







代码链接:https://github.com/SJTU-DMTai/MASTER
论文链接:https://arxiv.org/abs/2312.15235
引言
股票价格预测是金融领域一个充满挑战的任务。由于股票市场的高度波动性和复杂性,传统的时间序列模型和机器学习方法往往难以捕捉股票间的动态相关性以及市场变化对特征的影响。近年来,Transformer模型凭借其强大的序列建模能力被引入金融预测领域,但其高计算复杂度和对大规模数据的依赖限制了实际应用。《MASTER: Market-Guided Stock Transformer for Stock Price Forecasting》这篇论文提出了一种创新的Transformer架构,针对股票价格预测进行了优化,试图解决这些难题。本文将详细解析MASTER模型的技术细节,并对其贡献和局限性进行评价。
论文概述
论文聚焦于股票价格预测中的两个关键挑战:
1…如何高效捕捉股票间的瞬时相关性和跨时间相关性.
2.如何根据市场状态动态选择对预测最有效的特征。
提出的方法
MASTER(Market-Guided Stock Transformer)是一个专门为股票预测设计的模型,其核心创新包括:
1.市场引导的门控机制:利用市场状态(如指数价格、交易量)动态调整特征的重要性。
2.个股内聚合:通过Transformer编码器捕捉个股的时间序列模式。
3.个股间聚合:利用注意力机制建模股票间的瞬时相关性。
4.交替聚合策略:通过分解注意力计算,降低模型复杂度。
**结果:**在CSI300和CSI800数据集上,MASTER在排名指标(如IC、RankIC)和投资组合指标(如年化收益率AR、信息比率IR)上显著优于基线模型,展示了其在股票预测中的优越性。
技术细节
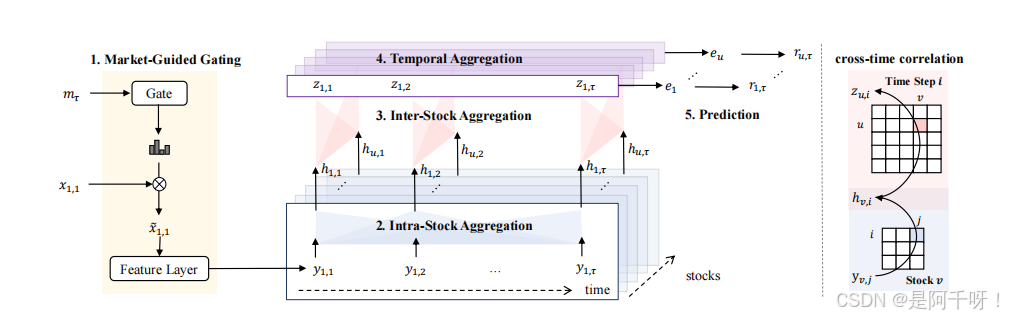
- 市场引导的门控机制
在金融市场中,特征的有效性会随市场状态变化而不同。MASTER引入了一个门控机制,利用市场状态向量
(包含市场指数价格和交易量)生成特征的缩放系数:
α ( m τ ) = F ⋅ softmax β ( W α m τ + b α ) \alpha(m_\tau) = F \cdot \text{softmax}_\beta(W_\alpha m_\tau + b_\alpha) α(mτ)=F⋅softmaxβ(Wαmτ+bα)
缩放后的特征为:
x ˉ u , t = α ( m τ ) ⊙ x u , t \bar{x}_{u,t} = \alpha(m_\tau) \odot x_{u,t} xˉu,t=α(mτ)⊙xu,t
其中,𝐹 是特征维度,𝛽 是温度参数,用于控制特征选择的平滑度。这一机制使模型能够自适应地选择对当前市场状态最重要的特征
- 个股内聚合
为捕捉个股的时间序列模式,MASTER首先对每个股票的特征序列 进行预处理,加入位置编码:
Y u = ∥ t ∈ [ 1 , τ ] LN ( f ( x ˉ u , t ) + p t ) Y_u = \big\|_{t \in [1, \tau]} \text{LN}(f(\bar{x}_{u,t}) + p_t) Yu= t∈[1,τ]LN(f(xˉu,t)+pt)
然后,使用单层Transformer编码器生成个股的局部嵌入:
H u 1 = ∥ t ∈ [ 1 , τ ] h u , t = FFN 1 ( MHA 1 ( Q u 1 , K u 1 , V u 1 ) + Y u ) H_u^1 = \big\|_{t \in [1, \tau]} h_{u,t} = \text{FFN}^1(\text{MHA}^1(Q_u^1, K_u^1, V_u^1) + Y_u) Hu1= t∈[1,τ]hu,t=FFN1(MHA1(Qu1,Ku1,Vu1)+Yu)
这一步骤保留了个股的时间维度信息,并提取了局部趋势。
3. 个股间聚合
在每个时间步 𝑡,MASTER通过多头注意力机制(MHA)捕捉股票间的瞬时相关性:
Z
t
=
∥
u
∈
S
z
u
,
t
=
FFN
2
(
MHA
2
(
Q
t
2
,
K
t
2
,
V
t
2
)
+
H
t
2
)
Z_t = \big\|_{u \in \mathcal{S}} z_{u,t} = \text{FFN}^2(\text{MHA}^2(Q_t^2, K_t^2, V_t^2) + H_t^2)
Zt=
u∈Szu,t=FFN2(MHA2(Qt2,Kt2,Vt2)+Ht2)
传统transformer复杂度为
O
(
N
M
2
τ
2
D
2
)
O(N M^2 \tau^2 D^2)
O(NM2τ2D2)
master为:
O
(
N
3
M
2
τ
D
2
)
O(N_3 M^2 \tau D^2)
O(N3M2τD2)
实验结果
数据集和设置
数据集:CSI300(300只股票)和CSI800(800只股票),2008-2022年日频数据。
基线模型:XGBoost、LSTM、GRU、TCN、Transformer、GAT、DTML。
评价指标:
排名指标:信息系数(IC)、排序信息系数(RankIC)、ICIR、RankICIR。
投资组合指标:年化收益率(AR)、信息比率(IR)
性能表现:
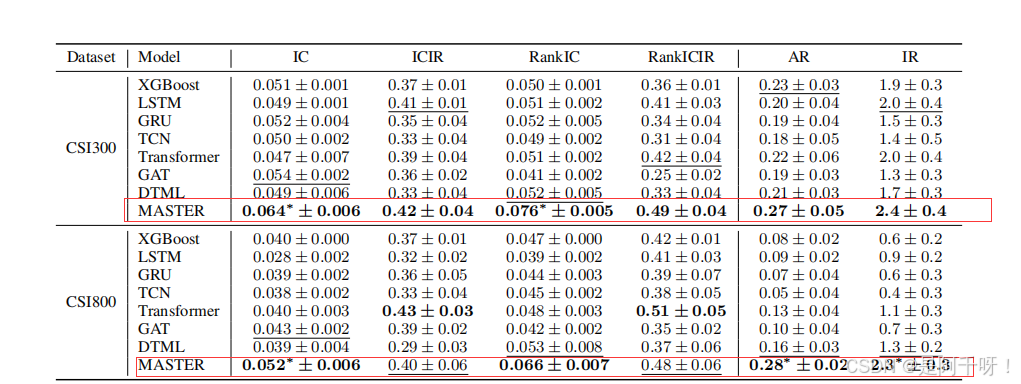
评价(个人)
实验仅基于中国股市(CSI300、CSI800),未在其他市场(如美股)验证,泛化性存疑,市场状态向量仅包含指数价格和交易量,未考虑宏观经济指标或外部事件的影响并,且模型基于日频数据,难以满足高频交易的需求,但是还是在顶级学术会议上的,在股价预测领域还是认可的。我也同时对应学习了qlib
代码部分
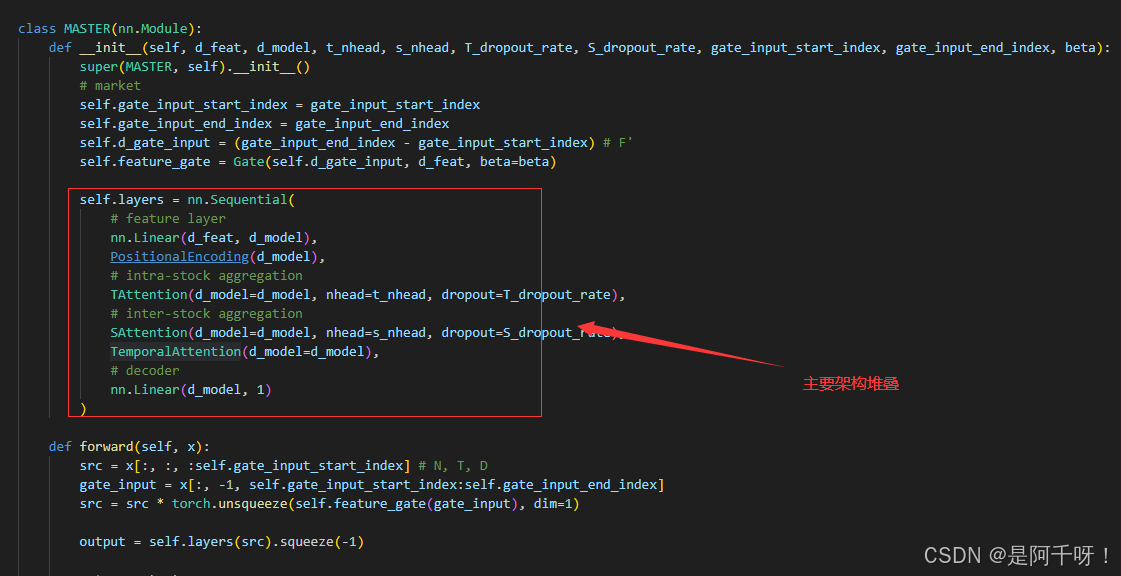
个人评价一下就是一个门控加双重注意力机制,这个st注意力机制是用的dtml的,但是dtml没有开源,所以就根据它的灵感来的吧。
如图:

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









