







文章目录
- Abstract
- 1 INTRODUCTION
- 2 BACKGROUND
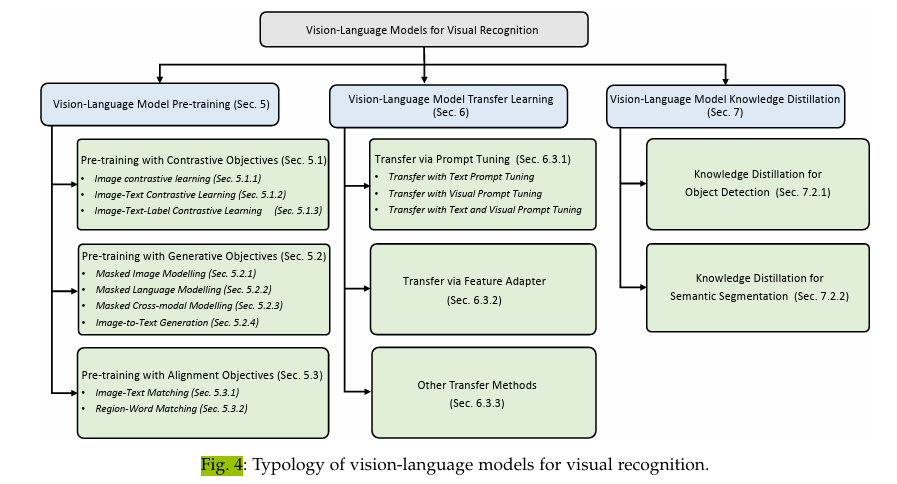
- 3 VLM FOUNDATIONS
- 4 DATASETS
- 5 VISION-LANGUAGE MODEL PRE-TRAINING
- 6 VLM TRANSFER LEARNING
- 7 VLM KNOWLEDGE DISTILLATION
- 8 PERFORMANCE COMPARISON
- 9 FUTURE DIRECTIONS
- 10 CONCLUSION
Vision-Language Models for Vision Tasks: A Survey
视觉任务的视觉语言模型:一项调查
改综述主要是针对”用于视觉识别任务的 VLM“ -但是也讲解了很丰富的VLM基础知识,可以做成VLM起步学习用~ 非常值得阅读哦
paper:2304.00685.pdf (arxiv.org)
github:jingyi0000/VLM_survey: Vision-Language Models for Vision Tasks: A Survey (github.com)
Abstract
大多数视觉识别研究在深度神经网络(DNN)训练中严重依赖人群标签数据,而且通常为每个单一的视觉识别任务训练一个 DNN,导致视觉识别范式费时费力。为了应对这两个挑战:
视觉语言模型(VLMs)最近得到了深入研究,该模型能从互联网上几乎无穷无尽的网络规模图像-文本对中学习丰富的视觉-语言相关性,并通过单个 VLM 对各种视觉识别任务进行zero-shot预测。
本文系统回顾了用于各种视觉识别任务的视觉语言模型,包括
- 介绍视觉识别范式发展的背景;
- 总结广泛采用的网络架构、预训练目标和下游任务的 VLM 基础;
- VLM 预训练和评估中广泛采用的数据集;
- 现有 VLM 预训练方法、VLM 转移学习方法和 VLM 知识提炼方法的回顾和分类;
- 已回顾方法的基准测试、分析和讨论;
- 未来视觉识别 VLM 研究的几个研究挑战和潜在研究方向。
与本调查相关的项目已在 https://github.com/jingyi0000/VLM 调查网站上创建。
1 INTRODUCTION
视觉识别(如图像分类、物体保护和语义分割)是计算机视觉研究中一个长期存在的难题,也是自动驾驶、遥感、机器人等无数计算机视觉应用的基石。随着深度学习的出现,视觉识别研究通过利用端到端可训练深度神经网络(DNN)取得了巨大成功。 然而,从传统机器学习向深度学习的转变带来了两个新的巨大挑战,即在 "从零开始深度学习 "的经典设置下 DNN 训练收敛缓慢以及 DNN 训练中大规模、特定任务和人群标签数据的费力收集。
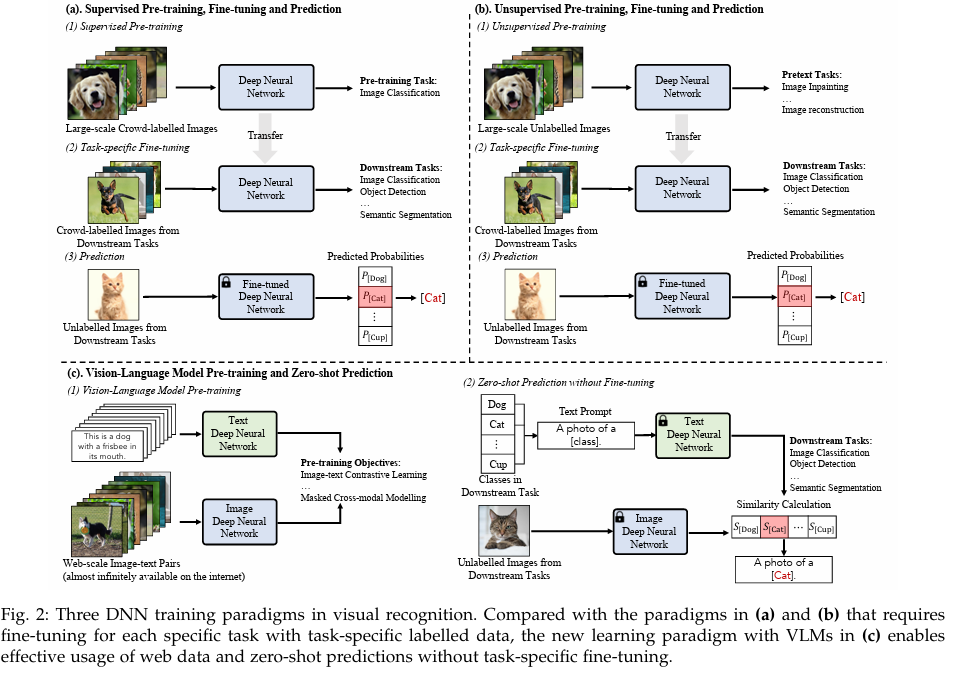
最近,一种新的学习范式 “预训练、微调和预测”(Pre-training, Fine tuning and Prediction)已在广泛的视觉识别任务中显示出极大的有效性。 在这种新范式下,DNN 模型首先使用某些现成的大规模训练数据(有注释或无注释)进行预训练,然后使用特定任务的注释训练数据对预训练模型进行微调,如图 2 (a) 和 (b) 所示。通过预训练模型学到的全面知识,这种学习范式可以加速网络收敛,并为各种下游任务训练出性能良好的模型。
尽管如此,预训练、微调和预测范式仍需要利用每个下游任务的标记训练数据,进行额外的特定任务微调。受自然语言处理技术进步的启发,一种名为 “视觉语言模型预训练和zero-shot预测”(Vision-Language Model Pre-training and Zero-shot Prediction)的新深度学习范式最近引起了越来越多的关注。在这一范例中,视觉语言模型(VLM)通过互联网上几乎无限可用的大规模图像-文本对进行预训练,如图 2 ©所示:
预训练的 VLM 无需微调即可直接应用于下游的图像识别任务。VLM 预训练通常以某些视觉语言目标为指导,以便从大规模图像文本对中学习图像文本对应关系,
例如,CLIP[10]采用图像文本对比目标,通过在嵌入空间中将配对图像和文本拉近并将其他图像和文本推远来学习。这样,预训练的 VLMs 就能捕捉到丰富的视觉语言对应知识,并能通过匹配任何给定图像和文本的嵌入进行zero-shot预测。这种新的学习范式可以有效利用网络数据,无需针对特定任务进行微调就能进行zero-shot预测,虽然实施起来非常简单,但性能却令人难以置信,例如,预先训练好的 CLIP 在 36 项视觉识别任务中取得了优异的zero-shot性能,这些任务包括经典图像分类以及人类动作和光学字符识别。
在视觉语言模型预训练和zero-shot预测取得巨大成功之后,除了各种 VLM 预训练研究之外,还有两个研究方向得到了深入探讨。
- 第一条:研究路线是探索具有迁移学习功能的 VLM。有几种迁移方法证明了这一点,如提示调整、视觉适应等,它们都有一个共同的目标,即让预训练的 VLM 有效适应各种下游任务。
- 第二条:是探索具有知识提炼功能的 VLM,例如,一些研究探讨了如何从 VLM 中提炼知识用于下游任务,目的是在物体检测、语义分割等方面获得更好的性能。
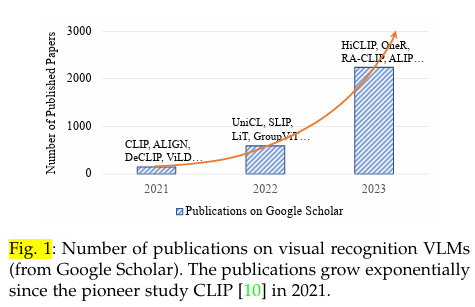
尽管如图 1 所示,从 VLM 中获取大量知识的兴趣日益浓厚,但研究界仍缺乏一份全面的调查报告,以帮助梳理现有的基于 VLM 的视觉识别研究、面临的挑战以及未来的研究方向。我们从背景、基础、数据集、技术方法、基准测试和未来研究方向等不同角度进行了调查。我们相信,这项调查将为我们提供一个清晰的大画面,让我们了解我们在这个新兴但极具前景的研究方向上已经取得了哪些成就,以及我们还能取得哪些成就。
总之,这项工作的主要贡献有三方面。
- 首先,它系统回顾了用于视觉识别任务的 VLM,包括图像分类、物体检测和语义分割。据我们所知,这是首次对用于视觉识别的 VLMs 进行调查,通过对现有研究的全面总结和分类,为这项前景广阔的研究提供了一个大视野。
- 其次,它研究了用于视觉识别的 VLM 的最新进展,包括对多个公共数据集的现有工作进行全面的基准测试和讨论。
- 第三,报告分享了视觉识别 VLMs 所面临的几个研究挑战和潜在的研究方向。
本调查报告的其余部分安排如下。第 2 节介绍了视觉识别的范式发展和一些相关研究。第 3 节介绍了 VLM 的基础,包括广泛使用的深度网络架构、预训练目标、预训练框架和 VLM 评估中的下游任务。第 4 节介绍了 VLM 预训练和评估中常用的数据集。第 5 节对 VLM 预训练方法进行了回顾和分类。第 6 节和第 7 节分别对 VLM 的迁移学习和知识提炼方法进行了系统回顾。最后,我们在第 9 节分享了几个有前景的 VLM 研究方向。
2 BACKGROUND
- 首先介绍视觉识别训练范式的发展,以及它如何向视觉语言模型预训练和zero-shot预测范式发展。
- 然后,我们介绍用于视觉识别的视觉语言模型(VLM)的发展。
- 我们还讨论了几个相关的调查,以突出本调查的范围和贡献。
2.1 Training Paradigms for Visual Recognition
视觉识别范式的发展大致可分为五个阶段,包括:
- 传统的机器学习和预测;
- 从零开始的深度学习和预测;
- 有监督的预训练、微调和预测;
- 无监督的预训练、微调和预测;
- 视觉语言模型预训练和zero-shot预测。
下面,我们将详细介绍、比较和分析这五种训练范式。
2.1.1 Traditional Machine Learning and Prediction
在深度学习时代到来之前,视觉识别研究主要依靠手工创建特征的特征工程和将手工创建的特征归入预定义语义类别的轻量级学习模型。然而,这种模式需要主要专家为特定的视觉识别任务制作有效的特征,不能很好地应对复杂的任务,而且可扩展性差。
2.1.2 Deep Learning from Scratch and Prediction
随着深度学习的出现,视觉识别研究取得了巨大成功,利用端到端可训练 DNN,避开了复杂的特征工程,专注于神经网络的架构工程以学习有效特征。 例如,ResNet[6]通过skip设计实现了非常深度的网络,并允许从海量人群标签数据中学习,在困难的 ImageNet 基准上取得了前所未有的性能。然而,从传统机器学习转向深度学习带来了两个新的巨大挑战:在 "从零开始深度学习 "的经典设置下,DNN 训练收敛缓慢;在 DNN 训练中,收集大规模、特定任务和人群标签数据非常费力。
2.1.3 Supervised Pre-training, Fine-tuning and Prediction
随着人们发现从有标签的大规模数据集中学习到的特征可以转移到下游任务中,"从零开始深度学习 "和 "预测 "的范式逐渐被 "监督预训练、微调和预测 "的新范式所取代。如图 2 (a) 所示,这种新的学习范式在大规模标记数据(如 ImageNet)上对 DNN 进行有监督损失的预训练,然后用特定任务的训练数据对预训练的 DNN 进行微调 。由于预训练的 DNN 已掌握了一定的视觉知识,因此可以加速网络收敛,并有助于利用有限的特定任务训练数据训练出性能良好的模型。
2.1.4 Unsupervised Pre-training, Fine-tuning & Prediction
尽管在许多视觉识别任务中,监督预训练、微调和预测取得了最先进的性能,但它在预训练中需要大规模的标记数据。为了缓解这一限制,采用了一种新的学习范式–无监督预训练、微调和预测,探索自监督学习,从无标签数据中学习有用和可迁移的表征,如图 2 (b) 所示。为此,人们提出了各种自我监督训练目标,包括建立交叉斑块关系模型的遮蔽图像建模、通过对比训练样本学习辨别特征的对比学习等。然后,利用特定任务的标记训练数据,在下游任务中对自监督预训练模型进行微调。由于这种模式在预训练中不需要标记数据,因此可以利用更多的训练数据来学习有用和可迁移的特征,从而获得比监督预训练更好的性能。
2.1.5 VLM Pre-training and Zero-shot Prediction
如图 2 (a) 和 (b) 所示,虽然有监督或无监督的预训练和微调都能提高网络的收敛性,但仍需要使用标记任务数据进行微调。受自然语言处理领域巨大成功的激励,一种名为 "视觉-语言模型预训练和zero-shot预测 "的新深度学习范式被提出用于视觉识别,如图 2 ©所示。互联网上的大规模图像-文本对几乎无穷无尽,通过某些视觉语言目标对视觉语言模型进行预训练,可以捕捉丰富的视觉语言知识,并通过匹配任何给定图像和文本的嵌入,对下游视觉识别任务进行zero-shot预测(无需调整)。
与预训练和微调相比,这一新范式能够有效利用大规模网络数据和zero-shot预测,而无需针对特定任务进行微调。大多数现有研究都试图从三个方面改进 VLM:
- 收集大规模信息图像文本数据
- 设计大容量模型,以便从大数据中有效学习;
- 设计新的预训练目标,以便学习有效的 VLM。
在本文中,我们对这一新的视觉语言学习范式进行了系统研究,旨在为这一具有挑战性但前景广阔的研究领域提供一个清晰的大视野,了解现有的 VLM 研究、面临的挑战和未来的发展方向。
2.2 Development of VLMs for Visual Recognition
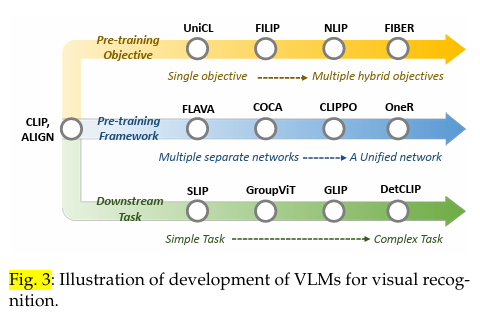
自 CLIP [10]问世以来,与视觉识别相关的 VLM 研究取得了长足的进步。如图 3 所示,我们从三个方面介绍了用于视觉识别的 VLM:
- 预训练目标:从 "单一目标 "到 “多重混合目标”。早期的 VLM 一般采用单一的预训练目标,而最近的 VLM 则引入了多个目标(如对比目标、排列目标和生成目标),以探索它们之间的协同作用,从而使 VLM 更稳健,在下游任务中表现更好;
- 预训练框架:从 "多个独立网络 "到 “一个统一网络”。早期的 VLM采用双塔预训练框架,而近期的 VLM 则尝试采用单塔预训练框架,用统一的网络对图像和文本进行编码,GPU 内存使用量更少,跨数据模态的通信效率更高;
- 下游任务:从简单到复杂的任务。早期的 VLM专注于图像级视觉识别任务,而近期的 VLM则更具通用性,也可用于复杂且需要定位相关知识的密集预测任务。
2.3 Relevant Surveys
据我们所知,这是第一份对各种视觉识别任务的 VLM 进行评测的调查报告。已有一些相关调查对视觉语言任务的 VLM 进行了评测,如视觉问题解答 [47]、视觉推理的自然语言 [48] 和短语接地 [49]。例如,Li 等人[50] 分享了视觉语言任务方面的进展,包括针对各种特定任务方法的 VLM 预训练。Du 等人[51] 和 Chen 等人[52] 综述了视觉语言任务的 VLM 预训练。徐等人[53]和王等人[54]分享了多模态学习在多模态任务上的最新进展。不同的是,我们主要从三个方面回顾了用于视觉识别任务的 VLM:
- 视觉识别任务中 VLM 预训练的最新进展;
- 从 VLM 到视觉识别任务的两种典型转移方法;
- 视觉识别任务中 VLM 预训练方法的基准测试。
视觉识别任务:是指利用计算机视觉技术对图像或视频进行分析和识别的过程。这些任务可以包括图像分类、目标检测、物体识别、人脸识别、图像分割等。通过深度学习和神经网络等技术的发展,视觉识别任务在诸如智能监控、自动驾驶、医疗影像识别、工业质检等领域得到广泛应用
3 VLM FOUNDATIONS
VLM 预训练旨在预训练 VLM 学习图像-文本相关性,目标是对视觉识别任务进行有效的zero-shot预测。给定图像-文本对,它首先使用文本编码器和图像编码器提取图像和文本特征,然后按照一定的预训练目标学习视觉-语言相关性。因此,通过匹配任何给定图像和文本的嵌入,VLMs 可以在未见过的数据上进行zero-shot评估。本节将介绍 VLM 预训练的基础,包括提取图像和文本特征的常见网络架构、模拟视觉语言相关性的预训练目标、VLM 预训练框架和 VLM 评估的下游任务。
3.1 Network Architectures
VLM 预训练使用深度神经网络,该网络从预训练数据集 D = { x n I , x n T } n = 1 N \mathcal{D} = \{ x_n^I, x_n^T \}_{n=1}^N D={xnI,xnT}n=1N中的 N N N 图像-文本对中提取图像和文本特征,其中 x n I x_n^I xnI 和 x n T x_n^T xnT 表示图像样本及其配对的文本样本。深度神经网络有一个图像编码器 f θ f_{\theta} fθ 和一个文本编码器 f ϕ f_{\phi} fϕ,它们分别将图像和文本(来自图像-文本对 { x n I x_n^I xnI, x n T x_n^T xnT})编码为图像嵌入值 z n I = f θ ( x n I ) z_n^I = f_{\theta}(x_n^I) znI=fθ(xnI) 和文本嵌入值 z n T = f ϕ ( x n T ) z_n^T = f_{\phi}(x_n^T) znT=fϕ(xnT)。本节将介绍在 VLM 预训练中被广泛采用的深度神经网络的架构。
3.1.1 Architectures for Learning Image Features
目前,有两种网络架构被广泛用于学习图像特征,即基于 CNN 的架构和基于 Transformer的架构。
CNN-based Architectures. 目前已有不同的 ConvNets(如 VGG、ResNet 和 EfficientNet)被用于学习图像特征。作为 VLM 预训练中最常用的 ConvNet 之一,ResNet采用了卷积块之间的跳接,从而避免了梯度消失和爆炸,实现了深度神经网络。为了更好地进行特征提取和视觉语言建模,一些研究对原始网络架构进行了修改。以 ResNet 为例。他们引入了ResNet-D [60],采用了抗锯齿矩形-2模糊池化,并在跨前多头注意力中用注意力池化取代了全局平均池化。
Transformer-based Architectures. Transformer最近在视觉识别任务中得到了广泛的应用,如图像分类 、物体检测和语义分割。作为用于图像特征学习的标准Transformer架构,ViT[57]采用了一系列Transformer模块,每个模块由一个多头自注意层和一个前馈网络组成。 输入图像首先被分割成固定大小的patch,然后经过线性投影和位置嵌入后被送入Transformer编码器。文献 [10]、[18]、[64] 对 ViT 进行了修改,在变换器编码器之前增加了一个归一化层。
3.1.2 Architectures for Learning Language Features
Transformer 及其变体已被广泛用于学习文本特征。标准的 Transformer具有编码器-解码器结构,其中编码器有6个块,每个块有一个多头自我注意层和一个多层感知器(MLP)。解码器也有6个区块,每个区块有一个多头注意力层、一个屏蔽多头层和一个 MLP。大多数 VLM 研究(如 CLIP [10])都采用了标准的 Transformer,并对 GPT2 [16]稍作修改,从头开始训练,不使用 GPT2 权重初始化。
3.2 VLM Pre-training Objectives
作为 VLM 的核心,人们设计了各种视觉语言预训练目标,用于学习丰富的视觉语言相关性。这些目标大致分为三类:对比目标、生成目标和对齐目标。
3.2.1 Contrastive Objectives
对比目标(Contrastive objectives)通过在特征空间中将成对样本拉近,将其他样本拉远,训练 VLM 学习判别表征。
图像对比学习(Image Contrastive Learning)的目的是通过迫使查询图像在嵌入空间中与其正键(即其数据增强)接近而与其负键(即其他图像)远离来学习具有区分性的图像特征。给定一批
B
B
B图像,对比学习目标(如 InfoNCE [68] 及其变体 [12]、[13])通常表述如下:
L I I n f o N C E = − 1 B ∑ i = 1 B log exp ( z i I ⋅ z + I / τ ) ∑ j = 1 , j ≠ i B + 1 exp ( z i I ⋅ z j I / τ ) \begin{equation} \mathcal{L}_I^{\mathrm{InfoNCE}}=- \frac{1}{B} \sum_{i=1}^B \log \frac{\exp{(z_i^I\cdot z^I_+/\tau)}}{\sum_{j=1, j \neq i}^{B + 1}{\exp(z_i^I\cdot z^I_j/\tau)}} \end{equation} LIInfoNCE=−B1i=1∑Blog∑j=1,j=iB+1exp(ziI⋅zjI/τ)exp(ziI⋅z+I/τ)
其中, z i I z_{i}^I ziI为查询嵌入, { z j I } j = 1 , j ≠ i B + 1 \{z_j^I\}_{j=1,j \neq i}^{B+1} {zjI}j=1,j=iB+1为关键嵌入,其中 z + I z^I_+ z+I代表 z i I z_{i}^I ziI的正关键字,其余为 z i I z_{i}^I ziI的负关键字。
图像-文本对比学习(Image-Text Contrastive Learning)旨在通过拉近配对图像和文本的嵌入,同时推远其他图像和文本的嵌入,来学习具有辨别力的图像-文本表征。它通常是通过最小化对称图像-文本 infoNCE 损失来实现的,即
L
i
n
f
o
N
C
E
I
T
=
L
I
→
T
+
L
T
→
I
\mathcal{L}_{\mathrm{infoNCE}}^{IT} = \mathcal{L}_{I \rightarrow T} + \mathcal{L}_{T \rightarrow I}
LinfoNCEIT=LI→T+LT→I,其中,
L
I
→
T
\mathcal{L}_{I \rightarrow T}
LI→T将查询图像与文本关键字进行对比,而
L
T
→
I
\mathcal{L}_{T \rightarrow I}
LT→I 则将查询文本与图像关键字进行对比。给定一批
B
B
B 图像-文本对,
L
I
→
T
\mathcal{L}_{I \rightarrow T}
LI→T 和
L
T
→
I
\mathcal{L}_{T \rightarrow I}
LT→I 的定义如下:
L
I
→
T
=
−
1
B
∑
i
=
1
B
log
exp
(
z
i
I
⋅
z
i
T
/
τ
)
∑
j
=
1
B
exp
(
z
i
I
⋅
z
j
T
/
τ
)
\begin{equation} \mathcal{L}_{I \rightarrow T}=- \frac{1}{B} \sum_{i=1}^B \log \frac{\exp{(z_i^I\cdot z^T_i/\tau)}}{\sum_{j=1}^{B}{\exp(z^I_i\cdot z^T_j/\tau)}} \end{equation}
LI→T=−B1i=1∑Blog∑j=1Bexp(ziI⋅zjT/τ)exp(ziI⋅ziT/τ)
L T → I = − 1 B ∑ i = 1 B log exp ( z i T ⋅ z i I / τ ) ∑ j = 1 B exp ( z i T ⋅ z j I / τ ) \begin{equation} \mathcal{L}_{T \rightarrow I}=- \frac{1}{B} \sum_{i=1}^B \log \frac{\exp{(z_i^T\cdot z^I_i/\tau)}}{\sum_{j=1}^{B}{\exp(z^T_i\cdot z^I_j/\tau)}} \end{equation} LT→I=−B1i=1∑Blog∑j=1Bexp(ziT⋅zjI/τ)exp(ziT⋅ziI/τ)
其中, z I z^I zI和 z T z^T zT 分别代表图像嵌入和文本嵌入。
图像-文本-标签对比学习(Image-Text-Label Contrastive Learning)将监督对比学习[69]引入到图像-文本对比学习中,并将公式 2 和公式 3 重新定义如下:
L I → T I T L = − ∑ i = 1 B 1 ∣ P ( i ) ∣ ∑ k ∈ P ( i ) log exp ( z i I ⋅ z k T / τ ) ∑ j = 1 B exp ( z i I ⋅ z j T / τ ) \begin{equation} \mathcal{L}_{I \rightarrow T}^{ITL}=- \sum_{i=1}^B \frac{1}{|\mathcal{P}(i)|} \sum_{k\in \mathcal{P}(i)} \log \frac{\exp{(z_i^I\cdot z^T_k/\tau)}}{\sum_{j=1}^{B}{\exp(z^I_i\cdot z^T_j/\tau)}} \end{equation} LI→TITL=−i=1∑B∣P(i)∣1k∈P(i)∑log∑j=1Bexp(ziI⋅zjT/τ)exp(ziI⋅zkT/τ)
L T → I I T L = − ∑ i = 1 B 1 ∣ P ( i ) ∣ ∑ k ∈ P ( i ) log exp ( z i T ⋅ z k I / τ ) ∑ j = 1 B exp ( z i T ⋅ z j I / τ ) \begin{equation} \mathcal{L}_{T \rightarrow I}^{ITL}=- \sum_{i=1}^B \frac{1}{|\mathcal{P}(i)|} \sum_{k\in \mathcal{P}(i)} \log \frac{\exp{(z^T_i \cdot z_k^I /\tau)}}{\sum_{j=1}^{B}{\exp(z^T_i \cdot z^I_j /\tau)}} \end{equation} LT→IITL=−i=1∑B∣P(i)∣1k∈P(i)∑log∑j=1Bexp(ziT⋅zjI/τ)exp(ziT⋅zkI/τ)
其中, k ∈ P ( i ) = { k ∣ k ∈ B , y k = y i } k \in \mathcal{P}(i) = \{k|k \in B, y_k = y_i \} k∈P(i)={k∣k∈B,yk=yi}和 y y y 是 ( z I , z T ) (z^{I}, z^{T}) (zI,zT) 的类别标签。根据公式 4 和 5,图像-文本标签 infoNCE 损失定义为 L i n f o N C E I T L = L I → T I T L + L T → I I T L \mathcal{L}^{ITL}_{\mathrm{infoNCE}} = \mathcal{L}_{I \rightarrow T}^{ITL} + \mathcal{L}_{T \rightarrow I}^{ITL} LinfoNCEITL=LI→TITL+LT→IITL.。
3.2.2 Generative Objectives
生成目标(Generative objective)通过训练网络生成图像/文本数据来学习语义特征,具体方法包括图像生成、语言生成或跨模态生成。
遮蔽图像建模(Masked Image Modelling) 通过Mask和重建图像来学习交叉补丁相关性。它随机Mask一组输入图像的patches,并训练编码器根据未Masked patches重建屏蔽patches。给定一批
B
B
B 图像,损失函数可表述为:
L M I M = − 1 B ∑ i = 1 B log f θ ( x ‾ i I ∣ x ^ i I ) \begin{equation} \mathcal{L}_{MIM} = - \frac{1}{B} \sum_{i=1}^B \log f_{\theta} ( \ \overline{x}^I_i \ | \ \hat{x}^I_i \ ) \end{equation} LMIM=−B1i=1∑Blogfθ( xiI ∣ x^iI )
其中, x ‾ i I \overline{x}^I_i xiI和 x ^ i I \hat{x}^I_i x^iI分别表示 x i I x^I_i xiI 中的Masked patches和未Masked patches。
屏蔽语言建模(Masked Language Modelling)是 NLP 中广泛采用的预训练目标。它随机Mask一定比例的输入文本标记(如 BERT [14] 中的 15%),然后用未Mask的标记进行重构:
L M L M = − 1 B ∑ i = 1 B log f ϕ ( x ‾ i T ∣ x ^ i T ) \begin{equation} \mathcal{L}_{MLM} = - \frac{1}{B} \sum_{i=1}^B \log f_{\phi} ( \ \overline{x}^T_i \ | \ \hat{x}^T_i \ ) \end{equation} LMLM=−B1i=1∑Blogfϕ( xiT ∣ x^iT )
其中 x ‾ i T \overline{x}^T_i xiT 和 x ^ i T \hat{x}^T_i x^iT 分别表示 x i T x^T_i xiT 中已Mask和未Mask的标记。 B B B 表示批量大小。
掩码跨模态建模(Masked Cross-Modal Modelling)整合了掩码图像建模和掩码语言建模。给定一对图像-文本,它随机Mask一个图像片段子集和一个文本标记子集,然后根据未Mask的图像片段和未Mask的文本标记,学习重建它们,如下所示:
L M C M = − 1 B ∑ i = 1 B [ log f θ ( x ‾ i I ∣ x ^ i I , x ^ i T ) + log f ϕ ( x ‾ i T ∣ x ^ i I , x ^ i T ) ] \begin{equation} \mathcal{L}_{MCM} = - \frac{1}{B} \sum_{i=1}^B [ \log f_{\theta} ( \overline{x}^I_i | \hat{x}^I_i, \hat{x}^T_i ) + \log f_{\phi} ( \overline{x}^T_i | \hat{x}^I_i, \hat{x}^T_i )] \end{equation} LMCM=−B1i=1∑B[logfθ(xiI∣x^iI,x^iT)+logfϕ(xiT∣x^iI,x^iT)]
其中, o v e r l i n e x i I overline{x}^I_i overlinexiI/ x ^ i I \hat{x}^I_i x^iI 表示 x i I x^I_i xiI 中已Mask/未Mask的patches, o v e r l i n e x i T overline{x}^T_i overlinexiT/ x ^ i T \hat{x}^T_i x^iT 表示 x i T x^T_i xiT 中已Mask/未Mask的文本标记 tokens。
图像到文本生成(Image-to-Text Generation)旨在根据与 x T x^T xT 配对的图像自动预测文本 x T x^T xT:
L I T G = − ∑ l = 1 L log f θ ( x T ∣ x < l T , z I ) \begin{equation} \mathcal{L}_{ITG} = - \sum^L_{l=1} \ \log \ f_{\theta} (x^T \ | \ x^T_{<l}, z^I) \end{equation} LITG=−l=1∑L log fθ(xT ∣ x<lT,zI)
其中, L L L 表示要对 x T x^T xT 进行预测的标记数, z I z^{I} zI 是与 x T x^T xT 配对的图像的嵌入。
3.2.3 Alignment Objectives
对齐(Alignment Objectives)目标通过嵌入空间上的全局图像-文本匹配或局部区域-单词匹配来对齐图像-文本对。
图像-文本匹配模型(Image-Text Matching)是图像和文本之间的全局相关性模型,可以用衡量图像和文本之间对齐概率的得分函数 $\mathcal{S}(\cdot)$ 和二元分类损失来表示:
L I T = p log S ( z I , z T ) + ( 1 − p ) log ( 1 − S ( z I , z T ) ) \begin{equation} \mathcal{L}_{IT} = p \log \mathcal{S} (z^I, z^T) + (1-p) \log (1 - \mathcal{S} (z^I, z^T)) \end{equation} LIT=plogS(zI,zT)+(1−p)log(1−S(zI,zT))
其中,如果图片和文字配对,则 p p p 为 1,否则为 0。
区域-词语匹配(Region-Word Matching)旨在为图像-文本配对中的局部跨模态相关性(即 "图像区域 "和 "词语 "之间的相关性)建模,用于对象检测等密集视觉识别任务。它可以表述为:
L R W = p log S r ( r I , w T ) + ( 1 − p ) log ( 1 − S r ( r I , w T ) ) \begin{equation} \mathcal{L}_{RW} = p \log \mathcal{S}^r (r^I, w^T) + (1-p) \log (1 - \mathcal{S}^r (r^I, w^T)) \end{equation} LRW=plogSr(rI,wT)+(1−p)log(1−Sr(rI,wT))
其中, ( r I , w T ) (r^I, w^T) (rI,wT) 表示区域-单词配对,如果区域和单词配对,则 p = 1 p = 1 p=1,否则 p = 0 p = 0 p=0。 m a t h c a l S r ( ⋅ ) mathcal{S}^r (\cdot) mathcalSr(⋅)表示局部得分函数,用于衡量 "图像区域 "和 "单词 "之间的相似性。
3.3 VLM Pre-training Frameworks
本节介绍 VLM 预训练中广泛采用的框架,包括双塔、双腿(two-leg )和单塔预训练框架。
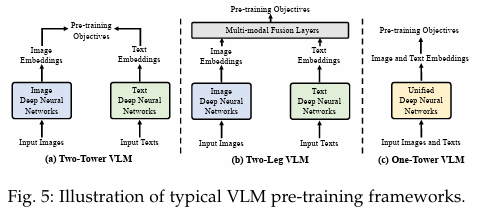
具体来说,双塔框架已被广泛用于 VLM 预训练,输入图像和文本分别由两个独立的编码器编码,如图 5 (a) 所示。稍有不同的是,双腿框架引入了额外的多模态赋值层,从而实现了图像和文本模态之间的特征交互,如图 5 (b) 所示。作为比较,单塔 VLM尝试将视觉和语言学习统一到一个编码器中,如图 5 ©所示,旨在促进数据模态之间的高效通信。
3.4 Evaluation Setups and Downstream Tasks
本节介绍在 VLM 评估中广泛采用的设置和下游任务。设置包括zero-shot预测和线性探测,下游任务包括图像分类、物体检测、语义分割、图像文本检索和动作识别。
3.4.1 Zero-shot Prediction
作为评估 VLMs 泛化能力的最常见方法,Zero-shot预测法直接将预先训练好的 VLMs 应用于下游任务,而无需针对具体任务进行任何微调。
图像分类(Image Classification)的目的是将图像归入预先确定的类别。VLM 通过比较图像和文本的嵌入,实现Zero-shot图像分类,其中通常采用 "提示工程 "来生成与任务相关的提示,如 “一张[标签]的照片”。
语义分割(Semantic Segmentation)的目的是为图像中的每个像素分配一个类别标签。预先训练好的 VLM 通过比较给定图像像素和文本的嵌入,实现分割任务的Zero-shot预测。
物体检测(Object Detection)的目的是对图像中的物体进行定位和分类,这对各种视觉应用都很重要。利用从辅助数据集中学习到的物体定位能力,预训练 VLM 通过比较给定物体提议和文本的嵌入,实现物体检测任务的Zero-shot预测。
图像-文本检索(Image-Text Retrieval)旨在根据一种模式的线索从另一种模式中检索所需的样本,它包括两项任务,即根据文本检索图像的text-to-image检索和根据图像检索文本的image to-text检索。
3.4.2 Linear Probing
线性探测在 VLM 评估中被广泛采用。它冻结预先训练好的 VLM,并训练线性分类器对VLM 编码的嵌入进行分类,以评估 VLM 表示。图像分类和动作识别已被广泛应用于此类评估中,在动作识别任务中,视频片段通常会进行子采样以实现高效识别。
4 DATASETS
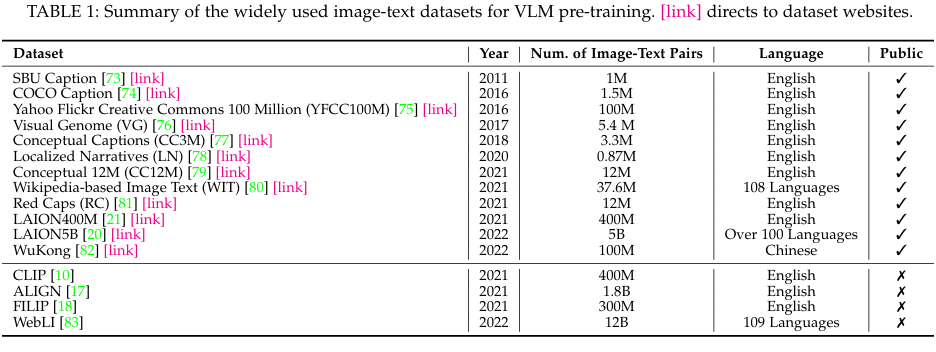
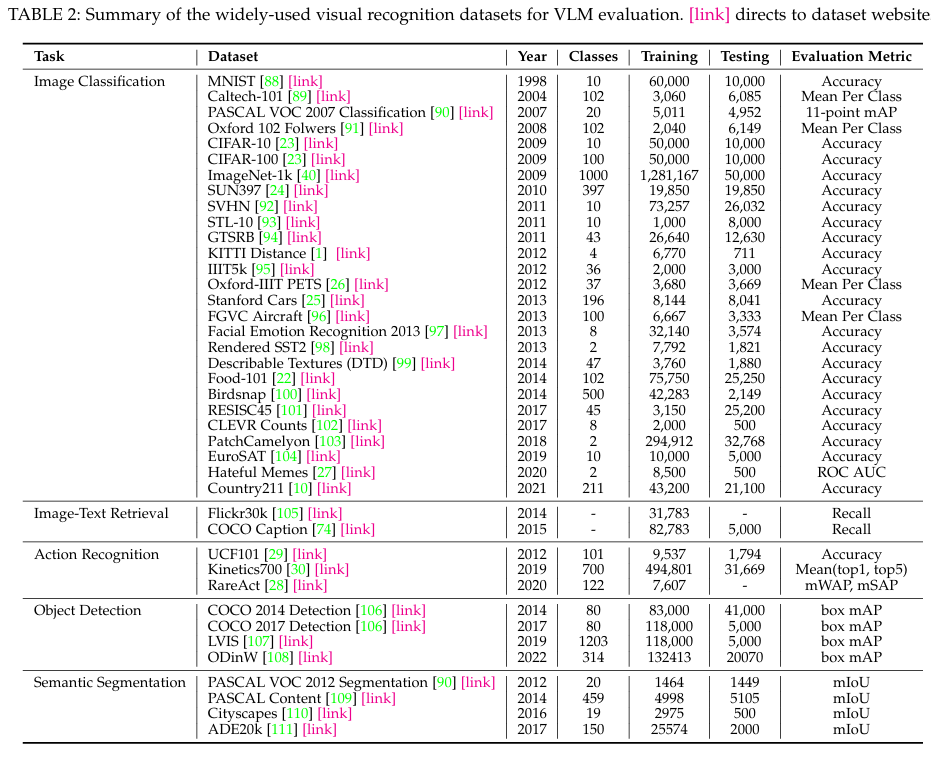
本节总结了用于 VLM 预训练和评估的常用数据集,详见表 1-2。
4.1 Datasets for Pre-training VLMs
为了进行 VLM 预训练,我们从互联网上收集了多个大规模图像文本数据集。 与传统的人群标签数据集相比,图像文本数据集的规模更大,收集成本更低。除了图像文本数据集,一些研究还利用辅助数据集为更好的视觉语言建模提供额外信息,例如,GLIP[67]利用 Object365[85]提取区域级特征。 用于VLM 预训练的图像文本数据集和辅助数据集的详情见附录 B。
4.2 Datasets for VLM Evaluation
如表 2 所示,VLM 评估采用了许多数据集,包括 27 个图像分类数据集、4 个物体检测数据集、4 个语义分割数据集、2 个图像文本检索数据集和 3 个动作识别数据集(数据集详情见附录 C)。例如,27 个图像分类数据集涵盖了广泛的视觉识别任务,从细粒度任务(如用于宠物识别的 Oxford-IIIT PETS 和用于汽车识别的 Stanford Cars)到一般任务(如 ImageNet [40])。
5 VISION-LANGUAGE MODEL PRE-TRAINING
VLM 预训练有三个典型的目标:对比目标、生成目标和对齐目标。本节将通过表 3 所列的多项 VLM 预训练研究对它们进行回顾。

5.1 VLMPre-Training with Contrastive Objectives
对比学习在 VLM 预训练中得到了广泛的探索,它设计了对比目标来学习具有鉴别力的图像-文本特征。
5.1.1 Image Contrastive Learning
这种预训练目标旨在学习图像模式中的判别特征,通常作为充分挖掘图像数据潜力的辅助目标。例如,SLIP[64] 采用公式 1 所示的标准 infoNCE 损失来学习辨别图像特征。
5.1.2 Image-Text Contrastive Learning
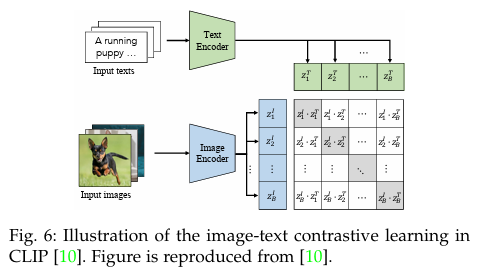
图像-文本对比(Image-text contrast )旨在通过对比图像-文本配对来学习视觉-语言相关性,即把配对图像和文本的嵌入点拉近,而把其他图像和文本的嵌入点拉远。例如,
CLIP[10] 在公式 2 中采用了对称的图像-文本 infoNCE 损失,通过图 6 中图像和文本嵌入之间的点积来测量图像文本的相似性。
因此,预训练的 VLM 可以学习图像与文本的相关性,从而在下游视觉识别任务中实现zero-shot预测。受 CLIP 取得巨大成功的启发,许多研究从不同角度改进了对称图像-文本 infoNCE loss。例如,
ALIGN[17] 利用大规模(即 18 亿)但有噪声的图像-文本对,通过噪声稳健的对比学习,扩大了 VLM 预训练的规模。
一些研究[112]、[113]和[114]则探索了使用更少图像文本对进行数据高效 VLM 预训练的方法。例如,DeCLIP[113] 引入了近邻监督,利用相似配对的信息,在有限的数据上实现有效的预训练。
OTTER [112] 采用最优传输技术将图像和文本伪配对,大大减少了所需的训练数据。
ZeroVL [114] 通过去偏数据采样和掷硬币混合数据扩充利用了有限的数据资源。
另一项后续研究旨在通过在不同语义层面进行图像-文本对比学习,建立全面的视觉-语言关联模型。例如,FILIP[18] 在对比学习中引入了区域-单词对齐,从而能够学习细粒度的视觉语言对应知识。
PyramidCLIP [116] 构建了多个语义层,并执行跨层和同层对比学习,以实现有效的 VLM 预训练。
此外,最近的一些研究还通过增强图像-文本对来进一步改进。例如,
LA-CLIP [126] 和 ALIP [127] 采用大型语言模型来增强给定图像的合成标题,
RA-CLIP [125] 则检索相关的图像-文本对来增强图像-文本对。
为了促进跨数据模式的高效通信,[44] 和 [43] 尝试在单个编码器中统一视觉和语言学习。
5.1.3 Image-Text-Label Contrastive Learning
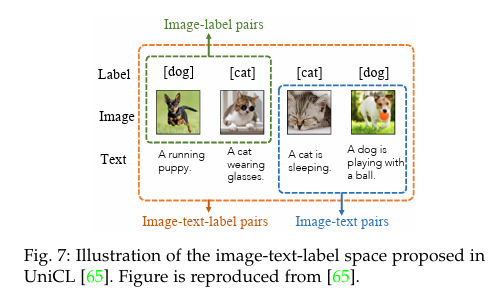
这种类型的预训练将图像分类标签引入式 4 所定义的图像-文本对比中,如图 7 所示,将图像、文本和分类标签编码到一个共享空间中。它既利用了图像标签的监督预训练,也利用了图像-文本对的无监督 VLM 预训练。正如
UniCL [65] 所报告的那样,这种预训练可以同时学习辨别特征和特定任务(即图像分类)特征。
随后的工作[115]将 UniCL 扩展到约 9 亿个图像-文本对,从而在各种下游识别任务中取得了出色的性能。
5.1.4 Discussion
对比目标要求正对与负对具有相似的嵌入。它们鼓励 VLM 学习辨别性视觉和语言特征,更多的辨别性特征通常会带来更自信、更准确的Zero-shot预测。然而,对比目标有两个限制:
- 联合优化正负对是一项复杂而具有挑战性的工作;
- 如第 3.2.1 节所述,它涉及到控制特征可辨别性的启发式温度超参数。
5.2 VLM Pre-training with Generative Objectives
生成式 VLM 预训练通过Masked图像建模、Masked语言建模、Masked跨模态建模和image-to-text生成来学习生成图像或文本,从而学习语义知识。
5.2.1 Masked Image Modelling
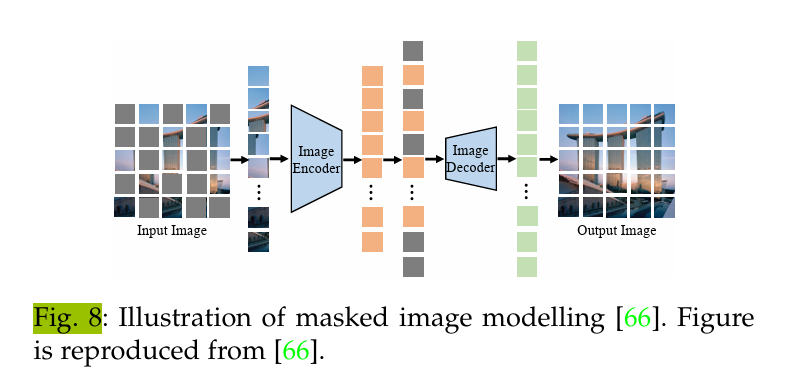
这种预训练目标通过Mask和重建图像来学习图像上下文的形成,如公式 6 所定义。例如,
FLAVA[42] 采用了与 BeiT [70] 相同的矩形块屏蔽,而 KELIP [120] 和 SegCLIP [46] 则遵循 MAE 的方法,在训练中屏蔽掉大部分(即 75%)的图像。
5.2.2 Masked Language Modelling
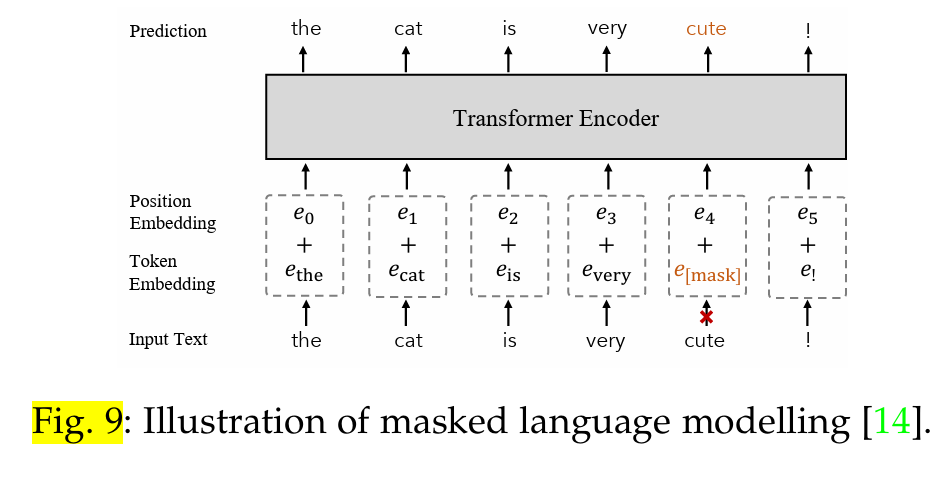
掩码语言建模(Masked Language Modelling)是 NLP 中广泛采用的预训练目标,其定义如式 7 所示,在 VLM 预训练中也证明了其在文本特征学习中的有效性。 如图 9 所示,其工作原理是Mask每个输入文本中的部分标记,并训练网络预测Mask标记。继[14]之后,FLAVA[42]屏蔽了 15%的文本标记,并从其余标记中重建它们,以模拟交叉词相关性。FIBER [71] 将屏蔽语言建模 [14] 作为 VLM 预训练目标之一,以提取更好的语言特征。
5.2.3 Masked Cross-Modal Modelling
如公式 8 所定义,Masked跨模态建模对图像Patches和文本标记进行Masked并联合重建,它继承了Masked图像建模和Masked语言建模的优点。例如,
FLAVA[42] 屏蔽了[70]中 40%的图像patches和[14]中15%的文本标记,然后使用 MLP 预测被屏蔽的patches和标记,从而捕捉到丰富的视觉语言对应信息。
5.2.4 Image-to-Text Generation
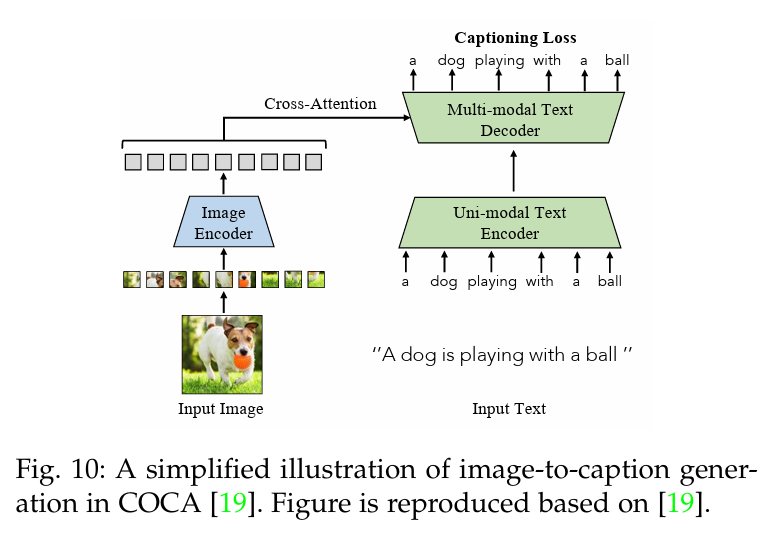
图像到文本生成(Image-to-Text Generation)的目的是通过训练 VLM 来预测标记化文本,从而为给定图像生成描述性文本,以捕捉细粒度的视觉语言相关性。它首先将输入图像编码为中间嵌入,然后按照公式 9 的定义将其解码为描述性文本。例如,如图 10 所示,COCA [19]、NLIP [123] 和 PaLI [83] 采用标准编码器-解码器架构和图像字幕目标训练 VLM。
5.2.5 Discussion
生成目标通过跨模态生成或遮蔽图像/语言/跨模态建模来工作,鼓励VLM 学习丰富的视觉、语言和视觉语言语境,以获得更好的Zero-shot预测。因此,生成目标通常被作为其他 VLM 预训练目标之上的附加目标,用于学习丰富的语境信息。
5.3 VLM Pre-training with Alignment Objectives
对齐目标(Alignment Objectives)通过学习预测给定文本是否正确描述了给定图像,强制 VLM 对成对图像和文本进行配准。在 VLM 预训练中,它大致可分为全局图像-文本匹配和局部区域-单词匹配。
5.3.1 Image-Text Matching
图像-文本匹配通过直接对齐公式 10 中定义的配对图像和文本来建立全局图像-文本相关性模型。例如,
给定一批图像-文本配对,FLAVA[42] 通过分类器和二元分类损失将给定图像与其配对文本进行匹配。
FIBER[71]借鉴了[72]的做法,挖掘具有成对相似性的硬否定,以更好地对齐图像和文本。
5.3.2 Region-Word Matching
区域-单词匹配目标通过对成对图像区域和单词词块进行对齐,建立局部细粒度视觉-语言相关性模型,大大有利于物体检测和语义分割中的zero-shot密集预测。 例如,
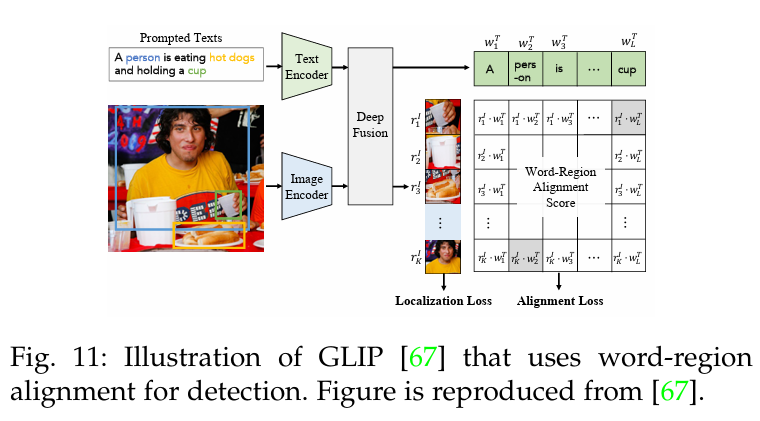
GLIP[67]、FIBER[71]和 DetCLIP[45]用区域-单词对齐分数(即区域视觉特征和单词特征之间的点积相似度)取代了物体分类logits,如图 11 所示。
5.3.3 Discussion
对齐目标学习预测给定图像和文本数据是否匹配,这种方法简单且易于优化,可以通过局部匹配图像和文本数据,轻松扩展到视觉-语言相关性建模。另一方面,它们通常在视觉或语言模式中学习到的相关信息很少。因此,对齐目标通常被用作其他 VLM 预训练目标的辅助损失,以加强对跨视觉和语言模式相关性的建模。
5.4 Summary and Discussion
总之,VLM 预训练通过不同的跨模态目标对视觉语言相关性进行建模,如图像-文本对比学习、遮蔽跨模态建模、图像-文本生成和图像-文本/区域词语匹配。此外,还探索了各种单模态目标,以充分利用其自身模态的数据潜力,如针对图像模态的Masked图像建模和针对文本模态的Masked语言建模。另一方面,最近的 VLM 预训练侧重于学习全局视觉语言相关性,这对图像分类等图像级识别任务大有裨益。同时,一些研究通过区域-单词匹配来建立局部精细视觉-语言相关性模型,目的是在物体检测和语义分割中实现更好的密集预测。
6 VLM TRANSFER LEARNING
除了直接将预先训练好的 VLM 应用于下游任务而不进行微调的zero-shot预测之外,最近还研究了迁移学习,即通过提示调整、特征适配器等方法将 VLM 适应于下游任务。本节将介绍针对预训练 VLM 的迁移学习的动机、整体迁移学习设置以及三种迁移学习方法,包括提示调整方法、特征适配器方法和其他方法。
6.1 Motivation of Transfer learning
尽管预先训练的 VLM 已显示出强大的基因化能力,但在应用于各种下游任务时,它们往往面临两类差距:
- 图像和文本分布方面的差距,例如,下游数据集可能具有特定任务的图像样式和文本格式;
- 训练目标方面的差距,例如,VLM 通常以任务无关的目标进行训练,学习一般概念,而下游任务往往涉及特定任务的目标,如粗粒度或细粒度分类、区域或像素级识别等。
6.2 Common Setup of Transfer Learning
为减少第 6.1 节所述的主要差距,我们探索了三种转移设置,包括监督转移、少量监督转移和无监督转移。有监督的转移利用了所有标记的下游数据来微调预训练的 VLM,而少量监督的转移只利用了少量标记的下游样本,因此注释效率更高。不同的是,无监督传输使用未标记的下游数据来微调 VLM。因此,对于 VLM 传输来说,它的难度更大,但更有前景,也更高效。
6.3 CommonTransfer Learning Methods
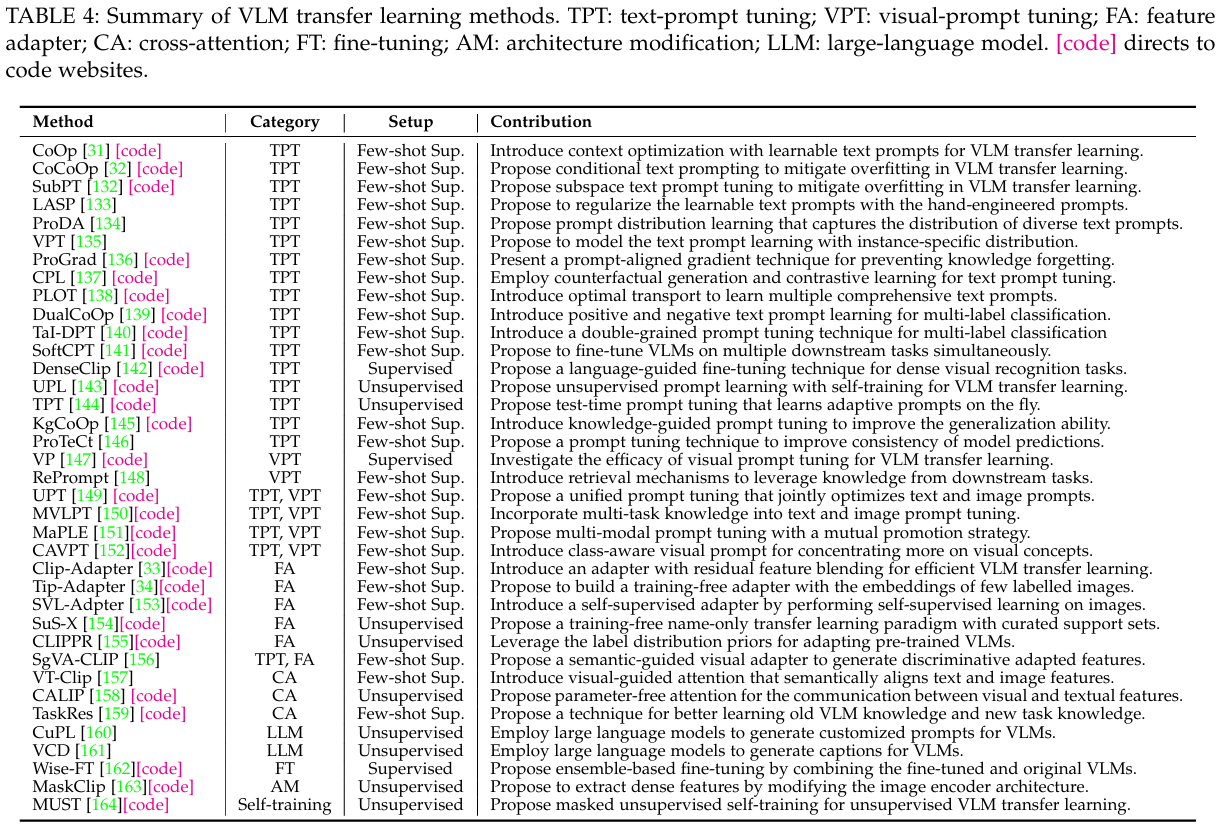
如表 4 所示,我们将现有的 VLM 转移方法大致分为三类,包括提示调整方法、特征适配器方法和其他方法。
6.3.1 Transfer via Prompt Tuning
受 NLP 中 "提示学习 "的启发,许多 VLM 提示学习方法被提出,用于通过寻找最佳提示来调整 VLM 以适应下游任务,而无需对整个 VLM 进行微调。现有研究大多采用文本提示调整、视觉提示调整和文本-视觉提示调整三种方法。
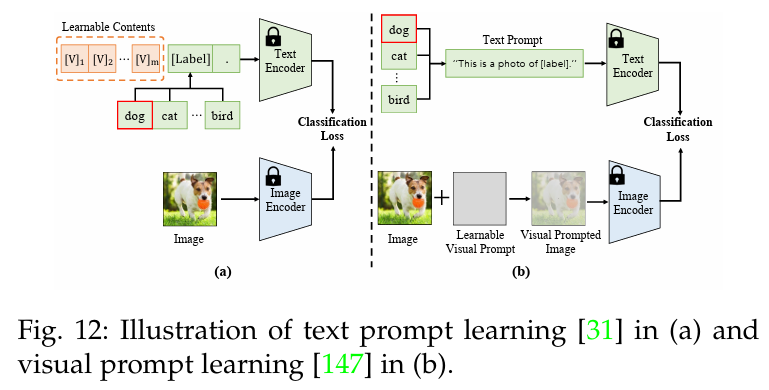
通过文本提示调节进行迁移(Transfer with Text Prompt Tuning)。不同于为每个任务手动设计文本提示的提示工程(prompt engineering),文本提示调整探索的是更有效、更高效的可学习文本提示,并为每个类别提供多个带标签的下游样本。例如,CoOp[31] 探索了上下文优化,利用可学习的单词向量为单个类别名称学习上下文单词。如图 12 (a)所示,它将一个类别词 [label] 扩展为一个句子’[V]1, [V]2, …, [V]m [label]',其中 [V] 表示可学习词向量,这些可学习词向量是通过最小化下游样本的分类损失而优化的。为了减轻提示学习中由于下游样本有限而导致的过拟合,CoCoOp [32] 探索了条件上下文优化,为每幅图像生成特定的提示。 SubPT [132] 设计了子提示调整,以提高所学提示的泛化能力。LASP[133]用手工设计的提示对可学习的提示进行了调整。 VPT[135]对文本提示进行了针对具体实例的分配建模,从而在下游任务中实现了更好的泛化。 KgCoOp[145]通过减少文本知识的遗忘,增强了对未见类别的泛化。
此外,SoftCPT[141] 还同时在多个少量任务上对 VLM 进行微调,以便从多任务学习中获益。PLOT [138] 采用优化传输来学习多个提示,以描述一个类别的不同特征。DualCoOp [139] 和 TaI-DP [140] 将 VLMs 转化为多标签分类任务,其中 Dual CoOp 采用正反两方面的提示进行多标签分类,而 TaI-DP 则引入了双粒度提示调整,以捕捉粗粒度和细粒度嵌入。DenseCLIP [142]探索了语言引导的微调,它采用视觉特征来调整文本提示,以进行密集预测 。ProTeCt [146] 证明了分层分类任务中模型预测的一致性。
除了有监督和少量监督提示学习之外,最近的研究还探索了无监督提示调整,以提高注释效率和可扩展性。例如,UPL[143] 通过在选定的伪标签样本上进行自我训练来优化可学习的提示。TPT [144] 则利用测试时间提示调整,从单个下游样本中学习自适应提示。
视觉提示调节进行迁移(Transfer with Visual Prompt Tuning)。与文本提示调整不同,视觉提示调整通过调节图像编码器的输入来转移 VLM,如图 12 (b) 所示。例如,VP[147] 采用可学习的图像扰动v,通过 x^I +v 来修改输入图像 x^I,目的是调整v以最小化识别损失。RePrompt [148] 将检索机制整合到视觉提示调整中,从而充分利用了下游任务的知识。视觉提示调整可实现像素级对下游任务的适应,尤其对高密度预测任务大有裨益。
文本-视觉提示调节进行迁移(Transfer with Text-Visual Prompt Tuning)的目的是同时调控文本和图像输入,从多种模式的联合提示优化中获益。例如,UPT[149] 将提示调谐统一为联合优化文本和图像提示,显示了两种提示调谐任务的互补性。MVLPT [150] 研究了多任务视觉语言提示调整,将跨任务知识纳入文本和图像提示调整。MAPLE [151]通过将视觉提示与相应的语言提示对齐来进行多模态提示调整,从而实现文本提示与图像提示之间的相互促进。CAVPT [152] 在类感知视觉提示和文本提示之间引入了交叉注意,鼓励视觉提示更多地关注视觉概念。
Discussion。提示调节通过使用一些可学习的文本/图像提示来修改输入文本/图像,从而实现参数高效的 VLM 传输。它简单易行,几乎不需要额外的网络层或复杂的网络修改。因此,提示调整允许以黑箱方式调整 VLM,这在涉及知识产权问题的 VLM 转移方面具有明显优势。然而,它仍存在一些局限性,如在提示时遵循原始 VLM 的流形,灵活性较低。
6.3.2 Transfer via Feature Adaptation
特征适配可通过附加的轻量级特征适配器对 VLM 进行微调,以适配图像或文本特征 。例如,Clip-Adapter [33] 在 CLIP 的语言和图像编码器之后插入了几个可训练的线性层,并在保持 CLIP 架构和参数不变的情况下对其进行优化,如图 13 所示。Tip Adapter [34] 提出了一种无需训练的适配器,它直接采用少量标记图像的嵌入作为适配器权重。SVL-Adapter [153] 设计了一种自监督适配器,它采用额外的编码器对输入图像进行自监督学习。总之,特征适配器可调整图像和文本特征,使 VLMs 适合下游数据,从而为 VLMs 传输提供了一种可选的提示调整方法。
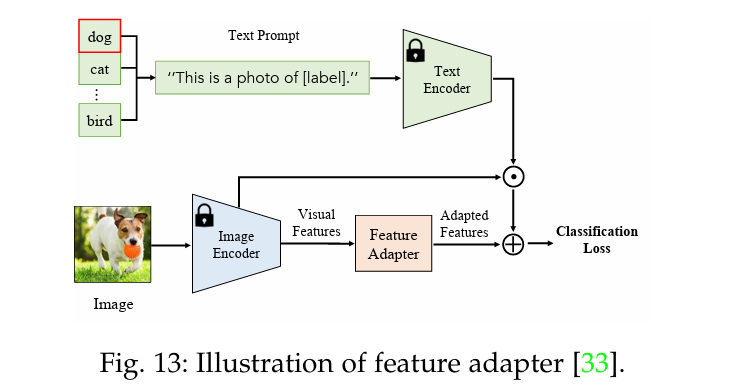
Discussion. 特征适配通过修改图像和文本特征来适配 VLM,并附加一个轻量级的特征适配器。由于其架构和插入方式允许针对不同的下游任务进行灵活定制,因此非常灵活有效。因此,在调整 VLM 以适应非常不同和复杂的下游任务方面,特征适配具有明显的优势。另一方面,它需要修改网络架构,因此无法处理涉及知识产权问题的VLM。
6.3.3 Other Transfer Methods
有几项研究通过直接微调、结构修改和交叉注意等方法转移 VLM。具体来说,Wise-FT[162] 将微调后的 VLM 和原始 VLM 的权重结合起来,以便从下游任务中学习新信息。MaskCLIP [163] 通过修改 CLIP 图像编码器的结构来提取密集图像特征。VT-CLIP [157] 引入了视觉引导注意力,将文本特征与下游图像进行语义关联,从而实现了更好的传输性能。CALIP [158] 引入了无参数关注,实现了视觉和文本特征之间的有效互动和交流,从而产生了文本感知图像特征和视觉引导文本特征。TaskRes [159] 直接调整基于文本的分类器,以利用预训练 VLM 中的旧知识。CuPL [160] 和 VCD [161] 采用大型语言模型(如 GPT3 [172])来增强文本提示,以学习丰富的判别文本信息。
6.4 Summaryand Discussion
总之,提示调节和特征适配器是 VLM 传输的两种主要方法,它们分别通过修改输入文本/图像和适配图像/文本特征来实现。此外,这两种方法都在冻结原始 VLM 的同时引入了非常有限的参数,从而实现了高效传输。此外,虽然大多数研究采用的是少数几次有监督传输,但最近的研究表明,无监督 VLM 传输可以在各种任务中实现有竞争力的性能,从而激发了对无监督 VLM 传输的更多研究。
7 VLM KNOWLEDGE DISTILLATION
由于 VLM 可捕捉到涵盖各种视觉和文本概念的通用知识,因此一些研究探讨了如何在处理复杂的密集预测任务(如物体检测和语义分割)的同时,蒸馏出通用且稳健的 VLM 知识。本节将介绍从 VLM 中蒸馏知识的动机,以及针对语义分割和物体检测任务的两组知识蒸馏研究。
7.1 Motivation of Distilling Knowledge from VLMs
VLM 迁移一般会在迁移过程中保持原有 VLM 架构不变,而 VLM 知识蒸馏则不同,它将通用和稳健的 VLM 知识蒸馏到特定任务模型中,而不受 VLM 架构的限制,在处理各种密集预测任务的同时使特定任务设计受益。例如,通过知识蒸馏,可以将通用 VLM 知识迁移到检测任务中,同时利用最先进的检测架构(如 Faster R-CNN [55] 和 DETR [62])的优势。
7.2 Common Knowledge Distillation Methods
由于 VLM 通常是根据为图像级表示设计的架构和目标预先训练的,因此大多数 VLM 知识蒸馏方法都侧重于将图像级知识转移到区域或像素级任务中,如物体检测和语义分割。表 5 列出了 VLM 知识蒸馏方法。

7.2.1 Knowledge Distillation for Object Detection
开放词汇对象检测旨在检测由任意文本描述的对象,即基类之外的任何类别的对象。由于像 CLIP 这样的 VLM 是通过涵盖非常广泛词汇的十亿尺度图像-文本对进行训练的,因此许多研究都在探索如何提炼 VLM 知识,以扩大检测器的词汇量。例如,ViLD [36] 将 VLM 知识提炼为两阶段检测器,其嵌入空间与 CLIP 图像编码器的嵌入空间保持一致。继 ViLD 之后,HierKD[186]探索了分层的全局-局部知识提炼,RKD[187]探索了基于区域的知识提炼,以更好地调整区域级嵌入和图像级嵌入。ZSD-YOLO [198] 引入了自标签数据增强技术,以利用 CLIP 进行更好的物体检测。 OADP [201] 在传输上下文知识的同时保留了提案特征。BARON [200] 使用邻域采样来提炼区域包,而不是单个区域。RO-ViT [199] 从 VLM 中提炼区域信息,用于开放词汇检测。
另一个研究方向是通过提示学习探索 VLM 蒸馏。例如,DetPro [37] 引入了一种检测提示技术,用于学习开放词汇对象检测的连续提示表征。PromptDet [188] 引入了区域提示学习,用于将单词嵌入与区域图像嵌入对齐。此外,有几项研究探索用 VLM 预测伪标签来改进物体检测器。例如,PB-OVD[189] 使用 VLM 预测的伪边界框训练物体检测器,而 XPM[194] 则引入了一种稳健的跨模态伪标签策略,利用 VLM 生成的伪掩码进行开放词汇实例分割。P3OVD [197] 则利用提示驱动的自我训练,通过细粒度的提示调整来完善 VLM 生成的伪标签。
7.2.2 Knowledge Distillation for Semantic Segmentation
用于开放词汇语义分割的知识蒸馏(Knowledge distillation for open-vocabulary semantic segmentation)利用 VLM 来扩大分割模型的词汇量,目的是分割任意文本描述的像素(即基类之外的任何像素类别)。例如,[35]、[180]、[181] 通过先将像素归类为多个分段,然后用 CLIP 进行分段识别,从而实现开放词汇语义分割。CLIPSeg [175] 引入了一种轻量级变换器解码器,将 CLIP 扩展用于语义分割。LSeg [176] 将 CLIP 文本嵌入与分割模型编码的像素图像嵌入之间的相关性最大化。Zeg-CLIP [174] 采用 CLIP 生成语义掩码,并引入了关系描述符,以减轻对基类的过度拟合。MaskCLIP+ [163] 和 SSIW [177] 利用 VLM 预测的像素级伪标签提炼知识。FreeSeg [185] 首先生成掩码提案,然后对其进行zero-shot分类。
用于弱监督语义分割的知识蒸馏( Knowledge distillation for weakly-supervised semantic segmentation)旨在利用 VLM 和弱超级视觉(如图像级标签)进行语义分割。 例如,CLIP-ES [184] 利用 CLIP 通过设计软最大函数和基于类别感知的注意力亲和模块来完善类别激活图,从而缓解类别混淆问题。CLIMS [183] 利用 CLIP 知识生成高质量的类激活图,以实现更好的弱监督语义分割。
7.3 Summaryand Discussion
总之,大多数 VLM 研究都是在两个密集的视觉识别任务(即物体检测和语义分割)中探索知识蒸馏,前者旨在更好地调整图像级和物体级表征,而后者则侧重于解决图像级和像素级表征之间的不匹配问题。它们还可根据方法进行分类,包括在 VLM 编码器和检测(或分割)编码器之间加强嵌入一致性的特征空间提炼,以及利用 VLM 生成的伪标签对检测或分割模型进行正则化的伪标签提炼。此外,与 VLM 传输相比,VLM 知识蒸馏显然具有更好的灵活性,可允许不同的下游网络,而不受原始 VLM 的影响。
8 PERFORMANCE COMPARISON
在本节中,我们将比较、分析和讨论第 5-7 节中回顾的 VLM 预训练、VLM 转移学习和 VLM 知识提炼方法。
8.1 Performance of VLM Pre-training
如第 3.4 节所述,zero-shot预测作为一种广泛采用的评估设置,可评估 VLM 在未见任务中的泛化能力,而无需针对特定任务进行微调。本小节将介绍zero-shot预测在不同视觉识别任务中的表现,包括图像分类、物体检测和语义分割。
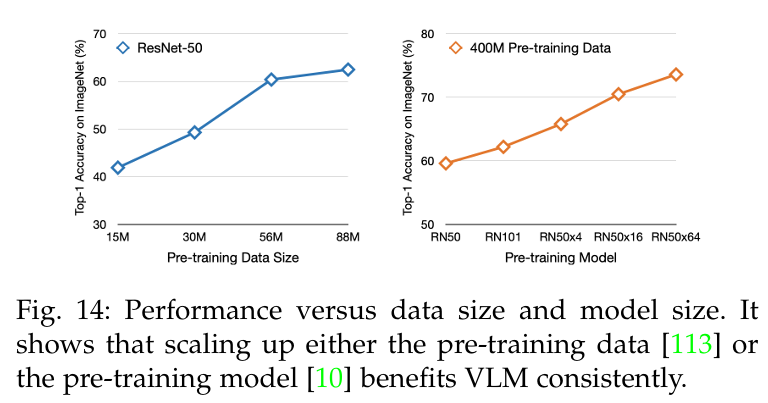
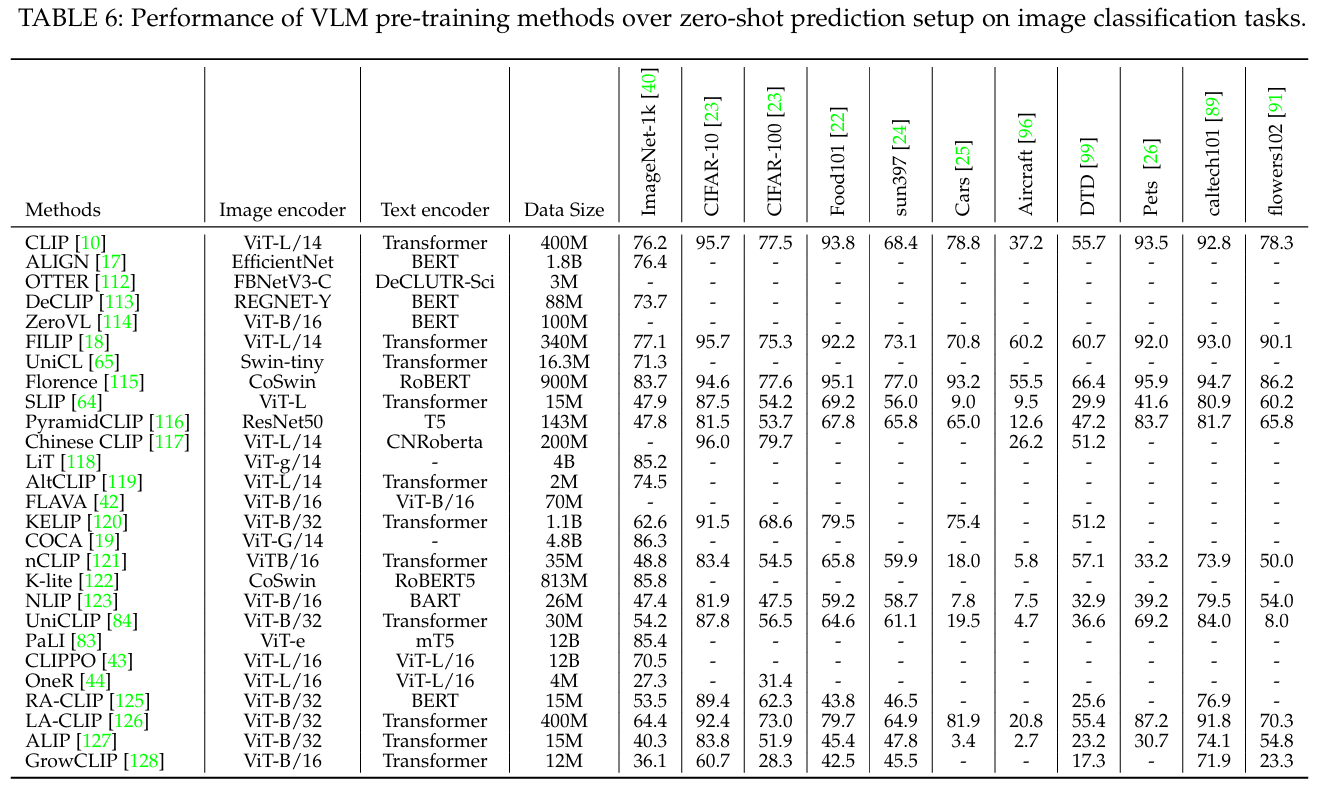
表 6 显示了对 11 项广泛采用的图像分类任务的评估结果。请注意,由于 VLM 预训练通常有不同的实现方式,因此它显示的是 VLM 的最佳性能。从表 6 和图 14 中可以得出三个结论:
- VLM 的性能通常取决于训练数据的大小。如图 14 中的第一张图所示,扩大预训练数据的规模会带来一致的改进;
- VLM 的性能通常取决于模型的大小。如第二张图所示,在相同的预训练数据下,扩大模型规模可以持续提高 VLM 性能;
- 利用大规模图像-文本训练数据,VLM 可以在各种下游任务中实现出色的zero-shot性能。如表 6 所示,COCA[19] 在 ImageNet 上取得了最先进的性能,FILIP[18] 在 11 项任务中表现稳定。
VLMs 优越的泛化能力主要归因于三个因素:
- 大数据–由于互联网上的图像-文本对几乎无穷无尽,VLM 通常使用数百万或数十亿的图像和文本样本进行训练,这些样本涵盖了非常广泛的视觉和语言概念,因此具有很强的泛化能力;
- 大模型–与传统的视觉识别模型相比,VLM 通常采用大得多的模型(如 COCA [19] 中的 ViT-G,参数为 2B),为从大数据中进行有效学习提供了强大的能力;
- 任务无关学习–VLM 预训练中的监督通常是通用的,与任务无关。与传统视觉识别中针对特定任务的标签相比,图像-文本对中的文本提供了与任务无关的、多样化的、信息丰富的语言监督,有助于训练可通用的模型,从而在各种下游任务中都能很好地发挥作用。
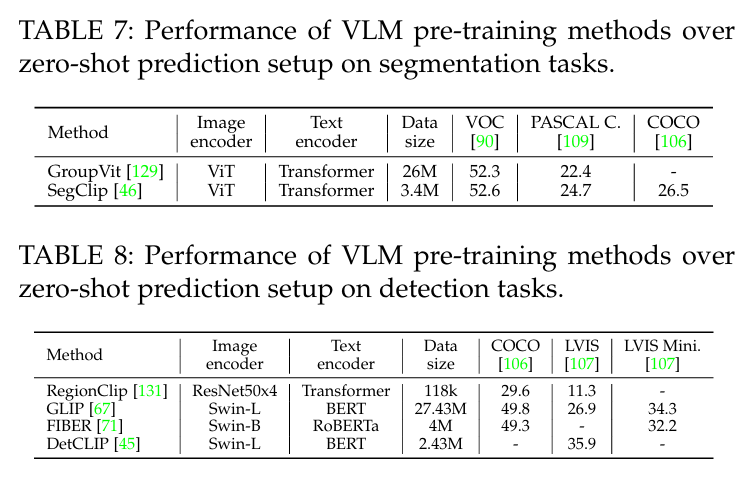
请注意,有几项研究研究了对象检测和语义分割的 VLM 预训练,并提出了局部 VLM 预训练目标,如区域-单词匹配。表 7 和表 8 总结了物体检测和语义分割任务的zero-shot预测性能。我们可以看到,VLM 在这两项密集预测任务中都能实现有效的zero-shot预测。请注意,表 7 和表 8 中的结果可能与前面段落中的结论不一致,这主要是因为这一研究领域尚未得到充分开发,在密集视觉任务中使用的 VLM 非常有限。
“密集视觉任务”(dense visual tasks)通常指的是需要对输入图像中的每个像素或每个区域进行预测或分割的视觉任务。这些任务通常包括语义分割(semantic segmentation)、实例分割(instance segmentation)和图像分割(image segmentation)等,要求模型对图像中的每个像素进行分类或将其分配给相应的类别。密集视觉任务相对于其他视觉任务,需要更加细致和精确的预测。
VLM 的局限性。如上所述,尽管 VLM 在数据/模型规模扩大时受益明显,但仍存在以下几个局限性:
- 当数据/模型规模不断增大时,性能趋于饱和,再扩大规模也不会提高性能;
- 在 VLM 预训练中采用大规模数据需要大量计算资源,例如,在 CLIP ViT-L 中,需要 256 个 V100 GPU,288 个训练小时;
- 采用大型模型会在训练和推理中引入过多的计算和内存开销。
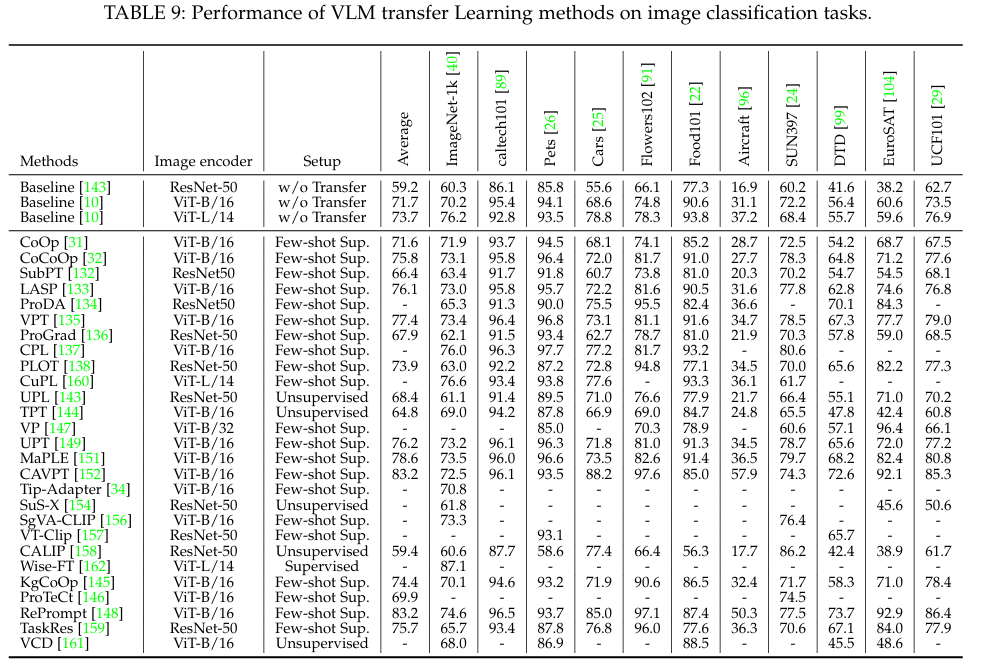
8.2 Performance of VLM Transfer Learning
本节总结了 VLM 迁移在有监督迁移、少量监督迁移和无监督迁移设置下的性能。表 9 显示了在 11 个广泛采用的图像分类数据集(如 EuroSAT、UCF101)上使用不同骨干网(如 CNN 骨干网 ResNet-50、Transformer 骨干网 ViT-B 和 ViT-L)的结果。注,表 9 总结了所有few-shot监督方法的 16 镜头设置性能。
从表 9 中可以得出三个结论。首先,VLM 迁移设置始终有助于下游任务。例如,有监督的 Wise-FT、少量监督的 CoOp 和无监督的 TPT 在 ImageNet 上的准确率分别提高了 10.9%、1.7% 和 0.8%。由于预先训练的 VLM 通常与特定任务数据存在领域差距,因此 VLM 转移可以通过从特定任务数据(有标签或无标签)中学习来缓解领域差距。
其次,少镜头监督迁移的性能远远落后于监督迁移(例如,WiseFT中为 87.1%,CuPL中为 76.6%),这主要是因为 VLMs 可能会过度拟合few-shot标记的样本,并进行分级泛化。
第三,无监督迁移的形式可与少量标记的有监督迁移相媲美(例如,无监督 UPL比 2-shot的有监督 CoOp高 0.4%,无监督 TPT 可与 16-shot的 CoOp相媲美),这主要是因为无监督转移可访问大量未标记的下游数据,过拟合风险低得多。不过,无监督传输也面临着一些挑战,例如伪标签噪声。我们期待着对这一前景广阔但不断变化的研究方向进行更多的研究。
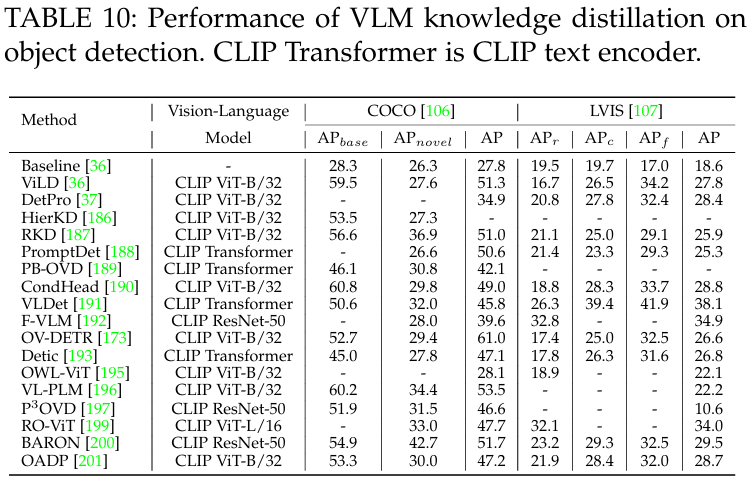
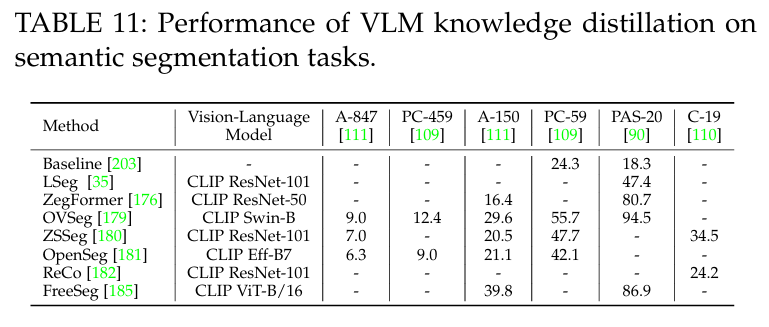
8.3 Performance of VLM Knowledge Distillation
本节将介绍 VLM 知识蒸馏如何帮助完成物体检测和语义分割任务。表 10 和表 11 分别显示了在广泛使用的检测数据集(如 COCO 和 LVIS)和分割数据集(如 PASCAL VOC和 ADE20k)上的知识蒸馏性能。我们可以观察到,VLM 知识蒸馏在检测和分割任务中始终带来明显的性能提升,这主要是因为它引入了通用和稳健的 VLM 知识,同时受益于检测和分割模型中的特定任务设计。
8.4 Summary
从表 6-11 中可以得出一些结论。在性能方面,VLM 预训练由于其精心设计的预训练目标,在广泛的图像分类任务中实现了出色的zero-shot预测。尽管如此,VLM 预训练在高密度视觉识别任务(区域或像素级检测和分割)上的发展仍远远落后。此外,VLM 传输在多个图像分类数据集和视觉骨干上取得了显著进展。然而,有监督或few-shot有监督传输仍然需要标注图像,而更有前景但更具挑战性的无监督 VLM 传输在很大程度上被忽视了。
在benchmark方面,大多数 VLM 转移研究都采用相同的预训练 VLM 作为基准模型,并在相同的下游任务上进行形式评估,这大大方便了基准测试。这些研究还发布了自己的代码,不需要密集的计算资源,大大方便了复制和基准测试。不同的是,VLM 预训练的研究对象包括不同的数据(如 CLIP、LAION400M 和 CC12M)和网络(如 ResNet、ViT、Transformer和 BERT),这使得公平基准测试成为一项极具挑战性的任务。一些 VLM 预训练研究还使用了非公开训练数据,或需要密集的计算资源(如 [10] 中的 256 V100 GPU)。因此,VLM 预训练和 VLM 知识蒸馏在训练数据、网络和下游任务方面都达不到一定的标准。
9 FUTURE DIRECTIONS
VLM 可以有效地利用网络数据,无需对特定任务进行任何微调即可实现 "zero-shot "预处理,并可对任意类别的图像进行开放式词汇视觉识别。它以令人难以置信的视觉识别性能取得了巨大成功。在本节中,我们将与大家分享未来 VLM 在各种视觉识别任务研究中可能面临的几个研究挑战和潜在研究方向。
在 VLM 预训练方面,有以下四个挑战和潜在的研究方向。
- 精细的视觉语言关联建模(Fine-grained vision-language correlation modelling)。有了局部视觉语言对应知识,VLM 可以更好地识别图像之外的patch和像素,从而大大有利于密集预测任务,如在各种视觉识别任务中发挥重要作用的物体检测和语义分割。鉴于这方面的 VLM 研究非常有限我们期待在零镜头密集预测任务的细粒度 VLM 预训练方面开展更多研究。
- 统一视觉和语言学习(Unification of vision and language learning)。Transformer的出现通过以相同的方式标记图像和文本,使得在单个 Transformer 中统一图像和文本学习成为可能。与现有的 VLM中使用两个独立的网络不同,统一视觉和语言学习可实现跨数据模式的高效通信,从而提高训练效果和训练效率。这个问题已经引起了一些关注,但要实现更可持续的 VLM 还需要更多的努力。
- 用多种语言预训练 VLM(Pre-training VLMs with multiple languages)。大多数现有的 VLM 都是用单一语言(如英语)训练的,这可能会带来文化和地区方面的偏差,阻碍 VLM 在其他语言领域的应用。使用多语言文本对 VLM 进行预训练可以学习不同语言下相同词义的不同文化视觉特征,从而使 VLM 能够在不同语言场景下高效工作。 我们期待更多关于多语言 VLM 的研究。
- 数据高效的 VLM(Data-efficient VLMs)。现有的大多数工作都是通过大规模的训练数据和密集的计算来训练 VLM,这使得 VLM 的可持续性成为一个很大的问题。使用有限的图像-文本数据训练有效的 VLM 可以大大缓解这一问题。例如,可以通过图像-文本对之间的监督来学习更多有用信息,而不是仅仅从每个图像-文本对中学习。
- 利用 LLM 预训练 VLM(Pre-training VLMs with LLMs)。最近的研究从 LLMs 中获取丰富的语言知识,以加强 VLM 的预训练。具体来说,他们使用 LLMs 来增强原始图像-文本对中的文本,从而提供更丰富的语言知识,帮助更好地学习视觉-语言相关性。我们期待在未来的研究中对 LLM 在 VLM 预训练中的应用进行更多探索。
对于 VLM 迁移学习,存在以下三个挑战和潜在的研究方向。
- 无监督 VLM 迁移。大多数现有的 VLM 迁移研究都是在有监督或少量监督的情况下进行的,这就需要有标签的数据,而后者往往会过度拟合少量样本。无监督 VLM 迁移允许探索大量无标签数据,过拟合的风险要低得多。在接下来的 VLM 研究中,预计会有更多关于无监督 VLM 迁移的研究。
- 带有视觉提示/适配器的 VLM 迁移。现有的 VLM 迁移研究大多集中于文本提示学习。 视觉提示学习或视觉适配器与文本提示互为补充,可在各种密集预测任务中实现像素级适配,但在很大程度上被忽视。 希望在视觉领域开展更多的 VLM 迁移研究。
- 测试时间 VLM 迁移。现有的大多数研究都是通过在每个下游任务中微调 VLM(即及时学习)来进行转移的,这导致了在面对许多下游任务时的重复性工作。测试时间 VLM 迁移允许在推理过程中即时调整提示,从而避免了现有 VLM 迁移中的重复训练。我们可以预见会有更多关于测试时间 VLM 迁移的研究。
- 利用 LLM 进行 VLM 迁移。与提示设计和提示学习不同,一些尝试利用LLM来生成能更好地描述下游任务的文本提示。这种方法是自动的,几乎不需要标注数据。我们期待在未来的研究中对 VLM迁移中的 LLMs 进行更多探索。
可以从两个方面进一步探索虚拟学习管理的知识蒸馏。首先是多个 VLM 的知识蒸馏,通过协调多个 VLM 的知识蒸馏,可以获得协同效应。其次是针对其他视觉识别任务的知识蒸馏,如实例分割、全景分割、人物再识别等。
10 CONCLUSION
用于视觉识别的视觉语言模型能有效利用网络数据,无需针对具体任务进行微调即可实现零误差预测,其实现简单,但在各种识别任务中取得了巨大成功。本调查报告从背景、基础、数据集、技术方法、基准测试和未来研究方向等几个方面广泛评述了视觉识别的视觉语言模型。以表格形式对视觉语言模型的数据集、方法和性能进行了比较总结,为视觉语言模型预训练的最新发展提供了清晰的全貌,这将极大地有利于未来沿着这一新兴但极具前景的研究方向开展研究。


















 6326
6326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









