







摘要
当今研究领域的一项事实就是,前向神经网络(feed-forward neural networks)的训练速度比人们所期望的速度要慢很多。并且,在过去的几十年中,前向神经网络在应用领域存在着很大的瓶颈。导致这一现状的两个关键因素就是:
- 神经网络的训练,大多使用基于梯度的算法,而这种算法的训练速度有限;
- 使用这种训练算法,在迭代时,网络的所有参数都要进行更新调整。
而在2004年,由南洋理工学院黄广斌教授所提出的极限学习机器(Extreme Learning Machine,ELM)理论可以改善这种情况。最初的极限学习机是对单隐层前馈神经网络(single-hidden layer feed-forward neural networks,SLFNs)提出的一种新型的学习算法。它随机选取输入权重,并分析以决定网络的输出权重。在这个理论中,这种算法试图在学习速度上提供极限的性能。
如需转载本文,请注明出处:http://blog.csdn.net/ws_20100/article/details/49555959
极限学习机原理
ELM是一种新型的快速学习算法,对于单隐层神经网络,ELM 可以随机初始化输入权重和偏置并得到相应的隐节点输出:
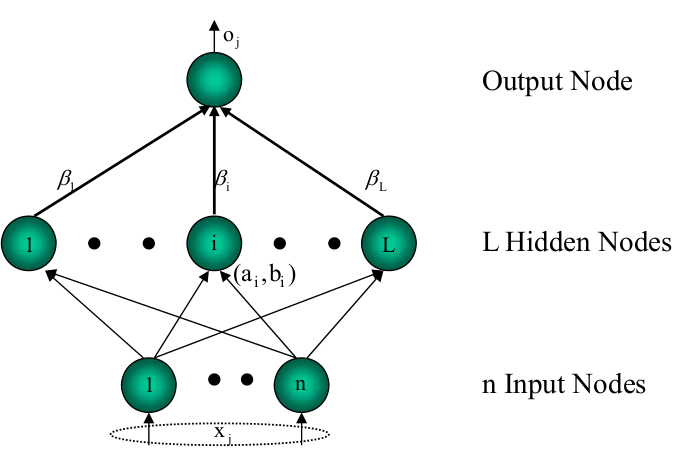
对于一个单隐层神经网络(结构如上图所示),假设有 N 个任意的样本
xj=[xj1,xj2,...,xjn]T∈Rn , tj=[tj1,tj2,...,tjm]T∈Rm
对于一个有
L
个隐层节点的单隐层神经网络可以表示为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









