






1、导读
生成对抗网络(GAN)是一种用于数据增强的深度学习框架,而DCGAN作为其改进版本,通过引入卷积神经网络(CNN)的架构,显著提升了图像生成任务中的性能。
DCGAN的核心在于利用卷积操作优化生成器和判别器的设计,使其更适合处理图像数据。本文将分析DCGAN的技术优势、与传统GAN的差异,并通过PyTorch代码展示其实施细节。
有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
2、DCGAN的技术优势和区别
DCGAN的技术优势:
DCGAN在图像生成中表现出以下关键特性:
-
图像细节的优化:卷积层能够捕捉图像的局部特征,使生成结果在纹理和细节上更加自然。
-
训练过程的稳定性:通过BatchNorm和LeakyReLU,DCGAN有效缓解了传统GAN训练中常见的梯度消失和模式崩溃问题。
-
架构的可扩展性:基于卷积的结构便于调整,可以生成不同分辨率的图像,适用于多种应用场景。
与传统GAN的差异:
DCGAN与传统GAN在网络设计上存在显著区别:
-
生成器设计:传统GAN使用全连接层直接从噪声生成图像像素,而DCGAN采用转置卷积(ConvTranspose)逐步上采样噪声向量。这种方法更符合图像的空间层次结构。
-
判别器设计:传统GAN依赖全连接层处理整个图像,而DCGAN使用卷积层(Conv)提取局部特征,提升了对图像结构的判别能力。
-
正则化技术:DCGAN引入批归一化来稳定训练,而传统GAN通常缺乏类似的机制。
这些改进使DCGAN在图像生成任务中更为高效和稳定。
2、DCGAN的实现细节
以下通过PyTorch代码展示DCGAN的核心组件及其实现逻辑,具体包括生成器、判别器和训练流程。
2.1 生成器实现
生成器负责将随机噪声向量转换为图像。以下是一个简化的实现:
import torch.nn as nn
classGenerator(nn.Module):
def__init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入:100维噪声,输出:4x4特征图
nn.ConvTranspose2d(100, 512, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# 上采样至8x8
nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# 继续上采样,最终输出64x64x3图像
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1, bias=False),
nn.Tanh() # 输出范围归一化至[-1, 1]
)
defforward(self, x):
returnself.main(x)解析:
-
转置卷积:从噪声向量逐步扩展特征图尺寸,直至生成目标分辨率的图像。
-
批归一化:稳定每一层的特征分布,加速收敛。
-
Tanh激活:将像素值映射到[-1, 1],与常见图像预处理范围一致。
2.2 判别器实现
判别器负责区分真实图像与生成图像:
class Discriminator(nn.Module):
def__init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 输入:64x64x3图像,输出:32x32特征图
nn.Conv2d(3, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 下采样至16x16
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# 最终压缩至1x1,输出真伪概率
nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=0, bias=False),
nn.Sigmoid()
)
defforward(self, x):
returnself.main(x).view(-1)解析:
-
卷积层:通过下采样提取图像特征,逐步压缩空间维度。
-
LeakyReLU:斜率为0.2的负梯度保留,避免梯度消失。
-
Sigmoid:输出0到1之间的概率值,表示图像真实性。
2.3 训练流程:
DCGAN的训练基于对抗学习,交替优化判别器和生成器:
for epoch inrange(num_epochs):
for real_data, _ in dataloader:
batch_size = real_data.size(0)
# 训练判别器
real_output = netD(real_data)
fake_data = netG(torch.randn(batch_size, 100, 1, 1))
fake_output = netD(fake_data.detach())
d_loss = criterion(real_output, torch.ones_like(real_output)) + \
criterion(fake_output, torch.zeros_like(fake_output))
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 训练生成器
g_output = netD(fake_data)
g_loss = criterion(g_output, torch.ones_like(g_output))
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()3、数据和训练过程呈现
本次实验我们采用CIFAR-10数据集作为输入数据,如下所示:

DCGAN的训练是一个动态过程,生成器从随机噪声开始,逐步学习生成越来越逼真的图像。
以下是训练初期、中期和后期的生成图像示例,展示模型在不同迭代次数下的表现:
第1个Epoch生成的图像:

第3个Epoch生成的图像:
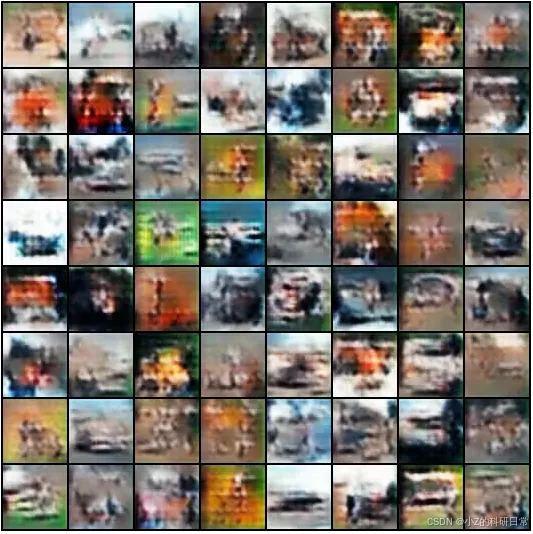
第25个Epoch生成的图像:

通过对比不同阶段的生成图像,我们可以看到DCGAN生成能力的逐步提升:
-
初期(第1个Epoch):图像质量较差,呈现为杂乱的像素点,缺乏可识别的物体特征。
-
后期(第25个Epoch):图像质量显著提高,整体视觉效果接近CIFAR-10的真实图像。
这种从模糊到逼真的变化展示了DCGAN在训练过程中的学习能力,也证明了深度卷积网络在图像生成任务中的强大潜力。
4、总结
通过展示CIFAR-10的真实图像和DCGAN在不同迭代次数下生成的图像,我们可以清晰地看到训练初期的模糊噪声逐渐演变为后期接近真实的图像,这种视觉反馈直观地反映了模型的训练效果。
你觉得图像增强的关键模块是什么? 欢迎留言分享你的看法!


















 5243
5243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











