






logistic回归这部分相信那些实现代码并不难以理解,难以理解的是为什么可以这样来实现这个算法,它背后的数学支撑究竟是怎样的。关于这个问题,我们将在下文中进行探索。
Logistic本质上是一个基于条件概率的判别模型(Discriminative Model)。利用了Sigmoid函数值域在[0,1]这个特性。

使用Sigmoid进行二分类操作时,当函数值大于0.5,我们将对应的样本数据划分到1类;否则将对应样本数据划分到0类(这里的1类和0类是要和数据集中类别标签相对应的)。
由于实际的使用需求,我们现在将该函数扩展到多维空间(毕竟只有一个特征值的情况是在是太少了),并且加上相应的参数。则扩展后的Sigmoid函数如下:

其中z是变量,θ是参数,由于是多维,所以写成了向量的形式,也可以看作矩阵。θT表示矩阵θ的转置,即行向量变成列向量。θTZ是矩阵乘法。
我们在进行算法训练的时候思路是这样的:数据集中有一系列的样本特征和类别标签(二分类时我们将其设置为0和1),我们通过不断的输入这些样本数据来调节2式中的θ向量(该向量的维度与数据的特征数量相同),从而尽可能地使得数据样本都可以划分到正确的分类。
在使用Sigmoid函数时,设:

上面两个公式表达了已知z和θ的情况下,样本的分类概率。可以将它们做如下的合并:
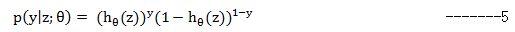
这样计算概率的公式就确定了,下面需要用到最大似然估计来为我们提供相应的服务。最大似然估计的基本思想是:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。
假定样本与样本之间相互独立,那么整个样本集生成的概率即为所有样本生成概率的乘积:
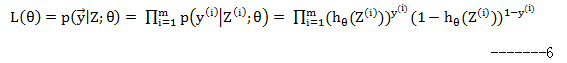
其中,m为样本的总数,y(i)表示第i个样本的类别,z(i)表示第i个样本特征值的情况,需要注意的是θ是多维向量,z(i)也是多维向量。
在解最大似然方程时,最常用的手段就是取对数,得到下式:
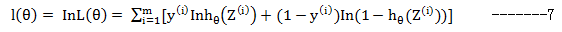
根据前的分析,我们要使得样本观测值的概率最大,即要求得L(θ)的最大值,而L(θ)与l(θ)在同一地方取得最大值,所以后面我们需要分析l(θ)到底在何处取得这个最值。
我们下面就针对第i个样本来进行推理,看看它的θ参数应该是怎样的。
我们知道在只有单一未知元的时候可以通过求导来分析函数的最值;而在有多个未知参数(多维向量)时我们需要通过求偏导来达到同样的目的。我们用l(θ)对θ的第j维求偏导,如下:

其中l(θ)(i)表示在l(θ)中我们只考虑m为i时的情况;Z(i)表示第i个样本的特征情况,θj表示参数θ的第j维。
我们从右往左一个个来计算这些偏导,首先第一个:
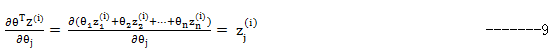
其中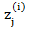
第二个,由于:
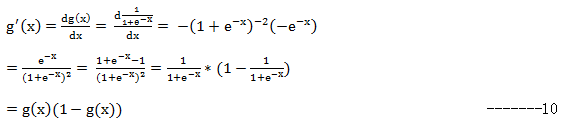
即有:

在解第三个时,注意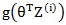
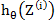
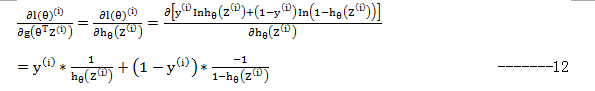
最后结合这三个部分的计算结果:
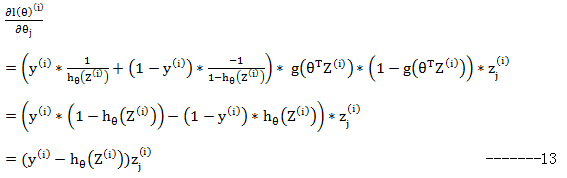
这就是参数θ中某一维的梯度更新方向。有了这个结论,再回头看Logistic回归就部分就很容易理解了。















 1755
1755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









