






Genomics, Proteomics & Bioinformatics(GPB) 在线发表了中国农业科学院特产研究所邢秀梅研究员课题组和中国农业科学院农业基因组研究所阮珏研究员课题组题为“The First High-Quality Reference Genome of Sika Deer Provides Insights for High-Tannin Adaptation”的研究论文。我们的“要文译荐”栏目很高兴邀请到文章的第一兼通讯作者邢秀梅研究员为大家解读关于梅花鹿耐受毒性食物的分子机制的研究情况。

要点介绍

研究问题:
梅花鹿主要分布于东亚地区,是世界著名的鹿种之一,其生产的鹿茸是一味名贵的中药材。另外,梅花鹿在研究鹿群体进化、物种适应性和生物医学领域也具有重要价值。栎树叶是梅花鹿的主要食物来源,但是栎树叶所富含的单宁酸对大多数哺乳动物都是有毒性的,而梅花鹿食用栎树叶却不中毒。高质量的梅花鹿基因组参考序列的建立结合转录组分析,有助于我们回答梅花鹿对丛林生活的适应性进化,以及有毒的食物在梅花鹿体内的独特代谢和解毒途径。
研究方法:
采集吉林省一头雌性梅花鹿血液样本,对该样本进行高深度测序,具体包括:约57.7x Pacbio long reads和100.6x Illumina PE测序数据。测序数据使用wtdbg软件初步组装得到梅花鹿基因组,并使用Hi-C测序技术将梅花鹿基因组组装至染色体水平。同时对12只梅花鹿进行了不同单宁含量的饲养实验,并对梅花鹿的15个组织进行了RNA测序,共得到1.44 Tb转录组数据。
主要结果:
组装得到目前已知最高质量的梅花鹿全基因组序列,序列总长约2.5 Gb,染色体水平基因组scaffold N50达到78.8 Mb。
梅花鹿群体的地理分布与栎树的生长分布具有高度的一致性,并且梅花鹿对高单宁含量饲料(以栎树叶为主)的耐受性较高。
UGT基因家族特别是UGT2B基因在梅花鹿基因组中显著扩张。
UGT基因家族在梅花鹿肝脏中呈显著的高表达,阐述了UGT基因家族参与梅花鹿单宁代谢的可能分子机制。
数据链接:
基因组数据链接:https://ngdc.cncb.ac.cn/gwh/GWHANOY00000000
测序数据链接: https://ngdc.cncb.ac.cn/gsa/CRA001393;https://ngdc.cncb.ac.cn/gsa/CRA002054;https://ngdc.cncb.ac.cn/gsa/CRA002056

背景和研究对象

梅花鹿(Cervus nippon)自然群体分布于东亚地区,是生产鹿茸的著名鹿种之一,而鹿茸是我国传统的名贵动物药材(图 1)。梅花鹿具有一些独特的习性,例如其地理分布明显与栎树更一致,并且能够耐受主要由栎树叶组成的高单宁饮食。

图1 野生梅花鹿在丛林中生活
栎树叶富含单宁酸,对牛、羊等大多数哺乳动物具有毒性,但人们在梅花鹿养殖过程中却发现栎树叶可以提高梅花鹿的繁殖率和仔鹿的成活率。因此,栎树叶对于维持野生和养殖梅花鹿的健康至关重要。然而,有关梅花鹿高单宁饮食解毒的分子机制方面的研究比较缺乏。
全基因组测序技术可以在分子水平上探索生物的分类、进化和环境适应性等生物学问题。先前研究通过比较分析9种鹿科动物和其他多种反刍动物物种的基因组,发现了反刍动物角的形成、鹿茸的快速再生等相关基因 (Chen et al, 2019; Wang et al , 2019)。而梅花鹿染色体水平基因组参考序列的构建将为我们了解梅花鹿的特殊特征提供新的见解和分子进化信息。

主要结果

1、梅花鹿参考基因组的从头测序和组装
我们使用wtdbg软件对PacBio reads进行组装,得到2040个contig序列,利用Hi-C技术将contigs聚类成染色体水平,并使用自编脚本进行了全基因组水平的纠错与校正,得到最终的参考基因组MHL_v1.0。该参考基因组序列总长2.5 Gb , contig N50为23.6 Mb , scaffold N50为78.8 Mb。总序列中99.24% 的序列挂载至染色体上。
我们比较了MHL_v1.0与已发表的马鹿基因组以及Hi-C热图密度图的不合理性 , 确定了基因组中34处不准确的连接,并通过总计264 Gb的Bionano光学图谱数据来判断34个不准确连接的真实性(图 2)。对不准确的连接进行了人工检查和校正。另外,我们从NCBI dbEST数据库中下载了2715条梅花鹿EST序列,并将其比对至MHL_v1.0。95.95%的EST序列与MHL_v1.0相匹配(覆盖率> 90%)。利用CEGMA 软件评价MHL_v1.0 , 248个核心基因集中有97.18%的基因全长被预测。BUSCO评估分析显示,完整的BUSCO占3880个(94.60%)基因,优于水牛(Bubalus bubalis,93.6%)和山羊(Capra hircus,82%)基因。单碱基水平错误率约为1.1E-5(表 1)。
表1 梅花鹿基因组和已发表最好的马鹿基因组的
基因组质量比较
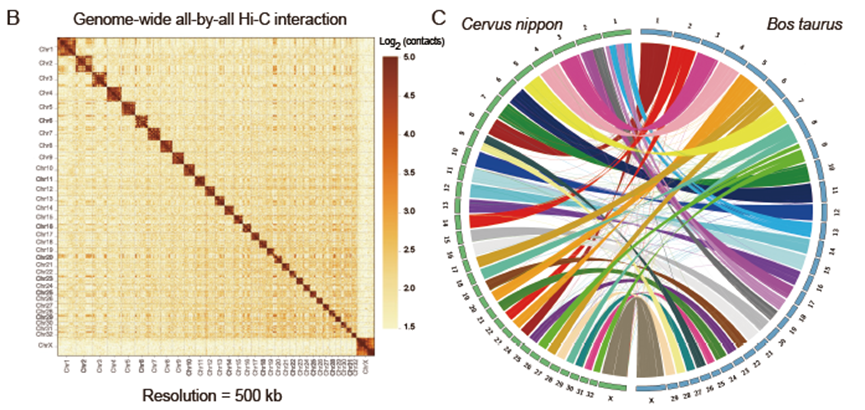
图2 梅花鹿基因组Hi-C热图及梅花鹿基因组与牛基因组的共线性
2、梅花鹿基因组中UGT基因家族的显著扩张
我们评估了19个物种同源基因家族的扩张和收缩。尿苷5'-二磷酸葡萄糖醛酸转移酶(UDP-glucuronosyltransferase, UGT)基因家族在879个显著扩张的基因家族中位于第27位。系统发育分析显示,19个物种的257个UGT基因可分为7个亚家族,而在MHL_v1.0中,我们发现两个亚家族发生了明显的扩张,即UGT2B亚家族和UGT2C亚家族。MHL_v1.0中UGT2B家族有15个基因,超过了本研究中使用的其他18个物种中UGT2B亚家族的基因数量。梅花鹿、黄牛、山羊和绵羊的基因共线性分析显示,梅花鹿27个UGT基因中有23个分布在27号染色体上,UGT2B亚家族的扩张可能来源于基因复制事件(图 3)。哺乳动物体内主要的解毒反应传统上分为I期和II期反应,已有研究表明UGT基因家族在外来毒性物质代谢中起着最重要的作用。这些结果提示,梅花鹿UGT基因家族的异常扩增可能是梅花鹿耐受高单宁性食物——栎树叶的关键遗传基础。
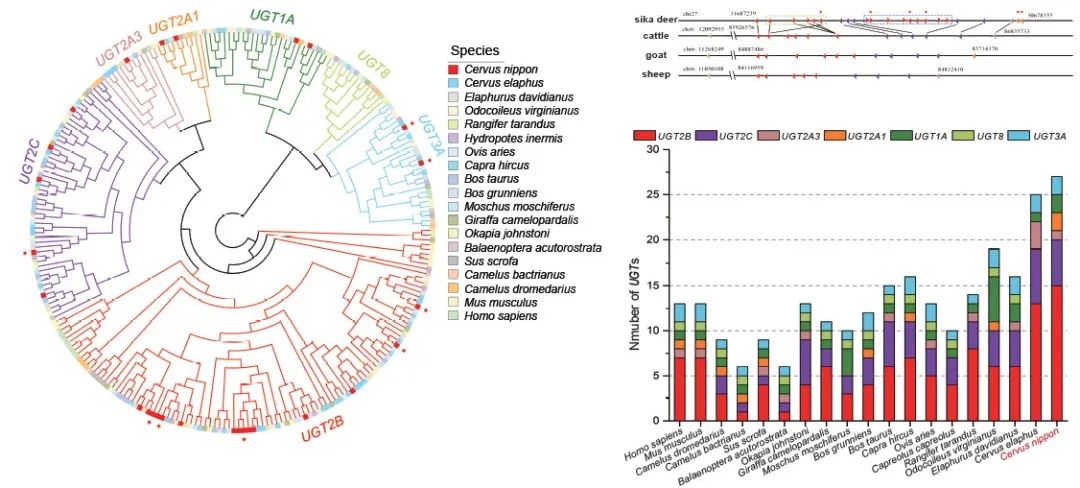
图3 UGT基因家族在梅花鹿基因组中的扩张
3、转录组实验揭示了高单宁饮食中重要的差异表达基因
梅花鹿适应了丛林生活,长期以高单宁含量的蒙古栎(Quercus mongolica)叶片(MOL)为食 , 潜在的遗传适应和分子机制是否与UGT基因家族的特殊扩增有关是一个有趣的问题。我们选取了9只育成鹿,分别饲喂不同的单宁含量(0%、50%、100%)饲粮,3只成年鹿(100%)作为对照组。对所有实验个体的15个组织进行转录组测序。
通过对肝组织中所有扩张/收缩基因家族和差异表达基因(DEG)的检测,发现在P450通路中有20个为扩张基因,12个为DEG。在这些关键基因中,6个UGT 基因(2个UGT2B4,3个UGT2B31和1个UGT2C1)在高单宁喂养组的肝组织中显著上调表达,且这6个显著上调的差异表达UGT基因分布在27号染色体,其中3个基因与基因复制有关。因此,我们推测UGT2B4和UGT2B31的复制和高表达可能是梅花鹿适应高单宁的主要原因。
有趣的是,在肝组织中,单宁可以以剂量依赖性的方式驱动许多UGT基因的表达。在不同MOL水平和年龄之间,我们发现了8个差异表达的UGT基因,其中6个是UGT2B和UGT2C亚家族的上调基因,这些上调的UGT基因都位于梅花鹿27号染色体上。随着单宁摄入量的增加,肝脏中UGT基因对单宁的响应主要是上调表达(图 4)。
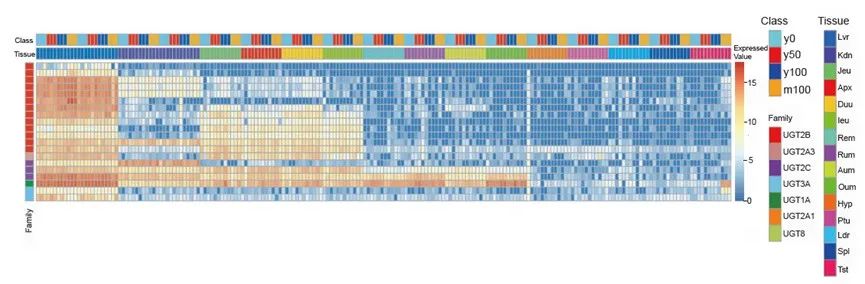
图4 梅花鹿UGTs基因在不同组织及处理中的表达热图
4、UGT基因的高表达和扩张有助于耐受高单宁饮食
通过分析UGT基因在梅花鹿中的表达水平,我们发现UGT基因在肝脏组织中具有较高的表达水平,这与它们的解毒作用一致。UGT基因的表达产物为尿苷-5'-二磷酸葡萄糖醛酸转移酶。其作用机理是催化葡萄糖醛酸基从尿苷5'-二磷酸葡萄糖醛酸(UDPGA)中转移到外源因子,生成比外源因子更极化、更容易排泄的糖醛酸化代谢产物,从而完成葡萄糖醛酸化反应,实现解毒功能(图 5)。UGT基因的表达上调会导致酶水平升高,从而增强梅花鹿对高单宁日粮的解毒能力。
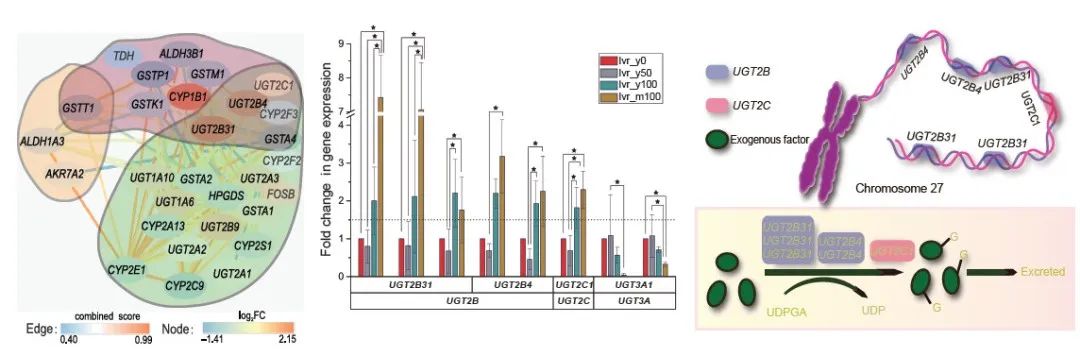
图5 UGT基因的扩张、上调表达与梅花鹿的高单宁适应

总结与展望

本研究利用Pacbio SMRT、Illumina测序和Hi-C技术对梅花鹿的基因组进行测序,并完成了染色体水平的组装。基因组结构、单碱基检测、基因集验证和基因注释质量的高百分比和准确率表明,我们构建的梅花鹿基因组具有较高的质量,可以有效地作为梅花鹿物种的参考基因组。
梅花鹿基因组的综合特征和转录组数据为阐明其进化事件提供了一个研究基础,揭示了梅花鹿独特的习性和单宁适应机制。通过详细的基因组学和转录组学分析,我们确定了梅花鹿中鞣质物质降解的可能机制。本文所采用的研究方法也将为研究动物对“有毒”食物的适应机制提供参考。梅花鹿基因组的染色体规模组装序列可用于许多领域,包括研究基因组区域的结构变异、特定基因组区域的预期重组频率、目标序列特征和基因编辑修饰等。
中国农业科学院特产研究所邢秀梅、杨福合、李春义,中国农业科学院农业基因组研究所阮珏和诺禾致源梁齐齐是本文的通讯作者。中国农业科学院特产研究所王天骄、李洋、刘汇涛、胡鹏飞、王桂武和中国农业科学院农业基因组研究所艾成为本文的第一作者。该研究得到中国农业科学院创新工程(2018YFD0502204)、中国梅花鹿基因组计划(20140309016YY)等项目经费的支持。
文章编译来源:
Xing X, Ai C, Wang T, Li Y, Liu H, Hu P, et al. The First High-quality Reference Genome of Sika Deer Provides Insights for High-tannin Adaptation. Genomics Proteomics Bioinformatics 2022. https://doi.org/10.1016/j.gpb.2022.05.008.
英文全文详见:https://www.sciencedirect.com/science/article/pii/S1672022922000754
GPB论文:
The First High-Quality Reference Genome of Sika Deer Provides Insights for High-Tannin Adaptation
长按并识别二维码,阅读全文

推荐阅读
GPB | 基于HiFi和ONT超长读长的拟南芥高质量基因组组装
GPB | 沿生活方式梯度的肠道微生物组变化研究揭示了亚洲象面临的威胁

About GPB
Genomics, Proteomics & Bioinformatics (基因组蛋白质组与生物信息学报,简称GPB)于2003年创刊,是由中国科学院主管、中国科学院北京基因组研究所(国家生物信息中心)与中国遗传学会共同主办的英文学术期刊,由Elsevier金色开放获取(Gold Open Access)出版。刊载来自世界范围内组学、生物信息学及相关领域的优质稿件。现为中国科学引文数据库(CSCD)和中国科技论文与引文数据库(CSTPCD)核心期刊,被SCIE、PubMed / MEDLINE、Scopus等数据库收录。2023年公布的官方数据显示,CiteScore为11.7;2年和5年Impact Factor分别为9.5和10.1,分别排名WoS遗传学领域12/171和13/171;2022 JCI为2.08,排名WoS遗传学领域10/189。期刊由科技部等七部门联合实施的 “中国科技期刊卓越行动计划” 资助(2019–2023)。

猜你喜欢
iMeta简介 高引文章 高颜值绘图imageGP 网络分析iNAP
iMeta网页工具 代谢组MetOrigin 美吉云乳酸化预测DeepKla
iMeta综述 肠菌菌群 植物菌群 口腔菌群 蛋白质结构预测
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature
一文读懂:宏基因组 寄生虫益处 进化树 必备技能:提问 搜索 Endnote
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流快速解决科研困难,我们建立了“宏基因组”讨论群,己有国内外6000+ 科研人员加入。请添加主编微信meta-genomics带你入群,务必备注“姓名-单位-研究方向-职称/年级”。高级职称请注明身份,另有海内外微生物PI群供大佬合作交流。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍未解决群内讨论,问题不私聊,帮助同行。
点击阅读原文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









