






本周值得关注的大模型 / AIGC 前沿研究:
-
减少生成式 LLM 中的死记硬背现象
-
清华 KEG 团队推出强化自训练方法 ReST-MCTS*
-
清华、智谱 AI 团队推出超长视频理解基准 LVBench
-
何恺明新作:无需矢量量化的自回归图像生成
-
mDPO:多模态大语言模型的条件偏好优化
-
哈佛、牛津团队提出 LLM 数据选择新方法 CoLoR-Filter
-
牛津大学新研究:将深度贝叶斯主动学习用于 LLM 偏好建模
-
ChatGLM 技术报告:从 GLM-130B 到 GLM-4 AII Tools
-
CityGPT:增强大型语言模型的城市空间认知能力
-
微软、清华团队提出指令预训练框架
-
Google DeepMind:在代码补全中衡量 RLHF 的记忆效应
1.减少生成式 LLM 中的死记硬背现象
大语言模型会记忆和重复训练数据,从而造成隐私和版权风险。为此,来自马里兰大学、ELLIS Institute Tübingen 和马克斯·普朗克智能系统研究所对下一个 token 的训练目标提出了一个微妙的修改,称为 “金鱼损失”(goldfish loss)。在训练过程中,随机抽样的 token 子集会被排除在损失计算之外。这些被剔除的 token 不会被模型记忆,从而防止逐字复制训练集中的完整 token 链。
他们进行了大量实验来训练十亿规模的 Llama-2 模型,包括预训练和重新训练,结果表明可提取的记忆量显著减少,对下游基准几乎没有影响。
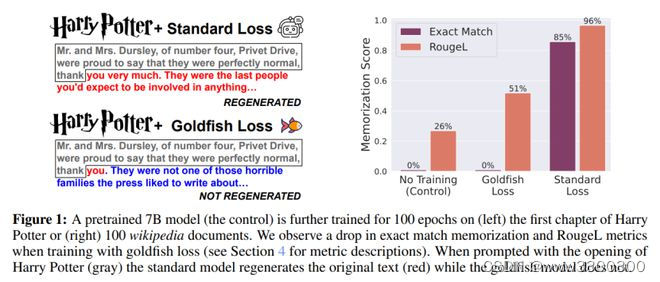
论文链接:
https://arxiv.org/abs/2406.10209
GitHub 地址:
https://github.com/ahans30/goldfish-loss
2.清华 KEG 团队推出强化自训练方法 ReST-MCTS*
最近的大语言模型(LLM)自训练方法大多依赖于 LLM 生成响应,并筛选出具有正确输出答案的响应作为训练数据。然而,这种方法通常会产生低质量的微调训练集,比如不正确的计划或中间推理。
在这项工作中,来自清华大学知识工程研究室(KEG)和加州理工学院的研究团队开发了一种强化自训练方法——ReST-MCTS*,其将过程奖励指导与树搜索 MCTS* 结合,来收集更高质量的推理轨迹和每步值,从而训练策略和奖励模型。通过基于树搜索的强化学习,ReST-MCTS* 规避了通常用于训练过程奖励的每一步人工标注:在给定特定任务正确答案的情况下,ReST-MCTS* 能够通过估计该步骤帮助得出正确答案的概率,推断出正确的过程奖励。这些推断出的奖励既是进一步完善过程奖励模型的目标,也有助于为策略模型的自训练选择高质量的轨迹。
他们首先证明,在相同的搜索预算下,ReST-MCTS* 中的树搜索策略比之前的 LLM 推理基线(如 Best-of-N 和 Tree-of-Thought )实现了更高的准确率。然后,他们展示了通过使用这种树搜索策略搜索到的踪迹作为训练数据,他们可以在多次迭代中持续增强三个语言模型,并超越 Self-Rewarding LM 等其他自训练算法。
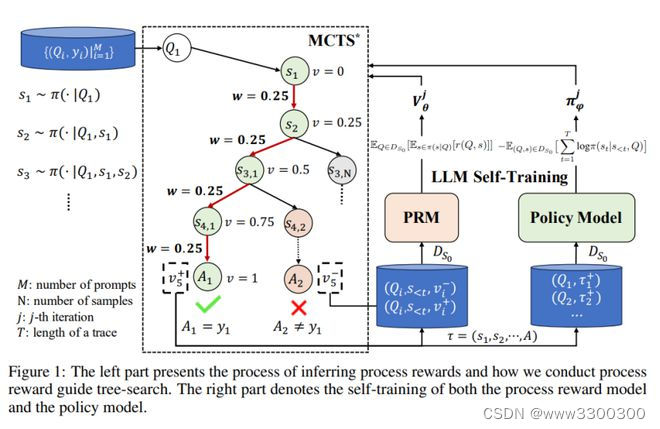
论文链接:
https://arxiv.org/abs/2406.03816
项目地址:
https://rest-mcts.github.io/
3.清华、智谱 AI 团队推出超长视频理解基准 LVBench
多模态大语言模型的最新进展显著提高了对短视频(通常在一分钟以内)的理解能力,并相应出现了一些评估数据集。然而,这些进步还不能满足现实世界应用的需求,比如用于长期决策的智能体、深入的电影评论和讨论以及现场体育评论,所有这些应用都需要理解长达数小时的长视频。
为了弥补这一差距,来自清华大学、智谱AI 和北京大学的研究团队推出了专门为长视频理解设计的基准测试——LVBench。这一数据集由公开来源的视频组成,包含一系列旨在理解长视频和提取信息的不同任务。LVBench 旨在检测多模态模型的长期记忆和扩展理解能力。
广泛的评估表明,当前的多模态模型在这些要求苛刻的长视频理解任务中仍然表现不佳。通过 LVBench,研究团队希望推动开发更先进的模型,从而应对长视频理解的复杂性。
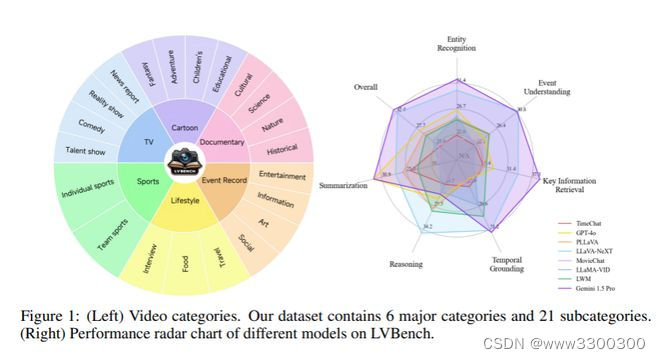
论文链接:
https://arxiv.org/abs/2406.08035
项目地址:
https://lvbench.github.io/
4.何恺明新作:无需矢量量化的自回归图像生成
传统观点认为,用于图像生成的自回归模型通常都伴随着向量量化的 token。
麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)何恺明团队与来自 Google DeepMind 和清华大学的合作者发现,虽然离散值空间有助于表示分类分布,但它并不是自回归建模的必要条件。
在这项工作中,他们建议使用扩散程序对每个 token 的概率分布进行建模,这样便可以在连续值空间中应用自回归模型。他们没有使用分类交叉熵损失,而是定义了一个扩散损失函数来为每个 token 概率建模。这种方法无需使用离散值 tokenizers,他们评估了其在各种情况下的有效性,包括标准自回归模型和广义掩码自回归(MAR)变体。通过去除矢量量化,他们提出的图像生成器在具有序列建模的速度优势的同时,还取得了很好的效果。他们希望这项工作能推动自回归生成技术在其他连续值领域和应用中的应用。
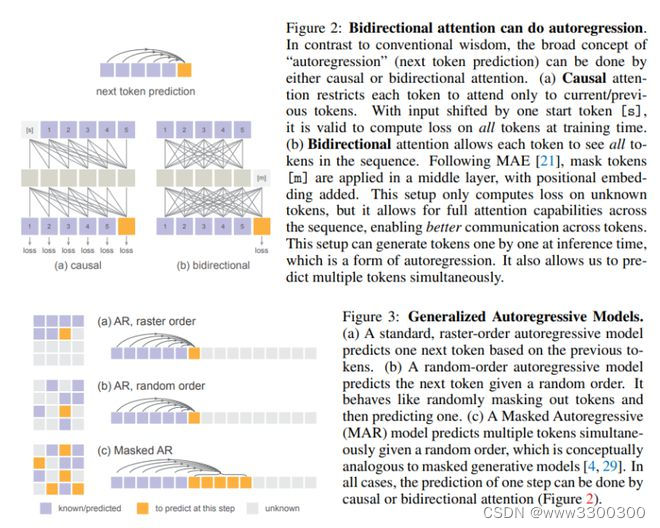
论文链接:
https://arxiv.org/abs/2406.11838
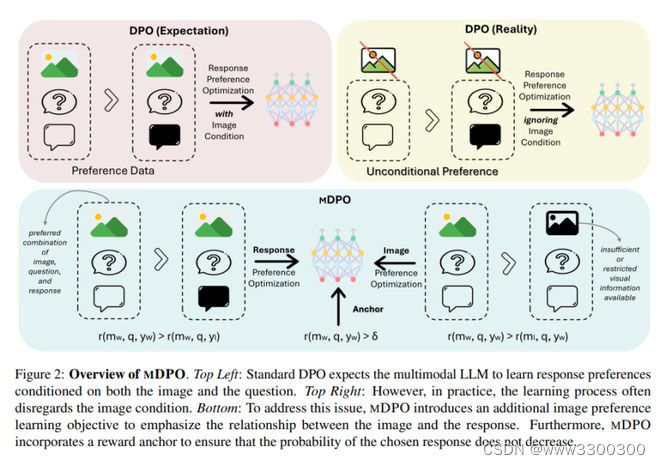
5.mDPO:多模态大语言模型的条件偏好优化
直接偏好优化(DPO)已被证明是大语言模型(LLM)对齐的有效方法。最近有研究尝试将 DPO 应用于多模态场景,但发现要实现一致的改进具有挑战性。
来自南加州大学、加利福尼亚大学戴维斯分校和微软的研究团队通过对比实验,发现了多模态偏好优化中的无条件偏好问题,即模型忽略了图像条件。为此,他们提出了一种多模态 DPO 目标 ——mDPO,通过同时优化图像偏好来防止仅语言偏好的过度优先化。此外,他们还提出了一个奖励锚,强制所选反应的奖励为正,从而避免其可能性的降低——这是相对偏好优化的一个固有问题。在两个不同规模的多模态 LLM 和三个广泛使用的基准上进行的实验表明,mDPO 有效地解决了多模态偏好优化中的无条件偏好问题,并显著提高了尤其在减少幻觉方面的模型性能。
论文链接:
https://arxiv.org/abs/2406.11839
6.哈佛、牛津团队提出 LLM 数据选择新方法 CoLoR-Filter
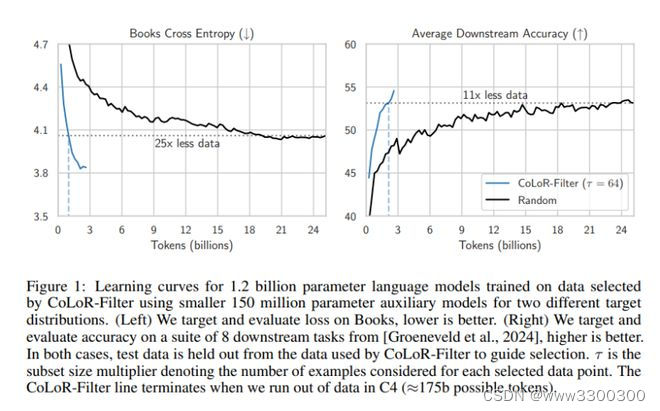
选择高质量的数据进行预训练对塑造语言模型的下游任务性能至关重要。确定最佳子集是一项重大挑战,因此需要可扩展的有效启发式方法。来自哈佛大学和牛津大学的研究团队提出了一种数据选择方法 —— 条件损失减少过滤 (CoLoR-Filter),利用贝叶斯启发法的经验,基于两个辅助模型的相对损失值,推理出一种简单且计算效率高的选择标准。
除了建模原理外,他们还在两个语言建模任务中对 CoLoR-Filter 进行了实证评估:(1)从 C4 中选择数据,用于在 Books 上进行领域适应性评估;(2)从 C4 中选择数据,用于一套下游选择题回答任务。通过更积极地进行子选择和使用小型辅助模型为大型目标模型选择数据,他们展示出了该方法良好的扩展性。
一个突出的结果是,使用一对 1.5 亿参数的辅助模型选择 CoLoR-Filter 数据,可以训练一个 1.2b 参数的目标模型,使其与在 25b 随机选择的 token 上训练的 1.2b 参数模型相匹配,而 Books 的数据要少 25 倍,下游任务的数据要少 11 倍。
论文链接:
https://arxiv.org/abs/2406.10670
GitHub 地址:
https://github.com/davidbrandfonbrener/color-filter-olmo
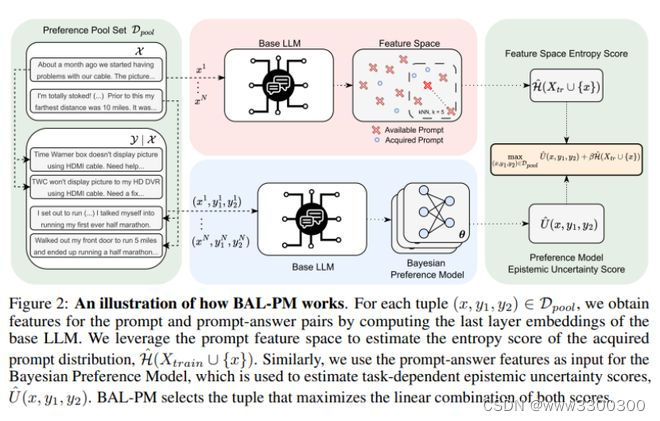
7.牛津大学新研究:将深度贝叶斯主动学习用于 LLM 偏好建模
近年来,利用人类偏好来引导大语言模型(LLM)的行为已经取得了显著的成功。然而,数据选择和标签仍然是这些系统尤其是在大规模应用中的瓶颈。因此,选择信息量最大的点来获取人类反馈,可以大大降低偏好标签的成本,促进 LLM 的进一步发展。贝叶斯主动学习(Bayesian Active Learning)为此提供了一个原则性框架,并在各种环境中取得了成功。然而,之前将其用于偏好建模的尝试并未达到预期效果。
来自牛津大学的研究团队发现原生(naive)的认识论不确定性估计会导致获取冗余样本。为此,他们提出了一种新颖的随机获取策略——贝叶斯主动学习器偏好建模(BAL-PM),它不仅能根据偏好模型锁定认识不确定性高的点,还能在所采用的 LLM 所跨的特征空间中寻求获取的提示分布熵的最大化。
实验证明,在两个流行的人类偏好数据集中,BAL-PM 所需的偏好标签减少了 33%-68%,超过了以前的随机贝叶斯获取策略。
论文链接:
https://arxiv.org/abs/2406.10023
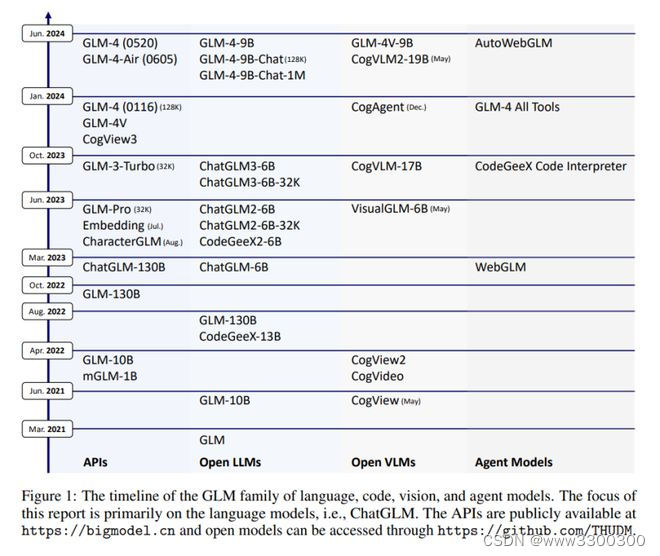
8.ChatGLM 技术报告:从 GLM-130B 到 GLM-4 AII Tools
GLM 技术团队介绍了 ChatGLM,这是一个不断发展的大语言模型系列。本报告主要关注 GLM-4 语言系列,包括 GLM-4、GLM-4-Air 和 GLM-4-9B。它们代表了 GLM 技术团队推出的前沿模型,这些模型是在吸取了前三代 ChatGLM 的所有经验和教训的基础上训练出来的。迄今为止,GLM-4 模型已在 10 万亿个 token(主要是中文和英文)以及 24 种语言的小型语料库上进行了预训练,并主要针对中文和英文的用法进行了对齐。高质量的对齐是通过多阶段的后训练过程实现的,其中包括监督微调和从人类反馈中学习。
评估结果表明,GLM-4 在 MMLU、GSM8K、MATH、BBH、GPQA 和 HumanEval 等通用指标方面与 GPT-4 非常接近,甚至优于 GPT-4;在指令跟随方面接近 GPT-4-Turbo(以 IFEval 衡量);在长上下文任务方面比肩 GPT-4 Turbo (128K) 和 Claude 3;在中文对齐方面优于 GPT-4(以 AlignBench 衡量)。
GLM-4 All Tools 模型经过进一步对齐,能够理解用户意图,并自主决定何时以及使用哪种工具(包括网络浏览器、Python 解释器、文本到图像模型以及用户自定义函数)来有效完成复杂任务。在实际应用中,GLM-4 All Tools 在通过网页浏览访问在线信息和使用 Python 解释器解决数学问题等任务中的表现超过了 GPT-4 All Tools。
GLM 技术团队开源了一系列模型,包括 ChatGLM-6B(1、2、3 代)、GLM-4-9B(128K、1M)、GLM-4V-9B、WebGLM 和 CodeGeeX,仅在 2023 年就在 Hugging Face 上吸引了超过 1000 万次下载。
论文链接:
https://arxiv.org/abs/2406.12793
GitHub 地址:
https://github.com/THUDM
Hugging Face 地址:
https://huggingface.co/THUDM
9.CityGPT:增强大型语言模型的城市空间认知能力
大语言模型(LLM)以其强大的语言生成和推理能力在许多领域取得了成功,如数学和代码生成。然而,由于在训练过程中缺乏现实世界的语料库和知识,它们通常无法解决城市空间中许多实际任务。
来自清华大学的研究团队提出了 CityGPT 这一系统框架,旨在通过在模型中构建城市规模的世界模型,增强 LLM 在理解城市空间和解决相关城市任务方面的能力。首先,研究团队构建了一个多样化的指令微调数据集 CityInstruction,用于有效注入城市知识和增强空间推理能力。通过使用 CityInstruction 和一般指令数据的混合,团队对各种 LLM(如 ChatGLM3-6B、Qwen1.5 和 LLama3 系列)进行微调,增强它们的能力而不损害其一般能力。为进一步验证所提方法的有效性,团队构建了一个全面的基准测试 CityEval,评估 LLM 在各种城市场景和问题上的能力。
广泛的评估结果表明,使用 CityInstruction 训练的小型 LLM 在 CityEval 的综合评估中可以达到与商业 LLM 竞争力相当的表现。

论文链接:
https://arxiv.org/abs/2406.13948
GitHub 地址:
https://github.com/tsinghua-fib-lab/CityGPT
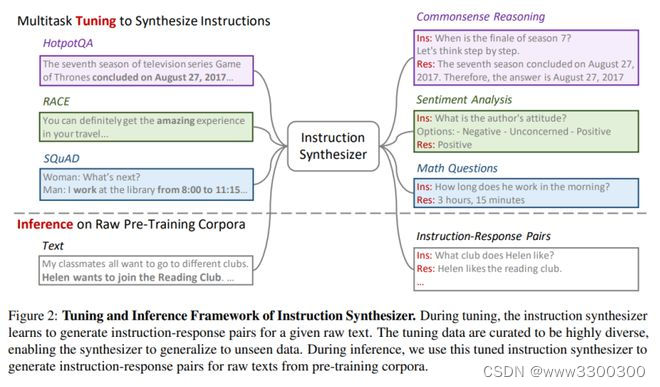
10.微软、清华团队提出指令预训练框架
无监督的多任务预训练是近期语言模型成功的关键方法。然而,监督多任务学习在训练后的阶段仍然显示出显著的潜力,因为其扩展趋势指向更好的泛化能力。
来自微软研究院和清华大学的研究团队通过提出“指令预训练”框架,探索了监督多任务预训练的可能性。该框架通过生成指令-响应对,以可扩展的方式增强大规模原始语料库,用于预训练语言模型。这些指令-响应对由基于开源模型的高效指令生成器生成。在实验中,研究团队生成了 2 亿个覆盖 40 多个任务类别的指令-响应对,从而验证指令预训练的有效性。
在从头开始的预训练中,指令预训练不仅持续增强了预训练的基础模型,还在进一步的指令微调中获得更多益处。在持续预训练中,指令预训练使 Llama3-8B 的性能与甚至超过 Llama3-70B。
论文链接:
https://arxiv.org/abs/2406.14491
GitHub 地址:
https://github.com/microsoft/LMOps
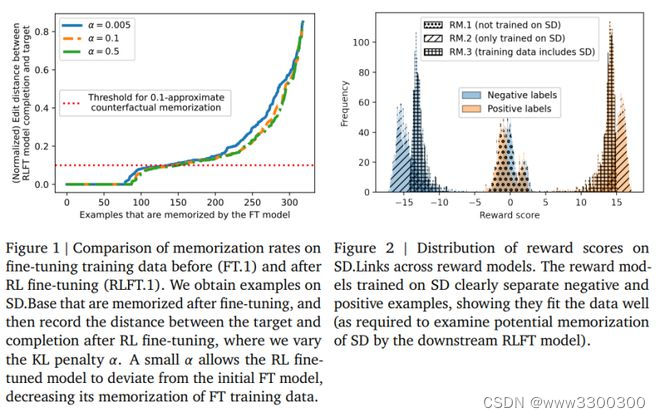
11.Google DeepMind:在代码补全中衡量 RLHF 的记忆效应
基于人类反馈的强化学习(RLHF)已经成为让大模型符合用户偏好的主要对齐方法。与微调不同,关于训练数据记忆的研究很多,但对于 RLHF 对齐过程中的记忆效应及其引入方式尚不清楚。理解这种关系很重要,因为实际用户数据可能会被收集并用于对齐大模型;如果用户数据在 RLHF 过程中被记忆并后续被复现,可能会引发隐私问题。
Google DeepMind 研究团队分析了训练数据记忆如何在 RLHF 的各个阶段出现和传播。团队专注于代码补全模型的研究,因为代码补全是大语言模型最流行的用例之一。研究发现,与直接微调数据相比,RLHF 显著降低了用于奖励建模和强化学习的数据被记忆的几率,但在 RLHF 微调阶段已经被记忆的示例在大多数情况下仍会在 RLHF 后保持被记忆。
论文链接:
https://arxiv.org/abs/2406.11715

















 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











