






前言
肖特基二极管是重要的电子元器件,因为其承载着保护电路的重要作用,所以显得格外的不可或缺,我们都知道在选择肖特基二极管时,主要看它的正向导通压降、反向耐压、反向漏电流等。

但我们却很少知道其在不同电流、不同反向电压、不同环境温度下的关系是怎样的,在电路设计中知道这些关系对选择合适的肖特基二极管显得极为重要,尤其是在功率电路中。知道其特性,对于我们的使用也更加得心应手,下面这篇文章将带你一起去探索神秘的肖特基二极管特性。
正向导通压降与导通电流的关系
在肖特基二极管两端加正向偏置电压时,其内部电场区域变窄,可以有较大的正向扩散电流通过PN结。
只有当正向电压达到某一数值(这一数值称为“门槛电压”,锗管约为0.2V,硅管约为0.6V)以后,肖特基二极管才能真正导通。
但肖特基二极管的导通压降是恒定不变的吗?它与正向扩散电流又存在什么样的关系?通过下图的测试电路在常温下对型号为SM360A的肖特基二极管进行导通电流与导通压降的关系测试,找元器件现货上唯样商城 可得到所示的曲线关系:正向导通压降与导通电流成正比,其浮动压差为0.2V。
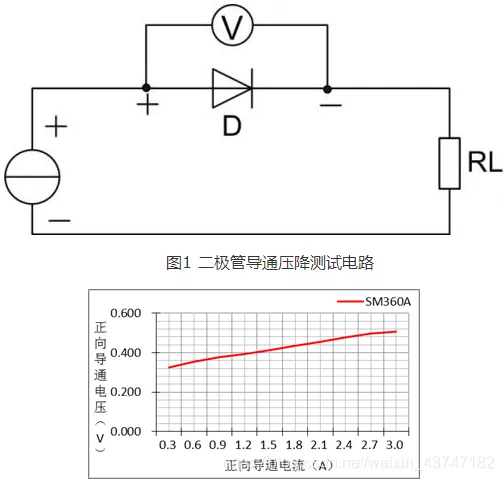
从轻载导通电流到额定导通电流的压差虽仅为0.2V,但对于功率肖特基二极管来说它不仅影响效率也影响肖特基二极管的温升,所以在价格条件允许下,尽量选择导通压降小、额定工作电流较实际电流高一倍的肖特二极管。
正向导通压降与环境的温度的关系
在我们开发产品的过程中,高低温环境对电子元器件的影响才是产品稳定工作的最大障碍。
环境温度对绝大部分电子元器件的影响无疑是巨大的,肖特基二极管当然也不例外,在高低温环境下通过对SM360A的实测数据表的关系曲线可知道:肖特基二极管的导通压降与环境温度成反比。
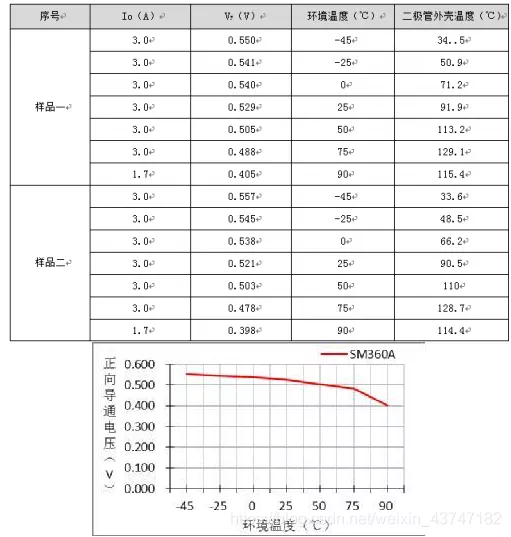
在环境温度为-45℃时虽导通压降最大,却不影响肖特基二极管的稳定性,但在环境温度为75℃时,外壳温度却已超过了数据手册给出的125℃,则该二极管在75℃时就必须降额使用。这也是为什么开关电源在某一个高温点需要降额使用的因素之一。
肖特基二极管漏电流与反向电压的关系
在肖特基二极管两端加反向电压时,其内部电场区域变宽,有较少的漂移电流通过PN结,形成我们所说的漏电流。
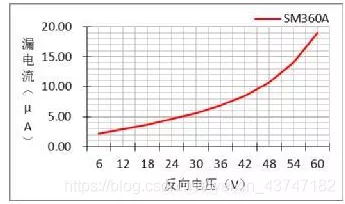
漏电流也是评估肖特基二极管性能的重要参数,肖特基二极管漏电流过大不仅使其自身温升高,对于功率电路来说也会影响其效率,不同反向电压下的漏电流是不同的,关系所示:反向电压愈大,漏电流越大,在常温下肖特基二极管的漏电流可忽略。
肖特基二极管漏电流与环境温度的关系
其实对肖特基二极管漏电流影响最大的还是环境温度,是在额定反压下测试的关系曲线,从中可以看出:温度越高,漏电流越大。
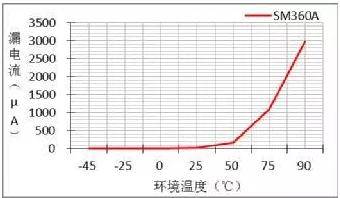
在75℃后成直线上升,该点的漏电流是导致肖特二极管外壳在额定电流下达到125℃的两大因素之一,只有通过降额反向电压和正向导通电流才能降低肖特基二极管的工作温度。

















 4125
4125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









