






今天在机器学习预测全家桶中继续添加关于优化CNN-GRU-Attention模型预测的代码。
本期代码主要功能为:采用冠豪猪算法优化CNN-GRU-Attention模型的四个参数,分别是学习率,卷积核个数,GRU的神经元个数,自注意力机制的键值数。并进行了优化前后的结果比较。
冠豪猪算法是2023年12月份发表的一个智能优化算法,参考文献如下:
Abdel-Basset M, Mohamed R, Abouhawwash M. Crested Porcupine Optimizer: A new nature-inspired metaheuristic[J]. Knowledge-Based Systems, 2023: 111257.
CNN-GRU神经网络模型介绍
CNN网络作为一种前馈式神经网络,一维-CNN(Cov1D)能够提取时间序列组成的数据矩阵的相应特征。本文在此选用窗宽为s的定时间窗以步长1截取数据矩阵,使用双层Conv1D卷积层对所选取矩阵进行特征向量提取,为了更好地克服传统RNN所普遍存在的梯度消失的问题,采用门控循环单元神经网络(GRU)作为处理CNN所得特征向量的点预测算法。GRU是LSTM网络的一个简化变体,属于门控循环神经网络家族。GRU中的更新门是由LSTM网络中的遗忘门和输入门合并而成,模型架构更为简单,在保证模型预测精度的同时减少了计算量和训练时间。LSTM有输出门,遗忘门和输出门,而GRU则只包含更新门和重置门,成少了参数的训练。更新门控制前一时刻的状态信息保留到当前状态中的程度,值越大表示前一时刻的状态信息保留越多。重置门控制当前状态与先前的信息结合的程度,值越小说明忽略的信息越多。
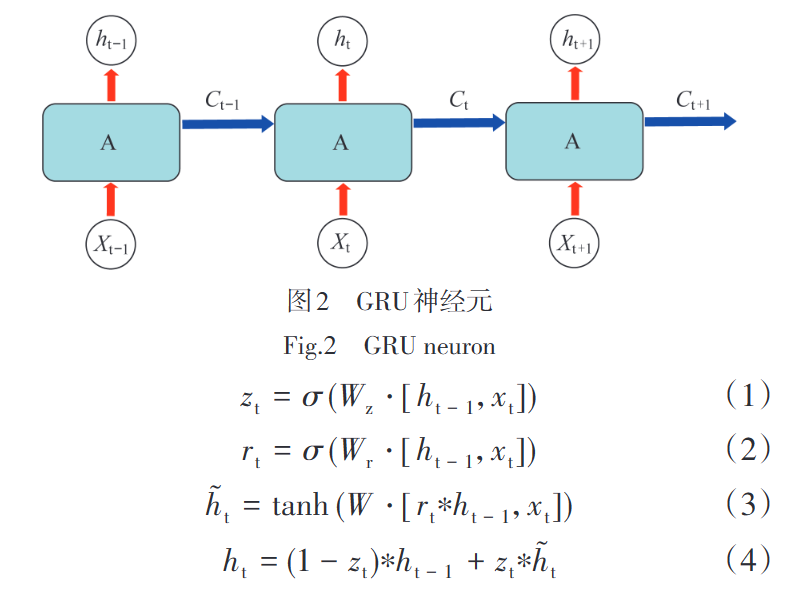
有关模型的介绍,本文就不再细讲。具体可以参考文献:
王雅兰,田野,杨丽华.基于DA-CNNGRU混合神经网络的超短期风电场功率预测方法[J].湖北电力,2021,45(03):23-28.DOI:10.19308/j.hep.2021.03.00
CNN-GRU-Attention网络模型搭建
本次搭建的模型如下:
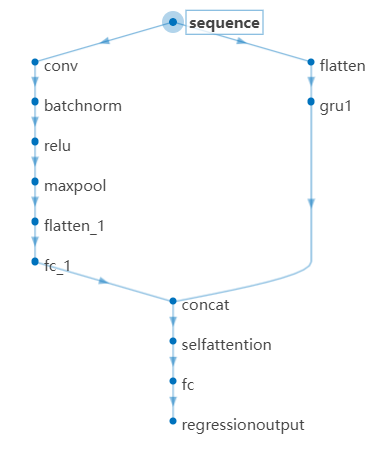
具体的参数变量如下:
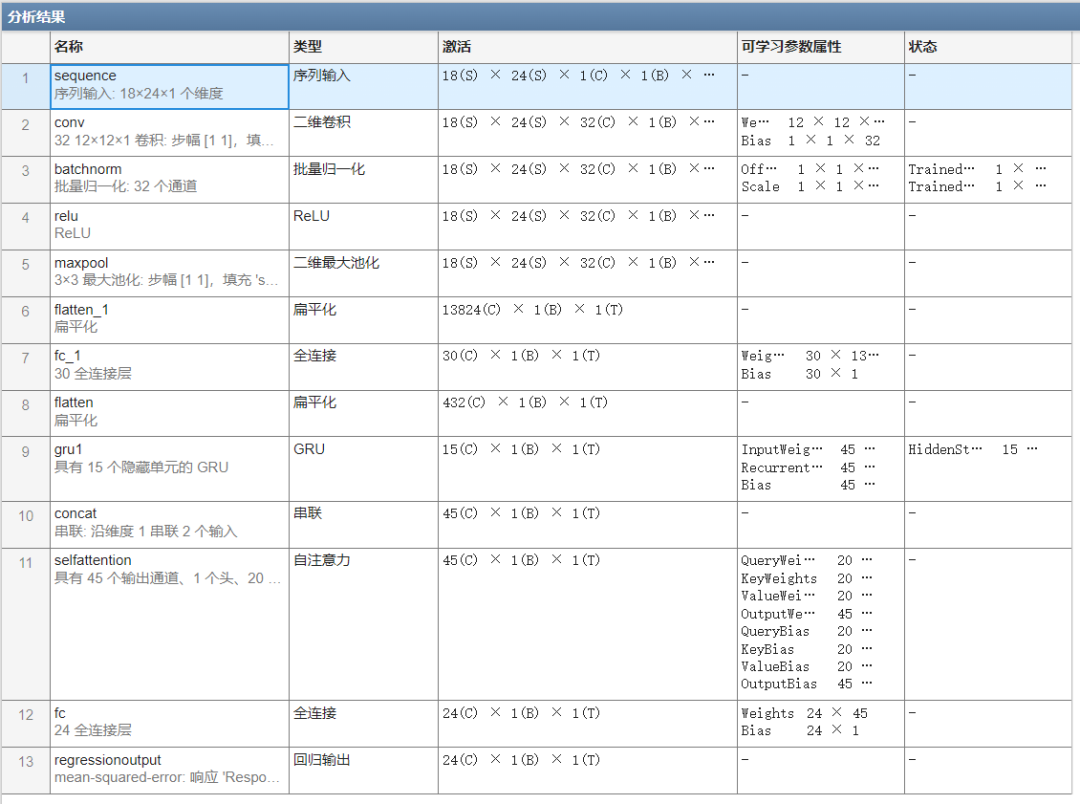
数据准备
数据共包含18个特征,一个小时采样一次,一天共24个样本点,采用前一天(24*18)数据特征去预测后一天(24*1)。

结果展示

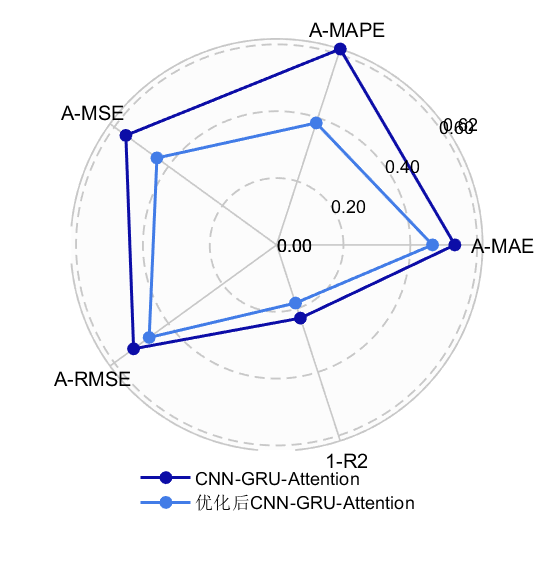




可以看到,优化后,CNN-GRU-ATTENTION的预测精度提升了很多!
后台私信获取代码。点击下方卡片获取更多代码!
















 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











