







 本文介绍了扩散模型如何通过马尔可夫链原理工作,包括扩散阶段(向原始数据添加噪声)和逆扩散阶段(从噪声图像恢复原数据)。模型在训练和使用时分别学习和预测噪声,利用高斯噪声大小的控制来实现图像去噪。
本文介绍了扩散模型如何通过马尔可夫链原理工作,包括扩散阶段(向原始数据添加噪声)和逆扩散阶段(从噪声图像恢复原数据)。模型在训练和使用时分别学习和预测噪声,利用高斯噪声大小的控制来实现图像去噪。
扩散模型:可以视为马尔可夫链,因为每一时刻的图像都是在上一时刻的基础上来实现的,其主要分为两个步骤:
- 扩散阶段:即逐渐向原始数据添加噪声
- 逆扩散阶段:从所添加噪声的最后一张噪声图像中恢复原图像。
模型在训练阶段,是不断地往原始图像中添加噪声,在该阶段网络模型需要将添加的噪声进行学习;在使用阶段,从随机的噪声图像中恢复原始数据。该阶段的网络模型需要预测,我的随机噪声的图像到底是什么噪声,然后逐步移除噪声,直到还原。
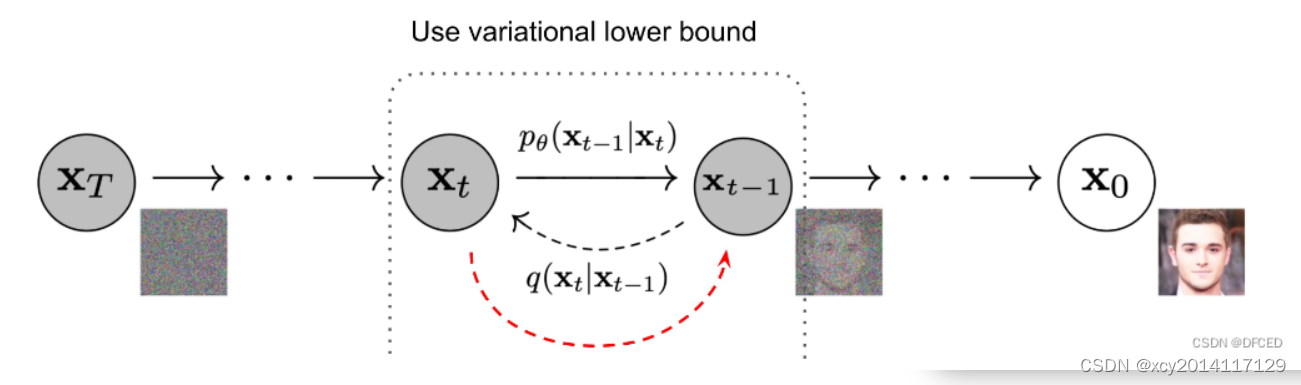
如图所示,前向过程(q过程)就是给定真实图像样本x0,通过T次累加对其添加高斯噪声,得到x1,x2,…xT。其每一步的所添加的高斯噪声的大小都是由一系列高斯分布方差的超参数βT来控制的。因为前向过程的每个时刻t只和t-1时刻有关,所以也可以看作马尔可夫过程。
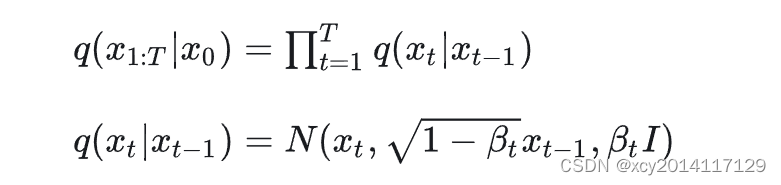
其中不同t的βt是预先定义好的,由时间1~T逐渐增加,满足β1<β2<βT,而重参数αt=1-βt,只会越来越小。这里可以理解因为xT已经是纯噪声图片了,所以添加的噪声会越来越大βt也就越来越大,原始数据占的比例就会越来越小。



反向推导过程由XT推导出来原始数据X0。参考https://blog.csdn.net/m0_63642362/article/details/127586200和https://blog.csdn.net/DFCED/article/details/132394895



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









