






差分进化算法经久不衰!作为经典的优化算法,近年来依旧有不少学者对其改进。本期推荐一个2024年发表的一个最新的改进差分进化算法。
本期推荐的改进差分算法于2024年发表在计算机领域三区SCI期刊“Neural Computing and Applications”上。

改进差分进化算法(Advanced Differential Evolution,ADE)旨在提高优化过程的有效性,该算法利用混沌理论生成初始种群,随后将其划分为两个具有自适应大小的子种群。每个子种群的大小是使用基于算法执行期间迭代次数的公式确定的。本算法的主要贡献是提出了两种新颖的改进策略,文中标写为MDE1和MDE2。
1、算法原理
(1)初始化
与大多数算法一样,改进的差分进化算法同样采用了混沌映射来初始化种群,逻辑映射法公式如下:
其中r为引起蝴蝶效应的logistic系数,将该关系产生的值转换为以下公式,即可作为优化变量使用:
首先,为了创建初始种群,需要一个n维向量,随机数是使用正态分布在区间[1,0]中随机生成的。n表示该向量中决策变量的数量。然后,通过映射上述公式将每个Xi分量映射到该变量对应的区间。
(2)改进的差分进化策略1 (MDE1)
MDE1阶段从本质上讲遵循与DE相同的基本原则,但合并了一些改进。该算法专门应用于第一个子种群。
首先,根据混沌理论创建初始种群。
其次,根据所选个体之间的欧氏距离对DE算法的三个关键因子之一尺度因子β (scale factor)进行调整。计算所选两个解的欧氏距离,若其大于优化变量上下值距离的十分之一,则从[βmin,βmax]中随机选取尺度因子值。在算法开始时确定βmin和βmax的值,分别取0.2和0.8。
第三个改进是第一个子种群(SizePop1)的大小逐渐减小。例如,如图所示,假设总体规模(Poptotal)为30。
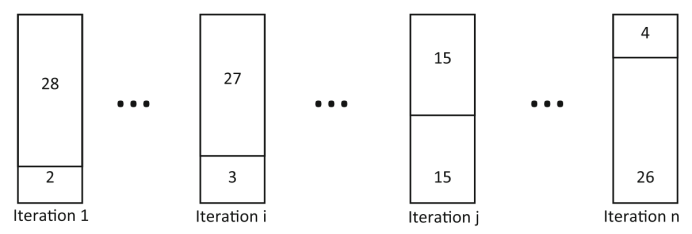
首先,MDE1对亚种群中的28个个体(Popinit)起作用,结果两个个体将留在第二个亚种群(SizePop2)中。随着迭代次数的增加,根据下式,第一子种群(Popmin)的个体数量减少到4个,其中:
在公式中,变量 表示MDE1算法中下一代(G+ 1)的第一个子种群的大小。MaxIter表示最大迭代次数,Iter表示当前迭代次数。Popinit表示算法开始时第一个子种群的初始大小,Popmin表示第一个子种群的最小大小。
为了减少第一亚种群的规模,有必要移除某些个体。这是通过选择和淘汰适应性最低的个体来实现的,因为它被认为是最差的个体。此外,随着第一个亚种群的规模减小,第二个亚种群的规模必须相应增加。为了实现这一目标,将第一个子种群中的最佳个体作为新个体添加到第二个子种群中。
(3)改进的差分进化策略2 (MDE2)
第二种算法对第二种群进行勘探和开采操作,包括以下步骤:
根据混沌理论创建初始种群。
对种群中的所有个体进行评估。
对于第二个子种群的每个成员,当前成员的位置存储在x2中。使用以下公式,计算两个向量的结果。这些向量是通过从x2中减去两个最佳候选(xbest1和xbest2)的位置,乘以随机系数r1和r2得到的。这个计算是为了生成一个合成向量vi。
为了引入多样性和随机性,在[βmin,βmax]的范围内随机计算系数β.然后,通过将vi与β相乘来生成矢量y。
与原始DE算法类似,以一定概率PCrossover在y和x2之间执行交叉操作。然而,与原始DE算法不同的是,如果后代的性能优于父代,则不替换后代。相反,它被简单地添加到当前的第二子群体。
通过将所有新的后代添加到现有的第二子群体,第二子群体的大小加倍。为了保持所需的种群规模,需要去除一半的个体。这是通过基于个体的适应度对个体进行排序并仅将最佳个体保留给下一代来实现的。
此外,在对第二个亚群运行MDE 2算法之前,必须检查条件 。如果该条件为真,则从第一子群体的最佳个体中选择一定数量的成员(等于Popmin)并将其迁移到第二子群体。执行此迁移是为了提高利用率,因为迁移的个体可能是迄今为止发现的最佳个体。
下图显示了所提出的算法的流程图。
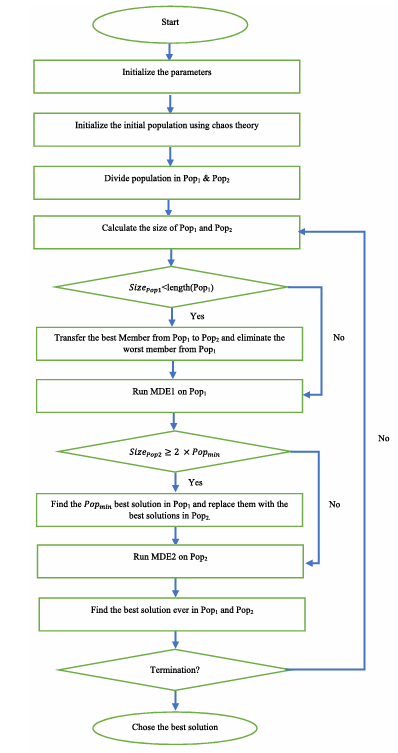
最后,本算法可以通过将一些个体从第一子种群迁移到第二子种群来利用原始DE的探索能力。
ADE对应的伪代码过程如下图所示

2、结果展示
结果图中,画出了种群寻优过程轨迹图,平均适应度曲线图,搜索二维空间图,迭代曲线图。



3、MATLAB核心代码
% 改进差分进化算法(Advanced Differential Evolution,ADE)
function [Convergence_curve , nfe , Fbest, Trajectories, fitness_history, position_history]=ADE(F_index,N,fobj,lb, ub , dim, MaxIt)%
%% Problem Definition
%CostFunction=@(x) Sphere(x); % Cost Function
global NFE;
global maxFEs bestStar;
nfe=zeros(MaxIt,1);
nVar=dim; % Number of Decision Variables
VarSize=[1 nVar]; % Decision Variables Matrix Size
VarMin= lb; % Lower Bound of Decision Variables
VarMax= ub; % Upper Bound of Decision Variables
%% ADE Parameters
nPop=N; % Population Size
NPopmin = 4;
NPopinit = 28;
Pop1Size=NPopinit;
Pop2Size=nPop-Pop1Size;
beta_min=0.2; % Lower Bound of Scaling Factor
beta_max=0.8; % Upper Bound of Scaling Factor
pCR=0.2; % Crossover Probability
NumIt=round(maxFEs/nPop);
fitness_history=zeros(nVar,NumIt);
position_history=zeros(nPop,NumIt,nVar);
Trajectories=zeros(nVar,NumIt);
Convergence_curve=zeros(1,NumIt);
%% Initialization
empty_individual.Position=[];
empty_individual.Cost=[];
pop=repmat(empty_individual,nPop,1);
NewSol=empty_individual;
NewSol2=empty_individual;
BestSol1Pop1.Cost=inf;
BestSol2Pop1.Cost=inf;
%% Initialization
mu=4; %constant in (eq. 1)
pop(1).Position = unifrnd(0, 1, VarSize);
for i = 1:nPop
% Initialize Solutions
pop(i+1).Position = mu* pop(i).Position.*(1- pop(i).Position); %(Eq. 1)
end
pop(1)=[];
for i = 1:nPop
pop(i).Position=mapping(pop(i).Position,dim,VarMax,VarMin);
% Evaluation
pop(i).Cost = fobj(pop(i).Position,F_index,dim);
fitness_history(i,1)=pop(i).Cost;
position_history(i,1,:)=pop(i).Position;
end
Trajectories(:,1)=pop(1).Position;
% Store Best Solution Ever Found
BestCost=zeros(MaxIt,1);
[~ ,index]= min([pop.Cost]);
BestSol = pop(index);
pop1=pop(1 : Pop1Size);
pop2=pop(Pop1Size + 1 : end);
%% ADE Main Loop
for it=1:MaxIt
if BestSol.Cost==bestStar
break;
end
% Population Reduction
Pop1Size=round((((NPopmin-NPopinit)/MaxIt)*it) + NPopinit);
if Pop1Size<length(pop1)
Pop2Size=nPop-Pop1Size;
pop2(Pop2Size)=BestSol1Pop1;
[~,WorstSolPop1_index]=max([pop1.Cost]);
pop1(WorstSolPop1_index)=[];
end
% Phase #1 (Pop 1 & improved DE)
for i=1:Pop1Size
x1=pop1(i).Position;
A=randperm(Pop1Size);
A(A==i)=[];
a=A(1);
b=A(2);
c=A(3);
% Set Scale Factor (beta1) and Mutation
if pdist2(pop1(b).Position,pop1(c).Position)>pdist2(VarMax,VarMin)/10
beta1=unifrnd(beta_min,beta_max,VarSize);
else
beta1=unifrnd(beta_min,beta_max*(1+rand),VarSize);
end
y1=pop1(a).Position+beta1.*(pop1(b).Position - pop1(c).Position);
% Bound
y1 = max(y1, VarMin);
y1 = min(y1, VarMax);
% Crossover
z1=Crossover(x1,y1,pCR);
% Evaluation
NewSol.Position=z1;
NewSol.Cost=fobj(NewSol.Position,F_index,dim);
fitness_history(i,it)=pop1(i).Cost;
position_history(i,it,:)=pop1(i).Position;
Trajectories(:,it)=pop1(1).Position;
% Select best between parent and Mutant
if NewSol.Cost<pop1(i).Cost
pop1(i)=NewSol;
% Update Global Best
if pop1(i).Cost<BestSol.Cost
BestSol=pop1(i);
end
end
% Find Best Solution of pop1
if pop1(i).Cost<BestSol1Pop1.Cost
BestSol1Pop1=pop1(i);
end
end
% Phase #2 (Pop 2 & New Algo)
if Pop2Size>=(2*NPopmin)
% Find the NPopmin best answers in pop1 and replace with best answers in pop2
[~,BestKSolPop1_index] = mink([pop1.Cost],NPopmin);
pop2(1:NPopmin)=pop1(BestKSolPop1_index);
end
for j=1:Pop2Size
x2=pop2(j).Position;
%resultant of top two vectors in pop 2
resOfTop2 = (rand(VarSize).*(x2 - pop2(1).Position) + ...
rand(VarSize).*(x2 - pop2(2).Position)) ;
% Set Scale Factor
beta2=unifrnd(beta_min,beta_max,VarSize);
y2= beta2.*resOfTop2 ;
% Bound
y2 = max(y2, VarMin);
y2 = min(y2, VarMax);
% Crossover
z2=Crossover(x2,y2,pCR);
% Evaluation
NewSol2.Position=z2;
NewSol2.Cost=fobj(NewSol2.Position,F_index,dim);
fitness_history(Pop1Size+j,it)=pop2(j).Cost;
position_history(Pop1Size+j,it,:)=pop2(j).Position;
% Find Best Solution so far
if NewSol2.Cost<BestSol.Cost
BestSol=NewSol2;
end
% Add new offspring to pop2
pop2=[pop2;NewSol2];
end
% Sort Pop2
Costs = [pop2.Cost];
[~, SortOrder] = sort(Costs);
pop2 = pop2(SortOrder);
% Truncation Pop2
pop2 = pop2(1:Pop2Size);
% Store Best Solution Ever Found
[~,BestSolPop2_index] = min([pop2.Cost]);
if pop2(BestSolPop2_index).Cost < BestSol.Cost
BestSol = pop2(BestSolPop2_index);
end
nfe(it)=NFE;
% Update Best Cost
BestCost(it)=BestSol.Cost;
% Show Iteration Information
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCost(it)) ]);
end
% Return Convergence_curve and BestSol
Convergence_curve = BestCost;
Fbest = BestSol;
%% Show Results
end
%%Crossover
function z=Crossover(x,y,pCR)
z=zeros(size(x));
j0=randi([1 numel(x)]);
for jj=1:numel(x)
if jj==j0 || rand<=pCR
z(jj)=y(jj);
else
z(jj)=x(jj);
end
end
end
%%Mapping
function MX=mapping(X,dim,ub,lb)
if numel(ub)==1
ub=ones(1,dim)*ub;
lb=ones(1,dim)*lb;
end
for i=1:dim
ub_i=ub(i);
lb_i=lb(i);
MX(:,i)=X(i).*(ub_i-lb_i)+lb_i; %(Eq. 2)
end
end
微信公众号搜索:淘个代码,获取更多免费代码
%唯一官方店铺:https://mbd.pub/o/author-amqYmHBs/work
%代码清单:https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu参考文献
[1]Abbasi B, Majidnezhad V, Mirjalili S. ADE: advanced differential evolution[J]. Neural Computing and Applications, 2024: 1-32.
完整代码获取
后台回复关键词:
TGDM815
获取更多代码:

或者复制链接跳转:
https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











