






社交网络中包含着丰富的信息,例如电子邮件,用户注册信息,位置数据,qq等,若两个人经常通过电子邮件联系,则代表两人可能有相同的兴趣。社交图谱(social graph,facebook和qq等(好友一般认识))和兴趣图谱(interest graph(twitter等 好友一般不认识))。
社交网络也可以用图来定义,G(V,E,w)其中V是顶点集合,E是边集合,w是边的权重,分为有向图和无向图,对于twitter这种社交网站加边为有向边,若为qq,facebook这种则添加边为无向边。一般来说有3种不同社交网络数据:
1.双向确认的社交网络数据:形成好友关系需要双方确定,添加无向边,例如qq
2.单向关注的社交网络数据:可以不需要得到允许的单方面关注,添加有向边,例如twitter,微博
3.基于社区的社交网络数据:比如同一个学校,同一家公司等
社交网络推荐可以增加推荐的信任度,还可以解决冷启动问题。
1.基于邻域的社会化推荐算法
如果给定了社交网络数据,我们能想到的简单算法是给用户推荐好友喜欢的东西,但是考虑到用户之间熟悉程度,以及用户之间的兴趣相似度等,用户u对物品i的兴趣可以定义为:
其中由两部分组成,分别为用户熟悉程度和用户相似度,用户熟悉程度用共同好友比例定义为:
兴趣相似度用两个用户喜欢物品集合重合度来定义:
N(u)是用户u喜欢物品的集合。
2.基于图的社会化推荐算法
在社交网站中存在两种关系,一种是用户对物品的兴趣关系,一种是用户之间的社交网络关系,均可以用图上顶点之间的边来表示。用户和用户之间边的权重为用户之间相似度的α倍(包括熟悉程度和兴趣相似度),用户和物品之间边的权重为用户对物品喜欢程度的β倍。若将社群(即两个用户同属于一个群体)也考虑进来,加入一种表示社群的顶点即可,如下图所示:
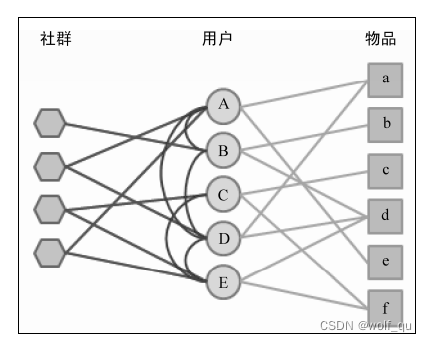
建完图之后使用personalrank算法即可。
3.信息流
EdgeRank算法考虑了信息流中每个会话的时间、长度与用户兴趣的相似度。将其他用户对当前用户信息流中的会话产生过行为的行为称为edge,一条会话的权重定义为:
其中指产生行为的用户和当前用户的相似度,主要为熟悉度;
指行为的权重,行为包括创建、评论、赞等不同行为权重不同;
指时间衰减参数,越早的行为对权重的影响越低。
此算法仅仅考虑了好友的影响,并没有考虑信息流的内容用户是否感兴趣,还应加入信息流内容用户是否感兴趣这一因素。
4. 给用户推荐好友
好友推荐系统的目的是根据用户现有的好友、用户的行为记录给用户推荐新的好友,从而增加整个社交网络的稠密度与活跃度。好友推荐算法在社交网络中被称为链接预测(link predicition)。
4.1 基于内容的匹配
给用户推荐和他们有相似内容属性的用户作为好友,常用的内容属性如下:
用户人口统计学属性,包括年龄、性别、职业、学校工作单位等;用户的兴趣,包括用户喜欢的物品和发布过的言论等;用户的位置信息等
4.2 基于共同兴趣的好友推荐
twitter和微博这样的社交网站并不关心两个用户现实中是否认识,而更看重两个用户的兴趣是否相似,根据两个用户的行为数据来判断兴趣是否相似,利用UserCF计算用户相似度即可。
4.3 基于社交网络图的好友推荐
可以根据用户之间的社交网络图,给用户推荐好友的好友。对于用户u和用户v,可以用共同好友比例计算他们的相似度:
out(u)是在社交网络中用户u指向的其他好友的集合。in(u)是社交网络图中所有指向用户u的集合。在qq这种无向社交网络中out(u)和in(u)是相同的集合,但是在微博这种社交网络中不同,因此可以通过in(u)定义另外一种相似度:
这两种相似度并不相同,表示两个用户关注的用户相似度,而
表示的是关注用户u和用户v的用户的集合重合度。这两种相似度都是无向的,即
,下面这个相似度是有向的:
这个相似度的含义是用户u关注的用户中有多大比例也关注了用户v。但是若v是一个明星,则关注v的人很多,即in(v)集合很大,因此相似度很高,考虑到这个问题,对公式进行改进:
这几种相似度计算并无好坏之分,根据数据集特征不同,所表现出的性能也不同。















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









