







Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
-
原文摘要
-
提出 FramePack 架构
-
一种新的视频生成模型结构。
-
基于“下一帧预测”的思路进行视频生成。
-
-
FramePack核心思想
-
压缩输入帧,固定上下文长度
-
将输入的多个帧压缩成固定长度的上下文。
-
无论视频有多少帧,Transformer 的输入长度都不变。
-
解决了随着视频长度增加而显存爆炸的问题。
-
-
提出 Anti-Drifting 反漂移采样策略
-
先生成视频的开头和结尾,再生成中间帧。
-
生成顺序是“时间反向”的。
-
目的:防止误差在逐帧生成中逐步累积。
-
-
支持大 Batch 训练
-
压缩上下文后,显存占用降低。
-
批量大小(batch size)可以显著提升,加速模型训练。
-
-
-
FramePack的效果
-
计算效率大幅提升
-
视频生成的计算成本接近图像生成。
-
可以处理更多帧、更长时间的视频片段。
-
-
兼容并优化已有视频扩散模型
-
可以在已有模型基础上微调 FramePack。
-
利用更“平衡”的扩散调度器,减少时间步的偏移。
-
带来更好的画面质量和流畅性。
-
-
-
1. Introduction
-
问题与挑战
-
核心问题:视频逐帧(或逐片段)预测模型存在两大关键问题:
- 遗忘(forgetting):模型难以记住早期内容,导致时间依赖性不一致。
- 漂移(drifting):逐帧预测中误差累积导致视觉质量迭代退化(曝光偏差 exposure bias)。
-
Dilemma:缓解遗忘的方法(如增强记忆)会加速误差传播(加剧漂移);而抑制漂移的方法(如打断时间依赖)会加重遗忘。
-
-
现有方法的局限性
- 遗忘的简单解法:直接编码更多帧会导致计算复杂度爆炸(Transformer注意力复杂度为平方级)。
-
效率问题:视频帧间存在大量冗余,全上下文编码效率低下。
-
漂移的复杂性:
- 误差来源:单帧初始错误。
- 误差影响:通过记忆机制传播累积,形成矛盾——强记忆机制既减少初始错误(抑制漂移),又加速错误传播(加剧漂移)。
-
- 遗忘的简单解法:直接编码更多帧会导致计算复杂度爆炸(Transformer注意力复杂度为平方级)。
-
解决方案框架
-
FramePack结构:
-
抗遗忘:通过重要性压缩输入帧,固定上下文长度上限,支持更多帧编码且不增加计算负担。
- 抗漂移采样方法:
- 打破因果预测链,引入双向上下文。
- 具体策略:
- 端点优先生成:先生成关键帧(endpoint frames),再填充中间内容。
- 逆向时序采样:反向生成,逐步逼近已知高质量帧。
- 抗漂移采样方法:
-
-
-
技术优势与发现
-
兼容性:可微调现有视频扩散模型(如HunyuanVideo、Wan)。
-
实验发现:
-
全视频生成的调度器问题:
-
由于一次性处理长序列,需在极端时间步(如极早或极晚的
timestep)分配更多权重,以覆盖全局信息。 -
例如:早期时间步需快速降噪以捕捉整体运动,后期时间步需精细调整细节,导致调度器
激进(aggressive),表现为:
- 时间步间隔不均匀(如大跨度跳跃)。
- 噪声强度变化剧烈(如突然从高噪声切换到低噪声)。
-
-
逐帧预测的调度器优势:
- 单步处理的张量小,允许调度器更平衡地分配时间步:
- 时间步间隔更均匀(如线性或余弦调度)。
- 噪声强度变化平缓(避免极端跳跃)。
- 结果:
- 模型在每个时间步都能充分优化,避免因激进调度导致的局部过拟合或欠优化。
- 误差在单帧内更容易被修正,不会因极端时间步累积到后续帧(缓解漂移的副作用)。
- 单步处理的张量小,允许调度器更平衡地分配时间步:
-
逐帧预测的每步张量更小,支持更平衡的扩散调度器(减少极端时间步偏移)。
-
温和的调度器可能间接提升视觉质量,超越解决遗忘/漂移的直接目标。
-
-
2. 相关工作
2.1 Anti-forgetting and Anti-drifting
- 核心问题:视频生成中遗忘(forgetting)和漂移(drifting)的权衡与现有解决方法。
-
噪声调度与增强(Noise Scheduling & Augmentation)
- 方法:通过修改历史帧的噪声水平或时序分布,减少对过去帧的依赖。
- 典型工作: 在特定时间步或频率上添加噪声,打断误差传播链。
- 作用:降低历史帧的误差累积(抗漂移),但可能加剧遗忘(因削弱时间依赖性)。
- 本文实验:通过消融研究分析历史帧加噪声的影响。
- 方法:通过修改历史帧的噪声水平或时序分布,减少对过去帧的依赖。
-
基于分类器无关引导(Classifier-Free Guidance, CFG)的方法
- 方法:对历史帧施加不同的掩码或噪声强度,放大遗忘-漂移的权衡效应。
- 典型工作: 通过引导策略调整历史帧的噪声水平。
- 本文实验:包含基于引导的噪声调度测试。
- 方法:对历史帧施加不同的掩码或噪声强度,放大遗忘-漂移的权衡效应。
-
锚定帧(Anchor Frames)规划
- 方法:使用关键帧(如参考图像)作为视频生成的规划基准。
- 典型工作:
- 锚定帧约束生成内容的一致性。
- 利用图像/视频锚点进行时序内容规划。
- 典型工作:
- 方法:使用关键帧(如参考图像)作为视频生成的规划基准。
-
潜在空间压缩(Latent Space Compression)
- 方法:压缩视频表示的潜在空间,提升计算效率。
- 典型工作:
- LTXVideo:高压缩潜在空间实现高效视频扩散。
- Pyramid-Flow:金字塔结构的多尺度潜在去噪,降低计算成本。
- FAR :多级因果注意力结构,建立长短期上下文缓存(KV caches)。
- HiTVideo :分层标记器(tokenizers)结合自回归语言模型增强生成。
- 典型工作:
- 方法:压缩视频表示的潜在空间,提升计算效率。
-
遗忘与漂移的权衡讨论
- 关键发现:
- CausVid :因果性视频生成器在长视频末尾出现质量下降(漂移),且视频长度受限。
- DiffusionForcing :漂移源于训练与推理阶段的观测差异导致的误差累积。
- Wang et al. :强记忆机制可能加速错误传播(漂移加剧)。
- 关键发现:
2.2 Long Video Generation
- 核心问题:如何扩展视频生成长度并保持时序一致性。
-
潜在扩散与多提示生成
- 典型工作:
- LVDM :基于潜在扩散的长视频生成。
- Phenaki :通过文本提示序列生成可变长度视频。
- Gen-L-Video :多文本条件视频的时序协同去噪。
- 典型工作:
-
无需训练的扩展方法
- 典型工作:
- FreeNoise :通过噪声重调度(rescheduling)扩展预训练模型。
- 典型工作:
-
分层与分布式生成
- 典型工作:
- NUWA-XL :扩散叠加扩散(Diffusion-over-Diffusion)的粗到细生成。
- Video-Infinity :分布式生成突破计算限制。
- 典型工作:
-
一致性长视频生成
- 典型工作:
- StreamingT2V :无硬切片的动态可扩展视频生成。
- CausVid :通过蒸馏将双向模型转为快速自回归模型。
- 典型工作:
-
其他前沿技术
- 方法分类:
- GPT式架构(ViD-GPT)、多事件生成(MEVG)。
- 注意力控制(DiTCtrl)、时序精控(MinT)。
- 历史引导(HistoryGuidance)、统一扩散(DiffusionForcing)。
- 谱混合注意力(FreeLong)、测试时训练(TTT )。
- 方法分类:
2.3 Efficient Architectures for Video Generation
- 核心问题:提升视频生成模型的效率。
-
线性注意力(Linear Attention)
- 方法:重构线性运算降低注意力复杂度
O
(
N
2
)
→
O
(
N
)
O(N^2) \rightarrow O(N)
O(N2)→O(N)。
- 典型工作: 通过核函数近似或矩阵分解优化。
- 方法:重构线性运算降低注意力复杂度
O
(
N
2
)
→
O
(
N
)
O(N^2) \rightarrow O(N)
O(N2)→O(N)。
-
稀疏注意力(Sparse Attention)
- 方法:仅计算重要标记对(token pairs)的注意力。
- 典型工作: 基于局部性、哈希或可学习稀疏模式。
- 方法:仅计算重要标记对(token pairs)的注意力。
-
低比特计算(Low-bit Computation)
- 方法:量化模型权重和激活值(如FP16 → INT8)。
- 典型工作: 通用量化;注意力专用量化。
- 方法:量化模型权重和激活值(如FP16 → INT8)。
-
隐藏状态缓存(Hidden State Caching)
- 方法:跨扩散时间步复用中间计算结果。
- 典型工作: 避免冗余计算,提升推理速度。
- 方法:跨扩散时间步复用中间计算结果。
-
蒸馏(Distillation)
- 方法:将大模型知识迁移到小模型或减少采样步数。
- 典型工作: 步数蒸馏、架构蒸馏。
- 方法:将大模型知识迁移到小模型或减少采样步数。
3. 方法
-
任务描述
- 目标:通过逐帧(或逐片段)预测生成连续视频。
- 每次预测
S
S
S 帧(通常
S
=
1
S=1
S=1 或小数值),条件依赖于
T
T
T 帧历史输入(
T
≫
S
T\gg S
T≫S )。
- 输入帧: F ∈ R T × h × w × c F \in \mathbb{R}^{T \times h \times w \times c} F∈RT×h×w×c
- 输出帧: X ∈ R S × h × w × c X \in \mathbb{R}^{S \times h \times w \times c} X∈RS×h×w×c
- 每次预测
S
S
S 帧(通常
S
=
1
S=1
S=1 或小数值),条件依赖于
T
T
T 帧历史输入(
T
≫
S
T\gg S
T≫S )。
- 目标:通过逐帧(或逐片段)预测生成连续视频。
-
模型类型:基于 扩散Transformer(DiT) 的预测模型,所有帧和像素均在潜在空间中操作。
-
核心挑战:上下文长度爆炸
-
单帧上下文长度:每帧的token数 L f L_f Lf(例如Hunyuan/Wan/Flux模型中480p的帧的 L f ≈ 1560 L_f \approx 1560 Lf≈1560)。
-
总上下文长度: L = L f ( T + S ) L = L_f (T + S) L=Lf(T+S)
- 当历史帧数 T T T 较大时(如长视频生成), L L L 急剧增长,导致计算不可行(Transformer注意力复杂度为 O ( L 2 ) O(L^2) O(L2) )。
-
3.1 FramePack
3.1.1 核心思想
- 基于时间重要性的帧压缩
-
重要性优先级假设
-
观察:输入帧 F 0 , F 1 , … , F T − 1 F_0, F_1, \dots, F_{T-1} F0,F1,…,FT−1 对下一帧预测的贡献不同。
-
简化假设:时间邻近性反映重要性(Temporal Proximity Prior)。
- 最近帧 F 0 F_0 F0(最新)最重要,最远帧 F T − 1 F_{T-1} FT−1(最旧)最不重要。
- 注:实际可扩展至其他重要性度量(如运动强度、语义关键性)。
-
-
目标
-
通过动态分配每帧的上下文长度(token数),实现:
-
重要帧(如 F 0 F_0 F0 )保留更多细节(高token数)。
-
非重要帧(如 F T − 1 F_{T-1} FT−1 )高度压缩(低token数)。
-
总上下文长度 L L L 收敛到固定上界,与历史帧数 T T T 无关。
-
-
3.1.2 压缩机制设计
-
长度函数 ϕ ( F i ) \phi(F_i) ϕ(Fi)
-
定义:在VAE编码和Transformer Patchifying之后,第 i i i 帧 F i F_i Fi 的上下文长度(token数,不改变token的维度)为:
ϕ ( F i ) = L f λ i ( λ > 1 ) \phi(F_i) = \frac{L_f}{\lambda^i} \quad (\lambda > 1) ϕ(Fi)=λiLf(λ>1)- L f L_f Lf :原始单帧token数(如480p帧的1560)
- λ \lambda λ:压缩因子
-
-
实现方式:动态Patchify核
- 操作:通过调整Transformer输入层的 patchify核尺寸 实现压缩。
- 示例:若
λ
=
2
\lambda=2
λ=2,
i
=
5
i=5
i=5,则核体积
λ
i
=
32
\lambda^i = 32
λi=32,可能的核形状:
- 空间维度: 8 × 2 × 2 8 \times 2 \times 2 8×2×2(长×宽×通道)。
- 时间维度: 2 × 4 × 4 2 \times 4 \times 4 2×4×4(若需时序感知)。
- 效果:核越大 → 下采样率越高 → token数越少。
- 示例:若
λ
=
2
\lambda=2
λ=2,
i
=
5
i=5
i=5,则核体积
λ
i
=
32
\lambda^i = 32
λi=32,可能的核形状:
- 操作:通过调整Transformer输入层的 patchify核尺寸 实现压缩。
3.1.3 总上下文长度数学性质
-
公式
L = S ⋅ L f + L f ⋅ ∑ i = 0 T − 1 1 λ i = S ⋅ L f + L f ⋅ 1 − 1 / λ T 1 − 1 / λ L = S \cdot L_f + L_f \cdot \sum_{i=0}^{T-1} \frac{1}{\lambda^i} = S \cdot L_f + L_f \cdot \frac{1 - 1/\lambda^T}{1 - 1/\lambda} L=S⋅Lf+Lf⋅i=0∑T−1λi1=S⋅Lf+Lf⋅1−1/λ1−1/λT-
第一项 S ⋅ L f S \cdot L_f S⋅Lf :预测帧 X X X 的原始token数。
-
第二项:历史帧压缩后的总token数(等比数列求和)。
-
-
极限行为( T → ∞ T \to \infty T→∞ )
lim T → ∞ L = ( S + λ λ − 1 ) ⋅ L f \lim_{T \to \infty} L = \left( S + \frac{\lambda}{\lambda - 1} \right) \cdot L_f T→∞limL=(S+λ−1λ)⋅Lf -
结论:
-
当历史帧数 T T T 趋近无穷时, L L L 收敛到固定值。
-
因为 L L L 收敛为固定值,所以复杂度瓶颈和 T T T (即帧数) 无关
-
示例:若 λ = 2 \lambda=2 λ=2 , S = 1 S=1 S=1 , L f = 1560 L_f=1560 Lf=1560 :
L ∞ = ( 1 + 2 2 − 1 ) ⋅ 1560 = 4680 ( 与 T 无关 ) L_\infty = \left(1 + \frac{2}{2-1}\right) \cdot 1560 = 4680 \quad (\text{与} T \text{无关}) L∞=(1+2−12)⋅1560=4680(与T无关)
-
-
λ \lambda λ 选择
-
硬件优先:默认选择 λ = 2 λ=2 λ=2 的幂次核尺寸(如 ( 4 , 4 , 4 ) (4,4,4) (4,4,4) )。
-
灵活调整:通过复制/舍弃级数项适配不同压缩需求(如长视频需更高压缩率)。
-
核尺寸权衡:
-
静态内容 → 大空间核。
-
动态内容 → 大时间核。
-
3D Patchify核的维度表示
-
3D核尺寸: ( p f , p h , p w ) (p_f,p_h,p_w) (pf,ph,pw)
- p f p_f pf :时间维度(帧数)的patch跨度。
- p h , p w p_h,p_w ph,pw :空间维度(高度、宽度)的patch大小。
-
物理意义:
- 每个3D核将输入视频块 p f × p h × p w × d p_f \times p_h \times p_w \times d pf×ph×pw×d( d d d 为通道数)压缩为1个token。
-
-
-
与FramePack结合:动态核调整实现抗遗忘(保留关键帧细节)与抗漂移(压缩非关键帧)。
3.1.4 Independent patchifying parameters
独立patchifying的参数
-
核心问题
- 不同压缩率下,深度神经网络提取到的特征是不同的,比如对一帧用压缩率 (2, 4, 4) 和 (8, 16, 16) 会产生显著不同的空间-时间表示。
- 所以不能一个卷积(用于将patch投影成token)用于所有压缩率。
-
实验发现:
- 如果每种压缩率都配一套独立的 projection 参数(即独立的卷积核),能让模型学习更稳定,效果更好。
- 因为不同尺度下的图像内容表达方式、重要性差异太大,不宜共用参数。
-
具体做法
-
选定3种主流压缩率来处理视频帧: ( 2 , 4 , 4 ) 、 ( 4 , 8 , 8 ) 、 ( 8 , 16 , 16 ) (2,4,4)、(4,8,8)、(8,16,16) (2,4,4)、(4,8,8)、(8,16,16)
-
对每种压缩率,他们都配了一套 单独的神经网络层 来做输入编码
-
处理极端压缩
-
如果某些帧需要更极端压缩(如 ( 16 , 32 , 32 ) (16,32,32) (16,32,32)),那就先做一次下采样(如用2×2×2卷积降分辨率);
-
然后用已有的最大卷积核
(8, 16, 16)来继续编码。 -
优势:避免无限制地增加新的 projection 层数量,提高参数复用性。
-
-
为了加速收敛,防止训练不稳定:
-
新的 projection 层会从已有的预训练模型中“插值”初始化(比如从 HunyuanVideo 的 (2,4,4) patch 投影参数中插值得到)。
-
插值初始化 = 保留已有模型的知识 + 提升收敛效率 + 避免随机初始化带来的不稳定。
-
-
3.1.5 Tail options
尾帧处理
-
问题背景
-
FramePack压缩过程通过一个 动态分配机制:
- 重要帧 → 使用更细致的压缩(低压缩率)
- 不重要帧(如尾部冗余帧)→ 使用更强压缩(高压缩率)或删除
-
现实中,如果视频非常长,最后那一部分帧可能:
-
已经被压缩得非常极端(比如 16×32×32)
-
再压缩下去就没法再分出一个 patch(比如只剩 1 个 latent 像素)
-
这就是所谓的 “tail 区域”:即最后这部分帧,已不足以组成一个 patch 或 token。
-
-
-
处理方法
-
直接删除尾帧(Delete the tail)
-
如果某些尾帧压缩后不足以形成一个 token,就不处理了,直接舍弃。
-
好处:保持固定上下文长度,计算量小。
-
缺点:丢掉一些帧(但这些帧本来就不重要)。
-
-
-
让每个尾帧单独增加 1 个 latent token
-
虽然不能组成 patch,但每一帧都映射成 1 个 token 加进 transformer。
-
意味着上下文长度 轻微增加(每多一帧就多 1 个 token)。
-
更保守地保留全部信息,但轻微打破 context length 固定的假设。
-
-
把所有尾帧做全局平均池化,然后用最大 kernel 编码为一个 token
-
把所有 tail 帧的 latent 特征做
global average pooling(类似做一个平均帧)。 -
然后用预设的最大压缩核(如 8×16×16)生成一个 token,代表全部尾帧。
-
既保留信息,也保证 context 长度不变。
-
-
-
实验观察
- 这些三种策略在视觉效果上的差异很小(visual differences are relatively negligible), 说明对尾帧的具体处理策略并不是特别敏感,毕竟这些帧不重要。
3.1.6 RoPE alignment
RoPE对齐
- 问题背景
- FramePack 对输入视频帧进行压缩编码 —— 有的帧用 2×4×4 的核,有的用 8×16×16 ,即
- 每个帧被编码成不同数量的 token,导致上下文长度不一致。
- RoPE 是位置编码机制,需要和上下文长度对齐。如果不处理这些差异,Transformer 就会“搞不清楚”哪个 token 来自哪个位置。
- FramePack 对输入视频帧进行压缩编码 —— 有的帧用 2×4×4 的核,有的用 8×16×16 ,即
- 解决方案
- 对 RoPE 相位本身进行下采样(平均池化)
- 使得位置编码(phase)与 压缩后 token 的空间位置数量一致,例如
- 原视频帧有 32×32 空间分辨率,RoPE 的相位是 32×32 个位置
- 用了 4×4 的压缩核,帧变成了 8×8 token
- 那就把原始 RoPE 的相位做
avg_pooling(kernel=4x4),变成 8×8 的相位 - 然后这个新相位用于编码压缩后的 token
3.2 FramePack Variants

-
典型几何级数(Typical Geometric Progression)
-
压缩率:按几何级数递减(如 1 , 1 2 , 1 4 , 1 8 , 1 16 1, \frac{1}{2}, \frac{1}{4}, \frac{1}{8}, \frac{1}{16} 1,21,41,81,161 )。
-
Patchify核:核尺寸逐级增大(如 ( 1 , 2 , 2 ) → ( 1 , 8 , 8 ) (1,2,2) \rightarrow (1,8,8) (1,2,2)→(1,8,8)),对应更粗粒度的分块。
-
特点:
- 最近帧 F 0 F_0 F0 保留完整token数(无压缩),旧帧逐步压缩。
- 计算效率高,但可能丢失远距离依赖。
-
-
带重复级别的级数(Progression with Duplicated Levels)
-
压缩率:非连续递减,部分级别重复(如 1 , 1 4 , 1 4 , 1 16 , … 1, \frac{1}{4}, \frac{1}{4}, \frac{1}{16}, \dots 1,41,41,161,… )。
-
Patchify核:相同核尺寸重复使用(如两个 ( 1 , 4 , 4 ) (1,4,4) (1,4,4) 连续应用)。
-
特点:
- 平衡压缩率与信息保留,避免某些帧被过度压缩。
- 适合中等长度视频,需兼顾局部与全局信息。
-
-
时空联合分块级数(Geometry Progression with Temporal Kernel)
-
压缩率:时空联合分块(如 ( 4 , 4 , 4 ) (4,4,4) (4,4,4) 表示跨4帧×4×4空间分块)。
-
Patchify核:核尺寸包含时间维度(如 ( 8 , 8 , 4 ) (8,8,4) (8,8,4) )。
-
特点:
- 显式利用时序冗余,减少总token数。
- 计算代价最低,但可能模糊快速运动细节。
-
-
重要起始级数(Progression with Important Start)
-
压缩率:与 1 相同,但强制首帧 F T − 1 F_{T-1} FT−1 保留完整token数。
-
Patchify核:同 1 ,但首帧不压缩。
-
特点:
- 首帧(如场景初始状态)作为长期记忆锚点,缓解遗忘。
- 适合场景切换较少的长视频。
-
-
对称级数(Symmetric Progression)
-
压缩率:首尾帧对称分配高token数(如 F T − 1 F_{T-1} FT−1 和 F 0 F_0 F0 均无压缩)。
-
Patchify核:同 4 ,但两端帧均保留完整信息。
-
特点:
- 双向依赖增强,适合需全局规划的任务(如文本到视频)。
- 计算成本略高,但抗漂移能力更强。
-
3.3 Anti-drifting Sampling
抗漂移采样
-
问题定义
- Drifting:在基于逐帧预测(next-frame prediction)的视频生成中,生成的画面随着帧数增加会变模糊、失真、甚至偏移主题
- 产生原因:模型只“从前往后看”(单向预测、严格因果)时,漂移就容易出现
- Drifting:在基于逐帧预测(next-frame prediction)的视频生成中,生成的画面随着帧数增加会变模糊、失真、甚至偏移主题
-
解决方法:提供未来帧的访问能力
- 让模型看到一个“未来帧”(哪怕只是一帧),也会显著缓解漂移现象。
- 启发式结论:视频的质量依赖于“双向上下文”,而非仅靠因果关系。
- 让模型看到一个“未来帧”(哪怕只是一帧),也会显著缓解漂移现象。
-
采样方式
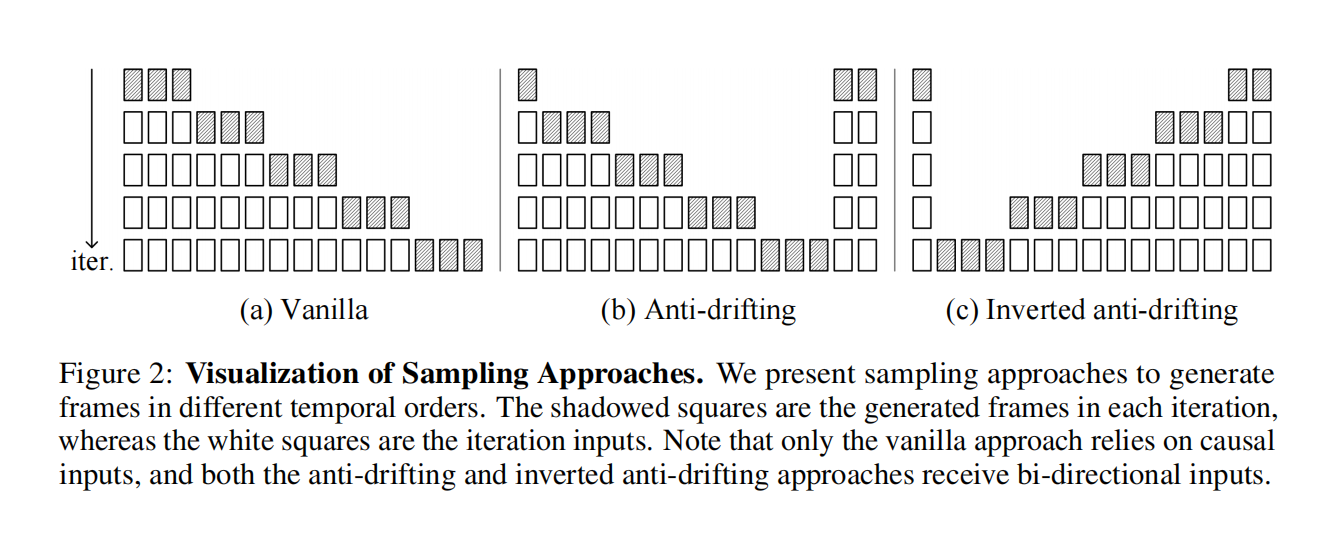
-
普通因果采样
-
就是传统的“从已知帧开始,一帧一帧往后生成”
-
完全因果,每次生成的帧依赖于前面的内容
-
缺点:越往后越不稳定 → 漂移现象严重
-
-
双向采样
-
第一轮就生成“开头帧”和“结尾帧”
-
后续轮次只负责填补中间的内容(inpainting)
-
好处:
-
生成过程有两个锚点(begin + end),
-
中间帧是受控生成 → 不易漂移
-
-
-
适合生成中等长度的高质量视频
-
-
反向采样
-
image-to-video中:
-
用户给的是高质量的第一帧
-
我们要生成后续帧,但要逐步逼近第一帧的风格和语义
-
-
即:
-
第一轮仍然生成末尾帧(作为 anchor)
-
然后反向采样 + 插值,保证前后帧都逼近第一帧
-
-
特别适合 image-to-video / prompt-to-video 任务
-
-
-
RoPE with random access
-
反向采样的问题:非连续RoPE编码
-
解决方法:
-
RoPE 编码仍然是“全局时间索引感知”的
-
但当我们不处理某些帧时(例如 frame 1~9),我们不生成这些帧的 RoPE 相位
-
只保留 frame 0、10、30、50 的 RoPE phase,且保持其真实时间位置
-
直观做法
# 原始位置 index: positions = [0, 10, 30, 50] # 假设你有一个 RoPE 编码器,支持任意 index 输入: rope_encoding = get_rope_encoding(positions) -
-
4. 实验
4.1 消融实验命名规范
-
命名结构的总体格式:
-
结构形如:
td_f16k4f4k2f1k1_g9_x_f1k1 -
可以被拆解为几个部分:
字段名 含义 td tail 处理方式(如 td、ta、tc) f16k4f4k2f1k1 主干压缩结构(表示不同帧段使用了不同的 kernel) g9 表示要生成的帧数量 x 表示“跳过”部分帧(防漂移) f1k1 表示在 x之后使用的 anchor 帧压缩设置(例如后端锚点)
-
-
Kernel 编码结构解释
-
完整表示法:
k1h2w2 → 表示 kernel=(1帧, 2高, 2宽) k2h4w4 → 表示 kernel=(2帧, 4高, 4宽) -
简写(常用)方式:
-
FramePack 为了简洁,引入如下缩写:
简写 实际 kernel k1 (1, 2, 2) k2 (2, 4, 4) k4 (4, 8, 8) k8 (8, 16, 16)
-
-
举例:
f16k4 → 表示 16 帧用 k4 编码(即 kernel=(4,8,8)) f4k2 → 表示 4 帧用 k2 编码(即 kernel=(2,4,4)) f1k1 → 表示 1 帧用 k1 编码(即 kernel=(1,2,2))
-
-
三种tail的策略
| 代码 | 含义 |
|---|---|
td | 删除这些尾帧(delete) |
ta | 先使用 3D Pooling (1,32,32),再找最接近的 kernel 编码(append) |
tc | 对 tail 全局 average pooling,再编码(compress) |
-
Sampling 采样策略对应的命名结构
-
Vanilla 采样(顺序采样 Fig.2-a)
-
td_f16k4f4k2f1k1_g9-
删除尾帧(td)
-
使用 f16k4f4k2f1k1 的三层结构来压缩连续的19帧的视频段
-
然后依次生成 9 帧(g9)
-
-
-
Anti-drifting 采样(双向锚点,Fig.2-b)
-
td_f16k4f4k2f1k1_g9_x_f1k1-
在 Vanilla 基础上加了
_x_f1k1 -
表示:跳过中间帧,在最后加了一个锚点帧(也用 k1 编码)
-
所以是“双向锚定”,先生成开头和结尾,再补中间 → 防漂移
-
-
-
Inverted anti-drifting(倒序采样,Fig.2-c)
-
f1k1_x_g9_f1k1f4k2f16k4_td-
倒过来:先以末尾帧为起点(f1k1)
-
加上前置 anchor,然后生成中间(g9)
-
再“反方向”补充前段(f4k2f16k4)
-
最后处理 tail(td)
-
-
-
-
跳帧
x的作用-
把中间帧留空,模型之后再去插补这些帧。
-
f1k1 + x + f1k1:提供两端锚点帧 -
g9:指在中间补出 9 帧
-
模型知道前后锚点,就不会发生质量飘移
-
-
4.2 实现细节
| 项目 | 内容 |
|---|---|
| 框架模式 | Text-to-video 与 Image-to-video |
| 模型 | Wan2.1 和 HunyuanVideo(推荐) |
| 关键修改 | 冻结 LLaMA、多模态清除、使用 SigLip、持续训练 |
| 数据集 | 参考 LTXVideo,质量过滤 + 分辨率桶 |
| 训练配置 | Adafactor、1e-5 学习率、梯度裁剪 0.5 |
| 硬件支持 | A100/H100,支持大 batch |
| 训练时间 | ablation 实验 48h,最终模型 7 天 |
| 优势 | 快速、适合实验室,视频生成清晰、稳定 |
4.3 评估
- 文本到视频(Text-to-video) 和 图像到视频(Image-to-video) 的任务分别测试了 512 个来自真实用户的提示(prompts)。这些提示来自 真实用户,以确保数据集的多样性和 真实世界的适用性。
- 测试的视频时长设定:
- 长视频:默认使用 30秒 作为标准时长;
- 短视频:默认使用 5秒 作为标准时长。

-
漂移测量:起始-结束对比度(start-end contrast)。
-
定义
- 对于任意一个视频质量指标
M
M
M,定义漂移度量为:
Δ
M
drift
(
V
)
=
∣
M
(
V
start
)
−
M
(
V
end
)
∣
\Delta M_{\text{drift}}(V) = |M(V_{\text{start}}) - M(V_{\text{end}})|
ΔMdrift(V)=∣M(Vstart)−M(Vend)∣
- V V V:待测视频
- V start V_{\text{start}} Vstart:视频的前15%的帧
- V end V_{\text{end}} Vend:视频的后15%的帧
- M M M:任意质量度量(如运动评分、图像质量等)
- 对于任意一个视频质量指标
M
M
M,定义漂移度量为:
Δ
M
drift
(
V
)
=
∣
M
(
V
start
)
−
M
(
V
end
)
∣
\Delta M_{\text{drift}}(V) = |M(V_{\text{start}}) - M(V_{\text{end}})|
ΔMdrift(V)=∣M(Vstart)−M(Vend)∣
-
含义
-
差值越大,表示前后质量差异越大,漂移越严重;
-
使用绝对值是为了忽略生成顺序的方向性(比如有的模型从前往后生成,有的从后往前)
-
-

















 3016
3016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









