






论文《Neural Attentive Session-based Recommendation》阅读
论文概况
本文是2017年ICKM上的一篇论文,通过使用GRU时序门控单元处理序列化的会话,结合局部和全局编码操作,最终对用户行为进行预测。
Introduction
作者提出问题
- 现阶段模型只重视会话本身,而没有挖掘用户的意图,例如:
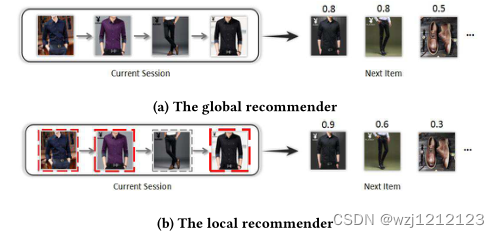
有效的推荐应该如图a,因为用户浏览了衣服裤子,那很可能再买一双鞋来搭配,而现阶段模型更倾向于图b,单纯去比较带推荐物品与会话中物品的相似程度来排序,因此只会推荐衣服和裤子。
对于上述问题,作者提出了NARM模型(Neural Attentive Recommendation Machine):
(1) 该模型考虑了用户在当前会话中的顺序行为和主要目的
(2) 应用注意力机制来提取用户在当前会话中的主要目的
Method
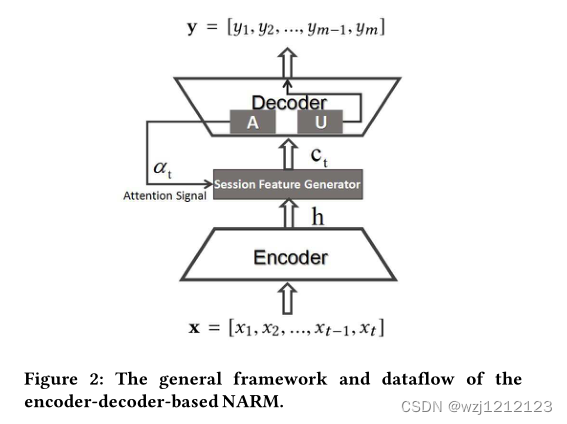

A.Global Encoder in NARM
在全局编码器中,输入是整个先前的单击,而输出是用户在当前会话中的顺序行为的特征。输入和输出均由高维向量统一表示。
h
t
−
1
\boldsymbol{h}_{t-1}
ht−1为上一轮activation,
h
^
t
\widehat{\boldsymbol{h}}_t
h
t为候选activation,新一轮的更新公式为:
h
t
=
(
1
−
z
t
)
h
t
−
1
+
z
t
h
^
t
(1)
\boldsymbol{h}_t=\left(1-\boldsymbol{z}_t\right) \boldsymbol{h}_{t-1}+\boldsymbol{z}_t \widehat{\boldsymbol{h}}_t\tag{1}
ht=(1−zt)ht−1+zth
t(1)
其中
z
t
z_t
zt更新公式为:
z
t
=
σ
(
W
z
x
t
+
U
z
h
t
−
1
)
(2)
\boldsymbol{z}_t=\sigma\left(\boldsymbol{W}_z \boldsymbol{x}_t+\boldsymbol{U}_z \boldsymbol{h}_{t-1}\right)\tag{2}
zt=σ(Wzxt+Uzht−1)(2)
候选activation
h
^
t
\widehat{\boldsymbol{h}}_t
h
t计算公式为:
h
^
t
=
tanh
[
W
x
t
+
U
(
r
t
⊙
h
t
−
1
)
]
(3)
\widehat{\boldsymbol{h}}_t=\tanh \left[\boldsymbol{W} \boldsymbol{x}_t+\boldsymbol{U}\left(\boldsymbol{r}_t \odot \boldsymbol{h}_{t-1}\right)\right]\tag{3}
h
t=tanh[Wxt+U(rt⊙ht−1)](3)
更新门
r
t
\boldsymbol{r}_t
rt计算方式为
r
t
=
σ
(
W
r
x
t
+
U
r
h
t
−
1
)
(4)
\boldsymbol{r}_t=\sigma\left(\boldsymbol{W}_r \boldsymbol{x}_t+\boldsymbol{U}_r \boldsymbol{h}_{t-1}\right)\tag{4}
rt=σ(Wrxt+Urht−1)(4)
全局编码为整体会话经过gru处理的结果
c
t
g
=
h
t
(5)
\boldsymbol{c}_t^{\mathrm{g}}=\boldsymbol{h}_t\tag{5}
ctg=ht(5)
然而,这种全局编码器有其缺点,例如整个序列行为的矢量概括通常难以捕捉当前用户的精确意图。
B.Local Encoder in NARM
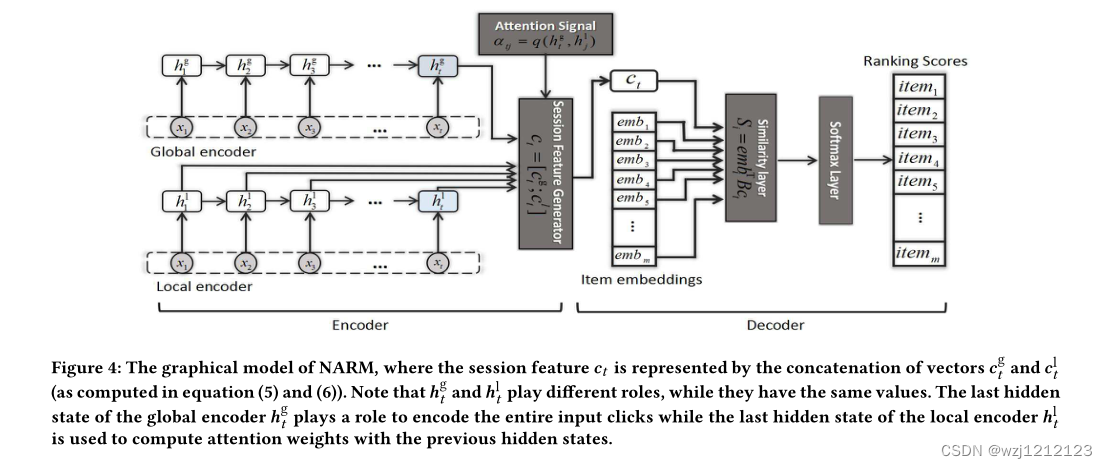
如图三所示,为了探寻用户短期意图,我们对gru每一轮的输出进行单独处理
c
t
1
=
∑
j
=
1
t
α
t
j
h
j
(6)
c_t^1=\sum_{j=1}^t \alpha_{t j} \boldsymbol{h}_j\tag{6}
ct1=j=1∑tαtjhj(6)
其中加权因子α确定在进行预测时应强调或忽略输入序列的哪个部分,α通过计算
h
t
\boldsymbol{h}_t
ht与
h
j
\boldsymbol{h}_j
hj的相似度来决定
α
t
j
=
q
(
h
t
,
h
j
)
(7)
\alpha_{t j}=q\left(\boldsymbol{h}_t, \boldsymbol{h}_j\right)\tag{7}
αtj=q(ht,hj)(7)
q
(
h
t
,
h
j
)
=
v
T
σ
(
A
1
h
t
+
A
2
h
j
)
(8)
q\left(\boldsymbol{h}_t, \boldsymbol{h}_j\right)=\boldsymbol{v}^{\mathrm{T}} \sigma\left(\boldsymbol{A}_1 \boldsymbol{h}_t+\boldsymbol{A}_2 \boldsymbol{h}_j\right)\tag{8}
q(ht,hj)=vTσ(A1ht+A2hj)(8)
C. NARM Model
最终用户喜好表示为全局与局部编码的级联
c
t
=
[
c
t
g
;
c
t
l
]
=
[
h
t
g
;
∑
j
=
1
t
α
t
j
h
t
l
]
(9)
\boldsymbol{c}_t=\left[\boldsymbol{c}_t^{\mathrm{g}} ; \boldsymbol{c}_t^{\mathrm{l}}\right]=\left[\boldsymbol{h}_t^{\mathrm{g}} ; \sum_{j=1}^t \alpha_{t j} \boldsymbol{h}_t^{\mathrm{l}}\right]\tag{9}
ct=[ctg;ctl]=[htg;j=1∑tαtjhtl](9)
使用点乘计算相似度的方式来给物品打分
S
i
=
e
m
b
i
T
B
c
t
(10)
S_i=e m b_i^{\mathrm{T}} \boldsymbol{B} \boldsymbol{c}_{\boldsymbol{t}}\tag{10}
Si=embiTBct(10)
其中B为|D|*|H|维度的可学习矩阵
最后损失函数设定为交叉熵函数:
L
(
p
,
q
)
=
−
∑
i
=
1
m
p
i
log
(
q
i
)
(11)
L(p, q)=-\sum_{i=1}^m p_i \log \left(q_i\right)\tag{11}
L(p,q)=−i=1∑mpilog(qi)(11)
其中q是预测概率分布,p是真实分布。
总结
NARM不仅提取了会话的序列化信息,还通过gru表达了用户的意图,将会话整体特征与用户意图相结合来解决会话推荐问题。















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









