






文章目录
一、FLAVA
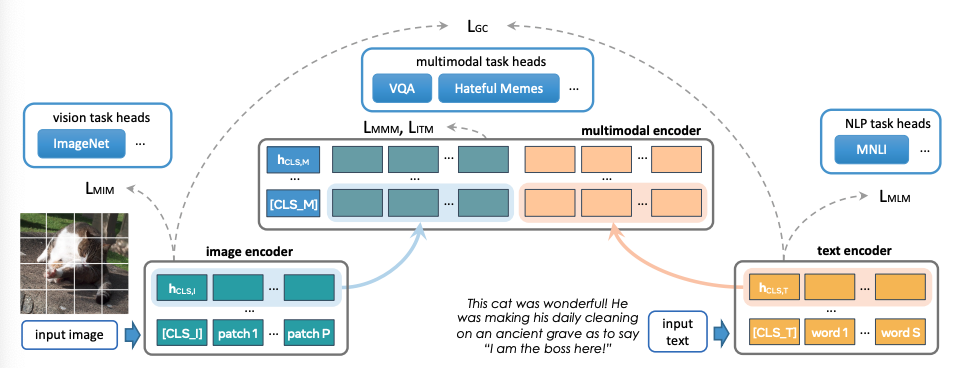
FLAVA 旨在建立一个同时针对所有模式的单一整体通用模型。 FLAVA 是一种语言视觉对齐模型,可以从多模态数据(图像文本对)和单模态数据(不成对的图像和文本)中学习强表示。 该模型由一个用于捕获单模态图像表示的图像编码转换器、一个用于处理单模态文本信息的文本编码器转换器和一个多模态编码转换器组成,该多模态编码转换器将编码的单模态图像和文本作为输入并集成它们的表示以进行多模态推理。 在预训练期间,掩模图像建模(MIM)和掩模语言建模(MLM)损失分别应用于单个图像或文本片段上的图像和文本编码器,而对比、掩模多模态建模(MMM)和图像文本 匹配(ITM)损失用于配对图像文本数据。 对于下游任务,分类头分别应用于图像、文本和多模态编码器的输出,用于视觉识别、语言理解和多模态推理任务它可以应用于三个领域(视觉识别、语言理解)的广泛任务 和多模态推理)在通用变压器模型架构下。
二、Visual-Linguistic BERT(VL-BERT)
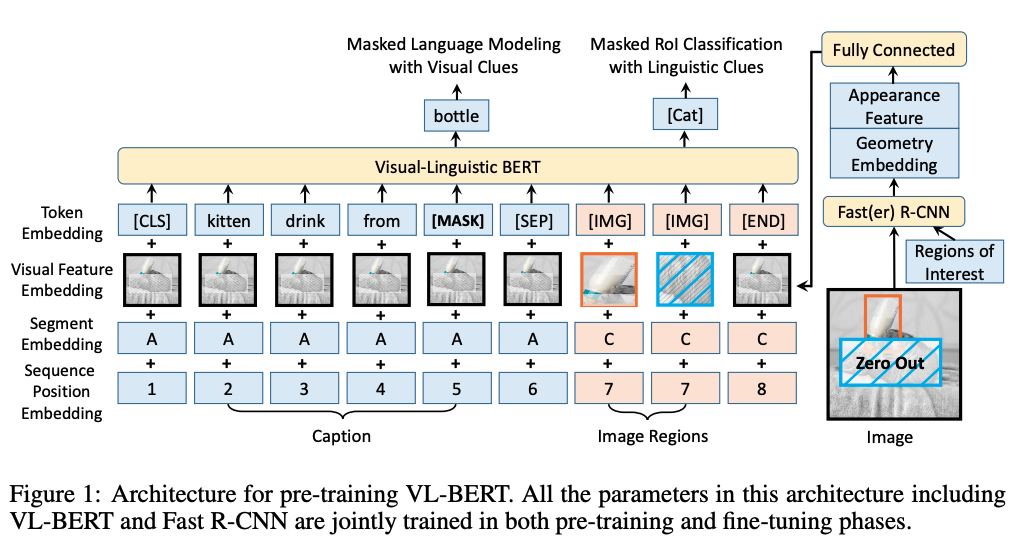
VL-BERT 在大规模图像字幕数据集和纯文本语料库上进行了预训练。 模型的输入要么是输入句子中的单词,要么是输入图像中的感兴趣区域 (RoI)。 它可以进行微调以适应大多数视觉语言下游任务。 它的主干是一个多层双向 Transformer 编码器,经过修改以适应视觉内容,以及将新型视觉特征嵌入到输入特征嵌入中。 VL-BERT 将视觉和语言元素作为输入,表示为图像中的 RoI 和输入句子中的子词。 使用四种不同类型的嵌入来表示每个输入:标记嵌入、视觉特征嵌入、片段嵌入和序列位置嵌入。 VL-BERT 使用概念字幕和纯文本数据集进行预训练。 使用两个预训练任务:具有视觉线索的掩蔽语言建模,以及具有语言线索的掩蔽 RoI 分类。
三、UNIMO
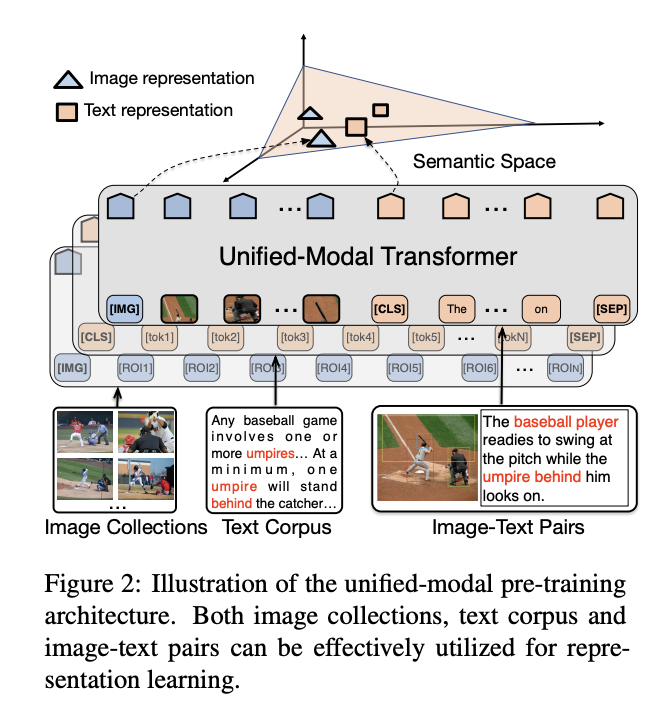
UNIMO是一种多模态预训练架构,可以有效适应单模态和多模态理解和生成任务。 UNIMO同时学习视觉表示和文本表示,并通过基于图像集合、文本语料库和图像文本对的大规模语料库的跨模态对比学习(CMCL)将它们统一到同一语义空间中。 CMCL将视觉表示和文本表示对齐,并基于图像-文本对将它们统一到相同的语义空间中。
四、VL-T5
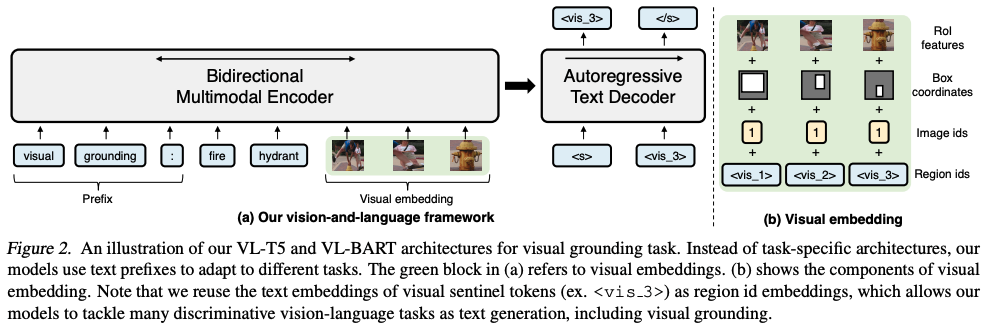
VL-T5 是一个统一的框架,它在具有相同语言建模目标的单一架构中学习不同的任务,即多模态条件文本生成。 该模型学习根据视觉和文本输入生成文本标签。 与其他现有方法相比,该框架将任务统一为根据多模式输入生成文本标签。 这使得该模型能够以统一的文本生成目标来处理视觉和语言任务。 这些模型使用文本前缀来适应不同的任务。
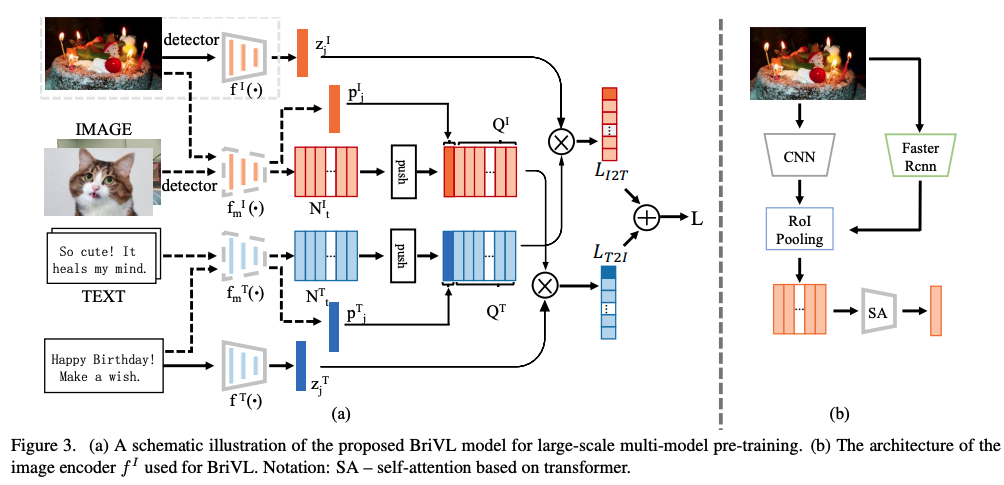
五、WenLan
在跨模态对比学习框架内提出了一种名为 BriVL 的两塔预训练模型。 基于图文检索任务定义了跨模态预训练模型。 因此,主要目标是学习两个编码器,它们可以将图像和文本样本嵌入到同一空间中,以进行有效的图像文本检索。 为了加强这种跨模式嵌入学习,我们将对比学习与 InfoNCE 损失引入 BriVL 模型中。 给定文本嵌入,学习目标旨在从一批图像嵌入中找到最佳图像嵌入。 类似地,对于给定的图像嵌入,学习目标是从一批文本嵌入中找到最佳的文本嵌入。 预训练模型通过联合训练图像和文本编码器来学习跨模态嵌入空间,以最大化批次中每个样本的真实对的图像和文本嵌入的余弦相似度,同时最小化 其他不正确的对。
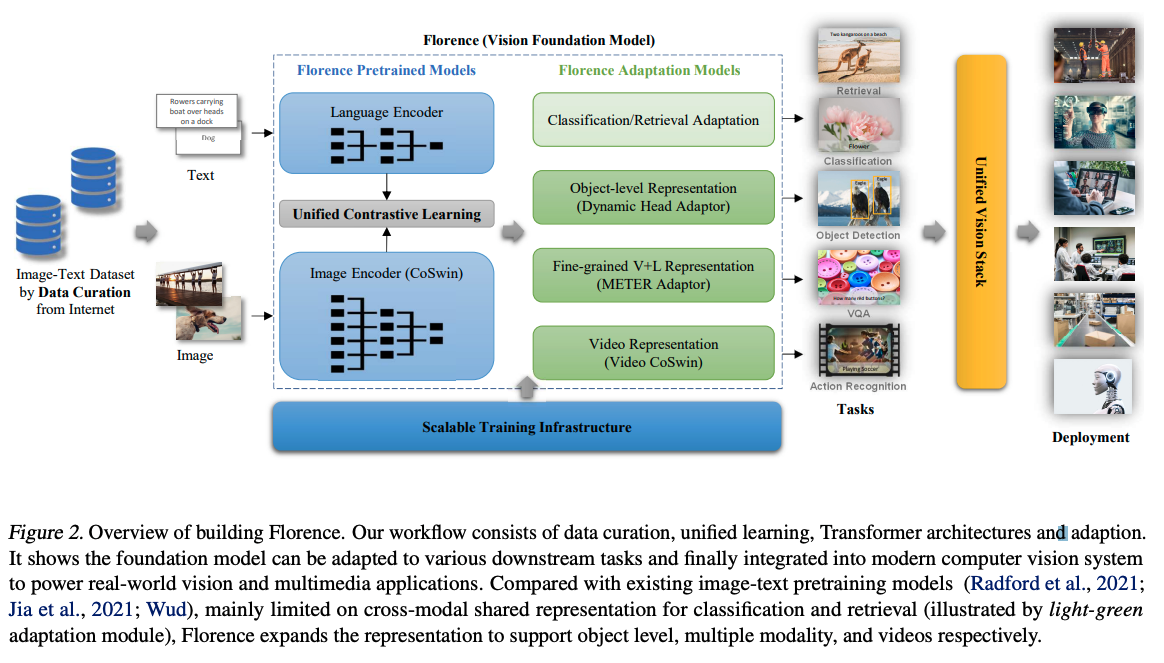
六、Florence
Florence 是一个计算机视觉基础模型,旨在学习通用视觉语言表示,适用于各种计算机视觉任务、视觉问答、图像字幕、视频检索等任务。 Florence 的工作流程包括数据管理、统一学习、Transformer 架构和适应。 Florence 在图像标签描述空间中进行了预训练,利用统一的图像文本对比学习。 它涉及两塔架构:用于语言编码器的 12 层 Transformer 和用于图像编码器的 Vision Transformer。 在图像编码器和语言编码器之上添加两个线性投影层,以匹配图像和语言特征的维度。 与以前的跨模态共享表示方法相比,Florence 超越了简单的分类和检索功能,扩展到分别支持对象级别、多模态和视频的高级表示。
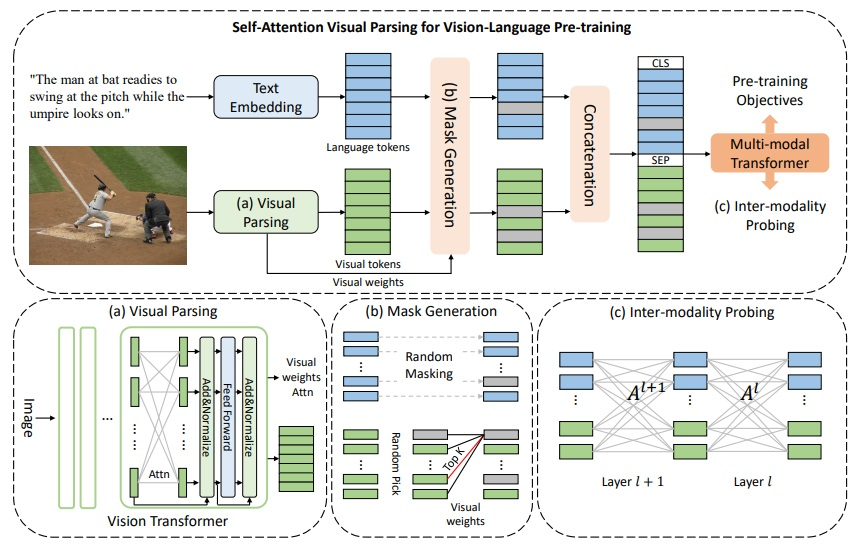
七、Visual Parsing
视觉解析是一种视觉和语言预训练模型,采用自注意力进行视觉特征学习,其中每个视觉标记是所有标记的近似加权混合。 因此,视觉解析提供了每个视觉标记对的依赖性。 它有助于更好地学习视觉与语言的关系并促进跨模式的协调。 该模型由一个以图像作为输入并输出视觉标记的视觉 Transformer 和一个多模态 Transformer 组成。 它应用线性层和层归一化来嵌入视觉标记。 它遵循 BERT 来获得词嵌入。 视觉和语言标记连接起来形成输入序列。 多模态 Transformer 用于融合视觉和语言模态。 名为互模态流 (IMF) 的指标用于量化两种模态之间的交互。 采用三个预训练任务:掩码语言建模(MLM)、图像文本匹配(ITM)和掩码特征回归(MFR)。 MFR 是一项新颖的任务,用于在该框架中掩盖具有相似或相关语义的视觉标记。
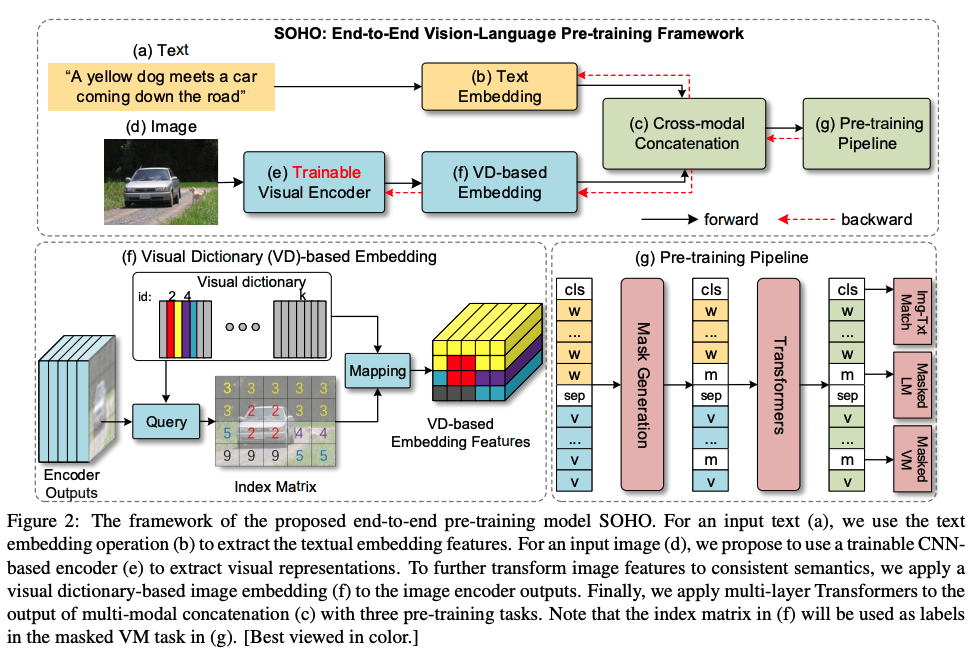
八、SOHO
SOHO(“跳出盒子”)将整个图像作为输入,并以端到端的方式学习视觉语言表示。 SOHO 不需要边界框注释,这使得推理速度比基于区域的方法快 10 倍。 文本嵌入用于提取文本嵌入特征。 可训练的 CNN 用于提取视觉表示。 SOHO 学习通过促进跨模态理解的视觉词典(VD)提取全面而紧凑的图像特征。 VD 旨在表示相似语义的一致视觉抽象。 它会动态更新并在建议的预训练任务 Masked Visual Modeling (MVM) 中使用。
九、InternVideo: General Video Foundation Models via Generative and Discriminative Learning
基础模型最近在计算机视觉的各种下游任务中表现出了出色的性能。 然而,大多数现有的视觉基础模型仅仅关注图像级的预训练和适应,这对于动态和复杂的视频级理解任务来说是有限的。 为了填补这一空白,我们通过利用生成性和判别性自监督视频学习,提出了通用视频基础模型 InternVideo。 具体来说,InternVideo 有效地探索了屏蔽视频建模和视频语言对比学习作为预训练目标,并以可学习的方式有选择地协调这两个互补框架的视频表示,以促进各种视频应用。 没有花里胡哨的东西,InternVideo 在 39 个视频数据集上实现了最先进的性能,涵盖了广泛的任务,包括视频动作识别/检测、视频语言对齐和开放世界视频应用程序。 特别是,我们的方法在具有挑战性的 Kinetics-400 和 Something-Something V2 基准测试上分别可以获得 91.1% 和 77.2% 的 top-1 准确率。 所有这些结果都有效地展示了我们的 InternVideo 用于视频理解的通用性。 代码将在 https://github.com/OpenGVLab/InternVideo 发布。
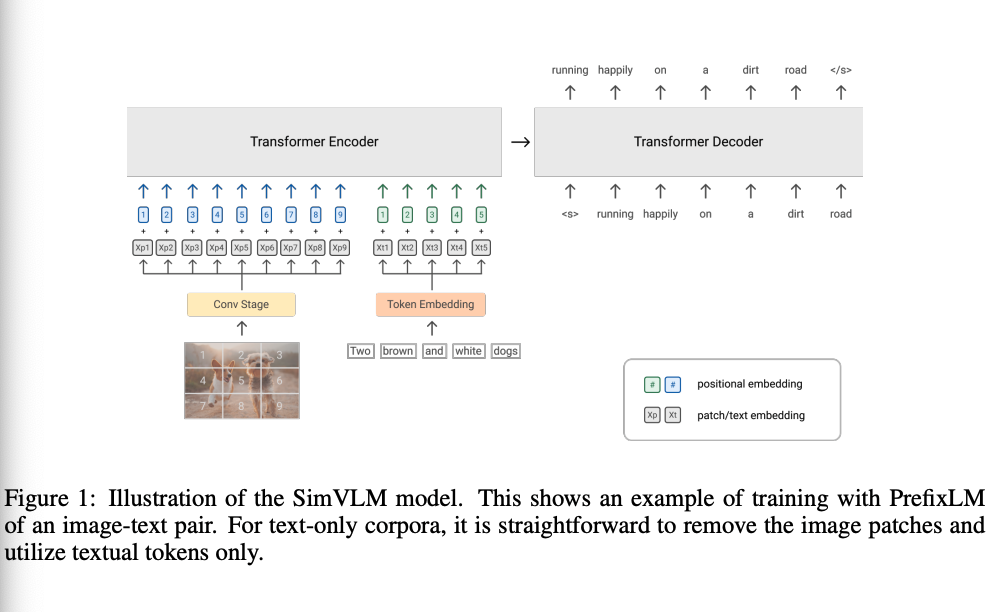
十、Simple Visual Language Model(SimVLM)
SimVLM 是一个极简的预训练框架,通过利用大规模弱监督来降低训练复杂性。 它使用单个前缀语言建模 (PrefixLM) 目标进行端到端训练。 PrefixLM 支持前缀序列内的双向注意力,因此它适用于仅解码器和编码器-解码器序列到序列语言模型。


















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











