







1.1 Probabilistic interpretation
why might the least-squares cost function J, be a reasonable choice?
Let us assume that the target variables and the inputs are related via the equation :
y(i)=θTx(i)+ϵ(i)
ϵ(i) is an error term that captures either unmodeled effects or random noise.
Let us further assume that the ϵ(i) are distributed IID (independently and identically distributed) .
ϵ(i)∼N(0,σ2)
p(ϵ(i))=12π−−√σexp(−(ϵ(i))2σ2)
p(y(i)|x(i);θ)=12π−−√σexp(−(y(i)−θTx(i))2σ2)
likelihood function:
L(θ)=L(θ;X,Y)=p(Y|X,θ)
=∏i=1mp(y(i)|x(i);θ)
=∏i=1m12π−−√σexp(−(y(i)−θTx(i))2σ2)
maximize the log likelihood
l(θ)=logL(θ)
=log∏i=1m12π−−√σexp(−(y(i)−θTx(i))2σ2)
=∑i=1mlog12π−−√σexp(−(y(i)−θTx(i))2σ2)
=mlog12π−−√σ−121σ2∑i=1m(y(i)−θTx(i))2
Hence, maximizing l(θ) gives the same answer as minimizing 12∑mi=1(y(i)−θTx(i))2
summarize: Under the previous probabilistic assumptions on the data, least-squares regression corresponds to finding the maximum likelihood estimate of θ.
1.2 Locally weighted linear regression
The leftmost figure below shows the result of fitting a y=θ0+θ1x to a dataset. We see that the data doesn’t really lie on straight line, and so the fit is not very good.
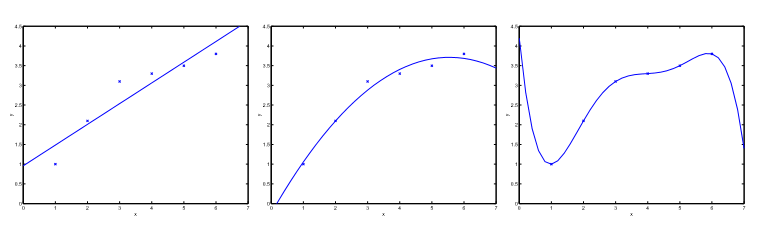
Instead, if we had added an extra feature x2 , and fit y=θ0+θ1x1+θ2x2 , then we obtain a slightly better fit to the data. (See middle figure)
it might seem that the more features we add, the better. However, there is also a danger in adding too many features: The rightmost figure is the result of fitting a 5-th order polynomial y=∑5j=0θjxj we’ll say the figure on the left shows an instance of underfitting—in which the data clearly shows structure not captured by the model—and the figure on the right is an example of overfitting.
As discussed previously, and as shown in the example above, the choice of features is important to ensuring good performance of a learning algorithm. (When we talk about model selection, we’ll also see algorithms for automatically choosing a good set of features.) In this section, let us talk briefly talk about the locally weighted linear regression (LWR) algorithm which, assuming there is sufficient training data, makes the choice of features less critical.
In the original linear regression algorithm, to make a prediction at a query point x .
1. Fit θ to minimize ∑mi=1(y(i)−θTx(i))2
2. Output θTx .
the locally weighted linear regression algorithm
1. Fit θ to minimize ∑mi=1ω(i)(y(i)−θTx(i))2
2. Output θTx .
A fairly standard choice for the weights is:
ω(i)=exp(−(x(i)−x)22τ2)
if |x(i) − x| is small, then w(i) is close to 1; and if |x(i) − x| is large, then w(i) is small. Hence, θ is chosen giving a much higher “weight” to the (errors on) training examples close to the query point x.
The parameter τ controls how quickly the weight of a training example falls off with distance of its x(i) from the query point x; τ is called the bandwidth parameter.
Locally weighted linear regression is a non-parametric algorithm.The (unweighted) linear regression algorithm that we saw earlier is known as a parametric learning algorithm, because it has a fixed, finite number of parameters (the θi ), which are fit to the data. Once we’ve fit the θi and stored them away, we no longer need to keep the training data around to make future predictions. In contrast, to make predictions using locally weighted linear regression, we need to keep the entire training set around. The term “non-parametric” (roughly) refers to the fact that the amount of stuff we need to keep in order to represent the hypothesis h grows linearly with the size of the training set.















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









