







本文来自斯坦福大学公开课CS229,Andrew Ng学习笔记
1.1 引言
从一个房屋面积和价格的关系入手,房屋面积和价格的数据集如下:
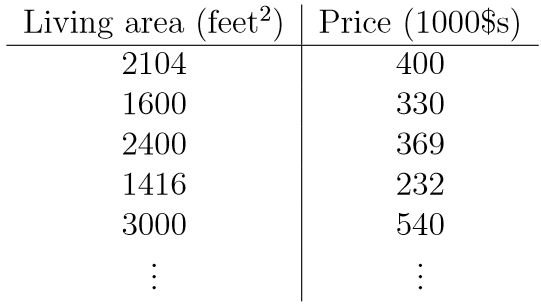
图形化的数据如下:
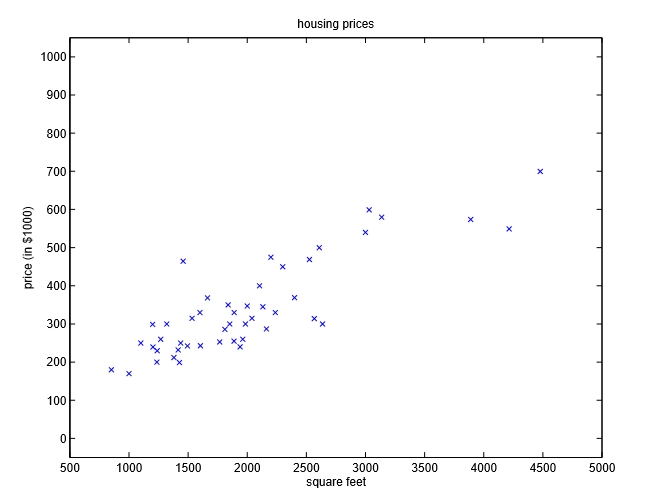
从这个数据集中,我们如何构建模型预测房价和面积的关系呢?
为了方便后面的描述,先引入一些表示方法。
x(i)
–input features
y(i)
–output,target variable
{(
x(i)
,
y(i)
);i=1,2,…,m} –training set
X –space of input values
Y –space of output values
supervised learning可以描述为从给定的训练集中学习一个从X到Y的映射关系h(x),使得h(x)与对应的y而言是一个好的预测。如下图所示:
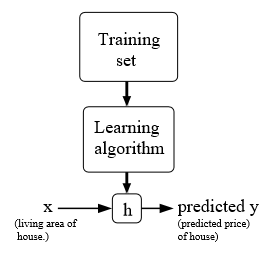
当target variable的取值是连续(continuous)的,我们称此learning problem为regression problem,如果target variable的取值是离散的(discrete),我们称此learning problem为classification problem.
1.2 Linear Regression
在房屋数据集中引入新的维度:房屋的bedrooms,更新后的数据如下:

用
x1(i)
表示第i个房间的面积,
x2(i)
第i个房间的bedrooms的数目,首先假设房屋价格与房屋面积和bedrooms的关系如下:
hθ(x)=θ0+θ1∗x1+θ2∗x2
上式可以简写为:
h(x)=∑ni=0θi∗xi=θT∗x
其中
x0=1
h(xi)
与
yi
的训练函数:
J(θ)=12∑mi=0(hθ(x)−yi)2
1.2.1 LMS(least mean squares) algorithm
首先给出一个初始的猜测的
θ
值,然后通过gradient descent 算法不断的迭代修改
θ
,直至J(
θ
)取得最小值。
θ
的更新公式:
θj:=θj−αδδθjJ(θ)(j=1,2,...n)
考虑只有一个训练集(x,y)的情况:
δδθjJ(θ)=δδθj(hθ(x)−y)2
=(hθ(x)−y)δδθj(hθ(x)−y)
=(hθ(x)−y)xj
单个训练样本的更新公式:
θj:=θj−α(hθ(x)−y)xj(j=1,2,...n)
多于一个训练样本的情况:
方法一:
Repeat until convergence {
θj:=θj−α∑mi=0(hθ(x)−y)xj(j=1,2,...n)
}
方法二:
Repeat until convergence {
for i=1 to m {
θj:=θj−α(hθ(x)−y)xj(j=1,2,...n)
}
}
通常情况下,方法二比方法一收敛的速度更快,因此当样本集数量较大时,通常会选择方法二。
1.2.2 The normal equations
先引入一系列定义:
f:Rm∗n−>R
f是将 m*n维向量映射到实数空间的相对于矩阵A的导数定义如下:
矩阵trace:
假设n*n的方阵A,
trace性质:
1) A、B均为方阵,则有trAB=trBA
2) trABC=trBCA=trCAB, rABCD=trBCDA=trCDAB=trDABC
3) trA=trAT
4) tr(A+B) = trA + trB
5) tr(aA)=a*trA
6) ΔAtrAB=BT
7) ΔATf(A)=(ΔAf(A))T
8) ΔAtrABATC=CAB+CTABT (涉及到复合函数求导,参考 https://en.wikipedia.org/wiki/Matrix_calculus)
9) ΔA|A|=|A|(A−1)T (待证明)
以上述矩阵为基础,重新定义 J(θ) ,
样本矩阵:
target values:
由于
minimize J
ΔθJ(θ)=Δθ12(Xθ−Y)T(Xθ−Y)
(tr(a)=a)
( trA=trAT )
ΔATtrABATC=BTATCT+BATC with AT=θ,B=BT=XTX,C=I
令















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









