







1.背景
2024年,P Duankhan受到差异化知识获取和创造性现实主义启发,提出了差异化创造性搜索算法(Differentiated Creative Search, DCS)。


2.算法原理
2.1算法思想
DCS是一种差异化创造性搜索方法,旨在优化复杂环境下的决策系统。其核心思想包括:
- 结合知识获取与创造性现实主义:DCS将独特的知识获取过程与创造性现实主义范式相结合,以提升优化策略
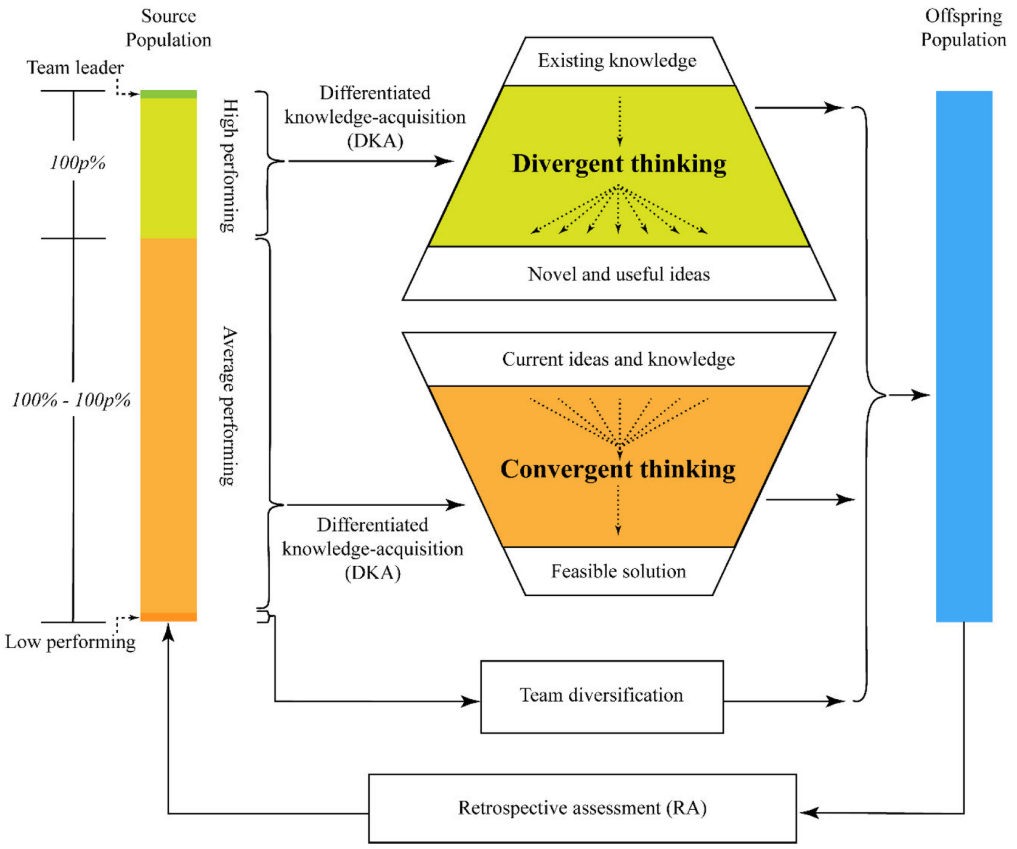
- 双策略方法:采用双策略方法平衡发散思维和收敛思维。团队中高效成员通过发散思维策略运用现有知识和创造性思维,而其余成员则通过收敛思维策略结合团队领导和其他成员的见解
- 差异化知识获取:根据个体团队成员的表现进行差异化知识获取,促进持续学习和适应环境的氛围
2.2算法过程
差异化知识获取(DKA)
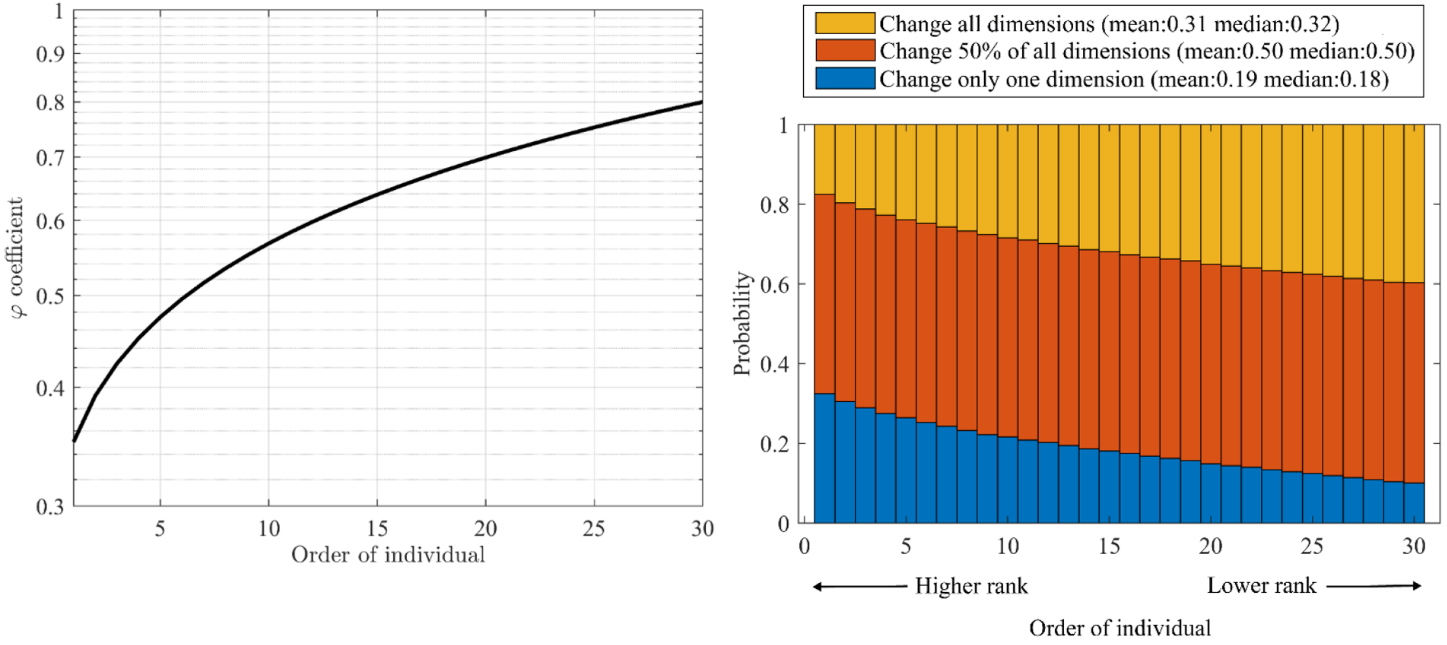
DKA与DE交叉的主要区别在于其根植于人类知识获取潜力的不同概念,更接近于自然过程,而不是DE所体现的随机原则。DKA侧重于新知识获取速率,对个体产生不同影响,这种变化主要体现在新知识对个体现有知识的属性或维度的改变上,参数ηi,t为个体在第t次迭代时的量化知识获取率(qKR):
η
i
,
t
=
1
2
×
(
[
U
(
0
,
1
)
×
φ
i
,
t
]
+
{
1
,
i
f
U
(
0
,
1
)
≤
φ
i
,
t
0
,
o
t
h
e
r
w
i
s
e
)
(1)
\left.\left.\eta_{i,t}=\frac12\times\left(\left[U(0,1)\times\varphi_{i,t}\right]+\left\{\begin{array}{ll}1,~if~U(0,1)\leq\varphi_{i,t}\\0,~otherwise\end{array}\right.\right.\right.\right)\tag{1}
ηi,t=21×([U(0,1)×φi,t]+{1, if U(0,1)≤φi,t0, otherwise)(1)
符号[•]表示将给定值四舍五入到最接近的整数,φi,t为个体在第t次迭代时的φ系数值:
φ
i
,
t
=
0.25
+
0.55
×
R
i
,
t
/
N
P
(2)
\varphi_{i,t}=0.25+0.55\times\sqrt{R_{i,t}/NP}\tag{2}
φi,t=0.25+0.55×Ri,t/NP(2)
φi,t为个体在第t次迭代时的φ系数值。Ri,t是第i个个体在第t次迭代开始时的秩(阶)。
φ系数随这些知识差距的程度而变化,值越高表示知识差距越大,表明个体更需要学习、吸收和吸收新的知识或经验。DKA过程对每个Xi的作用:
j
r
a
n
d
∼
U
(
{
1
,
2
,
.
.
.
,
D
}
)
ν
i
,
d
=
{
ν
i
,
d
,
i
f
U
(
0
,
1
)
≤
η
i
,
t
o
r
d
=
j
r
a
n
d
,
x
i
,
d
,
o
t
h
e
r
w
i
s
e
(3)
\left.\begin{aligned}&j_{rand}\sim U(\{1,2,...,D\})\\&\nu_{i,d}=\left\{\begin{array}{ll}\nu_{i,d},&if U(0,1)\leq\eta_{i,t} or d=j_{rand},\\x_{i,d},&otherwise\end{array}\right.\\\end{aligned}\right.\tag{3}
jrand∼U({1,2,...,D})νi,d={νi,d,xi,d,ifU(0,1)≤ηi,tord=jrand,otherwise(3)
收敛思维
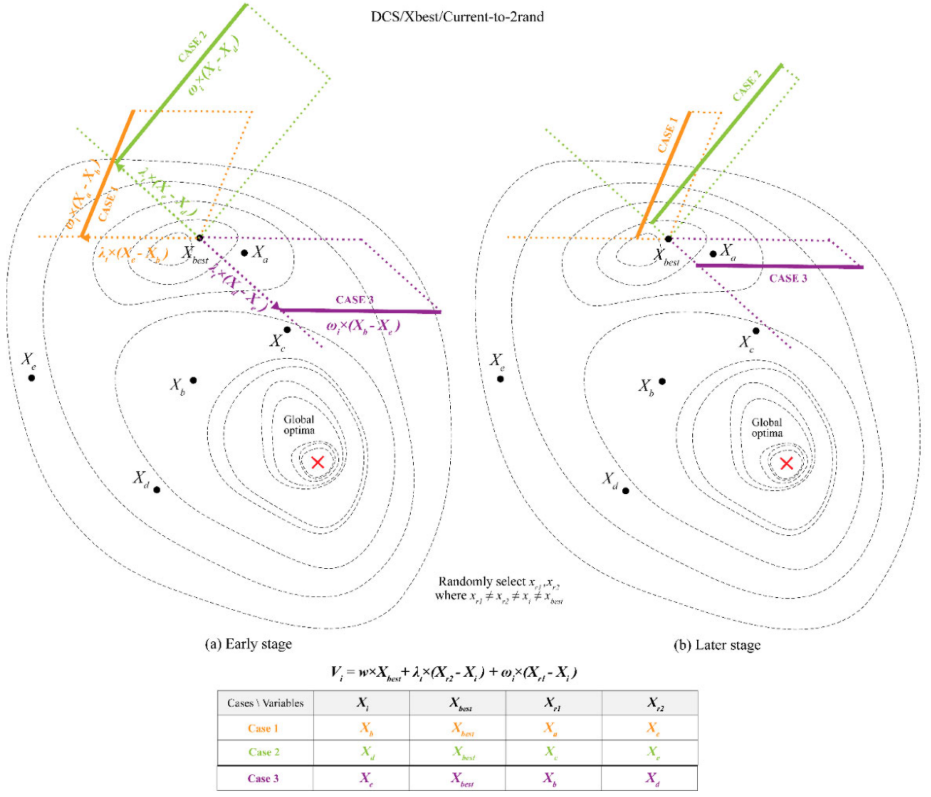
DCS/Xbest/Current-to-2rand策略依赖于顶级表现者的知识库,并将两名团队成员的随机贡献纳入当前个体所提出的解决方案中。
V
i
=
F
×
X
b
e
s
t
−
(
F
×
X
r
2
−
X
i
)
+
F
×
(
X
r
1
−
X
i
)
(4)
V_i=F\times X_{best}-(F\times X_{r2}-X_i)+F\times(X_{r1}-X_i)\tag{4}
Vi=F×Xbest−(F×Xr2−Xi)+F×(Xr1−Xi)(4)
Xi从趋同思维中汲取灵感,通过整合团队成员Xr1和Xr2提供的信息,提炼出团队领导者的知识Xbest:
V
i
=
w
×
X
b
e
s
t
+
λ
t
×
(
X
r
2
−
X
i
)
+
ω
i
,
t
×
(
X
r
1
−
X
i
)
(5)
V_i=w\times X_{best}+\lambda_t\times(X_{r2}-X_i)+\omega_{i,t}\times(X_{r1}-X_i)\tag{5}
Vi=w×Xbest+λt×(Xr2−Xi)+ωi,t×(Xr1−Xi)(5)
λt系数的表达式为:
λ
t
=
0.1
+
0.518
×
(
1
−
N
F
E
t
/
N
F
E
m
a
x
)
(6)
\lambda_t=0.1+0.518\times\left(1-\sqrt{NFE_t /NFE_{max}}\right)\tag{6}
λt=0.1+0.518×(1−NFEt/NFEmax)(6)
λt系数控制着团队环境中同伴对个体社会认知的影响。它反映了团队的社会动态对个人观点的影响程度。系数高表明个体更容易受到同伴压力和社会影响,可能是由于渴望融入或害怕脱颖而出。相反,系数值越低,则表明个体更自立,受同伴影响较小。
Xr1是从包括高绩效成员(绿色突出显示)在内的整个总体中随机选择的,而Xr2是从非高绩效成员(橙色突出显示)中选择的。这种抽样策略意味着Xr1很有可能优于Xr2:
v
i
,
d
=
w
×
x
b
e
s
t
,
d
+
λ
t
×
(
x
r
2
,
d
−
x
i
,
d
)
+
ω
i
,
t
×
(
x
r
1
,
d
−
x
i
,
d
)
(7)
v_{i,d}=w\times x_{best,d}+\lambda_t\times\begin{pmatrix}x_{r2,d}-x_{i,d}\end{pmatrix}+\omega_{i,t}\times\begin{pmatrix}x_{r1,d}-x_{i,d}\end{pmatrix}\tag{7}
vi,d=w×xbest,d+λt×(xr2,d−xi,d)+ωi,t×(xr1,d−xi,d)(7)

发散思维
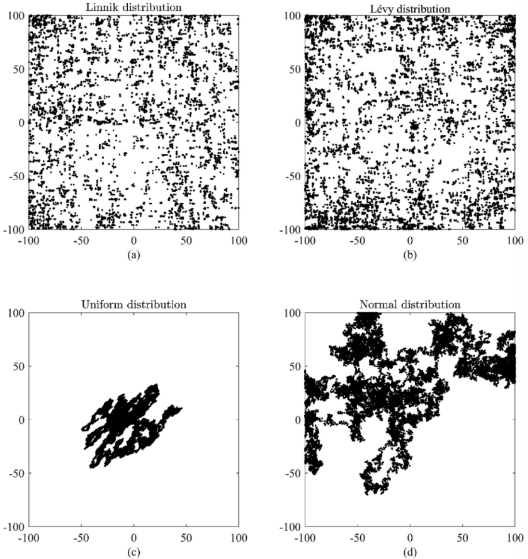
DCS中使用Linnik分布,Linnik分布与Levy分布 特征如下:
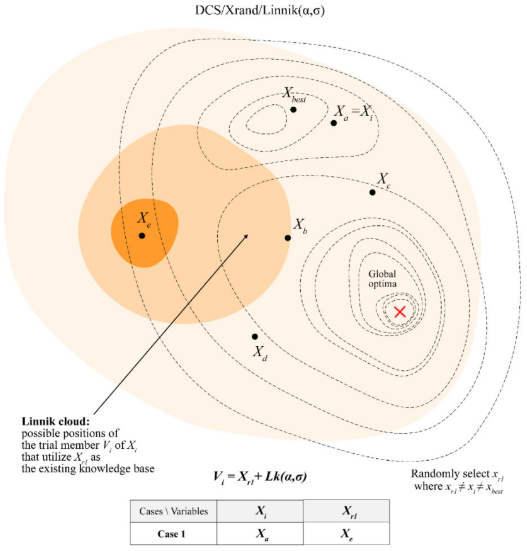
速度更新:
V
i
=
X
r
1
+
L
k
(
α
,
σ
)
(8)
V_i=X_{r1}+Lk(\alpha,\sigma)\tag{8}
Vi=Xr1+Lk(α,σ)(8)
这个新策略意味着试验向量(Vi)是现有知识(Xr1)和新颖性或创造性元素(Lk(α, σ))的混合。Xi可能会在Xe和Lk(α, σ)的影响下转移到发散区域内的新位置:
v
i
,
d
=
x
r
1
,
d
+
L
k
(
α
,
σ
)
(9)
v_{i,d}=x_{r1,d}+Lk(\alpha,\sigma)\tag{9}
vi,d=xr1,d+Lk(α,σ)(9)
回顾性评估(RA)
回顾评估(RA)是团队开发的关键工具。它建立评价标准作为衡量成功的基准,然后分析过去的绩效数据,以确定趋势和改进领域:
X
i
,
t
+
1
=
{
V
i
,
t
,
f
(
V
i
,
t
)
≤
f
(
X
i
,
t
)
,
X
i
,
t
,
o
t
h
e
r
w
i
s
e
(10)
X_{i,t+1}=\left\{\begin{array}{ll}V_{i,t},&f\big(V_{i,t}\big)\leq f\big(X_{i,t}\big),\\X_{i,t},&otherwise\end{array}\right.\tag{10}
Xi,t+1={Vi,t,Xi,t,f(Vi,t)≤f(Xi,t),otherwise(10)
跟踪最佳表现者:
X
b
e
s
t
,
t
=
{
X
i
,
t
+
1
,
f
(
X
i
,
t
+
1
)
<
f
(
X
b
e
s
t
,
t
)
,
X
b
e
s
t
,
t
,
o
t
h
e
r
w
i
s
e
(11)
X_{best,t}=\begin{cases} X_{i,t+1},&f\big(X_{i,t+1}\big)<f\big(X_{best,t}\big),\\ X_{best,t},&otherwise\end{cases}\tag{11}
Xbest,t={Xi,t+1,Xbest,t,f(Xi,t+1)<f(Xbest,t),otherwise(11)
伪代码


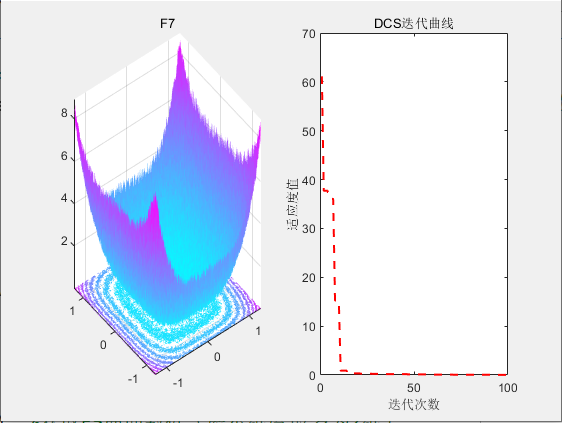
3.结果展示
4.参考文献
[1] Duankhan P, Sunat K, Chiewchanwattana S, et al. The Differentiated Creative search (DCS): Leveraging Differentiated knowledge-acquisition and Creative realism to address complex optimization problems[J]. Expert Systems with Applications, 2024: 123734.


















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











