








欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
“机器学习方法“系列,我本着开放与共享(open and share)的精神撰写,目的是让更多的人了解机器学习的概念,理解其原理,学会应用。希望与志同道合的朋友一起交流,我刚刚设立了了一个技术交流QQ群:433250724,欢迎对算法、技术、应用感兴趣的同学加入,在交流中拉通——算法与技术,让理论研究与实际应用深度融合;也希望能有大牛能来,为大家解惑授业,福泽大众。推广开放与共享的精神。如果人多我就组织一些读书会,线下交流。
本节的内容需要依赖上一节已经讲了的机器学习:概念到理解(一):线性回归,线性回归的模型是这样的,对于一个样本
xi
,它的输出值是其特征的线性组合:
其中, w0 称为截距,或者bias,上式中通过增加 xi0=1 把 w0 也吸收到向量表达中了,简化了形式,因此实际上 xi 有 p+1 维度。
线性回归的目标是用预测结果尽可能地拟合目标label,用最常见的Least square作为loss function:
可以直接求出最优解:
看起来似乎很简单,但是在实际使用的过程中会有不少问题,其中一个主要问题就是上面的协方差矩阵不可逆时,目标函数最小化导数为零时方程有无穷解,没办法求出最优解。尤其在 p>n 时,必然存在这样的问题,这个时候也存在overfitting的问题。这个时候需要对 w 做一些限制,使得它的最优解空间变小,也就是所谓的regularization,正则。
ridge regression
最为常见的就是对
有解析解:
其中
λ>0
是一个参数,有了正则项以后解就有了很好的性质,首先是对
w
的模做约束,使得它的数值会比较小,很大程度上减轻了overfitting的问题;其次是上面求逆部分肯定可以解,在实际使用中ridge regression的作用很大,通过调节参数
实际上ridge regression可以用下面的优化目标形式表达:
也就是说,我依然优化线性回归的目标,但是条件是 w 的模长不能超过限制
稀疏约束,Lasso
先看一下几种范式(norm)的定义,
如前面的ridge regression,对 w 做2范式约束,就是把解约束在一个
稀疏约束最直观的形式应该是约束0范式,如上面的范式介绍,
w
的0范式是求
有趣的是,
l1
-norm(1范式)也可以达到稀疏的效果,是0范式的最优凸近似,借用一张图[1]:

很重要的是1范式容易求解,并且是凸的,所以几乎看得到稀疏约束的地方都是用的1范式。
回到本文对于线性回归的讨论,就引出了Lasso(least absolute shrinkage and selection operator) 的问题:
也就是说约束在一个 l1 -ball里面。ridge和lasso的效果见下图:
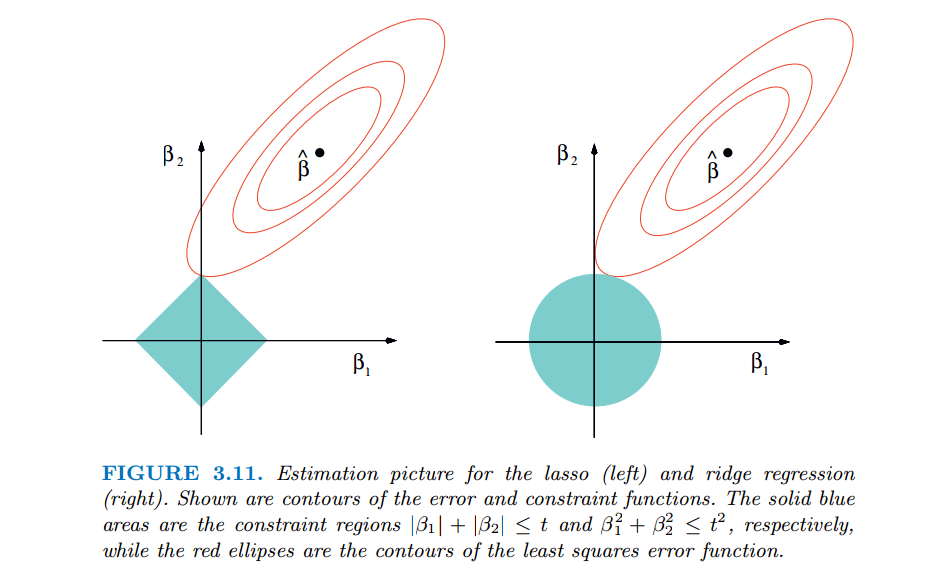
红色的椭圆和蓝色的区域的切点就是目标函数的最优解,我们可以看到,如果是圆,则很容易切到圆周的任意一点,但是很难切到坐标轴上,因此没有稀疏;但是如果是菱形或者多边形,则很容易切到坐标轴上,因此很容易产生稀疏的结果。这也说明了为什么1范式会是稀疏的。
Lasso稀疏性的进一步理解:
类似Ridge,我们也可以写出Lasso的优化目标函数:
根据一般的思路,我们希望对 JL(w) 求导数=0求出最优解,即 ▽JL(w)=0 ,但是 l1 -norm在0点是连续不可导的,没有gradient,这个时候需要subgradient:
定义1:记
f:U→R
是一个定义在欧式空间凸集
Rn
上的实凸函数,在该空间中的一个向量
v
称为
其中 ⋅ 是向量的点积。由在点 x0 处的所有subgradient所组成的集合称为 x0 处的subdifferential,记为 ∂f(x0) 。注意subgradient和subdifferential只是对凸函数定义的。例如一维的情况, f(x)=|x| ,在 x=0 处的 subdifferential就是 [−1,1] 这个区间(集合)。又例如下图中,在 x0 点不同红线的斜率就是表示subgradient的大小,有无穷多。
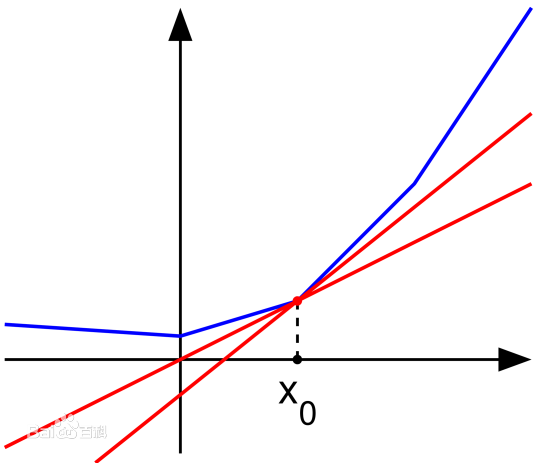
图 subgradient
注意在 x 的gradient存在的点,subdifferential 将是由gradient构成的一个单点集合。这样就将 gradient 的概念加以推广了。这个推广有一个很好的性质(condition for global minimizer)。以下部分参考了[3],是浙大毕业去MIT的一个牛人的博客,看了以后自己再照着重写了一遍。
性质1:点
很容易理解,看上面的图,在 x0 点不是全局最小值,因为subgradient不包含0,而原点0就是全局最小值。如果要证明也很显然,将 0∈∂f(x0) 带入前面的定义1中,就得到 f(x)≥f(x0) 。
为了方便说明,需要做一个简化假设,即数据
X
的列向量是orthonormal的[2,3],即
假设lasso问题 JL(w) 的全局最优解是 w¯∈Rn ,考察它的任意一个维度 w¯j ,需要分别讨论两种情况:
情况1:gradient存在的区间,即
w¯j≠0
由于gradient在最小值点=0,所以
所以
其中
λ≥0
。所以
很容易看出,
w¯j和w∗j
是同号的,因此可以得出
最后得到
其中
(x)+
表示取
x
的正数部分;
情况2:gradient不存在,即
w¯j=0
根据前面的性质1,如果
w¯j
是最小值,则
其中 e 是一个向量,每一个元素 ej∈[−1,1] ,使得 0=−w∗j+λ⋅ej 成立。因此
所以和情况(1)和(2)可以合并在一起。所以呢,如果在这种特殊的orthonormal情况下,我们可以直接写出Lasso的最优解:
OK,再回顾一下前面的ridge regression,如果也考虑上面说的orthonormal情况下,可以很容易得出最优解为
很容易得出结论,ridge实际上就是做了一个放缩,而lasso实际是做了一个soft thresholding,把很多权重项置0了,所以就得到了稀疏的结果!
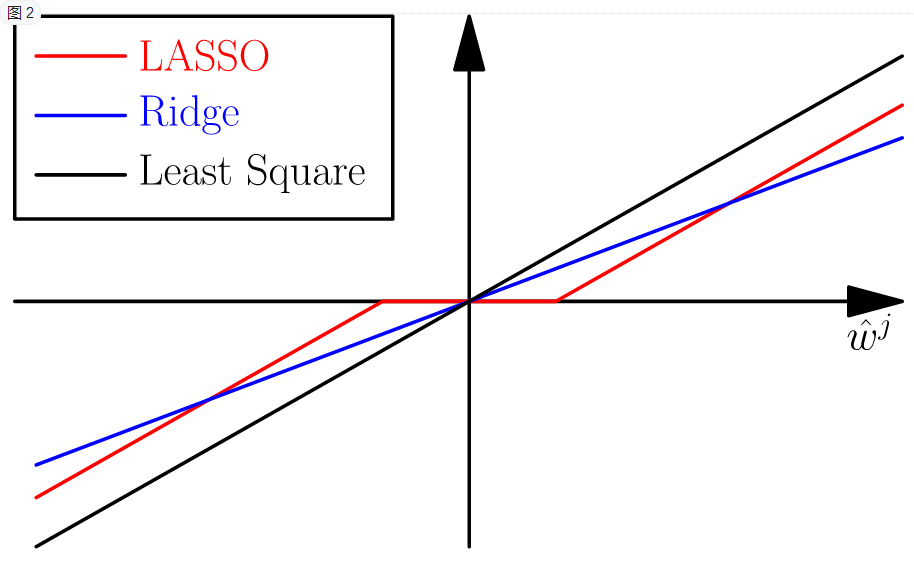
除了做回归,Lasso的稀疏结果天然可以做机器学习中的另外一件事——特征选择feature selection,把非零的系数对应的维度选出即可,达到对问题的精简、去噪,以及减轻overfitting。
上面是做了简化后的讨论,实际中lasso求解还要复杂的多。在下一篇文章中,将描述和Lasso非常相关的两种方法,forward stagewise selection和最小角回归least angle regression(LARS),它们三者产生的结果非常接近(几乎差不多),并且都是稀疏的,都可以做feature selection。有的时候就用Lars来作为Lasso的目标的解也是可以的。
参考资料
[1] http://blog.csdn.net/zouxy09/article/details/24971995
[2] The elements of statistical learning, ch3
[3] http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/
[4] http://en.wikipedia.org/w/index.php?title=Subderivative&redirect=no#The_subgradient

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









