






https://i-blog.csdnimg.cn/blog_migrate/9bb0718e2b9b87e26379067fe581a13f.png
导读:浮点数运算是一个非常有技术含量的话题,不太容易掌握。许多程序员都不清楚使用==操作符比较float/double类型的话到底出现什么问题。 许多人使用float/double进行货币计算时经常会犯错。这篇文章是这一系列中的精华,所有的软件开发人员都应该读一下。
随着你经验的增长,你肯定 想去深入了解一些常见的东西的细节,浮点数运算就是其中之一。
1. 什么是浮点数?
在计算机系统的发展过程中,曾经提出过多种方法表达实数。
【1】典型的比如相对于浮点数的定点数(Fixed Point Number)。在这种表达方式中,小数点固定的位于实数所有数字中间的某个位置。货币的表达就可以使用这种方式,比如 99.00 或者 00.99 可以用于表达具有四位精度(Precision),小数点后有两位的货币值。由于小数点位置固定,所以可以直接用四位数值来表达相应的数值。SQL 中的 NUMBER 数据类型就是利用定点数来定义的。
【2】还有一种提议的表达方式为有理数表达方式,即用两个整数的比值来表达实数。
定点数表达法的缺点在于其形式过于僵硬,固定的小数点位置决定了固定位数的整数部分和小数部分,不利于同时表达特别大的数或者特别小的数。最终,绝大多数现代的计算机系统采纳了所谓的浮点数表达方式。
【3】浮点数表达方式, 这种表达方式利用科学计数法来表达实数,即用一个尾数(Mantissa ),一个基数(Base),一个指数(Exponent)以及一个表示正负的符号来表达实数。比如 123.45 用十进制科学计数法可以表达为 1.2345 × 102 ,其中 1.2345 为尾数,10 为基数,2 为指数。浮点数利用指数达到了浮动小数点的效果,从而可以灵活地表达更大范围的实数。提示: 尾数有时也称为有效数字(Significand)。尾数实际上是有效数字的非正式说法。
同样的数值可以有多种浮点数表达方式,比如上面例子中的 123.45 可以表达为 12.345 × 101,0.12345 × 103 或者 1.2345 × 102。因为这种多样性,有必要对其加以规范化以达到统一表达的目标。规范的(Normalized)浮点数表达方式具有如下形式:
d.dd...d × βe , (0 ≤ di < β)
其中 d.dd...d 即尾数,β 为基数,e 为指数。尾数中数字的个数称为精度,在本文中用 p(presion) 来表示。每个数字 d 介于 0 和基数β之间,包括 0。小数点左侧的数字不为 0。
(1) 基于规范表达的浮点数对应的具体值可由下面的表达式计算而得:(p是精度个数)
±(d0 + d1β-1 + ... + dp-1β-(p-1))βe , (0 ≤ di < β)
对于十进制的浮点数,即基数 β 等于 10 的浮点数而言,上面的表达式非常容易理解,也很直白。计算机内部的数值表达是基于二进制的。从上面的表达式,我们可以知道,二进制数同样可以有小数点,也 同样具有类似于十进制的表达方式。只是此时 β 等于 2,而每个数字 d 只能在 0 和 1 之间取值。
(2) 比如二进制数 1001.101 相当于:精度为7
1 × 2 3 + 0 × 22 + 0 × 21 + 1 × 20 + 1 × 2-1 + 0 × 2-2 + 1 × 2-3,对应于十进制的 9.625。
其规范浮点数表达为 1.001101 × 23。
(3) IEEE (美国电气和电子工程师学会)浮点数
计算机中是用有限的连续字节保存浮点数的。
IEEE定义了多种浮点格式,但最常见的是三种类型:单精度、双精度、扩展双精度,分别适用于不同的计算要求。一般而言,单精度适合一般计算,双精度适合科学计算,扩展双精度适合高精度计算。一个遵循IEEE 754标准的系统必须支持单精度类型(强制类型)、最好也支持双精度类型(推荐类型),至于扩展双精度类型可以随意。单精度(Single Precision)浮点数是32位(即4字节)的,双精度(Double Precision)浮点数是64位(即8字节)的。
保存这些浮点数当然必须有特定的格式,Java 平台上的浮点数类型 float 和 double 采纳了 IEEE 754 标准中所定义的单精度 32 位浮点数和双精度 64 位浮点数的格式。注意: Java 平台还支持该标准定义的两种扩展格式,即 float-extended-exponent 和 double-extended-exponent 扩展格式。这里将不作介绍,有兴趣的读者可以参考相应的参考资料。
在 IEEE 标准中,浮点数是将特定长度的连续字节的所有二进制位分割为特定宽度的符号域,指数域和尾数域三个域,其中保存的值分别用于表示给定二进制浮点数中的符号,指数和尾数。这样,通过尾数和可以调节的指数(所以称为"浮点")就可以表达给定的数值了。
具体的格式参见下面的表格:

需要特别注意的是,扩展双精度类型没有隐含位,因此它的有效位数与尾数位数一致,而单精度类型和双精度类型均有一个隐含位,因此它的有效位数比位数位数多一个。
IEEE754标准规定一个实数V可以用: V=(-1)s×M×2^E的形式表示,说明如下:
(1)符号s(sign)决定实数是正数(s=0)还是负数(s=1),对数值0的符号位特殊处理。
(2)有效数字M是二进制小数,M的取值范围在1≤M<2或0≤M<1。
(3)指数E(exponent)是2的幂,它的作用是对浮点数加权。
为了强制定义一些特殊值,IEEE标准通过指数将表示空间划分成了三大块:
【1】最小值指数(所有位全置0)用于定义0和弱规范数
【2】最大指数(所有位全值1)用于定义±∞和NaN(Not a Number)
【3】其他指数用于表示常规的数。
这样一来,最大(指绝对值)常规数的指数不是全1的,最小常规数的指数也不是0,而是1。
S:符号位, Exponent:指数域 Fraction:尾数域
注意:尾数有时也称为有效数字(Significand),
一般如1.001001*2EValue,即一个尾数(Mantissa ),一个基数(底数Base),一个指数Evalue表示
即: M * BE = 尾数 * 底数指数
通常情况,IEEE标准写法,尾数的1,省略,Fraction= 0.001001,因为标准写法,前面的1总是省略Fraction = 尾数 - 1 ;(IEEE规定小数点左侧的 1 是隐藏的)
如果指数值:加上相应的浮点数偏执后的值:即 Exponent = EValue + Bias。
所以上述的值: X = (-1)S X ( 1 + Fraction) (Exponent - Bias), 也就不足为奇了
在上面的图例中:
① 第一个域:为符号域。其中 0 表示数值为正数,而 1 则表示负数。
② 第二个域为指数域,对应于我们之前介绍的二进制科学计数法中的指数部分。
指数阈:通常使用移码表示:
(移码和补码只有符号位相反,其余都一样。对于正数而言,原码、反码和补码都一样;对于负数而言,补码就是其绝对值的原码全部取反,然后加1(不包括符号位))。
其中单精度数为 8 位,双精度数为 11 位。以单精度数为例,8 位的指数为可以表达 0 到 255 之间的 255 个指数值。
但是,指数可以为正数,也可以为负数。为了处理负指数的情况,实际的指数值按要求需要加上一个偏差(Bias)值作为保存在指数域中的值,单精度数的偏差值为 127(0-111 1111)(8位),而双精度数的偏差值为 1023(0-1 1111 1111)(10位)。比如,单精度的实际指数值 0 在指数域中将保存为 127;而保存在指数域中的 64 则表示实际的指数值 -63。偏差的引入使得对于单精度数,实际可以表达的指数值的范围就变成 -127 到 128 之间(包含两端)[-127, 128]。
我们不久还将看到:
实际的指数值 -127(保存为 全 0),即: 首先-127原码1-111 1111,的补码1-000 0001,然后加上单精度偏执: 0-111 111 ,即结果:0-000 0000,全0. 所以0-000 0000 指数位表示:-127,即e-127
以及 +128(保存为全 1), 即:首先+128原码‘1’-000 0000,的补码, ‘1’-000 0000,然后加上单精度偏执:0-111 111 ,, 即结果:‘1’-111 1111,全1。 即全1 指数位表示:+128,即e+128
这些特殊值,保留用作特殊值的处理。这样,实际可以表达的有效指数范围就在 -127 和 127 之间。在本文中,最小指数和最大指数分别用 emin 和 emax 来表达。
计算机中的符号数有三种表示方法,即原码、反码和补码。
如补码的求取:
① 正数(符号位为0的数)补码与原码相同.
② 负数(符号位为1的数)变为补码时符号位不变,其余各项取反,最后在末尾+1;即求负数的反码不包括符号位。
例如:正数 原码01100110,补码为:01100110
负数 原码11100110,先变反码:10011001,再加1变为补码:10011010
计算机中的符号数有三种表示方法,即原码、反码和补码。三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位,三种表示方法各不相同。
在计算机系统中,数值一律用补码来表示和存储。原因在于:①使用补码,可以将符号位和数值域统一处理;②同时,加法和减法也可以统一处理。此外,③补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
特性
① 一个负整数(或原码)与其补数(或补码)相加,和为模。eg:原码11100110, 补码:10011010 和:
② 对一个整数的补码再求补码,等于该整数自身。
③ 补码的正零与负零表示方法相同。即 0-0000000, 1-0000000取反加1, 0-0000000
③ 图例中的第三个域为尾数域,其中单精度数为 23 位长,双精度数为 52 位长。除了我们将要讲到的某些特殊值外,IEEE 标准要求浮点数必须是规范的。这意味着尾数的小数点左侧必须为 1,因此我们在保存尾数的时候,可以省略小数点前面这个 1,从而腾出一个二进制位来保存更多的尾数。这样我们实际上用 23 位长的尾数域表达了 24 位的尾数。比如对于单精度数而言,二进制的 1001.101(对应于十进制的 9.625)可以表达为 1.001101 × 23,所以实际保存在尾数域中的值为 00110100000000000000000,即去掉小数点左侧的 1,并用 0 在右侧补齐。
根据IEEE(美国电气和电子工程师学会)754标准要求,无法精确保存的值必须向最接近的可保存的值进行舍入。这有点像我们熟悉的十进制的四舍五入,即不足一半则舍,一半以上(包括一半)则进。不过对于二进制浮 点数而言,还多一条规矩,就是当需要舍入的值刚好是一半时,不是简单地进,而是在前后两个等距接近的可保存的值中,取其中最后一位有效数字为零者。从上面 的示例中可以看出,奇数都被舍入为偶数,且有舍有进。我们可以将这种舍入误差理解为"半位"的误差。所以,为了避免 7.22 对很多人造成的困惑,有些文章经常以 7.5 位来说明单精度浮点数的精度问题。
据以上分析,IEEE 754标准中定义浮点数的表示范围为:
单精度浮点数 二进制:± (2-2^-23) × 2127 对应十进制: ~ ± 10^38.53
双精度浮点数 二进制:± (2-2^-52) × 21023
浮点数的表示有一定的范围,超出范围时会产生溢出(Flow),一般称大于绝对值最大的数据为上溢(Overflow),小于绝对值最小的数据为下溢(Underflow)。
2. 浮点数的表示约定
单精度浮点数和双精度浮点数都是用IEEE 754标准定义的,其中有一些特殊约定,例如:
(1) 当P=0,M=0时,表示0。
(2) 当P=255,M=0时,表示无穷大,用符号位来确定是正无穷大还是负无穷大。
(3) 当P=255,M≠0时,表示NaN(Not a Number,不是一个数)。
3. 特殊值
通过前面的介绍,你应该已经了解的浮点数的基本知识,这些知识对于一个不接触浮点数应用的人应该足够了。不过,如果你兴趣正浓,或者面对着一个棘手的浮点数应用,可以通过本节了解到关于浮点数的一些值得注意的特殊之处。
我们已经知道,单精度浮点数指数域实际可以表达的指数值的范围为 -127 到 128 之间(包含两端)。其中,值 -127(保存为全0)以及 +128(保存为全1)保留用作特殊值的处理。本节将详细 IEEE 标准中所定义的这些特殊值。
浮点数中的特殊值主要用于特殊情况或者错误的处理。比如在程序对一个负数进行开平方时,一个特殊的返回值将用于标记这种错误,该值为 NaN(Not a Number)。没有这样的特殊值,对于此类错误只能粗暴地终止计算。除了 NaN 之外,IEEE 标准还定义了 ±0,±∞ 以及非规范化数(Denormalized Number)。
对于单精度浮点数,所有这些特殊值都由保留的特殊指数值 -127 和 128 来编码。如果我们分别用 emin 和 emax 来表达其它常规指数值范围的边界,即 -126 和 127,则保留的特殊指数值可以分别表达为 emin - 1 和 emax + 1; 。基于这个表达方式,IEEE 标准的特殊值如下所示:
其中 f 表示尾数中的小数点右侧的(Fraction)部分,即标准记法中的有效部分-1。
第一行即我们之前介绍的普通的规范化浮点数。随后我们将分别对余下的特殊值加以介绍。
第2,3,4,5行,是特殊值。
(1)NaN
NaN 用于处理计算中出现的错误情况,比如 0.0 除以 0.0 或者求负数的平方根。
由上面的表中可以看出,对于单精度浮点数,NaN 表示为指数为 emax + 1 = 128(指数域全为 1),且尾数域不等于零的浮点数。IEEE 标准没有要求具体的尾数域,所以 NaN 实际上不是一个,而是一族。
不同的实现可以自由选择尾数域的值来表达 NaN,比如 Java 中的常量 Float.NaN 的浮点数可能表达为 0-11111111-10000000000000000000000,其中尾数域的第一位为 1,其余均为 0(不计隐藏的一位),但这取决系统的硬件架构。Java 中甚至允许程序员自己构造具有特定位模式的 NaN 值(通过 Float.intBitsToFloat() 方法)。比如,程序员可以利用这种定制的 NaN 值中的特定位模式来表达某些诊断信息。定制的 NaN 值,可以通过 Float.isNaN() 方法判定其为 NaN,但是它和 Float.NaN 常量却不相等。
实际上,所有的 NaN 值都是无序的。数值比较操作符 <,<=,> 和 >= 在任一操作数为 NaN 时均返回 false。等于操作符 == 在任一操作数为 NaN 时均返回 false,即使是两个具有相同位模式的 NaN 也一样。而操作符 != 则当任一操作数为 NaN 时返回 true。
这个规则的一个有趣的结果是 x!=x 当 x 为 NaN 时竟然为真。
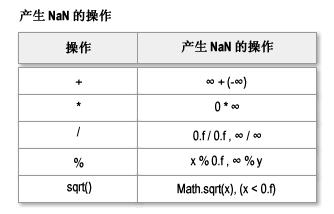
此外,任何有 NaN 作为操作数的操作也将产生 NaN。用特殊的 NaN 来表达上述运算错误的意义在于避免了因这些错误而导致运算的不必要的终止。比如,如果一个被循环调用的浮点运算方法,可能由于输入的参数问题而导致发生这些错误,NaN 使得 即使某次循环发生了这样的错误,也可以简单地继续执行循环以进行那些没有错误的运算。你可能想到,既然 Java 有异常处理机制,也许可以通过捕获并忽略异常达到相同的效果。但是,要知道,IEEE 标准不是仅仅为 Java 而制定的,各种语言处理异常的机制不尽相同,这将使得代码的迁移变得更加困难。何况,不是所有语言都有类似的异常或者信号(Signal)处理机制。
(2)无穷
和 NaN 一样,特殊值无穷(Infinity)的指数部分同样为 emax + 1 = 128,不过无穷的尾数域必须为零。无穷用于表达计算中产生的上溢(Overflow)问题。比如两个极大的数相乘时,尽管两个操作数本身可以用保存为浮点数,但其结果可能大到无法保存为浮点数,而必须进行舍入。根据 IEEE 标准,此时不是将结果舍入为可以保存的最大的浮点数(因为这个数可能离实际的结果相差太远而毫无意义),而是将其舍入为无穷。对于负数结果也是如此,只不过此时舍入为负无穷,也就是说符号域为 1 的无穷。有了 NaN 的经验我们不难理解,特殊值无穷使得计算中发生的上溢错误不必以终止运算为结果。
无穷和除 NaN 以外的其它浮点数一样是有序的,从小到大依次为负无穷,负的有穷非零值,正负零(随后介绍),正的有穷非零值以及正无穷。除 NaN 以外的任何非零值除以零,结果都将是无穷,而符号则由作为除数的零的符号决定。
回顾我们对 NaN 的介绍,当零除以零时得到的结果不是无穷而是 NaN 。原因不难理解,当除数和被除数都逼近于零时,其商可能为任何值,所以 IEEE 标准决定此时用 NaN 作为商比较合适。
(3)有符号的零
因为 IEEE 标准的浮点数格式中,小数点左侧的 1 是隐藏的,而零显然需要尾数必须是零。所以,零也就无法直接用这种格式表达而只能特殊处理。实际上,零保存为尾数域为全为 0,指数域为 emin - 1 = -127,也就是说指数域也全为 0。考虑到符号域的作用,所以存在着两个零,即 +0 和 -0。不同于正负无穷之间是有序的,IEEE 标准规定正负零是相等的。
零有正负之分,的确非常容易让人困惑。这一点是基于数值分析的多种考虑,经利弊权衡后形成的结果。有符号的零可以避免运算中,特别是涉及无穷的运算中,符号信息的丢失。举例而言,如果零无符号,则等式 1/(1/x) = x 当x = ±∞ 时不再成立。原因是如果零无符号,1 和正负无穷的比值为同一个零,然后 1 与 0 的比值为正无穷,符号没有了。解决这个问题,除非无穷也没有符号。但是无穷的符号表达了上溢发生在数轴的哪一侧,这个信息显然是不能不要的。零有符号也造成了其它问题,比如当 x=y 时,等式1/x = 1/y 在 x 和 y 分别为 +0 和 -0 时,两端分别为正无穷和负无穷而不再成立。当然,解决这个问题的另一个思路是和无穷一样,规定零也是有序的。但是,如果零是有序的,则即使 if (x==0) 这样简单的判断也由于 x 可能是 ±0 而变得不确定了。两害取其轻者,零还是无序的好。
(4)非规范化数
我们来考察浮点数的一个特殊情况。选择两个绝对值极小的浮点数,以单精度的二进制浮点数为例,比如 1.001 × 2-125 和 1.0001 × 2-125 这两个数(分别对应于十进制的 2.6448623 × 10-38 和 2.4979255 × 10-38)。显然,他们都是普通的浮点数(指数为 -125,大于允许的最小值 -126;尾数更没问题),按照 IEEE 754 可以分别保存为 00000001000100000000000000000000(0x1100000)和 00000001000010000000000000000000(0x1080000)。
现在我们看看这两个浮点数的差值。不难得出,该差值为 0.0001 × 2-125,表达为规范浮点数则为 1.0 × 2-129。问题在于其指数大于允许的最小指数值,所以无法保存为规范浮点数。最终,只能近似为零(Flush to Zero)。这中特殊情况意味着下面本来十分可靠的代码也可能出现问题:
if (x != y) { z = 1 / (x -y); }
正如我们精心选择的两个浮点数展现的问题一样,即使 x 不等于 y,x 和 y 的差值仍然可能绝对值过小,而近似为零,导致除以 0 的情况发生。
为了解决此类问题,IEEE 标准中引入了非规范(Denormalized)浮点数。规定当浮点数的指数为允许的最小指数值,即 emin 时,尾数不必是规范化的。比如上面例子中的差值可以表达为非规范的浮点数 0.001 × 2-126,其中指数 -126 等于 emin。注意,这里规定的是"不必",这也就意味着"可以"。当浮点数实际的指数为 emin,且指数域也为 emin 时,该浮点数仍是规范的,也就是说,保存时隐含着一个隐藏的尾数位。为了保存非规范浮点数,IEEE 标准采用了类似处理特殊值零时所采用的办法,即用特殊的指数域值 emin - 1 加以标记,当然,此时的尾数域不能为零。这样,例子中的差值可以保存为 00000000000100000000000000000000(0x100000),没有隐含的尾数位。
有了非规范浮点数,去掉了隐含的尾数位的制约,可以保存绝对值更小的浮点数。而且,也由于不再受到隐含尾数域的制约,上述关于极小差值的问题也不存在了,因为所有可以保存的浮点数之间的差值同样可以保存。
4. 范围和精度
很多小数根本无法在二进制计算机中精确表示(比如最简单的 0.1)由于浮点数尾数域的位数是有限的,为此,浮点数的处理办法是持续该过程直到由此得到的尾数足以填满尾数域,之后对多余的位进行舍入。
换句话说,除了我们之前讲到的精度问题之外,十进制到二进制的变换也并不能保证总是精确的,而只能是近似值。
事实上,只有很少一部分十进制小数具有精确的二进制浮点数表达。再加上浮点数运算过程中的误差累积,结果是很多我们看来非常简单的十进制运算在计算机上却往往出人意料。这就是最常见的浮点运算的"不准确"问题。
参见下面的 Java 示例:
System.out.print("34.6-34.0=" + (34.6f-34.0f));
这段代码的输出结果如下:
34.6-34.0=0.5999985
产生这个误差的原因是 34.6 无法精确的表达为相应的浮点数,而只能保存为经过舍入的近似值。这个近似值与 34.0 之间的运算自然无法产生精确的结果。
存储格式的范围和精度如下表所示:
5. 舍入
值得注意的是,对于单精度数,由于我们只有 24 位的尾数(其中一位隐藏),所以可以表达的最大指数为 224 - 1 = 16,777,215。
特别的,16,777,216 是偶数,所以我们可以通过将它除以 2 并相应地调整指数来保存这个数,这样 16,777,216 同样可以被精确的保存。相反,数值 16,777,217 则无法被精确的保存。由此,我们可以看到单精度的浮点数可以表达的十进制数值中,真正有效的数字不高于 8 位。
事实上,对相对误差的数值分析结果显示有效的精度大约为 7.22 位。
实例如下所示:
根 据标准要求,无法精确保存的值必须向最接近的可保存的值进行舍入。这有点像我们熟悉的十进制的四舍五入,即不足一半则舍,一半以上(包括一半)则进。不过 对于二进制浮点数而言,还多一条规矩,就是当需要舍入的值刚好是一半时,不是简单地进,而是在前后两个等距接近的可保存的值中,取其中最后一位有效数字为 零者。从上面的示例中可以看出,奇数都被舍入为偶数,且有舍有进。我们可以将这种舍入误差理解为"半位"的误差。所以,为了避免 7.22 对很多人造成的困惑,有些文章经常以 7.5 位来说明单精度浮点数的精度问题。
提示: 这里采用的浮点数舍入规则有时被称为舍入到偶数(Round to Even)。相比简单地逢一半则进的舍入规则,舍入到偶数有助于从某些角度减小计算中产生的舍入误差累积问题。因此为 IEEE 标准所采用。

浮点数加减法的运算步骤

- hillchan31
- 2012年05月14日 17:30
- 23472
浮点数运算中的舍入问题

- u011240016
- 2016年09月24日 09:50
- 1862
浮点加减法运算

- chen_lady
- 2016年04月09日 16:12
- 2815
浮点数的加减计算总结
- u011240016
- 2016年09月22日 15:41
- 5042
浮点运算结果出现误差原因分析及解决方案

- iloli
- 2012年12月28日 14:38
- 13214
浮点数精确运算的分析和解决办法

- tiger119
- 2006年07月07日 07:31
- 4323
二进制浮点数,IEEE标准

- shanyongxu
- 2015年08月16日 13:39
- 3507
浮点数二进制表示

- richerg85
- 2014年03月05日 20:56
- 20914
浮点数的二进制表示(IEEE 754标准)

- fwb330198372
- 2017年04月19日 12:55
- 1740
【C语言】得到浮点数的二进制

- cflys
- 2017年02月25日 19:59
- 506
IEEE二进制浮点数算术标准(IEEE 754)

- aqzwss
- 2016年08月11日 16:44
- 1237
进制浮点数与二进制浮点数之间的转换源代码
- 2015年12月26日 11:02
- 5KB
- 下载

float浮点数的二进制存储方式及转换

- zcczcw
- 2012年03月16日 19:34
- 32986
浮点加法、减法, 乘法、除法运算

- xingqingly
- 2014年02月08日 11:08
- 5477
单精度浮点数乘法的实现

- u014298090
- 2014年03月23日 13:09
- 2305
乘除运算及浮点数运算

- yongchaocsdn
- 2017年02月22日 21:55
- 450
Nvidia GPU的浮点计算能力(FP64/FP32/FP16)

- haima1998
- 2017年10月16日 15:20
- 2434
浮点数原理探究

- Scythe666
- 2015年07月13日 17:41
- 1894
浮点数的运算原理--IEEE 754

- joeadai
- 2013年10月21日 20:15
- 5297
关于浮点数的原理详解

- b2b160
- 2009年08月28日 11:15
- 4573

-
原创
- 8
-
粉丝
- 16
-
喜欢
- 18
-
评论
- 4


他的最新文章
更多文章文章分类
- 图像处理
32篇
- 串口通信 可移植
1篇
- 串口能信
2篇
- 摄像头操作
1篇
- c++编码规范
1篇
- c++基础知识
13篇
- opencv学习笔记
8篇
- 设计模式 Qt版
2篇
- Qt助手翻译篇
1篇
- Qt
3篇
- MFC
4篇
- halcon
0篇
- c语言基础
2篇
- 计算机底层
4篇
- th
0篇
- 算法
10篇
- 程序员必知系列
6篇
- DSP优化
4篇
- 自我规划系列
4篇
- 机器学习
3篇
文章存档
- 2018年2月
4篇
- 2018年1月
7篇
- 2017年11月
2篇
- 2017年10月
1篇
- 2017年9月
1篇
- 2017年5月
2篇
- 2017年4月
1篇
- 2017年3月
6篇
- 2017年2月
3篇
- 2017年1月
1篇
- 2016年12月
2篇
- 2016年11月
1篇
- 2016年10月
1篇
- 2016年9月
1篇
- 2016年8月
7篇
- 2016年5月
1篇
- 2016年4月
6篇
- 2016年3月
1篇
- 2015年10月
4篇
- 2015年9月
2篇
- 2015年8月
4篇
- 2015年1月
2篇
- 2014年12月
17篇
- 2014年11月
17篇
他的热门文章
联系我们
















 7729
7729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}