








多任务学习(MLT)是机器学习的一个子领域,其中通过共享模型同时学习多个任务。
这种类型的学习有助于提高数据效率和训练速度,因为共享模型将从同一数据集中学习多个任务,并且由于不同任务的辅助信息,学习速度更快。此外,它还减少了过拟合,因为考虑到每个任务的训练数据标签不同,模型将更难与训练数据完美匹配[1]。
本文将在入门级解释MTL,并将展示如何使用tensorflow的Keras模块在实际数据上实现和训练MTL。在我的GitHub存储库中可以找到完整的代码,以及一个Jupyter笔记本,你可以在其中体验所学内容:
https://github.com/JavierMtz5/ArtificialIntelligence
数据预处理
为了使解释变得容易理解和简单,将使用CIFAR-10[2]数据集,该数据集根据MIT许可证提供。
该数据集由60000张32x32像素的RGB图像组成,分为10个不同的类别。它被分为50000个训练样本和10000个测试样本,并且是完美平衡的,这意味着数据集包含每个类6000个图像。
可以通过执行以下操作轻松加载数据集:

数据集包含以下类别:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。多任务模型要学习的两个任务将是这些标签上的分类,请参见:
任务1:在修改后的CIFAR10数据集上进行多类别分类(飞机、汽车、鸟、猫、狗、青蛙、船和卡车标签,修改说明如下)。
任务2:二分类(标签为动物和载体)。
实现上述两个分类任务的一个更有效的选择是训练模型以仅学习第一个任务,然后将其输出用于预测动物或车辆。
这方面的一个例子是将青蛙的图像作为输入传递给模型,模型将获得青蛙类作为输出。由于青蛙是一种动物,因此图像将被分类为动物类(该解决方案的模式如下所示)。
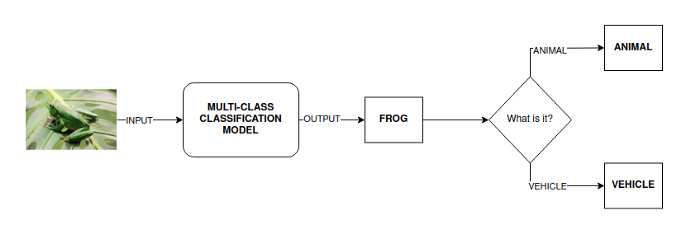
尽管如此,本文将通过应用多任务学习来解决这个问题,因为尽管它不是最有效的示例,但它完美地证明了MTL在这类问题中的有用性和应用,并且它是开发知识的绝佳基础。
考虑到这一点,为了有一个用于训练的平衡数据集,属于鹿和马的类的实例将被删除。之所以这样做,是因为最初数据集包含30000个属于动物的样本(5000个样本x 6类),只有20000个属于车辆(5000个样品x 4类),这将使数据集在二分类任务方面失衡。
马和鹿的实例被删除,因为它们与猫和狗的特性非常相似,因此可能会增加训练的复杂性,因为更难区分这些类的实例。
def erase_classes(classes_to_drop, x_train, x_test, y_train, y_test):
"""
:param classes_to_drop: list with the labels of the classes to be erased
:return: datasets tuple without the classes: (
"""
new_x_train, new_x_test, new_y_train, new_y_test = list(), list(), list(), list()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









