







准确率(precision)P:
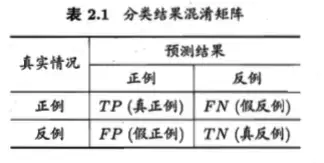
其中,TP(真正,True Positive)表示真正结果为正例,预测结果也是正例;FP(假正,False Positive)表示真实结果为负例,预测结果却是正例;TN(真负,True Negative)表示真实结果为正例,预测结果却是负例;FN(假负,False Negative)表示真实结果为负例,预测结果也是负例。显然,TP+FP+FN+TN=样本总数
精确率(Precision)P:
P=TP/(TP+FP)
TP(true positive) FP(false positive)
P是代表预测为真且真实为真的数据占预测为真数据的比例。
召回率(recall)R:
R=TP/(TP+FN)
FN(false negitive)
R是代表预测为真且真实为真的数据占真实为真数据的比例
此外:准确率和错误率也是常用评估指标
准确率accuracy
准确率(accuracy)=(TP+TN)/(TP+FP+TN+FN)
错误率 error rate
错误率(error rate)=(FP+FN)/(TP+FP+TN+FN)
精确率与准确率
精确率和准确率容易混淆,精确率是一个二分类指标,而准确率应用于多分类,其计算公式为:
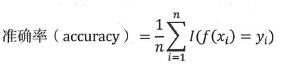
ROC曲线
Receiver Operating Characteristic Curve
ROC曲线横坐标为假阳性率:False Positive Rate --- FPR
ROC曲线纵坐标为真阳性率:True Positive Rate --- TPR
FPR=FP/N -----FP为N个负样本中被分类器预测为正样本个数
TPR=TP/P -----TP是P个正样本中被分类器预测为正样本个数
P是真实正样本数量
N是真实负样本数量
AUC
AUC指的是ROC曲线下的面积大小,该值能够量化的反映基于ROC曲线行列出的模型性能,计算AUC只需要沿着ROC横轴做积分就可以了。一般ROC曲线都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器),所以AUC取值一般在0.5~1之间,AUC越大,分类器分类效果越好。
AUC是一个数值,当仅仅看 ROC 曲线分辨不出哪个分类器的效果更好时,用这个数值来判断

AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
总结:ROC是由点(TPR,FPR)组成的曲线,AUC就是ROC的面积。AUC越大越好。
F1 Score
F1分数可以看作是模型精准率和召回率的一种加权平均,它的最大值是1,最小值是0。
F1 Score=2*Precison*Recall/(Precision+Recall)
我们使用调和平均而不是简单的算术平均的原因是:调和平均可以惩罚极端情况。一个具有 1.0 的精度,而召回率为 0 的分类器,这两个指标的算术平均是 0.5,但是 F1 score 会是 0。F1 score 给了精度和召回率相同的权重,它是通用 Fβ指标的一个特殊情况,在 Fβ中,β 可以用来给召回率和精度更多或者更少的权重。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









