







一、前言
要理解大模型为啥按 token 收费这个问题,我们先得知道到底什么是所谓的 token?
“Token”常见释义为“代币;令牌;标记;符号” 。在计算机领域,它常指用于标识或验证的一种机制;在加密货币领域,通常指各种 数字代币;
而在语言学中,“Token”指语言符号,在语料库语言学里,“token”是“形符”,即文本中出现的所有词的个数。

二、token是什么?
那么在自然语言处理技术领域,简单来说,Token(词元)是文本处理的基本单位,也可以简单理解为模型“理解”文本的最小片段。
Token的划分方式取决于具体模型采用的分词策略。
在某些情况下,如果使用了字节对编码(BPE)或者其他形式的子词分词方法,某些汉字或词语可能会被拆分成多个更小的部分,从而占据更多的token。
如腾讯混元大模型1Token ≈1.8个汉字,通义千问1Token ≈ 1个汉字,而英文 1 Token可能对应3-4个字母或一个单词。
自然语言Token化的过程,技术上叫做 Tokenization,即为将输入文本拆分为模型可理解的离散单元,它直接影响模型的计算资源和响应质量。
下面举个例子:
在中文中:一个汉字通常为1个Token,但组合词可能拆分,比方说:“人工智能”可能拆为“人工”+“智能”。
而在英文中:一个单词可能对应1个Token,如 “apple”;
也有可能一个单词是多个Token,如“ChatGPT” 拆为: “Chat” + “G” + “PT”。
理解了Tokens是啥了以后,我们就好理解为什么按tokens收费是比较合理的原因了。
三、资源消耗
大模型的运行涉及高昂的计算资源消耗(如GPU/TPU算力),而Token数量直接决定了处理文本所需的计算量。按Token计费能更公平地量化不同长度文本的实际成本。
例如,处理1000万Token的长文本所需算力远高于短文本,按量收费可避免“一刀切”定价的弊端。
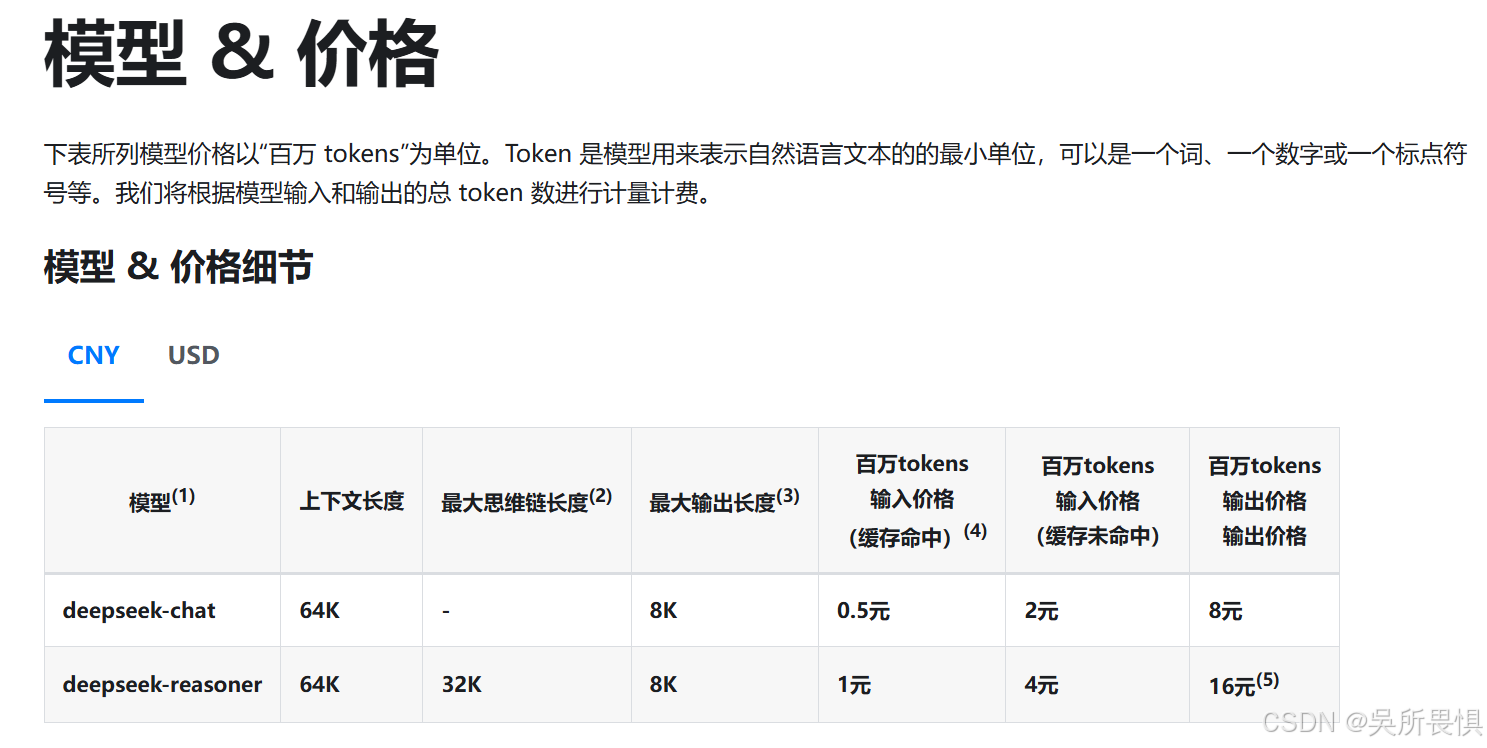
四、商业模式
Token计费将输入和输出的文本统一折算为可量化的单位,例如输入1k Token + 输出2k Token = 总费用3k Token,这样一来,用户可直观控制成本。相比之下,传统API按次收费(如每次0.01元)无法区分简单查询与复杂任务的资源差异。
另外,大模型的研发、训练、部署和维护成本极高,如训练成本可达数千万美元。按Tokens收费能分摊这些成本,尤其是推理阶段的实时算力消耗。
五、小结
但Tokens计费并非唯一模式,部分厂商采用混合收费,比方说:订阅制+按Tokens 付费,或针对轻量化模型提供免费额度。
目前Tokens定义缺乏统一标准,不同模型的中文Tokens对应字数不同,可能导致跨平台成本差异。但总体而言,Tokens作为“AI世界的数字货币”,已成为大模型商业化中最主流的计费方式。
都看到这里了,各位帅哥/美女,不管有用没用,都帮忙点个赞呗,❤️谢谢~
-
Author
- 吴所畏惧 2025.02.28



















 8172
8172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











