







介绍
图像分类是按照预先确定的原则对图像内的像素组进行分类和识别的过程。在创建分类规则时使用一种或多种光谱或文本质量是可行的。两种流行的分类技术是“有监督的”和“无监督的”。
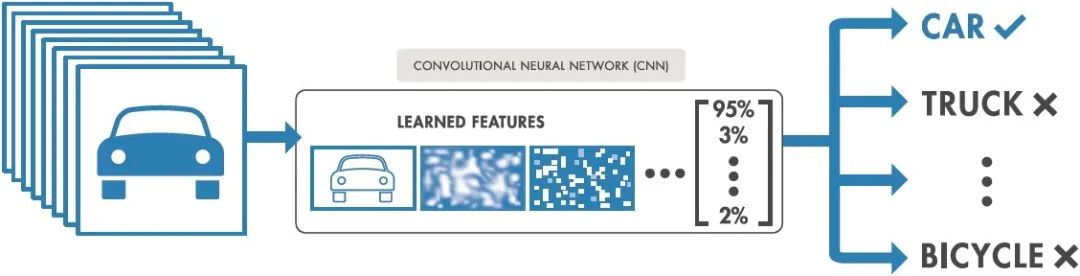
图像分类如何工作?
使用标记的样本照片,训练模型以检测目标类别(要在图像中识别的对象)。监督学习的一个例子是图像分类。原始像素数据是早期计算机视觉算法的唯一输入。
然而,单独的像素数据并不能提供足够一致的表示来包含图像中表示的项目的许多振荡。对象的位置、其背景、环境照明、相机角度和相机焦距都会影响原始像素数据。
传统的计算机视觉模型添加了源自像素数据的新组件,例如纹理、颜色直方图和形状,以更灵活地对对象进行建模。这种方法的缺点是特征工程变得非常耗时,因为需要更改大量输入。
哪些色调对猫的分类至关重要?形状的定义应该有多灵活?由于特征必须精确地调整,因此很难创建稳健的模型。
训练图像分类模型
本教程使用了一个基本的机器学习工作流程:
分析数据集
创建输入管道
建立模型
训练模型
分析模型
设置和导入 TensorFlow 和其他库
import itertools
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
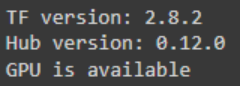
print("TF version:", tf.__version__)
print("Hub version:", hub.__version__)
print("GPU is", "available" if tf.config.list_physical_devices('GPU') else "NOT AVAILABLE")输出如下所示:
选择要使用的 TF2 Saved Model Module
可以在此处找到更多为图像生成特征向量的 TF2 模型:
https://tfhub.dev/s?module-type=image-feature-vector&tf-version=tf2
请注意,TF1 Hub 格式的模型在这里不起作用。
有许多模型可以工作。只需从下面单元格中的列表中选择一个不同的选项,然后继续使用Notebook。
在这里,我选择 了 Inception_v3 并自动从下面的列表中选择图像大小为299 x 299。
model_name = "resnet_v1_50" # @param ['efficientnetv2-s', 'efficientnetv2-m', 'efficientnetv2-l', 'efficientnetv2-s-21k', 'efficientnetv2-m-21k', 'efficientnetv2-l-21k', 'efficientnetv2-xl-21k', 'efficientnetv2-b0-21k', 'efficientnetv2-b1-21k', 'efficientnetv2-b2-21k', 'efficientnetv2-b3-21k', 'efficientnetv2-s-21k-ft1k', 'efficientnetv2-m-21k-ft1k', 'efficientnetv2-l-21k-ft1k', 'efficientnetv2-xl-21k-ft1k', 'efficientnetv2-b0-21k-ft1k', 'efficientnetv2-b1-21k-ft1k', 'efficientnetv2-b2-21k-ft1k', 'efficientnetv2-b3-21k-ft1k', 'efficientnetv2-b0', 'efficientnetv2-b1', 'efficientnetv2-b2', 'efficientnetv2-b3', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'bit_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









