






原文:Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks
作者: Nils Reimers and Iryna Gurevych Ubiquitous Knowledge Processing Lab (UKP-TUDA) Department of Computer Science, Technische Universita¨t Darmstadt http://www.ukp.tu-darmstadt.de
一、简介
Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks 使用连体BERT网络的句子嵌入
- Sentence BERT,简称SBERT;与传统的BERT模型不同,SBERT并不是基于单词级别的,而是基于句子级别进行训练。
- 具体来说,它首先通过对两个句子进行拼接,形成一个输入文本序列,然后训练一个变换网络,将该文本序列映射为一个固定长度的向量。
Input sentence 1 ------------+ | Input sentence 2 ------------+---Concatenate-----Transformer-----Pooling---Embedding Vector #Concatenate操作将两个句子拼接到一起; #Transformer模块对拼接后的文本序列进行变换; #Pooling模块对变换后的序列进行池化操作,以获取文本序列的整体特征; #最终,Embedding Vector表示转换后的向量表示。
1.背景介绍
BERT(Devlin 等人,2018 年)和 RoBERT a(Liu 等人,2019 年)在句对回归任务,如语义文本相似性(STS))上设置了一个新的最先进的性能。
然而,它需要将两个句子都输入网络,这会导致巨大的计算开销:在 10,000 个句子的集合中找到最相似的对需要使用 BERT 进行大约 5000 万次推理计算(约 65 小时)。 BERT 不适用于语义相似性搜索以及聚类等无监督任务。
- SBERT:孪生网络和三元组网络结构来导出具有语义意义的句子嵌入,可以使用余弦相似度进行比较。工作量从使用 BERT / RoBERTa 的 65 小时----SBERT 的 5 秒。
- 新任务:大规模语义相似性比较、聚类和通过语义搜索进行信息检索。
- BERT:交叉编码器;不适用于各种对回归任务。
首先,解决聚类和语义搜索的一种常用方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。
将单个句子输入 BERT 并导出固定大小的句子嵌入,方法:平均 BERT 输出层(称为 BERT 嵌入)或使用第一个token([CLS] token)的输出;糟糕的句子嵌入。
因此为了缓解这个问题,我们开发了 SBERT。孪生网络架构使得可以导出输入句子的固定大小的向量。
2.细节工作
BERT (Devlin et al., 2018) 是一个预训练的 transformer 网络 (Vaswani et al., 2017),它为各种 NLP 任务设定了新的最先进的结果,包括问答、句子分类和句子-对回归。
很大的缺点是没有计算独立的句子嵌入,这使得很难从 BERT 中推导出句子嵌入。
InferSent 始终优于 SkipThought 等无监督方法。训练句子嵌入的任务会显着影响它们的质量
发现 SNLI 数据集适合训练句子嵌入;使用 siamese DAN 和 siamese transformer 网络训练 Reddit 对话的方法,该方法在 STS 基准数据集上取得了良好的效果。
humeau解决了来自 BERT 的交叉编码器的运行时开销,并提出了一种方法(多编码器)来计算 m 个上下文向量和使用注意力的预计算候选嵌入之间的分数。这个想法适用于在更大的集合中找到得分最高的句子。然而,多编码器的缺点是得分函数不对称,并且计算开销对于像聚类这样的用例来说太大,这需要 O(n2) 得分计算。
SBERT 模型
在输出中添加了池化运算,以导出固定大小的句子嵌入。
试验了三种池化策略:
- 使用 CLS-token 的输出;
- 计算所有输出向量的平均值(MEAN 策略)默认;
- 以及计算输出向量的最大随时间推移(MAX 策略)。
创建了连体网络和三重网络,更新权重,使生成的句子嵌入在语义上有意义,并且可以与余弦相似度进行比较。将句子嵌入 u 和 v 与元素差异 |u - v| 连接起来并将其乘以可训练权重。
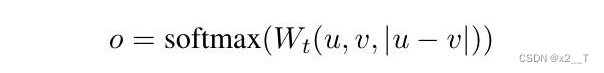
![]()
n 是句子嵌入的维度,k 是标签的数量
优化交叉熵损失:
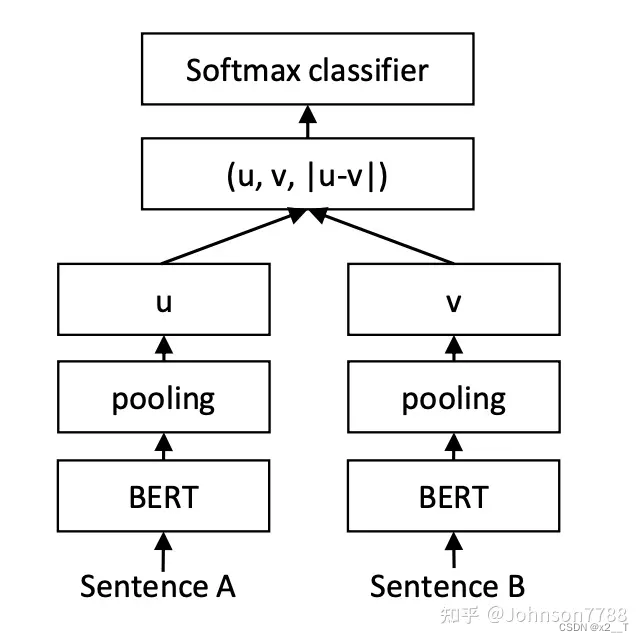
图 1:具有分类目标函数的 SBERT 架构,例如,用于对 SNLI 数据集进行微调。两个 BERT 网络具有绑定的权重(siamese 网络结构)。
回归目标函数。
计算两个句子嵌入 u 和 v 之间的余弦相似度(图 2)我们使用均方误差损失作为目标函数。
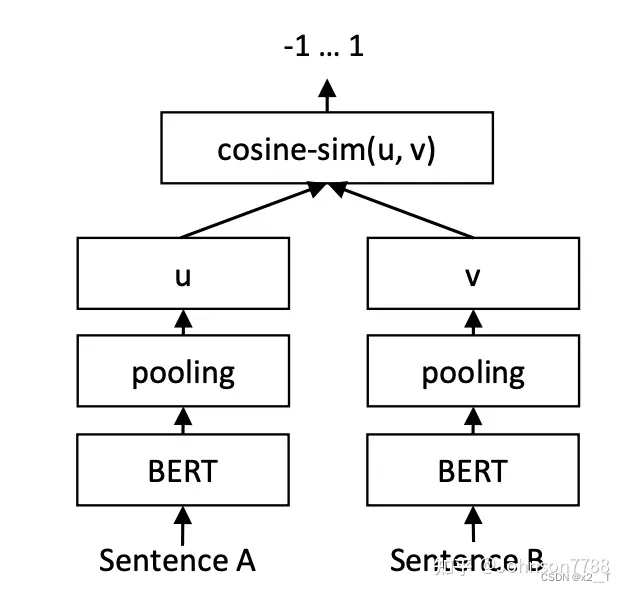
三元组目标函数。
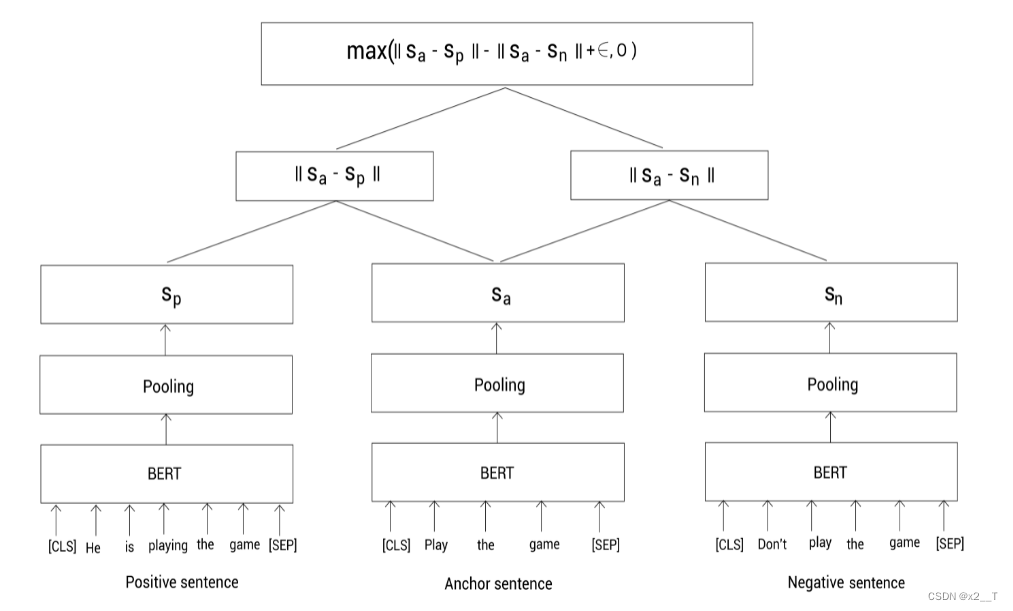
给定一个锚句 a、一个正样本 p 和一个负样本 n,triplet loss 调整网络,使 a 和 p 之间的距离小于 a 和 n 之间的距离。在数学上,我们最小化以下损失函数
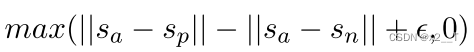 || · ||距离度量和边距ε。
|| · ||距离度量和边距ε。
带有三重态网络的SBERT
假设我们有三个句子,一个Anchor句子,一个正(positive)样本和一个负(negative)样本句子:
Anchor句子: Play the game
Positive 句子: He is playing the game
Negative 句子: Don’t play the game原文链接:https://blog.csdn.net/yjw123456/article/details/120464742
我们的任务是一个表示让Anchor句子和正样本句子之间的相似度很高,同时Anchor句子和负样本之间的相似度很低。因为我们有三个句子,此时,SBERT使用三重态网络架构。
首先,还是对句子进行预处理,然后喂给三个BERT模型,并通过池化得到每个句子的表示:
![]()
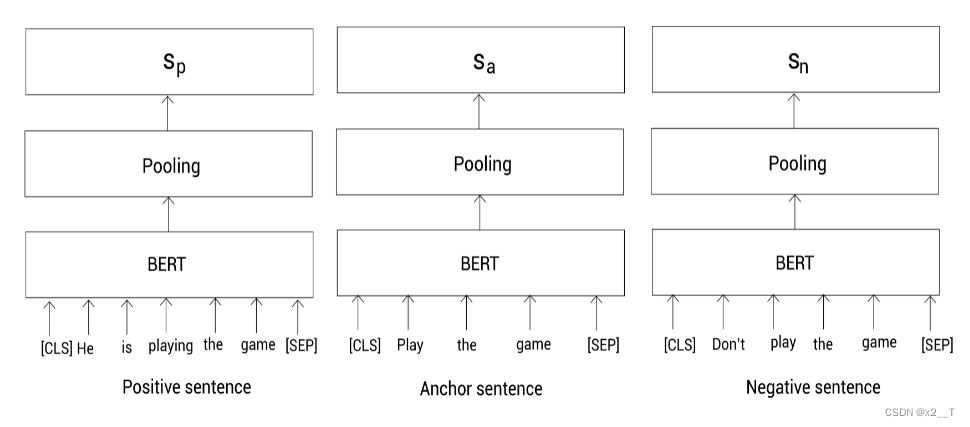
我们分别输入anchor,positive,negative句子到BERT模型,并通过池化得到句向量。然后,训练模型去最小化三重态损失函数。最小化该损失函数确保anchor和positive的相似度要大于和negative的相似度。
SBERT的作者发布了他们预训练的SBERT模型。所有预训练的模型可以在这里找到: https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/
我们可以返现这些预训练的模型以bert-base-nli-cls-token,bert-base-nli-mean-token,roberta-base-nli-max-tokens,distilbert-base-nli-mean-tokens这样的方式命名。
- bert-base-nli-cls-token 是以预训练BERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用[CLS]标记的输出作为句子表示
- bert-base-nli-mean-token是以预训练BERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示
- roberta-base-nli-max-tokens 是以预训练RoBERTa-base模型在NLI数据集进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示
- distilbert-base-nli-mean-tokens是以预训练DistilBERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示
这样,我们说预训练的SBERT模型,其实基本就是说我们有一个预训练的BERT模型然后使用孪生/三重态网络架构微调它。
训练
SNLI 是一个包含 570,000 个句子对的集合,这些句子对带有 contradiction、entailment 和 neutral 标签标注。
MultiNLI 包含 430,000 个句子对,涵盖各种口头和书面文本类型。
1.评估 SBERT 在常见语义文本相似性 (STS) 任务中的性能
2.(AFS) 语料库上评估 SBERT
AFS 语料库标注了来自社交媒体对话的 6,000 个句子参数对,涉及三个有争议的主题:枪支管制、同性婚姻和死刑。数据按从 0(“不同主题”)到 5(“完全等同”)的等级进行标注。
3.评估 - SentEval
在以下七个 SentEval 传输任务上将 SBERT 句子嵌入与其他句子嵌入方法进行了比较:
• MR:电影评论片段的情感预测,基于五个起始量表(Pang 和 Lee,2005 年)。
• CR:客户产品评论的情感预测(胡和刘,2004 年)。
• SUBJ:电影评论和情节摘要中句子的主观性预测(Pang 和 Lee,2004 年)。
• MPQA:来自新闻专线的短语级意见倾向分类(Wiebe 等人,2005 年)。
• SST:带有二分类标签的斯坦福情感树库(Socher 等人,2013 年)。
• TREC:来自 TREC 的细粒度问题类型分类(Li 和 Roth,2002 年)。
• MRPC:来自平行新闻来源的 Microsoft Research Paraphrase Corpus (Dolan et al., 2004)。
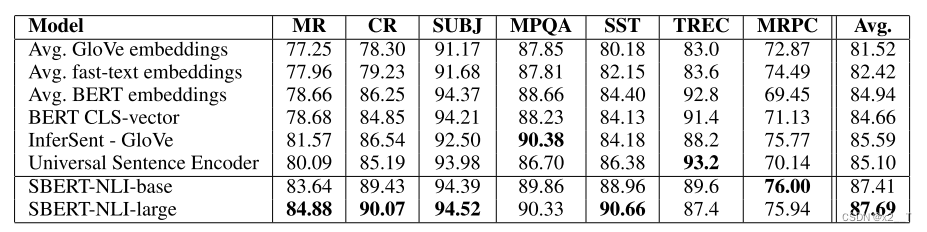
SBERT 的句子嵌入似乎很好地捕获了情感信息:与 InferSent 和 Universal Sentence Encoder 相比,我们观察到 SentEval 的所有情感任务(MR、CR 和 SST)都有很大改进。
无监督STS
监督STS
消融研究
评估了不同的合并策略(MEAN、MAX 和 CLS)。
使用 10 个不同的随机种子训练 SBERT,并对性能进行平均。
对于分类目标函数,我们在 SNLI 和 Multi-NLI 数据集上训练 SBERT base。对于回归目标函数,我们在 STS 基准数据集的训练集上进行训练。性能是根据 STS 基准数据集的开发拆分来衡量的。
计算效率
我们将 SBERT 与平均 GloVe 嵌入、InferSent(Conneau 等人,2017 年)和通用句子编码器(Cer 等人,2018 年)进行比较。
3.实战
pip install sentence-transformers3.1使用SBERT进行句子相似度计算
from sentence_transformers import SentenceTransformer, util
# 加载预训练模型
model = SentenceTransformer('distilbert-base-nli-stsb-mean-tokens')
# 输入句子
sentences = ['I love programming.', 'Programming is my passion.']
# 获取句子表示
sentence_embeddings = model.encode(sentences)
# 计算句子相似度
cosine_scores = util.pytorch_cos_sim(sentence_embeddings[0], sentence_embeddings[1])
print("Sentence 1:", sentences[0])
print("Sentence 2:", sentences[1])
print("Similarity score:", cosine_scores.item())刚开始还跑不出来,好像是没导包,或者包导错了地方,transform
Sentence 1: I love programming.
Sentence 2: Programming is my passion.
Similarity score: 0.8255198001861572
输出结果如下
Sentence 1: I love programming.
Sentence 2: Programming is my passion.
Similarity score: 0.82772731733322143.2使用SBERT进行情感分析
from sentence_transformers import SentenceTransformer
import torch.nn as nn
# 加载预训练模型
model = SentenceTransformer('distilbert-base-nli-stsb-mean-tokens')
# 构建情感分析分类器
classifier = nn.Linear(768, 1)
loss_function = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
# 训练分类器
# ...
# 预测情感
sentence = 'I hate Mondays.'
sentence_embedding = model.encode(sentence)
output = classifier(torch.tensor(sentence_embedding))
predicted_label = 1 if output > 0.5 else 0
print("Sentence:", sentence)
print("Predicted label:", predicted_label)输出结果如下:
Sentence: I hate Mondays.
Predicted label: 13.3使用SBERT进行命名实体识别
from sentence_transformers import SentenceTransformer
# 加载预训练模型
model = SentenceTransformer('distilbert-base-nli-stsb-mean-tokens')
# 输入句子
sentences = ['John works at Google.', 'Mike is a data scientist at Amazon.']
# 获取句子表示
sentence_embeddings = model.encode(sentences)
# 命名实体识别
for i, sentence in enumerate(sentences):
for j, token in enumerate(sentence.split()):
if token in ['Google', 'Amazon']:
print("Entity detected in sentence", i+1, "at index", j, ":", token)输出结果如下:
Entity detected in sentence 1 at index 3 : Google
Entity detected in sentence 2 at index 5 : Amazon4.总结
需要进行大型的下游任务,而不是对比简单的句子。
ps:后面会继续更新的















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









