






差异化创意搜索(DCS)算法是一种极具创新的元启发式优化方法,该方法采用差异化知识获取和创造性现实主义策略来解决复杂的优化问题。DCS通过数学建模和实施,有效地在广阔的搜索空间中进行优化。通过与近年来提出的10种其他元启发式算法的比较分析,DCS显示出其在解决复杂优化问题方面的高效能力,具有强大的进化能力、快速的搜索速度和出色的寻优能力。该成果于2024年发表在计算机领域SCI一区期刊Expert Systems with Applications上。

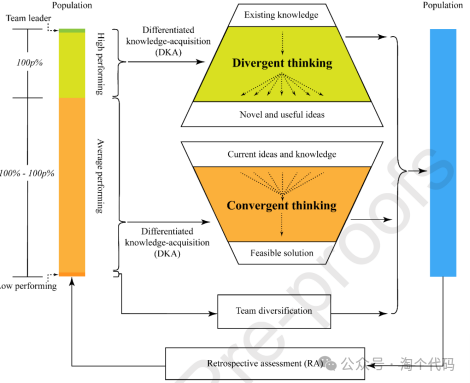
差异化创造性搜索(DCS)是一种突破性的优化算法,它彻底改变了复杂环境中的传统决策系统。与传统的差分进化方法不同,DCS将独特的知识获取过程与创造性现实主义范式相结合,从而改变了优化策略。DCS的主要目标是通过采用新提出的双战略方法来提高决策效率,该方法在基于团队的框架内平衡发散和收敛思维。该方法包括发散和收敛思维的迭代循环,由差异化的知识获取过程和回顾性评估支持。利用差异化知识获取和创造性现实主义的概念,我们提出了一个创新的差异化创造性搜索(DCS)优化模型,如下图所示。
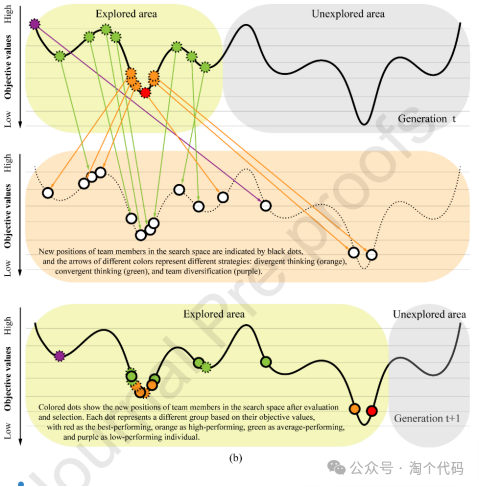
发散思维和收敛思维的活动如下图所示。高成就者擅长创造多样化的解决方案,探索不同的地区,以防止过早地解决次优解决方案。相反,表现一般的个体擅长在有希望的地区改进解决方案。虚线圈表示第t次迭代中的团队成员。箭头颜色表示所采用的策略:发散思维(橙色),收敛思维(绿色)和团队多样化(紫色)。黑色点表示策略实施后搜索空间中的试验解。(b)圆点表示考绩后的个人职位,根据其客观价值用颜色编码。红色代表表现最好的,橙色代表表现优秀的,绿色代表表现一般的,紫色代表表现不佳的。实线圆圈表示获胜的试验团队成员,虚线圆圈表示成功的原始团队成员。
1、算法原理
(1)方案初始化
在DCS中,优化过程从一组候选解决方案(团队成员)X开始,这些候选解决方案在优化问题的上限UB和下限LB之间随机生成。团队X在每次迭代中,获得的最佳解被认为是近似最优解。团队介绍如下:
其中,Xi=[xi,1 xi,2...xi,D]表示在第i行的第i个候选解,Xi,d表示Xi的第d个位置(维数)的元素;NP表示候选解决方案的数量(称为总体大小),D表示优化问题的维度。Xi的每个元素由下式随机生成。
其中U(0,1)表示区间(0,1)上的均匀分布,LBd和UBd分别表示优化问题规定的第d维的下界和上界。
初始化后,对每个Xi进行评估,得到其目标值或适应度值。随后,按X中的个体按照客观价值升序进行排序,较低的指数表示较好的性能。每一代人都是从表现最好的人开始,最后是表现最差的人。排序后的X,s与个体对应其等级;较低的秩表示较高的秩。当一个更优秀的人出现时,最优秀的人就会被更新。
(2)差异化知识获取(DKA)
DKA区别于DE交叉主要是由于其基本概念,植根于人类知识获取的不同潜力,这一概念更类似于自然过程,而不是DE中体现的随机原则。
对一些人来说,新知识可能会在某些方面带来比其他方面更大的变化。对于其他人来说,变化可能均匀地分布在所有维度上。这种可变性使学习成为每个人的独特体验,即使他们知识的整体维度保持不变。
数学公式中,参数ni,t为个体在第t次迭代时的量化知识获取率(qKR)。计算公式如下:
如上所述,符号[∙]代表一种表示将给定值四舍五入到最接近的整数的符号,其中,φ是个体在第t次迭代时的变量的变量的系数值,其计算方法如下:
其中,φi,t是个体在第t次迭代时的变量φ的值。Ri,t是第i个个体在第t次迭代开始时的排名。
φ系数是衡量一个人的知识不完善程度的定量决定因素,这个术语指的是与他人相比,一个人在理解、经验或信息方面的缺陷或不完整。φ系数随知识差距的大小而变化;值越高,意味着知识差距越大,表明个人更需要学习、吸收和整合新的知识或经验。反之,φ值越小,知识不完善程度越小,说明个人的知识基础更全面、更扎实。φ系数可以突出需要改进的领域,确定学习需求,甚至指导有针对性的干预措施,以增强个人解决问题的能力。
DKA过程对每个个体Xi的作用可以使用下式来执行:
式中vi,d为试验成员的第d个位置(维数)上的元素,Vi,t为第t次迭代的试验成员。其中,xid表示Xi中第d个位置(维度)的元素。U(0,1)表示区间(0,1)上的均匀分布。ni,t表示个体在第t次迭代时的量化知识获取率(qKR)。jrand是一个从1到D之间随机选择的整数,并为每个样本生成一次。
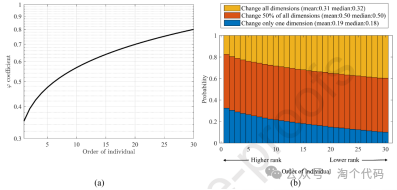
图5(a)给出了DCS算法中个体的阶数与变量的关系。(b)差别化知识获取策略根据个人的能力和表现水平,将个人随机分为三类,目的是为每个人量身定制知识修改的程度。每个人通常都会经历一半的变化。这些变化在一个或所有方面的程度取决于个人的表现;与那些表现较好的人相比,表现较差的人更需要吸收新的知识或经验。
(3)收敛思维
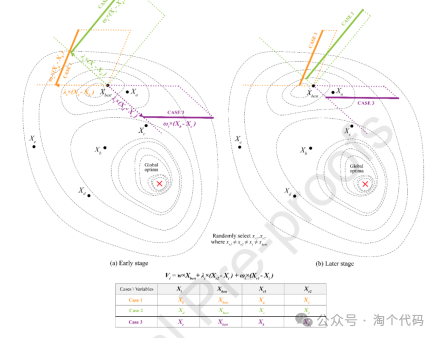
该策略依赖于顶级执行者的知识库,并结合了来自两个不同团队成员的随机贡献,这是由当前个人带来的。因此,它在生成的解决方案中促进了多样性和收敛性。这种方法反映了不同团队之间的相互作用,如图所示。
DE策略由下式表示。术语重组过程的结果是一种新的形式,可以表示为:
从收敛思维中汲取灵感,Xi通过整合团队成员Xr1和Xr2提供的信息,对团队领导者的知识Xbest进行细化。因此,DE策略可以重新表述为:
这种新的广义形式引入了三个不同的系数w,λt和ωi,t,每个系数都为当前向量与随机向量之间的差异提供了不同的含义和作用。
权重因子w调节最佳向量(Xbest)的影响。它的默认值是1,但不同的值会影响试验成员对团队领导的知识的行为。如果w不是一个,成员可能会偏离领导者的战略,采用创新的方法。这种灵活性鼓励多样化和创造性的想法。
λt是个体在第t次迭代时的计算阻尼系数,公式如下:
其中,NFEt表示在时间t的函数求值的当前数量,NFEmax并且表示函数求值的最大数量。
DCS的伪代码如下图所示。

2、结果展示

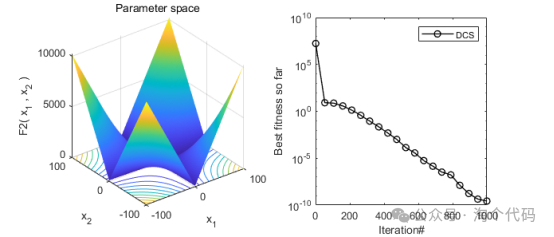
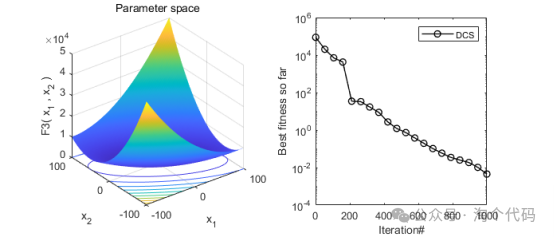
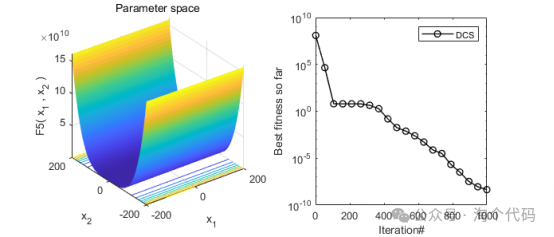
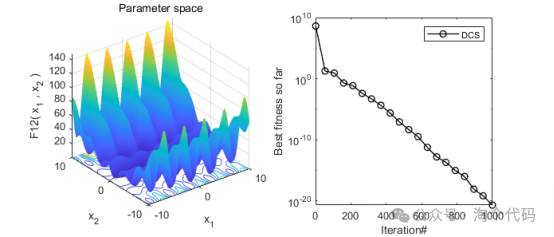
3、MATLAB核心代码
% % Differentiated Creative Search (DCS)
% CITATION:
% Duankhan P., Sunat K., Chiewchanwattana S., and Nasa-ngium P. "The Differentiated Creative Search (DCS): Leveraging Differentiated Knowledge-acquisition and Creative Realism
% to Address Complex Optimization Problems". (Accepted for publication in Expert Systems with Applications)
%
function [best_cost,best_x,convergence_curve,cul_solution,cul_nfe] = DCS(search_agent_no,max_nfe,lb,ub,dim,fobj)
%disp('DCS is now tackling your problem');
rng(sum(100*clock));
% Parameters
NP = search_agent_no;
D = dim;
lb = lb.*ones(1,dim);
ub = ub.*ones(1,dim);
L = lb;
U = ub;
next_pos = zeros(NP,D);
new_pos = zeros(NP,D);
max_itr = round(max_nfe/NP);
convergence_curve = zeros(1,max_itr);
eta_qKR = zeros(1,NP);
new_fitness = zeros(NP,1);
% Evaluation settings
eval_setting.case = fobj;
eval_setting.lb = L;
eval_setting.ub = U;
eval_setting.dim = dim;
cul_solution = [];
cul_nfe = [];
% Golden ratio
golden_ratio = 2/(1 + sqrt(5));
% High-performing individuals
ngS = max(6,round(NP * (golden_ratio/3)));
% Initialize the population
pos = zeros(NP,D);
for i = 1:NP
pos(i,:) = L + rand(1,D) .* (U - L);
end
% Initialize fitness values
fitness = zeros(NP,1);
for i = 1:NP
feasible_sol = FeasibleFunction(pos(i,:),eval_setting);
[fitness(i,1)] = feval(fobj,feasible_sol);
pos(i,:) = feasible_sol;
end
% Generation
nfe = 0;
itr = 1;
pc = 0.5;
% Best solution
best_fitness = min(fitness);
% Ranking-based self-improvement
phi_qKR = 0.25 + 0.55 * ((0 + ((1:NP)/NP)) .^ 0.5);
while nfe < max_nfe
% Sort population by fitness values
[pos, fitness, ~] = PopSort(pos,fitness);
% Reset
bestInd = 1;
% Compute social impact factor
lamda_t = 0.1 + (0.518 * ((1-(nfe/max_nfe)^0.5)));
for i = 1:NP
% Compute differentiated knowledge-acquisition rate
eta_qKR(i) = (round(rand * phi_qKR(i)) + (rand <= phi_qKR(i)))/2;
jrand = floor(D * rand + 1);
next_pos(i,:) = pos(i,:);
if i == NP && rand < pc
% Low-performing
next_pos(i,:) = L + rand * (U - L);
elseif i <= ngS
% High-performing
while true, r1 = round(NP * rand + 0.5); if r1 ~= i && r1 ~= bestInd, break, end, end
for d = 1:D
if rand <= eta_qKR(i) || d == jrand
next_pos(i,d) = pos(r1,d) + LnF3(golden_ratio,0.05,1,1);
end
end
else
% Average-performing
while true, r1 = round(NP * rand + 0.5); if r1 ~= i && r1 ~= bestInd, break, end, end
while true, r2 = ngS + round((NP - ngS) * rand + 0.5); if r2 ~= i && r2 ~= bestInd && r2 ~= r1, break, end, end
% Compute learning ability
omega_it = rand;
for d = 1:D
if rand <= eta_qKR(i) || d == jrand
next_pos(i,d) = pos(bestInd,d) + ((pos(r2,d) - pos(i,d)) * lamda_t) + ((pos(r1,d) - pos(i,d)) * omega_it);
end
end
end
% Boundary
next_pos(i,:) = boundConstraint(next_pos(i,:),pos(i,:),[lb; ub]);
feasible_sol = FeasibleFunction(next_pos(i,:),eval_setting);
[new_fitness(i,1)] = feval(fobj,feasible_sol);
new_pos(i,:) = feasible_sol;
if new_fitness(i,1) <= fitness(i,1)
pos(i,:) = new_pos(i,:);
fitness(i,1) = new_fitness(i,1);
if new_fitness(i,1) < best_fitness
best_fitness = new_fitness(i,1);
bestInd = i;
end
end
end
nfe = nfe + 1;
best_x = pos(bestInd,:);
best_cost = best_fitness;
convergence_curve(itr) = best_fitness;
itr = itr + 1;
cul_solution = [cul_solution best_x];
cul_nfe = [cul_nfe nfe];
end
end
function [sorted_population, sorted_fitness, sorted_index] = PopSort(input_pop,input_fitness)
[sorted_fitness, sorted_index] = sort(input_fitness,1,'ascend');
sorted_population = input_pop(sorted_index,:);
end
function Y = LnF3(alpha, sigma, m, n)
Z = laplacernd(m, n);
Z = sign(rand(m,n)-0.5) .* Z;
U = rand(m, n);
R = sin(0.5*pi*alpha) .* tan(0.5*pi*(1-alpha*U)) - cos(0.5*pi*alpha);
Y = sigma * Z .* (R) .^ (1/alpha);
end
function x = laplacernd(m, n)
u1 = rand(m, n);
u2 = rand(m, n);
x = log(u1./u2);
end
function vi = boundConstraint(vi, pop, lu)
[NP, D] = size(pop); % the population size and the problem's dimension
% check the lower bound
xl = repmat(lu(1, :), NP, 1);
pos = vi < xl;
vi(pos) = (pop(pos) + xl(pos)) / 2;
% check the upper bound
xu = repmat(lu(2, :), NP, 1);
pos = vi > xu;
vi(pos) = (pop(pos) + xu(pos)) / 2;
end参考文献
[1]Duankhan P, Sunat K, Chiewchanwattana S, et al. The Differentiated Creative search (DCS): Leveraging Differentiated knowledge-acquisition and Creative realism to address complex optimization problems[J]. Expert Systems with Applications, 2024: 123734.
完整代码获取
后台回复关键词:
TGDM899
















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











