







 超级会员免费看
超级会员免费看
大模型背后有大量的计算资源和开发人员支出, 厂商不得不思考商业化考量。现在通过API方式调用收费方式基本是按照token为基本单位进行收费。
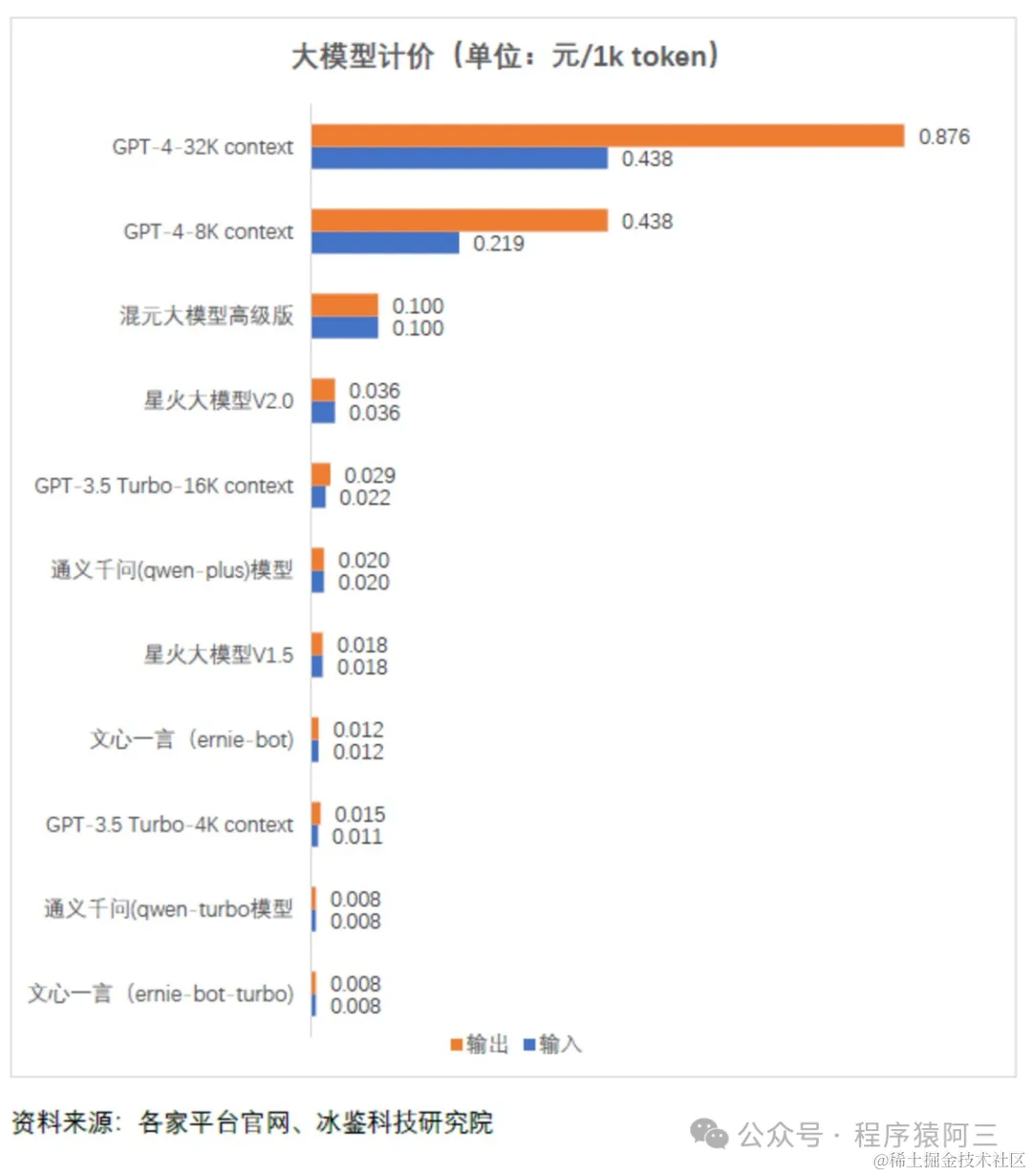
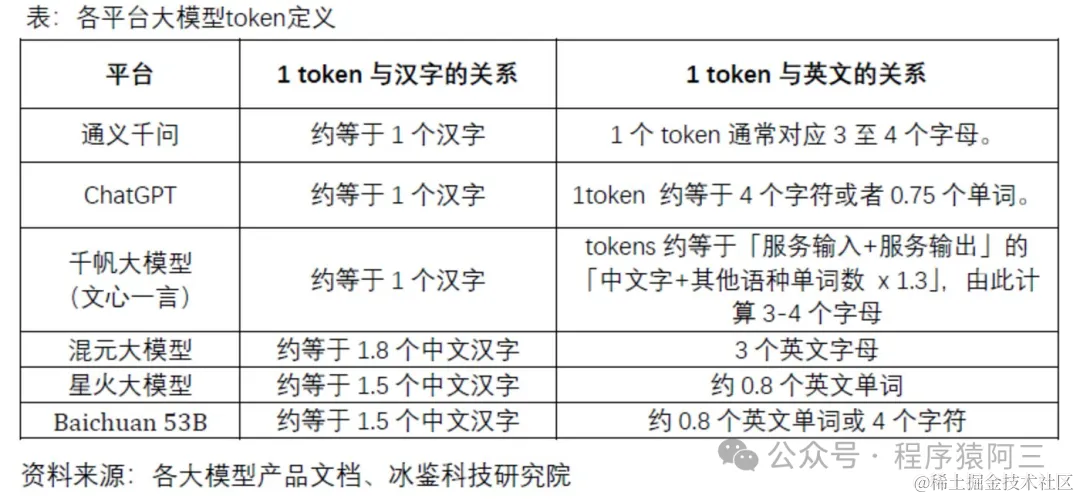
Token是用来计量大模型输入、输出的基本单位,也可以直观的理解为“字”或“词”。但是目前并没有统一计量标准,各家大模型平台根据自己的偏好“随意”定义。如腾讯1token≈1.8个汉字,通义千问、千帆大模型等1token=1个汉字,对于英文文本来说,1个token通常对应3至4个字母, 不同的模型对相同的输入分词, 分词结果是不一样的。
01 什么是Token?
对于普通用户很难理解Token这个概念, 这个概念是隐藏在模型内部的, 对于普通使用者来说,这种计价方式无疑是致命的, 所以对于大部分普通使用者,还是采用包月方式偏多, Token计价方式针对的是开发者,希望通过API方式进行调用,封装自己的应用。即使很多开发者如果没有进行自然语言相关开发,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4058
4058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











