







 文章探讨了社交网络的定义、不同类型如信任网络和社交评分网络,以及如何利用它们进行推荐系统的设计。重点介绍了基于社交网络的影响因素、挖掘与建模方法,包括基于记忆和模型的推荐策略,以及处理不信任关系的挑战和解决方案。
文章探讨了社交网络的定义、不同类型如信任网络和社交评分网络,以及如何利用它们进行推荐系统的设计。重点介绍了基于社交网络的影响因素、挖掘与建模方法,包括基于记忆和模型的推荐策略,以及处理不信任关系的挑战和解决方案。
一、学习目标
1.了解社交网络的定义以及作用
2.挖掘与构建社交网络
3.学习基于社交网络的推荐系统
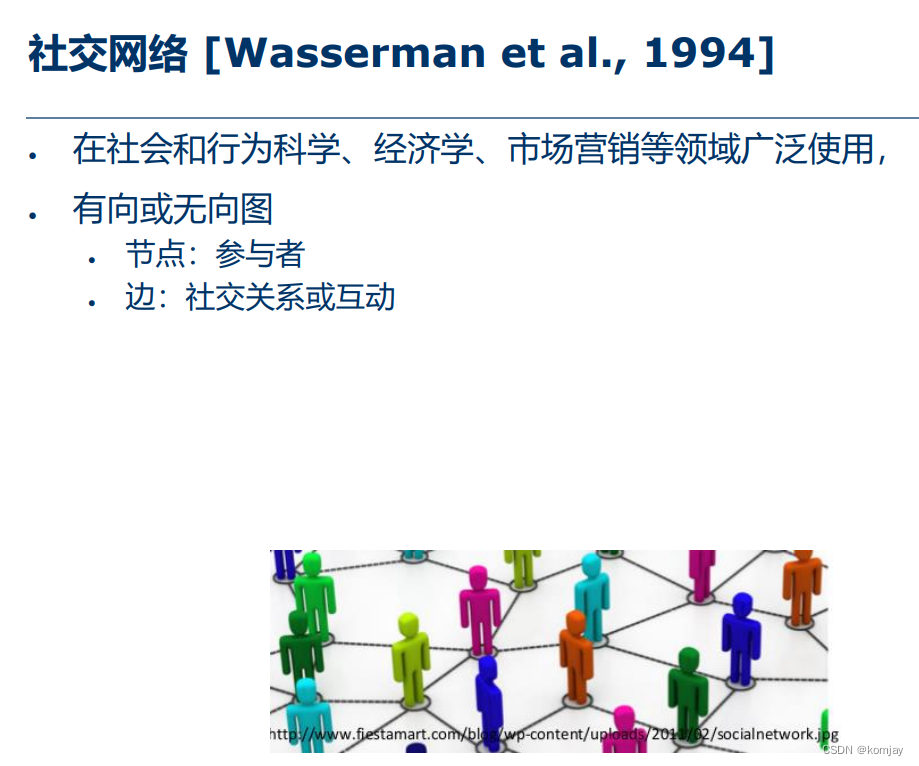
二、社交网络
社交网络,主要用于描述人之间的关系:
社交网络的形成因素主要有4种:个人兴趣、社会与资源交换(即交易行为)、同质性(与跟自己类似的人建立关系)、邻近性(地域上的邻近)。
1.信任网络
与一般的社交网络不同,信任网络主要建立用户之间的信任关系,主要应用在交易领域:

2.社交评分网络
社交评分网络是我们主要研究的对象,因为其有用户对物品的评分,我们可以根据他们的评分和用户关系来对推测其他用户的评分:

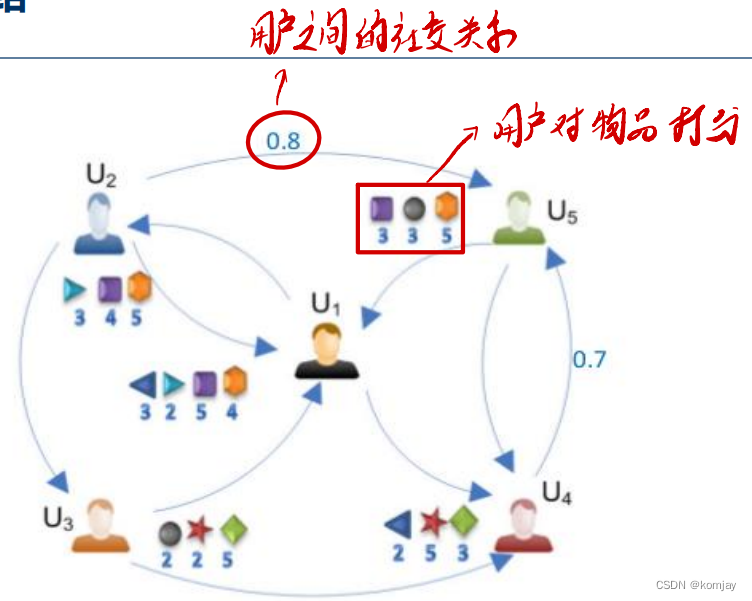
对于一些用户,他们不可能对所有的物品都有打分,于是为了给他作推荐(终极目标),我们可以预测他对所有物品的评分(短期目标)。虽然他没有对所有物品打分,我们就通过他朋友的打分来预测他的评分。
在SRN中,有着主要的4个影响因素:


运用这4条因素,并将其作为准则,可以帮助我们构建一个SRN并预测所有用户的评分。
3.好处与挑战
好处:

挑战:

三、社交网络挖掘与构建
在构建一个社交网络前,我们需要对前面讲的四个影响因素进行建模,前两个因素(社交影响和相关影响)用于确定当前用户的评分,后两个因素(选择效应和传递性)用于预测两个用户之间的关系。
1.社交网络挖掘
在这里主要讲两篇文章,Influence and Correlation一文主要证明了社交网络中,社交相关性明显,但社交影响力表现差,即我更受其他用户(跟我相似但不一定朋友)影响,而我的朋友对我的影响小。
反馈效应在相似性和社交影响之间的作用一文,主要证明了:
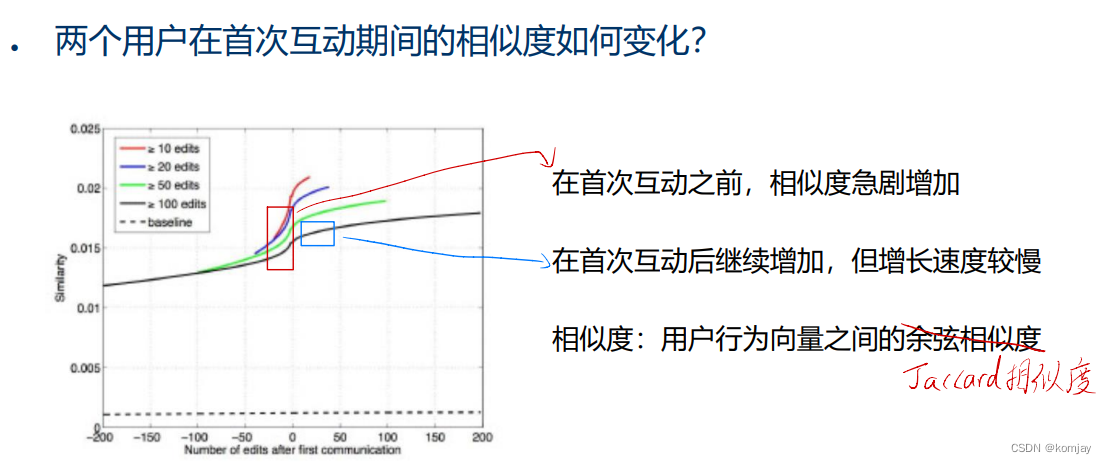
总体而言,两文主要证明了基于四因素来构建社交网络的正确性。
2.社交网络建模

首先需要明确一点:社交网络建模所需要的数据集是一系列的用户行为,主要分为“ 社交”(加好友)和“评分”两种行为,再通过概率建模与计算去预测其进行那种行为,受体对象是谁。整体结构如下::
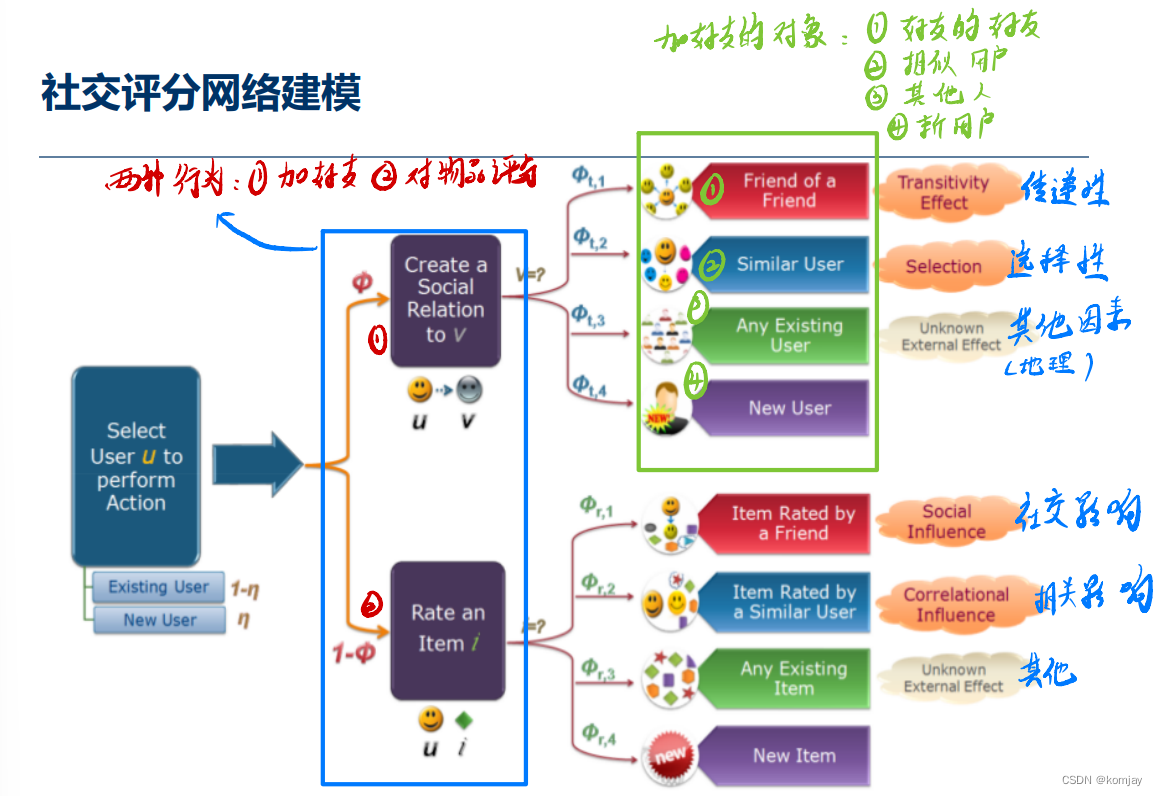
之后就是计算两种行为的似然概率,就可以用最大似然估计等方法来训练模型:(绿色的4个概率对应上图的绿色的4个社交对象)

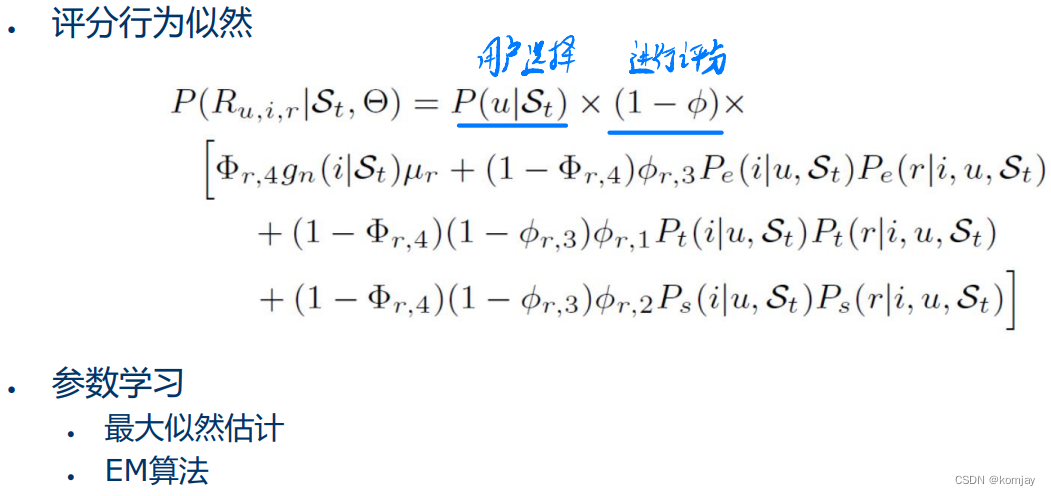
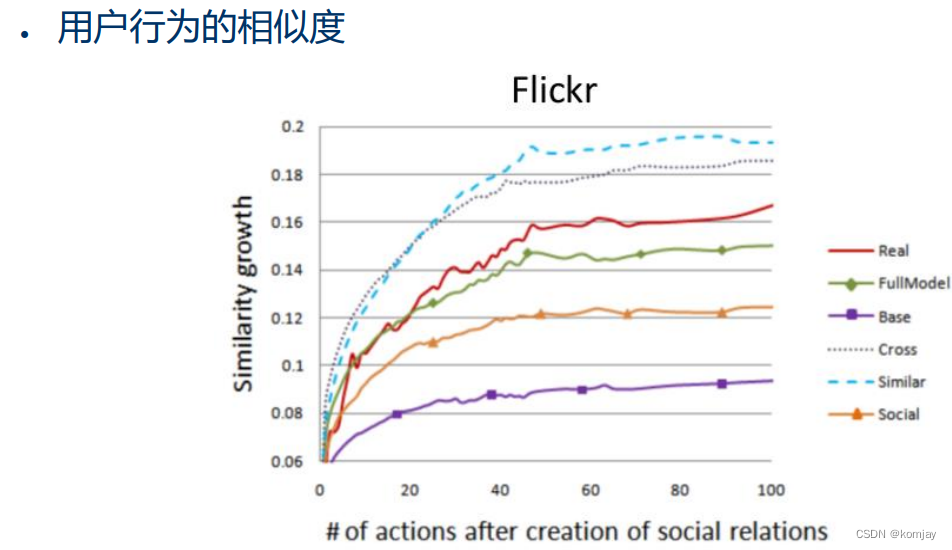
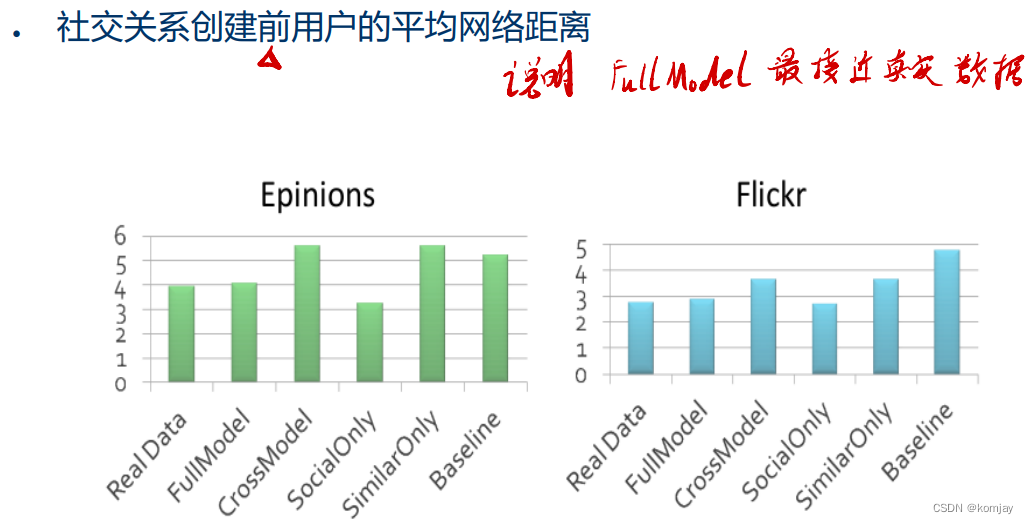
在结果中,实验证明了本文的模型FullModel各项指标是最接近实际情况的:
3.社交网络推断
与社交网络建模相似,目标也是构建一个社交网络,但不同在于,在建模一文中,其原始数据是包含了一个基础的社交网络,并不是从0开始构建。而社交网络推断,是要从用户行为中,从0开始构建网络:
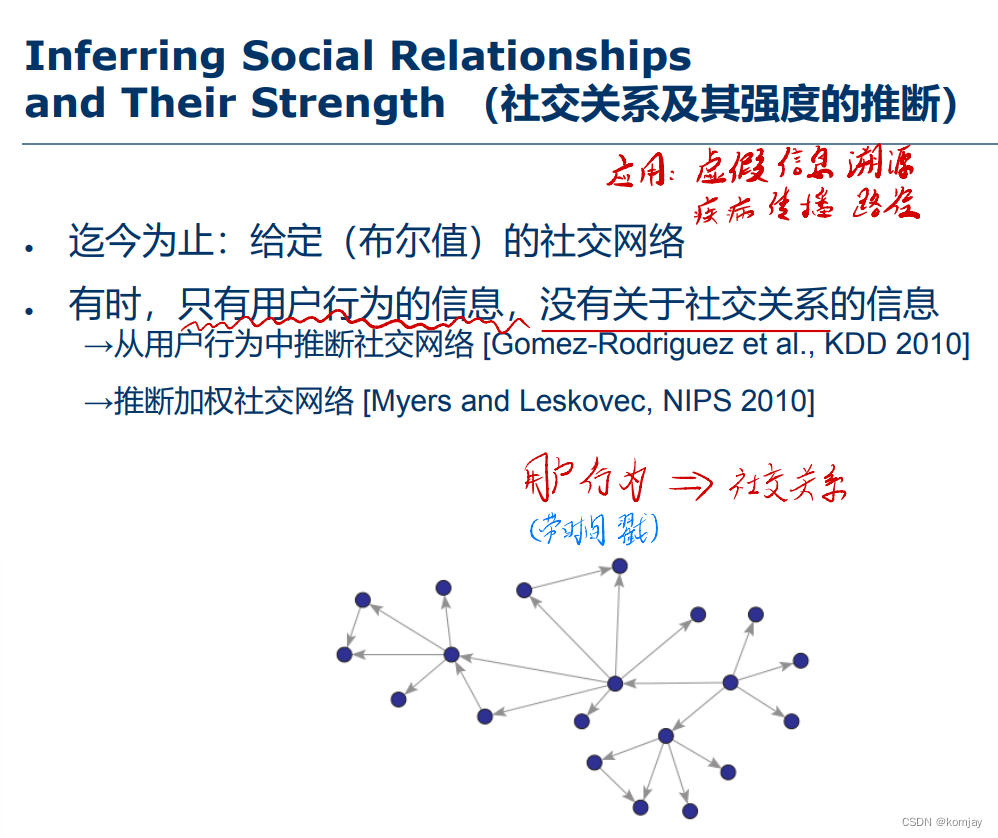
相比于建模,推断还有一个好处:有目标函数,虽然只能用贪心算法求解。而对比推断的两篇文章,加权的创新在于其建立了一个传播时间模型,这个时间模型就是将一个用户影响到其朋友的时间差作一个概率分布。
四、基于社交网络的推荐方法
有了社交网络后,终于来到我们推荐系统的内容中了,而相对而言,这部分内容是简单的。因为从社交网络中就能得到很多信息,只是如何使用这些信息的问题。对问题进行定义,可以归结为下图:
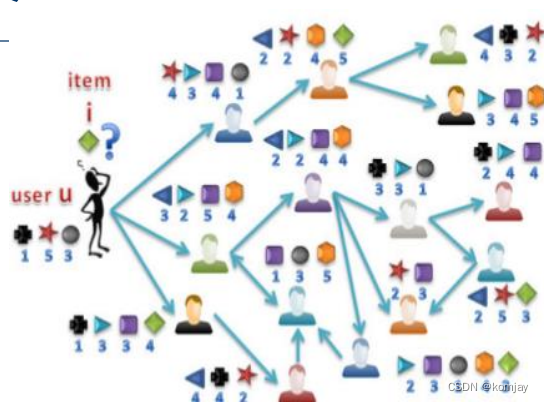
该节中,我们介绍两种推荐系统:基于记忆的和基于模型的。
1.基于记忆的方法
主要内容可归结为以下三条准则:

接下来列举几种不同的方法实现的推荐系统:
a)Advogato
Advogato方法核心是用一个信任度量指标来计算最可信的N个用户。但是用最大流的思想来计算这个信任度量指标。还有的技术细节有:分点(目的应该是将点的出度和入度分开,A-只有出度,A+只有入度)和设置超级汇点:
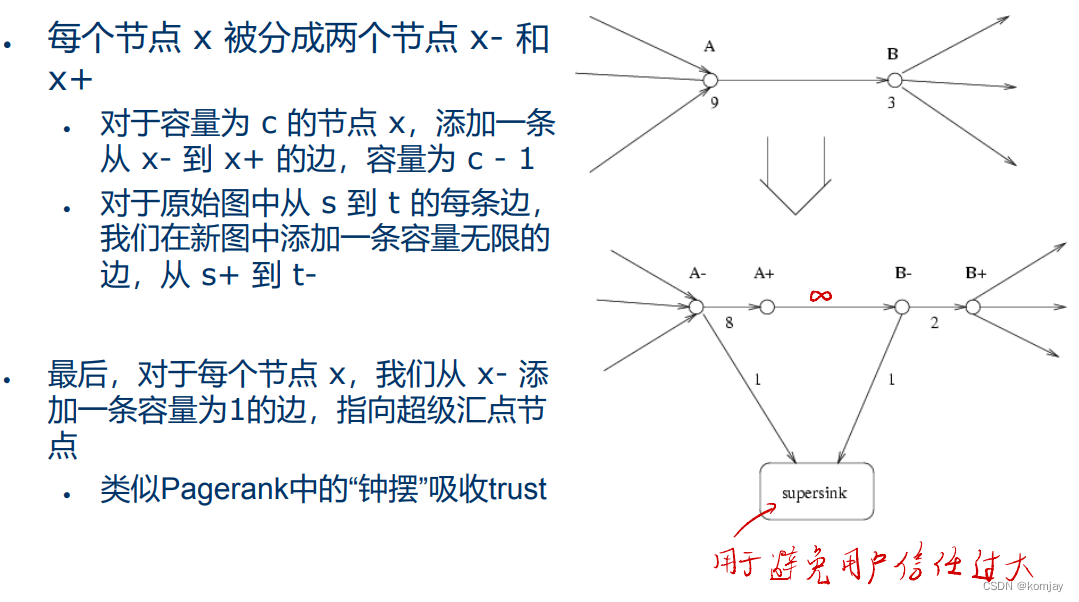
然后从任意节点负向点出发,找到到达超级汇点的最大流量的一条路径,再这条路径上选择前n个作为受信任用户。
优点:去中心化、动态的信用网络、透明简单。
缺点:有被操纵的风险、新用户难以提升网络地位。
b)AppleSeed
提出了一个新思想:用户的信任由其他节点提供。
c)TidalTrust
在b)的基础上,其可以计算网络上任意两个节点之间的信任程度,核心思想如下:(Nu表示u用户邻居。这条公式在网络中需要迭代更新,最后会收敛)

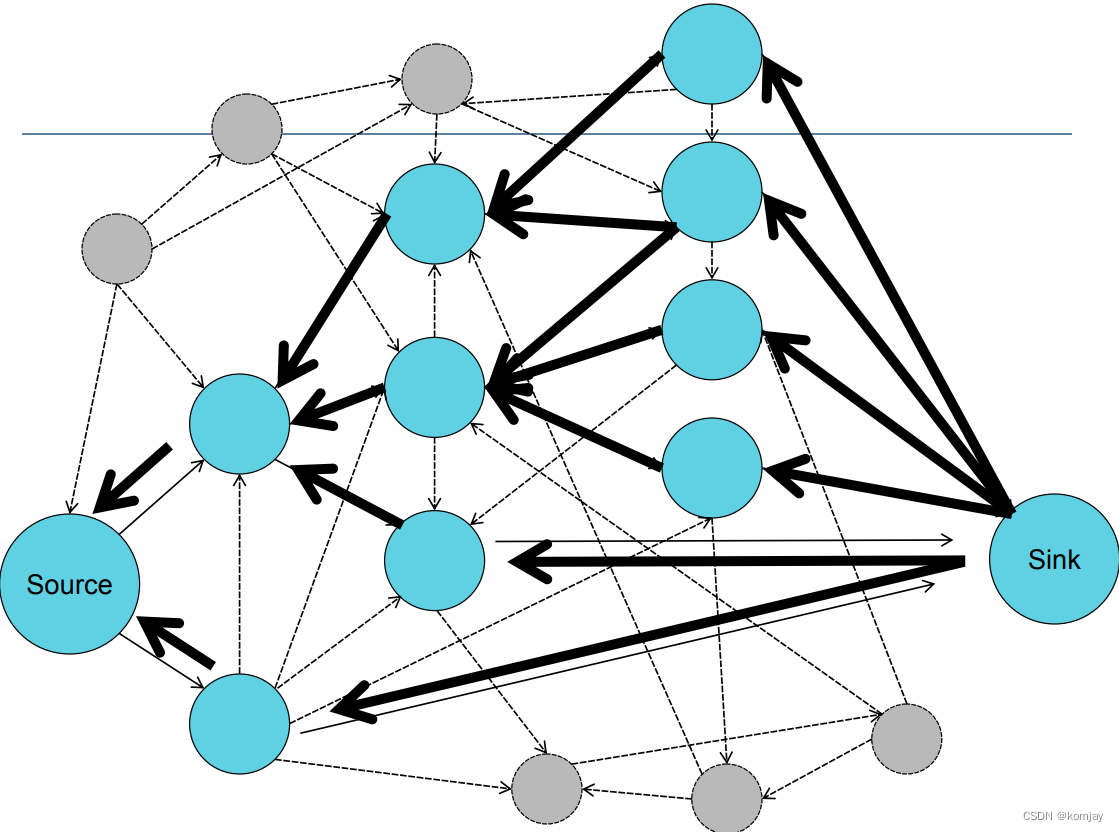
有信任程度后,就可以预测u用户对物品i的评分:

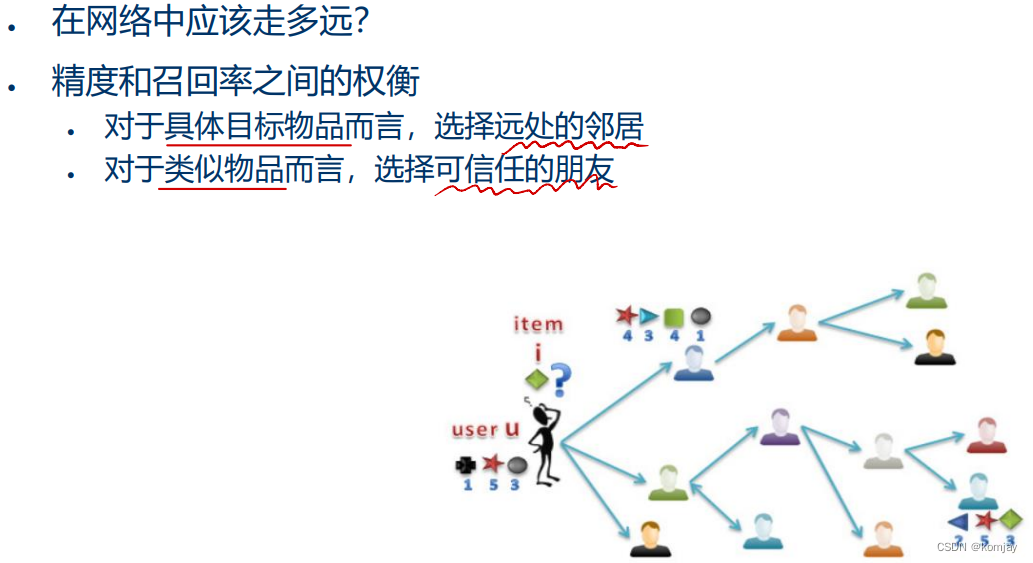
d)MoleTrust

关于d的设置,该方法也得到了一个结论:(其中,远处的邻居指的是:与当前用户有多跳的距离,不是朋友,但评分风格十分相似,兴趣上的“邻居”)
e)TrustWalker

显然,关键技术在于其游走策略:
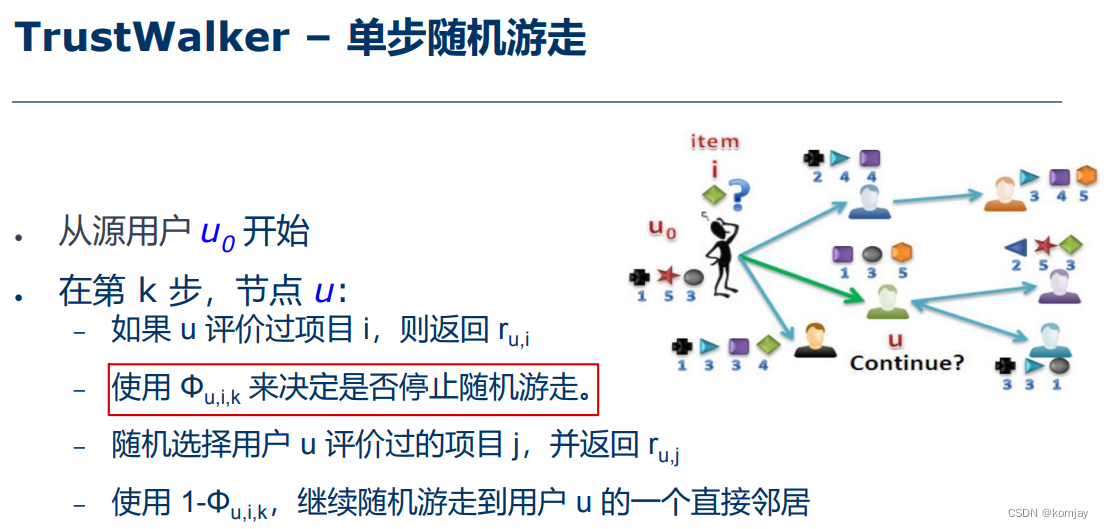
对于停止游走概率的建模,则是:

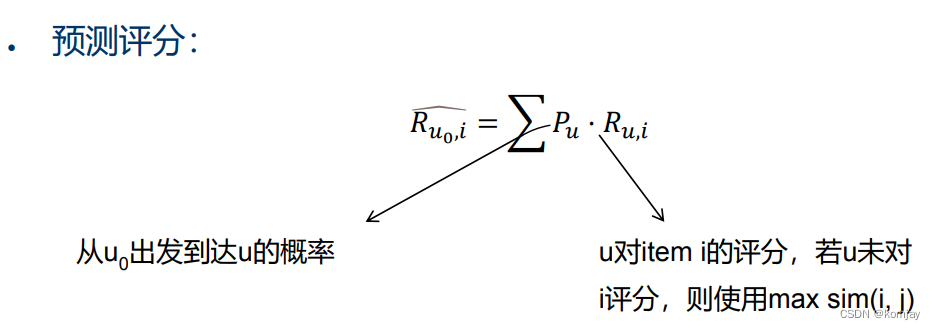
最后进行预测评分:
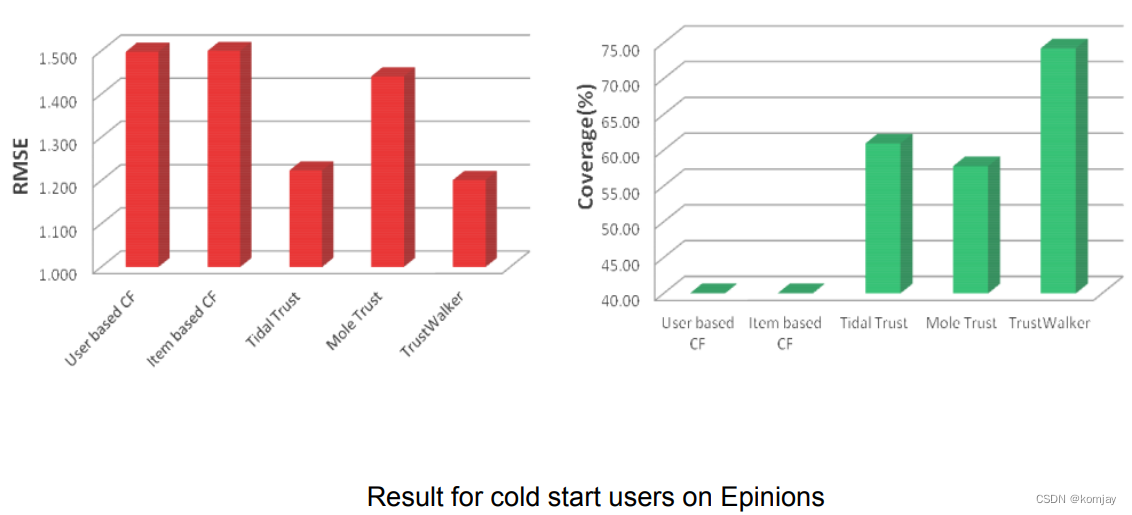
f)总结对比:
TrustWalker有着最低的错误率和最高的正确率。
总结基于记忆的方法,其特点有:不需要学习模型,只是探索网络以查找评分者;需要存储社交评分网络;由于需要探索,在线预测消耗时间长。
2.基于模型的方法
基于模型的方法就是要将物品和用户都向量化,然后好方便预测用户的未知评分。
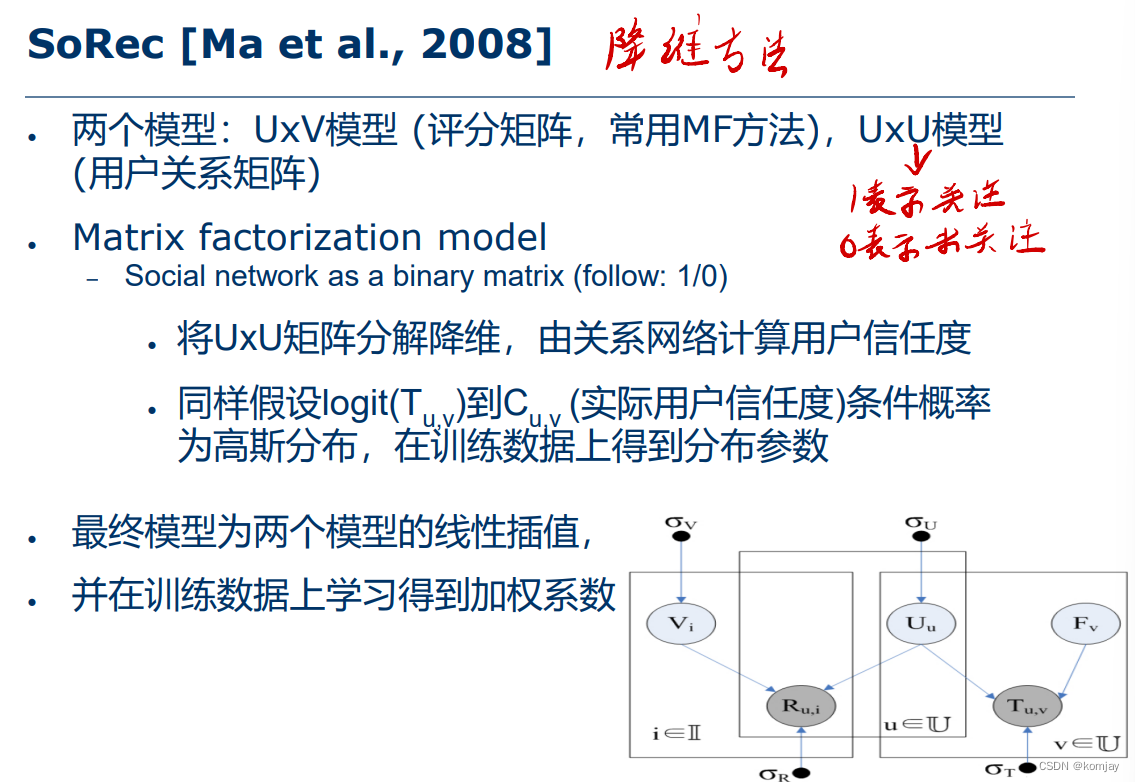
a)SoRec
一种通过降维获取用户向量、物品向量的方法。
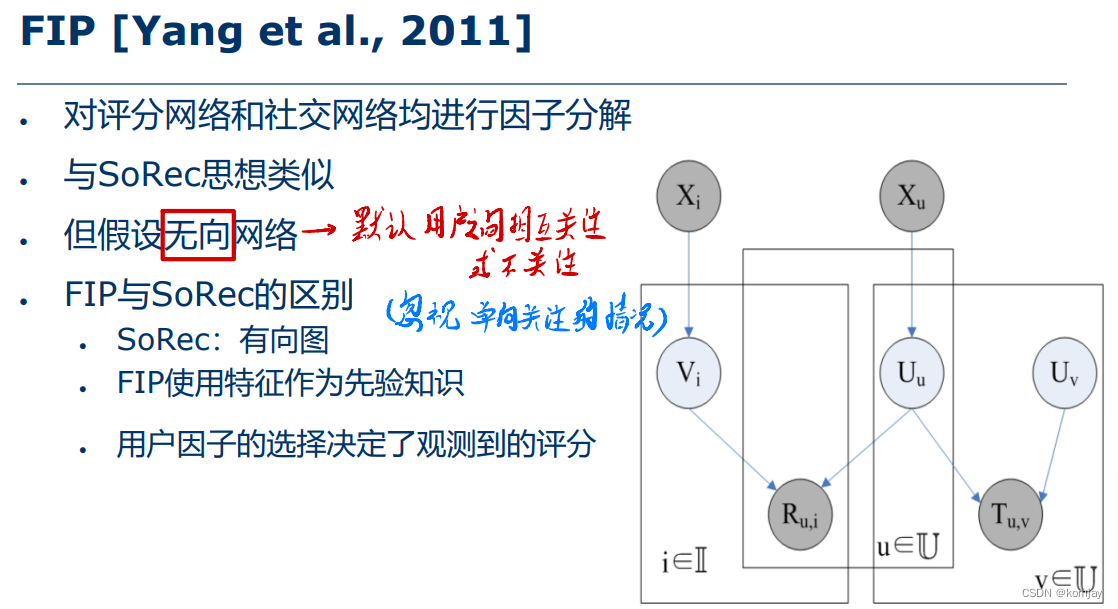
b)FIP
在SoRec的基础上,加入了对评分网络和社交网络进行因子分解。
c)社交信任集成

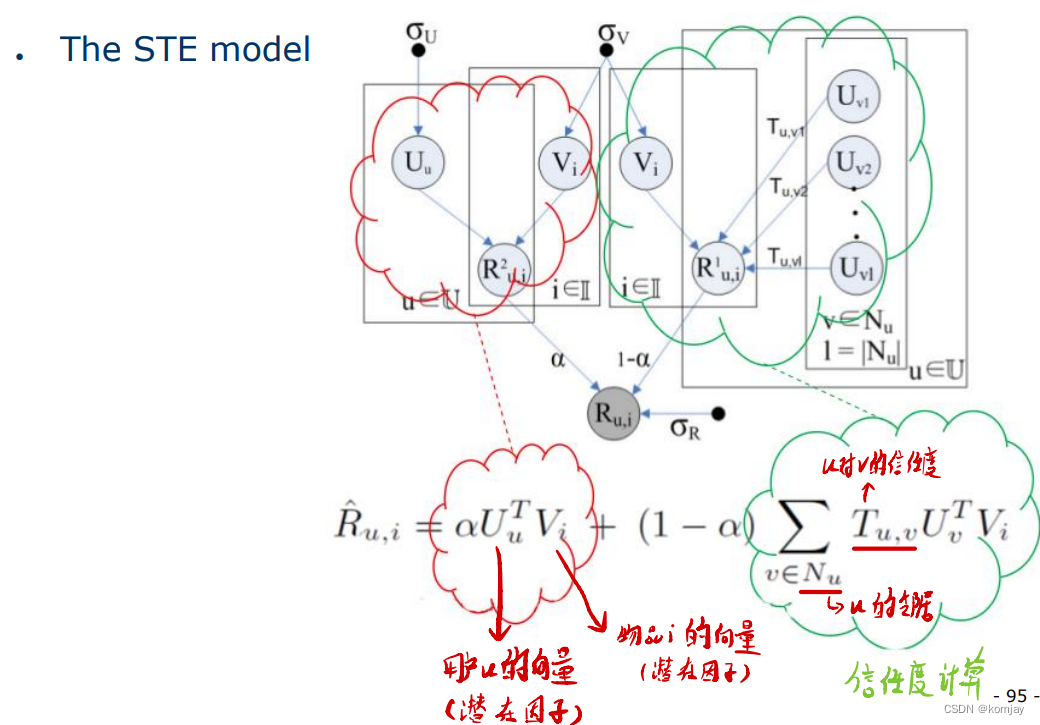
而显然,STE存在一个比较原则性的问题:

d)SocialMF
解决上面提到的问题:

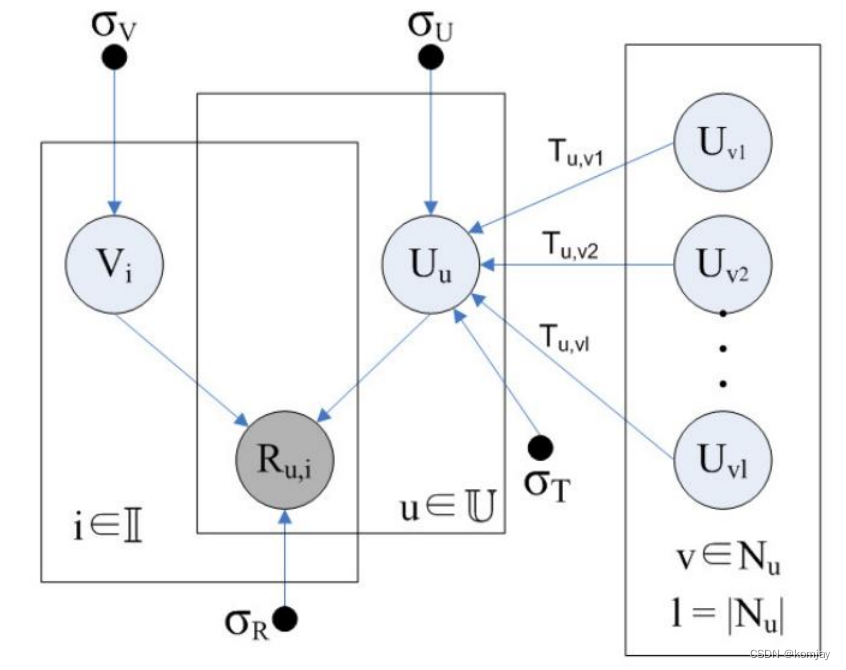

总结而言,SocialMF拥有最优的表现。
五、具有不信任关系的社交网络
不信任关系,特指“拉黑”这种社交行为,由于很多模型不支持负值计算,所以带来了许多挑战。其中,最简单的方法就是进行平移。但也有别的设定方法:
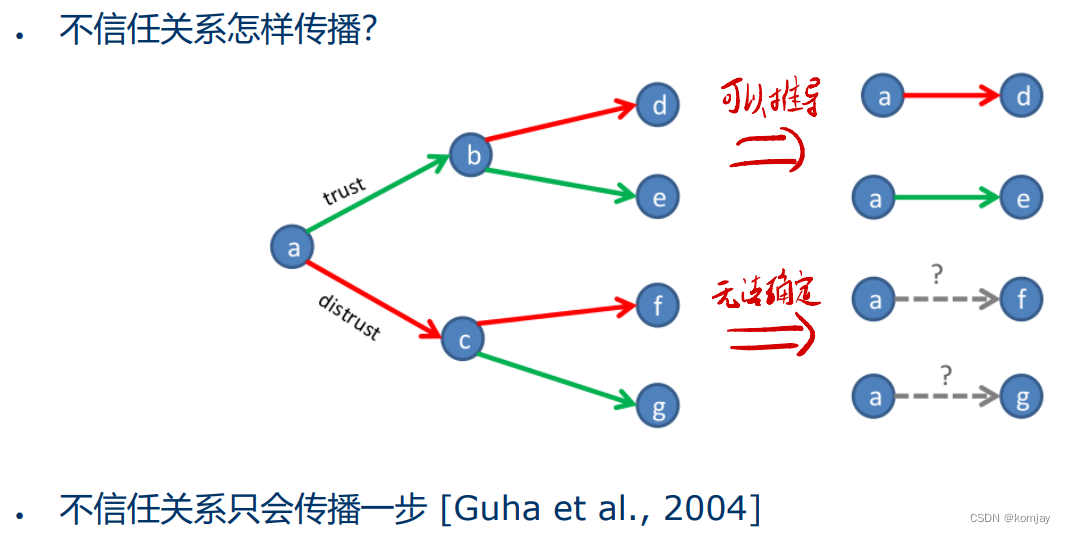
以及通过社会关系分析得出稳定结构的概念:
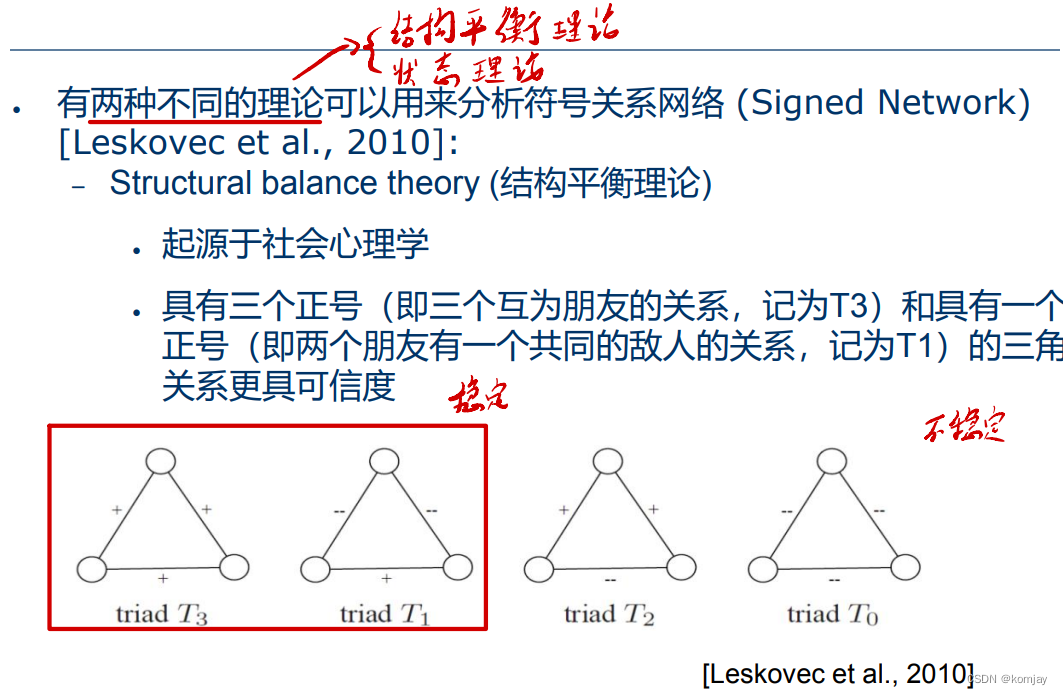
还有状态理论:

这两套理论后面被证明各有优势:

最后再讲解一个矩阵分解模型:


六、总结



















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









