






目录
A.写在前面
ViTDet[1] 其实就是MAE[2] 和ViT-based Mask R-CNN[3] 两项工作的衍生。
MAE提出了一种 ViT 视觉模型的生成式训练方法。ViT-based Mask R-CNN (后称MViTv1) 给出了使用ViT作为backbone的Mask R-CNN目标检测模型可以work的实现途径,并证明MAE对其性能的保证和提升。而ViTDet就是在上面提到的这些基础上,进一步改善ViT-based Mask R-CNN,通过对RPN部分优化提升其竞争力。
简单说,顺序为Mase R-CNN --> MAE --> MViTv1 --> MViTv2 --> ViTDet,后文再对这其中涉及到的实现细节解释。下图是MViTv1和ViTDet的主体结构的对比。
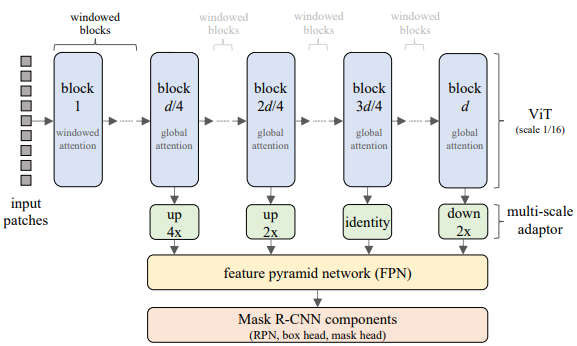
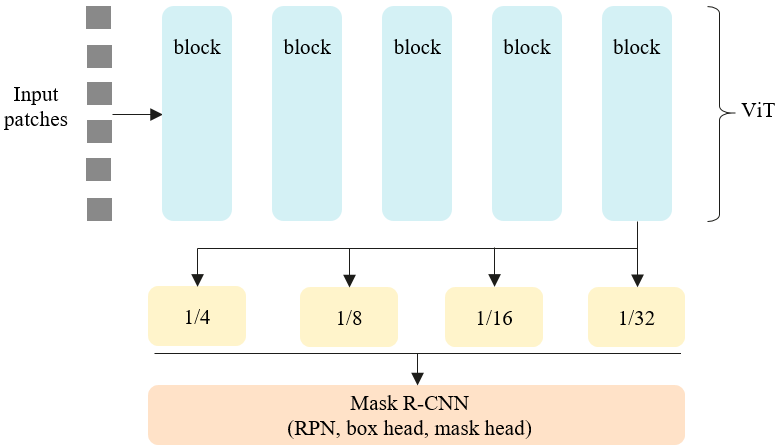
ViTDet (ViT-H版本)应该是我第一次见到在COCO上APbox刷到60的 (Single-scale test),充分证明了base Transformer模型的潜力。
题外话:
ViTDet的Github主页中写着:"The above models were trained and measured on 8-node with 64 NVIDIA A100 GPUs in total. *: Activation checkpointing is used.",是真的震惊,普通人玩深度学习真是越来越难了。
B.有个工作我得说说
Base Tranformer的目标检测工作还有另外一种路线,就是DETR [4] 系列。关于DERT系列和其他系列目标检测的对比我之前还有说过 [5]。DETR系列的目标检测系列也很有看点,基于此近期还有一个称为DINO [6]的工作,DINO做出了APbox63.3的结果。
C.摘要拆分
Abstract: We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 APbox on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors.
1.保持原有的不分层级的ViT结构去做目标检测。
2.在实现上一过程中发现,只需要从但尺度特征图中建立一个简单的特征金字塔SFP(没有常规的FPN过程)以及使用一个带有很少交叉窗口的传播模块的不带有偏移的窗口注意力过程即可使整个结构Work。
3.ViTDet在ImageNet-1K上预训练后于COCO上达到了61.3 APbox(Multi-Scale test),证明了plain-backbone的潜力。
摘要很简洁,主要是提醒读者关注SFP和window attention两部分。
D.先看看结果
因为APbox上60的模型不多,迫切的想对比一下实验数据。
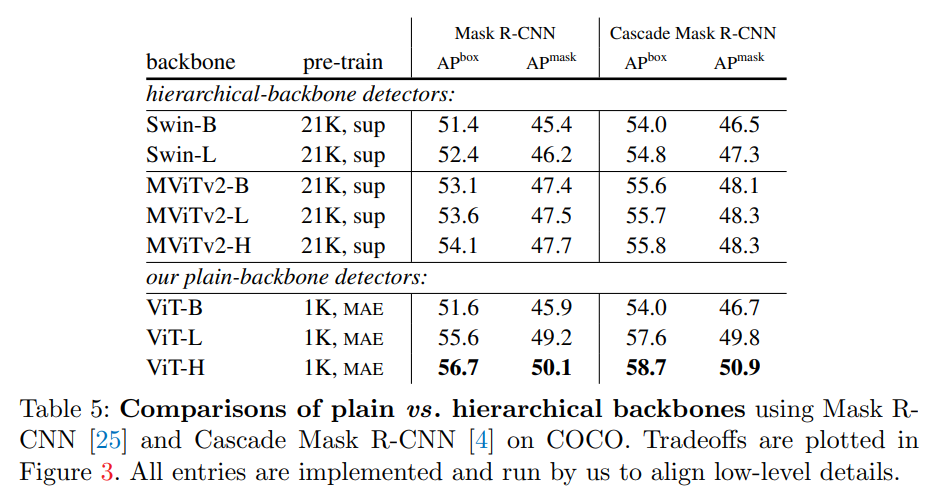
Table5是文章给出的参考试验结果,Github主页中给出的也是该试验结果的网路权重。对于hierarchical-backbone detectors(层级类backbone的目标检测器),给出Swin的B和L两个版本以及MViTv2的B、L、H三个版本的APbox和APmask试验数据。对于plain-backbone detectors给出B、L、H三个版本的试验数据。可以看到ViT-L的APbox就已经全面超越了层级类backbone的目标检测器。
这里的监督型的检测器都是带有FPN的,ViTDet带有SFP。
另外,监督型的检测器是在ImageNet-21K中进行的,MAE是在ImageNet-1K中进行的。
而横向对比,普遍Cascade Mask-RCNN的效果要比MaskR-CNN高一些。
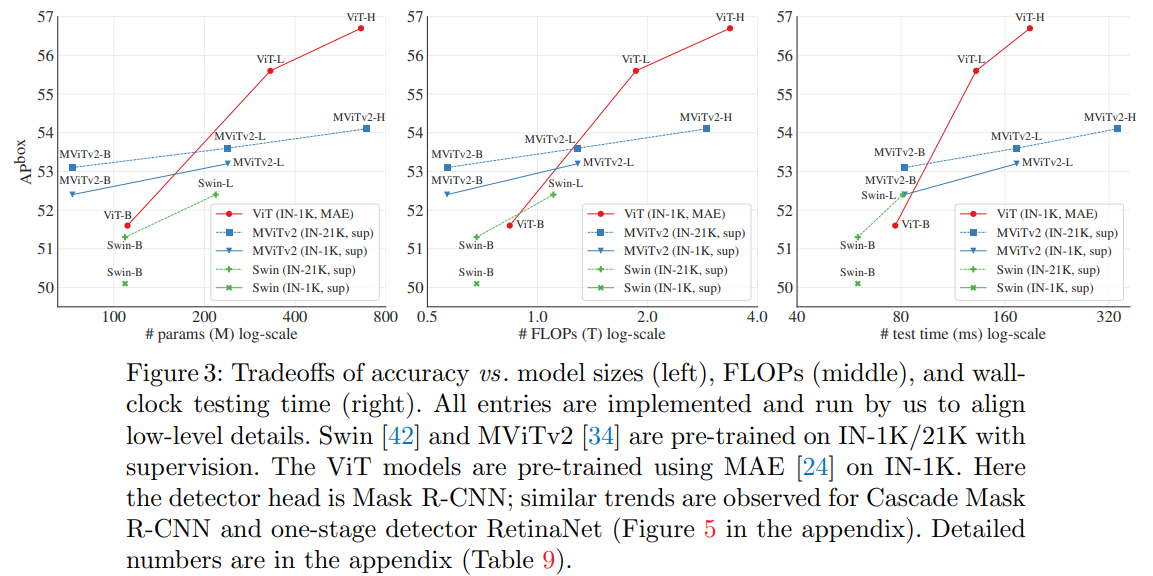
Figure3从左向右依次展示了APbox与params、FLOPs、test time之间的关系。
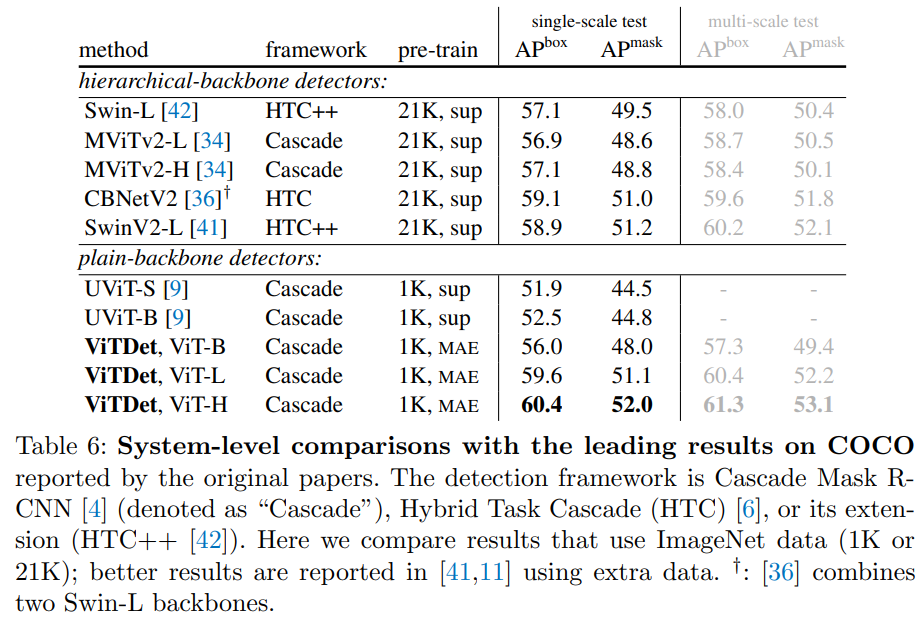
摘要中给出的最好结果也就是APbox61.3,他来自Table 6。这里涉及到几个方面去用于提升结果,其中包括使用soft-nms以及将输入图片的尺寸从提升至 1280 ,以及使用multi-scale test。
注意这里没有列出DINO的63.3结果,并与之对比性能。╮(╯▽╰)╭ 一句没提这个工作。
E.代码细节
接下来看一些代码实现的细节,如果觉得只是为了简单了解下ViTDet,这部分就可以忽略了。
1.MaskRCNN部分的修改
ViTDet中使用的MaskRCNN做了结构上的一些修改,总的来说有三处:
首先是ROI heads中的box head和mask head各自包含的卷积层之间的连接处使用的皆是LayerNorm;
然后是ROI heads中的box head从原来的2个全连接层修改为4个卷积层+1个全连接层;
最后是RPN中的1个隐含卷积层修改成了2个。
# modify
# use "LN"
model.roi_heads.box_head.conv_norm = model.roi_heads.mask_head.conv_norm = "LN"
# 2conv in RPN:
model.proposal_generator.head.conv_dims = [-1, -1]
# 4conv+1fc box head
model.roi_heads.box_head.conv_dims = [256, 256, 256, 256]
model.roi_heads.box_head.fc_dims = [1024]如果经典RPN网络的具体结构记得不清晰,可参照该链接回忆。
2.数据增强部分
数据增强使用了large scale jitter
dataloader.train.mapper.augmentations = [
L(T.RandomFlip)(horizontal=True), # flip first
L(T.ResizeScale)(
min_scale=0.1, max_scale=2.0, target_height=image_size, target_width=image_size
),
L(T.FixedSizeCrop)(crop_size=(image_size, image_size), pad=False),
]3.SFP的实现
class SimpleFeaturePyramid(Backbone):
"""
This module implements SimpleFeaturePyramid in :paper:`vitdet`.
It creates pyramid features built on top of the input feature map.
"""
def __init__(
self,
net,
in_feature,
out_channels,
scale_factors,
top_block=None,
norm="LN",
square_pad=0,
):
"""
Args:
net (Backbone): module representing the subnetwork backbone.
Must be a subclass of :class:`Backbone`.
in_feature (str): names of the input feature maps coming
from the net.
out_channels (int): number of channels in the output feature maps.
scale_factors (list[float]): list of scaling factors to upsample or downsample
the input features for creating pyramid features.
top_block (nn.Module or None): if provided, an extra operation will
be performed on the output of the last (smallest resolution)
pyramid output, and the result will extend the result list. The top_block
further downsamples the feature map. It must have an attribute
"num_levels", meaning the number of extra pyramid levels added by
this block, and "in_feature", which is a string representing
its input feature (e.g., p5).
norm (str): the normalization to use.
square_pad (int): If > 0, require input images to be padded to specific square size.
"""
super(SimpleFeaturePyramid, self).__init__()
assert isinstance(net, Backbone)
self.scale_factors = scale_factors
input_shapes = net.output_shape()
strides = [int(input_shapes[in_feature].stride / scale) for scale in scale_factors]
_assert_strides_are_log2_contiguous(strides)
dim = input_shapes[in_feature].channels
self.stages = []
use_bias = norm == ""
for idx, scale in enumerate(scale_factors):
out_dim = dim
if scale == 4.0:
layers = [
nn.ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2),
get_norm(norm, dim // 2),
nn.GELU(),
nn.ConvTranspose2d(dim // 2, dim // 4, kernel_size=2, stride=2),
]
out_dim = dim // 4
elif scale == 2.0:
layers = [nn.ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2)]
out_dim = dim // 2
elif scale == 1.0:
layers = []
elif scale == 0.5:
layers = [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
raise NotImplementedError(f"scale_factor={scale} is not supported yet.")
layers.extend(
[
Conv2d(
out_dim,
out_channels,
kernel_size=1,
bias=use_bias,
norm=get_norm(norm, out_channels),
),
Conv2d(
out_channels,
out_channels,
kernel_size=3,
padding=1,
bias=use_bias,
norm=get_norm(norm, out_channels),
),
]
)
layers = nn.Sequential(*layers)
stage = int(math.log2(strides[idx]))
self.add_module(f"simfp_{stage}", layers)
self.stages.append(layers)
self.net = net
self.in_feature = in_feature
self.top_block = top_block
# Return feature names are "p<stage>", like ["p2", "p3", ..., "p6"]
self._out_feature_strides = {"p{}".format(int(math.log2(s))): s for s in strides}
# top block output feature maps.
if self.top_block is not None:
for s in range(stage, stage + self.top_block.num_levels):
self._out_feature_strides["p{}".format(s + 1)] = 2 ** (s + 1)
self._out_features = list(self._out_feature_strides.keys())
self._out_feature_channels = {k: out_channels for k in self._out_features}
self._size_divisibility = strides[-1]
self._square_pad = square_pad
@property
def padding_constraints(self):
return {
"size_divisiblity": self._size_divisibility,
"square_size": self._square_pad,
}
def forward(self, x):
"""
Args:
x: Tensor of shape (N,C,H,W). H, W must be a multiple of ``self.size_divisibility``.
Returns:
dict[str->Tensor]:
mapping from feature map name to pyramid feature map tensor
in high to low resolution order. Returned feature names follow the FPN
convention: "p<stage>", where stage has stride = 2 ** stage e.g.,
["p2", "p3", ..., "p6"].
"""
bottom_up_features = self.net(x)
features = bottom_up_features[self.in_feature]
results = []
for stage in self.stages:
results.append(stage(features))
if self.top_block is not None:
if self.top_block.in_feature in bottom_up_features:
top_block_in_feature = bottom_up_features[self.top_block.in_feature]
else:
top_block_in_feature = results[self._out_features.index(self.top_block.in_feature)]
results.extend(self.top_block(top_block_in_feature))
assert len(self._out_features) == len(results)
return {f: res for f, res in zip(self._out_features, results)}F.参考文献
[1] Exploring Plain Vision Transformer Backbones for Object Detection
[2] Masked Autoencoders Are Scalable Vision Learners
[3] Benchmarking Detection Transfer Learning with Vision Transformers
[4] End-to-End Object Detection with Transformer
[5] 行为分析(九):人形检测部分(二):YOLO系、RCNN系、SSD系、EfficicnetDet系、Transformer系目标检测模型对比_是魏小白吗的博客-CSDN博客
[6] DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection


















 3596
3596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











