






Finetune 简介
大语言模型是在海量的文本内容上以无监督或半监督的进行训练的,这些海量的文本内容赋予了大语言模型各行各业的知识。但是如果想将大语言模型用到实际的生产或者科研中,往往会发现模型的回答不尽如人意。这种时候我们就需要微调(finetune),以使其在具体的场景或者领域中输出更好的回答。
常见的两种微调策略分别是增量预训练和指令跟随。 其中增量预训练是指给模型投喂一些新知识,这些新知识是目标领域有关的文本内容,让基底模型学习到一些新知识。而指令跟随是指让模型学会对话模板,根据人类指令进行对话。下图解释了增量微调和指令微调的区别:
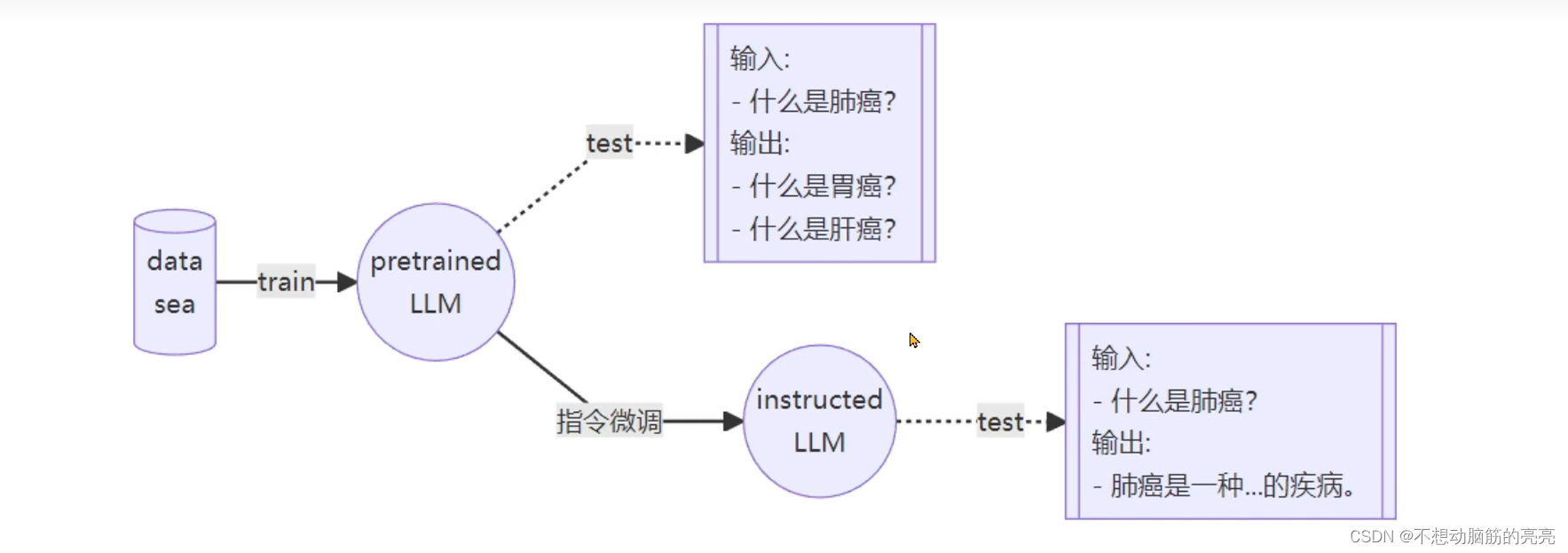
指令跟随微调
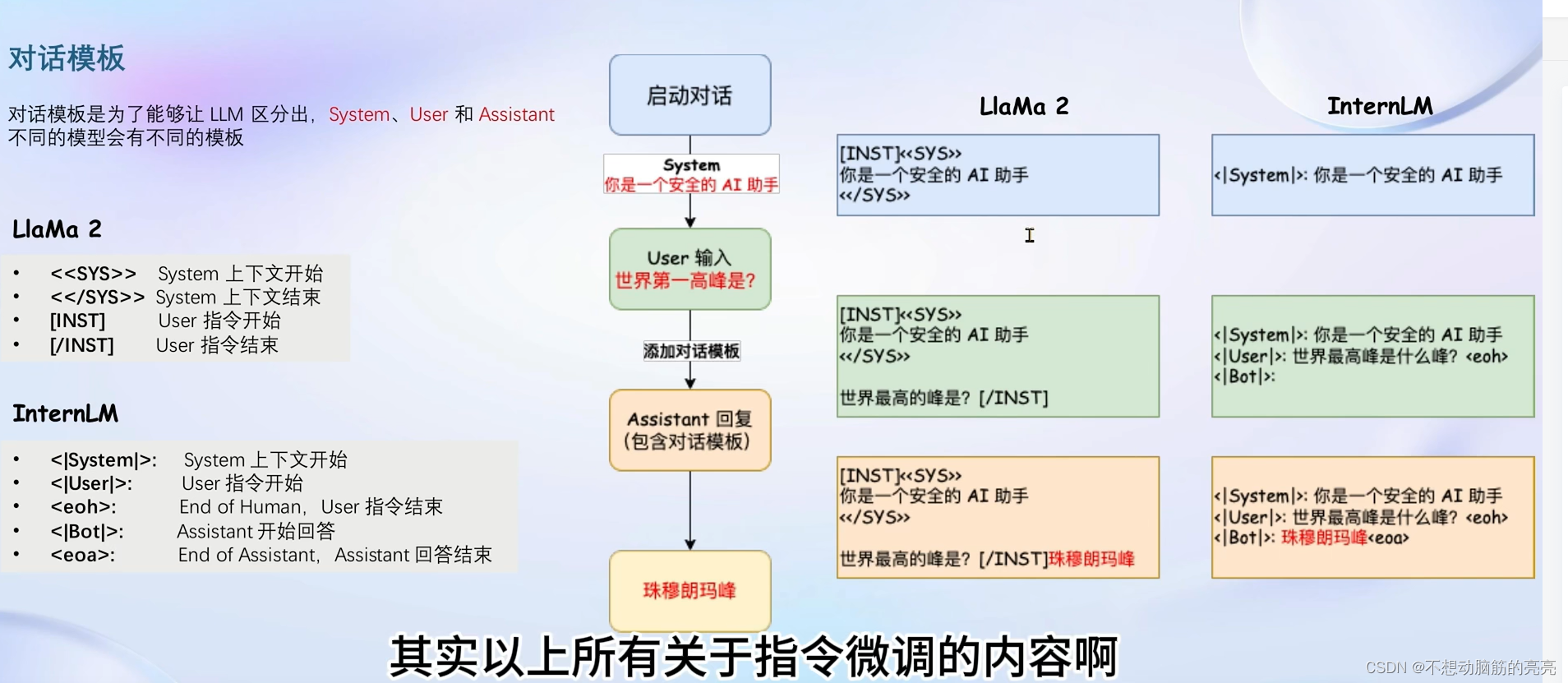
开始之前,首先要对训练数据进行角色指定,通常会有三种角色:
- System: 给定一些上下文信息,比如“你是一个安全的AI助手”;
- User:实际用户,会提出一些问题,比如“世界第一高峰是?”;
- Assistant: 根据user的输入,结合System的上下文信息,做出回答,比如“珠穆朗玛峰”;

不同的开源模型使用的对话模板不尽相同,System、User、Assistant 会有不同模板。下图对比了LLama2 和 InternLM 使用的区别:
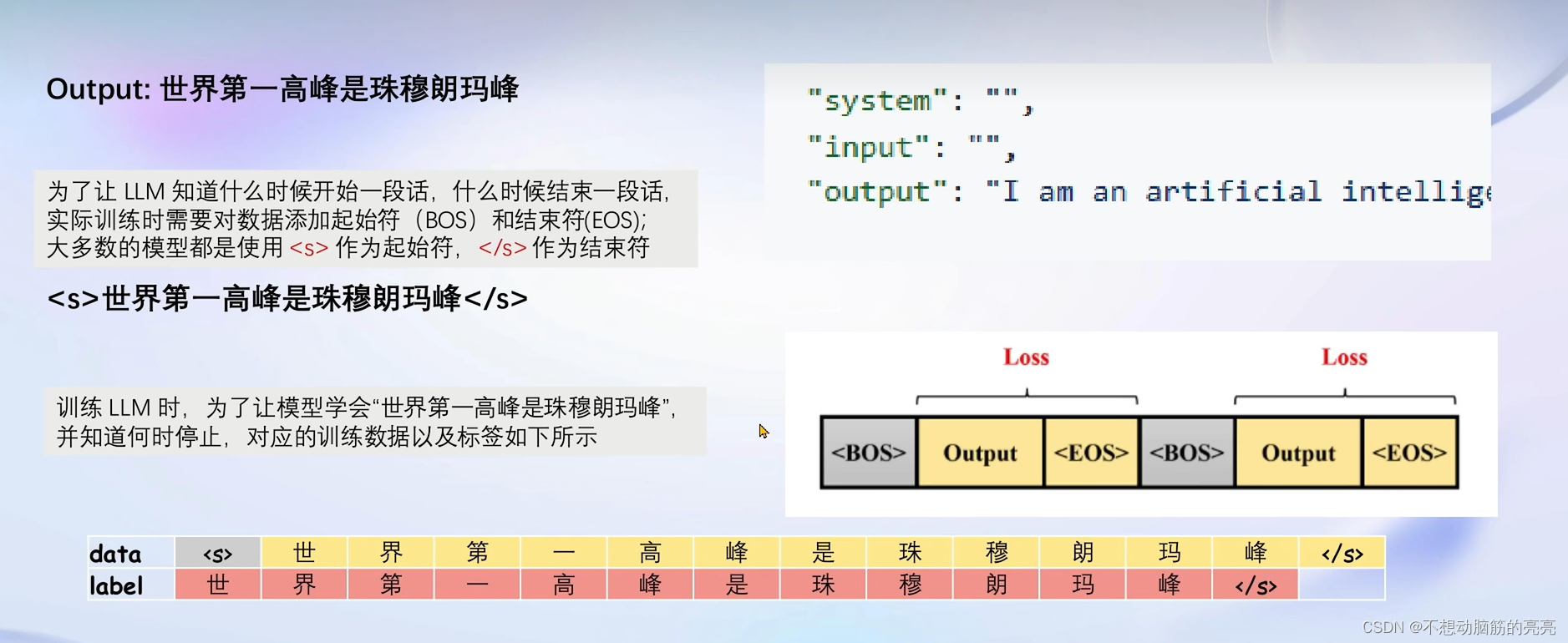
接下来要将构建好的数据输入模型,计算损失(答案部分)。

增量预训练微调
增量训练的数据不需要问题,只需要回答(没有问答形式存在)。 依据之前的模板,只需要把System 和 User这两个角色留空, 数据放到Assistant角色中即可。
LoRA & QLoRA
LoRA通过在原本的Linear 层 新增一个分支,包含两个小Linear。新增的支路通常叫做 Adapter,这个参数量远小于原本的Linear,能大幅降低训练的显存消耗。

三种微调方式对比:

XTuner ——微调工具箱
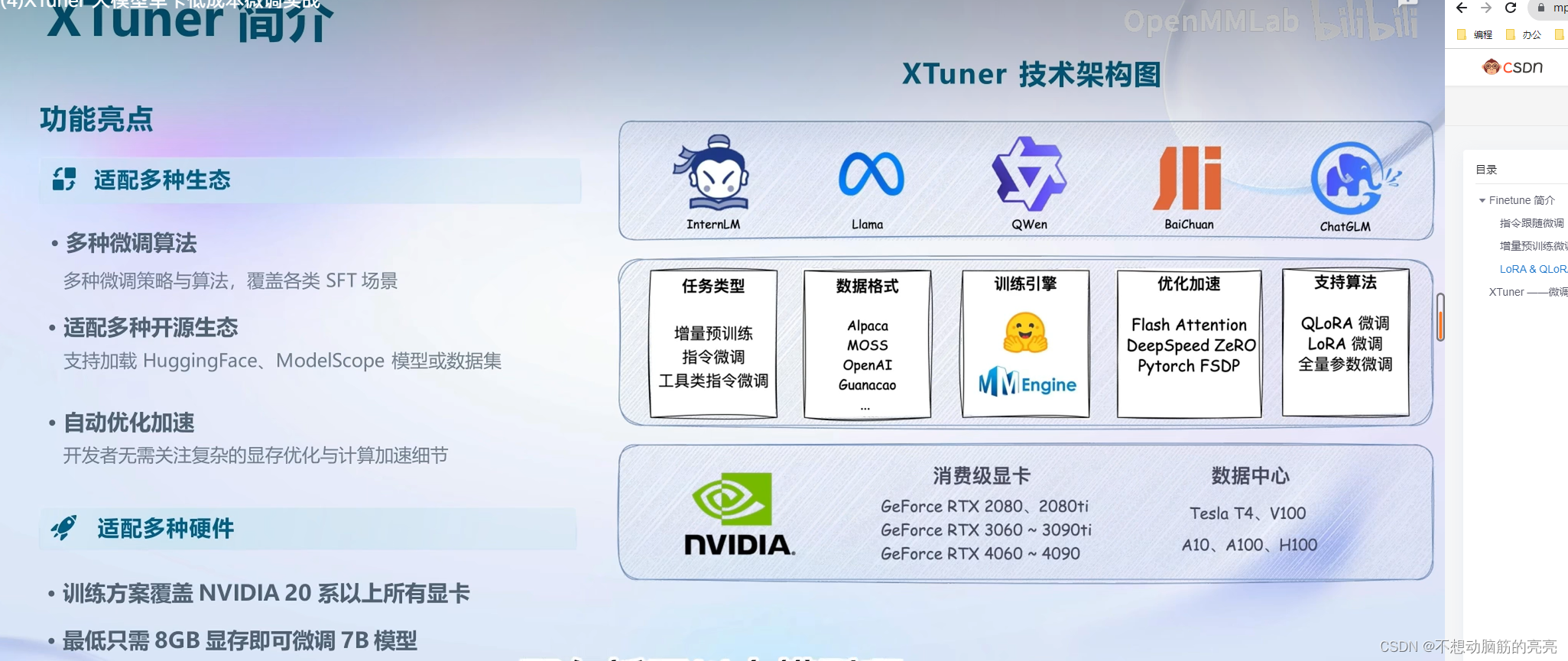
快速上手
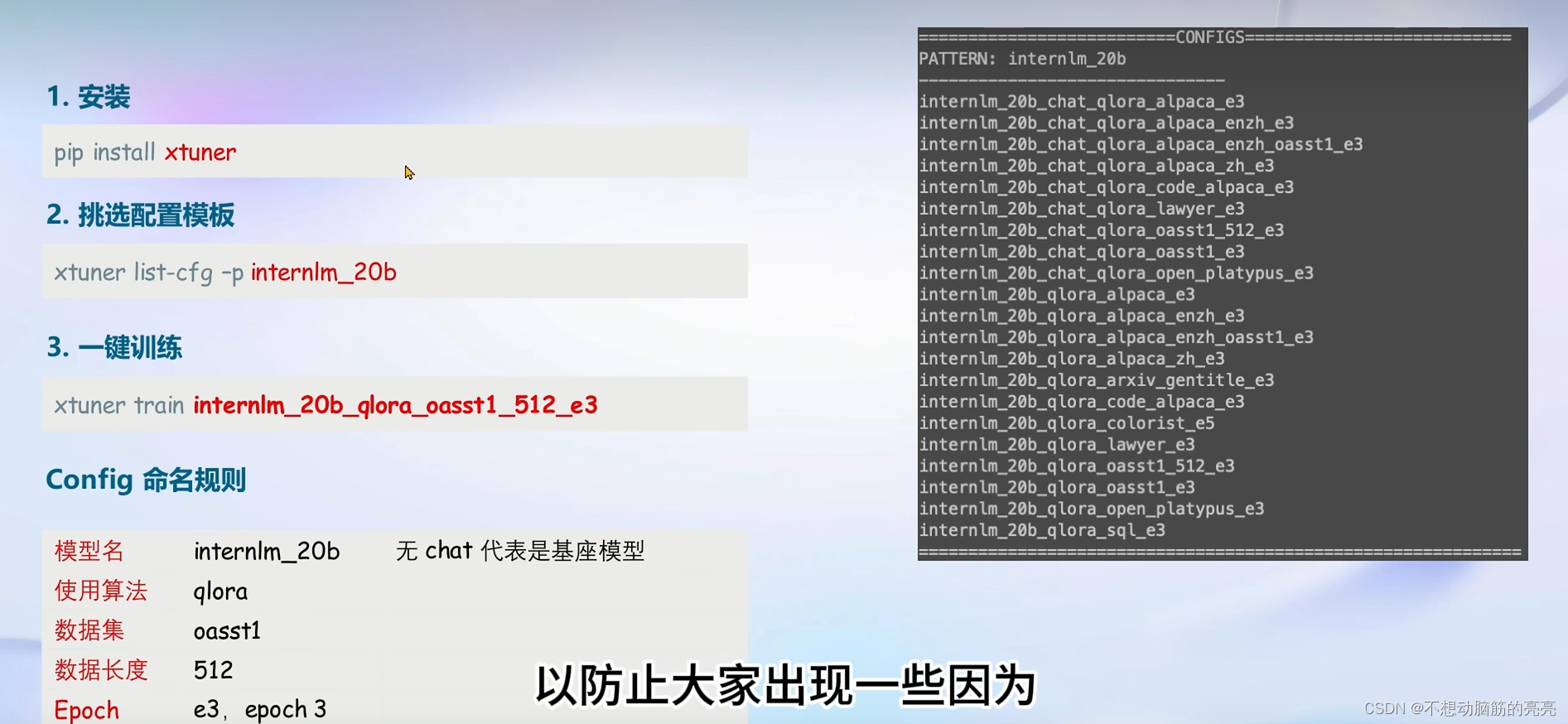
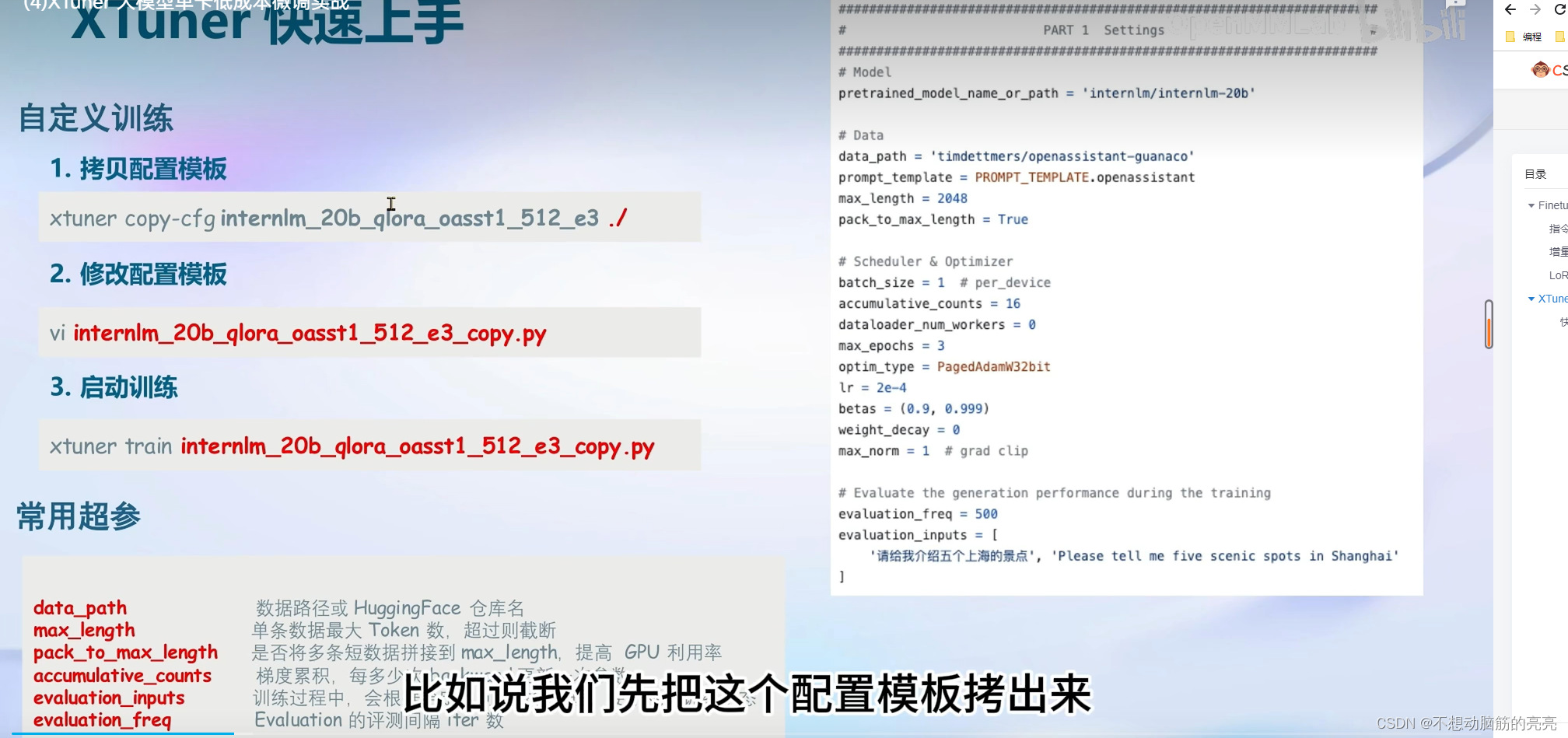
8GB 显卡玩转 LLM
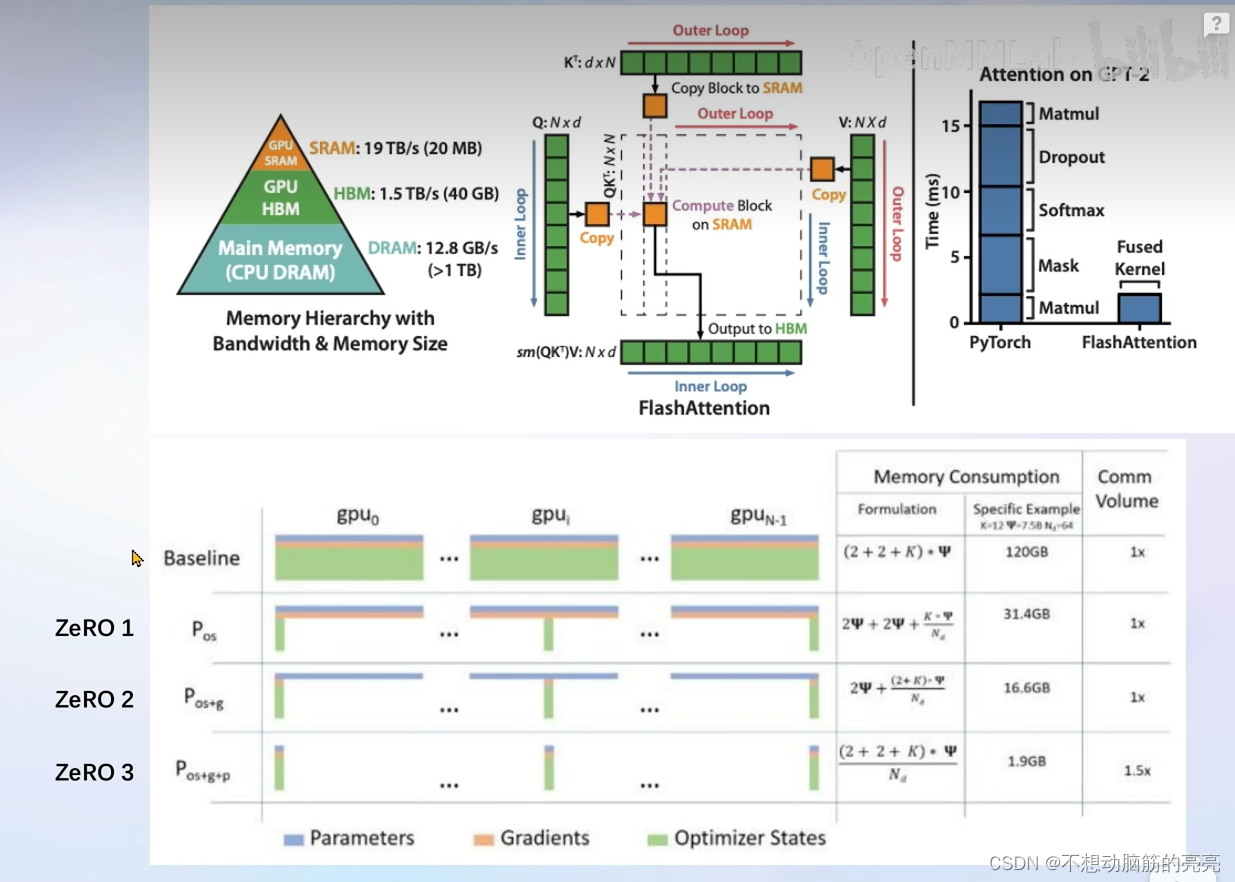
XTuner 支持了Flash Attention 和 DeepSpeed 功能。















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









