






问题背景:
问题四:根据实际情况,现需要扩大生产规模,将生产线每天的运行时间从 8 小时增加 到 24 小时不间断生产,考虑生产线与操作人员的搭配,制定最佳的操作人员排班方案,要求满足以下条件:(1) 各操作人员做五休二,尽量连休 2 天; (2) 各操作人员每班连续工作 8 小时; (3) 班次时间:早班(8:00-16:00)、中班(16:00-24:00)、晚班(0:00-8:00); (4) 各工龄操作人员的人数比例与问题 3 中的比例相同; (5) 各操作人员的班次安排尽量均衡。
已知问题三中原本每条生产线与相应操作人员对应如下:
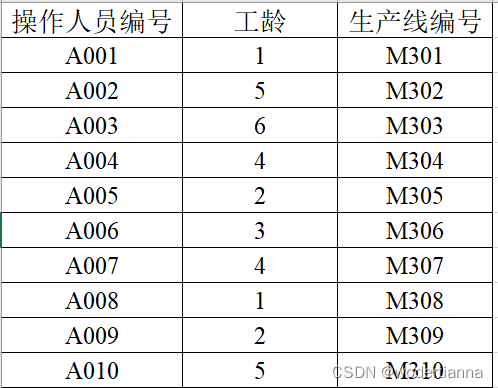
问题分析:
问题四为优化问题,考虑使用遗传算法,根据附件三给出的生产线与操作人员信息,无法将生产线与操作人员剥离开而单独讨论某条生产线或者某位操作人员的工作能力指标。因此,在本题中,固定生产线与相应工龄操作人员的搭配,即从理论上固定生产效率。那么,本题仅为优化问题中的排班问题,考虑如下约束条件:
1.每天10条线24小时工作;
2.一位操作人员每天工作8小时;
3.夜班之后必须至少休一天(考虑现实情况添加);
4.各操作人员上五休二,尽量连休;
5.各操作人员班次尽量均匀。
其中,为了生产线的正常运行与操作人员身体健康,1-3为硬性约束,4-5为软约束,以此建立遗传算法优化模型,希望得到合理的排班表。考虑到24小时生产线不间断运营,并且要保证操作人员工龄比例与附件三相同,至少需要5组生产线操作人员,即50人,约定员工与产线有如下对应关系:
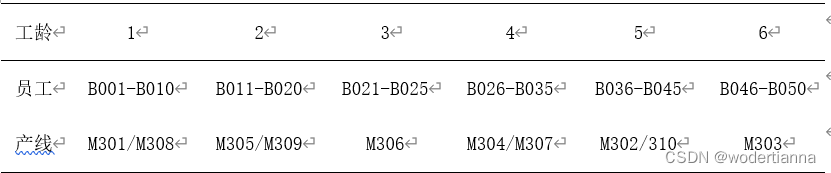
遗传算法排班:
使用遗传算法进行排班,首先,需要确定染色体的编码,这里,每条染色体代表一个排班表,染色体中每两位二进制编码表示一种班型,对于一周7天,每天有操作人员50人,一条染色体由7×50条操作人员基因组成,每一个操作人员基因又由2位的班型基因(二进制编码)构成,因此,一条染色体由7×50×2位编码的基因组成。
pop = 50; %设定初始种群数量
length = 700; %种群基因编码长度,一周七天,每天50个排班人员,总共3种班型(用2位二进制编码表示)
gen = 500; %迭代次数
crossover_probablity = 0.9; %交叉概率 %交叉概率一般在0.6~0.9之间
variation_probablity = 0.1; %变异概率 %
initial_pop = round(rand(pop,length)); %生成初始种群
%算法迭代m次
for m=1:gen
%将每一代 染色体长度为700位的二进制种群 转化为50*7的矩阵(50人,一周7天)
x = zeros(50,7,pop);
for i = 1:size(initial_pop,1) %分别遍历排班表
for j = 1:7 %遍历一周七天
for k = 1:50 %遍历50个排班人员
for l = 1:2 %二进制班型转换为十进制
x(k,j,i) = initial_pop ( i,100*(j-1)+2*(k-1)+l ) * 2^(2-l) + x(k,j,i); % 100是人数50×排班编码数2
end
end
end
%%%%%确定每天每个班次不超过十人上班,若超过10人,按工龄比例随机保留10名员
%%%%%工上班,其他人放假,且各工龄比例如题三
for j=1:7
for f = 0:2
if sum(x(1:10,j,i)==f)>2 % 工龄1人数大于2
w = find(x(1:10,j,i)==f); % 获取上班的人索引
n_geshu = size(w,1);
ran_index = randperm(n_geshu); % 生成随机索引
n_de = n_geshu - 2; % 要改为休假的员工人数
de_index = ran_index(1:n_de);
dey_index = w(de_index,:); % 随机抽取放假人员索引
x(dey_index,j,i) = 3;
end
if sum(x(11:20,j,i)==f)>2 % 工龄2人数大于2
w = find(x(11:20,j,i)==f);
n_geshu = size(w,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = n_geshu - 2;
de_index = ran_index(1:n_de);
dey_index = w(de_index,:);
x(dey_index+10,j,i) = 3;
end
if sum(x(21:25,j,i)==f)>1 % 工龄3人数大于2
w = find(x(21:25,j,i)==f);
n_geshu = size(w,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = n_geshu - 1;
de_index = ran_index(1:n_de);
dey_index = w(de_index,:);
x(dey_index+20,j,i) = 3;
end
if sum(x(26:35,j,i)==f)>2 % 工龄4人数大于2
w = find(x(26:35,j,i)==f); % 人索引
n_geshu = size(w,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = n_geshu - 2; % 要取消的工作人数
de_index = ran_index(1:n_de);
dey_index = w(de_index,:);
x(dey_index+25,j,i) = 3;
end
if sum(x(36:45,j,i)==f)>2 % 工龄5人数大于2
w = find(x(36:45,j,i)==f);
n_geshu = size(w,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = n_geshu - 2;
de_index = ran_index(1:n_de);
dey_index = w(de_index,:);
x(dey_index+35,j,i) = 3;
end
if sum(x(46:50,j,i)==f)>1 % 工龄6人数大于2
w = find(x(46:50,j,i)==f);
n_geshu = size(w,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = n_geshu - 1;
de_index = ran_index(1:n_de);
dey_index = w(de_index,:);
x(dey_index+45,j,i) = 3;
end
end
end
%%%!规定夜班后必是休息!
for j = 1:6 %遍历一周前6天
for k = 1:50 %遍历50个排班人员
if x(k,j,i)==2
x(k,j+1,i)=3;
end
end
end
%%%%%确定每天每个班次不低于十人上班,若低于,随机选取改工龄内休假的人排班
for j=1:7
for f = 0:2
if sum(x(1:10,j,i)==f)<2
w = find(x(1:10,j,i)==f); % 已经排班的人索引
n_geshu = size(w,1);
ww = find(x(1:10,j,i)==3); % 休假人索引
nj_geshu = size(ww,1);
ran_index = randperm(nj_geshu); % 随机索引
n_cre = 2 - n_geshu; % 要由休假变上班的人数
de_index = ran_index(1:n_cre);
dey_index = ww(de_index,:);
x(dey_index,j,i) = f;
end
if sum(x(11:20,j,i)==f)<2 % 工龄2
w = find(x(11:20,j,i)==f);
n_geshu = size(w,1);
ww = find(x(11:20,j,i)==3);
nj_geshu = size(ww,1);
ran_index = randperm(nj_geshu); % 随机索引
n_cre = 2 - n_geshu;
de_index = ran_index(1:n_cre);
dey_index = ww(de_index,:);
x(dey_index+10,j,i) = f;
end
if sum(x(21:25,j,i)==f)==0 % 工龄3一班次只需一人,所以如果无人上班,添加一人
ww = find(x(21:25,j,i)==3);
n_geshu = size(ww,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = 1;
de_index = ran_index(1);
dey_index = ww(de_index,:);
x(dey_index+20,j,i) = f;
end
if sum(x(26:35,j,i)==f)<2 % 工龄4
w = find(x(26:35,j,i)==f);
n_geshu = size(w,1);
ww = find(x(26:35,j,i)==3);
n_geshu = size(ww,1);
ran_index = randperm(n_geshu); % 随机索引
n_cre = 2 - n_geshu;
de_index = ran_index(1:n_cre);
dey_index = ww(de_index,:);
x(dey_index+25,j,i) = f;
end
if sum(x(36:45,j,i)==f)<2 % 工龄5
w = find(x(36:45,j,i)==f);
n_geshu = size(w,1);
ww = find(x(36:45,j,i)==3);
n_geshu = size(ww,1);
ran_index = randperm(n_geshu); % 随机索引
n_cre = 2 - n_geshu;
de_index = ran_index(1:n_cre);
dey_index = ww(de_index,:);
x(dey_index+35,j,i) = f;
end
if sum(x(46:50,j,i)==f)==0 % 工龄6
ww = find(x(46:50,j,i)==3);
n_geshu = size(ww,1);
ran_index = randperm(n_geshu); % 随机索引
n_de = 1;
de_index = ran_index(1);
dey_index = ww(de_index,:);
x(dey_index+45,j,i) = f;
end
end
end
end
%%%%%% 约束条件 %%%%%
%约束1--- 每天每班次上班十人,且工龄如题三比例 -------硬约束 --
y1 = zeros(pop,7);%每天的适应值
yy1 = zeros(pop,7); % yy1,2,3表示早中晚班人员配置适应值
yy2 = zeros(pop,7);
yy3 = zeros(pop,7);
yy4 = zeros(pop,7); % yy4表示每天20人休息适应值--硬
for i=1:size(initial_pop,1)
for j=1:7
yy1(i,j) = 1/((sum(x(1:10,j,i)==0)-2)^2 + (sum(x(11:20,j,i)==0)-2)^2 + (sum(x(21:25,j,i)==0)-1)^2 + (sum(x(26:35,j,i)==0)-2)^2 + (sum(x(36:45,j,i)==0)-2)^2 + (sum(x(46:50,j,i)==0)-1)^2 + 1);
% 每个时间段的各年龄工人刚好和生产线匹配----早班,午班晚班类似
yy2(i,j) = 1/((sum(x(1:10,j,i)==1)-2)^2 + (sum(x(11:20,j,i)==1)-2)^2 + (sum(x(21:25,j,i)==1)-1)^2 + (sum(x(26:35,j,i)==1)-2)^2 + (sum(x(36:45,j,i)==1)-2)^2 + (sum(x(46:50,j,i)==1)-1)^2 + 1);
yy3(i,j) = 1/((sum(x(1:10,j,i)==2)-2)^2 + (sum(x(11:20,j,i)==2)-2)^2 + (sum(x(21:25,j,i)==2)-1)^2 + (sum(x(26:35,j,i)==2)-2)^2 + (sum(x(36:45,j,i)==2)-2)^2 + (sum(x(46:50,j,i)==2)-1)^2 + 1);
yy4(i,j) = 1/((sum(x(1:10,j,i)==3)-4)^2 + (sum(x(11:20,j,i)==3)-4)^2 + (sum(x(21:25,j,i)==3)-2)^2 + (sum(x(26:35,j,i)==3)-4)^2 + (sum(x(36:45,j,i)==3)-4)^2 + (sum(x(46:50,j,i)==3)-2)^2 + 1);
y1(i,j) = yy1(i,j) + yy2(i,j) + yy3(i,j) + yy4(i,j);
end
end
%y1为每天的适应值(最大值为1),yw1为每周的适应值(理论最大值为7x4),此处为1
for i=1:size(initial_pop,1)
yw1(i,1) = sum(y1(i,:))/28;
end
%约束2----- 每人一周内上5休2
y2 = zeros(pop,7); %每人的适应值-硬 - 五休二
y3 = ones(pop,k); %每人的适应值-软
for i = 1:size(initial_pop,1)
for k = 1:49
y2(i,k) = 1/((sum(x(k,1:7,i)==3) - 2)^2 + 1); %最大 1 %上五休二
y4(i,k) = 1/((sum(x(k,1:7,i)==3)-sum(x(k+1,1:7,i)==3))^2 +1);
for j = 1:5 %遍历周一至周六
if x(k,j,i) == 2 % 如果是放假--夜班后
% 若放一天就继续工作的惩罚函数
y3(i,k) = y3(i,k) - 1/5 *( x(k,j+2,i)~=3 ); % 最大 1 尽量连休
end
end
end
end
%y2,y3为每人的适应值(最大值为1),yr1,yr2为整个排班表的适应值(理论最大值为50),此处1
for i=1:size(initial_pop,1)
yr1(i,1) = sum( y2(pop,:) )/50;
yr2(i,1) = sum( y3(pop,:) )/50;
yr3(i,1) = sum( y4(pop,:) )/50;
end
% 权重凭感觉给的,实际应该考虑约束条件的重要性及达到约束的难易程度
y = 0.8*yw1 +0.05*yr1 + 0.1*yr2 + 0.15*yr3;
%找到种群中的最优基因
[a,b] = max(y); % a-单次迭代中最大y值; b-最大y的索引位置
fit1=y/sum(y); %计算每个种群的适应度在总适应度里所占的比例
fit2=cumsum(fit1); %累加
%基因选择
choose=sort(rand(pop,1)); %有序随机数序列
k=1;
i=1;
while k<=pop
if choose(k)<fit2(i) % 此处使用的是--轮盘赌选择法
choosen_population(k,:)=initial_pop(i,:);
k=k+1;
else
i=i+1;
end
end
%基因交叉--
for i=1:2:pop-1
if rand<crossover_probablity
crossover_length=round(rand*(length-1))+1; %基因交叉长度
crossover_population(i,:)=[choosen_population(i,1:crossover_length),choosen_population(i+1,crossover_length+1:end)];
crossover_population(i+1,:)=[choosen_population(i+1,1:crossover_length),choosen_population(i,crossover_length+1:end)];
else
crossover_population(i:i+1,:) = choosen_population(i:i+1,:);
end
end
%基因变异
variation_population=crossover_population;
for i=1:pop
if rand<variation_probablity
variation_location=round(rand*(length-1))+1;
variation_population(i,variation_location)=1-variation_population(i,variation_location);
end
end
variation_population(end,:)=initial_pop(b,:); %保留该次迭代中的最优种群
initial_pop=variation_population; %经选择、交叉、变异后的种群作为下一代的初始种群,从而完成迭代
best(m,1)=y(b); % 记录下第m代的最优函数值
best(m,2) = yw1(b); %记录第m代的最优适应值们
best(m,3) = yr1(b);
best(m,4) = yr2(b);
best(m,5) = yr3(b);
best_pop(:,:,m) = x(:,:,b); % 记录下第m代的最优排班表
end
%画图
y_smoothed = smooth(1:size(best,1),best(:,1), 0.5, 'loess'); %添加平滑曲线
figure;
plot(1:size(best,1),best(:,1),'-', 'LineWidth',1.2);hold on;
plot(1:size(best,1),y_smoothed,'-','color','red', 'LineWidth',1.2);hold on;
xlabel('迭代次数');
ylabel('适应值');
title('适应值变化曲线(排班一周)');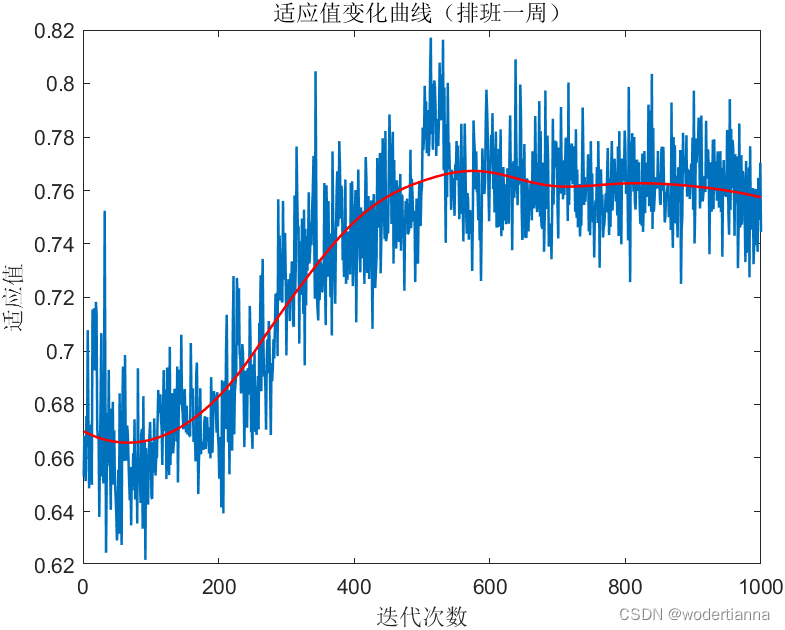















 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









