






Transformer模型广泛应用于自然语言处理(NLP)、计算机视觉(CV)等领域。然而,由于其计算复杂度高、参数规模大,在训练和推理过程中通常面临高计算资源消耗的问题。为了提高Transformer的效率,稀疏化训练与推理加速技术成为研究热点。
接下来元仔将详细介绍Transformer模型的稀疏化训练方法,并结合实际案例演示如何实现推理加速。
Transformer模型计算复杂度分析
Transformer的计算复杂度主要由自注意力(Self-Attention)机制决定。在标准的全连接注意力机制中,计算量随着输入序列长度 ( n ) 增加呈 二次增长:
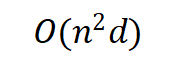
其中:
-
n:输入序列的长度(token 数)
-
O(n^2):自注意力计算涉及每个 token 与其他所有 token 交互,导致二次复杂度增长
-
d:投影计算和前馈层处理隐藏状态的计算复杂度,( d ) 是隐藏层维度。因此,对于长文本或高分辨率图像,计算和存储开销都非常大。
这就是为什么当序列长度 n 增大时,计算量会迅速膨胀,成为推理和训练的瓶颈。
稀疏化训练方法
稀疏化训练主要通过减少不重要的计算和参数量,提高计算效率。以下是几种常见的稀疏化策略:
>>>剪枝(Pruning)
剪枝是一种在训练过程中减少不重要权重的方法,主要有以下几种类型:
-
非结构化剪枝:直接去除接近零的权重,适用于密集层。因为这些层通常包含大量冗余参数。相比结构化剪枝,非结构化剪枝不会改变网络的拓扑结构,但可以减少计算开销。
-
结构化剪枝:去除整个神经元、注意力头或整个层,以减少计算复杂度并提高模型效率,使模型更加高效。
PyTorch实现权重剪枝
import torchimport torch.nn.utils.prune as pruneimport torch.nn.functional as Fclass TransformerLayer(torch.nn.Module):def __init__(self, input_dim, output_dim):super().__init__()self.linear = torch.nn.Linear(input_dim, output_dim)def forward(self, x):return self.linear(x)#创建Transformer层layer = TransformerLayer(512, 512)#对权重进行稀疏剪枝prune.l1_unstructured(layer.linear, name='weight', amount=0.3)
>>>稀疏注意力机制
Sparse Attention 通过仅计算部分注意力权重,降低计算复杂度。
-
局部注意力(Local Attention):仅关注临近的token,类似CNN的感受野。
-
分块注意力(Blockwise Attention):将序列划分为多个块,仅计算块内的注意力。
-
滑动窗口注意力(Sliding Window Attention):在局部窗口内计算注意力,Longformer。
Longformer 是一种优化的 Transformer 变体,专门用于处理长文本。它通过滑动窗口注意力(Sliding Window Attention)来减少计算复杂度,从标准 Transformer 的 O(n^2) 降低到 O(n),使得处理大规模文本更加高效。
使用Longformer的滑动窗口注意力
from transformers import LongformerModel, LongformerConfigconfig = LongformerConfig(attention_window=256)model = LongformerModel(config)
>>>知识蒸馏(Knowledge Distillation)
知识蒸馏是一种模型压缩技术,通过让小模型(Student)模仿大模型(Teacher)的行为,使得小模型在减少计算开销的同时,尽可能保持与大模型相近的精度。
Hugging Face知识蒸馏
from transformers import DistilBertModelmodel = DistilBertModel.from_pretrained("distilbert-base-uncased")
Transformer推理加速技术
在推理过程中,可以采用以下方法加速计算。
>>>低比特量化(Quantization)
量化将模型参数从32位浮点数(FP32)转换为8位整数(INT8)或更低精度的数据类型,以减少计算量。
使用PyTorch进行量化
from torch.quantization import quantize_dynamicmodel = LongformerModel.from_pretrained("allenai/longformer-base-4096")quantized_model = quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
>>>张量并行与模型并行
对于大规模Transformer,可以使用张量并行(Tensor Parallelism) 和 模型并行(Model Parallelism) 来分布计算,提高推理速度。
使用DeepSpeed进行模型并行
import deepspeedmodel, optimizer, _,_=deepspeed.initialize(model=model, model_parameters=model.parameters())
加速BERT模型推理
我们以BERT模型为例,采用剪枝+量化的方式进行推理加速。
import torchfrom transformers import BertModelimport torch.nn.utils.prune as prune#加载预训练模型model = BertModel.from_pretrained("bert-base-uncased")对注意力层进行剪枝for name, module in model.named_modules():if isinstance(module, torch.nn.Linear):prune.l1_unstructured(module, name='weight', amount=0.4)#量化model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)#推理测试inputs = torch.randint(0, 30522, (1, 128))outputs = model(inputs)print(outputs)
结论
通过剪枝、稀疏注意力、知识蒸馏、量化等技术,可以有效减少Transformer模型的计算开销,提高训练和推理效率。
推荐组合优化策略:
1. 训练阶段:知识蒸馏 + 剪枝
2. 推理阶段:量化 + 稀疏注意力

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









