






论文《Vision-Language Pre-Training with Triple Contrastive Learning》阅读
论文概况
本文是2022年CVPR上的一篇多模态论文,利用对比学习和动量来进行图片与文本信息的上游预训练。
Introduction
作者提出问题
- 简单的跨模态比对模型无法确保来自同一模态的相似输入保持相似。(模态内部语义信息损失)
- 全局互信息最大化的操作没有考虑局部信息和结构信息。
对于上述问题,作者提出了TCL模型
(1) 利用跨模态和模态内自监督在表示学习中提供互补的优势,这有助于在融合编码器中建模更好的联合多模态特征。
(2) 通过最大化局部区域及其全局摘要之间的局部MI最大化,来利用图像和文本输入中的局部和结构信息,而不是简单地依赖全局信息进行多模态对比学习。
Method
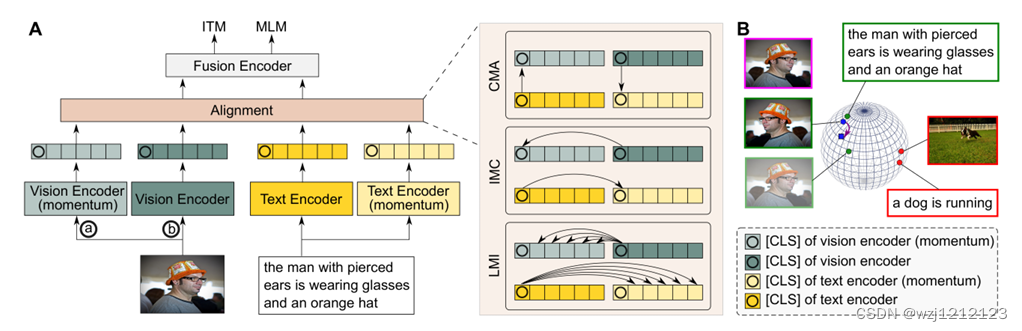
A.模型架构
模型包含视觉编码器g(.),文本编码器h(.),动量视觉编码器 g ^ ( ⋅ ) \hat{g}(\cdot) g^(⋅),动量文本编码器 h ^ ( ⋅ ) \hat{h}(\cdot) h^(⋅),其中 θ g ^ = m θ g ^ + ( 1 − m ) θ g \theta_{\hat{g}}=m\theta_{\hat{g}}+(1-m)\theta_{g} θg^=mθg^+(1−m)θg。(动量编码器放缓了编码器参数的变化)
B.单模态表示学习
给定一个图像-文本对(I,T),通过两个独立的增强操作,我们得到 I 1 I_{1} I1、 I 2 I_{2} I2、 T 1 T_{1} T1、 T 2 T_{2} T2,同一图片(文本)产生的两个增强结果视为正样本对。 I 1 I_{1} I1送到g(.), g ^ ( ⋅ ) \hat{g}(\cdot) g^(⋅),得到 { v c l s , v 1 , . . . , v M } , \{v_{cls},{v_{1}},...,v_{M}\}, {vcls,v1,...,vM}, { v ^ c l s , v ^ 1 , . . . , v ^ M } \{\hat{v}_{cls},\hat{v}_{1},...,\hat{v}_{M}\} {v^cls,v^1,...,v^M},对于文本T同理。
C.跨模态对齐CMA
CMA的目标是将匹配的图像-文本对的嵌入拉到一起,同时将不匹配的对的嵌入分开。由于连续和高维变量的互信息的直接最大化是难以解决的,TCL反而最小化了代表互信息下界的InfoNCE损失:
L
n
c
e
(
I
1
,
T
+
,
T
~
)
=
−
E
p
(
I
,
T
)
[
l
o
g
e
(
sin
(
I
1
,
T
+
)
/
τ
)
∑
k
=
1
K
e
(
sin
(
I
1
,
T
~
k
)
/
τ
)
]
\mathcal{L}_{nce}(I_1,T_+,\tilde{T})=-\mathbb{E}_{p(I,T)}\left[log\frac{e^{(\sin(I_1,T_+)/\tau)}}{\sum_{k=1}^Ke^{(\sin(I_1,\tilde{T}_k)/\tau)}}\right]
Lnce(I1,T+,T~)=−Ep(I,T)[log∑k=1Ke(sin(I1,T~k)/τ)e(sin(I1,T+)/τ)],
其中
T
~
=
{
T
~
1
,
.
.
.
,
T
~
K
}
\tilde{T}=\{\tilde{T}_{1},...,\tilde{T}_{K}\}
T~={T~1,...,T~K}是一组负样本,
s
i
m
(
I
1
,
T
+
)
=
f
v
(
v
c
l
s
)
T
f
^
t
(
t
^
c
l
s
)
sim(I_{1},T_{+})=f_{v}(v_{cls})^{T}\hat{f}_{t}(\hat{t}_{cls})
sim(I1,T+)=fv(vcls)Tf^t(t^cls),f(.)是将表示映射到空间的两个投影头。
相似的:
L
n
c
e
(
T
,
I
2
,
I
~
)
=
−
E
p
(
I
,
T
)
[
l
o
g
e
(
sin
(
T
,
I
2
)
/
τ
)
∑
k
=
1
K
e
(
sin
(
T
,
I
~
k
)
/
τ
)
]
\mathcal{L}_{nce}(T,I_2,\tilde{I})=-\mathbb{E}_{p(I,T)}\bigg[log\frac{e^{(\sin(T,I_2)/\tau)}}{\sum_{k=1}^{K}e^{(\sin(T,\tilde{I}_k)/\tau)}}\bigg]
Lnce(T,I2,I~)=−Ep(I,T)[log∑k=1Ke(sin(T,I~k)/τ)e(sin(T,I2)/τ)]
CMA的总损失是:
L
c
m
a
=
1
2
[
L
n
c
e
(
I
1
,
T
+
,
T
~
)
+
L
n
c
e
(
T
,
I
2
,
I
~
)
]
\mathcal{L}_{cma}=\frac{1}{2}[\mathcal{L}_{nce}(I_{1},T_{+},\tilde{T})+\mathcal{L}_{nce}(T,I_{2},\tilde{I})]
Lcma=21[Lnce(I1,T+,T~)+Lnce(T,I2,I~)]
然而,CMA损失忽略了每个模态内的自我监督,因此无法保证学习特征的理想表现力。原因是i)文本通常不能完全描述配对的图像。例如,尽管图(A)中的文本捕捉到了图像中的大多数显著对象,但它忽略了每个对象的详细特征,例如人的布料。因此,简单地将图像-文本对的嵌入拉在一起会导致表示降级(图B);以及ii)用于预训练的图像-文本对固有地具有噪声。
D.模态内对比IMC
与CMA同理,IMC的总损失为:
L
i
m
c
=
1
2
[
L
n
c
e
(
T
,
T
+
,
T
~
)
+
L
n
c
e
(
I
1
,
I
2
,
I
~
)
]
\mathcal{L}_{imc}=\frac{1}{2}[\mathcal{L}_{nce}(T,T_+,\tilde{T})+\mathcal{L}_{nce}(I_1,I_2,\tilde{I})]
Limc=21[Lnce(T,T+,T~)+Lnce(I1,I2,I~)]
CMA和IMC被设计为在表示学习中发挥互补作用:i)CMA映射在嵌入空间中接近的匹配图像-文本对,以及ii)IMC最大化相同数据示例的不同增强视图之间的一致性。将它们组合在一起可以提高学习表示的质量(图B),并可以进一步促进融合编码器中的联合多模态学习。
然而IMC与CMA都只比对全局信息,没有对局部信息的比对。
E.局部MI最大化(LMI)
LMI与IMC类似,但具体操作对象有所不同。
L
l
m
i
=
1
2
[
1
M
∑
i
=
1
M
L
n
c
e
(
I
1
,
I
2
i
,
I
~
l
)
+
1
N
∑
j
=
1
N
L
n
c
e
(
T
,
T
+
j
,
T
~
l
)
]
\mathcal{L}_{lmi}=\frac{1}{2}\bigg[\frac{1}{M}\sum_{i=1}^{M}\mathcal{L}_{nce}(I_{1},I_{2}^{i},\tilde{I}_{l})+\frac{1}{N}\sum_{j=1}^{N}\mathcal{L}_{nce}(T,T_{+}^{j},\tilde{T}_{l})\bigg]
Llmi=21[M1i=1∑MLnce(I1,I2i,I~l)+N1j=1∑NLnce(T,T+j,T~l)]
F.总损失
最终,模型总损失为
L
=
L
c
m
a
+
L
i
m
c
+
L
l
m
i
+
L
i
t
m
+
L
m
l
m
\mathcal{L}=\mathcal{L}_{cma}+\mathcal{L}_{imc}+\mathcal{L}_{lmi}+\mathcal{L}_{itm}+\mathcal{L}_{mlm}
L=Lcma+Limc+Llmi+Litm+Lmlm
其中,CMA IMC LMI上面都重点介绍了,ITM与MLM则是匹配任务和生成任务的损失,这里不详细介绍了。
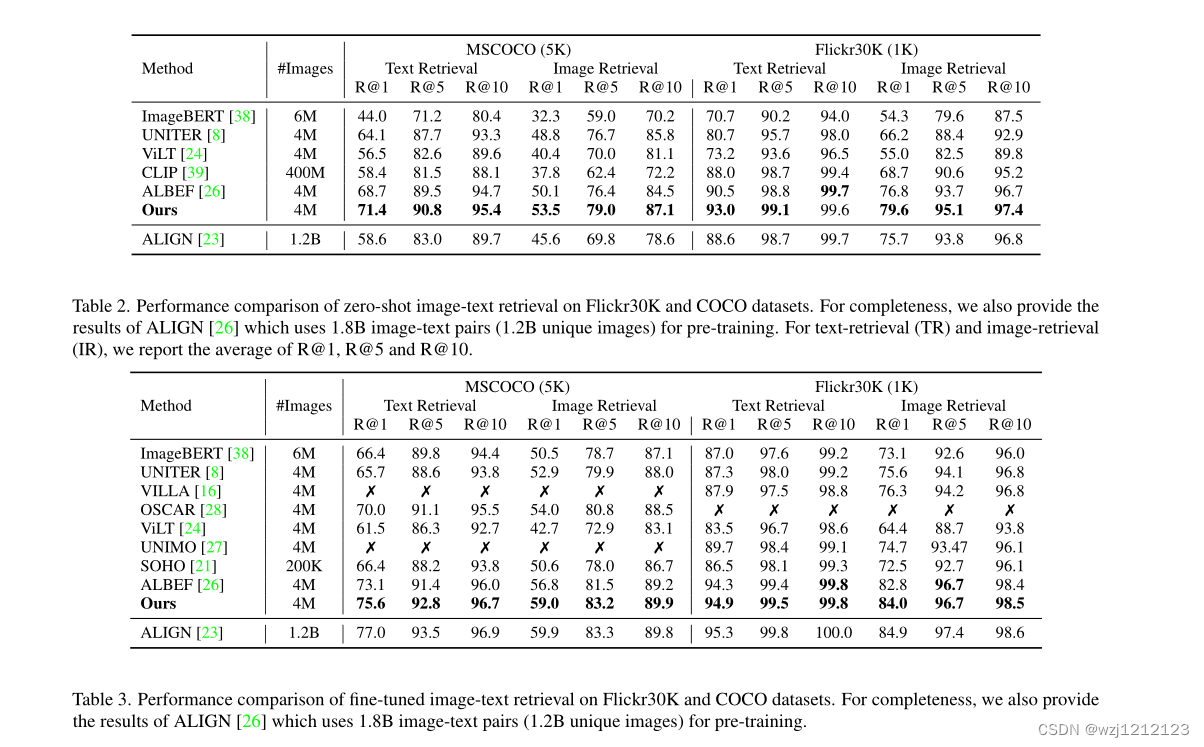
G.结果
总结
TCL模型在前人工作的基础上进一步提升上游预训练的准确度,论文讲得非常清晰。















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









