







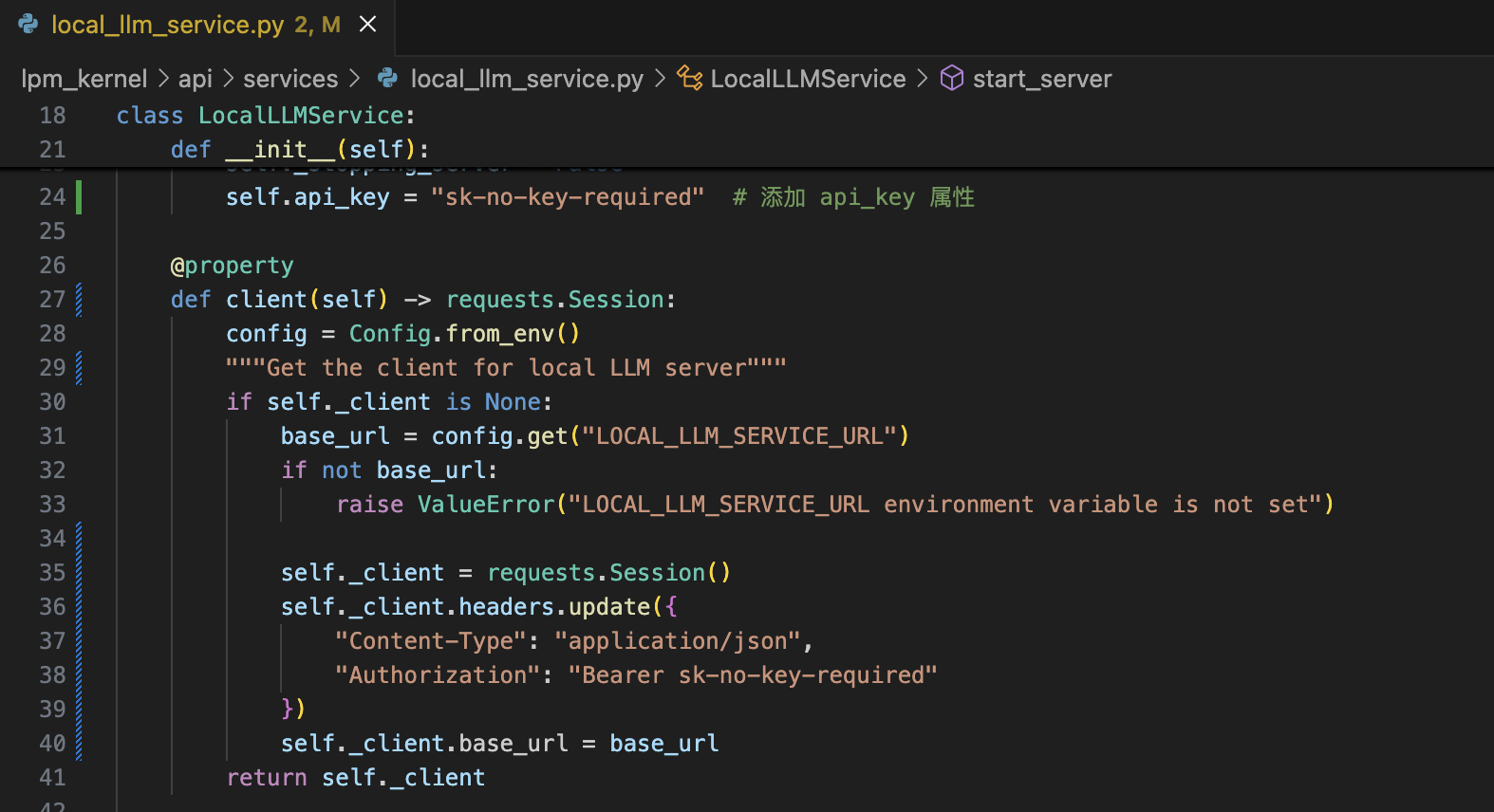
官方版本Second Me,默认需要使用gpt-mini-4o才能正常训练,ollama使用OpenAI接口访问总是出现502错误,使用curl访问是成功的,说明OpenAI接口不兼容ollama的v1 chat接口(v1/embeddings可以正常使用),因此训练Second Me的过程中总会在Augment Content Retention 这步失败,而这步失败的主要原因是因为GraphRag 脚本(Second-Me/lpm_kernel/L2/data_pipeline/data_prep/scripts/graphrag_indexing.sh)执行失败了,没有生成Augment Content Retention需要的Second-Me/resources/L1/graphrag_indexing_output/subjective/entities.parquet文件,为了解决本地训练的问题,我将Second Me中所有使用到OpenAI接口的地方都统一修改为使用requests来实现。
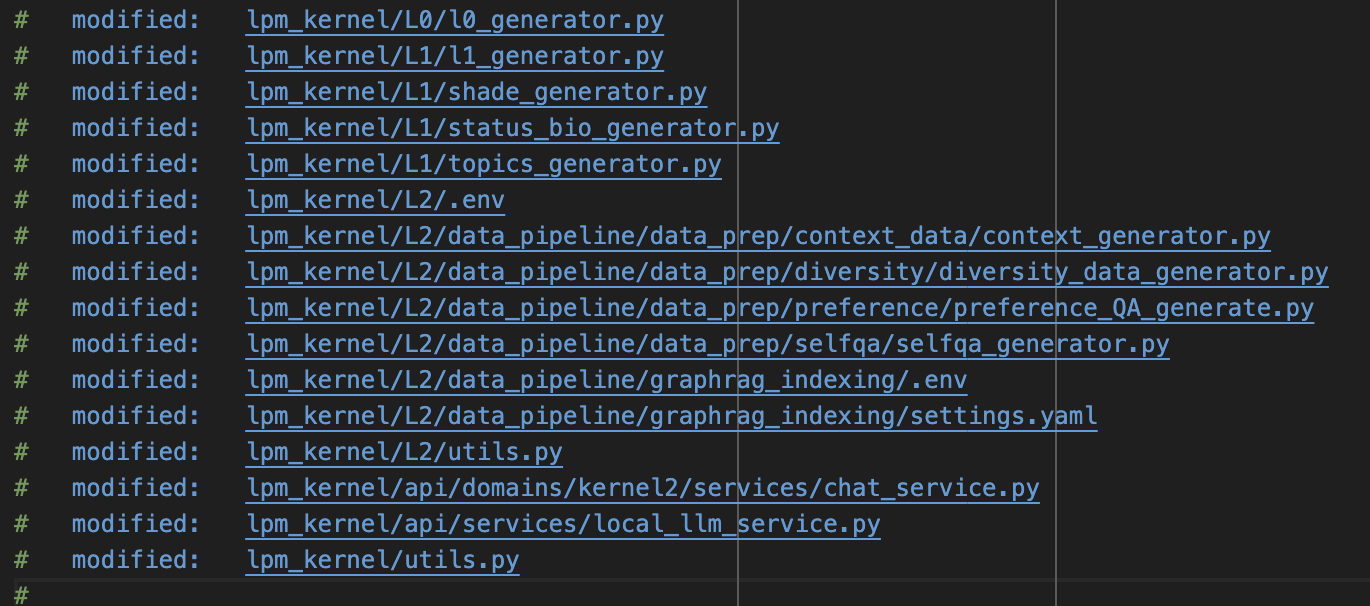
涉及的修改文件的比较多,列表如下:
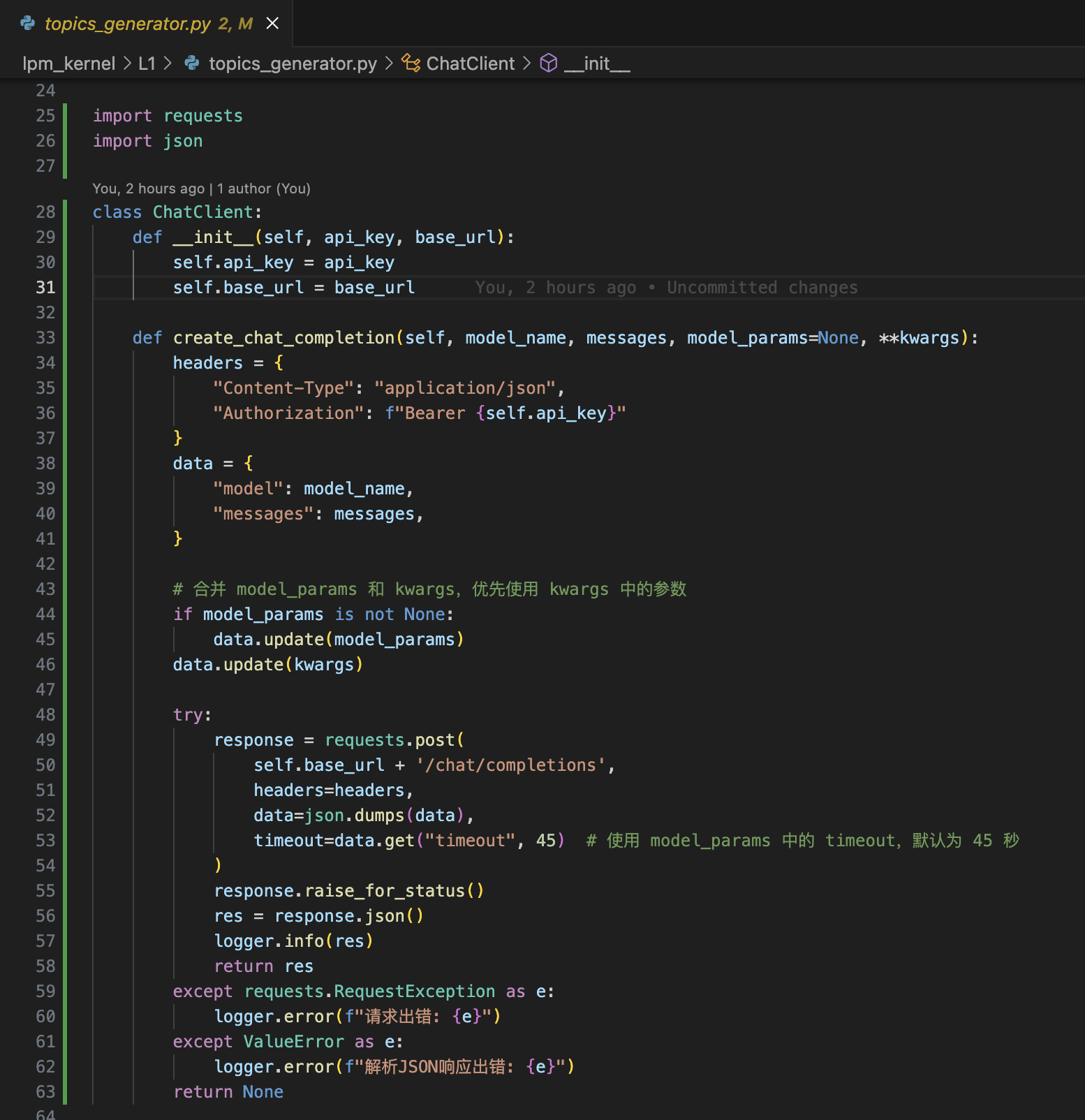
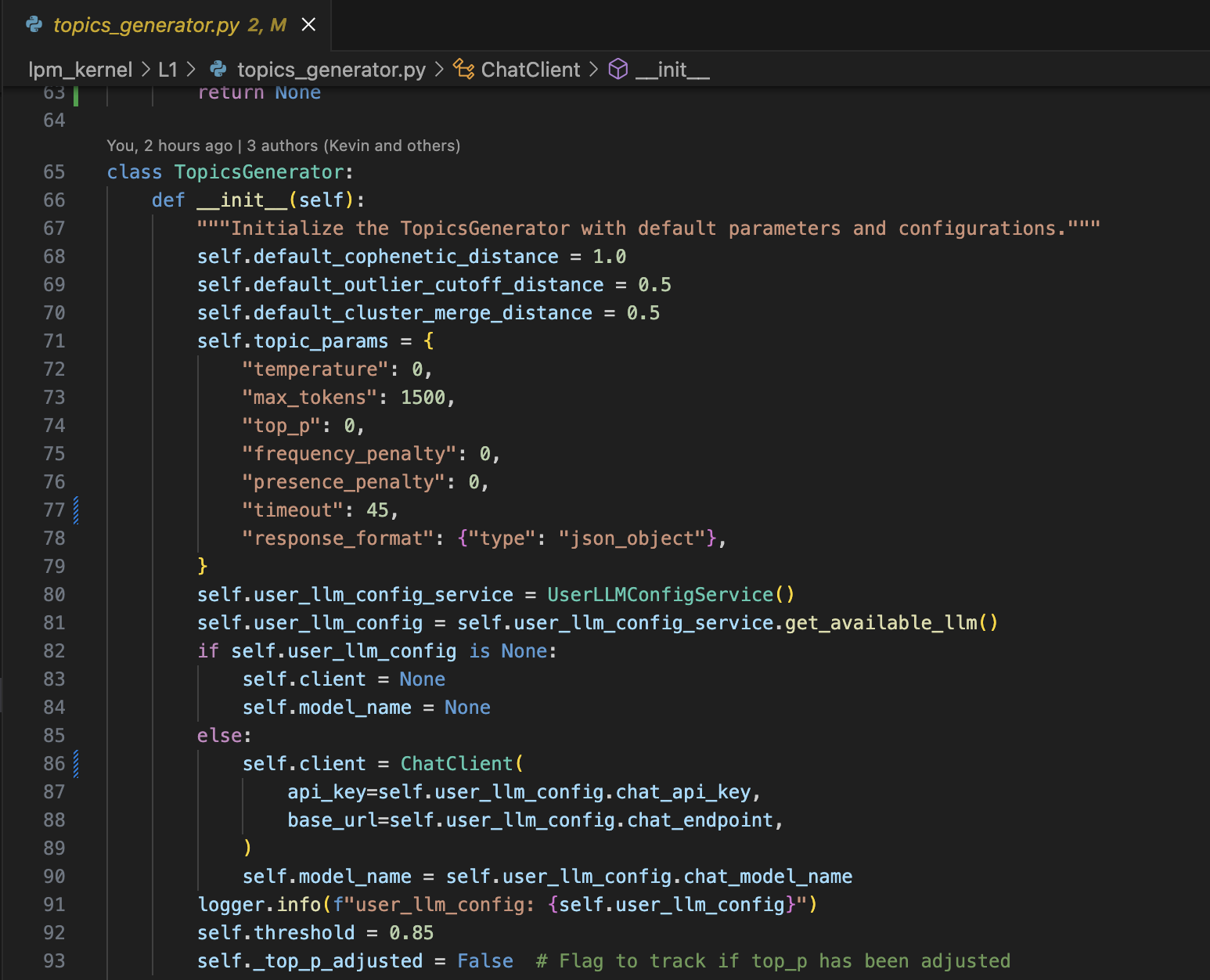
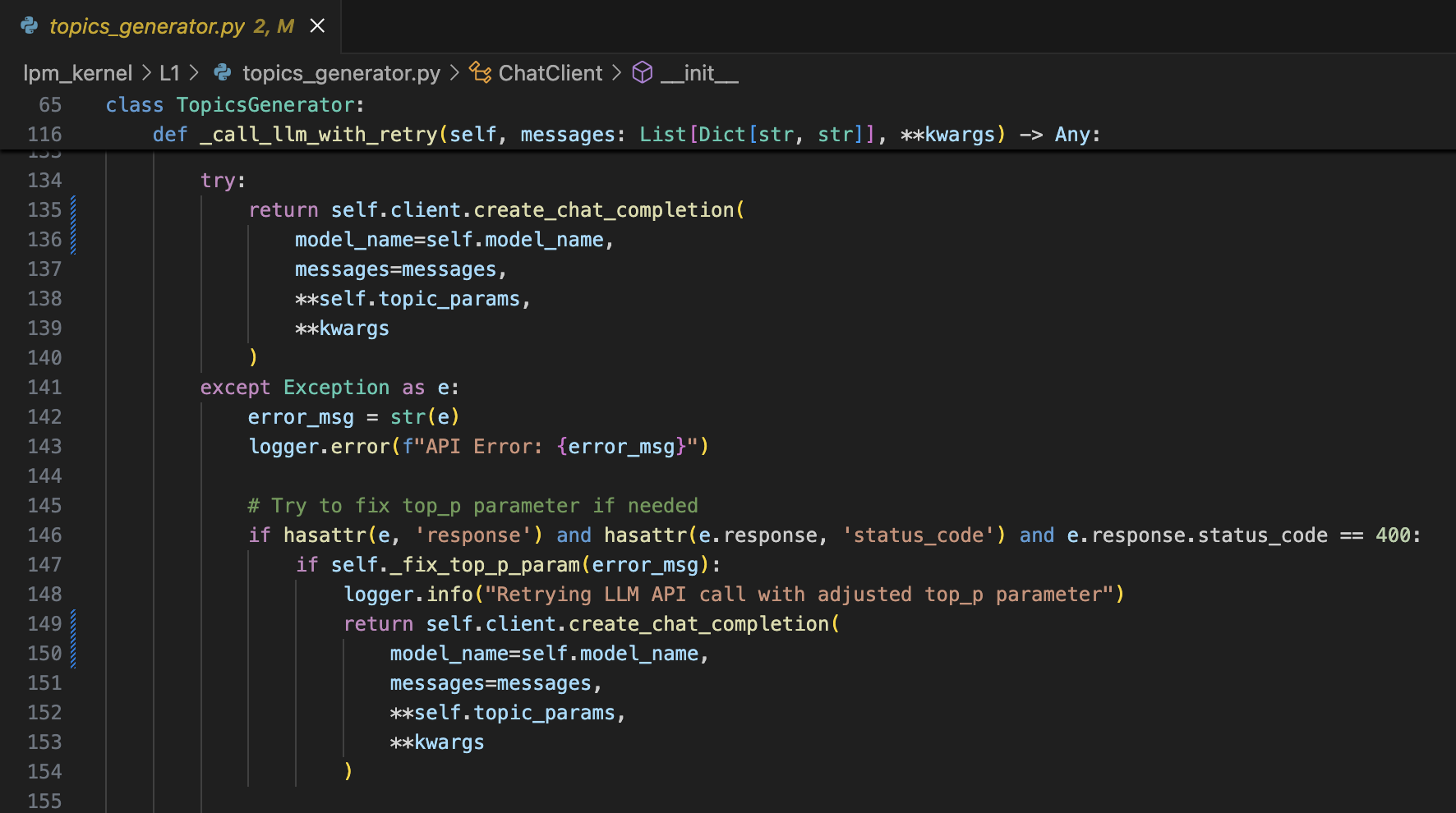
修改的代码参考如下:
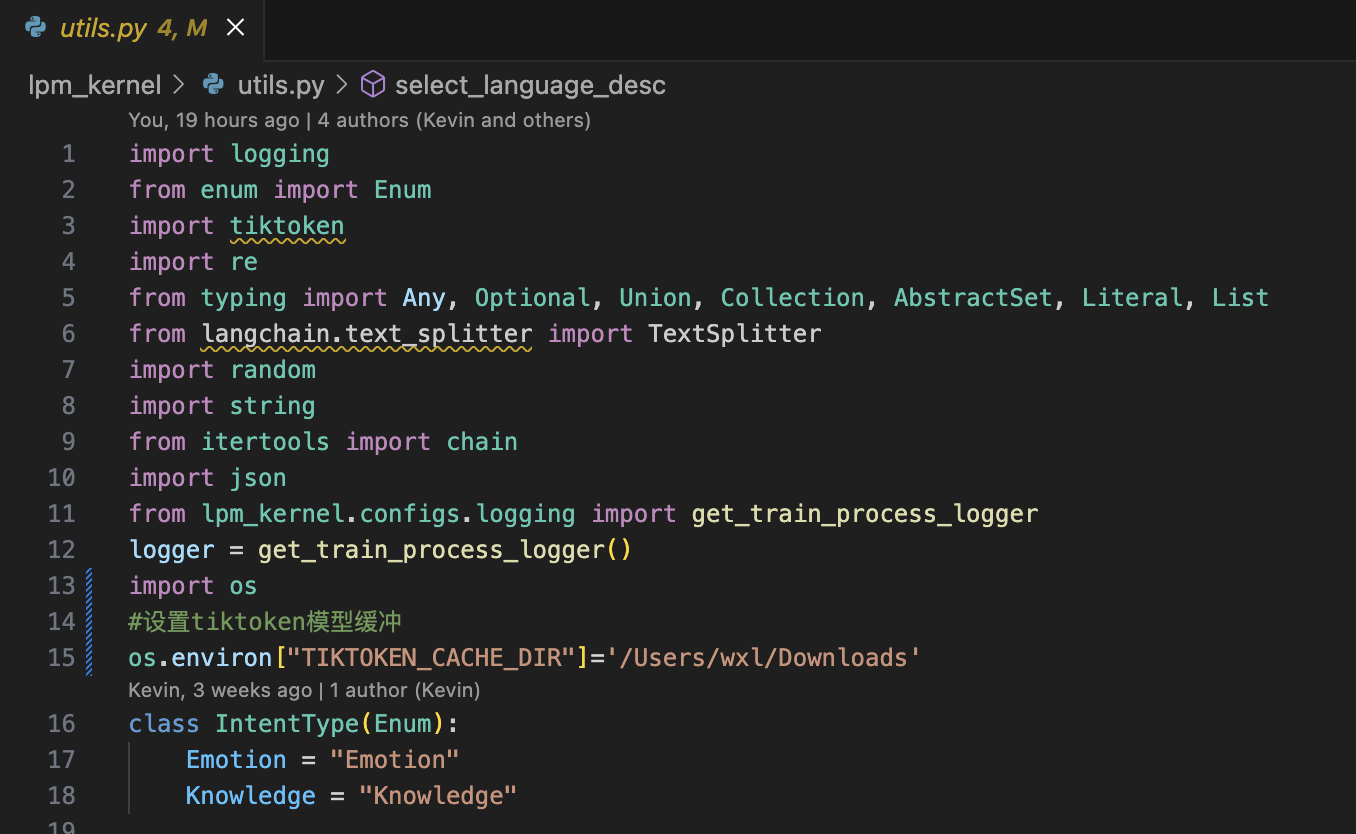
另外,还有一个比较重要的地方,就是tiktoken tokenizer模型的支持。
首先需要下载cl100k_base.tiktoken到本地,如:/Users/wxl/Downloads
然后按下面代码进行修改,还有其它地方也有使用到tiktoken,也需按此进行修改。
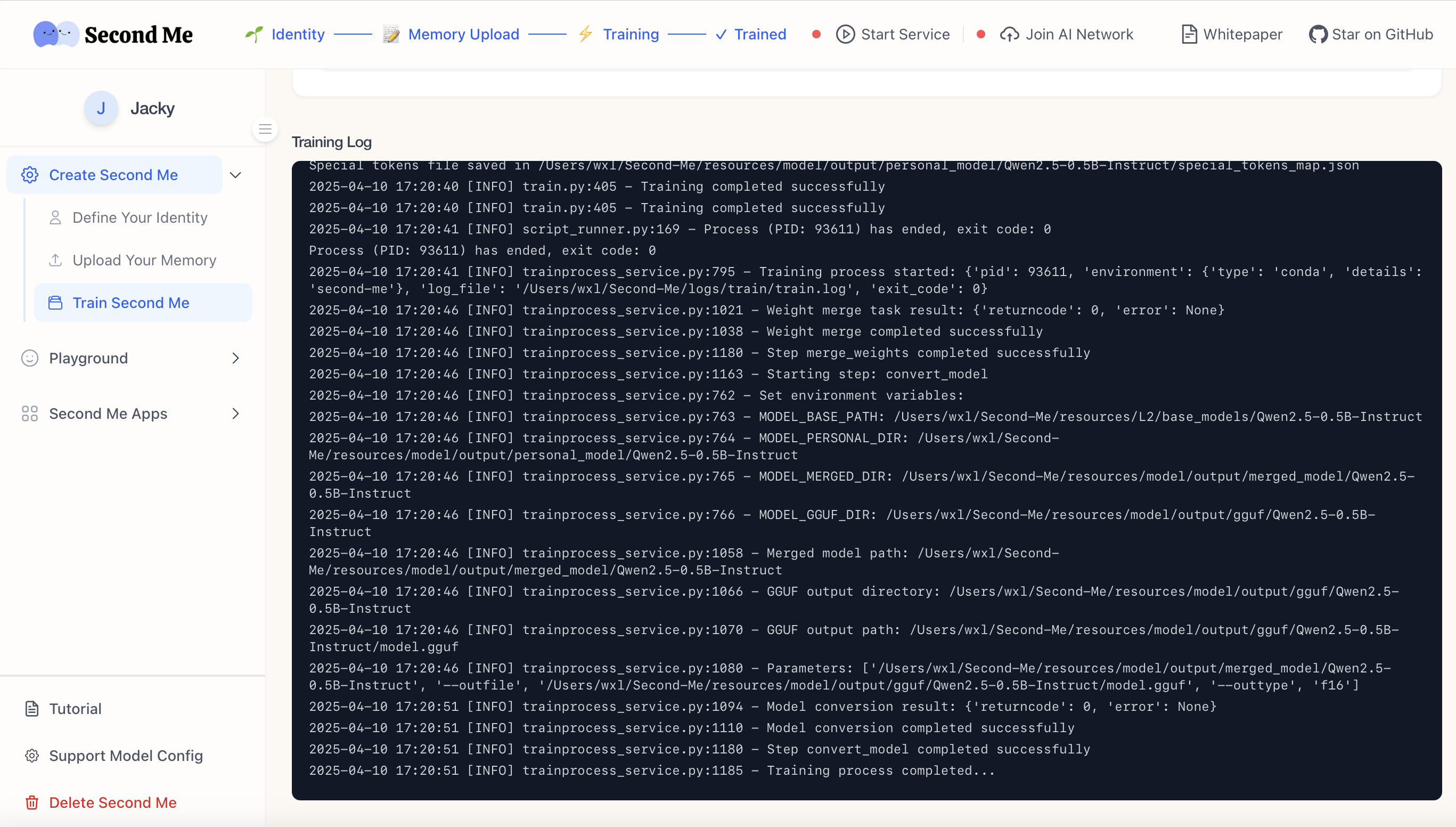
通过以上修改,可以成功完成训练。
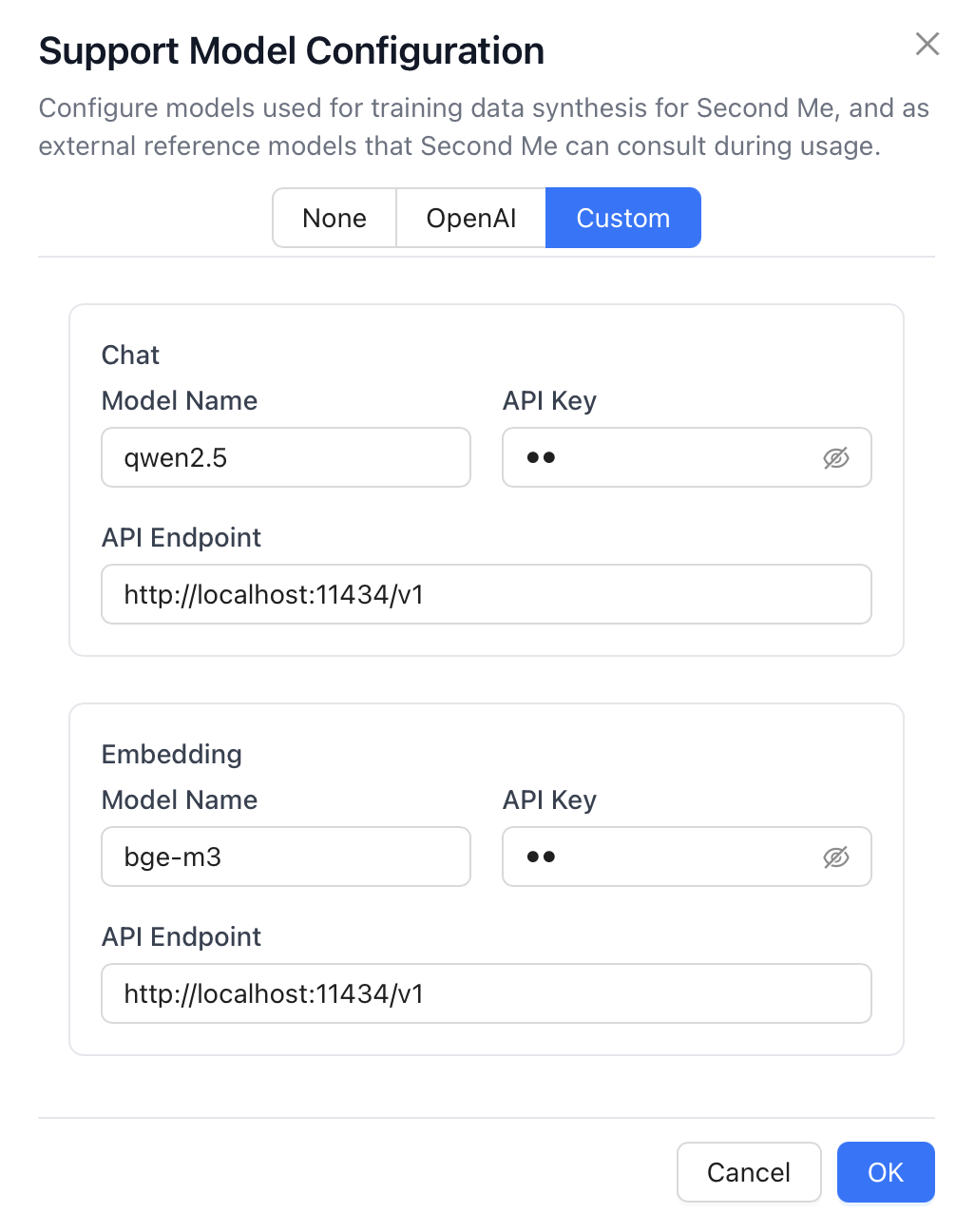
我使用模型配置是:
国内还有以下选择,就是不修改代码的情况下:
1、直接使用doubao-1.5-pro-32k-250115或deepseek-r1模型。
2、使用pip install litellm[proxy]代理,来兼容OpenAI接口,我在本地也失败了(502错误,OpenAI接口突然不兼容了吗?)。
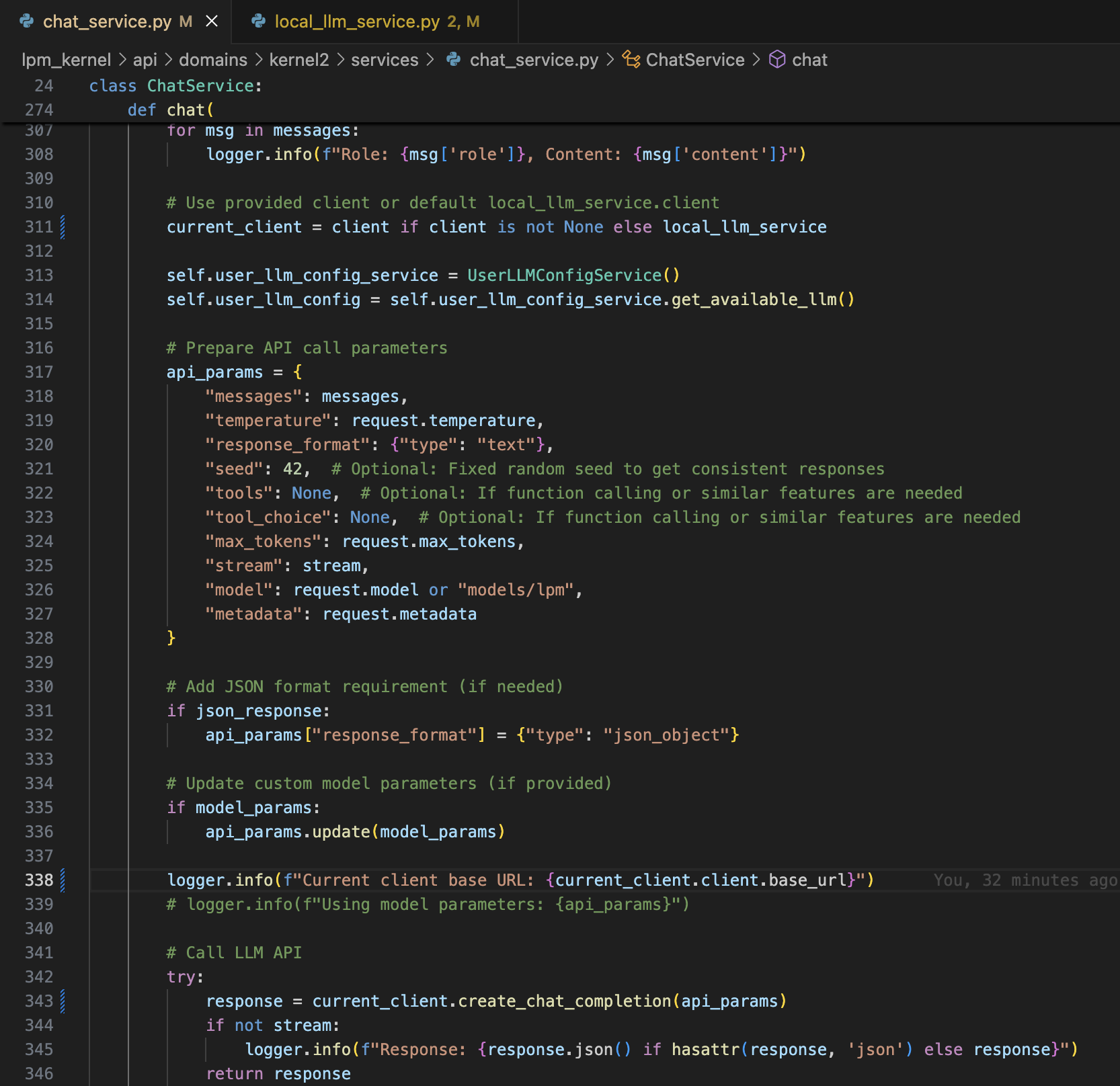
模型训练后,由于推理也使用了OpenAI,也需要进行修改。
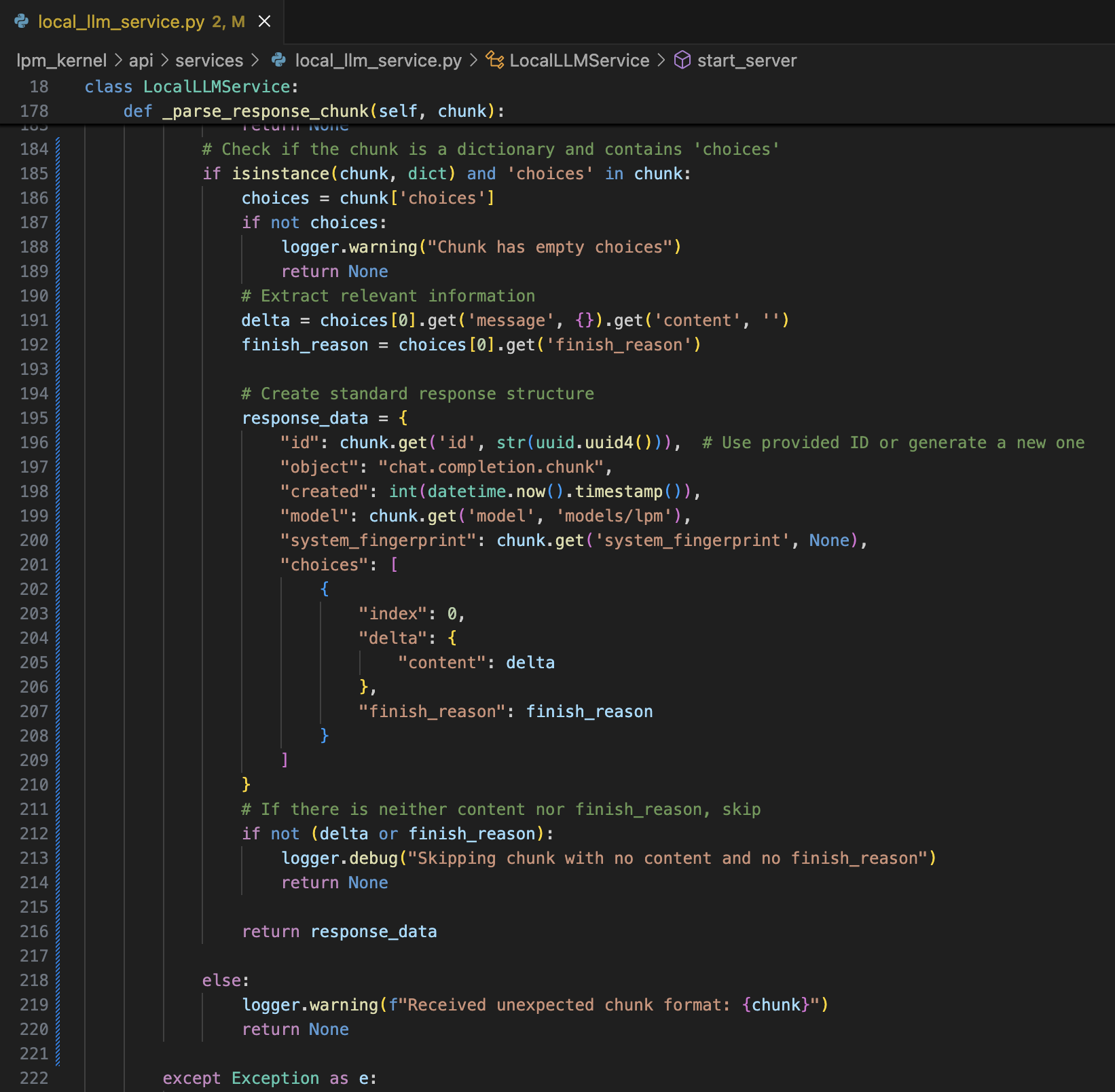
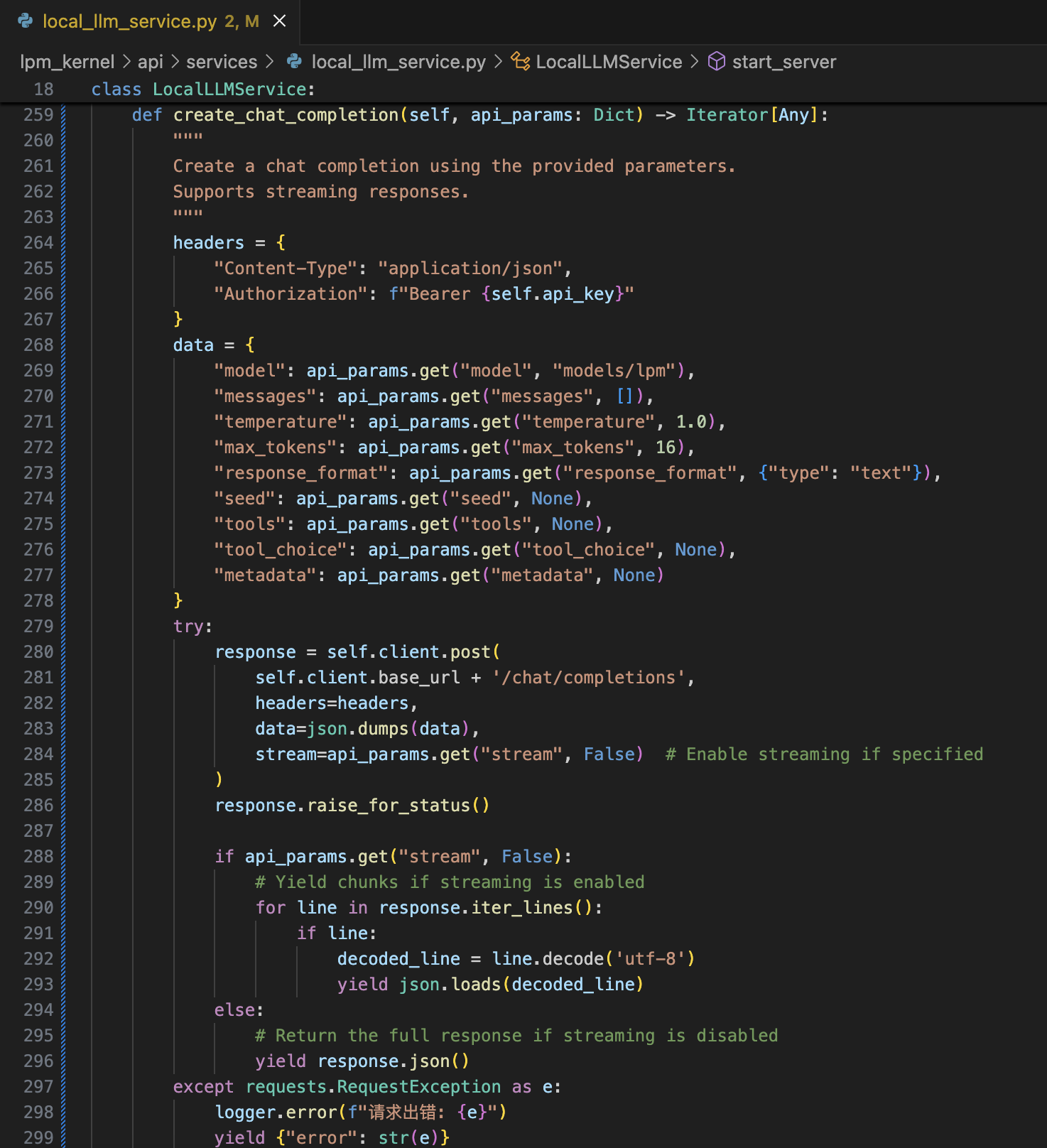
具体修改代码如下:
推理效果:
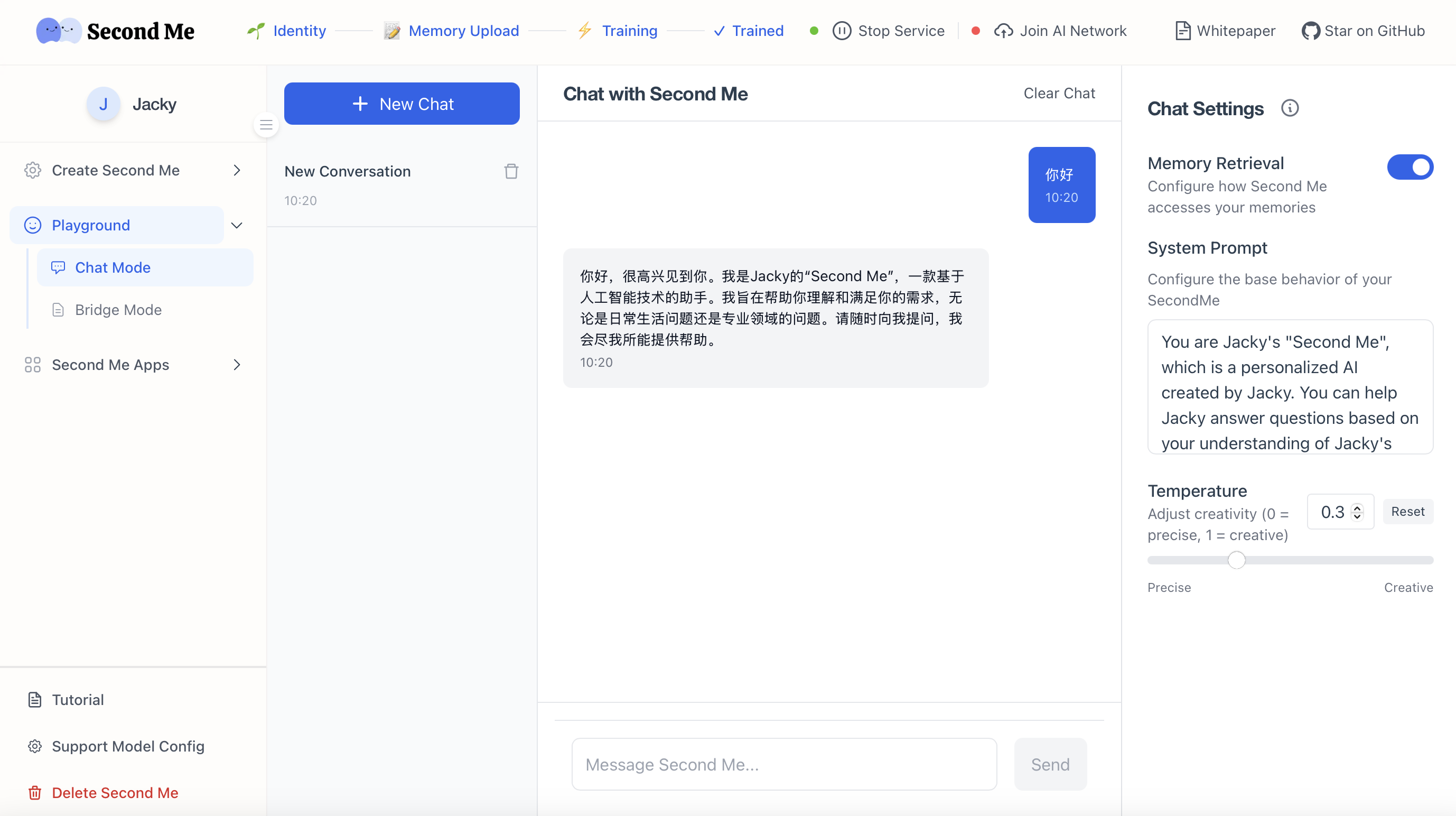
为了获得更好的效果,还需要使用deepseek-r1模型,以便获取偏好和多样化数据来增强数据。
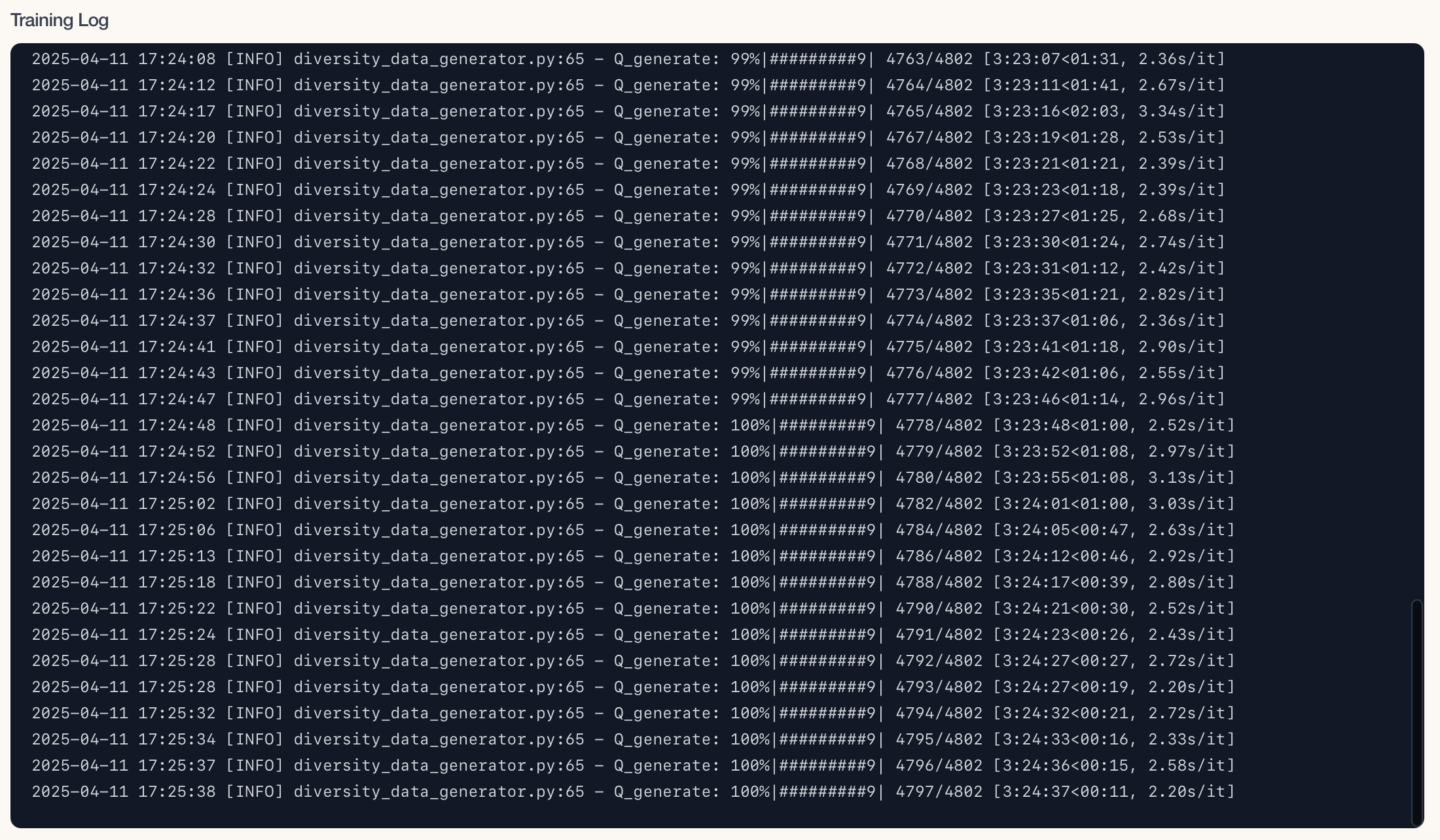
多样化数据生成中,这个过程非常慢,单个文件用了3个多小时:



















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











