









一、概述
在当前科技迅速发展的环境中,人工智能(AI)技术日益普及,边缘计算(Edge Computing) 也随之成为 AI 应用的核心支柱。传统云计算虽然具备强大的集中处理能力,但在大量数据传输和实时响应的需求下,延迟与带宽的瓶颈逐渐显现。因此,边缘计算的概念应运而生,通过将部分计算分配到数据生成端的应用,不仅显著降低延迟,还有效减轻网络负担,提升了应用的实时性与隐私性。
在这波边缘计算浪潮中,MemryX 加速卡以其卓越的浮点计算能力 (BF16) 及全面的软件服务,成为 AI 边缘计算的独树一帜的存在。过去传统边缘计算多集中于整数运算,但在实际应用中,仍有某些任务需要高度精确度,因此浮点运算的智能芯片将成为物体检测、图像识别和自然语言处理等边缘应用的理想选择。MemryX 于 2024 年提出了一套新的加速卡解决方案,能够在低功耗 (5 TFLOPS/W) 的情况下提供卓越的 AI 计算性能 (20 TFLOPS),逐渐成为边缘智能应用的关键推动者。
除了硬件性能,MemryX 还提供丰富的软件服务是一大亮点。其软件支持包括各模块评估、API 接口、驱动程序和多种开发工具,方便开发者快速集成并灵活调整 AI 运算需求。MemryX 的软件支持涵盖了从 MX3+ 芯片模拟性能(Simulator)、权重精度调整(Weight Precision)、模型裁剪(Model Cropping) 工具以及模型库资源,能够帮助 MX3+ 运行性能达到最佳状态。
未来,MemryX 不仅在现有系统升级中扮演重要角色,还将成为边缘计算和 AI 深度整合的核心引擎。其强大的浮点运算能力和全面的软件服务,为用户提供即插即用的 AI 解决方案,开创边缘智能新时代。
本章节将向用户介绍如何安装 MemryX 以及 C / C++ 的示例程序应用。
二、快速搭建 MemryX
(1) 硬件架构
将 MemryX MX3+ 2280 尺寸模块连接到 Orange Pi 的 M.2 插槽,并安装散热片(heat sink)、屏幕(screen)、摄像头(USB Camera)、鼠标(mouse)、键盘(keyboard) 和网线(Ethernet Cable)。

(2) 下载 Orange Pi 5 Plus 预构建镜像 (Ubuntu)
请至官方网站下载预构建镜像
下载 Orangepi5plus_1.0.8_ubuntu_focal_desktop_xfce_linux5.10.160.7z 并将其解压缩

Ubuntu适用版本:18.04 (Bionic Beaver)、20.04 (Focal Fossa)、22.04 (Jammy Jellyfish)
Linux 内核版本:5.10.x ~ 6.1.x
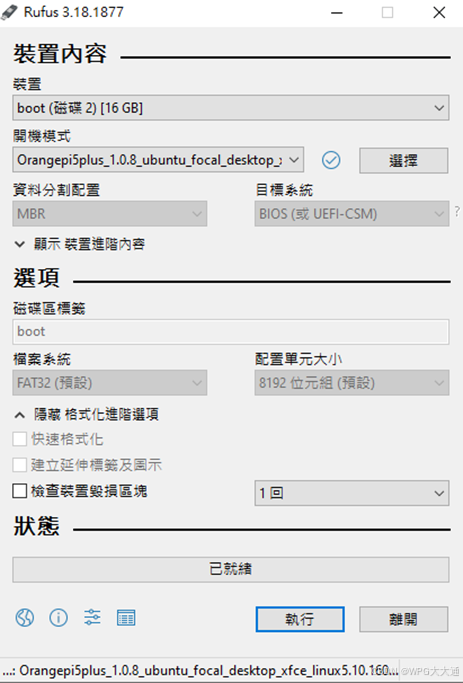
(3) 将 Ubuntu 系统烧录至 SD 卡
请将 SD 卡 (建议准备 16GB 以上的容量) 插入到 PC 端,并使用 Rufus 进行烧录。
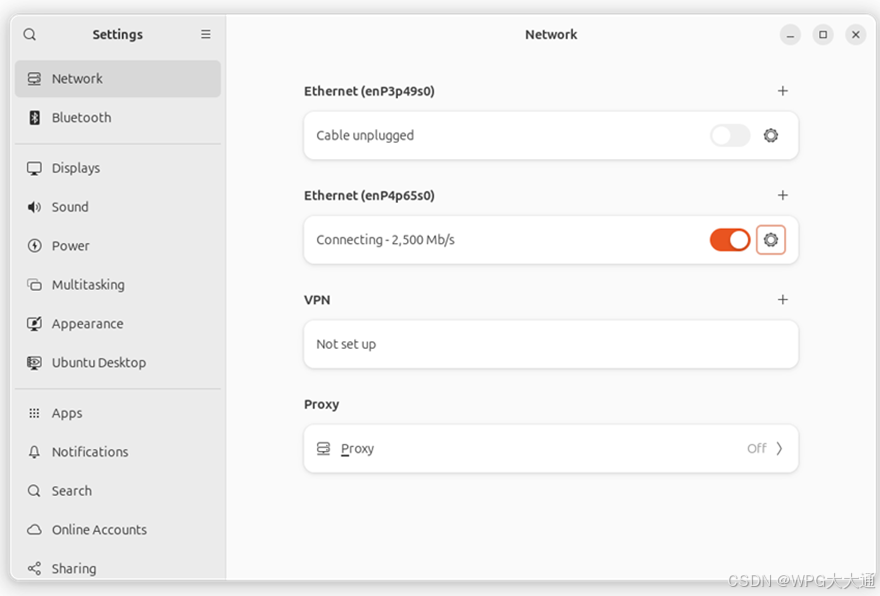
(4) 进入 Ubuntu 系统并连接网络
烧录完成后,请将 SD 卡放入 Orange Pi 5 Plus。即可连接电源进入系统,并连接上网络。
(5) 安装 kernel-header 头文件
$ sudo apt install linux-headers-$(uname -r)
(6) 安装 MemryX SDK 包 (C/C++)
▲ 添加 GPG 密钥
$ wget -qO- https://developer.memryx.com/deb/memryx.asc | sudo tee /etc/apt/trusted.gpg.d/memryx.asc >/dev/null
▲ 添加软件至 APT 列表
$ echo 'deb https://developer.memryx.com/deb stable main' | sudo tee /etc/apt/sources.list.d/memryx.list >/dev/null
▲ 安装 MemryX MX3+ NPU 驱动程序
$ sudo apt update
$ sudo apt install memx-drivers
▲ 安装 MemryX MX3+ 运行时 (C/C++)
$ sudo apt install memx-accl
▲ 安装 MemryX MX3+ 包
$ sudo apt install memx-accl-plugins
$ sudo apt install memx-utils-gui
$ sudo apt install qtbase5-dev qt5-qmake
$ sudo apt install cmake
$ sudo apt install libopencv-dev
$ sudo apt install libssl-dev
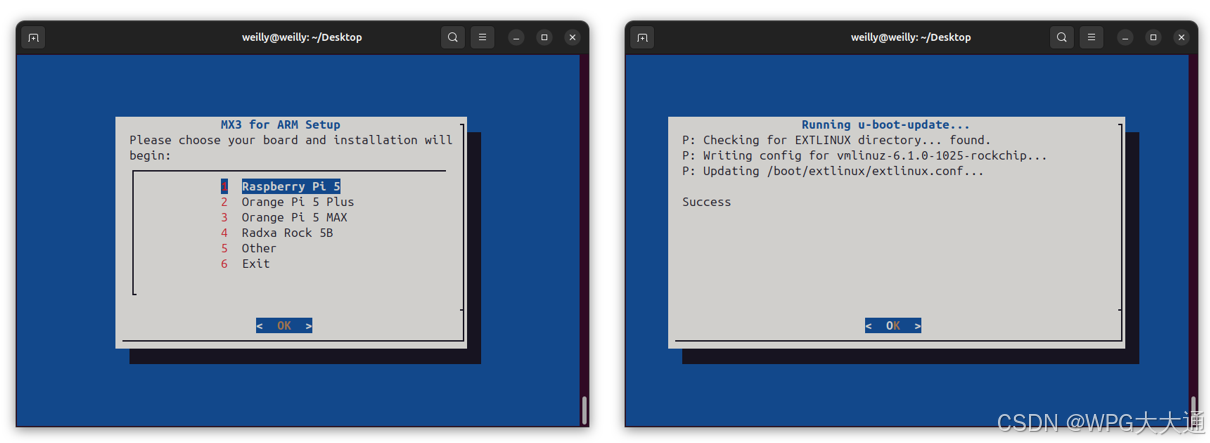
▲ 优化硬件设置
原厂目前提供 Raspberry Pi 5、Orange Pi 5 Plus、Radxa Rock 5B EVK 进行设置。若为 Intel (x86) 则可略过此步骤。
$ sudo mx_arm_setup
▲ 验证环境
请将系统重启后,以下列指令确认是否安装成功。
$ apt policy memx-drivers
三、DEMO 实作展示 (C/C++)
请前往官网连接到 Tutorials 进行 DEMO 教学示范,并请连接一台 USB 摄像头进行展示。
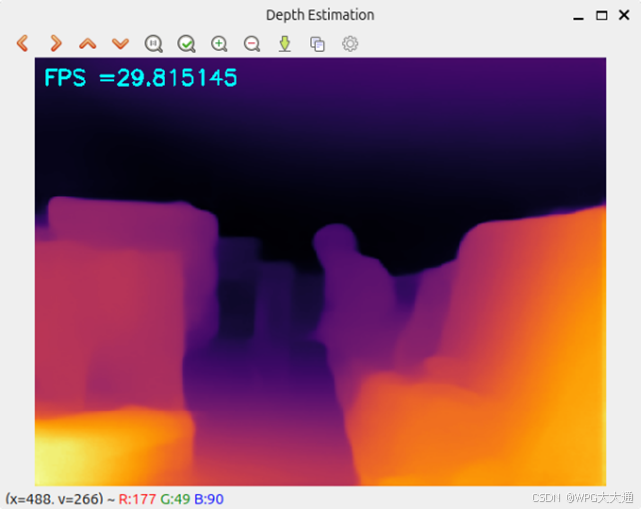
(1) 深度估计
深度估计(Depth Estimation) 展示了利用彩色影像图片来生成具有距离意义的深度图。
● 下载并解压 depthEstimation.zip
$ unzip depthEstimation.zip
● 修改权限
$ sudo chmod -R 777 depthEstimation/
● 编译
$ cd depthEstimation
$ mkdir build && cd build
$ cmake ..
$ make -j4
● 運行
$ ./depthEstimation –cam /dev/video0
每秒运行约 29.81 帧,CPU 使用率约 200%,内存使用率约 0.1%(0.016 GB)
(2) 目标检测 (CenterNet)
物体检测(Object Detection) - CenterNet 是经典的目标检测算法,于 2019 年提出。[PDF]
● 下载并解压 centernet_sample.zip
$ unzip centernet_sample.zip
● 修改权限
$ sudo chmod -R 777 CenterNet/
● 编译
$ cd centernet_sample/CenterNet
$ mkdir build && cd build
$ cmake ..
$ make -j4
● 運行
$ ./CenterNet
每秒运行约 23.6 帧,CPU 使用率约 493.4 %,内存使用率约 4.4 % (0.7 GB)

图片来源 : https://www.pexels.com/zh-tw/
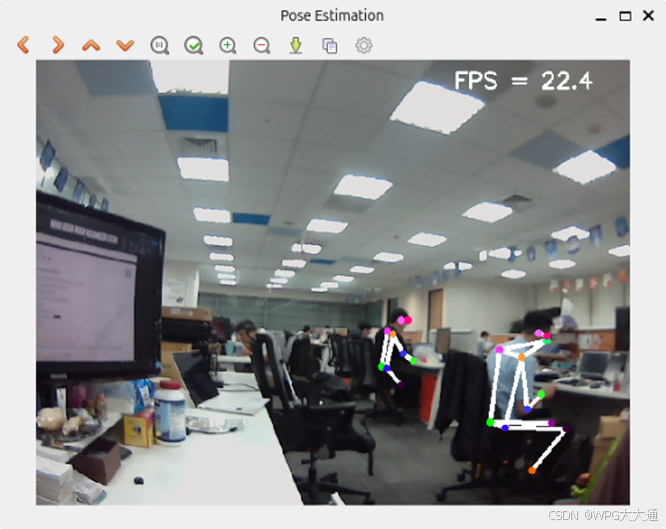
(3) 姿态估计 (YOLOv8)
肢体估计(Pose Estimation) - YOLOv8 是目前最热门的 DNN 算法,于 2023 年提出 [Ultralytics] 被设计用于计算人体肢体的节点位置与相关性。
● 下载并解压 poseEstimation_sample.zip
$ unzip poseEstimation_sample.zip
● 修改权限
$ sudo chmod -R 777 poseEstimation/
● 编译
$ cd poseEstimation
$ mkdir build && cd build
$ cmake ..
$ make -j4
● 運行
$ ./poseEstimation --cam /dev/video0
每秒运行约 22.4 帧,CPU 使用率约 155.4%,内存使用率约 1.6% (0.25 GB)
(4) 目标检测 (YOLOv7t)
物体检测(Object Detection) - YOLOv7 Tiny 是目前最热门的 DNN 算法,于 2022 年提出 [PDF ] 被设计用于计算各种物体的位置与相关性。
● 下载并解压 objectDetection_sample.zip
$ unzip objectDetection_sample.zip
● 修改权限
$ sudo chmod -R 777 objectDetection/
● 编译
$ cd objectDetection/
$ mkdir build && cd build
$ cmake ..
$ make -j4
● 運行
$ ./objectDetection
每秒运行约 45.5 帧,CPU 使用率约为 445 %,内存使用率约为 2.9 % (0.46 GB)

图片来源 : https://www.pexels.com/zh-tw/
(5) 目标检测 (YOLOv8s)
物体检测(Object Detection) - YOLOv8 是目前最热门的 DNN 算法,于 2023 年提出 [Ultralytics] 被设计用于计算各种物体的位置与相关性。
● 下载并解压 objectDetection_sample.zip
$ unzip objectDetection_sample.zip
● 修改权限
$ sudo chmod -R 777 yolov8_objectDetection
● 编译
$ cd yolov8_objectDetection/
$ mkdir build && cd build
$ cmake ..
$ make -j4
● 運行
$ ./yolov8_objectDetection
每秒运行约 42.8 帧,CPU 使用率约 225 %,内存使用率约 4.2%(0.67 GB)

图片来源 : https://www.pexels.com/zh-tw/
(6) 多流目标检测 (Multi-Stream Object Detection)
使用目前最热门的 YOLOv8 DNN 算法进行 多路影像流(Multi-Stream Object Detection) 展示。
● 下载并解压 MX_DEMOS_20241029.tgz
若想获取此 DEMO,请联系 MemryX 或 WPI 窗口。
$ tar zxvf MX_DEMOS_20241029.tgz
● 修改权限
$ sudo chmod -R 777 MX_DEMOS/
● 编译
$ cd MX_DEMOS/
$ mkdir build && cd build
$ cmake ..
$ make -j4
● 運行
$ ./demoVMS
每秒运行约 28.4 帧,CPU 使用率约 615.5%,内存使用率约 20.0%(3.2 GB)

四、结语
MemryX MX3+ AI 加速卡提供高性能、低功耗且灵活的 AI 边缘计算解决方案特别适用于物体检测、视觉分析和实时监控等应用场景。通过浮点数运算 (BF16) 及内置 10.5 MB SRAM内存,能够在不占用主系统内存资源的前提下,确保运算精度,并提升 AI 模型的性能与可扩展性。
在 C/C++ DEMO 测试中,单颗摄像机的物体检测仅需占用约一颗 CPU 处理视频,而系统内存使用量仅为 1.6%,显示出 MemryX 芯片的高效运算与极低资源占用特性。如果研究深入一些,MemryX 提供强大的开发工具,开发者可以灵活切割 AI 模块的前后处理,甚至能将图像前处理交由 ISP(图像信号处理器) 或 DSP(数字信号处理器) 处理,从而进一步优化运算效率。
MemryX MX3+ 的核心优势
● 高帧率运算:单张低功耗 M.2 卡可同时处理10路摄像机流,支持多AI模型并行运行。
● 高精度与自动编译:一键完成 BF16 浮点模型编译,确保 AI 准确度,无需额外调整或重新训练。
● 原始模型保持完整:无需修改 AI 模型即可直接部署,并可选择模型剪枝与压缩来优化设计。
● 自动化前/后处理:自动识别并整合前后处理代码,减少开发与调试时间,提高部署效率。
● 优异的可扩展性:可单芯片运行,也可16芯片组合为逻辑单元,无需额外的PCIe交换器。
● 低功耗设计:单颗 MX3 芯片仅消耗 0.5W ~ 2.0W,4 芯片模块的功耗低于主流 GPU 的 1/10。
● 广泛的硬件与软件支持:兼容 x86、ARM、RISC-V 平台及多种操作系统,开发灵活性极高。
随着人工智能在零售、汽车、工业、农业和机器人等行业中的广泛应用,MemryX 正站在边缘计算技术的前沿,为客户提供卓越的性能和更高的价值。在未来,MemryX 将继续推动技术创新,成为AI边缘计算领域中不可或缺的合作伙伴通过上述原厂提供的工具与示例,AI 不再是遥不可及的梦想,只需一步步按照示例步骤操作,就可以快速实现任何智能应用。若想试用或购买 MemryX 产品的新伙伴,请直接联系伊布小编!谢谢
五、参考文件
[1] MemryX 官方网站
[2] MemryX 开发者中心技术网站
[5] MemryX 示例
[6] 美通社 - MemryX宣布MX3边缘AI加速器正式投产
如有任何相关MemryX技术问题,欢迎在前往原博文底下留言提问!!
接下来还会分享更多MemryX的技术文章 !!敬请期待【ATU Book-MemryX系列】!!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









