






说明:
最近工作中用到了图片对比,趁着这个机会,也了解了下常见的一些图像对比算法,简单做下整理。
常见的图片对比算法有:
直方图算法、灰度图算法、哈希算法、MD5、余弦相似度、欧氏距离。
下面是对每种算法的一个简要说明,旨在提供一个易于理解的概览,适合新手入门:
-
直方图算法: 直方图是表示图像中像素强度分布的图形方法。在图像对比中,通过比较两张图像的色彩(或灰度)直方图,可以评估它们在颜色(或亮度)分布上的相似度。这种方法简单快速,但可能忽略空间信息,对图像旋转、缩放敏感。
-
灰度图算法: 这通常是指将彩色图像转换为灰度图像的过程,作为后续处理的基础。灰度图只包含亮度信息,去除了色彩信息,简化了图像处理的复杂度。在对比时,可以通过比较灰度图像的像素值来评估相似性。
-
哈希算法: 哈希算法将图像转换为短的、固定长度的指纹(哈希值),用于快速比较。常见的有均值哈希(Average Hash),差值哈希(Difference Hash),感知哈希(Perceptual Hash)等。这些算法能够高效检测图像是否被修改或判断图像之间的相似度,但可能会有误报和漏报的情况。
-
MD5: MD5严格来说是一种非图像专用的哈希函数,用于生成任意数据的128位指纹。尽管MD5有时也被用于图像完整性校验,但它不适用于图像相似度比较,因为它对微小变化非常敏感,且没有考虑到视觉上的相似性。
-
余弦相似度: 该方法主要用于向量空间中度量两个非零向量方向的相似度。在图像处理中,将图像表示为特征向量后,通过计算它们的余弦相似度来评估相似性。这种方法关注的是方向而非大小,适用于比较图像内容的相对构成。
-
欧氏距离: 欧氏距离是最常见的距离度量方法之一,用于计算两点间的真实距离。在图像处理中,可以将图像的像素值或特征向量看作多维空间中的点,通过计算两点间的欧氏距离来衡量它们的差异。距离越小,图像越相似。但这种方法对尺度和旋转敏感。
每种算法都有其适用场景和局限性,实际应用中可能需要根据具体需求选择合适的算法或结合多种方法以达到最佳效果。下面是各个算法的详细介绍
一、 直方图算法
什么是直方图?
直方图又称为质量分布图,是统计报告图的一种,也是反应资料变化情况的工具,是由英国数学家卡尔。皮尔逊引入。
直方图分为正常、异常
1)正常性:代表过程处于稳定状态
2)异常:孤岛型、折齿型、偏态型、平顶型、陡壁型、双峰型
扫盲相关解释:
单通道直方图:就是把图片颜色保留为一种颜色,其他颜色去掉
通道,是指存储图像颜色信息的独立原色平面。可以把通道看做是某种颜色的集合,比如红色通道,他记录了图像中不同位置的红色深度(即红色的灰度),除了红色以外,这个通道中没有记录其他颜色的信息。
巨大多数可见光可以通过将红、绿、蓝三原色按照不同的比例和强度混合来表示。原色的灰度分别由一个颜色通道记录,最后合成各种颜色。
通道有很多:RGB、红、绿、蓝、明度、颜色。
相关解释:https://www.sohu.com/a/538172620_121219579
直方图算法
按照某种距离度量的标准对两幅图像的直方图进行相似度的测量
优点:计算量比较小
缺点:直方图反映的是图像灰度值得概率分布,并没有图像的空间位置信息在里面,因此,会出现误判;比如纹理结构相同,但明暗不同的图像,应该相似度很高,但实际结果是相似度很低,而纹理结构不同的,但敏感相近的图像,相似度却很高
说明:
两幅图像之间的距离度量,采用的是巴氏距离或归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的方法。
相关使用:单通道直方图、RGB三通道直方图
1)单通道直方图
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#单通道直方图
def histogram(image1,image2):
#灰度直方图算法
#计算单通道的直方图的相似值
hist1=cv2.calcHist([image1],[0],[256],[0.0,255.0])
hist2=cv2.calcHist([image2],[0],[256],[0.0,255.0])
#计算直方图的重合度
degree=0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree=degree+(1-abs(hist1[i]-hist[i])/max(hist1[i],hist2[i]))
else:
degree=degree+1
degree=degree/len(hist1)
return degree2)RGB三通道直方图
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#三通道直方图
def Multiparty_histogram(self,image1,image2,size(256,256)):
#RGB每个通道的直方图相似度
#将图像resize后,分离为RGB三个通道,再计算每个通道的相似度
image1=cv2.resize(image1,size)
image2=cv2.resize(image2,size)
sub_image1=cv2.split(image1)
sub_image2=cv2.split(image2)
sub_data=0
for im1,im2 in zip(sub_image1,sub_image2):
sub_data +=self.calculate(im1,im2)
sub_data=sub_data/3
return sub_data二、灰度图算法
利用灰度图的值、均值、方差计算图像的差异性
1、MSE(Mean Squared Error)均方误差:针对单通道灰度图
MSE = (1/n) * Σ(y_i - y_pred_i)^2
其中:
- n为样本个数
- y_i 为第 i 个样本的真实值
- y_pred_i 为第 i 个样本的预测值
说明:
MSE通过计算预测值与真实值的平均平方差来表示,值越小,小时模型预测得越好。MSE的计算步骤包括:首先计算每个样本的预测误差,即真实值与预测值的差值;然后计算这些预测误差的平方;最后,讲这些平方误差求和并除以样本数量n,得到MSE值
缺点:
当差值大于1时,会放大误差;而当差值小于1时,则会缩小误差,这是平方运算决定的。MSE对于较大的误差(>1)给予较大的惩罚,较小的误差(<1)给予较小的惩罚。也就是说,对离群点比较敏感,收其影响较大。
2、SSIM(Structural Similarity)结构相似性:针对单通道灰度图
是一种衡量两幅图相似度的指标。
SSIM公式基于样本x和y之间的三个比较衡量:亮度(luminance)、对比度(contrast)、结构(structure)

𝝁𝒙为均值, 𝝈𝒙为方差, 𝝈𝒙𝒚表示协方差。

常数𝑪𝟏, 𝑪𝟐, 𝑪𝟑是为了避免当分母为 0 时造成的不稳定问题。

在实际应用中,可以利用滑动窗将图像分块,令分块总数为N,考虑到窗口形状对分块的影响,采用高斯加权计算每一窗口的均值、方差以及协方差,然后计算对应块的结构相似度SSIM,最后将平均值作为两图像的结构相似性度量,即平均结构相似性SSIM。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
def contrast_image(imageA,imageB):
"""
对比两张图片的相似度,相似度等于1,完美匹配
:param imageA
:param imageB
:return:
"""
imageA = cv2.imread(imageA)
imageB = cv2.imread(imageB)
grayA = cv2.cvtColor(imageA,cv2.COLOR_BGR2GRAY)
grayB = cv2.cvtColor(imageB,cv2,COLOR_BGR2GRAY)
#计算两个灰度图像之间的结构相似度指数,相似度等于1完美匹配
(score,diff)=structural_similarity(grayA,grayB,full=True)
diff = (diff*255).astype("unit8")
print("SSIM:{}".format(score))
return score,diff3、图片相似度算法(对像素求方差并对比)
步骤:1)缩放图片2)灰度处理3)计算平均值4)计算方差5)比较方差
4、PSNR
PSNR(Peak Signal to Noise Ratio),峰值信噪比,是一种基于像素点间误差的图像质量评价指标。他通过计算图像的均方误差(MES)并转化为分贝(dB)单位来衡量图像的失真程度。PSNR数值越大,表示图像的失真越小,即图像质量越好。
然而,PSNR并未考虑到人眼的视觉特性,如人眼对空间频率较低的对比差异敏感较高、人眼对亮度对比差异的敏感度较色度高,以及人眼对一个区域的感知结果会受到其周围临近区域的影响等因素,因此有时候评价结果与人的主观感觉不一致。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
def PSNR(img1,img2):
mse = np.mean((img1/255.-img2/255.)**2)
if mse == 0:
return 100
PIXEL_MAX = 1
return 20*math.log10(PIXEL_MAX/math.sqrt(mse))PSNR和SSIM区别
- PSNR(Peak Signal to Noise Ratio),峰值信噪比,是一种基于像素点间误差的图像质量评价指标。他通过计算图像的均方误差(MES)并转化为分贝(dB)单位来衡量图像的失真程度。PSNR数值越大,表示图像的失真越小,即图像质量越好。
然而,PSNR并未考虑到人眼的视觉特性,如人眼对空间频率较低的对比差异敏感较高、人眼对亮度对比差异的敏感度较色度高,以及人眼对一个区域的感知结果会受到其周围临近区域的影响等因素,因此有时候评价结果与人的主观感觉不一致。
- SSIM(Structural Similarity Index),结构相似指数,是一种全参考的图像质量评价指标。他从亮度、对比度和结构三个方面度量图像的相速度。SSIM的取值范围,值越大表示图像失真越小,即图像质量越好。SSIM考虑了图像内容的结构信息,有利于更准确的评价图像质量。
与PSNR不同,SSIM在图像去噪、图像相似度评价上表现优于PSNR,因为它更接近与人眼的视觉感知。
总结:
PSNR和SSIM主要区别在于他们的计算方法和应用场景。PSNR主要关注图像的失真程度,适用于需要精确度和灵敏度的场景;而SSIM则关注图像的结构相似度,适用于需要保留图像细节和结构的场景。在实际应用中,综合使用PSNR和SSIM可以更加全面的评价图像的质量。
三、哈希算法
计算图片的哈希后,利用汉明距离计算两张图片的差异
哈希相似度
实现突破相似度对比的hash算法有三种:均值哈希算法(AHash)、差值哈希算法(DHash)、感知哈希算法(PHash)
图片转成哈希表示后,用汉明距离计算两个图片的差距
AHash:平均值哈希,速度比较快,但是常常不太精确
PHash:感知哈希,精确度比较高,但是速度方面较差一些
DHash:差异值哈希。精确度较高,且速度也非常快。
1.均值哈希
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#均值哈希算法
#步骤:
#1.缩小尺寸:将图片缩小到8x8的尺寸,总共64个像素。作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异
#2.简化色彩:将缩小后的图片,转为64级灰度。也就是说所有像素点总共64种颜色
#3.计算均值:计算所有64个像素的灰度平均值
#4.比较像素的灰度:将每个像素的灰度,与平均值进行比较。大于或者等于平均值,记为1;小于平均值,记为0
#5.计算哈希值:将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图的指纹。组合的次序并不重要,只要保证所有图片都采用同样的次序就行了。
def aHash(img):
#平均值哈希算法
#缩放为8*8
img = cv2.resize(img,(8,8))
#转换为灰度图
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#s为像素和初值为0,hash为hash值初值为‘’
s=0
hash=''
#遍历累加求像素和
for i in range(8):
for j in range(8):
s = s_gray[i,j]
#求平均灰度
avg = s/64
#灰度大于平均值为1,相反为0,生成图片的hash值
for i in range(8):
for j in range(8):
if gray[i,j] >avg:
hash_str = hash+'1'
else:
hash_str = hash+'0'
return hash_str分析:均值哈希算法计算速度快,不受图片尺寸大小的影响,但是缺点就是对均值敏感,例如对图像进行伽马校正或直方图均衡就会影响均值,从而影响最终的hash值。
2.感知哈希算法(PHash)
感知哈希算法是一个比均值哈希算法更为健壮的一种算法,与均值哈希算法的区别在于感知哈希算法是通过DCT(离线余弦变化)来获取图片的低频信息
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#感知哈希算法
#步骤:
#1.缩小尺寸:PHash以小图片开始,但图片大于8x8,32x32是最好但。这样做的目的是简化DCT的计算,而不是减少频率。
#2.简化色彩:将图片转化成灰度图像,进一步简化计算量
#3.计算DCT:计算图片的DCT变换,得到32x32的DCT系数矩阵
#4.缩小DCT:虽然DCT的结果是32x32大小的矩阵,但我们只要保留左上角的8x8的矩阵,这部分呈现了图片中的最低频率
#5.计算平均值:如同均值哈希一样,计算DCT的均值
#6.计算hash值:这是最主要的一步,根据8x8的DCT矩阵,设置0或1到64位的hash值,大于等于DCT均值的设为1,下雨DCT均值的设为0。组合在一起,就构成了一个64位的整数,这就是这张图片的指纹
#结果并不能告诉我们真实性的低频率,智能粗略的告诉我们相对于平均值频率的相对比例。只要图片的整体结构保持不变,hash结果值就不变。能够避免伽玛校正或颜色直方图被调整带来的影响。对于变形程度在25%以内的图片也能精准识别
def pHash(img):
#感知哈希算法
#缩放32x32
img = cv2.resize(img,(32,32)) #,interpolation=cv2.INTER_CUBIC
#转换为灰度图
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#将灰度图转为浮点型,再进行dct变换,cv2.dct()是离散余弦变换
dct = cv2.dct(np.float32(gray))
#opencv实现的掩码操作
dct_roi=dct[0:8,0:8]
hash =[]
avrage = np.mean(dct_roi)
for i in range(dct_roi.shape[0]):
for j in range(dct_roi.shape[1]):
if dct_roi[i,j] >avrage:
hash.append(1)
else:
hash.append(0)
return hash
3.差值哈希算法(dHash)
比PHash,AHash的速度要快,相比AHash,dHash在效率几乎相同的情况下的效果要更好,他是基于渐变实现的。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#差值哈希算法
#步骤:
#1.缩小尺寸:收缩到8x9(高x宽)的大小,以便它有72的像素点
#2.转化为灰度图:把缩放后的图片转化为256阶的灰度图
#3.计算差异值:dHash算法工作在相邻像素之间,这样每行9个像素之间产生8个不同的差一点,一共8行,则产生64个差异值
#4.获取指纹:如果左边的像素比右边的更亮,则记录为1,否则为0
def dHash(img):
#差值哈希算法
#缩放8x8
img = cv2.resize(img,(9,8)) #,interpolation=cv2.INTER_CUBIC
#转换为灰度图
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
hash = ''
#每一行前一个像素大于后一个像素为1,相反为0,生成哈希
for i in range(8):
for j in range(8):
if gray[i,j] > gray[i,j+1]
hash_str = hash + '1'
else:
hash_str = hash + '0'
return hash_str汉明距离计算两个图像的哈希值
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
def cmpHash(hash1,hash2):
n=0
#hash长度不同则返回-1代表传参出错
if len(hash1)!= len(hash2):
return -1
#遍历判断
for i in range(len(hash1)):
#不相等则n计数+1,n最终为相似度
if hash1[i] !=hash2[i]:
n=n+1
return n四、MD5
粗暴的md5比较返回是否完全相同
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
def md5_similarity(img1_path,img2_path)
file1=open(img1_paht,"rb")
file2=open(img2_path,"rb")
md=hashlib.md5()
md.update(file1.read())
res1=md.hexdigest()
md=hashlib.md5()
md.update(file2.read())
res2=md.hexdigest()
return res1 == res2五、余弦相似度
把图片表示成一个向量,两个向量夹角的余弦值作为衡量两个个体间差异的大小
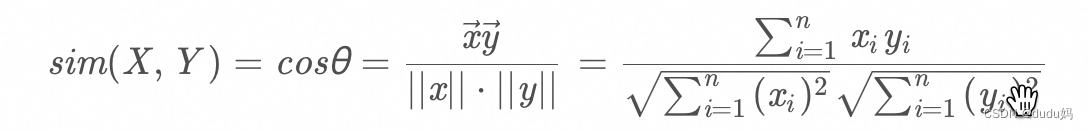
六、欧氏距离
欧几里德距离,也称为欧式距离,衡量的是多维空间中各个点之间的绝对距离
假设想x,y是n维空间的两点,他们之间的欧几里德距离公式如下:
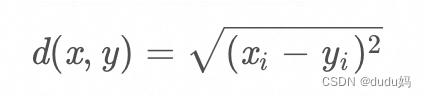
当n=2的时候,欧几里德距离就是平面上两点之间的距离
欧几里德相似度计算公式如下:
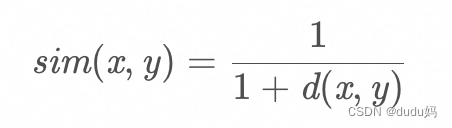
欧氏距离与余弦距离的区别:
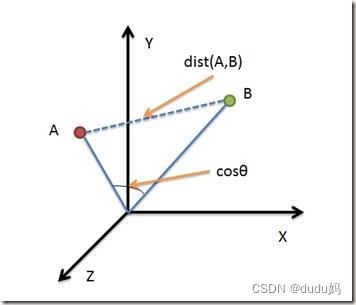
从图中可以看出:
- 欧式距离衡量的是空间个点的绝对距离,跟各个点所在的位置坐标直接相关
余弦距离衡量的是空间向量的夹角,更加体现在方向上的差异,而不是位置。
如果保持A点位置不变,B点朝原方向原理坐标轴原点,那么这个时候余弦距离cos是保持不变的(因为夹角没有发生变化),而A、B两点的距离显然是在发生改变,这是欧氏距离和余弦距离之间的不同之处
2)欧式距离和余弦距离各自有不同的计算方式和衡量特征,因此他们适用于不同的数据分析模型:
欧式距离能够体现个体数据特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不同意的问题(因为余弦距离对绝对数值不敏感)
文中相关内容参考了 图像相似度对比方法_图片相似度对比-CSDN博客 文章以及ai相关提供的信息















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









