









过程
寒假过程中,画了3天采集海贼王角色数据并进行标注,然后花了1天时间使用神经网络训练数据集,并进行验证
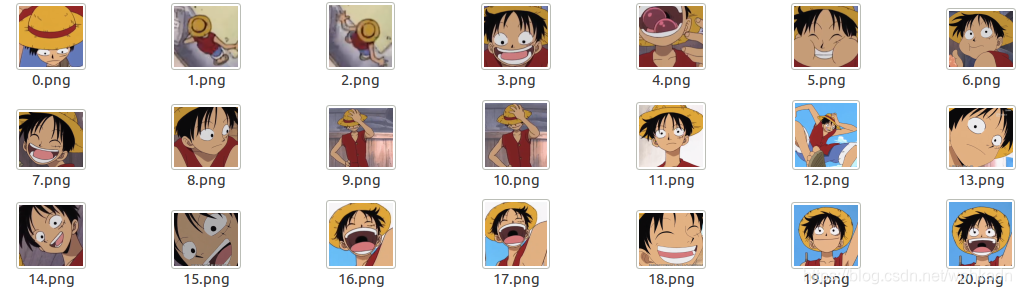
- 使用的训练集为自己从视频中提取而来的图片,大部分是角色的面部图片,小部分包含了全身图像.
| 序号 | 文件夹 | 含义 | 数量 |
|---|---|---|---|
| 0 | lufei | 路飞 | 117 张 |
| 1 | suolong | 索隆 | 90 张 |
| 2 | namei | 娜美 | 84 张 |
| 3 | wusuopu | 乌索普 | 77张 |
| 4 | qiaoba | 乔巴 | 102 张 |
| 5 | shanzhi | 山治 | 47 张 |
| 6 | luobin | 罗宾 | 105张 |
图像样例
实验成果
github代码 : https://github.com/kadn/haizeiwang_face
操作步骤
- 首先要收集图片
利用 screentogif 软件对海贼王视频进行截图,保存含有人物头像的图片 - 对人脸部分进行提取
使用MATLAB软件的 imcrop 函数对整张图片进行部分截图,并将不同的角色保存至不同的文件夹中,详见
https://github.com/kadn/haizeiwang_face/blob/master/hzw/imc.m
使用方法:- 将要截取人物图片的视频读取进来
- 对视频每一帧图像合适的地方进行截取
- 在MATLAB命令行界面输入角色名称
- 使用VGG16网络进行训练,详见我的VGG16_notebook
- 对图片进行预处理
- 首先根据VGG16要求的图片最小大小为(xx, xx)将图片resize成合适的大小
- 使用
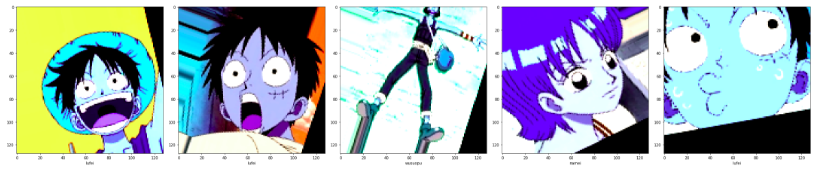
from keras.preprocessing.image import ImageDataGenerator导入keras中的预处理工具, 对图像数据进行增强,以此来增加样本数量
增强的结果# 参数设置 from matplotlib import pyplot from keras.preprocessing.image import ImageDataGenerator datagen = ImageDataGenerator(rotation_range=30, width_shift_range=0.1, height_shift_range=0.1, brightness_range=[0.8,1.5], zoom_range=[0.8,1.2], horizontal_flip=False, vertical_flip=False, rescale=1/128.0, featurewise_center=True) # 看一下增强的结果 datagen.fit(train_data) for batch_data, batch_label in datagen.flow(train_data, train_label, batch_size=9): batch_data = batch_data batch_data = np.clip(batch_data, 0,1) print(batch_data.max()) print(batch_data.min()) for i in range(9): pyplot.imshow(batch_data[i]) pyplot.show() break
- 导入keras中的VGG16模型, 并修改为自己的网络
- 去除掉VGG16的顶层, 修改为自己的.这是因为VGG16原来的输出种类有1000, 这里只有7个
- 保持VGG16卷积层参数不再训练,只训练自己新添加的层
from keras.layers import Input, Dense, Dropout, Activation, Flatten
from keras.models import Model
from keras.applications.vgg16 import VGG16
import numpy as np
tBatchSize = 64
'''第一步:选择模型''' #VGG16要求图片大小最少48
model_vgg = VGG16(include_top=False, input_shape=(128,128,3))
for layer in model_vgg.layers:
layer.trainable = False
model = Flatten(name='flatten')(model_vgg.output)
model = Dense(500, activation='relu', name='fc1')(model)
model = Dense(500, activation='relu', name='fc2')(model)
model = Dropout(0.5)(model)
model = Dense(7, activation='softmax')(model)
model = Model(inputs=model_vgg.input,
outputs = model, name = 'vgg16')
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
- 实验结果
将图片以及识别的结果使用 matplotlib打印出来
res = []
d = {0:'路飞', 1:'索隆', 2:'娜美', 3:'乌索普', 4:'乔巴', 5:'山治', 6:'罗宾'}
d = {0:'lufei', 1:'suolong', 2:'namei', 3:'wusuopu', 4:'qiaoba', 5:'shanzhi', 6:'luobin'}
for batch_data, batch_label in datagen.flow(train_data, train_label, batch_size=10):
res = model.predict(batch_data)
print('batch max : ',batch_data.max())
print('batch_min : ',batch_data.min())
batch_data = np.clip(batch_data, 0,1)
for i in range(10):
ax = pyplot.subplot(2,5,i+1)
pyplot.imshow(batch_data[i])
ax.set_xlabel('{}'.format(d[np.argmax(res[i])]))
# pyplot.axis('on')
pyplot.tight_layout()
pyplot.rcParams['figure.figsize'] = (5.0, 5.0)
pyplot.show()
break
print( np.argmax(res, axis=1))

其他
同时使用inception v3实验了一下,发现效果不好,有同学明白的话希望能帮助我一下.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









