






论文标题: Leveraging Old Knowledge to Continually Learn New Classes in Medical Images
论文链接:https://arxiv.org/abs/2303.13752
代码:https://github.com/EvelynChee/LO2LN
引用:Chee E, Lee M L, Hsu W. Leveraging Old Knowledge to Continually Learn New Classes in Medical Images[J]. arXiv preprint arXiv:2303.13752, 2023.

导读
类增量持续学习是开发人工智能系统的核心一步,该系统可以通过学习新概念来不断适应环境的变化,而不会忘记以前学过的概念。这在医学领域尤其需要,因为它需要不断地从新的输入数据中学习,以便对一组扩大的疾病进行分类。在这项工作中,我们关注于如何利用旧的知识来学习新的类,同时避免灾难性遗忘。
我们提出了一个由两个主要组件组成的框架:
(1 )具有扩展表示的动态架构,以保留以前学习过的特征和适应新特征;
(2) 在两个目标之间交替的训练过程,以平衡新特征的学习,同时保持模型在旧类上的性能。
在多个医学数据集上的实验结果表明,我们的解决方案能够在类的准确性和遗忘方面取得优于最先进的基线的性能。
本文方法
在类增量持续学习中,该模型需要从数据流中学习。每个增量步骤 t ∈ [1..T],定义 Yt 为新类别的集合,Dt 为包含样本 (x, y) 的数据集,其中 x 表示输入图像,y ∈ Yt 是相应的标签。目标是最大化直到步骤 t 的所有已见类别的总体分类准确性,即
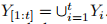
我们提出的框架利用先前学到的特征来学习新类别。采用动态扩展网络以容纳新特征而不损害旧特征。为了保持对先前见过的类别的性能,还采用了正则化损失和数据回放策略。此外,为了处理高度倾斜的类别分布,采用了成本敏感学习,并对来自欠表示的旧类别的样本施加更高的惩罚。
模型架构
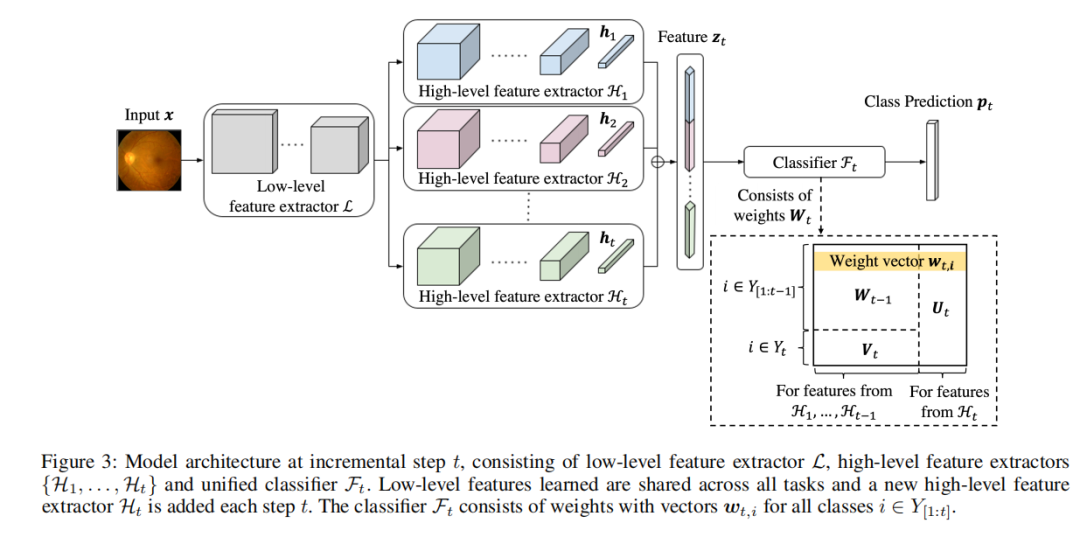
在模型架构方面,图 3 展示了提出的动态架构在增量步骤 t 的细节。有三个主要组件:低层特征提取器 L,一组高层特征提取器和一个统一的分类器。
低层特征提取器 L,由
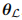
每个高层特征提取器
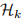
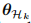
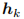
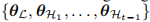
统一的分类器
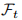
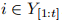
假设
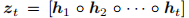
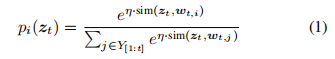
其中 η 是可学习的标量,sim(·) 是两个向量之间的余弦相似度
训练过程
遵循数据回放策略,在每个增量步骤 t > 1 中,我们的训练样本 St 包括传入的数据集 Dt 和内存中每个已见类别
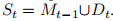
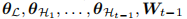
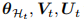
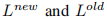
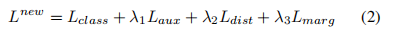
L old 侧重于对欠表示的旧类别进行处理,通过对错误分类的样本施加更高的惩罚,不需要辅助损失。具体表达如下:
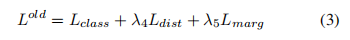
分类损失
与常用的交叉熵损失不同,由于新旧类别之间的不平衡会导致严重的遗忘问题,我们采用了类平衡焦点损失(Cui et al. 2019)。我们的分类损失定义如下:
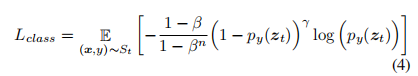
辅助损失
为了学习新类别的区分特征,我们引入了一个辅助损失。它同样使用类平衡焦点损失,但仅关注由 Ht 提取的特征 ht,以及类别 y 对应的权重向量
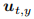
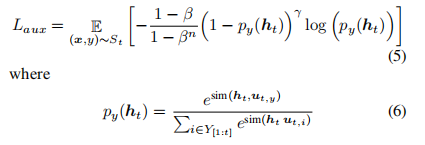
蒸馏损失
由于我们的架构旨在冻结先前学到的特征,我们使用 logits-level 蒸馏损失(Rebuffi et al. 2017),通过最小化模型在先前步骤预测的旧类别 Y[1:t−1] 的概率之间的 Kullback–Leibler 散度来实现,具体如下:
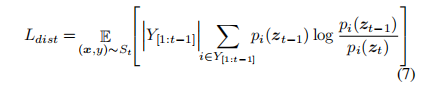
边际损失
由于训练集以新类别为主导,预测可能会偏向这些新类别。为了减少这种偏差,我们使用边际排名损失,使得从内存 Mt−1 中提取的样本具有至少 m 的边缘,将其与所有新类别的真实类别分离。给定一个训练样本 (x, y),设 K 为对应的预测置信度最高的 k 个新类别的集合。然后,损失定义为:
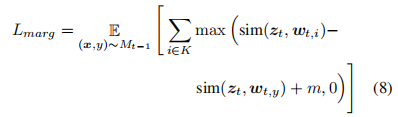
算法1给出了我们提出的训练方法的详细信息。
在第1行,使用 D1 对低层特征提取器 L、高层特征提取器 H1 和分类器 F1 进行训练,只使用分类损失,因为没有旧知识需要保留。
对于每个后续步骤 t,架构会通过添加一个新的高层特征提取器 Ht 和一个更大的分类器 Ft 进行扩展(第3行)。
第4行选择旧样本进行数据回放 Mt−1,而第5行将这些样本与 Dt 合并以获取训练数据集 St。
训练过程(第6-9行)通过先优化 L new,然后优化 L old 进行重复。

实验
实验结果
与其他方法的比较:
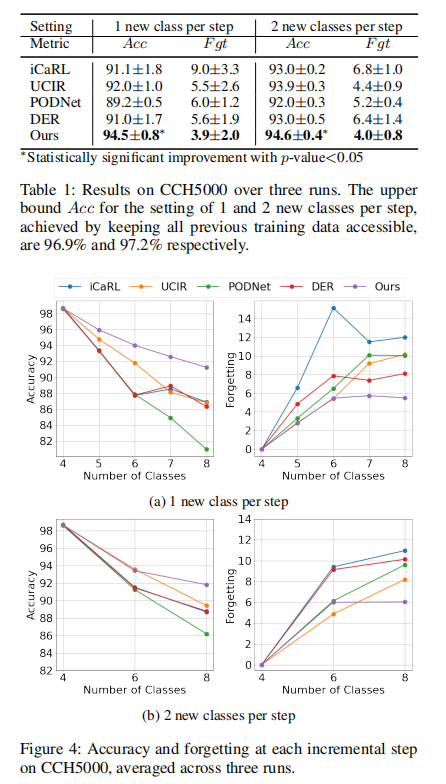
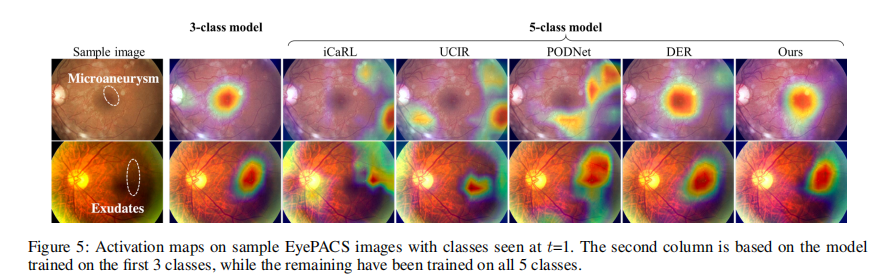
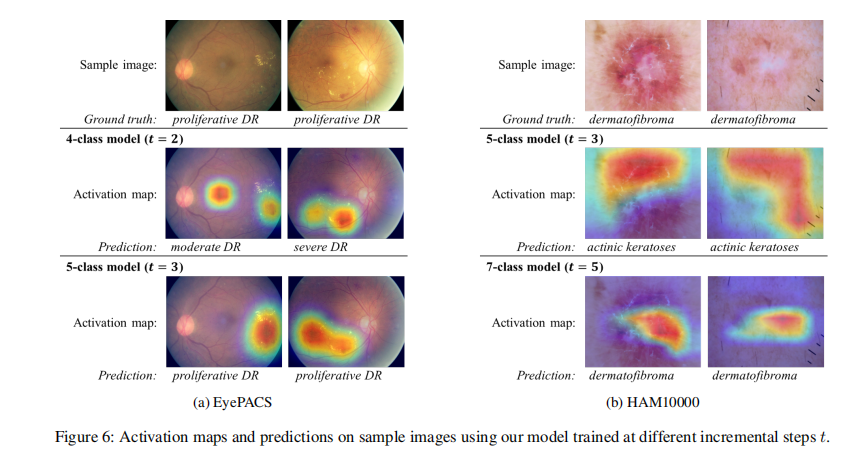
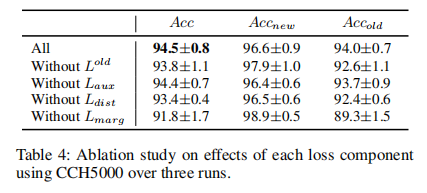
消融实验
结论
在这篇论文中,我们提出了一种针对医学领域的类增量持续学习框架,利用先前学到的特征获取新知识。通过采用动态架构和不断扩展的表示,它能够在学习新特征的同时保留旧特征。我们通过使用两个目标轮流训练模型,一个专注于从新进数据中学习,而另一个强调欠表示的旧类别,实现了在旧类别和新类别性能之间的良好平衡。
在三个医学图像数据集上的实验证明了我们提出的方法在性能上超过了现有技术基线,包括那些具有高度倾斜分布的数据集。未来的工作将包括研究在引入新类别时扩展模型的需求,并开发一个度量标准来量化添加特征提取器分支的贡献。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









