






0, prefix tuning
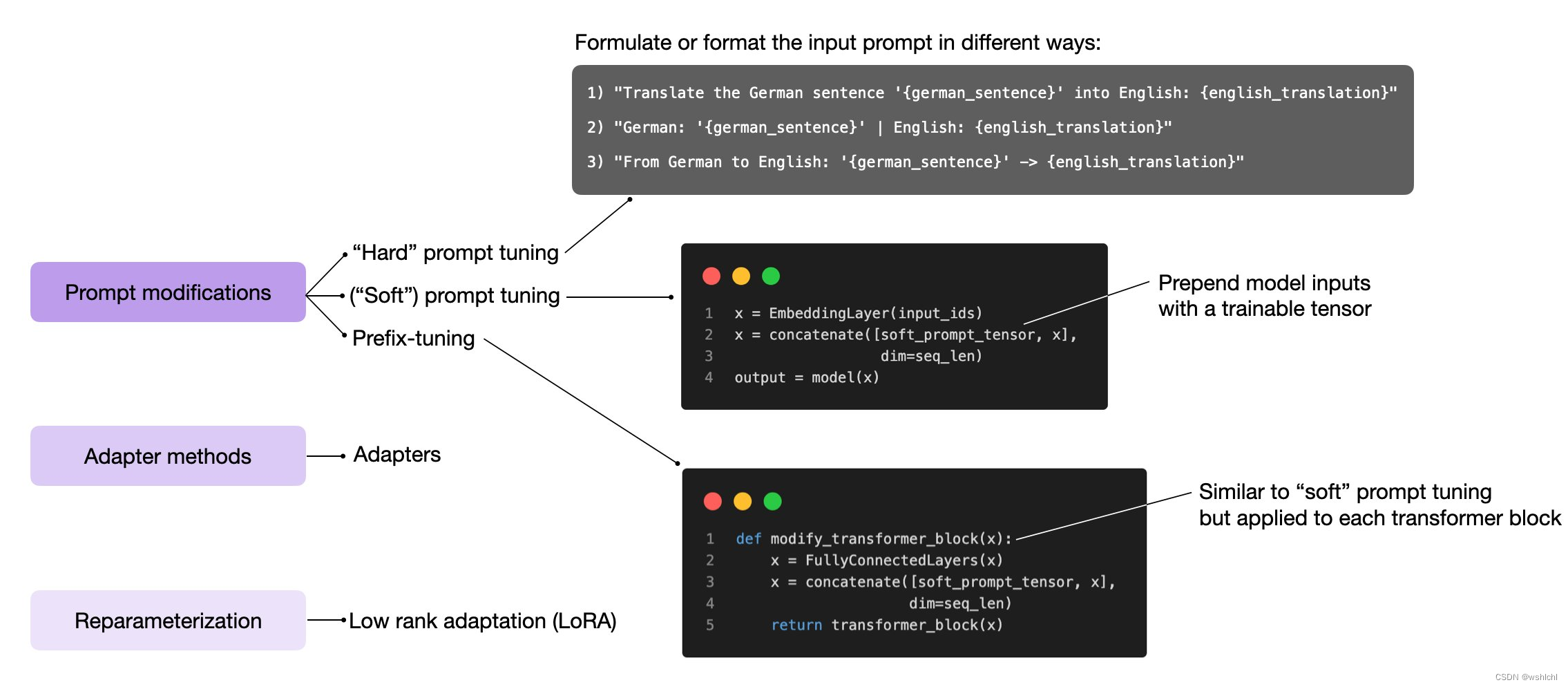
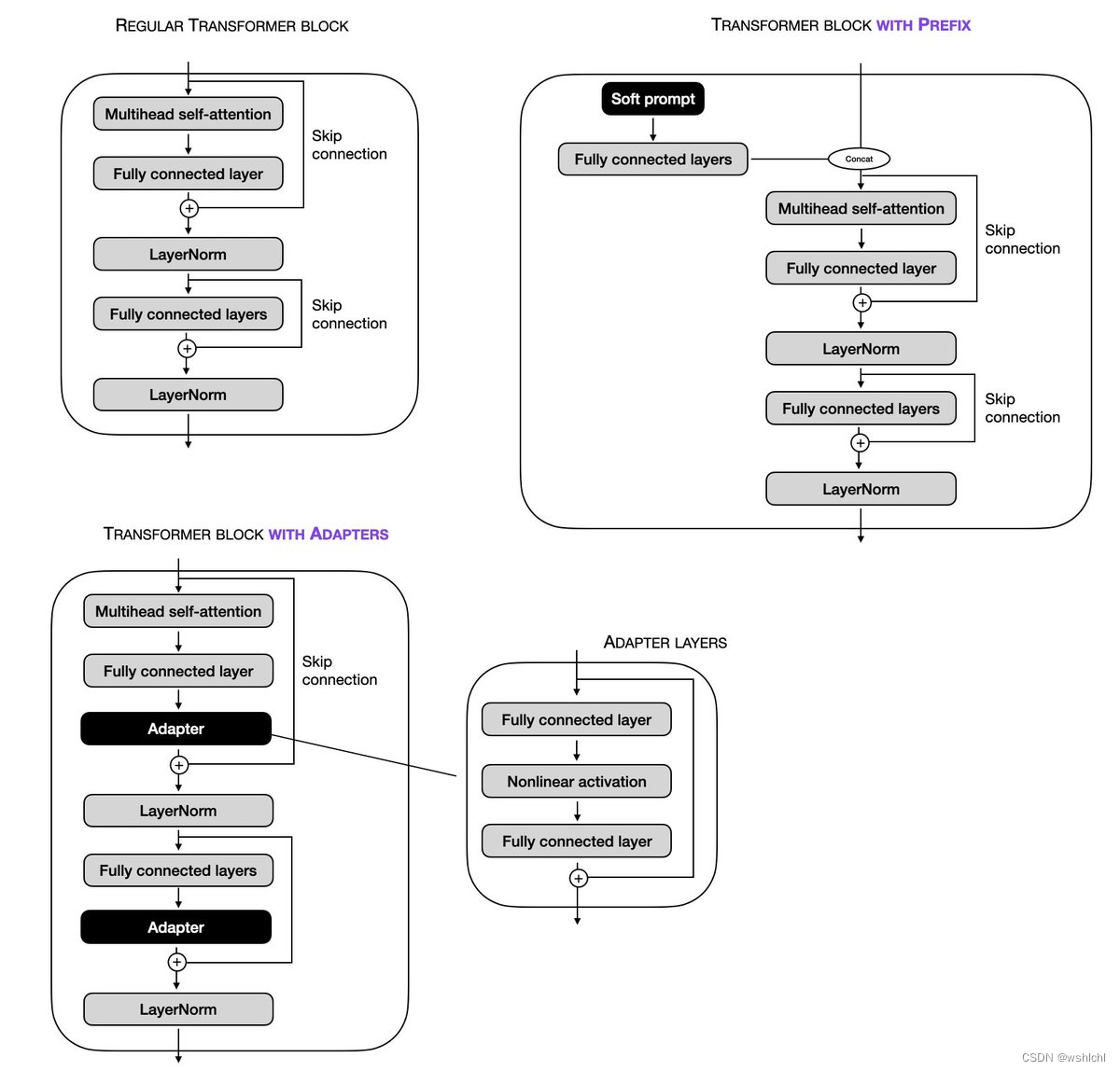
prefix-tuning 跟 soft prompt tuning 类似,只不过,soft prompt tuning 仅仅针对 transformer模型的输入进行,而prefixt-tuning 是针对 每一个 transformer block进行
soft prompt tuning 跟 hard prompt tuning区别在于 后者的拼接的 话术 是固定的(离散的,不能沟通过梯度下降进行训练),而soft那个是可变的,两者都是 transformer模型的 输入进行的。
1, lora
2, adapter
3, prompt-tuning(soft prompt, hard prompt)
adapter 和 soft prompt区别是啥,如下图,
- adapter 本质上是在ffn之后,增加了一些层(一般也是ffn,可能是ffn+激活+ffn这样搞起来),改变了模型的结构,adapter网络结构可以自定义
- soft prompt 是对于 输入 x 后,多头自注意力之前进行了操作,soft promt 经过ffn 之后 再和 x进行相加,从代码上体现来看,两者区别如下图
















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









