采用的都是上面提到的基于点的划分方法(Vertex-based),由于被分割的是边,有时也称之为 edge-cut(还有叫 1D partitioning 的)。 这种划分在各个点所相邻的边数比较均匀的时候是一个还算可以接受的办法,但问题在于,根据调研实际图计算中常用的图都满足 power law,即存在一定数量的点占据了绝大数量的边(如下图所示)。
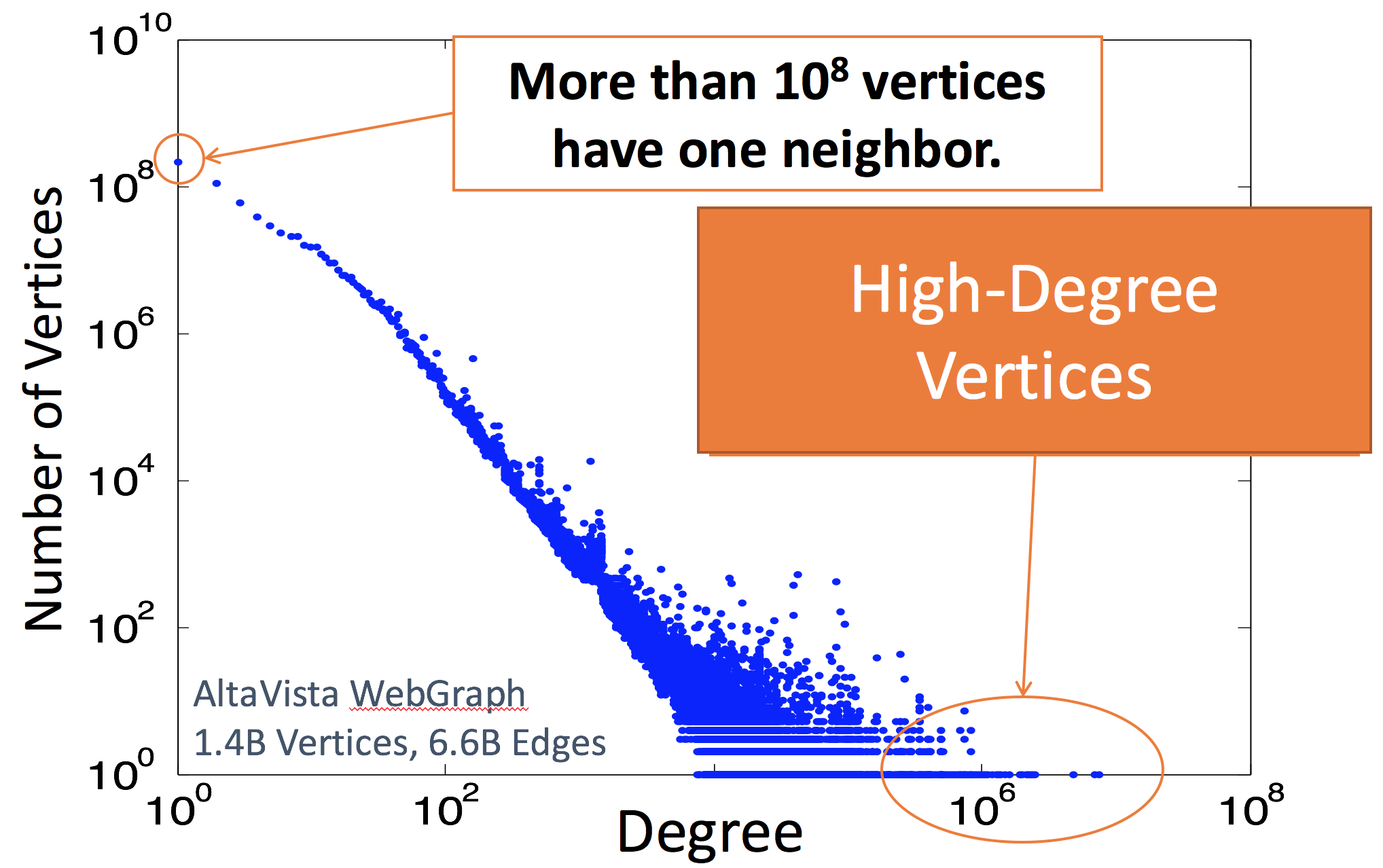
在这一情况下 1D 的划分方式就很容易产生极大的负债不均衡,因此 CMU 的研究人员在 2012 年的 OSDI 上公开了 PowerGraph,其中提出了基于边的划分方法(Edge-based,vertex-cut,2D)。 简单地说,2D 的划分方法就是将图中的边(而不是点)均分给各个计算节点从而达到负载均衡的目的(因为计算开销一般是和边数成正比的)。 同时,由于那些度数非常高的点在 2D 情况下可以被划分给多个节点,它们的计算可以被并行化。
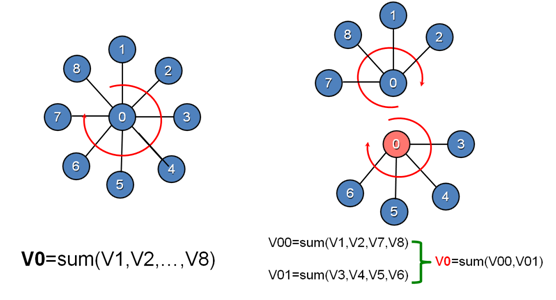
为了达到上述的目的,最原始的 Vertex Program 显然是不合适的,因为它要求一次就将与一个点相关的所有计算都完成。 因此,PowerGraph 提出了一种与 Vertex Program 类似的计算模型 GAS。 GAS 和 Vertex Program 一样都满足每个点相关的计算只访问其邻域的局部特性,但 GAS 将 Vertex Program 的过程明确地分割成了 Gather,Apply,和 Scatter 三个步骤,并通过强制要求 Gather 阶段对每一条边的结果进行聚合时的操作必须满足交换律和结合律的方式使得上图所示的并行化可以实现。 鉴于 GAS 的具体内容已经有太多等文章予以介绍,这里我就不再赘述。 如果不清楚的话建议参考这篇博客(需要注意的是,这篇博客将 PowerGraph 等价为了 GraphLab,因为事实上 PowerGraph 也被称之为 GraphLab 2.0)。
我们可以看到,PowerGraph 的 2D 划分方法最大的优点就在于它将拥有极大度数的那些 power vertex 的计算也并行化了,从而降低了可能的负债不均衡。 不过如果我们只是简单的利用边的 hash 值将它们平均的划分给各个节点的话,依然有可能产生巨大的通讯量。 具体来说,在 2D 划分方法中,如果与一个点相关的边被划分给了 X 个不同的节点,那么这个点在实际的系统中就需要维护包括一个 master 和 X-1 个 replica 在内的 X 份数据。 同时,每一次 GAS 操作时 master 都必须收集相应的 X-1 个 replica 的 partial-gather 结果并将最终计算后得到的值同步给它们。 由此可见,在 2D 划分方法下通讯量的大小是和 replica 的数量成正比的。 为了减少 replica 的数量,PowerGraph 以及随后的一些论文中都提出了各种各样的方法,然而它们经常难以在划分速度和划分结果这两个方面都达到一个很好的结果。 在此基础上,EuroSys '14 上的论文“PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs”提出了 hybrid-cut,其通过区分对待高度数的节点和低度数的节点达成了一个很好的结果,从而获得了那年 EuroSys 的 Best Paper Award。
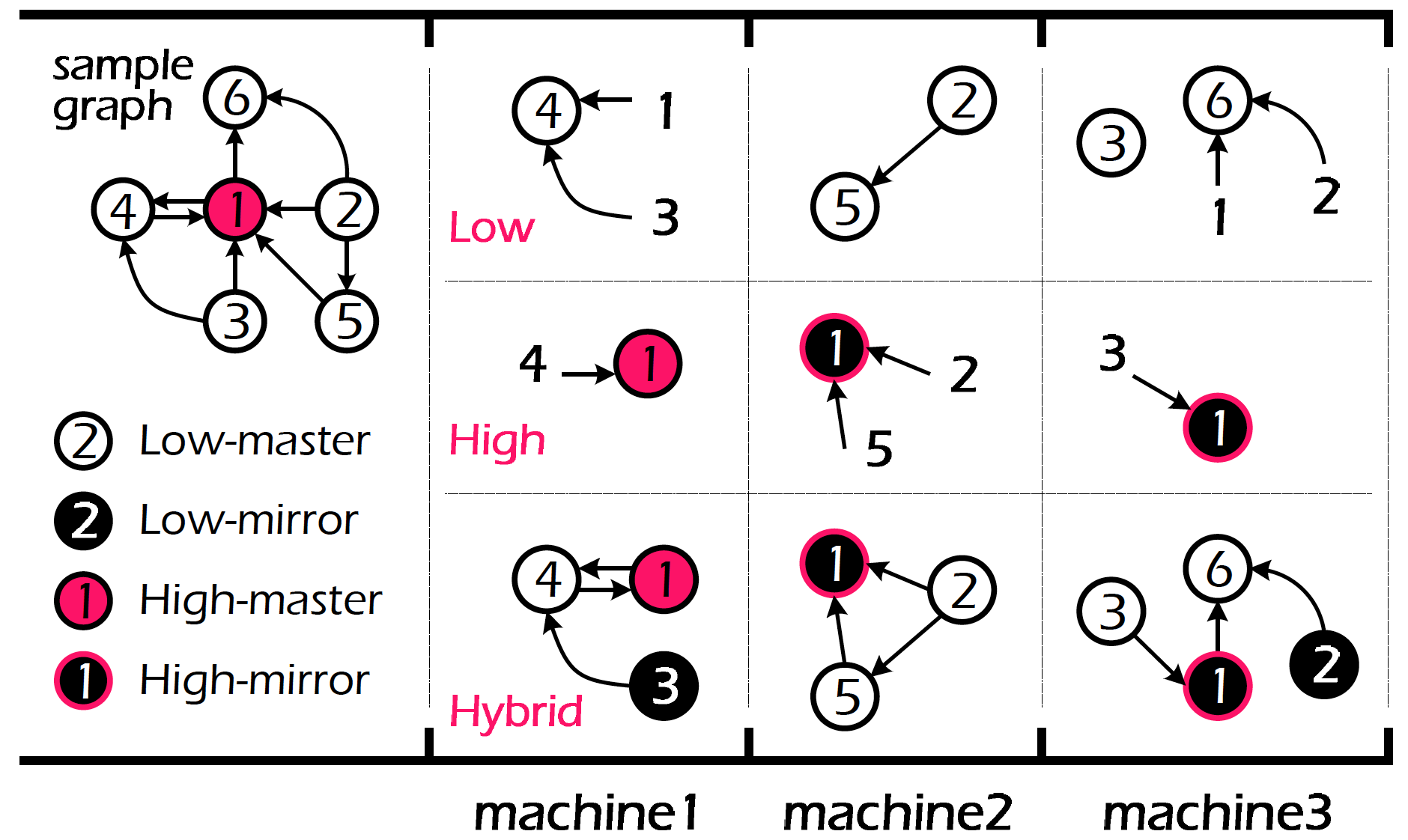
从上图可以看到,hybrid-cut 的方法其实很简单,当一条边的终点度数小于阈值(上图中为 3,但一般设为 100~200)时则将这条边按其终点的 hash 分配,反之则按源点的 hash 分配。 上图中除 1 以外的所有点入度都小于阈值,所以它们被均匀分配给三个计算节点,并附带其所有入边。 相对的,对于高度数的节点 1,它的 4 条入边被均分给了各个计算节点。 这样做的依据也很简单,可以概括为“度数大的点数量稀少且很难保证其 replica 的数量,因此我们干脆优先保证数量众多的度数小的点不存在 replica”。 简单地说,hybrid-cut 可以被看成是 1D 和 2D 划分的混合(对度数小的点用 1D,大的用 2D)。
P.S. 随后他们还在 ApSys '14 上公开了一种针对于二分图的划分方法,同样的简单有效。详情可参考“Bipartite-oriented Distributed Graph Partitioning for Big Learning”。















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









